
Os tempos em que uma das tarefas mais urgentes da visão computacional era a capacidade de distinguir fotografias de cães de fotografias de gatos já estão no passado. No momento, as redes neurais são capazes de executar tarefas muito mais complexas e interessantes para o processamento de imagens. Em particular, a rede com a arquitetura Mask R-CNN permite selecionar os contornos (“máscaras”) de diferentes objetos nas fotografias, mesmo que existam vários objetos, eles têm tamanhos diferentes e se sobrepõem parcialmente. A rede também é capaz de reconhecer as poses das pessoas na imagem.
No início deste ano, tive a oportunidade de participar da competição Data Science Bowl 2018 no Kaggle para fins educacionais. Para fins educacionais, usei um desses modelos que alguns participantes ocupam cargos altos generosamente. Era uma rede neural Mask R-CNN desenvolvida recentemente pelo Facebook Research. (Vale ressaltar que a equipe vencedora ainda usava uma arquitetura diferente - U-Net. Aparentemente, era mais adequada para tarefas biomédicas, que incluíam o Data Science Bowl 2018).
Como o objetivo era familiarizar-se com as tarefas do Deep Learning, e não ocupar um lugar alto, após o término da competição, havia um forte desejo de entender como a rede neural usada "por baixo do capô" funciona. Este artigo é uma compilação de informações obtidas de documentos originais do arXiv.org e de vários artigos no Medium. O material é de natureza puramente teórica (embora, no final, haja links sobre aplicação prática) e não contenha mais do que existe nas fontes indicadas. Mas há pouca informação sobre o assunto em russo, então talvez o artigo seja útil para alguém.
Todas as ilustrações são tiradas de fontes de outras pessoas e pertencem a seus legítimos proprietários.
Tipos de tarefas de visão computacional
Normalmente, as tarefas modernas de visão computacional são divididas em quatro tipos (não era necessário encontrar traduções de seus nomes nem mesmo em fontes de idioma russo, portanto em inglês, para não criar confusão):
- Classificação - classificação da imagem pelo tipo de objeto que ela contém;
- Segmentação semântica - definição de todos os pixels dos objetos de uma determinada classe ou plano de fundo da imagem. Se vários objetos da mesma classe se sobrepuserem, seus pixels não poderão ser separados um do outro;
- Detecção de objetos - detecção de todos os objetos das classes especificadas e determinação da estrutura anexa para cada uma delas;
- Segmentação de instância - definição de pixels pertencentes a cada objeto de cada classe separadamente;
Usando o exemplo de uma imagem com balões de
[9], isso pode ser ilustrado da seguinte maneira:
Desenvolvimento evolutivo da Máscara R-CNN
Os conceitos subjacentes ao Mask R-CNN passaram por um desenvolvimento em fases através da arquitetura de várias redes neurais intermediárias que resolveram tarefas diferentes da lista acima. Provavelmente, a maneira mais fácil de entender os princípios de funcionamento dessa rede é considerar sequencialmente todos esses estágios.
Sem insistir em coisas básicas como retropropagação, a função de ativação não linear e o que é uma rede neural multicamada, uma breve explicação de como as camadas das redes neurais de convolução funcionam provavelmente ainda vale a pena (R-CNN).
Convolução e MaxPooling
Uma camada convolucional permite combinar os valores de pixels adjacentes e destacar recursos mais gerais da imagem. Para fazer isso, a imagem é sequencialmente deslizada por uma janela quadrada de tamanho pequeno (3x3, 5x5, 7x7 pixels etc.) chamada kernel (kernel). Cada elemento principal tem seu próprio coeficiente de peso multiplicado pelo valor desse pixel da imagem na qual o elemento principal está atualmente sobreposto. Em seguida, os números obtidos para a janela inteira são somados e essa soma ponderada fornece o valor do próximo sinal.
Para obter uma matriz ("mapa") de atributos de toda a imagem, o núcleo é alternado sequencialmente na horizontal e na vertical. Nas camadas a seguir, a operação de convolução já é aplicada aos mapas de características obtidos nas camadas anteriores. Graficamente, o processo pode ser ilustrado da seguinte maneira:
Uma imagem ou cartões de recursos em uma camada podem ser digitalizados não por um, mas por vários filtros independentes, fornecendo não apenas um cartão, mas vários (eles também são chamados de "canais"). O ajuste dos pesos de cada filtro ocorre usando o mesmo procedimento de retropropagação.
Obviamente, se o núcleo do filtro durante a digitalização não for além da imagem, a dimensão do mapa de recursos será menor que a da imagem original. Se você deseja manter o mesmo tamanho, aplique os chamados preenchimentos - valores que complementam a imagem nas bordas e que são capturados pelo filtro junto com os pixels reais da imagem.
Além dos preenchimentos, as alterações dimensionais também são afetadas pelos avanços - os valores da etapa com a qual a janela se move pela imagem / mapa.
A convolução não é a única maneira de obter uma característica generalizada de um grupo de pixels. A maneira mais fácil de fazer isso é selecionar um pixel de acordo com uma regra especificada, por exemplo, o máximo. É exatamente isso que a camada MaxPooling faz.
Diferentemente da convolução, o maxpool geralmente é aplicado a grupos de pixels separados.
R-CNN
A arquitetura de rede R-CNN (Regiões com CNNs) foi desenvolvida por uma equipe da UC Berkley para aplicar redes neurais da convolução a uma tarefa de detecção de objetos. As abordagens para resolver esses problemas existentes naquele momento se aproximavam do máximo de suas capacidades e seu desempenho não era significativamente aprimorado.
A CNN teve um bom desempenho na classificação das imagens e, na rede fornecida, elas foram essencialmente aplicadas para as mesmas. Para fazer isso, nem toda a imagem foi alimentada na entrada da CNN, mas regiões preliminarmente alocadas de uma maneira diferente, na qual alguns objetos deveriam estar. Naquela época, havia várias dessas abordagens, os autores escolheram a
Pesquisa seletiva , embora indiquem que não há razões específicas para a preferência.
Uma arquitetura pronta também foi usada como rede CNN -
CaffeNet (AlexNet). Essas redes neurais, como outras para o conjunto de imagens ImageNet, são classificadas em 1000 classes. O R-CNN foi projetado para detectar objetos de um número menor de classes (N = 20 ou 200); portanto, a última camada de classificação do CaffeNet foi substituída por uma camada com saídas N + 1 (com uma classe adicional para o plano de fundo).
A Pesquisa seletiva retornou cerca de 2.000 regiões de diferentes tamanhos e proporções, mas o CaffeNet aceita imagens de tamanho fixo de 227x227 pixels como entrada, portanto, você deve modificá-las antes de enviar regiões para a entrada de rede. Para isso, a imagem da região foi encerrada na menor praça de abrangência. No lado (menor) ao longo do qual os campos foram formados, vários pixels "contextuais" (ao redor da região) da imagem foram adicionados, o restante do campo não foi preenchido com nada. O quadrado resultante foi dimensionado para um tamanho de 227x227 e alimentado à entrada do CaffeNet.

Apesar do fato de a CNN ter treinado para reconhecer as classes N + 1, no final, ela foi usada apenas para extrair um vetor de característica fixo 4096 dimensional. N SVMs lineares estavam envolvidos na determinação direta do objeto na imagem, cada um dos quais executava uma classificação binária de acordo com seu tipo de objeto, determinando se havia algo assim na região transferida ou não. No documento original, todo o procedimento é ilustrado pelo seguinte esquema:
Os autores argumentam que o processo de classificação no SVM é muito produtivo, sendo essencialmente apenas operações matriciais. Os vetores de recursos obtidos da CNN são combinados em todas as regiões em uma matriz de 2000x4096, que é multiplicada por uma matriz de 4096xN com pesos SVM.
