Olá colegas.
Acabamos de traduzir um livro interessante de Brendan Burns, que fala sobre padrões de design para sistemas distribuídos

Além disso, a tradução do livro "
Mastering Kubernetes " (2ª edição) já está em pleno andamento e o livro do autor sobre o Docker está prestes a ser publicado em setembro, e haverá um post separado sobre ele.
Acreditamos que a próxima parada nesse caminho seja um livro sobre Prometheus; hoje, chamamos a atenção para a tradução de um pequeno artigo de Björn Wenzel sobre a estreita interação entre Prometheus e Kubernetes. Lembre-se de participar da pesquisa.
O monitoramento do cluster Kubernetes é um negócio muito importante. O cluster contém muitas informações que permitem responder a perguntas da categoria: quanta memória e espaço em disco estão disponíveis agora, como a CPU é usada ativamente? Qual contêiner consome quantos recursos? Isso também inclui perguntas sobre o status dos aplicativos em execução no cluster.
Uma das ferramentas realizadas para esse trabalho é chamada Prometheus. É suportado pela Cloud Native Computing Foundation, originalmente Prometheus foi desenvolvido pela SoundCloud. Conceitualmente, Prometheus é muito simples:
Arquitetura
O servidor Prometheus pode funcionar, por exemplo, em um cluster Kubernetes e receber a configuração por meio de um arquivo especial. Essa configuração, em particular, contém informações sobre a localização do terminal a partir da qual coletar dados após o intervalo especificado. Em seguida, o servidor Prometheus solicita métricas desses terminais em um formato especial (geralmente estão disponíveis em
/metrics ) e as armazena em um banco de dados de séries temporais. A seguir, um breve exemplo: um pequeno arquivo de configuração solicitando métricas de um módulo
node_exporter implementado como um agente em cada nó:
scrape_configs: - job_name: "node_exporter" scrape_interval: "15s" target_groups: - targets: ['<ip>:9100']
Primeiro, definimos o nome da tarefa
job_name ; posteriormente, esse nome pode ser usado para solicitar métricas no Prometheus, depois o
scrape_interval dados
scrape_interval e o grupo de servidores executando o
node_exporter . Agora, o Prometheus solicitará ao servidor o
path /metrics para as métricas atuais. Parece algo como isto:
Primeiro, o nome da métrica é fornecido, depois a assinatura (informações entre chaves) e, finalmente, o valor da métrica. O mais interessante é a função de pesquisa para essas métricas. O Prometheus possui uma
linguagem de consulta muito poderosa para esse fim.
A principal idéia do Prometheus, já descrita acima, é a seguinte: Prometheus, em um determinado intervalo, pesquisa métricas na porta e as armazena em um banco de dados de séries temporais. Se o Prometheus não puder remover as métricas, haverá outra funcionalidade chamada pushgateway. O gateway pushgateway aceita métricas enviadas por trabalhos externos e o Prometheus coleta informações desse gateway em um intervalo especificado.
Outro componente opcional da arquitetura do Prometheus é o
alertmanager . O componente
alertmanager permite definir limites e, em caso de excedê-los, enviar notificações por e-mail, folga ou opsgenie.
Além disso, o servidor Prometheus contém muitos
recursos integrados , por exemplo, pode solicitar instâncias ec2 na API da Amazon ou solicitar pods, nós e serviços do Kubernetes. Também possui muitos
exportadores , por exemplo, o
node_exporter mencionado acima. Esses exportadores podem trabalhar, por exemplo, no nó em que um aplicativo como o MySQL está instalado e em um intervalo especificado para pesquisar métricas no aplicativo e fornecê-las no terminal / métricas, e o servidor Prometheus pode coletar essas métricas a partir daí.
Além disso, não é difícil escrever seu próprio exportador - por exemplo, para um aplicativo que fornece métricas como informações da jvm. Por exemplo, existe uma
biblioteca desenvolvida pela Prometheus para exportar essas métricas. Essa biblioteca pode ser usada em conjunto com o Spring e também permite definir suas próprias métricas. Aqui está um exemplo da página
client_java :
@Controller public class MyController { @RequestMapping("/") @PrometheusTimeMethod(name = "my_controller_path_duration_seconds", help = "Some helpful info here") public Object handleMain() {
Essa é uma métrica que descreve a duração do método, e agora outras métricas podem ser fornecidas através do terminal ou empurradas pelo pushgateway.
Uso no cluster Kubernetes
Como mencionei, para usar o Prometheus no cluster Kubernetes, existem recursos integrados para remover informações do coração, nó e serviço. O mais interessante é que o Kubernetes foi especialmente projetado para trabalhar com o Prometheus. Por exemplo, o
kubelet e o
kube-apiserver fornecem métricas
kube-apiserver no Prometheus; portanto, o monitoramento é muito simples.
Neste exemplo, para iniciantes, eu uso o gráfico oficial de leme.
Para mim, alterei um pouco a configuração do gráfico de leme padrão. Primeiro, eu precisava ativar o
rbac na instalação do Prometheus, caso contrário, o Prometheus não conseguiu coletar informações do
kube-apiserver . Portanto, escrevi meu próprio arquivo values.yaml, que descreve como o gráfico helm deve ser exibido.
Fiz as alterações mais simples:
alertmanager.enabled: false , ou seja, cancelou a implantação do alertmanager no cluster (eu não usaria o alertmanager, acho mais fácil configurar alertas com o Grafana)kubeStateMetrics.enabled: false Acho que essas métricas retornam apenas algumas informações sobre o número máximo de lareiras. Quando você inicia o sistema, essas informações não são importantes para mimserver.persistentVolume.enabled: false até que eu tenha um volume persistente configurado por padrão- Alterei a configuração da coleta de informações no Prometheus, como foi feito na solicitação pull no github . O fato é que, no Kubernetes v1.7, as métricas do cAdvisor funcionam em uma porta diferente.
Depois disso, você pode iniciar o Prometheus usando o helm:
helm install stable/prometheus --name prometheus-monitoring -f prometheus-values.yamlEntão, instalamos o servidor Prometheus e, em cada nó - instale em node_exporter. Agora você pode acessar a GUI da web do Prometheus e ver algumas informações:
kubectl port-forward <prometheus-server-pod> 9090A captura de tela a seguir mostra para quais finalidades o Prometheus coleta informações (Status / destinos) e quando as informações foram gravadas várias vezes na última:
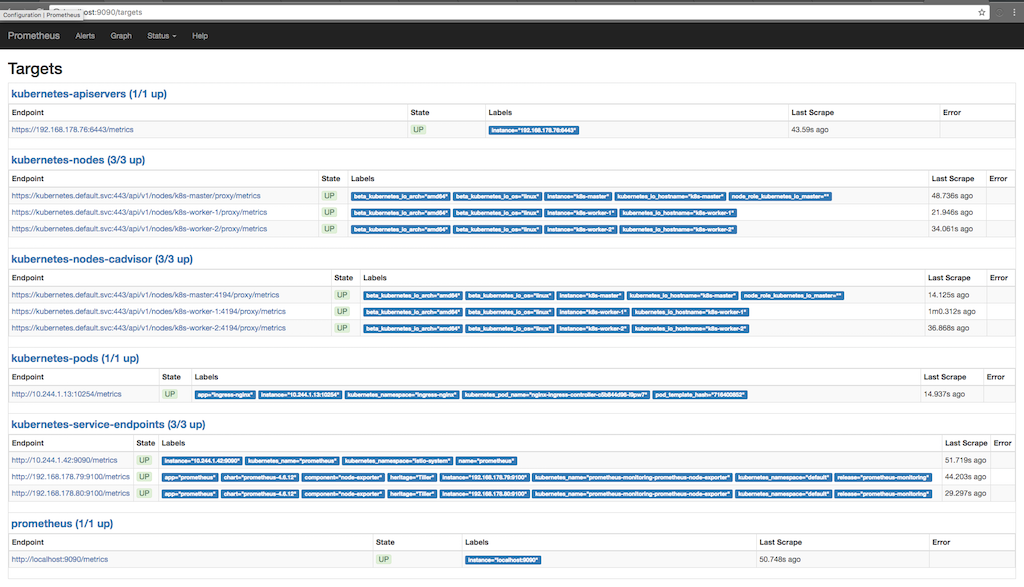
Aqui você pode ver como o Prometheus está solicitando métricas de apiserver, nós, um cadvisor executado em nós e terminais de serviço do kubernetes. Você pode ver as métricas em detalhes acessando o Graph e escrevendo uma consulta para visualizar as informações em que estamos interessados:

Aqui, por exemplo, vemos armazenamento gratuito no ponto de montagem “/”. Na parte inferior do diagrama, são adicionadas assinaturas adicionadas pelo Prometheus ou já disponíveis no node_exporter. Usamos essas assinaturas para solicitar apenas o ponto de montagem “/”.
Métricas personalizadas com anotações
Como já mostrado na primeira captura de tela, onde são derivadas as metas para as quais o Prometheus está solicitando métricas, também há uma métrica para a lareira que trabalha no cluster. Um dos recursos interessantes do Prometheus é a capacidade de obter informações de lareiras inteiras. Se o contêiner na lareira fornecer métricas do Prometheus, poderemos coletar essas métricas usando o Prometheus automaticamente. A única coisa que precisamos cuidar é fornecer à instalação duas anotações; no meu caso, o
nginx-ingress-controller faz isso imediatamente:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-ingress-controller namespace: ingress-nginx spec: replicas: 1 selector: matchLabels: app: ingress-nginx template: metadata: labels: app: ingress-nginx annotations: prometheus.io/port: '10254' prometheus.io/scrape: 'true' ...
Aqui vemos que o modelo de implantação vem com duas anotações do Prometheus. O primeiro descreve a porta através da qual o Prometheus deve solicitar métricas e o segundo ativa a funcionalidade de coleta de dados. Agora, o Prometheus solicita os
Kubernetes Api-Server anotados para coletar informações e tenta coletar informações do terminal / métricas.
Trabalho Federado
Temos um projeto no qual o Prometheus é usado em um modo federado. A idéia é a seguinte: coletamos apenas as informações acessíveis apenas dentro do cluster (ou é mais fácil coletá-las dentro do cluster), ativamos o modo federado e obtemos essas informações usando o segundo Prometheus instalado fora do cluster. Assim, é possível coletar informações de vários clusters do Kubernetes de uma só vez, capturando também outros componentes que não são acessíveis a partir desse cluster ou não estão relacionados a ele. Além disso, não é necessário armazenar os dados coletados no cluster por um longo tempo e, se algo der errado com o cluster, podemos coletar algumas informações, por exemplo, node_exporter, de fora do cluster.