
O segundo dia do programa principal do KDD. Sob o corte novamente, muitas coisas interessantes: do aprendizado de máquina no Pinterest a várias maneiras de cavar canos de água. Incluindo o discurso do Prêmio Nobel de Economia - uma história sobre como a NASA trabalha com telemetria e muitos gráficos incorporados :)
Design de mercado e mercado informatizado
Um bom desempenho do
Prêmio Nobel que trabalhou com Shapley nos mercados. O mercado é uma coisa artificial, cujo dispositivo as pessoas inventam. Existem os chamados mercados de commodities, quando você compra um determinado produto e não se importa com quem, importa apenas a que preço (por exemplo, o mercado de ações). E existem mercados correspondentes quando o preço não é o único fator (e às vezes não é de todo).
Por exemplo, a distribuição de crianças nas escolas. Anteriormente, nos EUA, o esquema funcionava assim: os pais escrevem a lista de escolas por prioridade (1, 2, 3 etc.), as escolas consideram primeiro as que as indicaram como número 1, classificam-nas de acordo com os critérios da escola e levam o máximo que podem receber . Para quem não acertou, pegamos a segunda escola e repetimos o procedimento. Do ponto de vista da teoria dos jogos, o esquema é muito ruim: os pais precisam se comportar "estrategicamente", é impraticável dizer honestamente suas preferências - se você não ingressar na escola 1, na segunda rodada, a escola 2 já estará cheia e você não entrará nela, mesmo que suas características sejam maiores do que aquelas que foram aceitas no primeiro turno. Na prática, o desrespeito à teoria dos jogos se traduz em corrupção e acordos internos entre pais e escola. Os matemáticos propuseram outro algoritmo - "aceitação adiada". A idéia principal é que a escola não dê consentimento imediatamente, mas simplesmente mantém uma lista classificada de candidatos "na memória" e, se alguém vai além da cauda, imediatamente recebe uma recusa. Nesse caso, existe uma estratégia dominante para os pais: primeiro vamos para a escola 1, se em algum momento temos uma recusa, depois vamos para a escola 2 e não temos medo de perder nada - as chances de chegar à escola 2 são as mesmas de se estivéssemos nela imediatamente. Este esquema foi implementado "em produção", no entanto. Os resultados do teste A / B não foram relatados.
Outro exemplo é o transplante de rim. Ao contrário de muitos outros órgãos, você pode viver com um rim, então surge uma situação em que alguém está pronto para dar um rim a outra pessoa, mas não um abstrato, mas um específico (devido a relacionamentos pessoais). No entanto, a probabilidade de o doador e o destinatário serem compatíveis é muito pequena e você deve esperar por outro órgão. Existe uma alternativa - troca de rim. Se dois pares são um doador e um destinatário e são incompatíveis por dentro, mas compatíveis entre os pares, você pode trocar: 4 operações simultâneas de extração / implantação. O sistema já funciona para isso. E se houver um órgão "livre" que não esteja vinculado a um par específico, ele poderá dar origem a toda uma cadeia de trocas (na prática, havia cadeias de até 30 transplantes).
Atualmente, existem muitos mercados semelhantes: do Uber ao mercado de publicidade on-line, e tudo muda muito rapidamente devido à informatização. Entre outras coisas, a “privacidade” está mudando bastante: como exemplo, o palestrante citou um estudo de um aluno que mostrou que nos EUA após a eleição, o número de viagens a visitar no Dia de Ação de Graças diminuiu devido a viagens entre estados com diferentes visões políticas. O estudo foi realizado em um conjunto de dados anônimo de coordenadas de telefone, mas o autor identificou com bastante facilidade a "casa" do proprietário do telefone, ou seja, conjunto de dados desanonimizado.
Separadamente, o orador caminhava sobre o desemprego tecnológico. Sim, carros não tripulados privarão muitos deles (6% dos empregos nos EUA estão em risco), mas eles criarão novos empregos (para mecânica de automóveis). Evidentemente, o motorista idoso não será mais capaz de treinar novamente e, para ele, será um forte golpe. Nesses momentos, você precisa se concentrar não em como evitar mudanças (não funcionará), mas em como ajudar as pessoas a passar por elas da maneira mais fácil possível. Em meados do século passado, durante a mecanização da agricultura, muitas pessoas perderam o emprego, mas estamos contentes que agora metade da população não precise trabalhar no campo? Infelizmente, trata-se apenas de opções de mitigação implementadas para aqueles que enfrentam desemprego tecnológico, o orador não sugeriu ...
E sim, novamente sobre justiça. É impossível tornar a distribuição do modelo de previsão a mesma em todos os grupos, o modelo perderá seu significado. O que pode ser feito, em teoria, para que a distribuição de ERROS do primeiro e do segundo tipo seja a mesma para todos os grupos? Já parece muito mais sensato, mas como conseguir isso na prática não está claro. Ele deu um link para um artigo interessante sobre prática jurídica - nos EUA, um juiz decide se deve ser libertado sob fiança
com base nas previsões de ML .
Recomendadores I
Fiquei confuso na programação e cheguei ao discurso errado, mas ainda no tópico - o primeiro bloco em sistemas de recomendação.
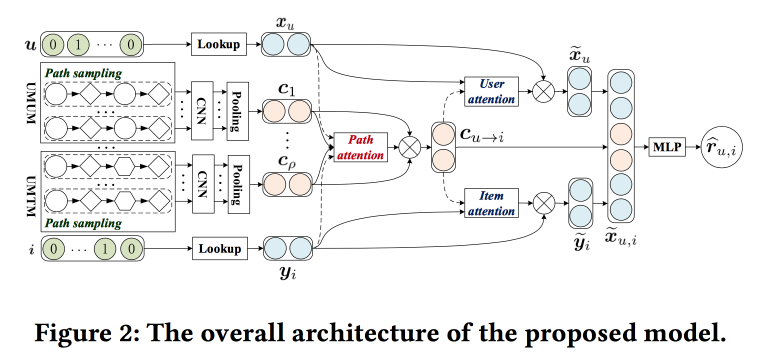
Alavancando o contexto baseado em meta-caminho para a recomendação Top N com mecanismo de co-atenção
Os caras estão tentando melhorar as recomendações analisando os caminhos no gráfico. A ideia é bem simples. Existe um recomendador de rede neural "clássico" com incorporação de objetos e usuários e uma parte totalmente conectada na parte superior. Existem recomendações no gráfico, incluindo aquelas com marcações de redes neurais. Vamos tentar combinar tudo isso em um mecanismo. Começamos construindo um “meta-gráfico” que une usuários, filmes e atributos (ator / diretor / gênero, etc.). No gráfico aleatório, mostramos vários caminhos, alimentamos a rede de convolução, adicionamos incorporações de usuários ao lado e objeto, e mais colocamos atenção (aqui um pouco complicado, com suas próprias características para diferentes ramos). Para obter a resposta final, coloque um perceptron com duas camadas ocultas no topo.
Aplicativos de Internet para Consumidores
No intervalo entre os relatórios, passo para a apresentação onde originalmente queria: palestrantes convidados do LinkedIn, Pinterest e Amazon falam aqui. Todas as meninas e todos os chefes dos departamentos da DS.
Recomendações contextuais da Neraline para comunidades ativas LinkedIn
O ponto principal é estimular o desenvolvimento e a ativação da comunidade no LinkedIn. Eu perdi metade do desenvolvimento, a última recomendação: explorar padrões locais. Por exemplo, na Índia, os alunos geralmente após a graduação tentam entrar em contato com os graduados da mesma universidade de cursos anteriores com uma carreira estabelecida. O LinkedIn leva isso em consideração ao criar e ao fazer recomendações.
Mas apenas criar uma comunidade não é suficiente, é necessário que haja atividade: os usuários publicam conteúdo, recebem e dão feedback. Mostre a correlação do feedback recebido com o número de publicações no futuro. Mostre como as informações são distribuídas em cascata pelo gráfico. Mas e se um nó não estiver envolvido na cascata? Enviar aviso!
Depois, houve muitas conversas com a história de ontem sobre como trabalhar com notificações e a fita. Aqui eles também usam a abordagem de otimização multiuso de "maximizar uma das métricas enquanto mantém as outras dentro de certos limites". Para controlar a carga, introduzimos o nosso sistema Air Trafic Control, que limita a carga nas notificações por usuário (eles foram capazes de reduzir o número de cancelamentos de inscrição e reclamações em 20% sem diminuir o envolvimento). O ATC decide se o envio pode ser enviado ao usuário ou não, e esse envio é preparado por outro sistema chamado Concourse, que funciona no modo de streaming (como o nosso, no
Samza !). Foi sobre ela que muito foi dito ontem. O Concourse também tem um parceiro offline chamado Beehive, mas gradualmente está cada vez mais transmitindo.
Observou mais alguns pontos:
- A desduplicação é importante e de alta qualidade, dada a presença de muitos canais e conteúdos.
- É importante ter uma plataforma. E eles têm uma equipe de plataforma dedicada e os programadores trabalham lá.
Abordagem do Pinterest para aprendizado de máquina
Um
porta -
voz do Pinterest agora fala e fala sobre duas grandes tarefas que usam o ML-feed (homefeed) e a pesquisa. O palestrante diz imediatamente que o produto final é o resultado do trabalho não apenas dos cientistas de dados, mas também dos engenheiros e programadores da ML - pessoas foram alocadas a todos eles.
