
Então, o quinto, último dia do KDD terminou. Consegui ouvir alguns relatórios interessantes do Facebook e do Google AI, lembrar das táticas de futebol e gerar alguns produtos químicos. Sobre isso e não apenas - sob o corte. Vejo você em um ano em Anchorage, capital do Alasca!
Sobre o Big Data Learning para problemas de dados pequenos
O relatório da manhã do
professor chinês foi difícil. O palestrante claramente se libertou durante a preparação, muitas vezes se desviou, começou a pular slides e, em vez de falar pela vida, tentou carregar o cérebro sonolento com matemática.
O esboço geral da história girava em torno da ideia de que há longe de sempre muitos dados. Há, por exemplo, uma cauda longa na qual existem muitos exemplos diversos. Existem conjuntos de dados com um grande número de classes que, embora grandes por si só, possuem apenas alguns registros para cada classe. Como exemplo desse conjunto de dados, ele citou caracteres manuscritos
Omniglot de 50 alfabetos, 1623 classes e 20 imagens por classe, em média. Mas, de fato, nessa perspectiva, você também pode considerar conjuntos de dados de tarefas de recomendação, quando temos muitos usuários e não tantas classificações para cada um deles individualmente.
O que pode ser feito para facilitar a vida de ML em tal situação? Primeiro de tudo. tente trazer conhecimento da área de assunto para ela. Isso pode ser feito de várias formas: engenharia de recursos, regularização específica e refinamento da arquitetura de rede. Outra solução comum é a transferência de aprendizado, acho que quase todo mundo que trabalhou com imagens começou atualizando algumas ImageNet a partir de seus dados. No caso de Omniglot, o doador natural para a transferência será o
MNIST .
Uma forma de transferência pode ser o
aprendizado em várias tarefas , sobre o qual o KDD foi comentado várias vezes. O desenvolvimento do MTL pode ser considerado a abordagem de
meta-aprendizado - treinando o algoritmo em amostras de várias tarefas, podemos APRENDER não apenas parâmetros, mas também hiperparâmetros (é claro, apenas se nosso procedimento for diferenciável).
Continuando o tópico da multitarefa, podemos chegar ao conceito de aprendizado contínuo ao longo da vida, que pode ser mais claramente demonstrado pelo exemplo da robótica. O robô deve ser capaz de resolver problemas diferentes e ao aprender uma nova tarefa para usar a experiência anterior. Mas você pode considerar essa abordagem com o exemplo de Omniglot: depois de aprender um dos personagens, você pode continuar aprendendo o próximo, usando a experiência acumulada. É verdade que um perigoso problema de
esquecimento catastrófico nos espera nesse caminho, quando o algoritmo começa a esquecer o que aprendeu antes (para combater isso, aconselha a regularização do
EWC ).
Além disso, o orador falou sobre vários de seus trabalhos nessa direção.
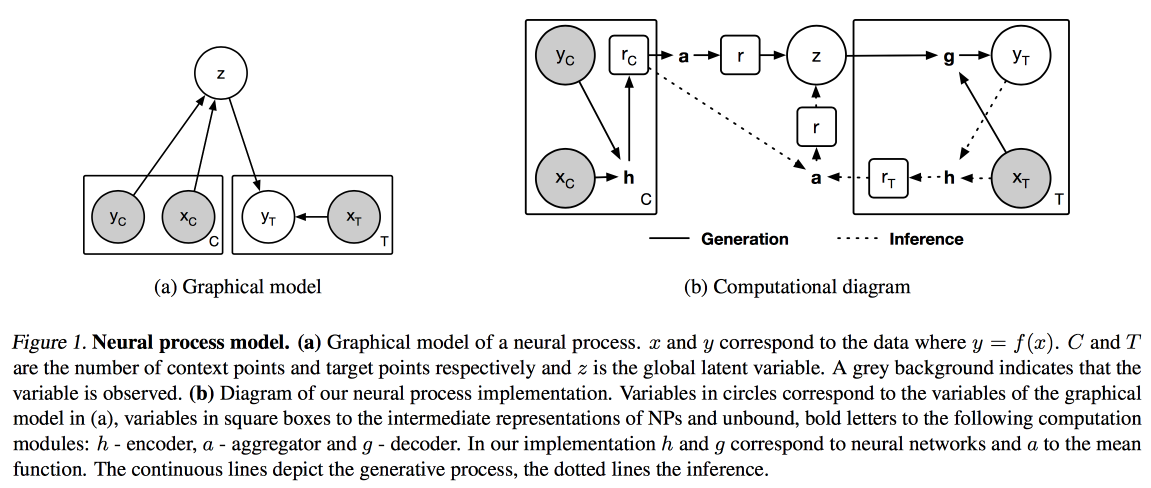
Processos Neurais (uma analogia do processo Gaussiano para redes neurais) e
Aprendizagem por Distil e Transferência (otimização da aprendizagem por transferência para o caso em que não tomamos como base um modelo previamente treinado, mas treinamos o nosso no modo de múltiplas tarefas).
Imagens e textos
Hoje eu decidi andar de relatórios aplicados, pela manhã, sobre como trabalhar com textos, imagens e vídeos.
Serviço de conversão de corpus
A frequência das publicações está crescendo muito rapidamente, é difícil trabalhar com isso, principalmente considerando o fato de que quase toda a pesquisa é realizada no texto. A IBM
oferece seus serviços para marcar gabinetes de conhecimento científico 3.0. O fluxo de trabalho principal é assim:
- Parsim PDF, reconheça o texto nas imagens.
- Verificamos se existe um modelo para essa forma de texto; se houver, fazemos um extrato semântico com ela.
- Se não houver modelo, enviamos anotações e treinamos.
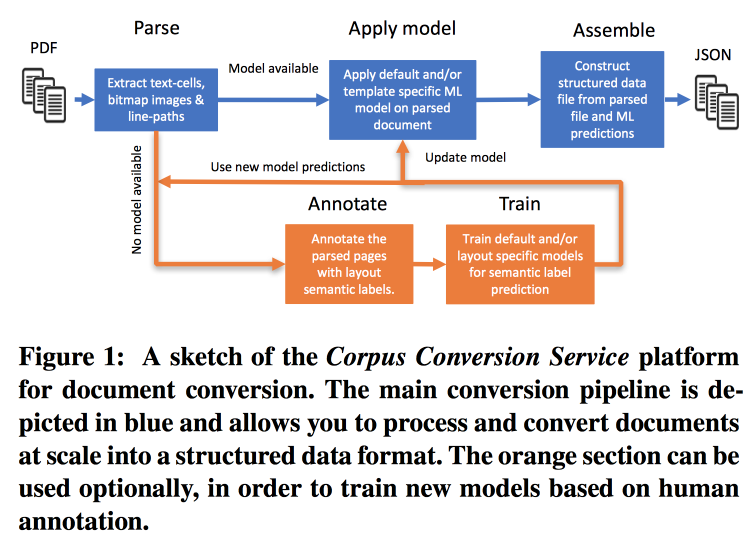
Para treinar modelos, começamos com o agrupamento por estrutura. Dentro de um cluster usando crowdsourcing, criamos várias páginas de layout. Ele atinge precisão> 98% ao treinar a marcação de 200 a 300 documentos. Há um forte desequilíbrio de classe na marcação (quase tudo é marcado como texto), portanto, é necessário examinar a precisão de todas as classes e a matriz de confusão.
Os modelos têm uma estrutura hierárquica. Por exemplo, um modelo reconhece uma tabela e o outro corta em linhas / colunas / cabeçalhos (e sim, uma tabela pode ser aninhada em uma tabela). Como modelo, uma rede convolucional é usada.
Por tudo isso, eles montaram um transportador no Docker com o Kubernetes e estão prontos para fazer o download do seu corpus de texto por uma taxa razoável. Eles podem trabalhar não apenas com PDF em texto, mas também com digitalizações; eles suportam idiomas orientais. Além de apenas extrair o texto, eles estão trabalhando para extrair o gráfico de conhecimento, eles prometem contar detalhes no próximo KDD.
Expansão de consultas raras por meio de redes adversas generativas em publicidade de pesquisa
Os mecanismos de pesquisa ganham mais dinheiro com publicidade, e a publicidade é exibida dependendo do que o usuário está procurando. Mas a comparação nem sempre é óbvia. Por exemplo, a pedido de passagens aéreas, a exibição de anúncios de passagens de ônibus baratas não é muito correta, mas a expedia fará bem, mas você não pode entender isso com palavras-chave. Modelos de aprendizado de máquina podem ajudar, mas eles não funcionam bem com consultas raras.
