Anteriormente,
conversamos sobre o mais poderoso supercomputador japonês para pesquisas em física nuclear. Agora, no Japão, eles estão criando um supercomputador Exaflops Post-K - os japoneses serão os primeiros a lançar uma máquina com esse poder de computação.
O comissionamento está previsto para 2021.
Na semana passada, a Fujitsu falou sobre as características técnicas do chip A64FX, que formará a base da nova "máquina". Falaremos mais sobre o chip e seus recursos.
 / photo Toshihiro Matsui CC / Computador japonês supercomputador K
/ photo Toshihiro Matsui CC / Computador japonês supercomputador KEspecificações A64FX
Espera-se que os recursos de computação do Post-K sejam quase dez vezes
superiores ao desempenho dos mais poderosos dos supercomputadores
IBM Summit existentes (
em junho de 2018 ).
O supercomputador deve desempenho semelhante ao do chip A64FX Arm. Esse chip
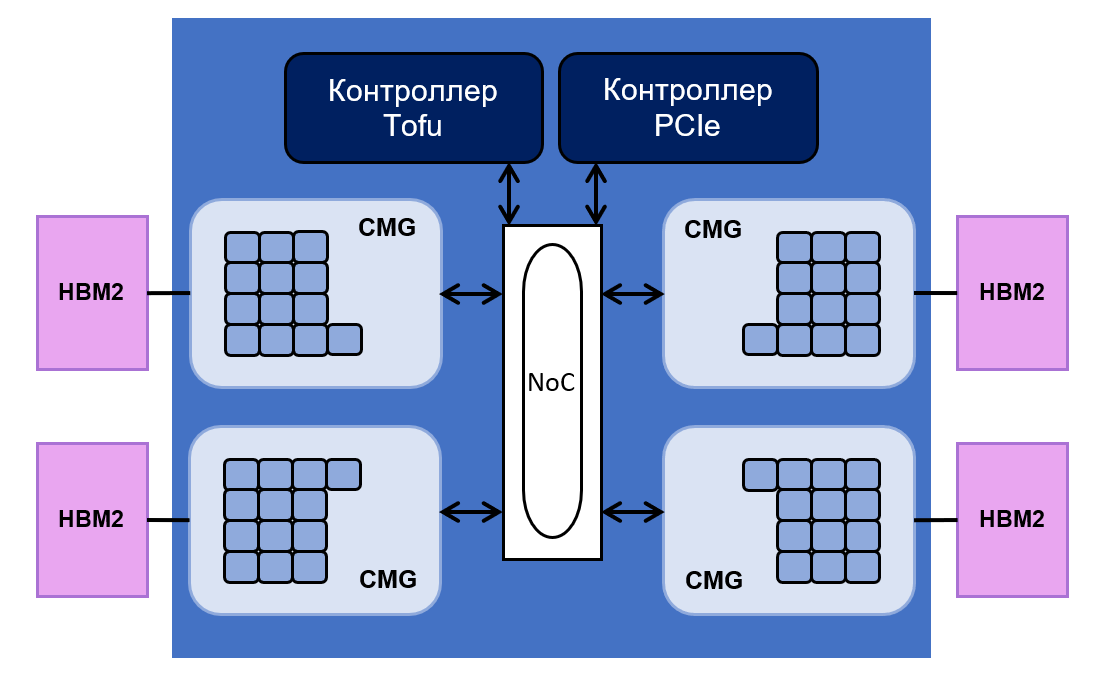
consiste em 48 núcleos para operações de computação e quatro núcleos para controlá-los. Todos eles são divididos igualmente em quatro grupos - Core Memory Groups (CMG).
Cada grupo possui 8 MB de cache L2. Ele está conectado ao controlador de memória e à interface NoC ("
rede em um chip "). O NoC conecta vários CMGs aos controladores PCIe e Tofu. Este último é responsável pela comunicação entre o processador e o restante do sistema. O controlador Tofu possui dez portas com uma taxa de transferência de 12,5 GB / s.
O layout do chip é o seguinte:
A memória
HBM2 total do processador é de 32 gigabytes e seu rendimento é igual a 1024 GB / s. A Fujitsu diz que o desempenho do processador em operações de ponto flutuante atinge 2,7 teraflops para operações de 64 bits, 5,4 teraflops para 32 bits e 10,8 teraflops para 16 bits.
A criação do Post-K é monitorada pelos editores de recursos Top500, que compilam uma lista dos mais poderosos sistemas de computação. Segundo eles, para obter desempenho em um exaflops, o supercomputador usa mais de 370 mil processadores A64FX.
O dispositivo utilizará primeiro a tecnologia de extensão vetorial chamada Scalable Vector Extension (SVE). Difere de outras
arquiteturas SIMD por não
limitar o comprimento dos registros vetoriais, mas define um intervalo válido para eles. O SVE suporta vetores de 128 a 2048 bits de comprimento. Portanto, qualquer programa pode ser executado em outros processadores compatíveis com o SVE, sem a necessidade de recompilação.
Usando o SVE (uma vez que é uma função SIMD), o processador pode executar cálculos simultaneamente com várias matrizes de dados. Aqui está um exemplo de uma destas instruções para a função NEON, que foi usada para computação vetorial em outras arquiteturas de processadores Arm:
vadd.i32 q1, q2, q3
Ele adiciona quatro números inteiros de 32 bits do registro de 128 bits q2 com os números correspondentes no registro de 128 bits q3 e grava a matriz resultante em q1. O equivalente a esta operação em C é assim:
for(i = 0; i < 4; i++) a[i] = b[i] + c[i];
Além disso, o SVE oferece suporte à vetorização automática. Um vetorizador automático analisa os ciclos no código e, se possível, usa registradores de vetor para executá-los. Isso melhora o desempenho do código.
Por exemplo, uma função em C:
void vectorize_this(unsigned int *a, unsigned int *b, unsigned int *c) { unsigned int i; for(i = 0; i < SIZE; i++) { a[i] = b[i] + c[i]; } }
Ele será compilado da seguinte maneira (para um processador Arm de 32 bits):
104cc: ldr.w r3, [r4, #4]! 104d0: ldr.w r1, [r2, #4]! 104d4: cmp r4, r5 104d6: add r3, r1 104d8: str.w r3, [r0, #4]! 104dc: bne.n 104cc <vectorize_this+0xc>
Se você usar a vetorização automática, ficará assim:
10780: vld1.64 {d18-d19}, [r5 :64] 10784: adds r6, #1 10786: cmp r6, r7 10788: add.w r5, r5, #16 1078c: vld1.32 {d16-d17}, [r4] 10790: vadd.i32 q8, q8, q9 10794: add.w r4, r4, #16 10798: vst1.32 {d16-d17}, [r3] 1079c: add.w r3, r3, #16 107a0: bcc.n 10780 <vectorize_this+0x70>
Aqui, os registros SIM8 q8 e q9 são carregados com dados de matrizes apontadas por r5 e r4. Depois disso, a instrução vadd adiciona quatro valores inteiros de 32 bits por vez. Isso aumenta a quantidade de código, mas dessa forma muito mais dados são processados para cada iteração do loop.
Quem mais cria supercomputadores exaflops
Os supercomputadores Exaflops não são criados apenas no Japão. Por exemplo, também estão em andamento trabalhos na China e nos Estados Unidos.
Na China, crie o Tianhe-3 (Tianhe-3). Seu protótipo já está
sendo testado no Centro Nacional de Supercomputação em Tianjin. A versão final do computador está prevista para ser concluída em 2020.
 / photo O01326 CC / Supercomputador Tianhe-2 - antecessor do Tianhe-3
/ photo O01326 CC / Supercomputador Tianhe-2 - antecessor do Tianhe-3No coração de Tianhe-3
estão os processadores chineses Phytium. O dispositivo contém 64 núcleos,
um desempenho de 512 gigaflops e uma largura de banda de memória de 204,8 GB / s.
Também foi criado um protótipo de trabalho para uma máquina da série
Sunway . Está sendo testado no Centro Nacional de Supercomputadores em Jinan. Segundo os desenvolvedores, cerca de 35 aplicativos estão operando atualmente no computador - simuladores biomédicos, aplicativos para processamento de big data e programas para estudar as mudanças climáticas. Espera-se que o trabalho no computador seja concluído no primeiro semestre de 2021.
Quanto aos Estados Unidos, os americanos
planejam criar seus computadores exaflops até 2021. O projeto se chama Aurora A21, e o
Laboratório Nacional de Argonne do Departamento de Energia dos EUA , assim como Intel e Cray, estão trabalhando nele.
Este ano, os pesquisadores já
selecionaram dez projetos para o Aurora Early Science Program, cujos participantes serão os primeiros a usar o novo sistema de alto desempenho. Entre eles estavam os programas para criar um
mapa dos neurônios cerebrais, estudar a matéria escura e desenvolver um simulador de acelerador de partículas.
Os computadores Exaflops possibilitarão a construção de modelos complexos de pesquisa, pois muitos projetos científicos aguardam a criação dessas máquinas. Um dos mais ambiciosos é o Projeto Cérebro Humano (HBP), cujo objetivo é criar um modelo completo do cérebro humano e estudar cálculos neuromórficos. Segundo os cientistas da HBP, o uso de novos sistemas de exaflops pode ser encontrado desde os primeiros dias de sua existência.
O que fazemos no IT-GRAD: • IaaS • Hospedagem de PCI DSS • Nuvem -152
Conteúdo do nosso blog corporativo IaaS: