Há algum tempo, ativei uma avaliação gratuita no Google para a nuvem deles, não resolvi meu problema, o Google concedeu US $ 300 por 12 meses para uma avaliação, mas, contrariamente às minhas expectativas, outros limites são impostos além do limite de orçamento. Por exemplo, não permiti o uso de máquinas virtuais com mais de 8 vcpu em uma região. Depois de meio ano, decidi usar o orçamento de avaliação para me familiarizar com o dataproc, um cluster de hadup pré-instalado do Google. A tarefa é tentar avaliar como seria fácil lançar um projeto no acesso do Google, se faz sentido ou é melhor me concentrar imediatamente no meu hardware e pensar na administração. Tenho a vaga sensação de que o hardware e as grandes datas modernos devem se adaptar facilmente a pequenos bancos de dados de dezenas ou centenas de GB, carregando brutalmente, se não todo o conjunto de dados, e a grande maioria na memória do cluster. Alguns subdados separados para data marts podem não ser mais necessários.
Em resumo, o dataproc ficou impressionado com a facilidade de inicialização e configurações, comparado ao Oracle e Cloudera. No primeiro estágio, joguei com um cluster de nós em 8 vCpu, o máximo dos quais permite uma avaliação totalmente gratuita. Se você observar a simplicidade, a tecnologia deles já permite que um hindu inicie um cluster em 15 minutos, carregue dados de amostra e prepare relatórios usando uma ferramenta de BI comum, sem sub-janelas intermediárias. Algum conhecimento profundo de Hadoup não é mais necessário.
Em princípio, vi que a coisa é maravilhosa para um início rápido e, com um bom dinheiro, você pode executar um protótipo, avaliar o tipo de hardware necessário para uma tarefa. No entanto, um cluster maior, em dezenas de nós, obviamente consumirá muito mais do que um aluguel + alguns administradores que estão olhando para o cluster. Longe do fato de que a nuvem parecerá economicamente viável. A primeira etapa, tentei avaliar uma opção completamente micro com um cluster de nó 8 vCpu e 0,5 TB de dados brutos. Em princípio, os testes spark + hadoop em clusters maiores já estão completos na Internet, mas pretendo testar a opção um pouco maior posteriormente.
Em apenas uma hora, pesquisei os scripts para criar um backup de cluster, configurar seu firewall e configurar um servidor de poupança, que permitia ao jdbc se conectar ao spark sql no Windows doméstico. Passei mais duas ou três horas otimizando as configurações padrão do spark e carregando algumas pequenas tabelas com cerca de 10 GB de tamanho (o tamanho dos arquivos de dados no Oracle). Coloquei as tabelas inteiras na memória (altere o cache da tabela;) e foi possível trabalhar com elas na máquina Windows do Dbeaver e Tableau (por meio do conector spark sql).
Por padrão, o spark usou apenas 1 executor em 4 vCpu, editei o spark-defaults.conf, instalei 3 executores, 2 vCpu cada e por um longo tempo não entendi por que realmente só tenho 1 executor no meu trabalho. Aconteceu que eu não editei a memória, os outros dois fios simplesmente não conseguiram alocar memória. Defina 6,5 GB no executor, após o qual todos os três começaram a aumentar conforme o esperado.
Em seguida, decidi jogar com um volume um pouco mais sério e uma tarefa mais próxima do DWH dos testes TPC-DS. Para iniciantes, eu gerava oficialmente tabelas com um fator de escala 500 da ferramenta oficial.Eu obtive algo como 480 GB de dados brutos (texto delimitado). O teste TPC-DS é um DWH típico, com fatos e dimensões. Não entendi como gerar dados diretamente no armazenamento do google, tive que gerar máquinas virtuais no disco e copiá-las para o armazenamento do google. O Google, pelo que entendi, acredita que o exaustor funciona perfeitamente com o armazenamento do Google e a velocidade promete um pouco melhor do que se os dados estivessem dentro do cluster no HDFS. Nesse caso, parte da carga vai do HDFS para o armazenamento do Google.
Após conectar-me através do Dbeaver, converti os arquivos de texto em tablets baseados em parquet com empacotamento rápido usando comandos SQL. 480 GB de dados de texto compactados em arquivos parquet de 187 GB. O processo levou cerca de duas horas, a maior tabela do texto ocupava 188 GB, três executores de faísca os transformaram em parquet em 74 minutos, o tamanho do SUV era de 66,8 GB. Na minha área de trabalho, com aproximadamente os mesmos 8 vCpu (i7-3770k), acho que “inserir na tabela selecione * ...” em uma tabela Oracle com um bloco de 8k levaria um dia, e quanto o arquivo de dados levaria é assustador de se imaginar.
