Já está claro pelo nome que um navegador sem cabeça é algo sem cabeça. No contexto de um front-end, é uma ferramenta indispensável para um desenvolvedor, com a qual você pode testar o código, verificar a qualidade e a conformidade com o layout. Vitaliy Slobodin, do Frontend Conf, decidiu que era necessário conhecer o dispositivo dessa ferramenta mais de perto.
Sob os componentes e recursos de corte do Headless Chrome, cenários interessantes para o uso do Headless Chrome. A segunda parte sobre o Puppeteer é uma conveniente biblioteca Node.js. para gerenciar o modo sem cabeça no Google Chrome e Chromium.
Sobre o palestrante: Vitaliy Slobodin - um ex-desenvolvedor do PhantomJS - quem o fechou e o enterrou. Às vezes, ajuda o Konstantin Tokarev (
anulen ) na versão "ressuscitada" do QtWebKit - o próprio QtWebKit, onde há suporte para ES6, Flexbox e muitos outros padrões modernos.
Vitaliy adora explorar navegadores, pesquisar no WebKit, Chrome etc. em seu tempo livre e muito mais. Hoje falaremos sobre navegadores, ou seja, sobre navegadores sem cabeça e toda a sua família fantasma.
O que é um navegador sem cabeça?
Já pelo nome, está claro que isso é algo sem cabeça. Em um contexto de navegador, isso significa o seguinte.
- Não possui uma renderização real do conteúdo , ou seja, desenha tudo na memória.
- Devido a isso, consome menos memória , porque não há necessidade de desenhar imagens ou PNGs de gigabyte que as pessoas tentam colocar no back-end usando uma bomba.
- Ele funciona mais rápido porque não precisa renderizar nada na tela real.
- Possui uma interface de programação para gerenciamento . Você pergunta - ele não tem uma interface, botões, janelas? Como administrar isso? Portanto, é claro, ele tem uma interface para gerenciamento.
- Uma propriedade importante é a capacidade de instalar em um servidor Linux simples . Isso é necessário para que, se você tiver um Ubuntu ou Red Hat instalado recentemente, solte o binário ou coloque o pacote nele, e o navegador funcione imediatamente. Não é necessário xamanismo ou magia vodu.
Este é um navegador típico baseado no WebKit. Você não pode entender os componentes - esta é apenas uma imagem visual.

Estamos interessados apenas no componente principal da interface do navegador. Essa é a mesma interface do usuário - janelas, menus, notificações pop-up e tudo mais.

É assim que o navegador sem cabeça se parece. Percebe a diferença? Removemos completamente a interface do usuário. Ele não existe mais.
Somente o navegador permanece .
Hoje falaremos sobre o Headless Chrome (). Qual é a diferença entre eles? De fato, o Chrome é uma versão com marca do Chromium, que possui codecs proprietários, o mesmo H.264, integração com os serviços do Google e tudo mais. O Chromium é apenas uma implementação de código aberto.

Data de nascimento do Chrome sem cabeça: 2016. Se você se deparar com ele, poderá me fazer uma pergunta complicada: "Como assim, eu me lembro das notícias de 2017?" O fato é que uma equipe de engenheiros do Google entrou em contato com os desenvolvedores do PhantomJS em 2016, quando eles estavam apenas começando a implementar o modo Sem Cabeça no Chrome. Escrevemos o Google Docks inteiro, como implementaremos a interface e assim por diante. Então o Google queria tornar uma interface totalmente compatível com o PhantomJS. Foi só então que a equipe de engenheiros decidiu não fazer essa compatibilidade.
Falaremos sobre a interface de gerenciamento (API), que é o protocolo Chrome DevTools, mais tarde e veremos o que você pode fazer com ele.
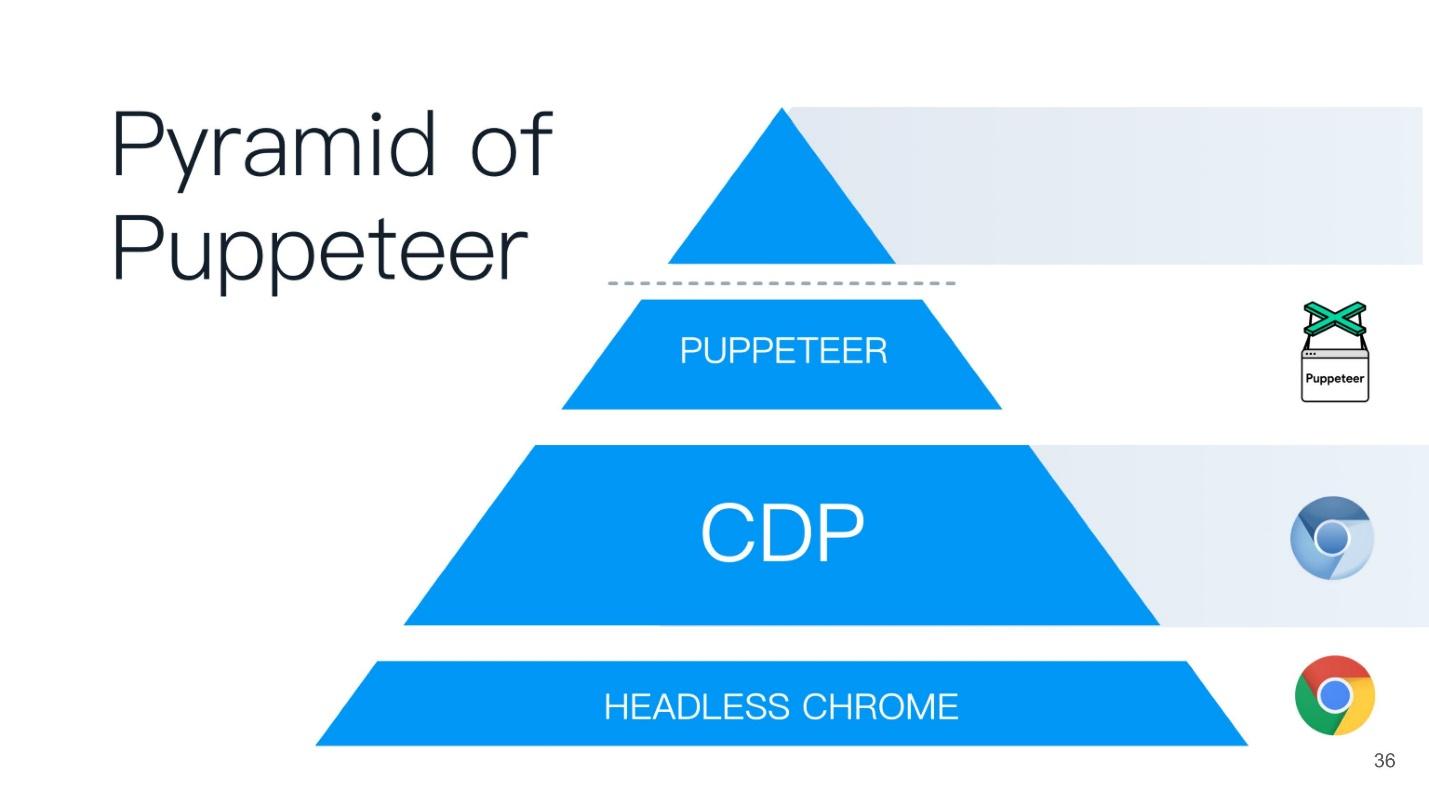
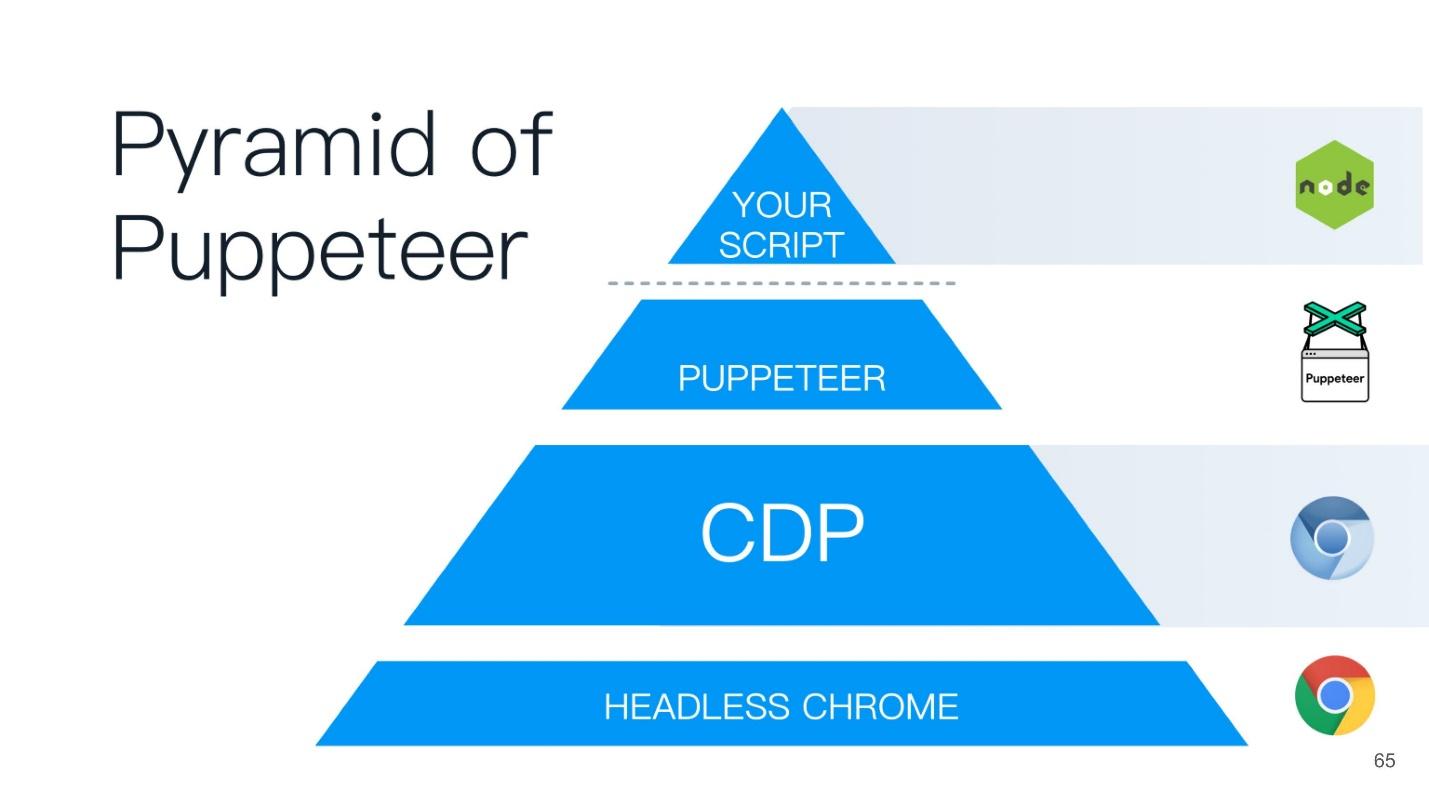
Este artigo será construído com base no princípio da pirâmide de marionetistas (do marionetista inglês). Um bom nome é escolhido - o marionetista é quem controla todos os outros!
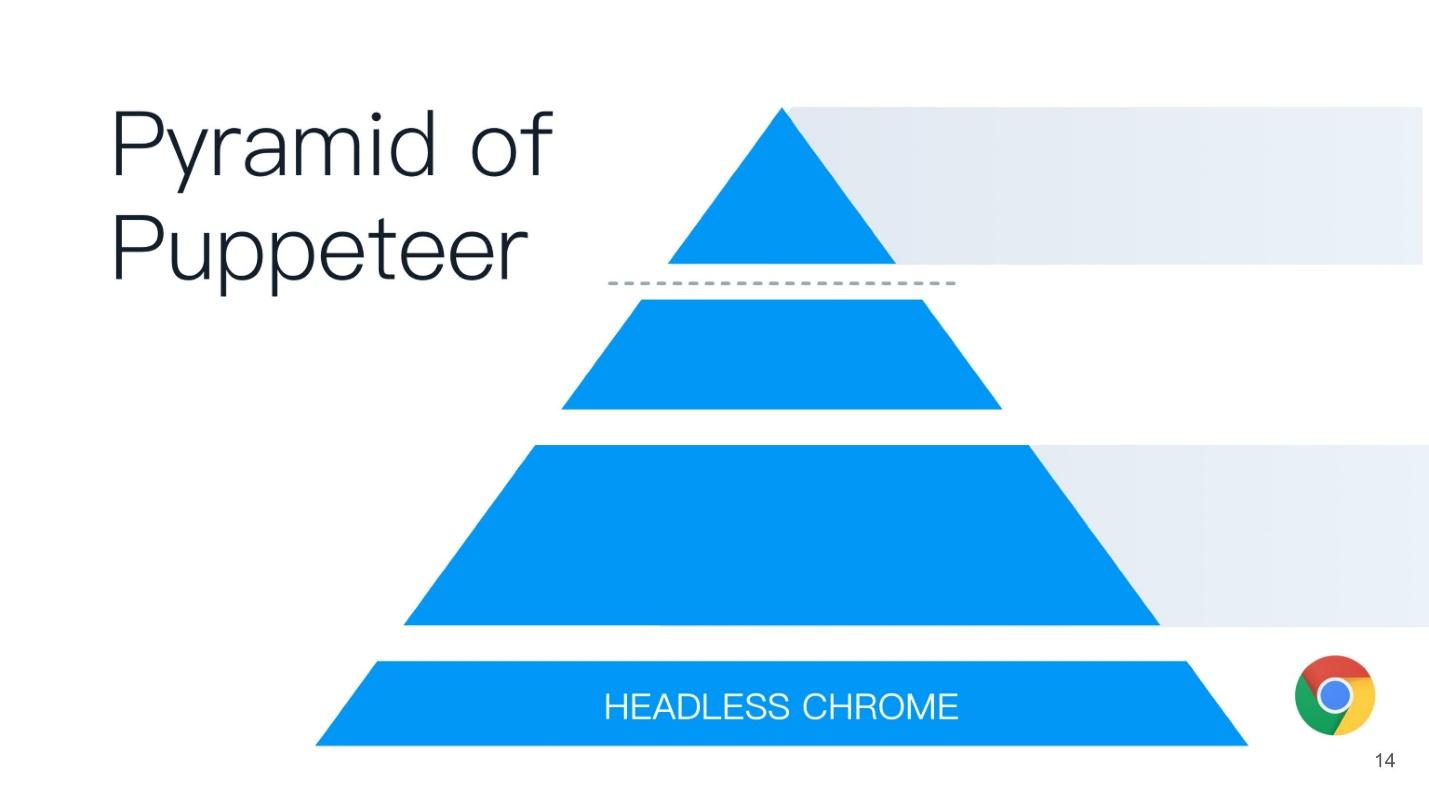
Na base da pirâmide está o Headless Chrome - Headless Chrome - o que é?