Deve-se observar que as regiões obtidas usando a Pesquisa seletiva
podem conter apenas alguns objetos, e não o fato de que eles os contêm por inteiro. A consideração ou não de uma região que contém um objeto foi determinada pela
métrica Intersecção sobre União (IoU) . Essa métrica é a razão da área de interseção de uma região candidata retangular com um retângulo que realmente abrange o objeto e a área de união desses retângulos. Se a proporção exceder um valor limite predeterminado, a região candidata é considerada como contendo o objeto desejado.
A IoU também foi usada para filtrar um número excessivo de regiões contendo um objeto específico (supressão não máxima). Se a IoU de uma região com uma região que recebeu o resultado máximo para o mesmo objeto estivesse acima de um limite, a primeira região seria simplesmente descartada.
Durante o procedimento de análise de erro, os autores também desenvolveram um método que permite reduzir o erro de selecionar a regressão de quadro delimitador - caixa delimitadora do objeto. Após classificar o conteúdo da região candidata, quatro parâmetros foram determinados usando regressão linear com base nos atributos da CNN - (dx, dy, dw, dh). Eles descreveram quanto o centro do quadro da região deve ser deslocado por xey, e quanto alterar sua largura e altura para cobrir com mais precisão o objeto reconhecido.
Assim, o procedimento para detectar objetos pela rede R-CNN pode ser dividido nas seguintes etapas:
- Destaque regiões candidatas usando a Pesquisa seletiva.
- Convertendo uma região para o tamanho aceito pela CNN CaffeNet.
- Obtenção usando o vetor dimensional CNN 4096 de recursos.
- Realização de N classificações binárias de cada vetor de recurso usando N SVMs lineares.
- Regressão linear dos parâmetros do quadro da região para uma cobertura mais precisa do objeto
Os autores observaram que a arquitetura que eles desenvolveram também teve um bom desempenho no problema de segmentação semântica.
R-cnn rápido
Apesar dos bons resultados, o desempenho da R-CNN ainda era baixo, especialmente para redes mais profundas do que CaffeNet (como VGG16). Além disso, o treinamento para o regressor de caixa delimitadora e o SVM exigia salvar um grande número de atributos no disco, por isso era caro em termos de tamanho de armazenamento.
Os autores do Fast R-CNN propuseram acelerar o processo devido a algumas modificações:
- Para passar pela CNN, não cada uma das 2000 regiões candidatas separadamente, mas toda a imagem. As regiões propostas são então sobrepostas no mapa de características comuns resultante;
- Em vez de treinamento independente de três modelos (CNN, SVM, regressor bbox), combine todos os procedimentos de treinamento em um.
A conversão de sinais que caíram em diferentes regiões para um tamanho fixo foi realizada usando o procedimento
RoIPooling . Uma janela de região de largura w e altura h foi dividida em uma grade com células H × W de tamanho h / H × w / W. (Os autores do documento usaram W = H = 7). Para cada uma dessas células, Max Pooling foi realizado para selecionar apenas um valor, fornecendo assim a matriz característica H × W resultante.
SVMs binários não foram utilizados; em vez disso, os recursos selecionados foram transferidos para uma camada totalmente conectada e depois para duas camadas paralelas: softmax com saídas K + 1 (uma para cada classe + 1 para o fundo) e regressor de caixa delimitadora.
A arquitetura de rede geral é assim:
Para o treinamento conjunto do classificador softmax e do regressor bbox, foi utilizada a função de perda combinada:
Aqui:
- a classe do objeto realmente representado na região candidata;
- perda de log para a classe u;
- mudanças reais na estrutura da região para uma cobertura mais precisa do objeto;
- mudanças previstas na estrutura da região;
- função de perda entre mudanças de quadro previstas e reais;
- função indicadora igual a 1 quando
e 0 quando vice-versa. Class
o fundo é indicado (ou seja, a ausência de objetos na região).