Para resolver esse problema, para expandir a consulta de pesquisa,
treinaremos o GAN Condicional de acordo com o modelo de sequência a sequência. Utilizamos redes recorrentes (GRU de 2 camadas) como arquitetura. Estamos modificando o min-max do GAN, tentando adicionar palavras-chave para as quais houve cliques nos anúncios.
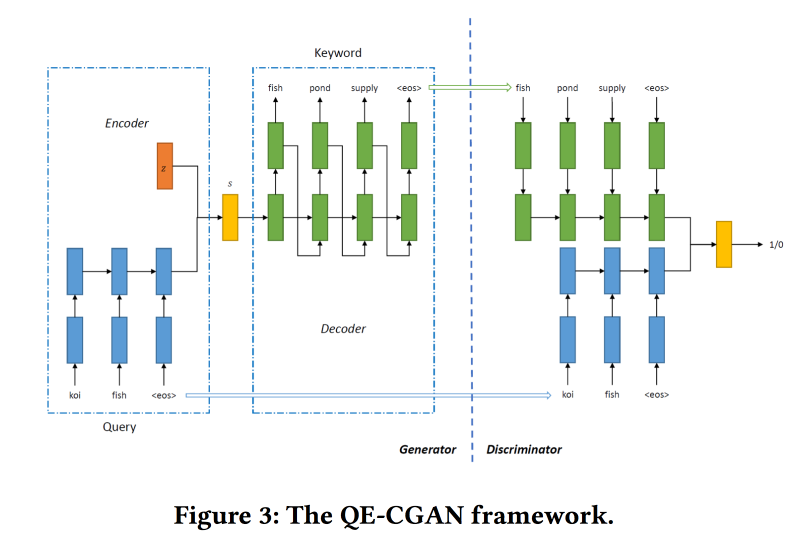
Conjunto de dados para treinamento em 14 milhões de consultas e 4 milhões de palavras-chave de publicidade. O modelo proposto funciona melhor na cauda longa da solicitação, para a qual foi feita. Mas na cabeça, o desempenho não é maior.
Aprendizado métrico profundo e colaborativo para compreensão de vídeo
O trabalho é apresentado pelos caras do Google AI. Eles querem criar boas incorporações de vídeo e usá-los em vídeos, recomendações, anotações automáticas semelhantes etc. Funciona da seguinte maneira:
- A partir do vídeo, mostramos quadros - uma imagem e um pedaço da faixa de áudio.
- Extraímos recursos das imagens que o Inception aprendeu anteriormente.
- Fazemos o mesmo com o fragmento de áudio (a arquitetura de rede específica não foi mostrada). Nos sinais obtidos, penduramos malhas totalmente conectadas com puxar pelos quadros. Nós normalizamos por L2.
- Em seguida, um ponto interessante - estamos tentando garantir que vídeos semelhantes sejam próximos em termos de similaridade colaborativa. Para fazer isso, usamos a perda de trigêmeos no treinamento (pegamos um objeto, o provamos de maneira semelhante e diferente, asseguramos que os encaixes dos diferentes sejam mais distantes do original do que o similar). Não esqueça que você precisa usar mineração negativa.

Eles são usados para começar a frio em vídeos semelhantes, mas existem alguns problemas: por semelhança visual, eles podem encontrar vídeos em outro idioma ou vídeos sobre um tópico diferente (especialmente relevante para o formato de vídeo “quadro e palestrante”). Aconselhe-o a usar meta-informações adicionais sobre o vídeo.
Há um problema com as recomendações: você precisa corresponder ao histórico de navegação e aos 5 bilhões de vídeos do Youtube. Para acelerar o trabalho, calculamos para o usuário o vetor da incorporação média dos vídeos assistidos. Verificado em
movielens , bombeado reboques do YouTube para análise. Eles mostraram que, para usuários com um pequeno número de classificações, funciona melhor.
No problema da anotação de vídeo, a abordagem da
mistura de especialistas é usada: eles treinam no logreg para incorporação para cada anotação possível. Verificado no
Youtube-8 e mostrou um resultado muito bom.
Desambiguação de nome no AMiner: cluster, manutenção e humanos no loop
AMiner - um gráfico para a academia, fornecendo vários serviços para trabalhar com literatura. Um dos problemas: colisões de nomes de autores e entidades. Um algoritmo automático com alguma forma de aprendizado ativo é
oferecido para solução.
O processo consiste em três etapas: usando uma pesquisa de texto, coletamos candidatos (documentos com nomes semelhantes de autores), agrupamentos (com determinação automática do número de agrupamentos) e criamos perfis.

Para considerar a semelhança no cluster, você precisa de algum tipo de apresentação (emissão). Pode ser obtido usando o modelo global (em todo o gráfico) ou local (para os candidatos que fizeram a amostra). Padrões globais de captura que podem ser transferidos para novos documentos e locais ajudam a levar em consideração características individuais - nós combinaremos. Para obter incorporações globais, elas também usam a rede siamesa treinada em perda de trigêmeos e para as locais - um codificador automático de gráficos (deixei as fotos no artigo para economizar espaço).
A pergunta mais dolorosa é quantos aglomerados eu tenho? A abordagem dos
meios X não é dimensionada para um grande número de clusters; a RNN é usada para prever seu número: os clusters K são amostrados de um conjunto marcado e, em seguida, N exemplos desses clusters. Eles treinam a rede para revelar o número inicial de clusters.

Os dados chegam com rapidez suficiente, 500 mil por mês, mas leva semanas para executar todo o modelo. Para uma inicialização rápida, eles usam a seleção de candidatos para pesquisa de texto e IPN para incorporação global. Um ponto importante: as pessoas que marcam o que deve ou não estar no cluster são incluídas no processo de aprendizado. Com esses dados, o modelo é treinado novamente.
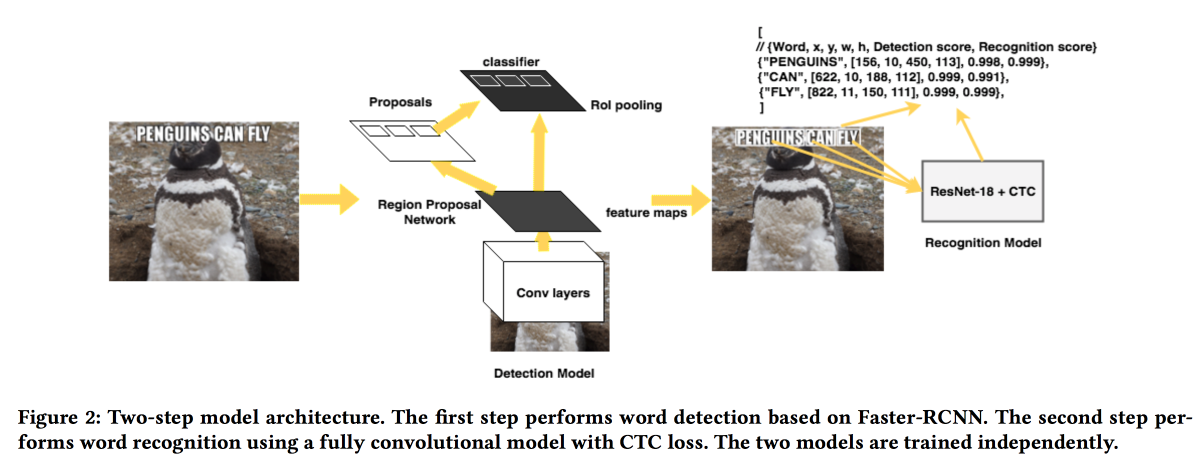
Rosetta: sistema de grande escala para detecção e reconhecimento de texto em imagens
Os caras do FB
apresentarão sua solução para extrair textos de fotos. O modelo funciona em duas etapas: a primeira rede determina o texto, a segunda o reconhece.
O RCNN mais rápido foi usado como um detector com a substituição do ResNet pelo
SuffleNet para acelerar o trabalho. Para reconhecimento, eles usaram o ResNet18 e treinaram com a
perda de CTC .
Para melhorar a convergência, usamos vários truques:
- Durante o treinamento, um pequeno ruído foi introduzido no resultado do detector.
- Os textos foram esticados horizontalmente em 20%.
- Aprendizado de currículo usado - exemplos gradualmente complicados (pelo número de caracteres).
Ciências naturais
A última seção de conteúdo da conferência foi dedicada às "ciências naturais". Um pouco de química, futebol e muito mais.
