O reconhecimento automático de imagens de satélite ou aéreas é a maneira mais promissora de obter informações sobre a localização de vários objetos no solo. A rejeição da segmentação manual de imagens é especialmente relevante quando se trata de processar grandes áreas da superfície da Terra em pouco tempo.
Recentemente, tive a oportunidade de aplicar habilidades teóricas e me testar no campo de aprendizado de máquina em um projeto de segmentação de imagem real. O objetivo do projeto é o reconhecimento de áreas florestais, nomeadamente copas de árvores em imagens de satélite de alta resolução. Sob o corte, vou compartilhar minha experiência e resultados.
Quando se trata de processamento de imagem, a segmentação pode receber a seguinte definição - esta é a presença na imagem de áreas características que são igualmente descritas neste espaço de recursos.
Distinga entre brilho, contorno, textura e segmentação semântica.
A segmentação de imagem semântica (ou semântica) é para destacar áreas na imagem, cada uma das quais corresponde a um atributo específico. Em termos gerais, os problemas de segmentação semântica são difíceis de algoritmos, de modo que redes neurais convolucionais que mostram bons resultados são atualmente amplamente utilizadas para segmentação de imagens.
Declaração do problema
O problema de segmentação binária está sendo resolvido - imagens coloridas (imagens de satélite de alta resolução) são alimentadas na entrada da rede neural, na qual é necessário destacar as áreas de pixels pertencentes à mesma classe - árvores.
Dados de origem
À minha disposição, havia um conjunto de ladrilhos de imagens de satélite de uma área retangular na qual o polígono se encaixa. Dentro dela, e você precisa procurar por árvores. O polígono ou multipolígono é apresentado como um arquivo GeoJSON. No meu caso, os ladrilhos estavam no formato png do tamanho 256 por 256 pixels na cor verdadeira. (infelizmente, sem IR) Numeração de blocos no formato /zoom/x/y.png.
É garantido que todos os ladrilhos do conjunto sejam obtidos a partir de imagens de satélite tiradas aproximadamente na mesma época do ano (final da primavera - início do outono, dependendo do clima de uma região específica) e um dia em um ângulo semelhante à superfície, onde uma leve cobertura de nuvens era permitida.
Preparação de dados
Como a área do polígono desejado pode ser menor que essa área retangular, a primeira coisa a fazer é excluir os blocos que ultrapassam os limites do polígono. Para isso, foi escrito um script simples que seleciona os blocos necessários no polígono do arquivo GeoJSON. Funciona da seguinte maneira. Para começar, as coordenadas de todos os vértices do polígono são
convertidas em números de bloco e adicionadas a uma matriz. Há também um deslocamento em relação à origem. Para inspeção visual, é gerada uma imagem em que um pixel é igual a um bloco. O polígono na imagem já está preenchido, levando em consideração o deslocamento usando PIL. Depois disso, a imagem é transferida para uma matriz, de onde os blocos necessários são selecionados, que caem dentro do polígono.
from PIL import Image, ImageDraw
 Resultado visual da conversão de um polígono em um conjunto de blocos
Resultado visual da conversão de um polígono em um conjunto de blocosModelo de rede
Para resolver os problemas de segmentação de imagens,
existem vários modelos de redes neurais convolucionais. Decidi usar o
U-Net , que se provou nas tarefas de segmentação de imagens binárias. A arquitetura U-Net consiste nos chamados caminhos contratantes e expansivos, que são conectados por probros nos estágios de tamanho apropriado, e primeiro reduzem a resolução da imagem e aumentam, combinando-a previamente com os dados da imagem e passando por outras camadas convolução. Assim, a rede atua como uma espécie de filtro. Os blocos de compressão e descompressão são apresentados como um conjunto de blocos de uma determinada dimensão. E cada bloco consiste em operações básicas: convolução, ReLu e pool máximo. Existem implementações do modelo U-Net no Keras, Tensorflow, Caffe e PyTorch. Eu usei Keras.
