Olá Habr! Hoje eu quero falar sobre como o aprendizado profundo nos ajuda a entender melhor a arte. O artigo é dividido em partes de acordo com as tarefas que resolvemos:
- procure uma foto no banco de dados a partir de uma fotografia tirada por um telefone celular;
- determinação do estilo e gênero de uma imagem que não está no banco de dados.
Tudo isso passou a fazer parte do serviço de banco de dados Arthive e de seus aplicativos móveis.
A tarefa de identificar as pinturas era encontrar a imagem correspondente da imagem proveniente do aplicativo móvel no banco de dados, gastando menos de um segundo nisso. O processamento inteiramente no dispositivo móvel foi excluído na fase de estudo pré-design. Além disso, descobriu-se que é impossível realizar com segurança em um dispositivo móvel a separação da imagem do fundo em condições reais de fotografia. Portanto, decidimos que nosso serviço aceitará a foto inteira do celular como uma entrada, com todas as distorções, ruídos e possível sobreposição parcial.

Ajudaremos o Dasha a encontrar essas pinturas em um banco de dados com mais de 200.000 imagens?
A base artística da Arthive inclui quase 250.000 imagens, além de vários metadados. A base é constantemente atualizada - de dezenas a centenas de imagens por dia. Mesmo com uma resolução limitada (não mais que 1400 pixels na maioria dos lados), as imagens ocupam mais de 80 gigabytes. Infelizmente, o banco de dados está "sujo": há arquivos quebrados ou muito pequenos, imagens desalinhadas e não processadas, imagens duplicadas. No entanto, no geral, são bons dados.
Comparação de pinturas
Vamos ver como são as imagens no banco de dados:
Basicamente, as imagens no banco de dados são alinhadas, cortadas nas bordas da tela, as cores são preservadas.
E aqui está a aparência das solicitações de dispositivos móveis:

As cores são quase sempre distorcidas - é encontrada iluminação complexa, brilho presente, até reflexos de outras pinturas no vidro. As imagens em si são distorcidas em perspectiva, podem ser cortadas parcialmente ou, pelo contrário, ocupam menos da metade da imagem, podem ser parcialmente fechadas, por exemplo, por pessoas.
Para identificar imagens, você precisa comparar imagens de consultas com imagens no banco de dados.
Para comparar imagens propensas a distorção de perspectiva e distorção de cores, usamos a correspondência de pontos principais. Para fazer isso, encontramos pontos-chave com descritores nas imagens, encontramos sua correspondência e, em seguida, exibimos homograficamente os pontos correspondentes usando o método RANSAC. Isso geralmente é feito da mesma maneira descrita no exemplo do OpenCV . Se o número de pontos “inlier” encontrados pelo RANSAC for grande o suficiente e a transformação homográfica encontrada parecer plausível (não possui escala ou rotações fortes), podemos assumir que as imagens desejadas são uma e a mesma imagem sujeitas a distorções de perspectiva .
Um exemplo de mapeamento de pontos principais:

Exemplo de correspondência negativa Comparação de pinturas do exemplo acima Obviamente, a busca por pontos-chave geralmente é um processo bastante lento, mas, para pesquisar no banco de dados, você pode encontrar os pontos-chave de todas as imagens com antecedência e salvar algumas delas. Em nossas experiências, chegamos à conclusão de que menos de 1000 pontos são suficientes para uma pesquisa confiável de pinturas. Ao usar 64 bytes por ponto (coordenadas + descritor AKAZE) para armazenar 1024 pontos, 64 kbytes por imagem ou cerca de 15 GB por base são suficientes.
A comparação de imagens por pontos-chave no nosso caso levou cerca de 15 ms, ou seja, para uma enumeração completa de um banco de dados de 250.000 fotos, leva cerca de 1 hora. Isso é muito.
Por outro lado, se aprendermos a selecionar rapidamente do banco de dados inteiro vários (digamos, 100) dos candidatos mais prováveis, atingiremos o tempo alvo de 1 segundo por solicitação.
Classificação de similaridade
As redes de convolução profunda se estabeleceram como uma boa maneira de procurar imagens semelhantes. A rede é usada para extrair características e calcular com base em um descritor que possua a propriedade de que a distância (euclidiana, cosseno ou outra) entre os descritores de imagens semelhantes será menor do que para imagens diferentes.
Você pode treinar a rede de forma que, para a imagem da imagem da base e sua imagem distorcida da foto, produz descritores próximos e para imagens diferentes - mais distantes. Além disso, essa rede é usada para calcular descritores de todas as imagens no banco de dados e descritores de fotos em solicitações. Você pode selecionar rapidamente as imagens mais próximas e organizá-las de acordo com a distância entre os descritores.
A maneira básica de treinar uma rede para calcular um descritor é usar uma rede siamesa.
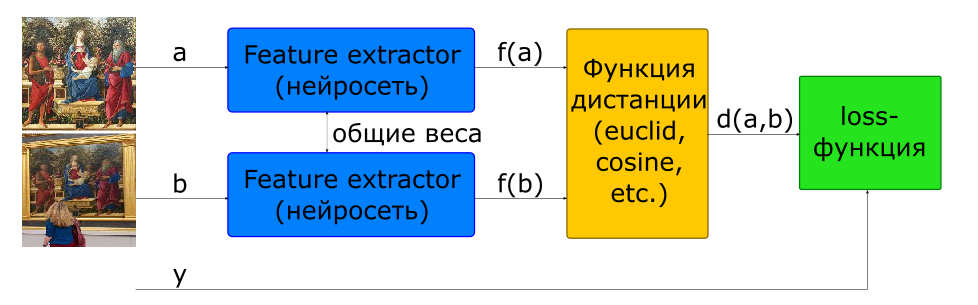
- imagens de entrada
se e - uma aula se diferente
- descritores de imagem
- distância entre um par de vetores de recursos
- função objetiva
Para construir essa arquitetura, uma rede que calcula um descritor (Feature Extractor) é usada no modelo 2 vezes com pesos comuns. Algumas imagens são alimentadas na entrada da rede. A rede Extrator de recursos calcula os descritores de imagem e, em seguida, a rede calcula a distância de acordo com a métrica especificada (geralmente é usada a distância euclidiana ou cosseno). A função alvo do treinamento em rede é construída de tal maneira que, para pares positivos (imagens de uma foto), a distância diminui e, para negativos (imagens de fotos diferentes), aumenta. Para reduzir a influência de pares negativos, a distância entre eles é limitada pelo valor da margem.
Assim, podemos dizer que, no processo de treinamento, a rede procura computar descritores de imagens semelhantes dentro de uma hiperesfera com um raio de margem e descritores de diferentes - para sair dessa esfera.
Por exemplo, isso pode parecer como treinar um descritor bidimensional usando a rede siamesa no conjunto de dados MNIST.
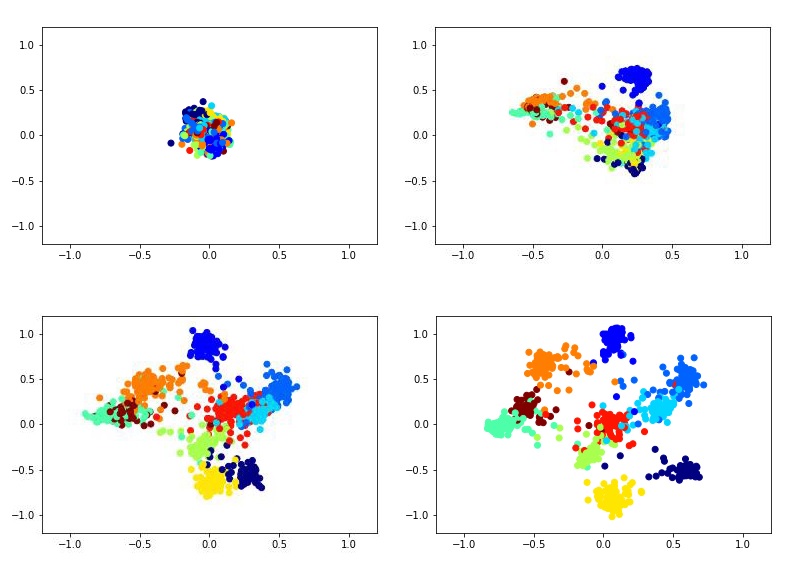
Para treinar a rede siamesa, é necessário inserir pares de imagens e um rótulo igual a 1 se as imagens pertencerem à mesma classe ou 0 se diferente. Existe o problema de escolher a proporção de pares positivos e negativos. Idealmente, é claro, seria necessário submeter à rede o treinamento de todas as combinações possíveis de pares do conjunto de treinamento, mas isso é tecnicamente impossível. E o número de pares negativos nesse caso excede significativamente o número de pares positivos, o que também não terá um efeito muito bom no processo de aprendizagem.
Parte do problema com a escolha da proporção de pares para treinamento é resolvida usando a arquitetura tripla.
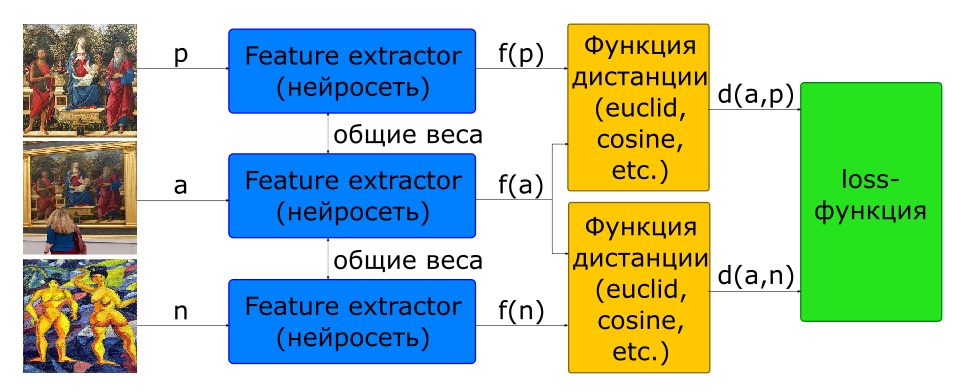
- imagens de entrada: - uma foto, - outro
- função objetiva
Na entrada dessa rede, três figuras são imediatamente formadas, formando um par positivo e negativo.
Além disso, quase todos os pesquisadores concordam que a escolha de pares negativos é fundamental para o aprendizado em rede. A função objetivo para muitas amostras (pares para siameses, triplos para trigêmeos) acaba sendo 0 se não violarem o limite de margem; portanto, essas amostras não participam do treinamento da rede. Com o tempo, o processo de aprendizado diminui ainda mais, pois há cada vez menos amostras com um valor diferente de zero da função objetivo. Para resolver esse problema, pares negativos são escolhidos não por acaso, mas procurando por mineração de casos difíceis. Na prática, vários candidatos negativos são selecionados para isso, para cada um dos quais um descritor é calculado usando a versão mais recente dos pesos de rede (de uma era anterior ou mesmo da atual). Com um descritor, é possível selecionar um negativo em cada três, de modo a produzir uma perda diferente de zero conhecida.
Para procurar imagens semelhantes, o Extrator de recursos é separado da rede e usado para calcular descritores. Para imagens no banco de dados, os descritores são calculados previamente quando adicionados. Portanto, a tarefa de encontrar imagens semelhantes é calcular o descritor de imagens na consulta e procurar os descritores mais próximos da métrica especificada no banco de dados.
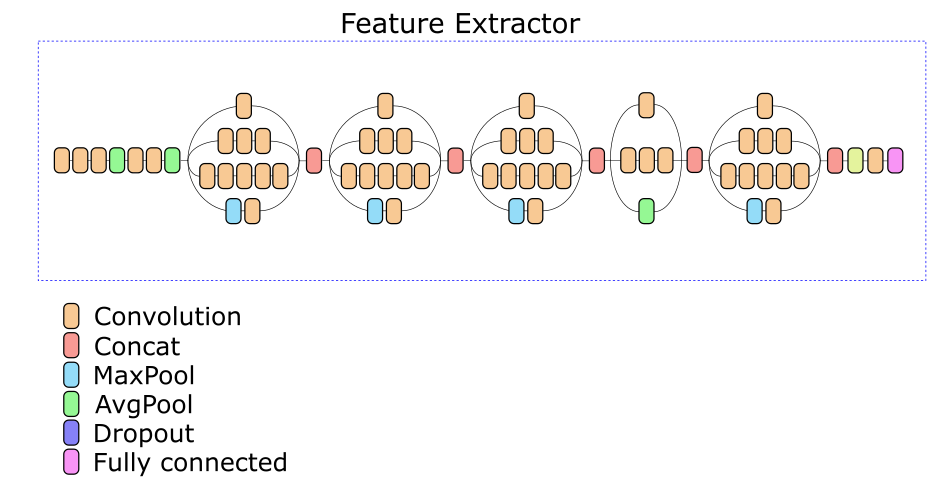
Nosso Extrator de recursos de rede é baseado na arquitetura Inception v3. Uma das camadas intermediárias foi selecionada experimentalmente, com base na saída da qual é calculado um descritor de 512 números reais.
Aumento de Dados
Seria bom se pudéssemos colocar cada foto em quadros diferentes, em paredes diferentes e tirar fotos a cada vez de um ângulo diferente em telefones diferentes. Na prática, isso, é claro, é impossível. Portanto, é necessário gerar dados de treinamento.
Para gerar dados, foram coletadas cerca de 500 fotografias de várias pinturas com diferentes origens sob diferentes condições de iluminação. Para cada foto, foram selecionados 4 pontos correspondentes aos cantos da tela da imagem. Por quatro pontos, podemos ajustar arbitrariamente qualquer imagem no quadro, substituindo a imagem e obtendo uma distorção de perspectiva quase aleatória da imagem no banco de dados. Complementando esse processo com corte aleatório, distorção de ruído e cor, temos a oportunidade de gerar imagens completamente adequadas que imitam fotografias de pinturas.

Separação de uma imagem de um plano de fundo
A qualidade do trabalho e modelos para identificar pinturas e modelos para classificar gêneros / estilos depende em grande parte de quão bem a imagem é separada do plano de fundo. Idealmente, antes de alimentar uma imagem em um modelo, você precisa encontrar os 4 cantos da tela e exibir a perspectiva em um quadrado. Na prática, acabou sendo muito difícil implementar um algoritmo que garantisse isso. Por um lado, há uma variedade significativa de planos de fundo, quadros e objetos que podem cair dentro do quadro próximo à imagem. Por outro lado, há pinturas dentro das quais existem contornos bastante visíveis de formas retangulares (janelas, fachadas de edifícios, imagem em imagem). Como resultado, muitas vezes é muito difícil dizer onde a imagem termina e seu ambiente começa.
No final, decidimos por uma implementação simples, baseada em métodos clássicos de visão computacional (detecção de bordas + filtragem morfológica + análise de componentes conectados), o que permite cortar confiantemente fundos monofônicos, mas não perder parte da imagem.
Velocidade de trabalho
O algoritmo de processamento de consultas consiste nas seguintes etapas principais:
- preparação - de fato, um simples detector da imagem é implementado, o que funciona bem se a imagem contiver um plano de fundo simples;
- calcular um descritor de imagem usando uma rede profunda;
- classificação das imagens por distância aos descritores no banco de dados;
- procure pontos-chave na imagem;
- verificação de candidatos em ordem de classificação.
Testamos a velocidade da rede em 200 solicitações, o seguinte tempo de processamento para cada um dos estágios foi obtido (tempo em segundos):
| estágio | min | max | média |
|---|
| Preparação (pesquisa de imagens) | 0,008 | 0,011 | 0,016 |
| Cálculo do descritor (GPU) | 0,082 | 0,092 | 0,088 |
| KNN (k <500, CPU, força bruta) | 0,199 | 0.820 | 0,394 |
| Pesquisa de ponto principal | 0,031 | 0,432 | 0,156 |
| Verifique os principais pontos | 0,007 | 9,844 | 2.585 |
| Tempo total de solicitação | 0,358 | 10,386 | 3,239 |
Como a verificação dos candidatos para imediatamente, como a imagem é encontrada com confiança suficiente, podemos assumir que o tempo mínimo de processamento das solicitações corresponde às fotos encontradas entre os primeiros candidatos. O tempo máximo de solicitação é obtido para pinturas que não foram encontradas - a verificação é interrompida após 500 candidatos.
Pode-se observar que a maior parte do tempo é gasta na seleção de candidatos e sua verificação. Vale ressaltar que a implementação dessas etapas foi feita de maneira não ideal e com grande potencial de aceleração.
Pesquisa duplicada
Tendo construído o índice completo da base de pinturas, foi utilizado para procurar duplicatas no banco de dados. Após aproximadamente 3 horas de visualização do banco de dados, verificou-se que pelo menos 13657 imagens são repetidas no banco de dados duas vezes (e cerca de três).
Além disso, foram encontrados casos muito interessantes que não são duplicados.
 Um dois
Um dois Parece que essas são duas etapas do mesmo trabalho.
 Um dois dois
Um dois dois Não preste atenção ao nome - todas as três fotos são diferentes.
Bem como um exemplo de identificação de falso positivo por pontos-chave.
 Um dois
Um doismapeamento de pontos-chave Em vez de uma conclusão
Em geral, estamos satisfeitos com o resultado do serviço.
Nos conjuntos de teste, é alcançada uma precisão de identificação acima de 80%. Na prática, geralmente acontece que, se a imagem não for encontrada pela primeira vez, basta fotografá-la de um ângulo diferente e ela estará localizada. Erros quando a imagem errada é encontrada quase nunca ocorrem.
No total, a solução foi acondicionada em um contêiner e entregue ao cliente. Agora, a identificação de pinturas por fotos está disponível em aplicativos usando o serviço Arthive, por exemplo, o Museu Pushkin, disponível no Play Market (no entanto, destaca a pintura do fundo, exigindo que o fundo seja claro, o que às vezes dificulta a fotografia).