Em um
artigo anterior, prometi revelar com mais detalhes alguns detalhes que omiti durante a investigação [o Gmail trava no Chrome no Windows - aprox. Por.], Incluindo tabelas de páginas, bloqueios, WMI e o erro vmmap. Agora preencho essas lacunas junto com exemplos de código atualizados. Mas primeiro, esboce brevemente a essência.
O ponto foi que um processo que oferece suporte ao
Control Flow Guard (CFG) aloca memória executável, além de alocar memória CFG que o Windows nunca libera. Portanto, se você continuar alocando e liberando memória executável
em endereços diferentes , o processo acumulará uma quantidade arbitrária de memória CFG. O navegador Chrome faz isso, o que leva a um vazamento de memória quase ilimitado e congela em algumas máquinas.
Deve-se observar que é difícil evitar congelamentos se o VirtualAlloc começar a executar mais de um milhão de vezes mais devagar que o normal.
Além do CFG, há outra memória desperdiçada, embora não seja tanto quanto o vmmap afirma.
CFG e páginas
A memória do programa e a memória CFG são finalmente alocadas com páginas de 4 kilobytes (mais sobre isso posteriormente). Como 4 KB de memória CFG podem descrever 256 KB de memória de programa (mais sobre isso mais tarde), isso significa que, se você selecionar um bloco de memória de 256 KB alinhado com 256 KB, receberá uma página CFG de 4 KB. E se você alocar um bloco executável de 4 KB, ainda receberá uma página CFG de 4 KB, mas a maior parte não será usada.
Tudo fica mais complicado se a memória executável for liberada. Se você usar a função VirtualFree em um bloco de memória executável que não seja múltiplo de 256 KB ou não esteja alinhado em 256 KB, o sistema operacional deverá realizar algumas análises e verificar se alguma outra memória executável não usa uma página CFG. Os autores do CFG decidiram não se incomodar - e simplesmente deixaram para sempre a memória CFG alocada. É muito lamentável. Isso significa que, quando meu programa de teste aloca e libera 1 gigabyte de memória executável alinhada, ele deixa 16 MB de memória CFG.
Na prática, verifica-se que, quando o mecanismo JavaScript do Chrome aloca e libera 128 MB de memória executável alinhada (nem toda ela foi usada, mas todo o intervalo foi alocado e liberado imediatamente), até 2 MB de memória CFG permanecerão alocados, embora seja trivial liberá-lo completamente . Como o Chrome aloca e libera repetidamente a memória em endereços aleatórios, isso leva ao problema descrito acima.
Memória perdida adicional
Em qualquer sistema operacional moderno, cada processo obtém seu próprio espaço de endereço de memória virtual, para que o sistema operacional isole processos e proteja a memória. Isso é feito usando
uma unidade de gerenciamento de memória (MMU) e
tabelas de páginas . A memória é dividida em páginas de 4 KB. Essa é a quantidade mínima de memória que o sistema operacional fornece. Cada página é indicada por um registro de oito bytes na tabela de páginas e os próprios registros são armazenados em páginas de 4 KB. Cada um deles aponta para um máximo de 512 páginas diferentes de memória, portanto, precisamos de uma hierarquia de tabelas de páginas. Para um espaço de endereço de 48 bits em um sistema operacional de 64 bits, o sistema é o seguinte:
- Uma tabela de nível 1 cobre 256 TB (48 bits), apontando para 512 tabelas diferentes de nível 2 de página
- Cada tabela de nível 2 abrange 512 GB, apontando para 512 tabelas de nível 3
- Cada tabela do nível 3 abrange 1 GB, apontando para 512 tabelas do nível 4
- Cada tabela do nível 4 abrange 2 MB, apontando para 512 páginas físicas
A MMU indexa a tabela do 1º nível nos primeiros 9 (de 48) bits do endereço, as tabelas do 2º nível nos próximos 9 bits e os demais níveis recebem 9 bits, ou seja, apenas 36 bits. Os 12 bits restantes são usados para indexar páginas de 4 kilobytes de uma tabela de 4º nível. Bem, bem.
Se você preencher imediatamente todos os níveis das tabelas, precisará de mais de 512 GB de RAM, para que eles sejam preenchidos conforme necessário. Isso significa que, ao alocar uma página de memória, o sistema operacional seleciona algumas tabelas de páginas - de zero a três, dependendo se os endereços alocados estão em uma área não utilizada anteriormente de 2 MB, uma área não utilizada anteriormente de 1 GB ou uma área não utilizada anteriormente de 512 GB (tabela de páginas de nível 1 sempre se destaca).
Em resumo, alocar para endereços aleatórios é muito mais caro do que alocar para endereços próximos, pois, no primeiro caso, as tabelas de páginas não podem ser compartilhadas. Os vazamentos de CFG são raros; portanto, quando o
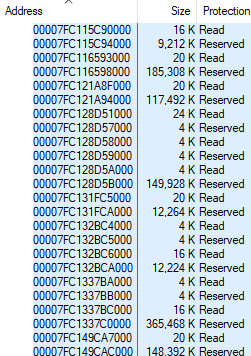
vmmap mostrou
412.480 KB de tabelas de páginas usadas no Chrome, presumi que os números estavam corretos. Aqui está uma captura de tela do vmmap com o layout de memória chrome.exe do artigo anterior, mas com a linha Tabela da página:
Mas algo parecia errado. Decidi adicionar um simulador de tabela de páginas à minha ferramenta
VirtualScan . Ele calcula quantas páginas de tabelas de páginas são necessárias para toda a memória alocada durante o processo de digitalização. Você só precisa digitalizar a memória alocada, adicionando ao contador um número múltiplo de 2 MB, 1 GB ou 512 GB.
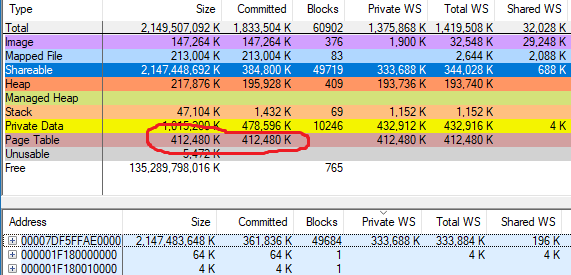
Foi rapidamente descoberto que os resultados do simulador correspondem ao vmmap em processos normais, mas não em processos com uma grande quantidade de memória CFG. A diferença corresponde aproximadamente à memória CFG alocada. Para o processo acima, em que o vmmap fala sobre 402,8 MB (412.480 KB) de tabelas de páginas, minha ferramenta mostra 67,7 MB.
Tempo de verificação, confirmado, tabelas de páginas, blocos confirmados
Total: 41.763s, 1457,7 MiB, 67,7 MiB, 32112, 98 blocos de código
CFG: 41.759s, 353,3 MiB, 59,2 MiB, 24866
Verifiquei o erro do
vmmap executando o
VAllocStress , que nas configurações padrão faz com que o Windows aloque 2 gigabytes de memória CFG. O vmmap alegou ter alocado 2 gigabytes de tabelas de páginas:
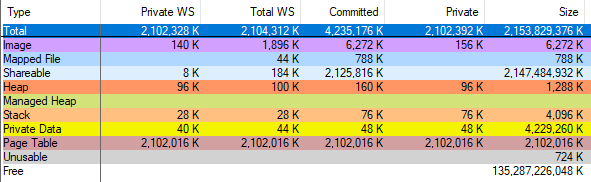
E quando concluí o processo por meio do Gerenciador de tarefas, o vmmap mostrou que a quantidade de memória alocada diminuía em apenas 2 gigabytes. Portanto, o vmmap está errado, meus cálculos com tabelas de páginas estão corretos e, após uma
discussão proveitosa
no Twitter, enviei um relatório sobre o erro do vmmap, que deve ser corrigido. A memória CFG ainda consome muitas entradas da tabela de páginas (59,2 MB no exemplo acima), mas não tanto quanto o vmmap diz, e depois de corrigi-la não consumirá nada.