Criando um conjunto de treinamento
Para aprender este modelo Unet, você precisa de imagens. A primeira coisa na minha cabeça surgiu com a ideia de pegar os dados do OpenStreetMap e gerar máscaras para treinamento com base neles. Mas, como aconteceu no meu caso, a precisão dos polígonos de que preciso deixa muito a desejar. Eu também precisava da presença de árvores únicas, que nem sempre são mapeadas. Portanto, tive que abandonar esse compromisso. Mas vale a pena dizer que, para outros objetos, como estradas ou edifícios, essa abordagem pode ser
eficaz .

Como a ideia de gerar automaticamente uma amostra de treinamento com base nos dados do OSM teve que ser abandonada, decidi marcar manualmente uma pequena área. Para fazer isso, usei o editor JOSM, onde utilizei imagens de terreno disponíveis como substrato, que coloquei em um servidor local. Em seguida, surgiu outro problema - não encontrei a oportunidade de ativar a exibição da grade de blocos usando ferramentas JOSM regulares. Portanto, algumas linhas simples no arquivo .htaccess no mesmo servidor de um diretório diferente começaram a emitir um bloco vazio com uma borda de pixel para qualquer solicitação do formulário grid_tile / z / x / y.png e adicionaram uma camada improvisada ao JOSM. Que bicicleta.
Primeiro, marquei cerca de 30 peças. Com uma mesa digitalizadora e o "modo de desenho rápido" no JOSM, não demorou muito tempo. Entendi que essa quantidade não é suficiente para o treinamento completo, mas decidi começar com isso. Além disso, o treinamento em tantos dados será rápido o suficiente.
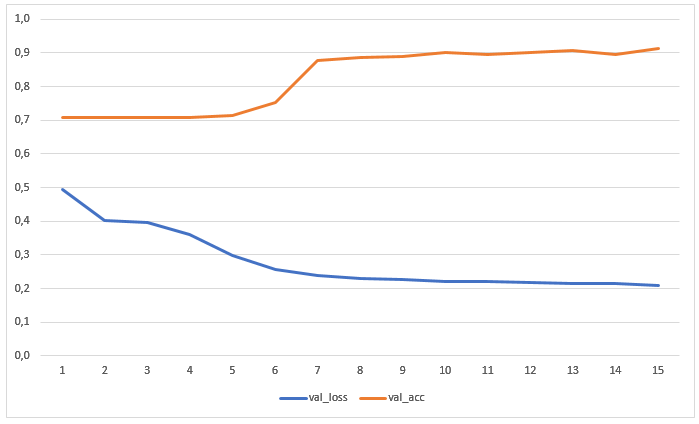
Treinamento e primeiro resultado
A rede foi treinada por 15 épocas sem aumento prévio de dados. O gráfico mostra os valores de perdas e precisão na amostra de teste:
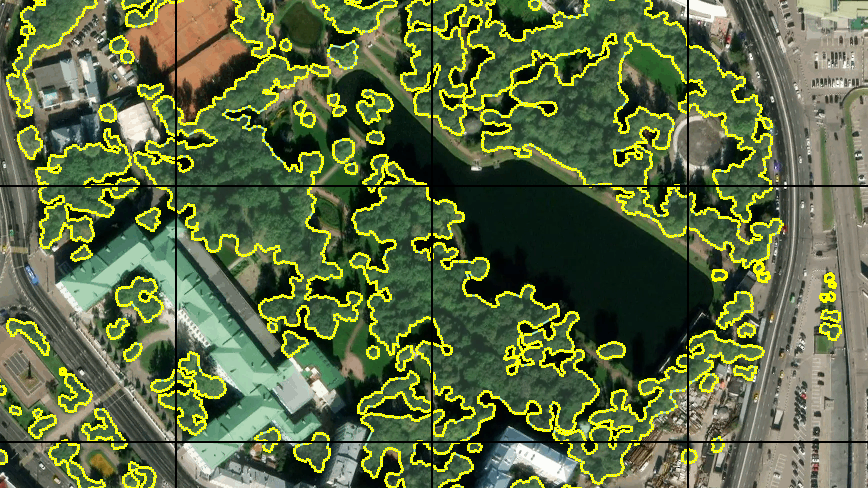
O resultado do reconhecimento de imagens que não estavam no treinamento nem na amostra de teste mostrou-se bastante sensato:

Após um estudo mais aprofundado dos resultados, alguns problemas ficaram claros. Muitas falhas ocorreram nas áreas sombreadas das imagens - a rede encontrou árvores na sombra onde não estavam, ou exatamente o oposto. Isso era esperado, pois havia poucos exemplos no conjunto de treinamento. Mas eu não esperava que alguns pedaços da superfície da água e telhados escuros do perfil de metal (presumivelmente) fossem reconhecidos como árvores. Também houve imprecisões nos gramados. Decidiu-se melhorar a amostra adicionando um número maior de imagens com seções controversas, assim a amostra de treinamento quase dobrou.