- coeficiente projetado para equilibrar a contribuição de ambas as funções de perda para o resultado geral. Em todos os experimentos dos autores do documento, no entanto, foi igual a 1.
Os autores também mencionam que usaram a decomposição truncada SVD da matriz de pesos para acelerar os cálculos em uma camada totalmente conectada.
R-cnn mais rápido
Após as melhorias feitas no Fast R-CNN, o gargalo da rede neural acabou sendo o mecanismo para gerar regiões candidatas. Em 2015, uma equipe da Microsoft Research conseguiu fazer esse passo significativamente mais rápido. Eles sugeriram calcular regiões não a partir da imagem original, mas novamente a partir de um mapa de recursos obtidos da CNN. Para isso, foi adicionado um módulo chamado Region Proposal Network (RPN). A arquitetura inteira é a seguinte:
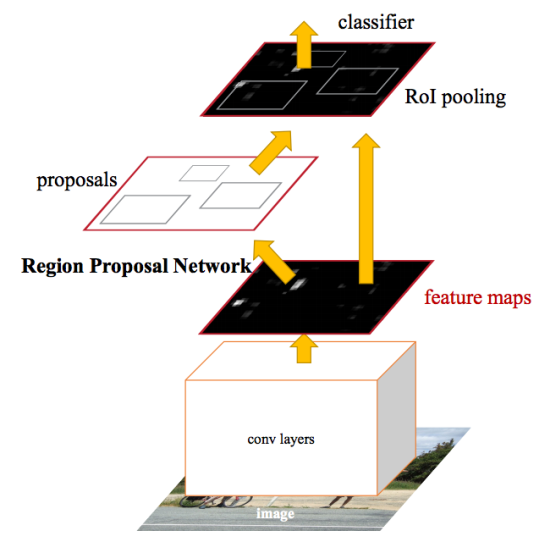
Dentro da estrutura da RPN, de acordo com a CNN extraída, eles deslizam para uma “rede mini-neural” com uma pequena janela (3x3). Os valores obtidos com sua ajuda são transferidos para duas camadas paralelas totalmente conectadas: camada de regressão em caixa (reg) e camada de classificação em caixa (cls). As saídas dessas camadas são baseadas nas chamadas âncoras: k quadros para cada posição da janela deslizante, que possuem tamanhos e proporções diferentes. A camada de registro para cada uma dessas âncoras produz 4 coordenadas, corrigindo a posição da estrutura anexa; A camada cls produz dois números cada - a probabilidade de o quadro conter pelo menos algum objeto ou não. No documento, isso é ilustrado pelo seguinte esquema:
O processo de aprendizagem reg e cls camadas combinadas; eles têm uma função de perda em comum, que é a soma das funções de perda de cada um deles, com um coeficiente de equilíbrio.
Ambas as camadas RPN fornecem apenas ofertas para regiões candidatas. Aqueles com alta probabilidade de conter um objeto são transmitidos para o módulo de detecção e refinamento de objetos, que ainda é implementado como Fast R-CNN.
Para compartilhar os recursos obtidos na CNN entre o RPN e o módulo de detecção, o processo de treinamento de toda a rede é iterativamente construído usando várias etapas:
- A parte RPN é inicializada e treinada para identificar regiões candidatas.
- Usando as regiões RPN propostas, a parte Fast R-CNN é treinada novamente.
- Uma rede de detecção treinada é usada para inicializar pesos para RPNs. As camadas de convolução geral, no entanto, são fixas e apenas as camadas específicas do RPN são ajustadas novamente.
- Com camadas de convolução fixas, o Fast R-CNN é finalmente sintonizado.
O esquema proposto não é o único e, mesmo em sua forma atual, pode ser continuado por outras etapas iterativas, mas os autores do estudo original realizaram experimentos precisamente após esse treinamento.