O que são CFG e CFG?
Eu quero voltar um pouco e dizer com mais detalhes o que é CFG.
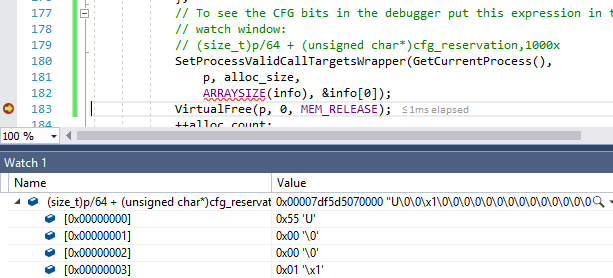
CFG significa Control Flow Guard. Este é um método de proteção contra explorações, reescrevendo ponteiros de função. Com o CFG ativado, o compilador e o SO juntos verificam a validade do destino da ramificação. Primeiro, o byte de controle CFG correspondente é carregado a partir da área CFG reservada de 2 TB. O processo de 64 bits no Windows gerencia o espaço de endereço de 128 TB, portanto, dividir o endereço por 64 permite encontrar o byte CFG correspondente para esse objeto.
uint8_t cfg_byte = cfg_base[size_t(target_addr) / 64];Agora, temos um byte que deve descrever quais endereços no intervalo de 64 bytes são destinos de ramificação válidos. Para fazer isso, o CFG trata o byte como quatro valores de dois bits, cada um dos quais corresponde a um intervalo de 16 bytes. Esse número de dois bits (cujo valor é de zero a três) é
interpretado da seguinte maneira :
- 0 - todos os destinos neste bloco de 16 bytes são destinos inválidos de ramificações indiretas
- 1 - o endereço inicial neste bloco de 16 bytes é o destino válido da ramificação indireta
- 2 - associado a chamadas CFG "suprimidas" ; endereço potencialmente inválido
- 3 - endereços não alinhados neste bloco de 16 bytes são destinos válidos de uma ramificação indireta, no entanto, um endereço alinhado de 16 bytes é potencialmente inválido
Se o destino da ramificação indireta for inválido, o processo será encerrado e a exploração será impedida. Viva!
A partir disso, podemos concluir que, para segurança máxima, os objetivos indiretos da ramificação devem ser alinhados por 16 bytes e podemos entender por que a memória CFG do processo é aproximadamente 1/64 da memória do programa.
Na verdade, o CFG carrega 32 bits por vez, mas esses são detalhes de implementação. Muitas fontes descrevem a memória CFG como um bit de 8 bytes em vez de um bit de 16 bytes. Minha explicação é melhor.
É por isso que tudo está ruim
O Gmail trava por dois motivos. Primeiro, a digitalização da memória CFG no Windows 10 16299 ou anterior é muito lenta. Vi como a varredura do espaço de endereçamento de um processo leva 40 segundos ou mais e, literalmente, 99,99% desse tempo, a memória reservada do CFG é varrida, embora represente apenas 75% dos blocos de memória fixos. Não sei por que a verificação foi tão lenta, mas eles a corrigiram no Windows 10 17134, por isso não faz sentido estudar o problema com mais detalhes.
A verificação lenta causou uma desaceleração porque o Gmail queria redundância de CFG e o WMI reteve o bloqueio durante a verificação. Mas o bloqueio de reserva de memória não foi mantido durante a verificação. No meu exemplo, existem aproximadamente 49.000 blocos na área CFG, e a função
NtQueryVirtualMemory , que recebe e libera o bloqueio, foi chamada uma vez para cada um deles. Portanto, o bloqueio foi obtido e liberado ~ 49.000 vezes e cada vez foi mantido por menos de 1 milissegundo.
Mas, embora o bloqueio tenha sido liberado 49.000 vezes, o processo do Chrome, por algum motivo, não foi possível. Isso é injusto!
Essa é a essência do problema. Como escrevi da última vez:
Isso ocorre porque os bloqueios do Windows são inerentemente injustos - e se o thread libera o bloqueio e o solicita imediatamente novamente, ele pode ser recuperado para sempre.