Cromo sem cabeça
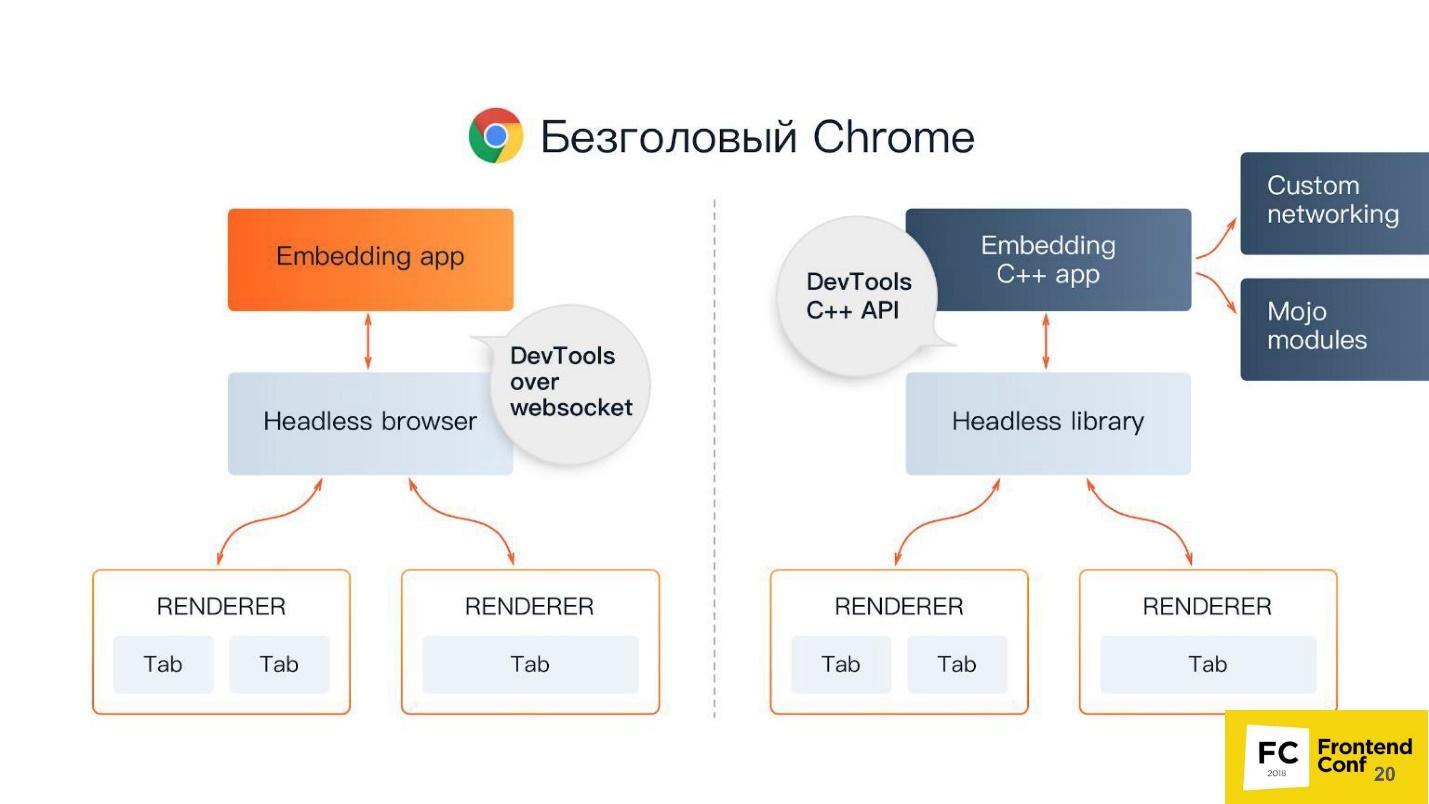
No centro - navegador sem cabeça - o mesmo Chromium ou Chrome (geralmente Chromium). Possui os chamados renderizadores (RENDERER) - processos que desenham o conteúdo da página (sua janela). Além disso, cada guia precisa de seu próprio renderizador; portanto, se você abrir muitas guias, o Chrome iniciará tantos processos para renderização.
Além disso, está sua aplicação. Se usarmos o Chromium ou o Headless Chrome, o Chrome estará em cima dele ou em algum aplicativo no qual você possa incorporá-lo. O analógico mais próximo pode ser chamado de Steam. Todo mundo sabe que, em essência, o Steam é apenas um navegador para o site do Steam. Ele, é claro, não é decapitado, mas semelhante a esse esquema.
Existem duas maneiras de incorporar o Chrome sem cabeça no seu aplicativo (ou usá-lo):
- Padrão quando você usa o Puppeteer e usa o Headless Chrome.
- Quando você pega o componente de biblioteca Sem Cabeça , ou seja, uma biblioteca que implementa o modo sem cabeça e o incorpora ao seu aplicativo, por exemplo, em C ++.
Você pode perguntar, por que o C ++ está no front end? A resposta é a API do DevTools C ++. Você pode implementar e usar os recursos do Chrome sem cabeça de diferentes maneiras. Se você usar o Puppeteer, a comunicação com um navegador sem cabeça será feita através de soquetes da web. Se você incorporar a biblioteca Headless em um aplicativo da área de trabalho, usará a interface nativa, escrita em C ++.
Mas, além de tudo isso, você ainda tem outras coisas, incluindo:
- Rede personalizada - implementação personalizada de interação com a rede. Suponha que você trabalhe em um banco ou em uma agência governamental que consista em três letras e comece com "F" e use um protocolo de autenticação ou autorização muito complicado, que não é suportado pelos navegadores. Portanto, você pode precisar de um manipulador personalizado para sua rede. Você pode simplesmente pegar sua biblioteca já implementada e usá-la no Chrome.
- Módulos Mojo . O análogo mais próximo do Mojo são os binders nativos no Node.js para as bibliotecas nativas escritas em C ++. O Mojo faz o mesmo - você pega sua biblioteca nativa, escreve uma interface Mojo para ela e pode chamar os métodos da sua biblioteca nativa no seu navegador.
Componentes de cromo
Novamente, ouço uma pergunta delicada: “Por que preciso desse esquema terrível? Escrevo em (insira o nome da sua estrutura favorita). ”
Eu acredito que um desenvolvedor deve saber como sua ferramenta funciona. Se você escreve em React, deve saber como o React funciona. Se você escreve em Angular, deve saber o que o Angular tem sob o capô.
Porque, no caso de algo, por exemplo, um erro fatal ou um bug muito sério na produção, você precisa lidar com a coragem e pode se perder por aí - onde, o que e como. Se você, por exemplo, escreve testes ou usa o Headless Chrome, também pode encontrar alguns de seus comportamentos e erros estranhos. Portanto, explicarei brevemente o que o Chromium possui componentes. Quando você vê um rastreamento de pilha grande, já sabe qual caminho cavar e como corrigi-lo.
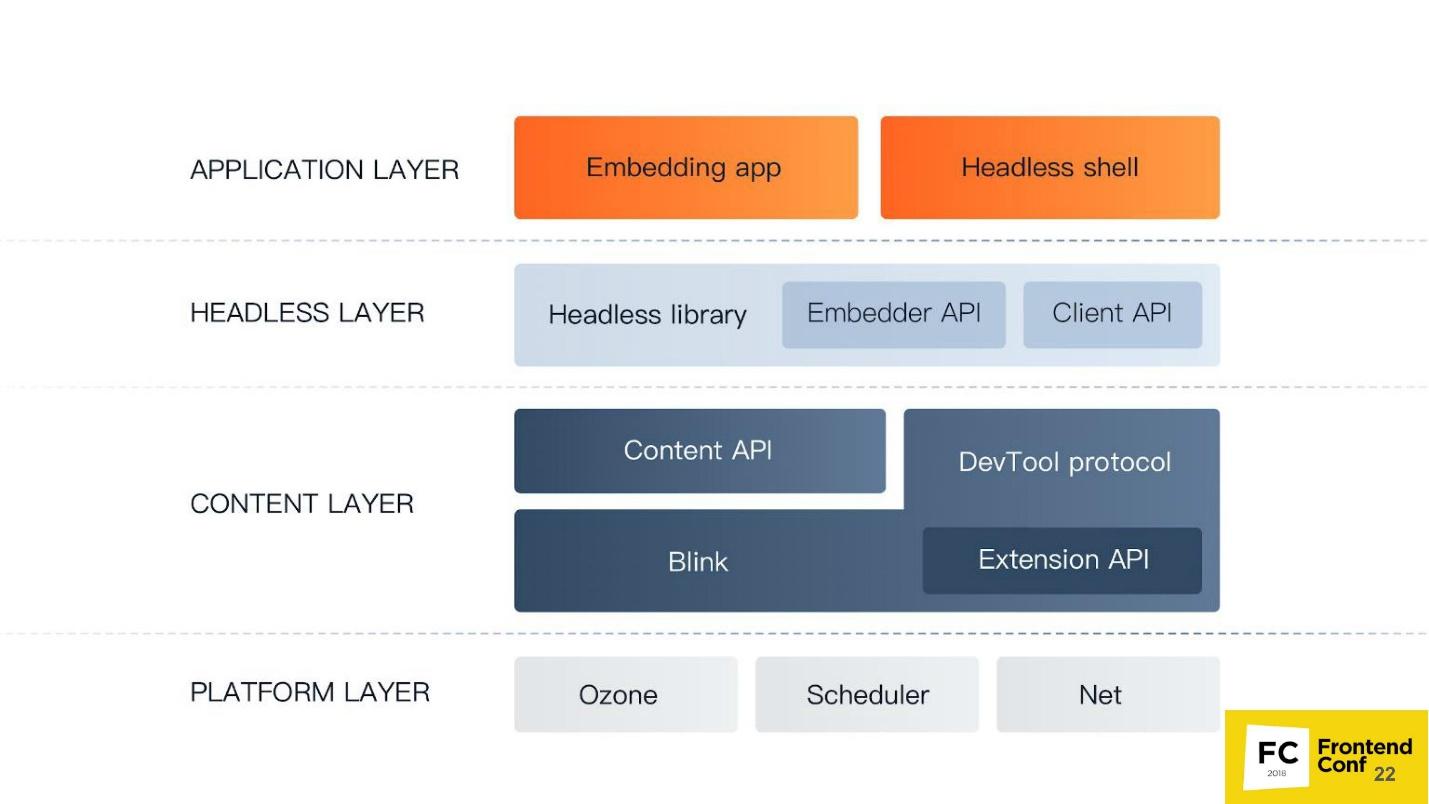
O nível mais baixo da
camada Plataforma . Seus componentes:
- Ozone , o gerenciador de janelas abstratas do Chrome, é o que interage com o gerenciador de janelas do sistema operacional. No Linux, é um servidor X ou Wayland. No Windows, é um gerenciador de janelas do Windows.
- O agendador é o mesmo agendador sem o qual não estamos em lugar algum, porque todos sabemos que o Chrome é um aplicativo com vários processos e precisamos resolver de alguma forma todos os threads, processos e tudo mais.
- Rede - o navegador sempre deve ter um componente para trabalhar com a rede, por exemplo, analisar HTTP, criar cabeçalhos, editar etc.
A
camada de conteúdo é o maior componente que o Chrome possui. Inclui:
- O Blink é um mecanismo da Web baseado no WebCore do WebKit. Pode levar HTML como uma string, analisar, executar JavaScript - e é isso. Ele não sabe mais fazer nada: nem trabalha com a rede nem desenha - tudo isso acontece em cima do Blink.
O Blink inclui: uma versão altamente modificada do WebCore - um mecanismo da web para trabalhar com HTML e CSS; V8 (mecanismo JavaScript); bem como uma API para todas as extensões que usamos no Chrome, como um bloqueador de anúncios. Ele também inclui o protocolo DevTools.
- A API de conteúdo é uma interface com a qual você pode facilmente usar todos os recursos do mecanismo da web. Como existem muitas coisas no Blink (provavelmente mais de um milhão de interfaces), para não se perder em todos esses métodos e funções, você precisa de uma API de conteúdo. Você digita HTML, o mecanismo o processa automaticamente, analisa o DOM, cria CSS OM, executa JavaScript, executa cronômetros, manipuladores e tudo mais.
Nível da
camada sem cabeça - nível do navegador sem cabeça:
- Biblioteca sem cabeça .
- Interface da API do incorporador para incorporar a biblioteca Headless no aplicativo.
- A API do cliente é uma interface que o Puppeteer usa.
Camada de aplicação Camada de aplicação :
- Sua aplicação ( aplicativo de incorporação );
- Gadgets, por exemplo, Shell sem cabeça .
Agora vamos subir das profundezas um pouco mais alto, ativar - agora o frontend irá.
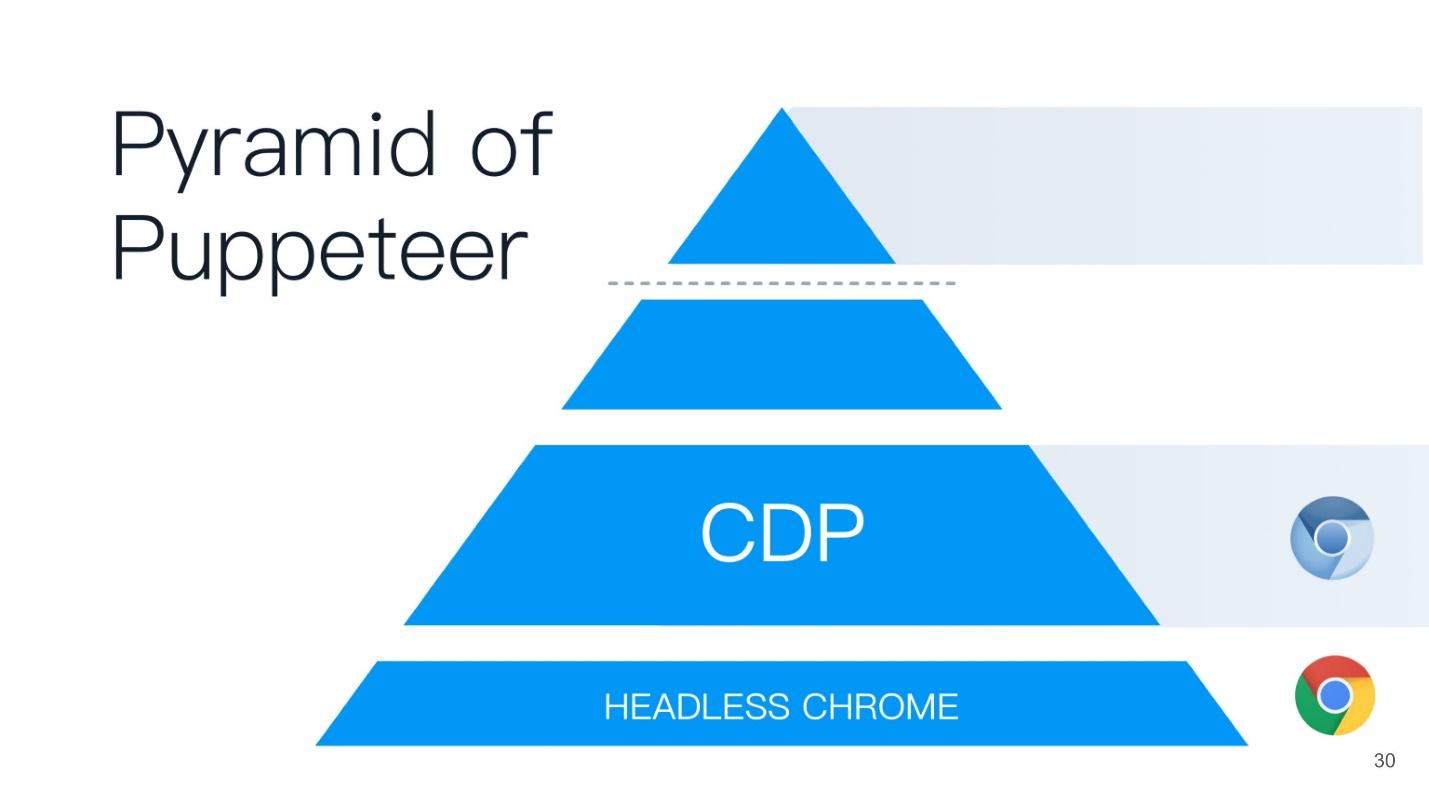
Protocolo Chrome DevTools
Todos nos deparamos com o protocolo Chrome DevTools, porque usamos o painel do desenvolvedor no Chrome ou o depurador remoto - as mesmas ferramentas de desenvolvimento. Se você executar as ferramentas do desenvolvedor remotamente, a comunicação com o navegador ocorrerá usando o protocolo DevTools. Ao instalar o depurador, veja a cobertura do código, use a localização geográfica ou algo mais - tudo isso é controlado usando o DevTools.