Máscara r-cnn
A máscara R-CNN desenvolve a arquitetura Faster R-CNN adicionando outra ramificação que prediz a posição da máscara que cobre o objeto encontrado e, assim, resolve o problema de segmentação da instância. A máscara é apenas uma matriz retangular, na qual 1 em alguma posição significa que o pixel correspondente pertence a um objeto de uma determinada classe, 0 - que o pixel não pertence ao objeto.

A visualização de máscaras multicoloridas nas imagens de origem pode fornecer imagens coloridas:

Os autores do documento dividem condicionalmente a arquitetura desenvolvida em uma rede CNN para computar recursos de imagem, chamados backbone e head - a união das partes responsáveis por prever a moldura de cobertura, classificar o objeto e determinar sua máscara. A função de perda é comum para eles e inclui três componentes:
A extração de máscara ocorre em um estilo independente de classe: as máscaras são previstas separadamente para cada classe, sem o conhecimento prévio do que é representado na região e, em seguida, a máscara da classe que venceu o classificador independente é simplesmente selecionada. Argumenta-se que tal abordagem é mais eficaz do que confiar em um conhecimento a priori da classe.
Uma das principais modificações decorrentes da necessidade de prever a máscara é uma alteração no procedimento
RoIPool (que calcula a matriz de recursos para a região candidata) no chamado
RoIAlign . O fato é que o mapa de recursos obtido da CNN tem um tamanho menor que a imagem original e a região que cobre o número inteiro de pixels na imagem não pode ser exibida em uma região proporcional do mapa com o número inteiro de recursos:
No RoIPool, o problema foi resolvido simplesmente arredondando os valores fracionários para números inteiros. Essa abordagem funciona bem ao selecionar o quadro anexo, mas a máscara calculada com base nesses dados é muito imprecisa.
Por outro lado, o RoIAlign não usa arredondamento, todos os números permanecem válidos e a interpolação bilinear nos quatro pontos inteiros mais próximos é usada para calcular os valores dos atributos.
No documento original, a diferença é explicada da seguinte maneira:
Aqui, o mapa hachurado indica um mapa de recursos e contínuo - a exibição no mapa de recursos da região candidata a partir da fotografia original. Deve haver 4 grupos nessa região para o pool máximo com 4 atributos indicados por pontos na figura. Diferentemente do procedimento RoIPool, que devido ao arredondamento simplesmente alinharia a região com coordenadas inteiras, o RoIAlign deixa os pontos em seus locais atuais, mas calcula os valores de cada um deles usando interpolação bilinear de acordo com os quatro sinais mais próximos.
Interpolação bilinearA interpolação bilinear da função de duas variáveis é realizada aplicando interpolação linear, primeiro na direção de uma das coordenadas, depois na outra.
Seja necessário interpolar o valor da função
no ponto P com valores conhecidos da função nos pontos circundantes
(veja a imagem abaixo). Para fazer isso, primeiro os valores dos pontos auxiliares R1 e R2 são interpolados e, em seguida, o valor no ponto P é interpolado com base neles.
( — ,
)
Além dos altos resultados nas tarefas de segmentação de instância e detecção de objetos, o Mask R-CNN provou ser adequado para determinar a pose de pessoas na fotografia (estimativa de pose humana). O ponto-chave aqui é a seleção de pontos-chave (pontos-chave), como ombro esquerdo, cotovelo direito, joelho direito, etc., através dos quais você pode desenhar uma estrutura da posição de uma pessoa: para determinar os pontos de referência, a rede neural é treinada de maneira a emitir máscaras, em dos quais apenas um pixel (o mesmo ponto) tinha um valor de 1 e o restante - 0 (uma máscara quente). Ao mesmo tempo, a rede está treinando para emitir K máscaras de pixel único, uma para cada tipo de ponto de referência.
para determinar os pontos de referência, a rede neural é treinada de maneira a emitir máscaras, em dos quais apenas um pixel (o mesmo ponto) tinha um valor de 1 e o restante - 0 (uma máscara quente). Ao mesmo tempo, a rede está treinando para emitir K máscaras de pixel único, uma para cada tipo de ponto de referência.Redes de pirâmides
Em experimentos com o Mask R-CNN, junto com o habitual CNN ResNet-50/101 como espinha dorsal, também foram realizados estudos sobre a viabilidade do uso da Feature Pyramid Network (FPN). Eles mostraram que o uso da FPN no backbone proporciona à Mask R-CNN um aumento na precisão e no desempenho. Isso torna útil descrever a melhoria da mesma maneira, apesar de um documento separado ser dedicado a ela e ter pouco a ver com a série de artigos em consideração.O objetivo das pirâmides de recursos, como as pirâmides de imagens, é melhorar a qualidade da detecção de objetos, levando em consideração uma ampla variedade de tamanhos possíveis.Na Rede de Pirâmides de Recursos, os mapas de recursos extraídos por sucessivas camadas CNN com dimensões decrescentes são considerados como algum tipo de "pirâmide" hierárquica chamada caminho de baixo para cima. Além disso, os mapas de características dos níveis inferior e superior da pirâmide têm suas vantagens e desvantagens: os primeiros possuem alta resolução, mas baixa capacidade de generalização semântica; o segundo - pelo contrário:A arquitetura FPN permite combinar as vantagens das camadas superior e inferior adicionando caminho de cima para baixo e conexões laterais. Para isso, o mapa de cada camada subjacente é ampliado para o tamanho da camada subjacente e seu conteúdo é adicionado elemento a elemento. Nas previsões finais, as cartas resultantes de todos os níveis são usadas.Esquematicamente, isso pode ser representado da seguinte maneira:O aumento do tamanho do mapa de nível superior (upsampling) é feito pelo método mais simples - o vizinho mais próximo, ou seja, aproximadamente assim:Links úteis
Artigos de pesquisa originais no arXiv.org:1. R-CNN: https://arxiv.org/abs/1311.25242. R-CNN rápido : https://arxiv.org/abs/1504.080833. R-CNN mais rápido : https://arxiv.org/abs/1506.014974. Máscara R-CNN: https://arxiv.org/abs/1703.068705. Rede de pirâmide de recursos: https://arxiv.org/abs/1612.03144Em meio. com o tema da Mask R-CNN, existem muitos artigos, eles são fáceis de encontrar. Como referências, cito apenas as que li:6. Simple Understanding of Mask RCNN - um breve resumo dos princípios da arquitetura resultante.7. Breve histórico das CNNs na segmentação de imagens: do R-CNN para mascarar o R-CNN- A história do desenvolvimento da rede na mesma ordem cronológica que neste artigo.8. De R-CNN a Mask R-CNN é outra consideração dos estágios de desenvolvimento.9
Splash of Color: Segmentação de Instância com Mask R-CNN e TensorFlow - implementação da rede neural na biblioteca Opensource da Matterport.O último artigo, além de descrever os princípios da Mask R-CNN, oferece a oportunidade de experimentar a rede na prática: para colorir balões em cores diferentes em imagens em preto e branco.Além disso, você pode praticar com a rede neural no modelo que usei na competição Data Science Bowl 2018 no kaggle (mas não apenas com este modelo, é claro; você pode encontrar muitas coisas interessantes nas seções Kernels e discussões):10. Mask R- CNN em PyTorch por Heng CherKeng. A implementação envolve uma série de etapas de implantação; o autor fornece instruções. O modelo requer PyTorch 0.4.0, suporte para computação de GPU, NVIDIA CUDA. Se meu próprio sistema não atender aos requisitos, eu posso recomendar imagens AMI do Deep Learning para máquinas virtuais da Amazon (instâncias são pagas, com cobrança por hora, o tamanho mínimo adequado, aparentemente, é p2.xlarge).Também encontrei aqui no hub, um artigo sobre o uso da rede da Matterport no processamento de imagens com pratos (embora sem fonte). Espero que o autor fique satisfeito com a menção adicional:11. ConvNets. Protótipo de um projeto usando Mask R-CNN