Bloqueio justo significa que dois segmentos concorrentes o receberão por sua vez. Mas isso significa muitas opções de contexto caras, portanto, por um longo tempo, o bloqueio não será usado.

Bloqueios injustos são mais baratos e não fazem com que os threads fiquem na fila. Eles apenas capturam a fechadura, como mencionado no
artigo de Joe Duffy . Ele também escreve:
A introdução de fechaduras injustas pode indubitavelmente levar à fome. Mas, estatisticamente, o tempo em sistemas paralelos tende a ser tão variável que cada thread recebe uma virada para execução, do ponto de vista probabilístico.
Como correlacionar a afirmação de Joe de 2006 sobre a raridade da fome com a minha experiência em um problema 100% repetido e de longo prazo? Eu acho que o principal motivo foi o que aconteceu em 2006. A Intel
lançou o Core Duo , e os computadores com vários núcleos são onipresentes.
Afinal, acontece que esse problema de fome ocorre apenas em um sistema multinúcleo! Nesse sistema, o thread WMI libera a trava, sinaliza o thread do Chrome para ativar e continua. Como o fluxo WMI já está em execução, ele possui um “handicap” na frente do fluxo do Chrome, para que possa chamar facilmente o
NtQueryVirtualMemory novamente e recuperar o bloqueio antes que o Chrome possa fazer isso.
Obviamente, em um sistema de núcleo único, apenas um encadeamento pode funcionar por vez. Como regra, o Windows aumenta a prioridade de um novo encadeamento, e aumentar a prioridade significa que, quando o bloqueio for liberado, o novo encadeamento do Chrome estará pronto e imediatamente avançará no encadeamento WMI. Isso dá ao thread do Chrome muito tempo para acordar e bloquear, e a fome nunca chega.
Você entende? Em um sistema com vários núcleos, na maioria dos casos, um aumento de prioridade não afeta o fluxo WMI, pois será executado em um kernel diferente!
Isso significa que um sistema com núcleos adicionais pode
responder mais lentamente do que um sistema com a mesma carga de trabalho e menos núcleos. Outra conclusão é curiosa: se meu computador tiver uma carga pesada - threads com a prioridade correspondente, trabalhando em todos os núcleos do processador -, travamentos poderão ser evitados (não tente repetir isso em casa).
Assim,
bloqueios injustos aumentam a produtividade, mas podem levar à fome. Suspeito que a solução possa ser o que chamo de bloqueios "às vezes justos". Digamos, 99% das vezes elas serão injustas, mas em 1% a trava para outro processo. Isso preservará os benefícios da produtividade com mais, evitando o problema da fome. Anteriormente, os bloqueios do Windows eram distribuídos de maneira justa e você provavelmente pode retornar parcialmente a esse problema, encontrando o equilíbrio perfeito. Isenção de responsabilidade: eu não sou especialista em bloqueios ou engenheiro de SO, mas estou interessado em ouvir pensamentos sobre isso e, pelo menos, não sou
o primeiro a oferecer algo assim .
Linus Torvalds recentemente apreciou a importância das fechaduras justas:
aqui e
aqui . Talvez seja hora de mudar também no Windows.
Para resumir : O bloqueio por alguns segundos não é bom, limita a simultaneidade. Porém, em sistemas com vários núcleos com bloqueios injustos, a remoção e o recebimento imediato do bloqueio se comportam
exatamente dessa maneira - outros threads não têm como funcionar.
Quase uma falha no ETW
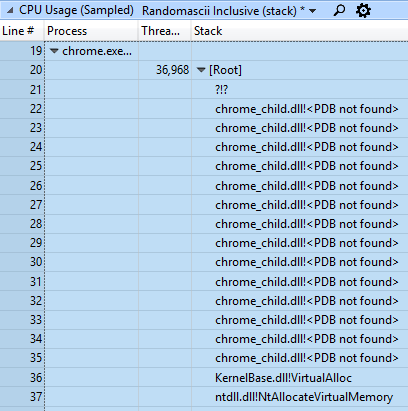
Para toda essa pesquisa, contei com o rastreamento ETW, por isso fiquei um pouco assustado ao descobrir, no início da investigação, que o Windows Performance Analyzer (WPA) não podia carregar caracteres do Chrome. Estou certo de que, literalmente, na semana passada tudo deu certo. O que aconteceu ...