Aumento de Dados
Para aumentar ainda mais a quantidade de dados, decidi girar a imagem em um ângulo arbitrário. Primeiro de tudo, tentei o módulo padrão keras.preprocessing.image.ImageDataGenerator. Quando você gira enquanto preserva a escala, as áreas vazias permanecem nas bordas das imagens, cujo preenchimento é definido pelo parâmetro
fill_mode . Você pode simplesmente preencher essas áreas com cores especificando-as em
cval , mas eu queria uma volta completa, esperando que a seleção fosse mais completa, e eu mesmo implementei o gerador. Isso permitiu aumentar o tamanho em mais de dez vezes.
 fill_mode = mais próximo
fill_mode = mais próximoMeu gerador de dados cola quatro blocos vizinhos em um único bloco de origem de 512x512 px. O ângulo de rotação é escolhido aleatoriamente, levando em consideração que os intervalos permitidos de xey são calculados para o centro do bloco resultante, no qual ele não vai além do bloco original. As coordenadas do centro são escolhidas aleatoriamente, levando em consideração os intervalos permitidos. Obviamente, todas essas transformações se aplicam ao par de máscaras de lado a lado. Tudo isso é repetido para vários grupos de peças vizinhas. De um grupo, você pode obter mais de uma dúzia de peças com diferentes seções do terreno giradas em diferentes ângulos.
 Um exemplo do resultado do gerador
Um exemplo do resultado do geradorAprendendo com mais dados
Como resultado, o tamanho da amostra de treinamento foi de 1881 imagens, também aumentei o número de eras para 30:
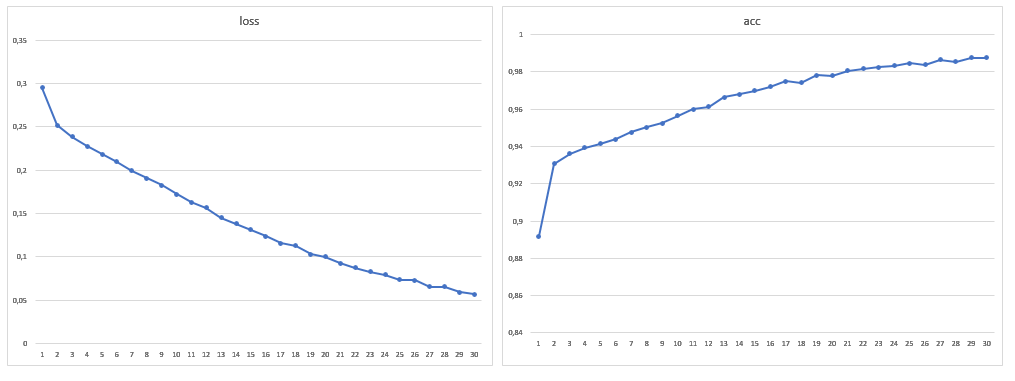
Após treinar o modelo em um novo volume de dados, não foram mais detectados problemas com segmentação incorreta de telhados e água. Não era possível se livrar dos erros na sombra, mas eles se tornaram menos visuais, assim como erros nos gramados. Deve-se notar que, em geral, a grande maioria dos erros é que a rede vê árvores onde elas não estão e não vice-versa. A precisão alcançada pode ser melhorada usando imagens de satélite com um grande número de canais e modificando a arquitetura da rede para uma tarefa específica.

