 Para tornar o monitoramento útil, precisamos elaborar diferentes cenários de problemas prováveis e projetar painéis e acionadores de forma que eles entendam imediatamente a causa do incidente.
Para tornar o monitoramento útil, precisamos elaborar diferentes cenários de problemas prováveis e projetar painéis e acionadores de forma que eles entendam imediatamente a causa do incidente.
Em alguns casos, entendemos bem como esse ou aquele componente da infraestrutura funciona e, então, é sabido antecipadamente quais métricas serão úteis. E, às vezes, removemos quase todas as métricas possíveis com o máximo de detalhes e, em seguida, analisamos como certos problemas são visíveis nelas.
Hoje, veremos como e por que o Write-Ahead Log (WAL) do postgres pode aumentar. Como sempre - exemplos da vida real em imagens.
Um pouco da teoria WAL no postgresql
Qualquer alteração no banco de dados é registrada primeiro no WAL e somente depois os dados na página no cache do buffer são alterados e marcados como sujos - o que precisa ser salvo no disco. Além disso, o processo CHECKPOINT é iniciado periodicamente, o que salva todas as páginas sujas no disco e o número do segmento WAL, até o qual todas as páginas alteradas já estão gravadas no disco.
Se de repente o postgresql, por algum motivo, travar e reiniciar, todos os segmentos WAL a partir do momento do último ponto de verificação serão reproduzidos durante o processo de recuperação.
Os segmentos WAL que precedem o ponto de verificação não nos serão mais úteis para recuperação de banco de dados pós-falha, mas no postgres o WAL também participa do processo de replicação, e o backup de todos os segmentos para Point In Time Recovery - PITR também pode ser configurado.
Um engenheiro experiente provavelmente já entendeu como se decompõe na vida real :)
Vamos assistir as paradas!
Inchaço WAL # 1
Nosso agente de monitoramento para cada instância encontrada do postgres calcula o caminho no disco para o diretório com wal e remove o tamanho total e o número de arquivos (segmentos):
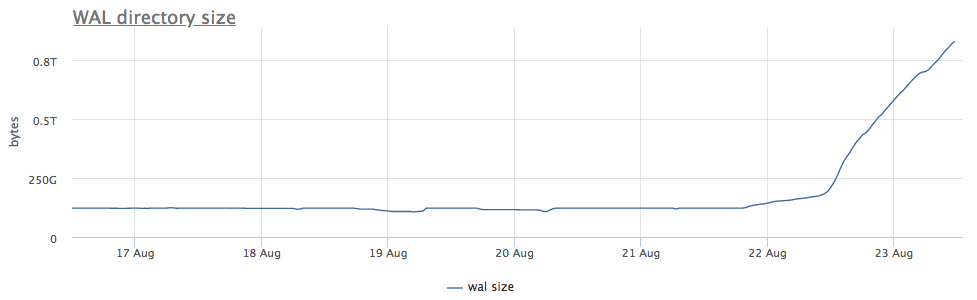
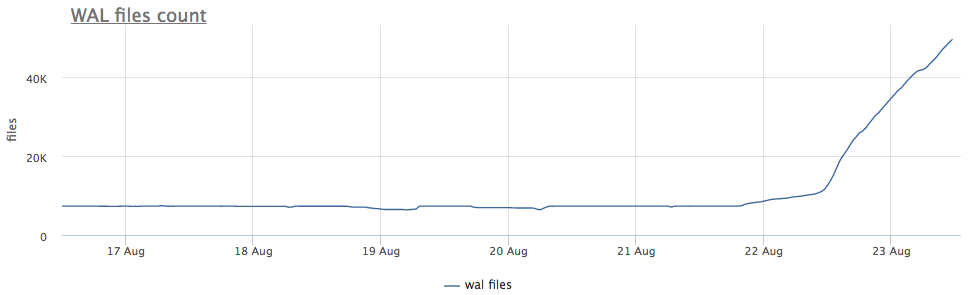
Antes de mais, analisamos há quanto tempo estamos executando o CHECKPOINT.