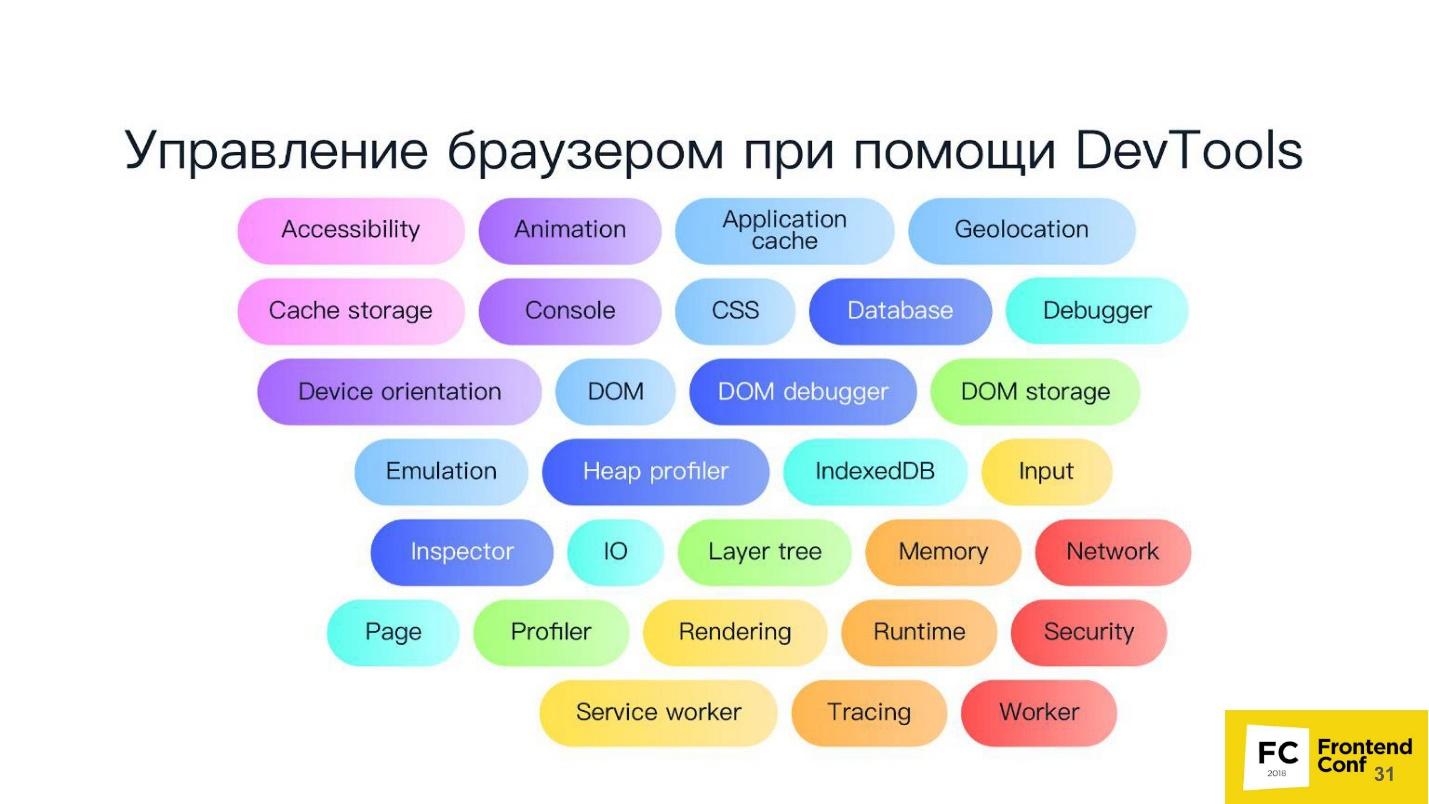
De fato, o próprio protocolo DevTools possui um grande número de métodos. Sua ferramenta de desenvolvedor não tem acesso, provavelmente a 80% deles. Realmente, você pode fazer tudo lá!
Vamos ver o que é esse protocolo. De fato, é muito simples. Possui 2 componentes:
- Destino do DevTools - a guia que você está inspecionando;
- Cliente do DevTools - digamos que este é um painel do desenvolvedor que é iniciado remotamente.

Eles se comunicam usando JSON simples:
- Há um identificador para o comando, o nome do método a ser executado e alguns parâmetros.
- Enviamos uma solicitação e obtemos uma resposta que também parece muito simples: um identificador necessário porque todos os comandos executados usando o protocolo são assíncronos. Para podermos sempre comparar qual resposta a qual equipe recebemos, precisamos de um identificador.
- Existe um resultado. No nosso caso, é um objeto de resultado com os seguintes atributos: tipo: "número", valor: 2, descrição: "2" , nenhuma exceção foi lançada: wasThrown: false.
Mas, entre outras coisas, sua guia pode enviar eventos de volta para você. Suponha que quando um evento em uma página ocorreu ou houve uma exceção em uma página, você receberá uma notificação através deste protocolo.

Marionetista
Você pode instalar o Puppeteer usando seu gerenciador de pacotes favorito - seja fio, npm ou qualquer outro.
Também é fácil usá-lo - basta solicitá-lo no seu script Node.js. Você já pode usá-lo.

Usando o link
https://try-puppeteer.appspot.com, você pode escrever um script diretamente no site, executá-lo e obter o resultado diretamente no navegador. Tudo isso será implementado usando o Chrome sem cabeça.
Considere o script mais simples em Node.js:
const puppeteer = require('puppeteer'); (async() => { const browser = await puppeteer.launch() ; const page = await browser.newPage(); await page.goto('http://devconf.ru/') ; await page.emulateMedia('screen') ; await page.pdf({ path: './devconf.pdf, printBackground: true }); await browser.close() ; })();
Aqui, basta abrir a página e imprimi-la em PDF. Vamos ver a operação desse script em tempo real:
Tudo ficará legal, mas não está claro o que está dentro. Obviamente, temos um navegador sem cabeça, mas não vemos nada. Portanto, o Puppeteer possui uma bandeira especial chamada headless: false:
const browser = await puppeteer.launch({ headless: false });
É necessário iniciar o navegador sem cabeçalho no modo completo, quando você pode ver alguma janela e ver o que acontece com a sua página em tempo real, ou seja, como o script interage com a sua página.