A fita (a situação em que não há intenção do usuário) é construída de acordo com o seguinte modelo:
- Entendemos o usuário - usamos informações do perfil, gráfico, interação com os pinos (que vi que chutei), construímos incorporações de acordo com o comportamento e os atributos.
- Entendemos o conteúdo - o analisamos em todos os aspectos: visual, textual, quem é o autor, quais painéis se envolvem, quem reage. É muito importante lembrar que as pessoas em uma imagem costumam ver coisas diferentes: alguém tem um sotaque azul no design, alguém tem uma lareira e alguém tem uma cozinha.
- Juntando tudo - um procedimento de três etapas: geramos candidatos (recomendações + assinaturas), personalizamos (usando o modelo de classificação) e combinamos de acordo com políticas e regras de negócios.
Para recomendações, eles usam um passeio aleatório sob o gráfico de pinos do quadro de usuários, eles apresentam o PinSage, sobre o qual falaram
ontem . A personalização evoluiu da triagem de tempo, passando por um modelo linear e GBDT para uma rede neural (desde 2017). Ao coletar a lista final, é importante não esquecer as regras de negócios: frescura, variedade, filtros adicionais. Começamos com heurísticas, agora estamos caminhando para o modelo de otimização de contexto como um todo com relação às metas.
Numa situação de busca (quando existe uma intenção), eles se movem um pouco diferente: tentam entender melhor a intenção. Para fazer isso, use as técnicas de entendimento e expansão de consultas, e a extensão é feita não apenas pelo preenchimento automático, mas por uma bela navegação visual. Eles usam técnicas diferentes para trabalhar com figuras e textos. Começamos em 2014 sem aprendizado profundo, lançamos a Pesquisa Visual com aprendizado profundo em 2015. Em 2016, adicionamos a detecção de objetos com análise e pesquisa semântica, lançamos recentemente o serviço Lens - você aponta a câmera do smartphone para o assunto e obtém pinos. No aprendizado profundo, eles usam ativamente várias tarefas: existe um bloco comum que cria a incorporação da imagem. e outras redes no topo para resolver problemas diferentes.
Além dessas tarefas, o ML é usado muito mais onde: notificações / publicidade / spam / previsão, etc.
Um pouco sobre as lições aprendidas:
- Devemos lembrar dos preconceitos, um dos mais ricos “ricos fica mais rico” (a tendência do aprendizado de máquina de transferir tráfego para objetos já populares).
- É obrigatório testar e monitorar: a implementação da grade reduziu muito todos os indicadores e, em seguida, ocorreu que, devido à distribuição de bugs dos recursos, flutuava por um longo tempo e os vazios apareciam online.
- A infraestrutura e a plataforma são muito importantes, com ênfase especial na conveniência e paralelização de experimentos, mas você deve poder interromper os experimentos offline.
- Métricas e entendimento: offline não garante online, mas para a interpretação de modelos, fabricamos ferramentas.
- Construindo um ecossistema sustentável: sobre o filtro de lixo e a isca de cliques, adicione feedback negativo à interface do usuário e ao modelo.
- Lembre-se de ter uma camada para incorporar regras de negócios.
Gráfico amplo de conhecimento da Amazon
Agora uma
garota da Amazon está brincando.
Existem gráficos de conhecimento - nós de entidade, arestas de atributos etc. - que são criados automaticamente, por exemplo, na Wikipedia. Eles ajudam a resolver muitos problemas. Gostaríamos de obter algo parecido com os produtos, mas há muitos problemas com isso: não há dados de entrada estruturados, produtos são dinâmicos, há todos os tipos de aspectos que não se encaixam no modelo de gráfico de conhecimento (é discutível, na minha opinião, provavelmente “não fique sem uma complicação séria da estrutura "), Muitas verticais e" entidades sem nome ". Quando o conceito foi "vendido" para a gerência e recebeu o aval, os desenvolvedores disseram que era um "projeto por cem anos" e, como resultado, conseguiram em 15 meses-homem.
Começamos extraindo entidades do diretório Amazon: existe algum tipo de estrutura aqui, apesar de estar com crowdsourcing e sujo. Em seguida, eles conectaram o OpenTag (descrito em mais detalhes ontem) para processamento de texto. E o terceiro componente foi o Ceres - uma ferramenta para analisar a partir da web, levando em consideração a árvore DOM. A ideia é que, ao anotar uma das páginas do site, você possa analisar facilmente o restante - afinal, todas são geradas por um modelo (mas há muitas nuances). Para fazer isso, usamos o sistema de marcação Vertex (comprado pela Amazon em 2011) - eles fazem a marcação, com base nele, um conjunto de xpath é criado para isolar os atributos e a regressão logística determina quais são aplicáveis em uma página específica. Para mesclar informações de sites diferentes, use floresta aleatória. Eles também usam treinamento ativo, páginas complexas são enviadas para marcação manual. No final, eles supervisionam a limpeza do conhecimento - um classificador simples, por exemplo, uma marca / não uma marca.