Em seguida, verifiquei o desempenho das ferramentas de BI nessa configuração e criei um relatório simples no Tableua
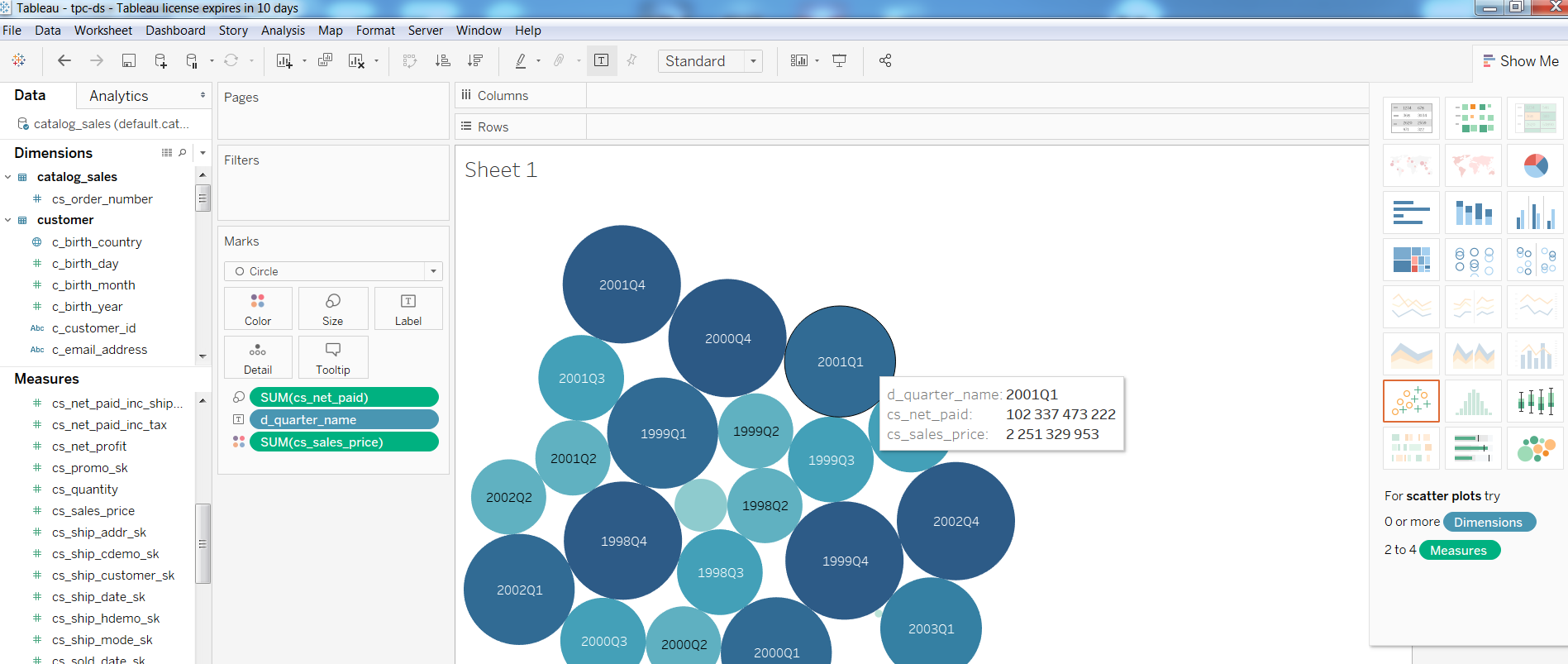
Quanto às consultas, Query1 do teste TPC-DS
Consulta1WITH customer_total_return AS (SELECT sr_customer_sk AS ctr_customer_sk, sr_store_sk AS ctr_store_sk, Sum(sr_return_amt) AS ctr_total_return FROM store_returns, date_dim WHERE sr_returned_date_sk = d_date_sk AND d_year = 2001 GROUP BY sr_customer_sk, sr_store_sk) SELECT c_customer_id FROM customer_total_return ctr1, store, customer WHERE ctr1.ctr_total_return > (SELECT Avg(ctr_total_return) * 1.2 FROM customer_total_return ctr2 WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk) AND s_store_sk = ctr1.ctr_store_sk AND s_state = 'TN' AND ctr1.ctr_customer_sk = c_customer_sk ORDER BY c_customer_id LIMIT 100;
concluída em 1:08, Query2 com a participação das maiores tabelas (catalog_sales, web_sales)
Consulta2 WITH wscs AS (SELECT sold_date_sk, sales_price FROM (SELECT ws_sold_date_sk sold_date_sk, ws_ext_sales_price sales_price FROM web_sales) UNION ALL (SELECT cs_sold_date_sk sold_date_sk, cs_ext_sales_price sales_price FROM catalog_sales)), wswscs AS (SELECT d_week_seq, Sum(CASE WHEN ( d_day_name = 'Sunday' ) THEN sales_price ELSE NULL END) sun_sales, Sum(CASE WHEN ( d_day_name = 'Monday' ) THEN sales_price ELSE NULL END) mon_sales, Sum(CASE WHEN ( d_day_name = 'Tuesday' ) THEN sales_price ELSE NULL END) tue_sales, Sum(CASE WHEN ( d_day_name = 'Wednesday' ) THEN sales_price ELSE NULL END) wed_sales, Sum(CASE WHEN ( d_day_name = 'Thursday' ) THEN sales_price ELSE NULL END) thu_sales, Sum(CASE WHEN ( d_day_name = 'Friday' ) THEN sales_price ELSE NULL END) fri_sales, Sum(CASE WHEN ( d_day_name = 'Saturday' ) THEN sales_price ELSE NULL END) sat_sales FROM wscs, date_dim WHERE d_date_sk = sold_date_sk GROUP BY d_week_seq) SELECT d_week_seq1, Round(sun_sales1 / sun_sales2, 2), Round(mon_sales1 / mon_sales2, 2), Round(tue_sales1 / tue_sales2, 2), Round(wed_sales1 / wed_sales2, 2), Round(thu_sales1 / thu_sales2, 2), Round(fri_sales1 / fri_sales2, 2), Round(sat_sales1 / sat_sales2, 2) FROM (SELECT wswscs.d_week_seq d_week_seq1, sun_sales sun_sales1, mon_sales mon_sales1, tue_sales tue_sales1, wed_sales