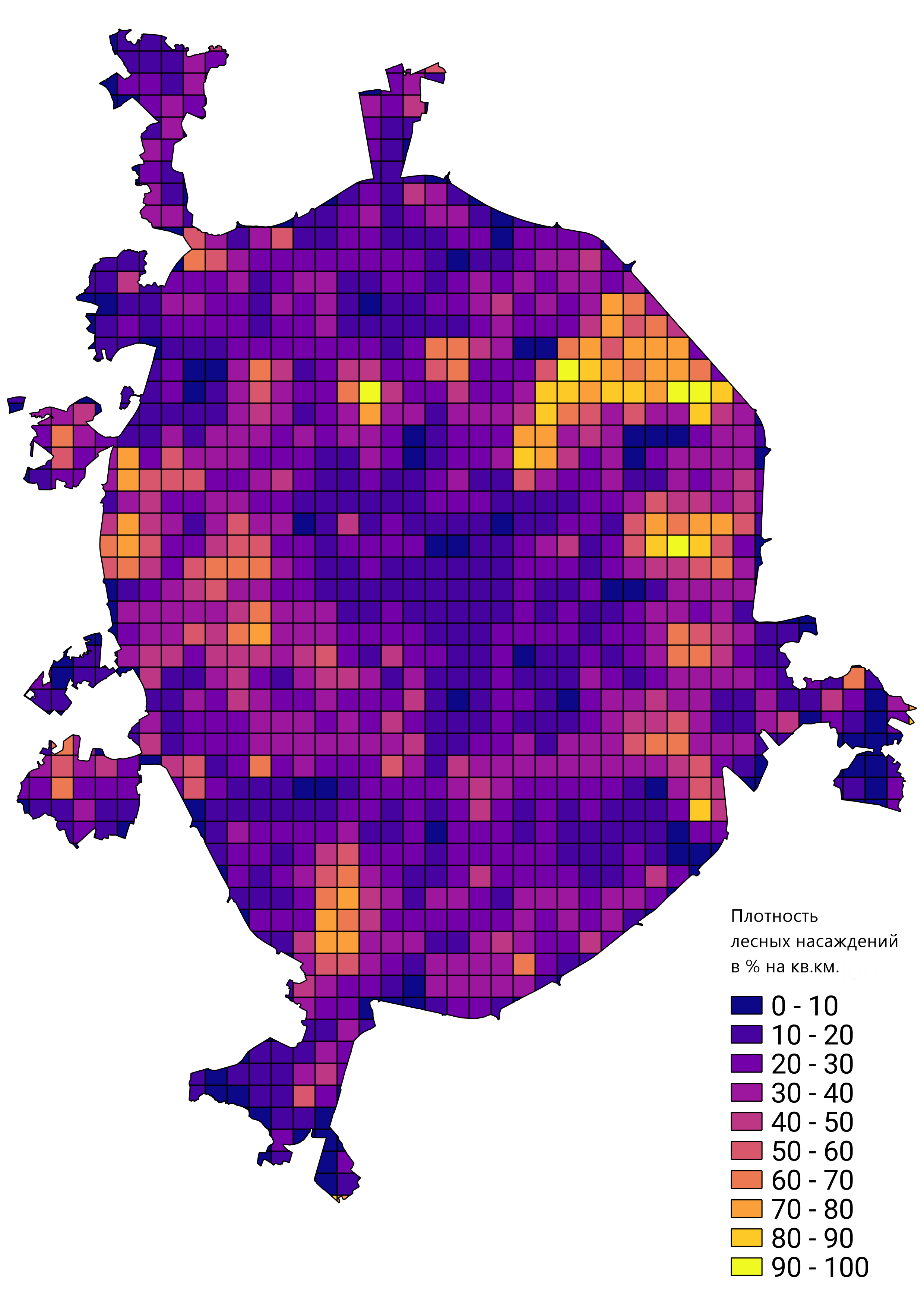
Em geral, fiquei satisfeito com o resultado do trabalho realizado e o protótipo de rede treinado foi aplicado para resolver problemas reais. Por exemplo, calcular a densidade da floresta fica em Moscou: