Todos os dias, os usuários comprometem milhões de atividades online. O projeto FACETz DMP precisa estruturar esses dados e segmentá-los para identificar as preferências do usuário. No artigo, falaremos sobre como a equipe segmentou uma audiência de 600 milhões de pessoas, processou 5 bilhões de eventos diariamente e trabalhou com estatísticas usando Kafka e HBase.
O material é baseado na transcrição de um
relatório de Artyom Marinov , especialista em big data da Directual, da conferência SmartData 2017.
Meu nome é Artyom Marinov. Quero falar sobre como redesenhamos a arquitetura do projeto FACETz DMP quando trabalhei na Data Centric Alliance. Por que fizemos, o que levou, para onde seguimos e que problemas encontramos.
O DMP (Data Management Platform) é uma plataforma para coletar, processar e agregar dados do usuário. Dados são muitas coisas diferentes. A plataforma tem cerca de 600 milhões de usuários. São milhões de cookies que entram na Internet e fazem vários eventos. Em geral, um dia, em média, se parece com isso: vemos cerca de 5,5 bilhões de eventos por dia, eles são espalhados de dia para dia e, no pico, atingem cerca de 100 mil eventos por segundo.

Eventos são vários sinais do usuário. Por exemplo, uma visita a um site: vemos de qual navegador o usuário parte, seu agente do usuário e tudo o que podemos extrair. Às vezes, vemos como e para que consultas de pesquisa ele veio ao site. Também podem ser vários dados do mundo offline, por exemplo, o que ele paga com cupons de desconto e assim por diante.
Precisamos salvar esses dados e marcar o usuário nos chamados grupos de segmentos de público. Por exemplo, os segmentos podem ser uma "mulher" que "adora gatos" e está procurando "serviço de carro", ela "tem um carro com mais de três anos".
Por que segmentar um usuário? Existem muitos aplicativos para isso, por exemplo, publicidade. Várias redes de anúncios podem otimizar os algoritmos de veiculação de anúncios. Se você estiver anunciando seu serviço de carro, poderá configurar uma campanha de forma que apenas pessoas que tenham um carro antigo mostrem informações, excluindo proprietários de novos. Você pode alterar dinamicamente o conteúdo do site, pode usar os dados para pontuação - existem muitos aplicativos.
Os dados são obtidos de muitos lugares completamente diferentes. Pode ser configurações diretas de pixel - isto é, se o cliente deseja analisar sua audiência, ele coloca o pixel no site, uma imagem invisível que é baixada do nosso servidor. O ponto principal é que vemos a visita do usuário a este site: você pode salvá-lo, começar a analisar e entender o retrato do usuário, todas essas informações estão disponíveis para o nosso cliente.

Os dados podem ser obtidos de vários parceiros que veem muitos dados e desejam monetizá-los de várias maneiras. Os parceiros podem fornecer dados em tempo real e fazer uploads periódicos na forma de arquivos.
Principais requisitos:
- Escalabilidade horizontal;
- Avaliação do volume da audiência;
- Conveniência de monitoramento e desenvolvimento;
- Boa taxa de reação a eventos.
Um dos principais requisitos do sistema é a escalabilidade horizontal. Há um momento em que, quando você está desenvolvendo um portal ou loja online, pode estimar o número de usuários (como ele crescerá, como ele mudará) e entenderá a quantidade de recursos necessários e como a loja viverá e se desenvolverá com o tempo.
Ao desenvolver uma plataforma semelhante ao DMP, você precisa estar preparado para o fato de que qualquer site grande - a Amazon condicional - pode colocar seu pixel nele, e você terá que trabalhar com o tráfego desse site inteiro, enquanto não deve cair, e os indicadores os sistemas não devem, de alguma forma, mudar disso.
Também é muito importante entender o volume de um determinado público para que um anunciante em potencial ou outra pessoa possa elaborar um plano de mídia. Por exemplo, uma pessoa vem até você e pede que você descubra quantas mulheres grávidas de Novosibirsk estão procurando uma hipoteca para avaliar se faz sentido direcioná-las ou não.
Do ponto de vista do desenvolvimento, você precisa monitorar tudo o que acontece no seu sistema, depurar parte do tráfego real e assim por diante.
Um dos requisitos mais importantes do sistema é uma boa taxa de reação a eventos. Quanto mais rápido os sistemas respondem aos eventos, melhor é óbvio. Se você estiver procurando por ingressos para o teatro, poderá ver algum tipo de oferta de desconto após um dia, dois dias ou até uma hora - isso pode ser irrelevante, pois você já pode comprar ingressos ou assistir a uma apresentação. Quando você está procurando uma broca - você está procurando, encontra, compra, pendura uma prateleira e, após alguns dias, o bombardeio começa: “Compre uma broca!”.
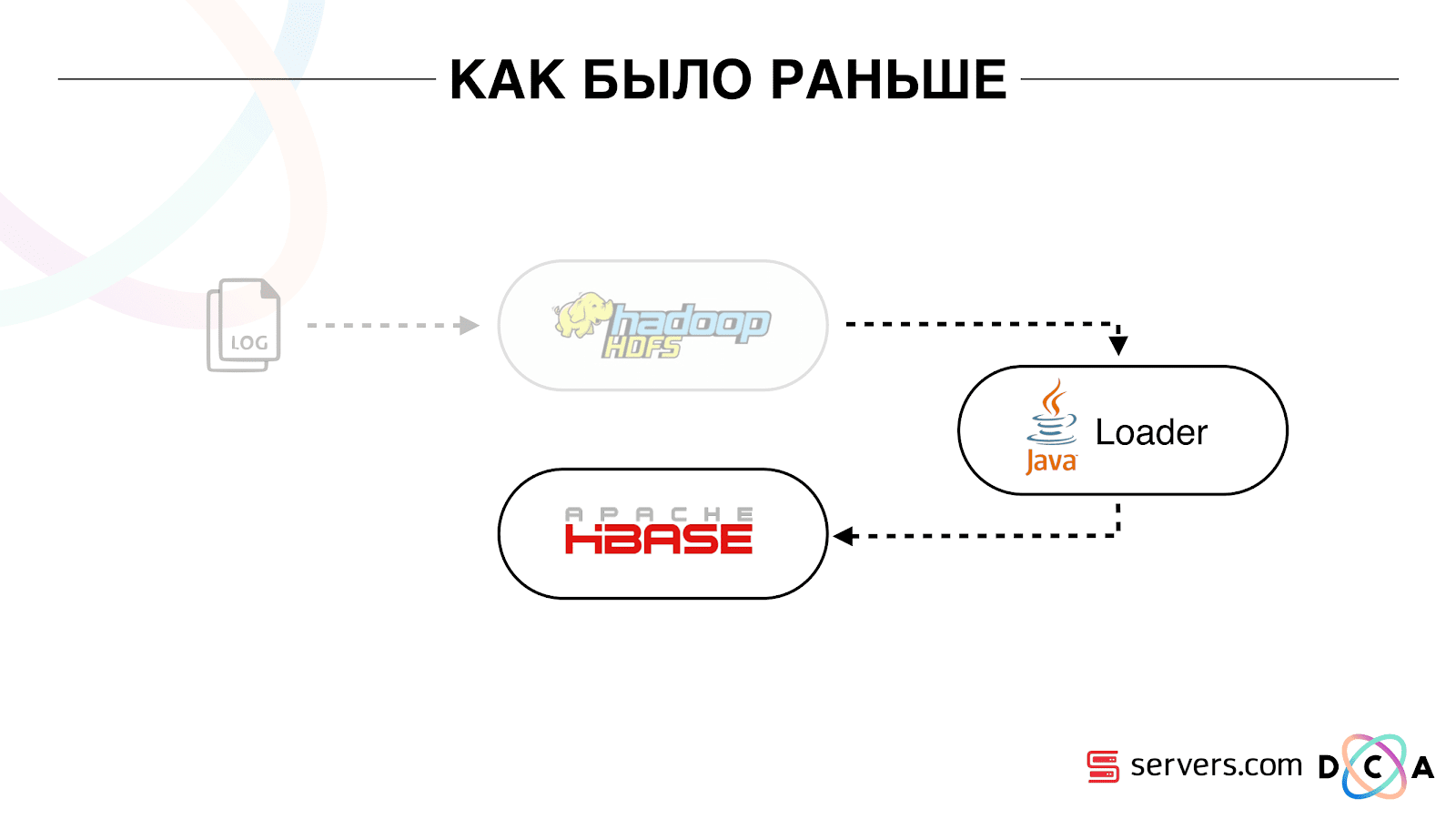
Como era antes
O artigo como um todo é sobre reciclagem de arquitetura. Gostaria de dizer qual foi o nosso ponto de partida, como tudo funcionou antes das mudanças.
Todos os dados que tínhamos, fosse um fluxo de dados direto ou logs, foram armazenados no HDFS - armazenamento de arquivos distribuídos. Depois, houve um certo processo iniciado periodicamente, pegou todos os arquivos não processados do HDFS e os converteu em solicitações de enriquecimento de dados no HBase ("solicitações de PUT").
Como armazenamos dados no HBase
Este é um banco de dados colunar de séries temporais. Ela tem o conceito de uma chave de linha - esta é a chave sob a qual você armazena seus dados. Usamos o ID do usuário como a chave, o ID do usuário, que geramos quando o vemos pela primeira vez. Dentro de cada chave, os dados são divididos em Família de colunas - entidades no nível em que você pode gerenciar as metainformações de seus dados. Por exemplo, você pode armazenar mil versões de registros para os "dados" da Família de Colunas e armazená-los por dois meses, e para a Família de Colunas "brutos" - um ano, como opção.
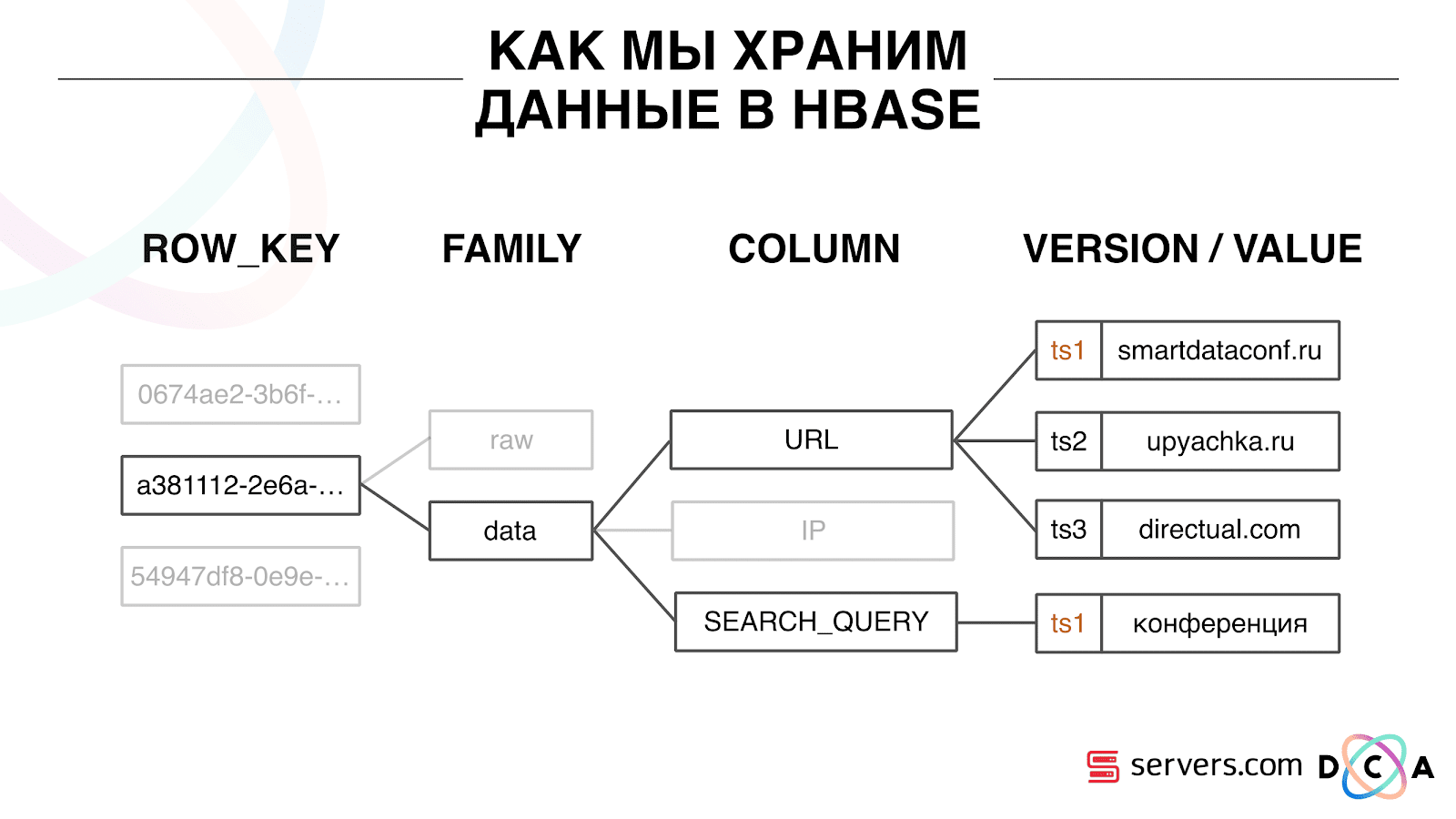
Dentro da família de colunas, há muitos qualificadores de coluna (a seguir coluna). Usamos vários atributos do usuário como coluna. Pode ser o URL para o qual ele foi, endereço IP, consulta de pesquisa. E o mais importante, muitas informações são armazenadas dentro de cada coluna. Dentro do URL da coluna, pode ser indicado que o usuário foi para smartdataconf.ru e depois para outros sites. E o carimbo de data / hora é usado como a versão - você vê um histórico ordenado de visitas de usuários. No nosso caso, podemos determinar que o usuário acessou o site smartdataconf com a palavra-chave “conference”, porque eles têm o mesmo registro de data e hora.
Trabalhar com HBase
Existem várias opções para trabalhar com o HBase. Podem ser solicitações PUT (solicitação de alteração de dados), solicitação GET ("forneça todos os dados do usuário Vasya" e assim por diante). Você pode executar solicitações de digitalização - varredura sequencial multithread de todos os dados no HBase. Usamos isso anteriormente para marcar nos segmentos de público.
Havia uma tarefa chamada Analytics Engine, que era executada uma vez por dia e examinava o HBase em vários threads. Para cada usuário, ela retirou toda a história do HBase e a executou através de um conjunto de scripts analíticos.

O que é um script analítico? Esse é um tipo de caixa preta (classe java), que recebe todos os dados do usuário como entrada e fornece um conjunto de segmentos que considera adequados como saída. Damos tudo ao script que vemos - IP, visitas, UserAgent, etc., e a saída dos scripts é: “essa é uma mulher, adora gatos, não gosta de cachorros”.
Esses dados foram fornecidos aos parceiros, as estatísticas foram consideradas. Era importante para nós entender quantas mulheres são em geral, quantos homens, quantas pessoas amam gatos, quantas têm ou não um carro e assim por diante.
Armazenamos estatísticas no MongoDB e escrevemos incrementando um contador de segmento específico para cada dia. Tivemos um gráfico do volume de cada segmento para cada dia.
Este sistema foi bom para o seu tempo. Permitiu escalar horizontalmente, crescer, permitiu estimar o volume da audiência, mas teve várias desvantagens.
Nem sempre era possível entender o que estava acontecendo no sistema, observar os logs. Enquanto estávamos no hoster anterior, a tarefa muitas vezes caiu por várias razões. Havia um cluster Hadoop de mais de 20 servidores, uma vez por dia, um dos servidores travava de maneira estável. Isso levou ao fato de que a tarefa poderia cair parcialmente e não calcular os dados. Era necessário ter tempo para reiniciá-lo e, dado que funcionou por várias horas, havia várias nuances.
A coisa mais básica que a arquitetura existente não cumpriu foi que o tempo de reação ao evento foi muito longo. Há até uma história sobre esse assunto. Havia uma empresa que emitia microempréstimos para a população das regiões e fizemos uma parceria com eles. O cliente chega ao site, preenche um pedido de microcrédito, a empresa precisa responder em 15 minutos: eles estão prontos para conceder um empréstimo ou não. Se você estiver pronto, eles imediatamente transferiram dinheiro para o cartão.
Tudo funcionou bem. O cliente decidiu verificar como isso geralmente acontece: eles pegaram um laptop separado, instalaram um sistema limpo, visitaram muitas páginas na Internet e acessaram o site. Eles veem que há uma solicitação e, em resposta, dizemos que ainda não há dados. O cliente pergunta: "Por que não há dados?"
Nós explicamos: existe um certo atraso antes que o usuário tome uma ação. Os dados são enviados para o HBase, processados e somente então o cliente recebe o resultado. Parece que se o usuário não viu o anúncio - tudo está em ordem, nada de ruim acontecerá. Mas nessa situação, o usuário pode não receber um empréstimo por causa do atraso.
Este não é um caso isolado e foi necessário mudar para um sistema em tempo real. O que queremos dela?

Queremos gravar dados no HBase assim que os vemos. Vimos uma visita, enriquecemos tudo o que sabemos e a enviamos para a Storage. Assim que os dados no Storage forem alterados, você precisará executar imediatamente todo o conjunto de scripts analíticos que temos. Queremos a conveniência do monitoramento e desenvolvimento, a capacidade de escrever novos scripts, depurá-los em partes do tráfego real. Queremos entender o que o sistema está ocupado no momento.
A primeira coisa que começamos é resolver o segundo problema: segmentar o usuário imediatamente após alterar os dados sobre ele no HBase. Inicialmente, tínhamos nós de trabalho (tarefas de redução de mapa foram lançadas neles) localizados no mesmo local que o HBase. Em vários casos, foi muito bom - os cálculos são realizados próximos aos dados, as tarefas funcionam rapidamente, pouco tráfego passa pela rede. É claro que a tarefa consome alguns recursos, porque executa scripts analíticos complexos.
Quando vamos trabalhar em tempo real, a natureza da carga no HBase muda. Passamos para leituras aleatórias em vez de sequenciais. É importante que a carga no HBase seja esperada - não podemos permitir que alguém execute a tarefa no cluster Hadoop e prejudique o desempenho do HBase.
A primeira coisa que fizemos foi mover o HBase para servidores separados. Também aprimoramos o BlockCache e o BloomFilter. Em seguida, fizemos um bom trabalho em como armazenar dados no HBase. Eles praticamente reformularam o sistema sobre o qual falei no início e colheram os dados em si.

Do óbvio: nós armazenamos o IP como uma string e ficamos longos em números. Alguns dados foram classificados, executaram coisas de vocabulário e assim por diante. O ponto principal é que, por causa disso, conseguimos sacudir o HBase cerca de duas vezes - de 10 TB a 5 TB. O HBase possui um mecanismo semelhante aos gatilhos em um banco de dados regular. Este é um mecanismo de coprocessador. Escrevemos um coprocessador que, quando um usuário muda para o HBase, envia o ID do usuário para Kafka.
O ID do usuário está em Kafka. Além disso, existe um certo "segmentador" de serviço. Ele lê o fluxo de identificadores de usuários e executa neles todos os mesmos scripts que eram antes, solicitando dados do HBase. O processo foi lançado em 10% do tráfego, vimos como ele funciona. Tudo foi muito bom.

Em seguida, começamos a aumentar a carga e vimos vários problemas. A primeira coisa que vimos foi que o serviço funciona, segmenta e depois cai do Kafka, se conecta e começa a funcionar novamente. Vários serviços - eles se ajudam. Então o próximo cai, outro e assim por diante em um círculo. Ao mesmo tempo, a fila de usuários para segmentação quase não está sendo processada.
Isso ocorreu devido à peculiaridade do mecanismo de batimento cardíaco em Kafka, que ainda era a versão 0.8. Pulsação é quando os consumidores dizem ao corretor se estão vivos ou não, no nosso caso, o segmentador relata. Aconteceu o seguinte: recebemos um pacote de dados bastante grande e o enviamos para processamento. Por um tempo, funcionou, enquanto funcionava - nenhum batimento cardíaco foi enviado. Os corretores acreditavam que o consumidor estava morto e o desligaram.
O consumidor trabalhou até o fim, desperdiçando CPUs preciosas, tentou dizer que o pacote de dados estava funcionando e o próximo poderia ser levado, mas ele foi recusado porque o outro levou embora o que estava trabalhando. Corrigimos o problema com o calor do fundo, e a verdade veio a uma versão mais recente do Kafka, onde solucionamos esse problema.
Surgiu então a pergunta: em que tipo de hardware nossos segmentadores deveriam ser instalados. A segmentação é um processo intensivo de recursos (vinculado à CPU). É importante que o serviço não apenas consuma muita CPU, mas também carregue a rede. Agora o tráfego atinge 5 Gbit / s. A questão era: onde colocar os serviços, em muitos servidores pequenos ou um pouco grandes.
Nesse momento, já nos mudamos para o
servers.com em metal
puro . Conversamos com os funcionários dos servidores, eles nos ajudaram, possibilitaram testar o trabalho da nossa solução em um pequeno número de servidores caros e em muitos baratos com CPUs poderosas. Escolhemos a opção apropriada, calculando o custo unitário do processamento de um evento por segundo. A propósito, a escolha recaiu sobre o Dell R230, suficientemente poderoso e ao mesmo tempo extremamente acessível, eles o lançaram - tudo funcionou.
É importante que, depois que o segmentador tenha marcado o usuário em segmentos, o resultado de sua análise retorne a Kafka, em um determinado tópico Resultado da segmentação.
Além disso, podemos nos conectar de maneira independente a esses dados por diferentes consumidores que não interferem entre si. Isso nos permite fornecer dados de forma independente para cada parceiro, sejam alguns parceiros externos, DSP interno, Google, estatísticas.
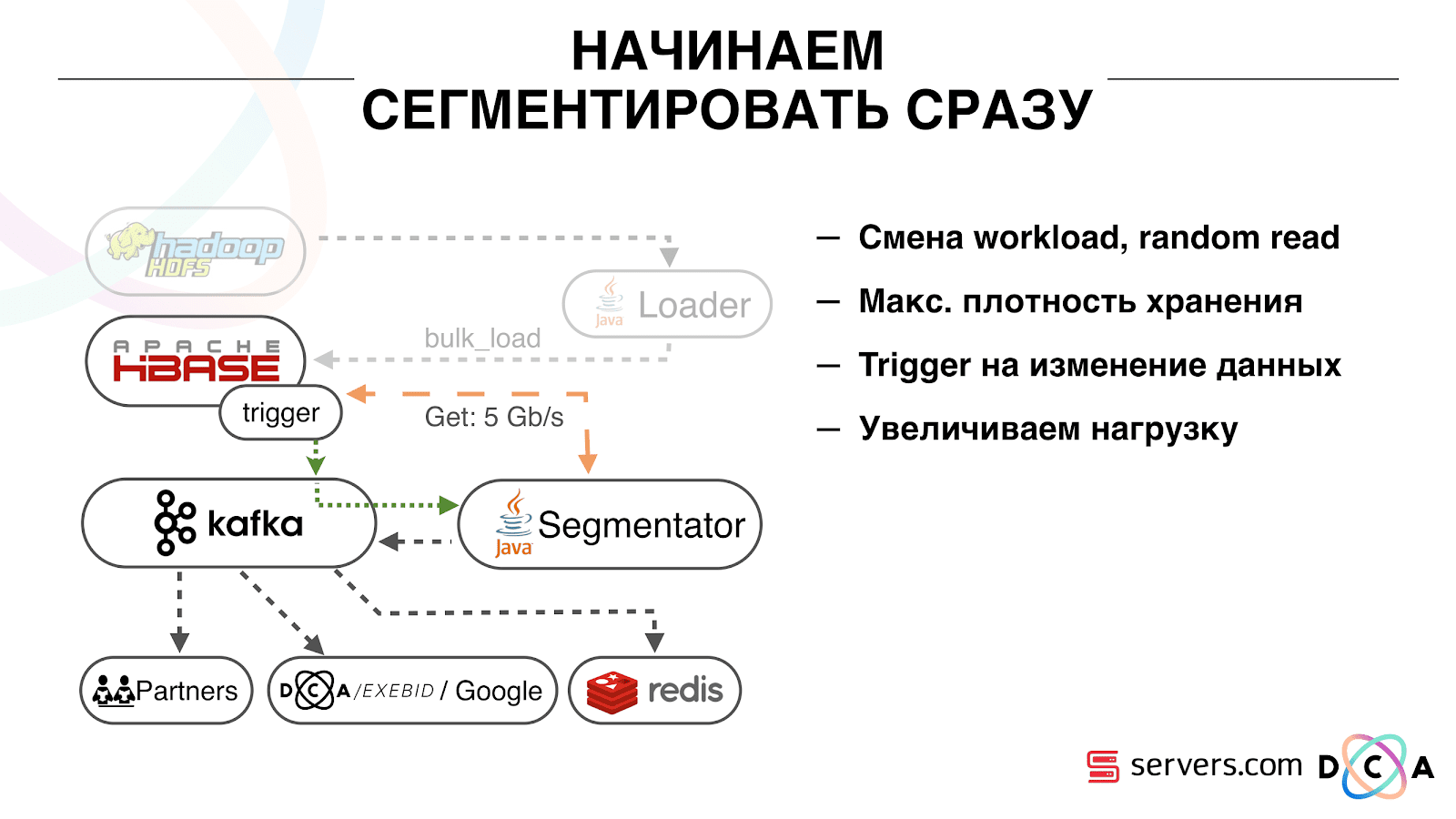
Com as estatísticas, há também um ponto interessante: antes, poderíamos aumentar o valor dos contadores no MongoDB, quantos usuários estavam em um determinado segmento por um determinado dia. Agora, isso não pode ser feito porque agora analisamos cada usuário depois que ele conclui um evento, ou seja, várias vezes ao dia.
Portanto, tivemos que resolver o problema de contar o número exclusivo de usuários no fluxo. Para isso, usamos a estrutura de dados HyperLogLog e sua implementação no Redis. A estrutura de dados é probabilística. Isso significa que você pode adicionar identificadores de usuário lá, os identificadores em si não serão armazenados; portanto, você pode armazenar milhões de identificadores exclusivos no HyperLogLog extremamente compactos, e isso levará até 12 kilobytes por chave.
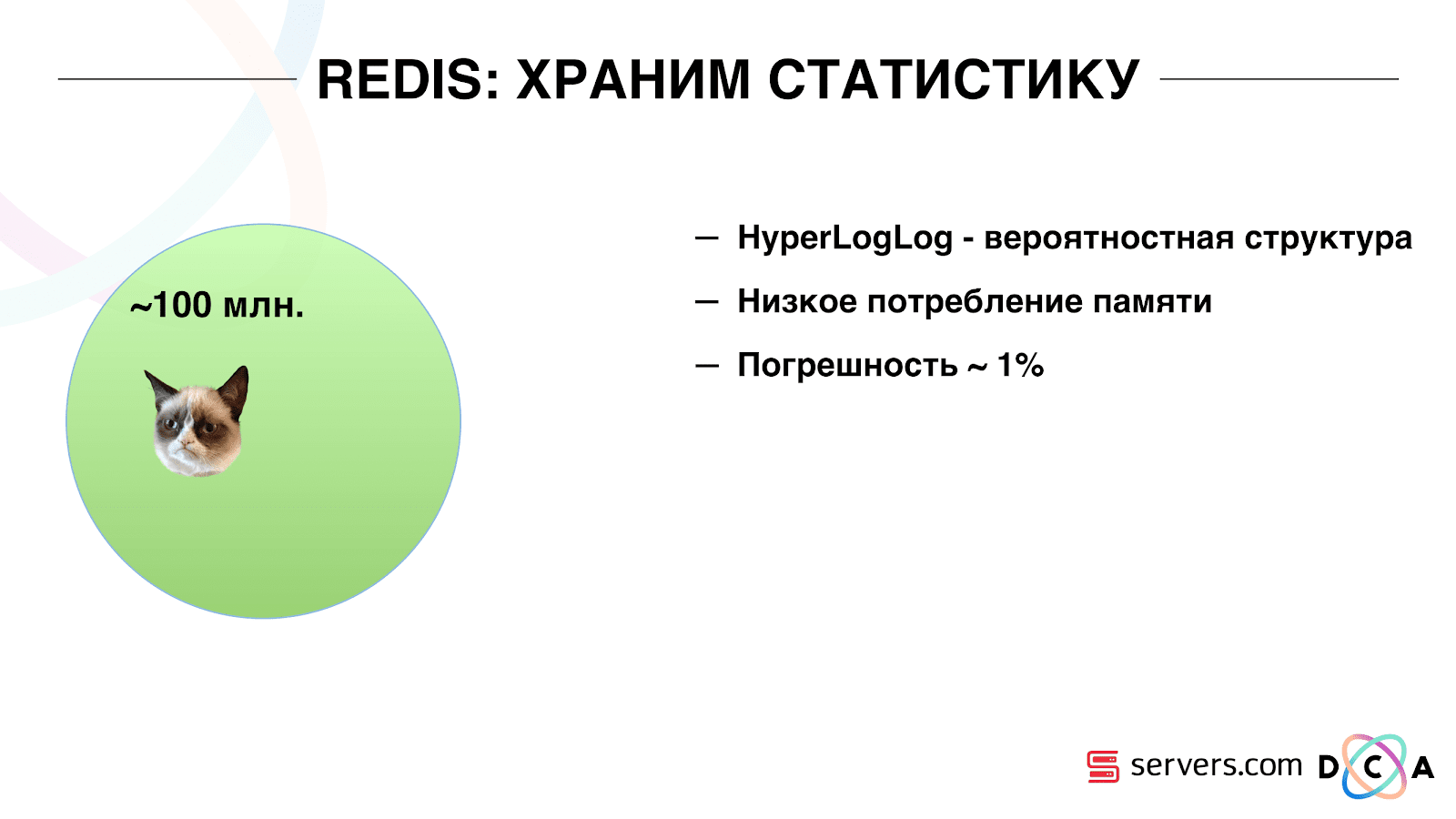
Você não pode obter os identificadores por conta própria, mas pode descobrir o tamanho desse conjunto. Como a estrutura de dados é probabilística, há algum erro. Por exemplo, se você tiver um segmento "gosta de gatos", solicitando o tamanho desse segmento por um determinado dia, receberá 99,2 milhões e isso significará algo como "de 99 a 100 milhões".
Também no HyperLogLog, você pode obter o tamanho da união de vários conjuntos. Digamos que você tenha dois segmentos: "adora focas" e "adora cachorros". Digamos os primeiros 100 milhões, o segundo 1 milhão.Pode-se perguntar: "Quantos animais eles gostam?" e obtenha a resposta "cerca de 101 milhões" com um erro de 1%. Seria interessante calcular quanto gatos e cães são amados ao mesmo tempo, mas fazer isso é bastante difícil.

Por um lado, você pode descobrir o tamanho de cada conjunto, descobrir o tamanho da união, adicionar, subtrair um do outro e obter a interseção. Mas, como o tamanho do erro pode ser maior que o tamanho da interseção final, o resultado final pode ter a forma "de -50 a 50 mil".

Nós trabalhamos bastante em como aumentar o desempenho ao gravar dados no Redis. Inicialmente, alcançamos 200 mil operações por segundo. Mas quando cada usuário tem mais de 50 segmentos - registrando informações sobre cada usuário - 50 operações. Acontece que somos bastante limitados em largura de banda e, neste exemplo, não podemos gravar informações sobre mais de 4 mil usuários por segundo, isso é várias vezes menor do que precisamos.
Nós fizemos um “procedimento armazenado” separado no Redis via Lua, carregamos lá e começamos a passar uma string para ele com a lista inteira de segmentos de um usuário. O procedimento interno cortará a sequência passada nas atualizações necessárias do HyperLogLog e salvará os dados, portanto, alcançamos cerca de 1 milhão de atualizações por segundo.
Um pouco incondicional: o Redis é de thread único, você pode fixá-lo em um núcleo de processador e uma placa de rede em outra e obter outro desempenho de 15%, economizando na alternância de contexto. Além disso, o ponto importante é que você não pode simplesmente agrupar a estrutura de dados, porque as operações de obtenção do poder dos uniões de conjuntos não são agrupadas
Kafka é uma ótima ferramenta
Você vê que o Kafka é nossa principal ferramenta de transporte no sistema.
Tem a essência do "tópico". É aqui que você escreve os dados, mas em essência - a fila. No nosso caso, existem várias filas. Um deles é o identificador de usuários a quem é necessário segmentar. O segundo são os resultados da segmentação.
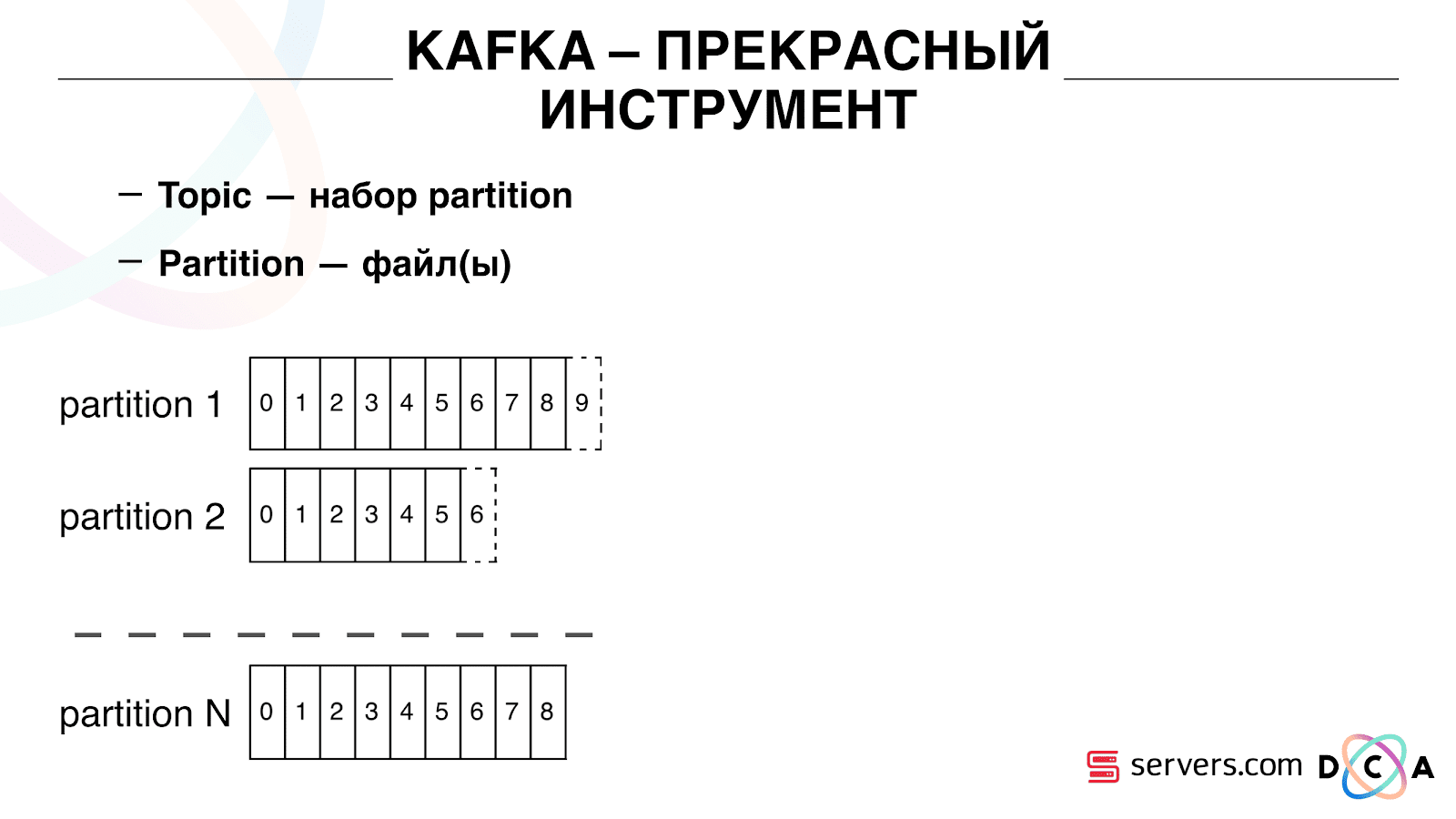
Um tópico é um conjunto de partições s. É dividido em algumas partes. Cada partição é um arquivo no disco rígido. Quando seus produtores gravam dados, eles escrevem trechos de texto no final da partição. Quando seus consumidores leem os dados, eles simplesmente leem dessas partições.
O importante é que você possa conectar independentemente vários grupos de consumidores, eles consumirão dados sem interferir entre si. Isso é determinado pelo nome do grupo de consumidores e é alcançado da seguinte maneira.
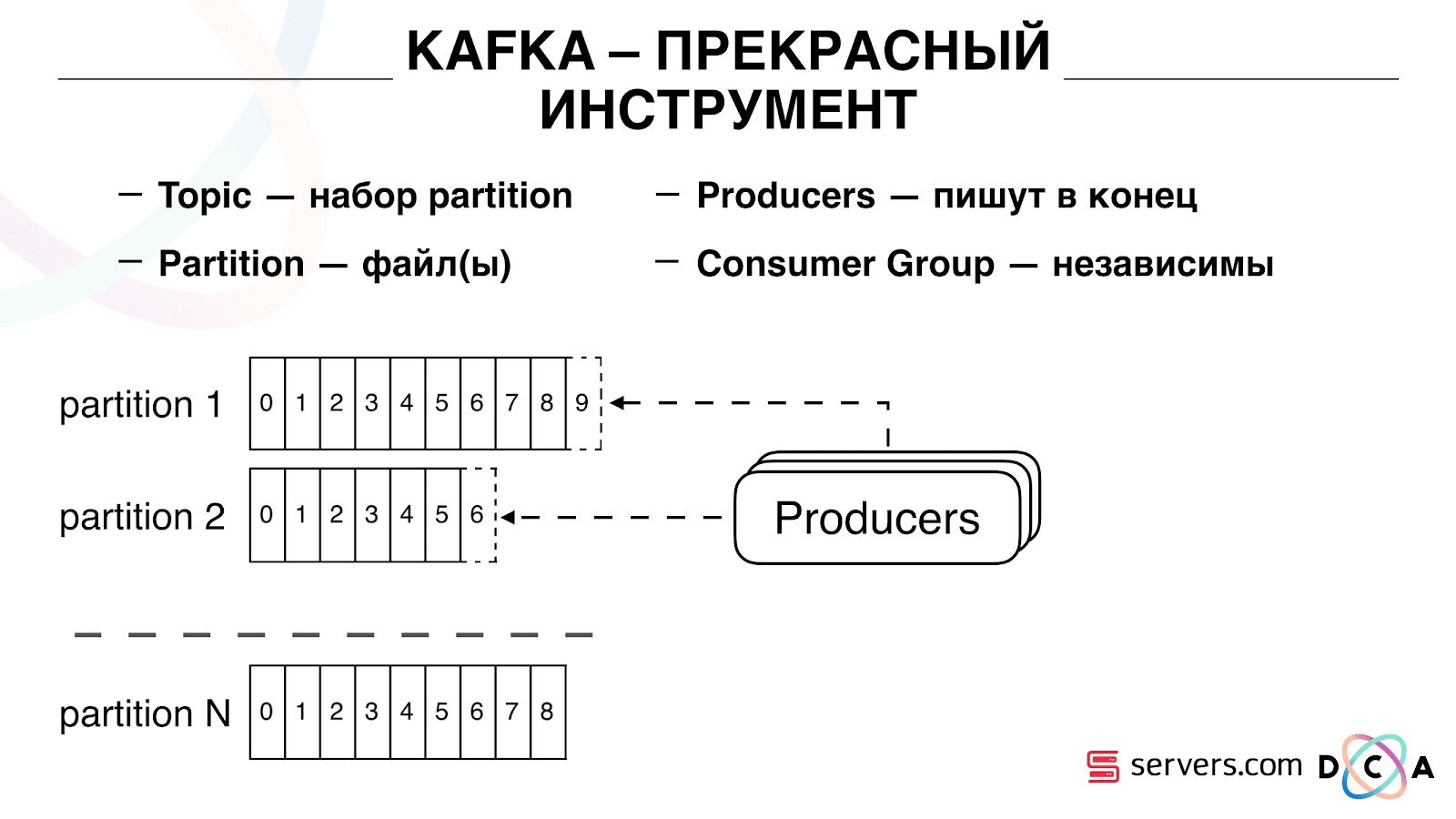
Existe o deslocamento, a posição em que o grupo de consumidores agora está localizado em cada partição. Por exemplo, o grupo A consome a sétima mensagem da partição1 e a quinta da partição2. O grupo B, independente de A, tem outro deslocamento.
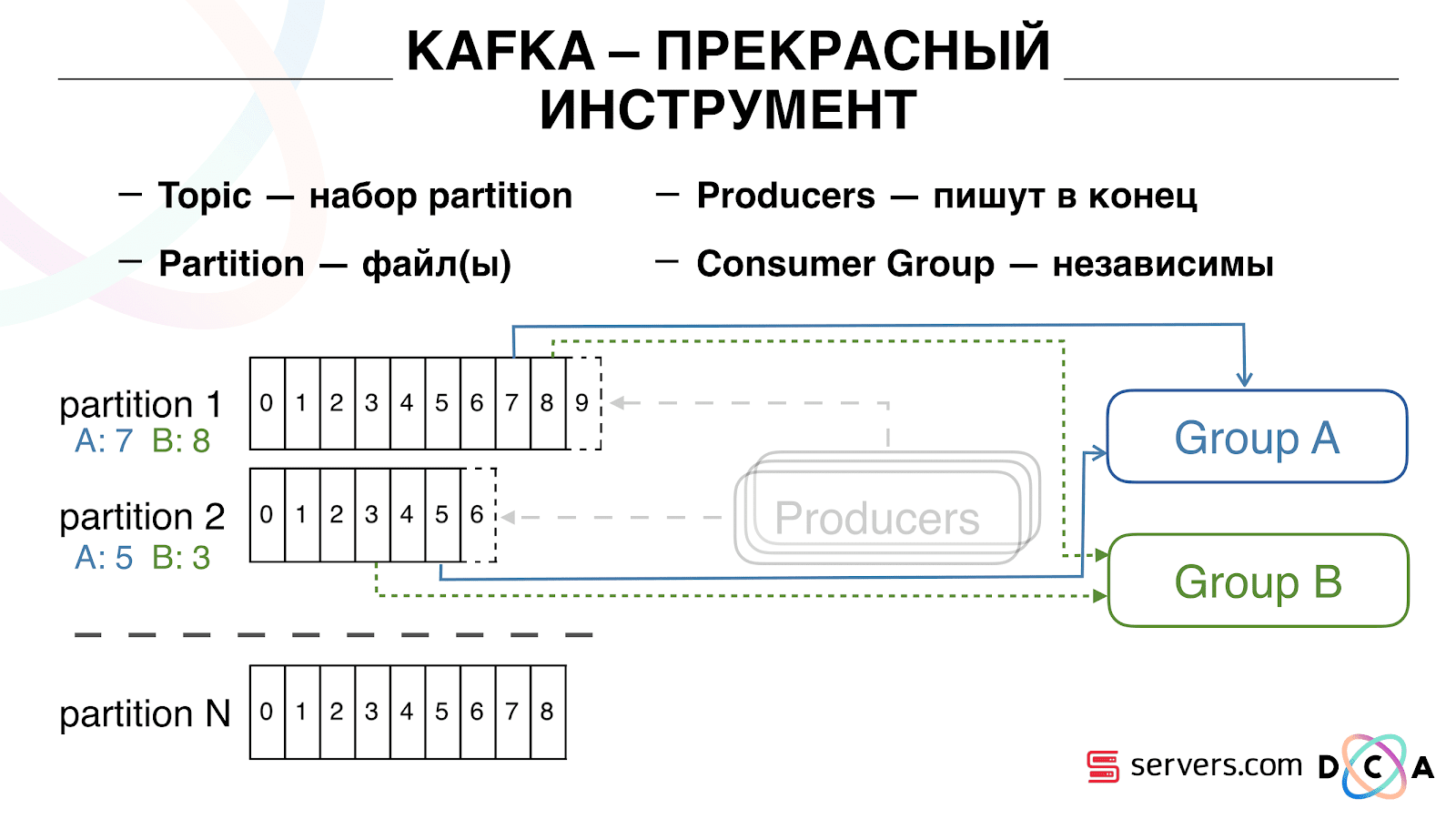 Você pode dimensionar seu grupo de consumidores horizontalmente, adicionar outro processo ou servidor. Isso acontecerá com a reatribuição de partições (o Kafka broker atribuirá a cada consumidor uma lista de partições para consumo) Isso significa que o primeiro grupo de consumidores começará a consumir apenas a partição 1 e o segundo consumirá apenas a partição 2. Se alguns dos consumidores morrerem (por exemplo, o ritmo do coração não chega), uma nova reatribuição , cada consumidor recebe uma lista de partições atualizada para processamento.
Você pode dimensionar seu grupo de consumidores horizontalmente, adicionar outro processo ou servidor. Isso acontecerá com a reatribuição de partições (o Kafka broker atribuirá a cada consumidor uma lista de partições para consumo) Isso significa que o primeiro grupo de consumidores começará a consumir apenas a partição 1 e o segundo consumirá apenas a partição 2. Se alguns dos consumidores morrerem (por exemplo, o ritmo do coração não chega), uma nova reatribuição , cada consumidor recebe uma lista de partições atualizada para processamento. É bastante conveniente. Primeiro, você pode manipular o deslocamento para cada grupo de consumidores. Imagine que exista um parceiro para quem você transfira dados deste tópico com os resultados da segmentação. Ele escreve que perdeu acidentalmente o último dia de dados como resultado de um bug. E você, para o grupo de consumidores desse cliente, reverte um dia e despeje todo o dia de dados nele. Também podemos ter nosso próprio grupo de consumidores, conectar-se ao tráfego de produção, observar o que acontece e depurar dados reais.Assim, conseguimos que começamos a segmentar usuários ao mudar, podemos conectar independentemente novos consumidores, escrevemos estatísticas e podemos assisti-las. Agora você precisa obter os dados gravados no HBase imediatamente após a chegada deles.
É bastante conveniente. Primeiro, você pode manipular o deslocamento para cada grupo de consumidores. Imagine que exista um parceiro para quem você transfira dados deste tópico com os resultados da segmentação. Ele escreve que perdeu acidentalmente o último dia de dados como resultado de um bug. E você, para o grupo de consumidores desse cliente, reverte um dia e despeje todo o dia de dados nele. Também podemos ter nosso próprio grupo de consumidores, conectar-se ao tráfego de produção, observar o que acontece e depurar dados reais.Assim, conseguimos que começamos a segmentar usuários ao mudar, podemos conectar independentemente novos consumidores, escrevemos estatísticas e podemos assisti-las. Agora você precisa obter os dados gravados no HBase imediatamente após a chegada deles.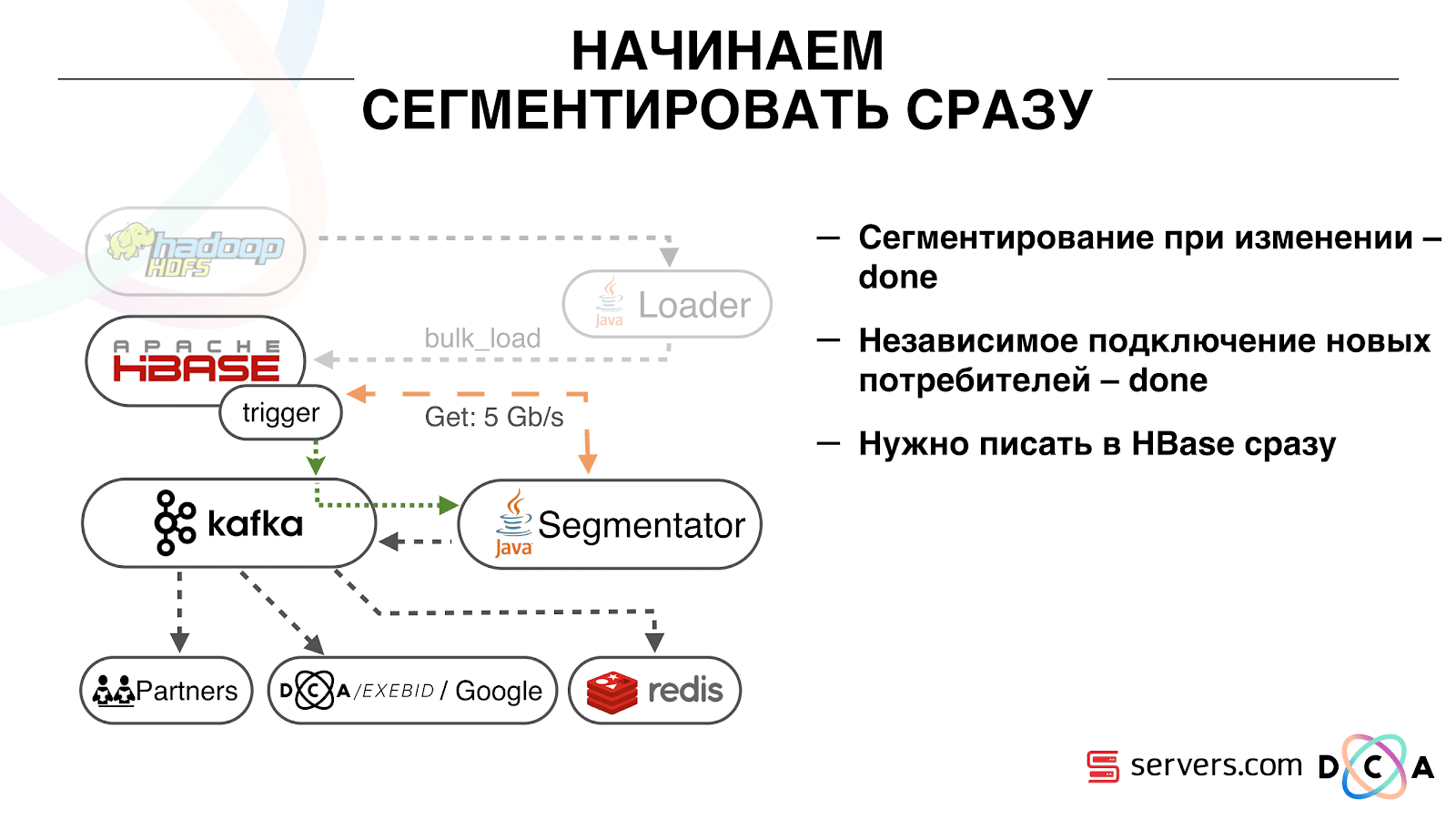 Como nós fizemos isso. Costumava haver carregamento de dados em lote. Havia um Batch Loader, que processava arquivos de log de atividades do usuário: se um usuário fazia 10 visitas, o lote vinha para 10 eventos, ele era registrado no HBase em uma operação. Houve apenas um evento por segmentação. Agora queremos escrever cada evento separado no armazenamento. Aumentaremos bastante o fluxo de gravação e o fluxo de leitura. O número de eventos por segmentação também aumentará.