Detecção de efeito de tratamento heterogêneo controlado por taxa de descoberta falsa para experimento controlado on-line
Trabalho muito interessante na análise de testes A / B. O problema com a maioria dos sistemas de análise é que eles observam o efeito médio, enquanto na realidade, na maioria dos casos, alguns usuários reagem à mudança de maneira positiva e negativa, e mais pode ser alcançado se você entender para quem é o recurso e quem não

Você pode dividir os usuários em coortes antecipadamente e avaliar o efeito por eles, mas com um aumento no número de coortes, o número de falsos positivos aumenta (você pode tentar reduzi-los usando o método
Bonferoni , mas é muito conservador). Além disso, você precisa conhecer as coortes com antecedência. Os caras sugerem o uso de uma combinação de várias abordagens: combinar o mecanismo de detecção de efeito heterogêneo (HTE) com métodos de filtragem de falso positivo.
Para detectar um efeito heterogêneo, uma matriz com
x=0/1 0/1 (no grupo ou não) e o efeito é transformado em uma matriz na qual, em vez de
0/1 reside o número
(x — p)/p(1-p) , onde
p é a probabilidade de inclusão em o teste. A seguir, é ensinado um modelo para prever o efeito de
x (regressão linear ou laço). Os usuários para quem o resultado é significativamente diferente da previsão são candidatos à separação em um efeito "heterogêneo".
Em seguida, tentamos dois métodos para o filtro falso positivo:
Benjamini-Hochberg e
Knockoffs . O primeiro é muito mais fácil de implementar, mas o segundo é mais flexível e mostrou resultados mais interessantes.
Maldição do vencedor: estimativa de viés para efeitos totais de recursos em experimentos controlados online
Os caras do AirBnB conversaram um pouco sobre como eles melhoraram o sistema de análise experimental. O principal problema é que, ao experimentar muitos vieses, consideramos o viés de seleção neste trabalho - selecionamos experimentos com o melhor resultado
observado , mas isso significa que selecionaremos mais frequentemente experimentos nos quais o resultado observado é muito alto em relação ao real.
Como resultado, ao combinar experimentos, o efeito final é menor que a soma dos efeitos dos experimentos. Mas conhecendo esse viés, você pode tentar avaliá-lo e subtraí-lo usando o aparato estatístico (assumindo que a diferença entre os efeitos reais e os observados seja distribuída normalmente). Em suma, algo como isto:

E se você adicionar o
bootstrap , poderá criar intervalos de confiança para uma estimativa imparcial do efeito.
Descoberta automática de táticas em dados de partidas de futebol espaço-temporais
Trabalho interessante sobre a divulgação das táticas dos times de futebol. Os dados da partida estão disponíveis na forma de sequências de ações (aprovação / toque / ocorrência, etc.), cerca de 2000 ações por partida. Combine atributos contínuos (coordenadas / tempo) e discretos (jogador). É importante expandir os dados usando o conhecimento da área de assunto (adicione o papel do jogador e o tipo de passe, por exemplo), mas nem sempre funciona. Além disso, diferentes tipos de usuários estão interessados em diferentes tipos de padrões: treinadores - bem-sucedidos, atacante - defensivo, jornalista - único.
O método proposto é o seguinte:
- Divida o fluxo em fases para a transição da bola entre as equipes.
- Fases de cluster usando distorção dinâmica do tempo à distância. Como determinar o número de clusters, não informados.
- Classificamos os clusters por objetivo (para quem estamos procurando táticas).
- Minimizando os padrões dentro do cluster (mineração sequencial de padrões CM-SPADE ), abandonamos as coordenadas de acordo com os segmentos do campo (flanco esquerdo / direito, meio, penalidade).
- Classifique os padrões novamente.