Em seguida, um pouco de vida. Eles distinguem dois tipos de objetivos. Tiros de telhado são os objetivos de curto prazo que alcançamos ao mover o produto, e Moonshots são os objetivos que aumentamos os limites e a liderança global.
Casamentos e representantes
Após o almoço, fui para a seção sobre como criar incorporações, principalmente para gráficos.
Encontrando exercícios semelhantes com uma representação semântica unificada
Os caras
resolvem o problema de encontrar tarefas semelhantes em algum sistema de aprendizado online chinês. As atribuições são descritas por texto, imagens e um conjunto de kontsetov relacionados. A contribuição dos desenvolvedores é reunir informações dessas fontes. Convoluções são feitas para figuras, incorporações são treinadas para conceitos e também para palavras. Incorporações de palavras são passadas para o LSTM baseado em atenção, juntamente com informações sobre conceitos e imagens. Obtenha alguma representação do trabalho.

O bloco descrito acima é transformado em uma rede siamesa, na qual também é adicionada atenção e, na saída, uma pontuação de similaridade.
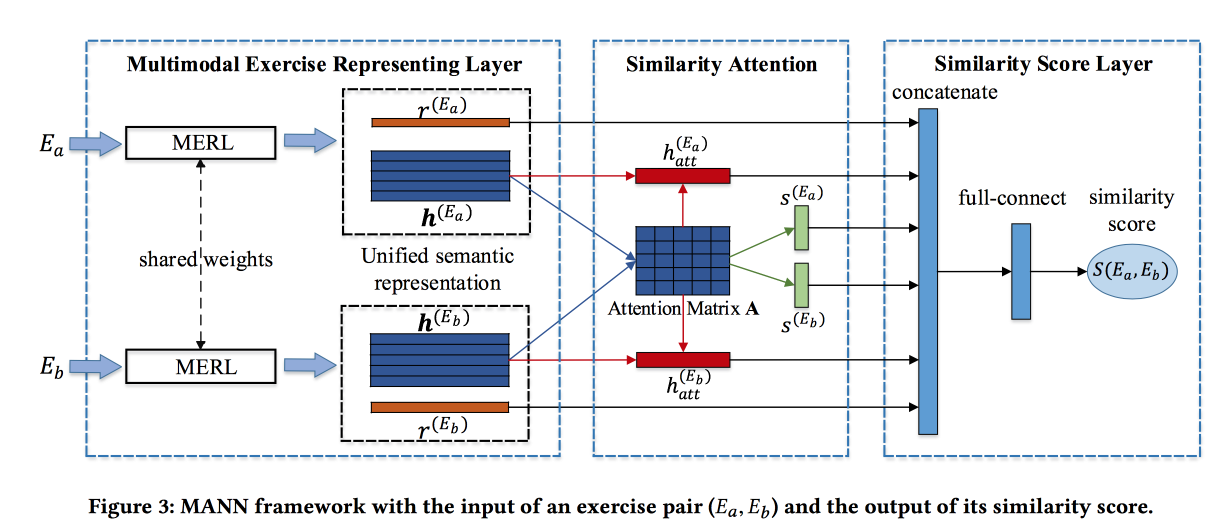
Eles ensinam em um conjunto de dados marcado de 100 mil exercícios e 400 mil pares (um total de 1,5 milhão de exercícios). Acrescente negativo negativo amostrando exercícios com os mesmos conceitos. Matrizes de atenção podem então ser usadas para interpretar similaridade.
Incorporação de rede preservada por proximidade de ordem arbitrária
Os caras
estão construindo uma variante muito interessante de incorporar gráficos. Primeiro, os métodos baseados em caminhadas e com base nos vizinhos são criticados por focarem na “proximidade” de um determinado nível (correspondente ao comprimento da caminhada). Eles oferecem um método que leva em consideração a proximidade da ordem desejada e com pesos controlados.
A ideia é muito simples. Vamos pegar uma função polinomial e aplicá-la à matriz de adjacência do gráfico, e fatoramos o resultado por SVD. Nesse caso, o grau de um membro específico do polinômio é o nível de proximidade e o peso desse membro é a influência desse nível no resultado. Naturalmente, essa ideia selvagem não é viável: depois de elevar a matriz de adjacência a uma potência, ela se torna mais densa, não se encaixa na memória e você fatora essa figura.
Sem matemática, é besteira, porque se você aplicar a função polinomial ao resultado APÓS a expansão, obteremos exatamente o mesmo que se a expansão fosse aplicada a uma matriz grande. Na verdade não. Consideramos o SVD aproximadamente e deixamos apenas os autovalores mais altos, mas após a aplicação do polinômio a ordem dos autovalores pode mudar, portanto, é necessário anotar números com uma margem.

O algoritmo cativa com sua simplicidade e mostra resultados impressionantes na tarefa de previsão de links.

NetWalk: uma abordagem flexível de incorporação profunda para detecção de anomalias em redes dinâmicas
Como o nome indica,
construiremos as incorporações de gráfico com base em caminhadas. Mas não apenas, mas no modo de streaming, já que resolvemos o problema de procurar anomalias em redes dinâmicas (houve trabalho sobre esse tópico ontem). Para ler e atualizar rapidamente as incorporações, elas usam o conceito de "
reservatório ", no qual se encontra uma amostra do gráfico e é atualizado estocamente quando as alterações são recebidas.
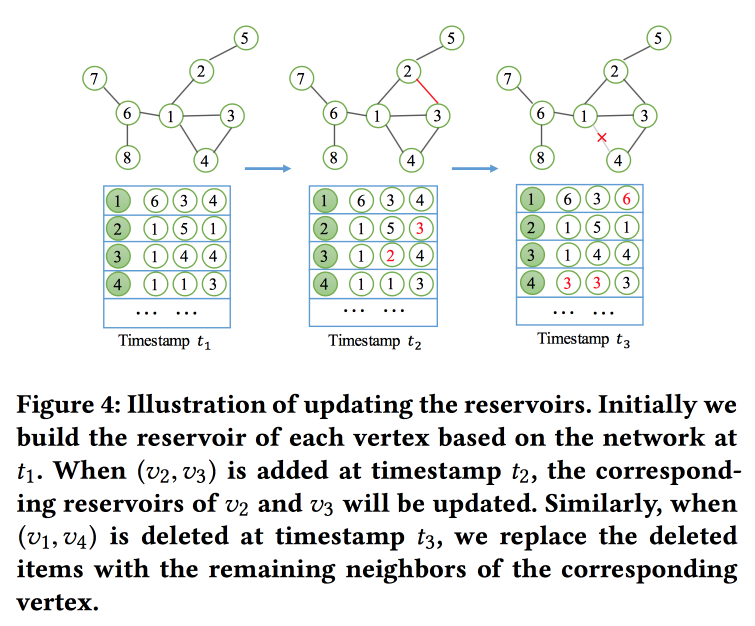
Para o treinamento, eles formulam uma tarefa bastante complicada com vários objetivos, os principais são a proximidade das incorporações de nós em um caminho e os erros mínimos ao restaurar a rede com um codificador automático.
Incorporação de rede consciente de taxonomia hierárquica
Outra
opção para a construção de incorporações para um gráfico, desta vez com base em um modelo de geração probabilístico. A qualidade dos embeddings é aprimorada usando informações de uma taxonomia hierárquica (por exemplo, um domínio de conhecimento para redes de citações ou uma categoria de produto para produtos em cauda eletrônica). O processo de geração é construído em alguns "tópicos", alguns dos quais estão vinculados a nós em uma taxonomia e outros a um nó específico.
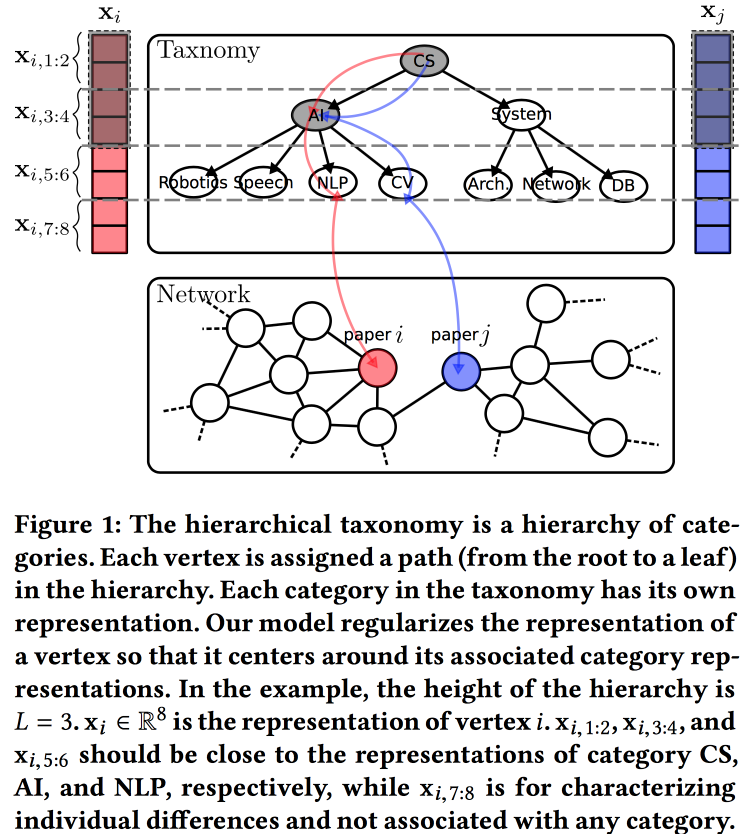
Associamos a distribuição normal a priori a uma média zero aos parâmetros da taxonomia, os parâmetros de um vértice em particular na taxonomia - a distribuição normal com a média igual ao parâmetro da taxonomia e a distribuição livre dos vértices com a distribuição média com média zero e dispersão infinita. Geramos o ambiente do vértice usando a distribuição de Bernoulli, onde a probabilidade de sucesso é proporcional à proximidade dos parâmetros dos nós. Otimizamos todo esse colosso com o
algoritmo EM .
Incorporação profunda em rede recursiva com equivalência regular
Técnicas de incorporação comuns não funcionam para todas as tarefas. Por exemplo, considere a função de uma tarefa do nó. Para determinar o papel, vizinhos não específicos (que geralmente são vistos) são importantes, mas a estrutura do gráfico na vizinhança do vértice e alguns padrões nele. Ao mesmo tempo, é muito difícil procurar por algoritmos esses padrões (equivalência regular) diretamente, mas para gráficos grandes isso não é realista.
Portanto, iremos para o
outro lado . Para cada nó, calculamos os parâmetros associados ao seu gráfico: grau, densidade, diferentes centralidades, etc. Incorporações não podem ser construídas somente com elas, mas a recursão pode ser usada, porque a presença do mesmo padrão implica que os atributos dos vizinhos de dois nós com a mesma função sejam semelhantes. O que significa que você pode empilhar mais camadas.
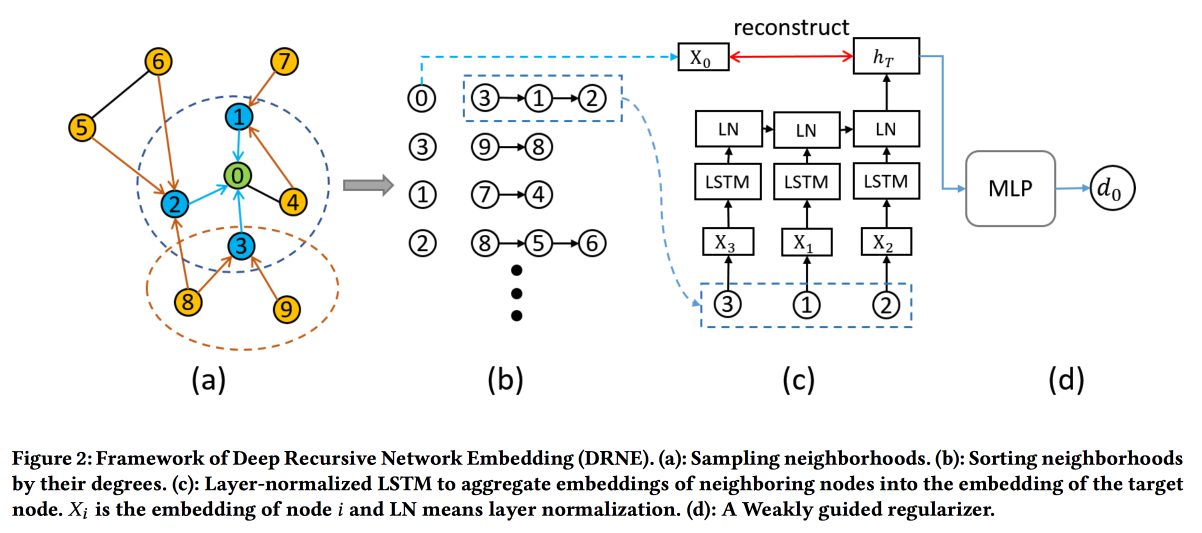
As validações mostram que eles ignoram as linhas de base padrão do DeepWalk e do node2wek em muitas tarefas.