Tomamos métricas de pg_stat_bgwriter:
- checkpoints_timed - contador de ativações de ponto de verificação que ocorreram desde que o tempo do último ponto de verificação tenha sido excedido em mais de pg_settings.checkpoint_timeout
- checkpoints_req - contador de partidas do ponto de verificação, desde que o tamanho do wal seja excedido desde o último ponto de verificação
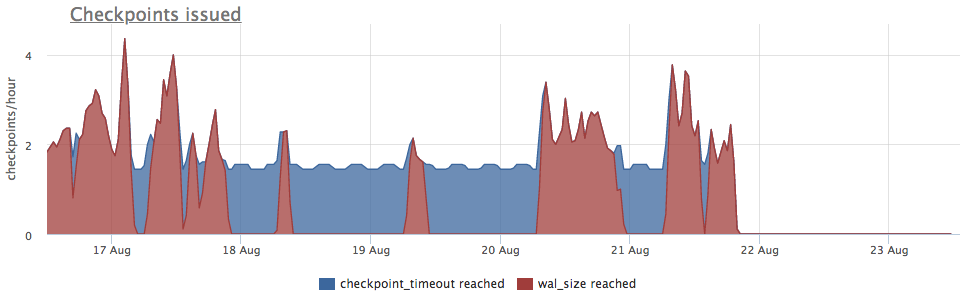
Vemos que o ponto de verificação não é lançado há muito tempo. Nesse caso, é impossível entender diretamente o motivo para NÃO iniciar esse processo (mas seria legal, é claro), mas sabemos que no postgres muitos problemas surgem devido a transações longas!
Verificamos:

Além disso, fica claro o que fazer:
- matar uma transação
- lidar com as razões pelas quais é longo
- espere, mas verifique se há espaço suficiente
Outro ponto importante: nas réplicas conectadas a esse servidor, o wal também está inchado !
Arquivador WAL
Lembro-lhe de vez em quando: a replicação não é um backup!
Um bom backup deve permitir a recuperação a qualquer momento. Por exemplo, se alguém "acidentalmente" executou
DELETE FROM very_important_tbl;
Em seguida, poderemos restaurar o banco de dados para o estado exatamente antes desta transação. Isso é chamado PITR (recuperação point-in-time) e é implementado no postgresql com backups completos periódicos do banco de dados + salvando todos os segmentos WAL após o despejo.
A configuração archive_command é responsável pelo backup do wal, o postgres apenas inicia o comando especificado e, se ele for concluído sem erros, o segmento será considerado copiado com êxito. Se ocorrer um erro, ele tentará até a vitória, o segmento ficará no disco.
Bem, e como ilustração - gráficos de arquivo quebrado wal:
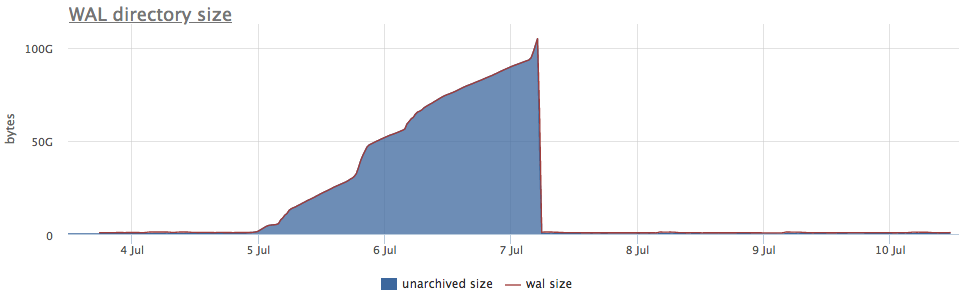
Aqui, além do tamanho de todos os segmentos wal, há um tamanho não- arquivado - este é o tamanho dos segmentos que ainda não foram considerados salvos com sucesso.