Como nós fizemos isso. Costumava haver carregamento de dados em lote. Havia um Batch Loader, que processava arquivos de log de atividades do usuário: se um usuário fazia 10 visitas, o lote vinha para 10 eventos, ele era registrado no HBase em uma operação. Houve apenas um evento por segmentação. Agora queremos escrever cada evento separado no armazenamento. Aumentaremos bastante o fluxo de gravação e o fluxo de leitura. O número de eventos por segmentação também aumentará. A primeira coisa que fizemos foi portar o HBase para o SSD. Por meios padrão, isso não é feito particularmente. Isso foi feito usando o HDFS. Você pode dizer que um diretório específico no HDFS deve estar nesse grupo de discos. Houve um problema legal com o fato de que, quando levamos o HBase para o SSD e o esvaziamos, todos os instantâneos chegaram lá e nossos SSDs terminaram rapidamente.Isso também foi resolvido, começamos a exportar periodicamente instantâneos para um arquivo, gravar em outro diretório do HDFS e excluir todas as meta-informações sobre os instantâneos. Se você precisar restaurar - pegue o arquivo salvo, importe e restaure. Felizmente, esta operação não é frequente.Também no SSD, eles removeram o Write Ahead Log, torceram o MemStore, ativaram o bloco de cache na opção de gravação. Ele permite que você os coloque imediatamente no cache do bloco ao gravar dados. Isso é muito conveniente porque no nosso caso, se registrarmos os dados, é altamente provável que sejam lidos imediatamente. Isso também deu algumas vantagens.Em seguida, mudamos todas as nossas fontes de dados para gravar dados no Kafka. Já em Kafka, registramos dados no HDFS para manter a compatibilidade com versões anteriores, inclusive para que nossos analistas pudessem trabalhar com dados, executar tarefas do MapReduce e analisar seus resultados.Conectamos um grupo de consumidores separado que grava dados no HBase. Este é, de fato, um wrapper que lê Kafka e forma os PUTs no HBase.
A primeira coisa que fizemos foi portar o HBase para o SSD. Por meios padrão, isso não é feito particularmente. Isso foi feito usando o HDFS. Você pode dizer que um diretório específico no HDFS deve estar nesse grupo de discos. Houve um problema legal com o fato de que, quando levamos o HBase para o SSD e o esvaziamos, todos os instantâneos chegaram lá e nossos SSDs terminaram rapidamente.Isso também foi resolvido, começamos a exportar periodicamente instantâneos para um arquivo, gravar em outro diretório do HDFS e excluir todas as meta-informações sobre os instantâneos. Se você precisar restaurar - pegue o arquivo salvo, importe e restaure. Felizmente, esta operação não é frequente.Também no SSD, eles removeram o Write Ahead Log, torceram o MemStore, ativaram o bloco de cache na opção de gravação. Ele permite que você os coloque imediatamente no cache do bloco ao gravar dados. Isso é muito conveniente porque no nosso caso, se registrarmos os dados, é altamente provável que sejam lidos imediatamente. Isso também deu algumas vantagens.Em seguida, mudamos todas as nossas fontes de dados para gravar dados no Kafka. Já em Kafka, registramos dados no HDFS para manter a compatibilidade com versões anteriores, inclusive para que nossos analistas pudessem trabalhar com dados, executar tarefas do MapReduce e analisar seus resultados.Conectamos um grupo de consumidores separado que grava dados no HBase. Este é, de fato, um wrapper que lê Kafka e forma os PUTs no HBase.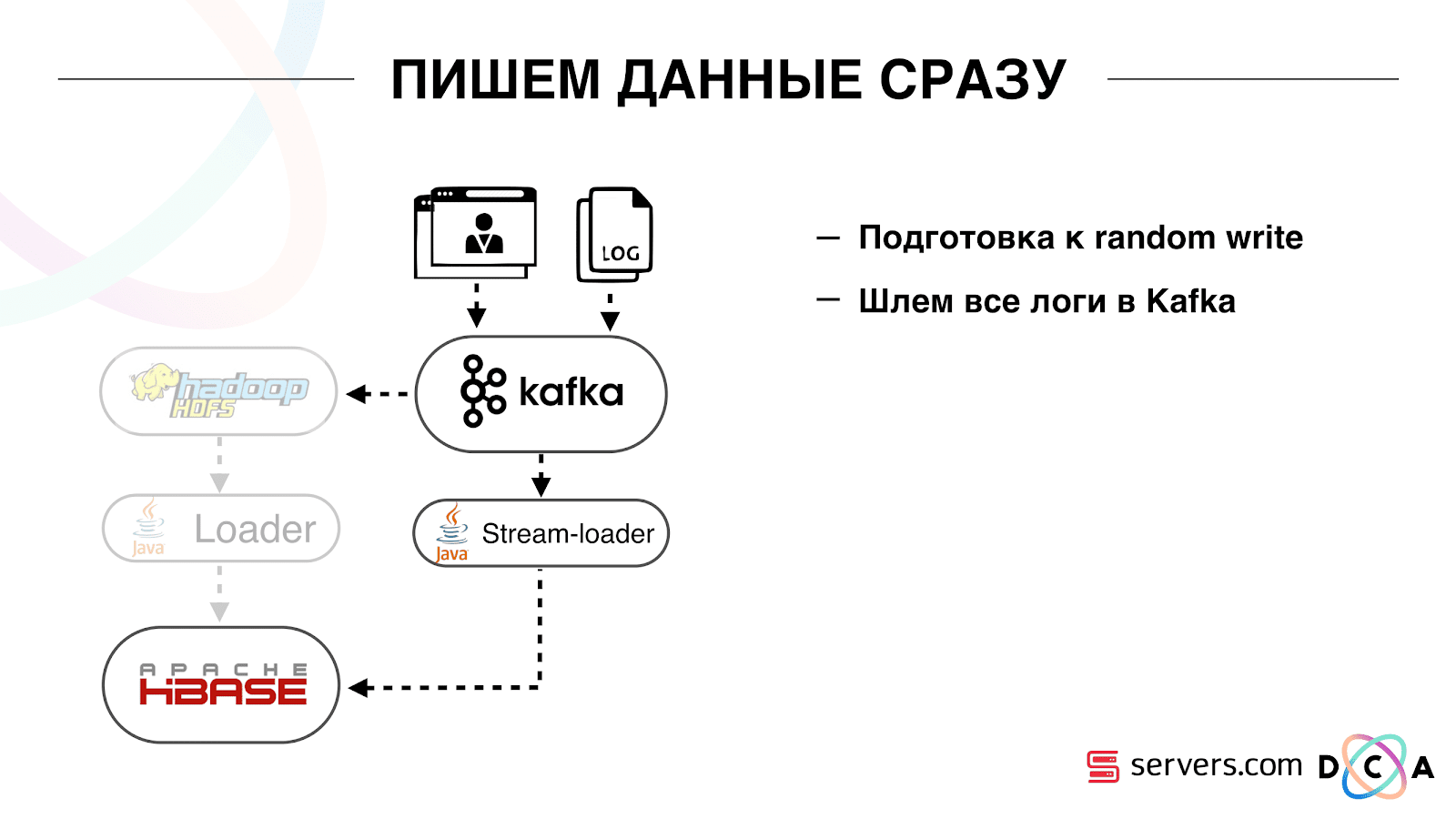 Lançamos dois circuitos em paralelo para não prejudicar a compatibilidade com versões anteriores e não prejudicar o desempenho do sistema. Um novo esquema foi lançado apenas em uma certa porcentagem de tráfego. Com 10%, tudo foi bem legal. Porém, com uma carga maior, os segmentadores não conseguiam lidar com o fluxo de segmentação.