Isso parecerá o mesmo script quando adicionarmos esse sinalizador. Uma janela do navegador aparece à esquerda - mais claramente.
Profissionais do marionetista:+ Esta é a biblioteca Node.js. para o Chrome sem cabeça.
+ Suporte para versões herdadas do Node.js> = 6.
+ Fácil instalação.
+ API de alto nível para gerenciar toda essa máquina gigante.
O Chrome sem cabeça é instalado facilmente e sem intervenção do sistema. Na primeira instalação, o Puppeteer baixa a versão do Chromium e a instala diretamente na pasta node_modules especificamente para sua arquitetura e sistema operacional. Você não precisa baixar nada extra, ele faz isso automaticamente. Você também pode usar sua versão favorita do Chrome, instalada no seu sistema. Você também pode fazer isso - o Puppeteer fornece essa API.
Infelizmente, também existem desvantagens, se tomarmos apenas a instalação básica.
Contras Titereiro :
-
Sem funções de nível superior : sincronização de marcadores e senhas; suporte de perfil; aceleração de hardware etc.
-
Renderização de software é o menos significativo. Todos os cálculos e renderizações ocorrem na sua CPU. Mas aqui, os engenheiros do Google nos surpreenderão em breve - o trabalho de implementação da aceleração de hardware já está em andamento. Agora você pode tentar usá-lo se for corajoso e corajoso.
- Até recentemente, não havia suporte para extensões - agora existe! Se você é um desenvolvedor astuto, pode usar seu AdBlock favorito, especificar como o Puppeteer o usará e todos os anúncios serão bloqueados.
-
Sem suporte de áudio / vídeo . Porque, bem, por que áudio e vídeo em navegadores sem cabeça?
O que pode Puppeteer:- Sessões de isolamento.
- Temporizadores virtuais.
- Interceptação de solicitações de rede.
E algumas coisas legais que vou mostrar um pouco mais.
Isolamento da sessão
O que é, o que é comido e não vamos sufocar? - Não engasgue!
O isolamento da sessão é um
"repositório" separado para cada guia . Ao iniciar o Puppeteer, você pode criar uma nova página e cada nova página pode ter seu próprio repositório, incluindo:
- cozinheiros
- armazenamento local;
- cache.
Todas as páginas viverão independentemente uma da outra. Isso é necessário, por exemplo, para manter a atomicidade dos testes.
O isolamento da sessão
economiza recursos e tempo ao iniciar sessões paralelas . Suponha que você esteja testando um site que está sendo construído no modo de desenvolvimento, ou seja, o pacote configurável não é minimizado e pesa 20 MB. Se você quiser apenas armazená-lo em cache, pode pedir ao Puppeteer para usar um cache comum a todas as páginas criadas, e esse pacote será armazenado em cache.
Você pode
serializar sessões para uso posterior . Você escreve um teste que verifica uma determinada ação no seu site. Mas você tem um problema - o site requer autorização. Você não adicionará constantemente antes em cada teste para autorização no site. O Puppeteer permite que você faça login no site uma vez e depois reutilize esta sessão no futuro.
Temporizadores virtuais
Você já pode estar usando temporizadores virtuais. Se você moveu o controle deslizante em uma ferramenta de desenvolvedor que acelera ou desacelera a animação (e lava as mãos depois disso, é claro!), Nesse momento você usava temporizadores virtuais no navegador.
O navegador pode usar temporizadores virtuais em vez de reais para
"rolar" o tempo a frente para acelerar o carregamento da página ou concluir a animação. Suponha que você tenha o mesmo teste, vá para a página principal e a animação por 30 segundos. Não é benéfico para alguém esperar o teste todo esse tempo. Portanto, você pode simplesmente acelerar a animação para que ela seja concluída instantaneamente quando a página carregar, e seu teste continuará.
Você pode
parar o tempo enquanto a solicitação de rede estiver em execução . Por exemplo, você testa a reação do seu aplicativo para quando uma solicitação enviada para o back-end demora muito tempo para ser executada ou retorna com um erro. Você pode parar o tempo - o Puppeteer permite.
No slide abaixo, há outra opção:
parar e continuar o renderizador. No modo experimental, foi possível dizer ao navegador para não renderizar e, posteriormente, se necessário, solicitar uma captura de tela. O Chrome decapitado renderizaria tudo rapidamente, faria uma captura de tela e deixaria de desenhar qualquer coisa. Infelizmente, os desenvolvedores já conseguiram alterar o princípio de funcionamento desta API e não existe mais essa função.
Uma visão esquemática dos cronômetros virtuais abaixo.
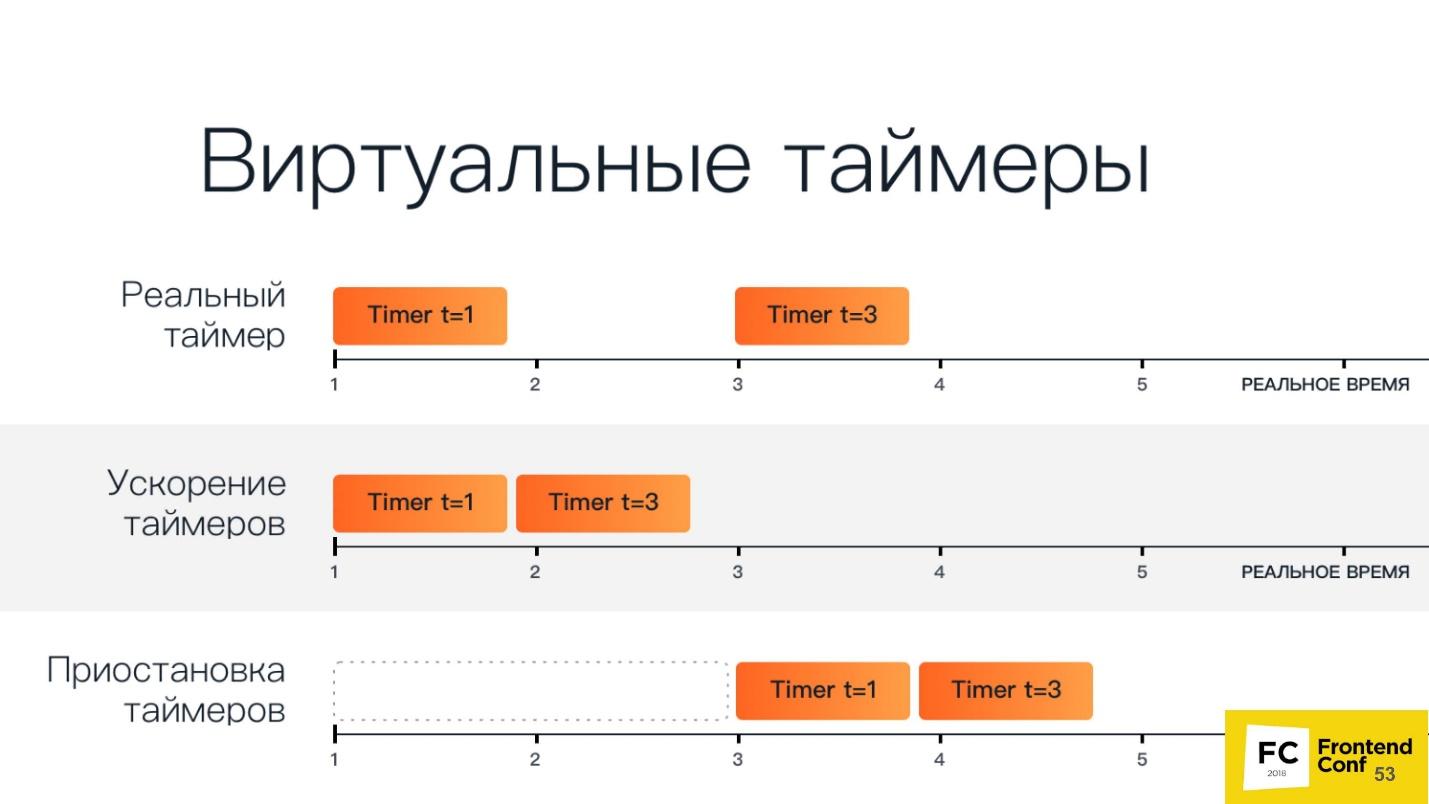
A linha superior possui dois cronômetros regulares: o primeiro inicia na primeira unidade de tempo e é executado em uma unidade de tempo, o segundo começa na terceira unidade de tempo e é executado em três unidades de tempo.
Acelerando os temporizadores - eles começam um após o outro. Quando os pausamos, temos um período de tempo após o qual todos os temporizadores são iniciados.
Considere isso como um exemplo. Abaixo está um trecho de código que basicamente carrega a página de animação do codepen.io e aguarda:
(async() => { const browser = await puppeteer.launch(); const page = await browser.newPage(); const url = 'https ://codepen.o/ajerez/full/EaEEOW/';
Esta demonstração de implementação durante a apresentação é apenas animação.
Agora, usando o protocolo Chrome DevTools, enviaremos um método chamado Animation.setPlaybackRate, passaremos a playbackRate com um valor de 12 como parâmetros:
const url = 'https://codepen.o/ajerez/full/EaEEOW/';
Carregamos o mesmo link e o animashka começou a trabalhar muito mais rápido. Isso se deve ao fato de termos usado um timer virtual e acelerado a reprodução da animação em 12 vezes.
Vamos fazer um experimento agora - passe playbackRate: 0 - e veja o que acontece. E aqui vai ser isso: não há animação alguma, ela não toca. Valores zero e negativos simplesmente pausam toda a animação completamente.
Trabalhar com solicitações de rede
Você pode
interceptar solicitações de rede , definindo o seguinte sinalizador:
await page.setRequestlnterception(true);
Nesse modo, aparece um evento adicional que é acionado quando uma solicitação de rede é enviada ou recebida.
Você pode
alterar a solicitação rapidamente . Isso significa que você pode alterar completamente todo o seu conteúdo (corpo) e seus cabeçalhos, inspecionar e até cancelar a solicitação.
Isso é necessário para
processar a autorização ou autenticação , incluindo autenticação básica via HTTP.
Você também pode fazer a
cobertura do
código (JS / CSS) . Com o Puppeteer, você pode automatizar tudo isso. Todos conhecemos utilitários que podem carregar uma página, mostrar quais classes são usadas nela, etc. Mas estamos satisfeitos com eles? Eu acho que não.
O navegador sabe melhor quais seletores e classes são usados - é um navegador! Ele sempre sabe qual JavaScript foi executado, qual não, qual CSS é usado e qual não.
O protocolo Chrome DevTools vem em socorro:
await Promise.all ( [ page.coverage.startJSCoverage(), page.coverage.startCSSCoverage() ]); await page.goto('https://example.com'); const [jsCoverage, cssCoverage] = await Promise,all([ page.coverage.stopJSCoverage(), page.coverage.stopCSSCoverage() ]):
Nas duas primeiras linhas, lançamos um recurso relativamente novo que permite descobrir a cobertura do código. Execute JS e CSS, vá para alguma página e diga - pare - e podemos ver os resultados. E esses não são alguns resultados imaginários, mas aqueles que o navegador vê devido ao mecanismo.
Entre outras coisas, já existe um plugin que para Puppeteer exporta tudo para Istambul.
No topo da pirâmide de marionetistas, há um script que você escreveu no Node.js - é como o padrinho de todos os pontos mais importantes.
Mas ... "nem tudo está calmo no reino dinamarquês ..." - como William Shakespeare escreveu.
O que há de errado com navegadores sem cabeça?
Os navegadores sem cabeça têm problemas, embora todos os seus recursos interessantes possam fazer muito.
Diferença na renderização da página em diferentes plataformas
Eu realmente amo esse item e falo constantemente sobre ele. Vamos olhar para esta foto.

Aqui está uma página comum com texto simples: à direita - renderização no Chrome no Linux, à esquerda - no Windows. Aqueles que testam com capturas de tela sabem que um valor é sempre definido, chamado de “margem de erro”, que determina quando a captura de tela é considerada idêntica e quando não.
De fato, o problema é que, não importa como você tente definir esse limite, o erro sempre ultrapassará essa linha e você ainda receberá resultados falsos positivos. Isso se deve ao fato de que todas as páginas e até fontes da Web são renderizadas de maneira diferente nas três plataformas - no Windows de acordo com um algoritmo, no MacOS de maneira diferente, no Linux em geral, em um zoológico.
Você não pode simplesmente tirar e testar com capturas de tela .
Você dirá: "Eu só preciso de uma máquina de referência onde eu execute todos esses testes e compare as capturas de tela". Mas, na verdade, isso é extremamente inconveniente, porque você precisa aguardar o IC e deseja verificar aqui localmente na sua máquina se quebrou alguma coisa. Se você tiver capturas de tela de referência tiradas em uma máquina Linux e tiver um Mac, haverá resultados falsos.
Portanto, eu digo que não teste com screenshots - esqueça.
A propósito, se você ainda deseja testar com capturas de tela, há um maravilhoso artigo de Roman Dvornov, “
Teste de unidade com capturas de tela: quebrando a barreira do som ”. Isso é pura ficção policial.
Fechaduras
Muitos grandes provedores de conteúdo não gostam quando você raspa ou obtém o conteúdo de maneira ilegal. Imagine que eu sou um grande provedor de conteúdo e quero jogar o mesmo jogo com você. Existem duas solicitações GET em dois navegadores diferentes.
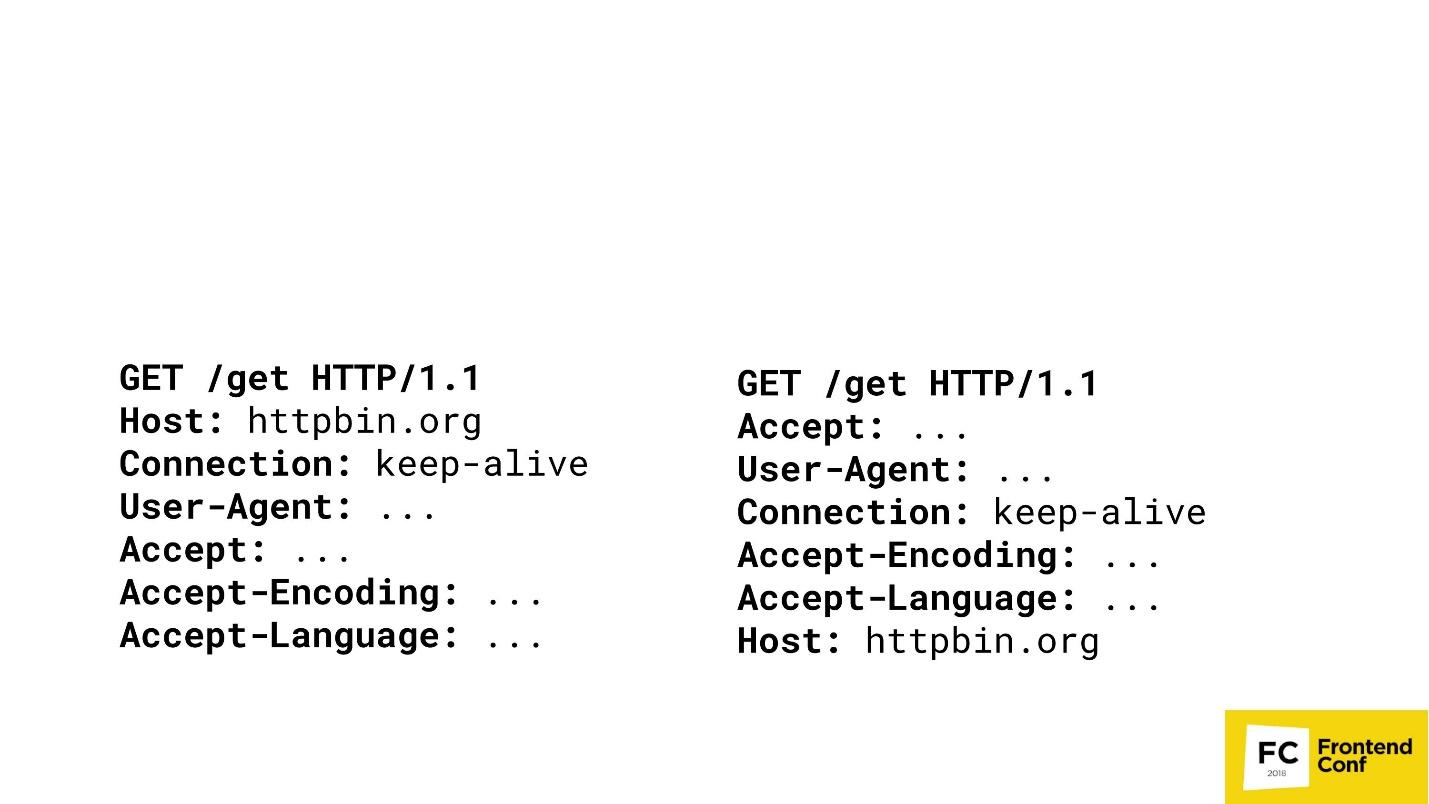
Você consegue adivinhar onde está o Chrome? A opção "both" não é aceita - o Chrome é apenas um. Provavelmente, você não conseguirá responder a essa pergunta e eu, como principal fornecedor de conteúdo, posso: à direita - PhantomJS e à esquerda - Chrome.

Posso chegar ao ponto em que detectarei seus navegadores (o que exatamente é o Chrome ou o FireFox), correspondendo à ordem dos cabeçalhos HTTP em suas solicitações. Se o host for o primeiro - eu sei claramente - esse é o Chrome. Então eu não posso comparar. Sim, é claro, existem algoritmos mais complexos - verificamos não apenas a ordem, mas também os valores, etc. etc. Mas é importante que eu possa lançar seus cabeçalhos, verificar quem você é e depois apenas bloquear ou não.
Não foi possível implementar alguns recursos (Flash)
Você já estudou em profundidade, diretamente hardcore, Flash em navegadores? De alguma forma, procurei - e não dormi por seis meses.
Todos nos lembramos de como costumávamos assistir ao YouTube quando ainda havia o Flash: o vídeo está girando, está tudo bem. Porém, no momento em que um objeto incorporado é criado em uma página como o Flash, ele sempre solicita uma janela real do seu sistema operacional. Ou seja, além da janela do navegador, havia outra janela do seu sistema operacional dentro da janela do Flash do YouTube. O Flash não funciona, a menos que você forneça uma janela real - não apenas uma janela real, mas uma janela visível na tela. Portanto, algumas funções não podem ser implementadas em navegadores sem cabeça, incluindo o Flash.
Automação completa e bots
Como eu disse anteriormente, grandes provedores de conteúdo têm muito medo quando você escreve aranhas ou pegadas que simplesmente roubam informações fornecidas por uma taxa.
Vários truques são usados. Existem artigos sobre como ainda detectar navegadores sem cabeça. Posso dizer que
você não poderá detectar navegadores sem cabeça . Todos os métodos descritos lá são ignorados. Por exemplo, havia métodos de detecção usando o Canvas. Lembro que havia até um script que assistiu o mouse se mover pela tela e encheu a tela. Somos pessoas e movemos o mouse lentamente, e o Headless Chrome é muito mais rápido. O script entendeu que o Canvas é preenchido muito rapidamente - o que significa que provavelmente é o Chrome sem cabeça. Também contornamos isso, apenas desacelerar o navegador não é um problema.
Não há API (única) padrão
Se você assistiu a implementações decapitadas em outros navegadores - seja Safari ou FireFox -, tudo é implementado usando a API do driver da web. O Chrome possui o protocolo Chrome DevTools. No Edge, nada está claro - o que está lá, o que não está.
WebGL?
As pessoas também pedem o WebGL no modo sem cabeça. Este
link permite acessar o rastreador de erros do Google Chrome. Lá, os desenvolvedores estão votando ativamente na implementação do modo sem cabeça para o WebGL, e ele já pode desenhar algo. Agora eles são simplesmente restringidos pela renderização de hardware. Assim que a implementação da renderização do hardware for concluída, o WebGL estará automaticamente disponível, ou seja, algo poderá ser feito em segundo plano.
Mas nem tudo é tão ruim!
Temos um segundo player no mercado - em 11 de maio de 2018, havia
notícias de que a Microsoft em seu navegador Edge decidiu implementar quase o mesmo protocolo usado no Google Chrome. Eles criaram um consórcio especialmente onde estão discutindo um protocolo que desejam trazer para um padrão do setor, para que você possa pegar seu script e executá-lo no Edge, Chrome e FireFox.
Mas existe um "mas" - o Microsoft Edge não possui um modo sem cabeça, infelizmente. Eles têm uma cédula de votação onde as pessoas escrevem: "Dê-nos um modo sem cabeça!" - mas eles estão calados. Provavelmente vendo algo em segredo.
TODO (conclusão)
Eu contei tudo isso para que você possa procurar seu gerente ou, se você é gerente, o desenvolvedor e dizer: “É isso!
Não queremos mais o selênio - dê-nos marionetista! Vamos testar nele. " Se isso acontecer, ficarei feliz.
Mas se você puder aprender, como eu, navegadores usando o Puppeteer, postar bugs ativamente ou enviar uma solicitação de recebimento, ficarei feliz ainda mais. Essa
ferramenta no OpenSource encontra-se no GitHub, está escrita no Node.js - você pode simplesmente pedir emprestado e contribuir com ele.
O caso do Puppeteer é único, pois existem duas equipes trabalhando no Google: uma lida especificamente com o Puppeteer, a outra com o modo sem cabeça. Se um usuário encontrar um bug e escrever sobre ele no GitHub, se esse bug não estiver no Puppeteer, mas no Headless Chrome, o bug irá para o comando Headless Chrome. Se eles o corrigirem, o Puppeteer é atualizado rapidamente. Isso resulta em um único ecossistema quando a comunidade ajuda a melhorar o navegador.
Portanto, peço que você ajude a melhorar a ferramenta, usada não apenas por você, mas também por outros desenvolvedores e testadores.
Detalhes de contato:
- github.com/vitallium
- vk.com/vitallium
- twitter.com/vitalliumm
Frontend Conf Moscow - uma conferência especializada de desenvolvedores front-end será realizada nos dias 4 e 5 de outubro em Moscou , na Infospace. Uma lista de relatórios aceitos já foi publicada no site da conferência.
Em nosso boletim informativo, fazemos regularmente revisões temáticas de discursos, conversamos sobre as transcrições lançadas e os eventos futuros - inscreva-se para receber as notícias primeiro.
E este é um link para o nosso canal do Youtube no front end, contém todos os discursos relacionados ao desenvolvimento da parte do cliente dos projetos.