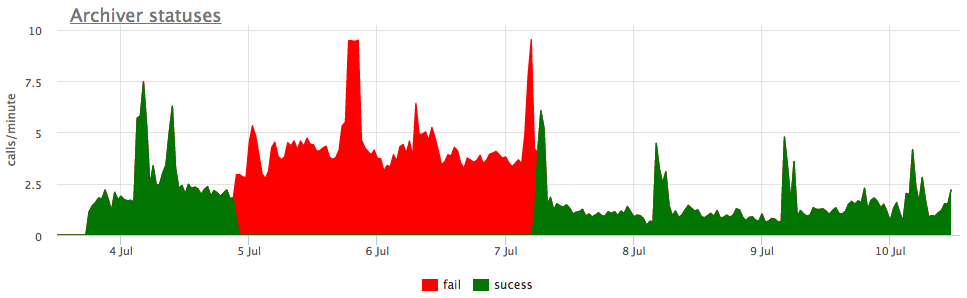
Consideramos os status de acordo com os contadores de pg_stat_archiver. Para o número de arquivos, fizemos um disparador automático para todos os clientes, pois ele geralmente falha, principalmente quando algum armazenamento em nuvem é usado como destino (S3, por exemplo).
Atraso na replicação
A replicação de streaming em andamento funciona através da transferência e reprodução de wal em réplicas. Se, por algum motivo, a réplica estiver atrasada e não perder um determinado número de segmentos, o assistente armazenará os segmentos pg_settings.wal_keep_segments para ela. Se a réplica ficar para trás em um número maior de segmentos, ela não poderá mais se conectar ao mestre (precisará ser derramada novamente).
Para garantir a preservação de qualquer número desejado de segmentos, a funcionalidade dos slots de replicação apareceu na 9.4, que será discutida mais adiante.
Slots de replicação
Se a replicação estiver configurada usando o slot de replicação e houver pelo menos uma conexão de réplica bem-sucedida ao slot, caso a réplica desapareça, o postgres armazenará todos os novos segmentos wal até que o local se esgote.
Ou seja, um slot de replicação esquecido pode causar aumento de volume. Felizmente, porém, podemos monitorar o status dos slots através de pg_replication_slots.
Aqui está o que parece em um exemplo ao vivo:
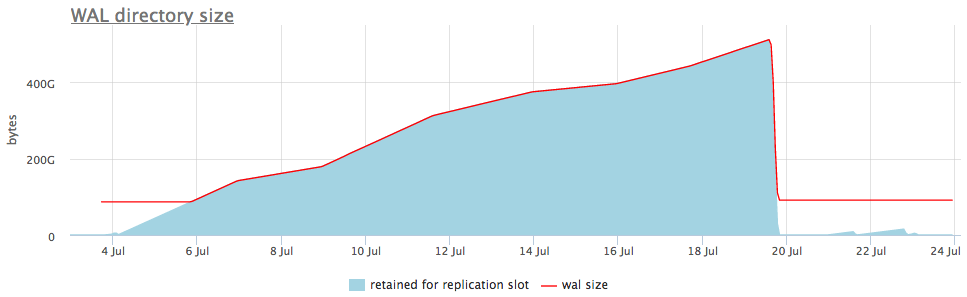

No gráfico superior, ao lado do tamanho do wal, sempre exibimos um slot com o número máximo de segmentos acumulados, mas também há um gráfico detalhado que mostra qual slot está inchado.
Depois de entendermos que tipo de slot está coletando dados, podemos reparar as réplicas associadas a ele ou simplesmente excluí-lo.
Eu citei os casos mais comuns de wal swelling, mas tenho certeza de que existem outros casos (também são encontrados erros no postgres). Portanto, é importante monitorar o tamanho do wal e responder a problemas antes que o espaço em disco se esgote e o banco de dados pare de atender às solicitações.
Nosso serviço de monitoramento já sabe coletar tudo isso, visualizar e alertar corretamente. E também temos uma opção de entrega local para aqueles a quem a nuvem não se adequa.