Lançamos dois circuitos em paralelo para não prejudicar a compatibilidade com versões anteriores e não prejudicar o desempenho do sistema. Um novo esquema foi lançado apenas em uma certa porcentagem de tráfego. Com 10%, tudo foi bem legal. Porém, com uma carga maior, os segmentadores não conseguiam lidar com o fluxo de segmentação. Coletamos a métrica "quantas mensagens existem em Kafka antes de serem lidas a partir daí". Essa é uma boa métrica. Inicialmente, coletamos a métrica "quantas mensagens brutas existem agora", mas não diz nada de especial. Você olha: "Eu tenho um milhão de mensagens brutas", e daí? Para interpretar esse milhão, você precisa saber com que rapidez o segmentador (consumidor) está funcionando, o que nem sempre é claro.Com essa métrica, você vê imediatamente que os dados estão sendo gravados na fila, extraídos dela e o quanto eles esperam que sejam processados. Vimos que não tínhamos tempo para segmentar e a mensagem estava na fila várias horas antes de lê-la.Você pode simplesmente adicionar capacidade, mas seria muito
Coletamos a métrica "quantas mensagens existem em Kafka antes de serem lidas a partir daí". Essa é uma boa métrica. Inicialmente, coletamos a métrica "quantas mensagens brutas existem agora", mas não diz nada de especial. Você olha: "Eu tenho um milhão de mensagens brutas", e daí? Para interpretar esse milhão, você precisa saber com que rapidez o segmentador (consumidor) está funcionando, o que nem sempre é claro.Com essa métrica, você vê imediatamente que os dados estão sendo gravados na fila, extraídos dela e o quanto eles esperam que sejam processados. Vimos que não tínhamos tempo para segmentar e a mensagem estava na fila várias horas antes de lê-la.Você pode simplesmente adicionar capacidade, mas seria muito caro . Portanto, tentamos otimizar.Auto-dimensionável
Nós temos o HBase. O usuário está mudando, seu identificador está voando em Kafka. O tópico é dividido em partições, a partição de destino é selecionada pelo ID do usuário. Isso significa que quando você vê o usuário "Vasya" - ele vai para a partição 1. Quando você vê "Petya" - para particionar 2. Isso é conveniente - você pode conseguir que verá um consumidor em uma instância do seu serviço e o segundo - por outro.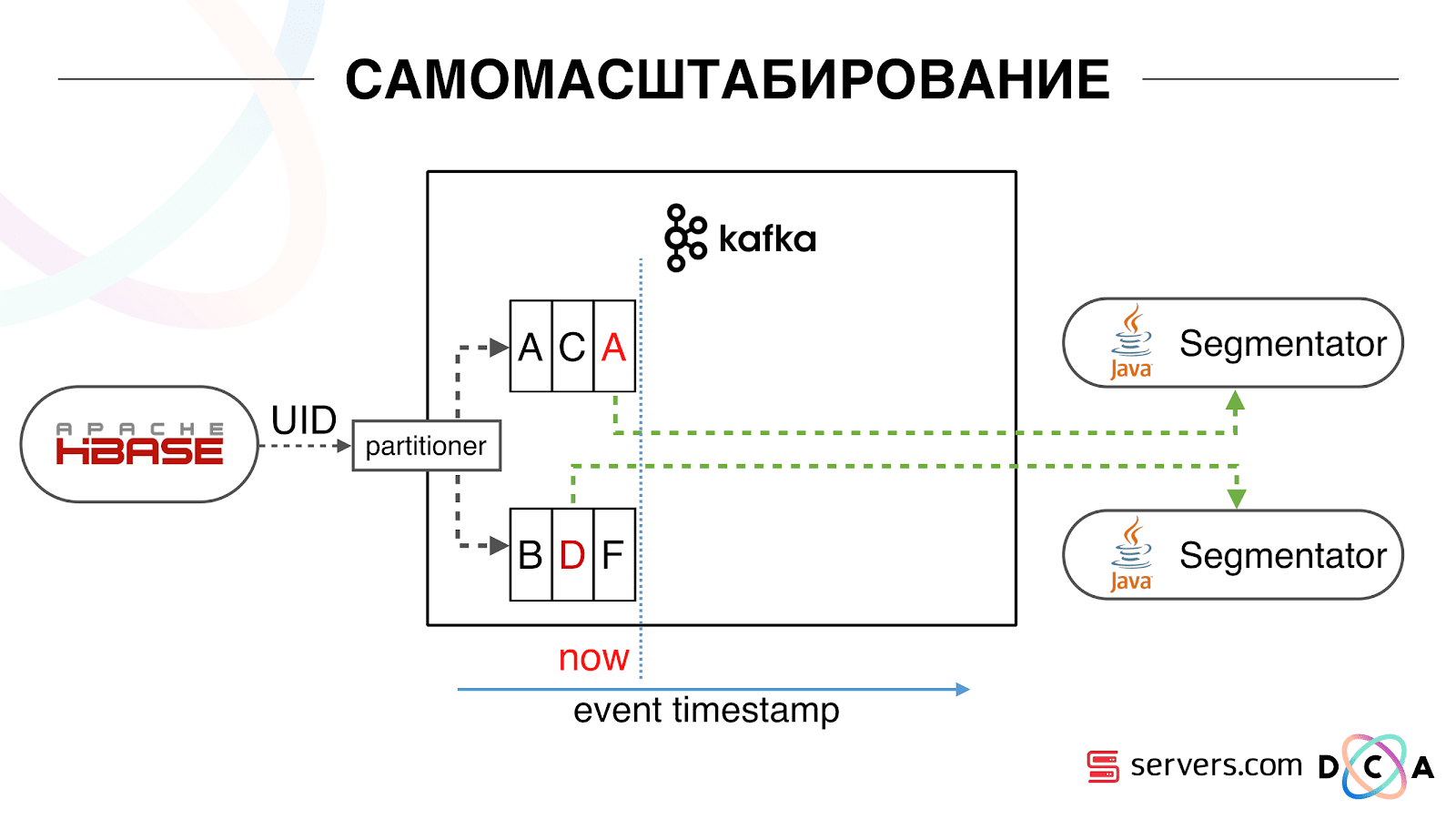 Começamos a assistir o que estava acontecendo. Um comportamento típico do usuário na Internet é acessar um site e abrir várias guias em segundo plano. O segundo é ir ao site e fazer alguns cliques para chegar à página de destino.Observamos a fila de segmentação e vemos o seguinte: O usuário A visitou a página. Mais 5 eventos vêm desse usuário - cada um significa uma abertura de página. Processamos cada evento do usuário. Mas, de fato, os dados no HBase contêm todas as 5 visitas. Processamos todas as 5 visitas pela primeira vez, pela segunda vez e assim por diante - estamos desperdiçando recursos da CPU.
Começamos a assistir o que estava acontecendo. Um comportamento típico do usuário na Internet é acessar um site e abrir várias guias em segundo plano. O segundo é ir ao site e fazer alguns cliques para chegar à página de destino.Observamos a fila de segmentação e vemos o seguinte: O usuário A visitou a página. Mais 5 eventos vêm desse usuário - cada um significa uma abertura de página. Processamos cada evento do usuário. Mas, de fato, os dados no HBase contêm todas as 5 visitas. Processamos todas as 5 visitas pela primeira vez, pela segunda vez e assim por diante - estamos desperdiçando recursos da CPU.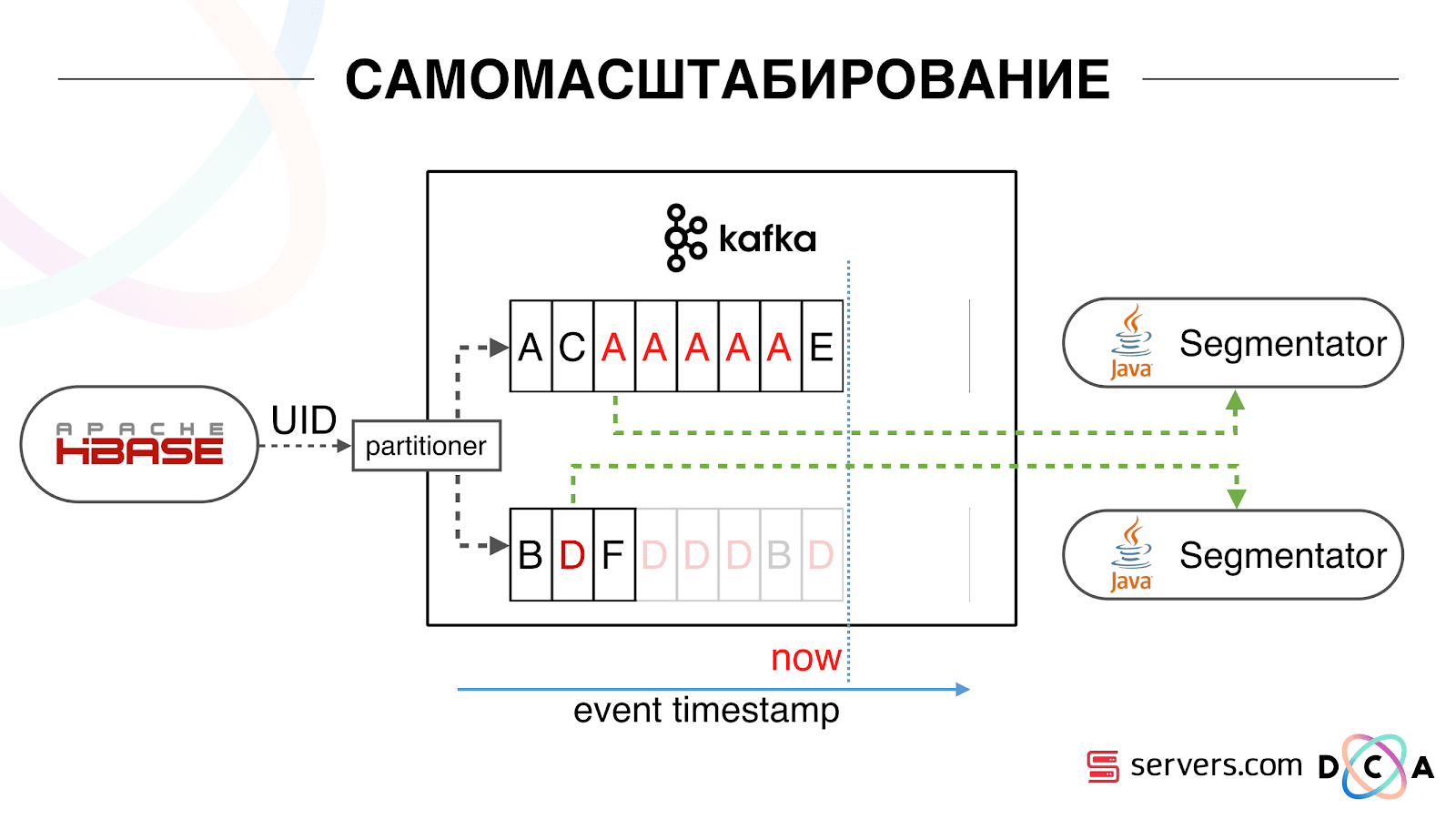 Portanto, começamos a armazenar um determinado cache local em cada um dos segmentadores com a data em que analisamos esse usuário pela última vez. Ou seja, nós processamos, escrevemos seu ID do usuário e carimbo de data e hora no cache. Cada mensagem kafka também possui um registro de data e hora - simplesmente a comparamos: se o registro de data e hora na fila for menor que a data da última segmentação - já analisamos o usuário para esses dados e você pode simplesmente pular esse evento.Os eventos do usuário (Vermelho A) podem ser diferentes e ficam fora de ordem. O usuário pode abrir várias guias em segundo plano, abrir vários links seguidos, talvez o site tenha vários de nossos parceiros ao mesmo tempo, cada um dos quais envia esses dados.Nosso pixel pode ver a visita do usuário e outras ações - enviaremos o capacete para nós. Chegam cinco eventos, estamos processando o primeiro A. vermelho. Se o evento chegou, ele já está no HBase. Vemos eventos, executamos um conjunto de scripts. Vemos o seguinte evento, e todos os mesmos eventos, porque eles já estão gravados. Nós o executamos novamente e salvamos o cache com a data, comparamos com o registro de data e hora do evento.