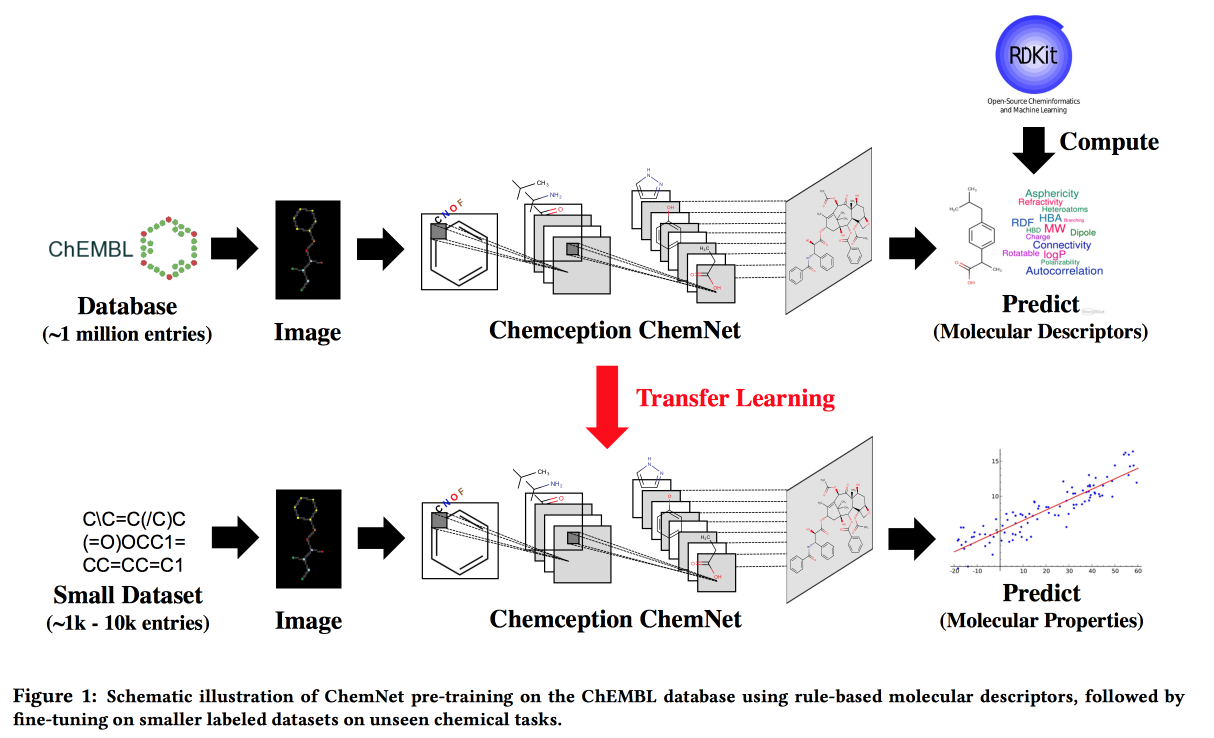
Uso de etiquetas baseadas em regras para um aprendizado supervisionado fraco: um ChemNet para propriedades químicas transferíveis P
Trabalhe para situações em que não há big data, mas existem modelos teóricos com regras hierárquicas. Usando a teoria, construímos uma rede neural "especializada". Aplicável à tarefa de desenvolver compostos químicos com propriedades desejadas.
Gostaria, por analogia com as imagens, de obter uma rede na qual as camadas correspondam a diferentes níveis de abstração: átomos / grupos funcionais / fragmentos / moléculas. No passado, havia abordagens para grandes conjuntos de dados rotulados, por exemplo, SMILE2Vect: use
SMILE para traduzir uma fórmula em texto e, em seguida, aplique técnicas para criar incorporações para textos.
Mas e se não houver um grande conjunto de dados marcado? Ensinamos a ChemNet usando
RDKit para os objetivos que ele pode prever e depois transferimos o aprendizado para resolver o problema. Mostramos que podemos competir com modelos treinados em dados rotulados. Você pode aprender em camadas, o que significa alcançar o objetivo - dividir as camadas por nível de abstração.
PrePeP - Uma Ferramenta para Identificação e Caracterização de Compostos de Interferência de Pan Assay
Desenvolvemos medicamentos , usamos ciência de dados para selecionar candidatos. Existem moléculas que reagem com muitas substâncias. Eles não podem ser usados como medicamentos, mas geralmente aparecem nos estágios iniciais do teste. Estas são as moléculas de
PAINS que iremos filtrar.
Existem dificuldades: os dados são descarregados e arrogantes (107 mil), as classes são desequilibradas (positivas 0,5%) e os químicos desejam obter um modelo interpretado. Combine os dados da estrutura gráfica (
gSpan ) da molécula e impressões digitais químicas. Eles lutaram com o equilíbrio, ensacando a subamostragem negativa, ensinando árvores, previsões agregadas pelo voto da maioria.