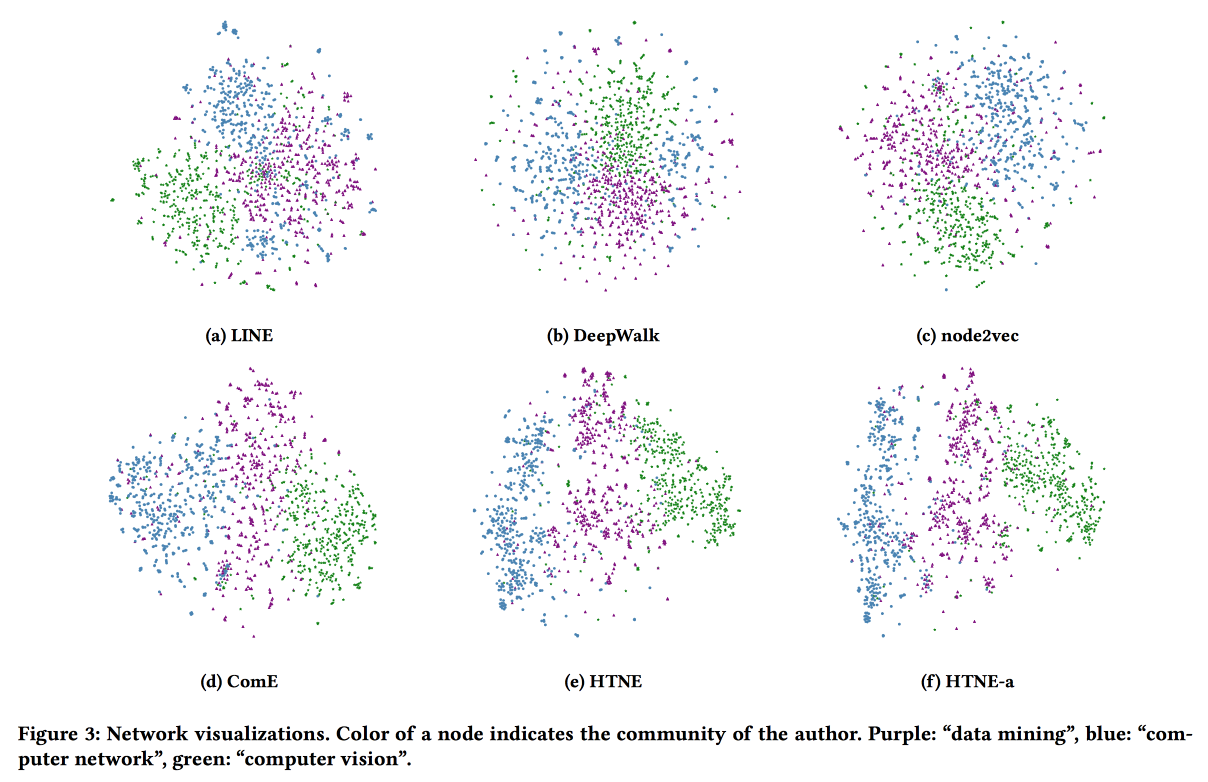
Incorporando Rede Temporal via Formação de Bairro
O último trabalho de incorporação de gráficos para hoje. Desta vez, examinaremos a dinâmica: avaliaremos o momento da conexão e todos os fatos da interação no tempo. Tome a rede de citações como exemplo, onde a interação é uma publicação conjunta.
Usamos o Processo Hawkes para modelar como as interações passadas dos vértices afetam suas interações futuras. HP . attention . log likelihood . .
Safety
. , . , ML , , .
Using Machine Learning to Assess the Risk of and Prevent Water Main Breaks
: , , — . , . , ( - , ), 1-2 % . ,
.
data miner-
Data Science for Social Good . , , :

, . : , GBDT. -1 % .
base line-: « » , , « , » . ML, , .
27 32- , , , ( , — ). , $1,2 .
, , , 1940-, , ( ) .
Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding
NASA
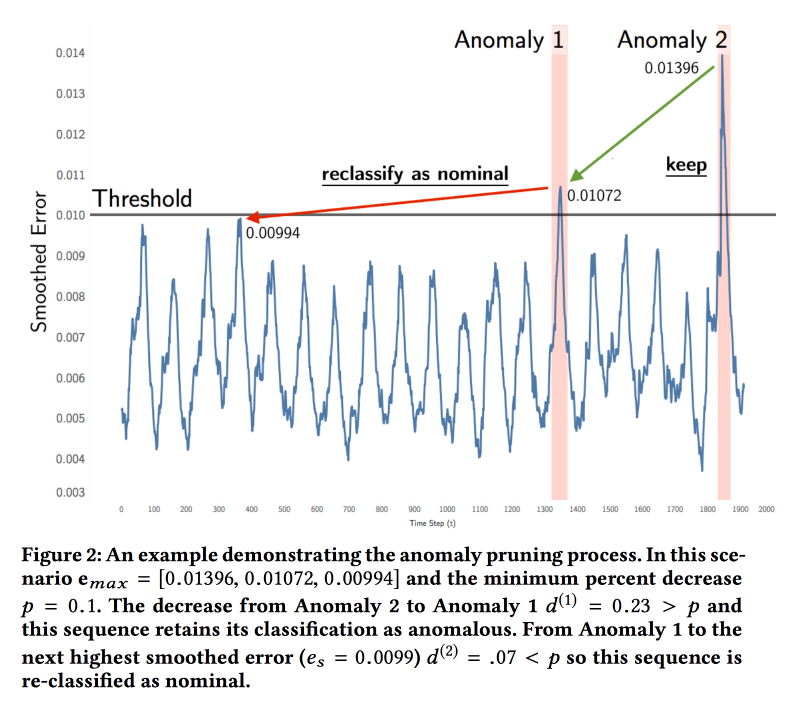
( ). — . , . , .
ML . LSTM , . ( , ). , , . , . , .
:
soil moisture active passive Curiosity c Mars Science Laboratory. 122 , 80 %. , , . , , .
Explaining Aviation Safety Incidents Using Deep Temporal Multiple Instance Learning
, , . Safety Incidents, , . , . .
, - , . «», .. , . , , . , , .
GRU ,
Multiple Instances Learning . , «» — , . « , , — » ( = ). max pooling .

cross entropy loss . base line
MI-SVM ADOPT.
ActiveRemediation: The Search for Lead Pipes in Flint, Michigan
, ,
.
. 120 . , 2013 , : . , 2014-. 2015- — . , . , …
— , . , . .
. «», . : , , , . , , — , …
6 . , 20 %. data scientist-.
, 19 , , , . , « ». , , XGBoost - . ( 7 % , ).
, -, , , — . « » .

, , 16 % 3 %. , , — Excel .
A Dynamic Pipeline for Spatio-Temporal Fire Risk Prediction
Em conclusão, outro ponto sensível são as inspeções de incêndio. Sobre o que acontece se não forem realizadas, aprendemos em março de 2018. Nos EUA, esses casos também não são raros. Ao mesmo tempo, os recursos para a inspeção de bombeiros são limitados, devendo ser direcionados aos locais de maior risco.
Existem modelos abertos para avaliar o risco de incêndios, mas eles são projetados para incêndios florestais e não são adequados para a cidade. Existe algum tipo de sistema em Nova York, mas está fechado. Então, você precisa tentar
fazer o seu próprio .
Em colaboração com os bombeiros de Pittsburgh, os meninos coletaram dados sobre incêndios ao longo de vários anos, acrescentaram informações sobre dados demográficos, renda, formas de negócios etc., bem como outras chamadas para o corpo de bombeiros que não estão relacionadas a incêndios. E eles tentaram avaliar o risco de incêndio com base nesses dados.
São ensinados dois modelos XGBoost diferentes: para residências e imóveis comerciais. A qualidade do trabalho foi avaliada, em primeiro lugar, segundo
Kappa , tendo em vista o forte desequilíbrio de classes.
A adição de fatores dinâmicos (chamadas ao corpo de bombeiros, acionamento de detectores / alarmes) ao modelo melhorou significativamente a qualidade, mas, para usá-los, o modelo precisava ser recontado toda semana. Com base na previsão, os modelos criaram um agradável focinho da tela para os inspetores de incêndio, mostrando onde estão localizados os objetos com maior risco.
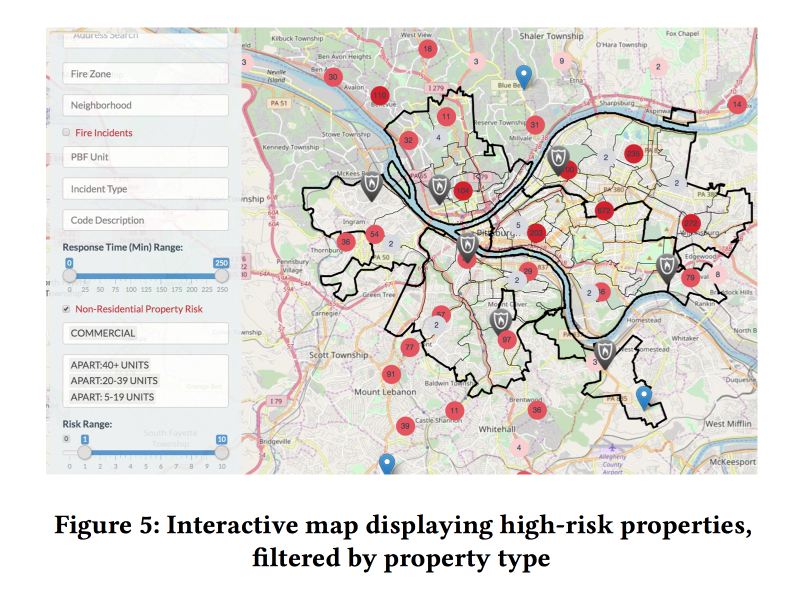
A importância dos sintomas foi analisada. Entre os recursos importantes para o comércio, estavam relacionados a alarmes falsos (aparentemente, o desligamento vai além). Mas para as famílias - o valor dos impostos pagos (Hi Fairness, as inspeções contra incêndios em áreas pobres serão mais frequentes).