Portanto, começamos a armazenar um determinado cache local em cada um dos segmentadores com a data em que analisamos esse usuário pela última vez. Ou seja, nós processamos, escrevemos seu ID do usuário e carimbo de data e hora no cache. Cada mensagem kafka também possui um registro de data e hora - simplesmente a comparamos: se o registro de data e hora na fila for menor que a data da última segmentação - já analisamos o usuário para esses dados e você pode simplesmente pular esse evento.Os eventos do usuário (Vermelho A) podem ser diferentes e ficam fora de ordem. O usuário pode abrir várias guias em segundo plano, abrir vários links seguidos, talvez o site tenha vários de nossos parceiros ao mesmo tempo, cada um dos quais envia esses dados.Nosso pixel pode ver a visita do usuário e outras ações - enviaremos o capacete para nós. Chegam cinco eventos, estamos processando o primeiro A. vermelho. Se o evento chegou, ele já está no HBase. Vemos eventos, executamos um conjunto de scripts. Vemos o seguinte evento, e todos os mesmos eventos, porque eles já estão gravados. Nós o executamos novamente e salvamos o cache com a data, comparamos com o registro de data e hora do evento. Graças a isso, o sistema obteve a propriedade de auto-escalabilidade. O eixo y é a porcentagem do que fazemos com os IDs de usuário quando eles chegam até nós. Verde - o trabalho que realizamos, lançou o script de segmentação. Amarelo - não fizemos isso porque Já segmentou exatamente esses dados.
Graças a isso, o sistema obteve a propriedade de auto-escalabilidade. O eixo y é a porcentagem do que fazemos com os IDs de usuário quando eles chegam até nós. Verde - o trabalho que realizamos, lançou o script de segmentação. Amarelo - não fizemos isso porque Já segmentou exatamente esses dados.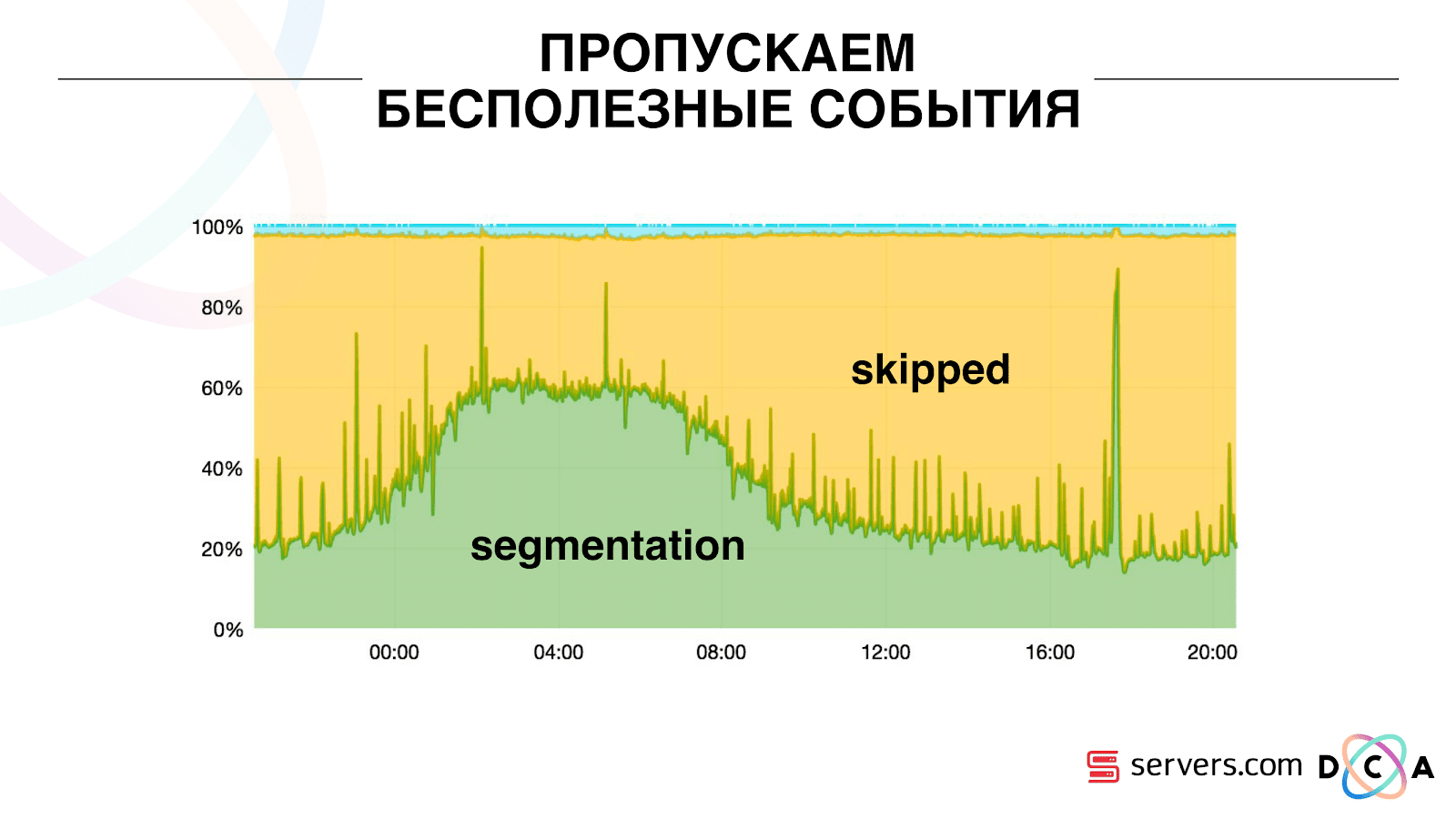 Pode-se observar que há recursos à noite, há menos fluxo de dados e você pode segmentar a cada segundo evento. Um dia de recursos menor, e segmentamos apenas 20% dos eventos. Um salto no final do dia - o parceiro fez o upload de arquivos de dados que não tínhamos visto antes e eles tiveram que ser "honestamente" segmentados.O próprio sistema se adapta ao crescimento de carga. Se temos um parceiro muito grande, processamos os mesmos dados, mas com um pouco menos de frequência. Nesse caso, as características do sistema se deteriorarão à noite, a segmentação será adiada não por 2-3 segundos, mas por um minuto. De manhã, adicione os servidores e retorne aos resultados desejados.Assim, economizamos cerca de 5 vezes nos servidores. Agora trabalhamos em 10 servidores e, portanto, levaria de 50 a 60.A coisinha azul no topo são os bots. Essa é a parte mais difícil da segmentação. Eles têm um grande número de visitas, eles criam uma carga muito grande no ferro. Vemos cada bot em um servidor separado. Podemos coletar nele um cache local com uma lista negra de bots. Introduziu um antifraude simples: se um usuário faz muitas visitas por um certo tempo, algo está errado com ele, adicionamos à lista negra por um tempo. Esta é uma pequena faixa azul, cerca de 5%. Eles nos deram mais 30% de economia na CPU.Assim, alcançamos o que vemos em todo o pipeline de processamento de dados em cada estágio. Vemos métricas de quanto a mensagem estava em Kafka. À noite, algo embotou em algum lugar, o tempo de processamento aumentou para um minuto, depois foi liberado e voltou ao normal.
Pode-se observar que há recursos à noite, há menos fluxo de dados e você pode segmentar a cada segundo evento. Um dia de recursos menor, e segmentamos apenas 20% dos eventos. Um salto no final do dia - o parceiro fez o upload de arquivos de dados que não tínhamos visto antes e eles tiveram que ser "honestamente" segmentados.O próprio sistema se adapta ao crescimento de carga. Se temos um parceiro muito grande, processamos os mesmos dados, mas com um pouco menos de frequência. Nesse caso, as características do sistema se deteriorarão à noite, a segmentação será adiada não por 2-3 segundos, mas por um minuto. De manhã, adicione os servidores e retorne aos resultados desejados.Assim, economizamos cerca de 5 vezes nos servidores. Agora trabalhamos em 10 servidores e, portanto, levaria de 50 a 60.A coisinha azul no topo são os bots. Essa é a parte mais difícil da segmentação. Eles têm um grande número de visitas, eles criam uma carga muito grande no ferro. Vemos cada bot em um servidor separado. Podemos coletar nele um cache local com uma lista negra de bots. Introduziu um antifraude simples: se um usuário faz muitas visitas por um certo tempo, algo está errado com ele, adicionamos à lista negra por um tempo. Esta é uma pequena faixa azul, cerca de 5%. Eles nos deram mais 30% de economia na CPU.Assim, alcançamos o que vemos em todo o pipeline de processamento de dados em cada estágio. Vemos métricas de quanto a mensagem estava em Kafka. À noite, algo embotou em algum lugar, o tempo de processamento aumentou para um minuto, depois foi liberado e voltou ao normal. Podemos monitorar como nossas ações com o sistema afetam sua taxa de transferência, podemos ver quanto o script está sendo executado, onde é necessário otimizar e quanto pode ser economizado. Podemos ver o tamanho dos segmentos, a dinâmica do tamanho dos segmentos, avaliar sua associação e interseção. Isso pode ser feito para mais ou menos os mesmos tamanhos de segmento.
Podemos monitorar como nossas ações com o sistema afetam sua taxa de transferência, podemos ver quanto o script está sendo executado, onde é necessário otimizar e quanto pode ser economizado. Podemos ver o tamanho dos segmentos, a dinâmica do tamanho dos segmentos, avaliar sua associação e interseção. Isso pode ser feito para mais ou menos os mesmos tamanhos de segmento.O que você gostaria de refinar?
Temos um cluster Hadoop com alguns recursos de computação. Ele está ocupado - os analistas trabalham durante o dia, mas à noite ele é praticamente livre. Em geral, podemos contêiner e executar o segmentador como um processo separado em nosso cluster. Queremos armazenar estatísticas com mais precisão para calcular com mais precisão o volume da interseção. Também precisamos de otimização na CPU. Isso afeta diretamente o custo da decisão.Resumindo: o Kafka é bom, mas, como qualquer outra tecnologia, você precisa entender como ele funciona por dentro e o que acontece com ele. Por exemplo, a garantia de prioridade da mensagem funciona apenas dentro da partição. Se você enviar uma mensagem que vá para diferentes partições, não está claro em que ordem elas serão processadas.Dados reais são muito importantes. Se não tivéssemos testado o tráfego real, provavelmente não teríamos problemas com bots, com sessões do usuário. Desenvolveria algo no vácuo, correria e se deitaria. É importante monitorar o que você considera necessário monitorar e não monitorar o que você não pensa.Minuto de publicidade. Se você gostou deste relatório da conferência SmartData, observe que o SmartData 2018 será realizado em São Petersburgo em 15 de outubro, uma conferência para aqueles que estão imersos no mundo do aprendizado de máquina, análise e processamento de dados. O programa terá muitas coisas interessantes, o site já tem seus primeiros oradores e relatórios.