wed_sales1, thu_sales thu_sales1, fri_sales fri_sales1, sat_sales sat_sales1 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998) y, (SELECT wswscs.d_week_seq d_week_seq2, sun_sales sun_sales2, mon_sales mon_sales2, tue_sales tue_sales2, wed_sales wed_sales2, thu_sales thu_sales2, fri_sales fri_sales2, sat_sales sat_sales2 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998 + 1) z WHERE d_week_seq1 = d_week_seq2 - 53 ORDER BY d_week_seq1;
concluída em 4:33 minutos, Query3 em 3,6, Query4 em 32 minutos.
Se alguém estiver interessado nas configurações, abaixo do recorte minhas anotações sobre a criação de um cluster. Em princípio, existem apenas alguns comandos do gcloud e a configuração HIVE_SERVER2_THRIFT_PORT.
Anotaçõesopção de cluster de um nó:
clusters gcloud dataproc --region europe-north1 criam test1 \
--subnet padrão \
--backet tape1 \
--zona europa-norte1-a \
- nó único \
--master-machine-type n1-highmem-8 \
--master-boot-disk-size 500 \
--image-version 1.3 \
--initialization-actions gs: //dataproc-initialization-actions/hue/hue.sh \
--initialization-actions gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--initialization-actions gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--projeto 123
opção para 3 nós:
gcloud dataproc - clusters de região europa-norte1 \
criar cluster-teste1 - fita adesiva1 \
--subnet default --zone europe-north1-a \
--master-machine-type n1-standard-1 \
--master-boot-disk-size 10 --num-workers 2 \
--worker-machine-type n1-standard-1 --worker-boot-disk-size 10 \
--initialization-actions gs: //dataproc-initialization-actions/hue/hue.sh \
--initialization-actions gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--initialization-actions gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--projeto 123
computação gcloud --project = 123 \
regras de firewall criam allow-dataproc \
--direction = INGRESS --priority = 1000 --network = default \
--action = ALLOW --rules = tcp: 8088, tcp: 50070, tcp: 8080, tcp: 10010, tcp: 10000 \
--sources-range = xxx.xxx.xxx.xxx / 32 --target-tags = dataproc
no nó principal:
sudo su - vi /usr/lib/spark/conf/spark-env.sh
mudança: exportar HIVE_SERVER2_THRIFT_PORT = 10010
sudo -u spark /usr/lib/spark/sbin/start-thriftserver.sh
Para continuar ...