Aconteceu que o Chrome M68 saiu e foi vinculado usando o lld-link em vez do vinculador VC ++. Se você executar o
dumpbin e examinar as informações de depuração, verá:
C:\b\c\b\win64_clang\src\out\Release_x64\./initialexe/chrome.exe.pdbBem, provavelmente o WPA não gosta dessas barras. Mas ainda não faz sentido, porque mudei o vinculador para lld-link e lembro que testei o WPA antes disso, então o que aconteceu ...
Aconteceu que o motivo estava na nova versão WPA 17134. Testei o layout lld-Link - e funcionou bem no WPA 16299. Que coincidência! O novo vinculador e o novo WPA não eram compatíveis.
Instalei a versão antiga do WPA para continuar a investigação (xcopy de uma máquina com a versão antiga) e relatei um
bug do lld-link , que os desenvolvedores rapidamente corrigiram. Agora você pode retornar ao WPA 17134 quando o M69 é montado com um vinculador fixo.
Wmi
O gatilho de congelamento da WMI é um
snap-in da Instrumentação de Gerenciamento do Windows e eu não sou bom nisso. Descobri que em
2014 ou mais cedo, alguém enfrentou o problema do uso significativo da CPU no
WmiPrvSE.exe no
perfproc! GetProcessVaData , mas não forneceu informações suficientes para entender as causas do bug. Em algum momento, cometi um erro e tentei descobrir que solicitação WMI maluca poderia travar o Gmail por alguns segundos. Conectei
alguns especialistas à investigação e passei muito tempo tentando encontrar essa consulta mágica.
Registrei a atividade Microsoft-Windows-WMI-Activity em rastreamentos ETW, experimentei o PowerShell para encontrar todas as solicitações de Win32_Perf e me perdi em mais algumas maneiras indiretas que são muito chatas para discutir. No final, descobri que um travamento do Gmail causou esse contador,
Win32_PerfRawData_PerfProc_ProcessAddressSpace_Costly , acionado por um PowerShell de linha única:
measure-command {Get-WmiObject -Query “SELECT * FROM Win32_PerfFormattedData_PerfProc_ProcessAddressSpace_Costly”}
Fiquei
ainda mais confuso por causa do nome do balcão ("querido"? Sério?) E porque esse contador aparece e desaparece com base em fatores que eu não entendo.
Mas os detalhes do WMI não importam. O WMI não fez nada de errado - na verdade - apenas examinou a memória. Escrever seu próprio código de verificação acabou sendo muito mais útil na investigação do problema.
Hassle for Microsoft
Chrome lançou um patch, o resto é para a Microsoft.
Acelere a digitalização da região CFG - OK, está pronto- Libere memória CFG quando a memória executável é liberada - pelo menos no caso do alinhamento de 256K, é fácil
- Considere um sinalizador que permita alocar memória executável sem memória CFG ou use PAGE_TARGETS_INVALID para esse fim. Observe que o manual Windows Internals Part 1 7th Edition diz que “você deve selecionar páginas [CFG] com pelo menos um conjunto de bits {1, X}” - se o Windows 10 implementar isso, o sinalizador PAGE_TARGETS_INVALID ( atualmente usado pelo mecanismo v8 ) evitará alocação de memória
- Corrija o cálculo das tabelas de páginas no vmmap para processos com um grande número de alocações de CFG
Atualizações de código
Atualizei os
exemplos de código , especialmente o VAllocStress. Existem 20 linhas incluídas para demonstrar como encontrar uma reserva CFG para um processo. Também adicionei código de teste que usa
SetProcessValidCallTargets para verificar o valor dos bits CFG e demonstrar os truques necessários para chamá-los com êxito (dica: chamar via GetProcAddress provavelmente levará à violação do CFG!)