Nesta primavera, foi realizado um importante concurso OpenAI Retro, dedicado ao aprendizado por reforço, ao aprendizado por meta e, é claro, ao Sonic. Nossa equipe ficou em 4º lugar entre mais de 900 equipes. O campo de treinamento com reforço é um pouco diferente do aprendizado de máquina padrão, e esse concurso era diferente de uma competição típica de RL. Peço detalhes sob gato.
TL; DR
Uma linha de base devidamente ajustada não precisa de truques adicionais ... praticamente.
Introdução ao treinamento de reforço
O aprendizado reforçado é uma área que combina a teoria do controle ideal, teoria dos jogos, psicologia e neurobiologia. Na prática, o aprendizado por reforço é usado para resolver problemas de tomada de decisão e procurar estratégias comportamentais ideais ou políticas muito complexas para a programação "direta". Nesse caso, o agente é treinado no histórico de interações com o meio ambiente. O ambiente, por sua vez, avaliando as ações do agente, fornece a ele uma recompensa (escalar) - quanto melhor o comportamento do agente, maior a recompensa. Como resultado, a melhor política é aprendida com o agente que aprendeu a maximizar a recompensa total por todo o tempo de interação com o ambiente.
Como um exemplo simples, você pode jogar BreakOut. Neste bom e velho jogo da série Atari, uma pessoa / agente precisa controlar a plataforma horizontal inferior, bater na bola e gradualmente quebrar todos os blocos superiores com ela. Quanto mais derrubado, maior a recompensa. Consequentemente, o que uma pessoa / agente vê é uma imagem da tela e é necessário tomar uma decisão em que direção mover a plataforma inferior.
Se você estiver interessado no tópico de treinamento por reforço, aconselho você em um curso introdutório interessante do HSE , bem como em seu colega de código aberto mais detalhado. Se você quer algo que possa ler, mas com exemplos - um livro inspirado nesses dois cursos. Revisei / completei / ajudei a criar todos esses cursos e, portanto, sei por experiência própria que eles fornecem uma excelente base.
Sobre a tarefa
O principal objetivo dessa competição era conseguir um agente que pudesse jogar bem na série de jogos SEGA - Sonic The Hedgehog. A OpenAI estava começando a importar jogos da SEGA para sua plataforma de treinamento de agentes da RL, e decidiu promover um pouco esse momento. Até o artigo foi lançado com o dispositivo de tudo e uma descrição detalhada dos métodos básicos.
Todos os três jogos do Sonic foram suportados, cada um com 9 níveis, nos quais, ao abrir uma lágrima, você pode até jogar, lembrando a sua infância (depois de comprá-los no Steam primeiro).
O estado do ambiente (o que o agente viu) foi a imagem do simulador - uma imagem RGB e, como ação, o agente foi solicitado a escolher qual botão do joystick virtual pressionar - pular / esquerda / direita e assim por diante. O agente recebeu pontos de recompensa, bem como no jogo original, ou seja, para coletar anéis, bem como para a velocidade de passar de nível. De fato, tínhamos um som original à nossa frente, mas era necessário passar por ele com a ajuda de nosso agente.
A competição foi realizada de 5 de abril a 5 de junho, ou seja, apenas 2 meses, o que parece bastante pequeno. Nossa equipe conseguiu se unir e participar da competição apenas em maio, o que nos fez aprender muito em qualquer lugar.
Linhas de base
Como linhas de base, foram fornecidos guias de treinamento completos para o treinamento Rainbow (abordagem DQN) e PPO (abordagem Gradiente de Política) em um dos níveis possíveis no Sonic e o envio do agente resultante.
A versão Rainbow foi baseada no pouco conhecido projeto anyrl , mas o PPO usou as boas e antigas linhas de base do OpenAI e nos pareceu muito mais preferível.
As linhas de base publicadas diferiam das abordagens descritas no artigo por sua maior simplicidade e conjuntos menores de "hacks" para acelerar o aprendizado. Assim, os organizadores lançaram idéias e definiram a direção, mas a decisão sobre o uso e a implementação dessas idéias foi deixada para o participante da competição.
Em relação às idéias, gostaria de agradecer à OpenAI pela abertura e, individualmente, a John Schulman pelos conselhos, idéias e sugestões que ele expressou no início desta competição. Nós, como muitos participantes (e ainda mais novos no mundo da RL), isso nos permitiu focar melhor no objetivo principal da competição - o aprendizado de meta e a melhoria da generalização de agentes, sobre os quais falaremos agora.
Características da avaliação da decisão
A coisa mais interessante começou no momento da avaliação dos agentes. Em competições / benchmarks típicos de RL, os algoritmos são testados no mesmo ambiente em que foram treinados, o que contribui para algoritmos que são bons em lembrar e têm muitos hiperparâmetros. No mesmo concurso, o teste do algoritmo foi realizado nos novos níveis do Sonic (que nunca foram mostrados a ninguém), desenvolvidos pela equipe OpenAI especificamente para este concurso. A cereja do bolo foi o fato de que, no processo de teste, o agente também recebeu uma recompensa durante a passagem do nível, o que possibilitou a reciclagem direta no processo de teste. No entanto, neste caso, vale a pena lembrar que os testes eram limitados em tempo - 24 horas e em ticks de jogo - 1 milhão. Ao mesmo tempo, a OpenAI apoiou fortemente a criação de agentes que poderiam rapidamente treinar para novos níveis. Como já mencionado, obter e estudar essas soluções foi o principal objetivo da OpenAI durante esta competição.
No ambiente acadêmico, a direção do estudo de políticas que podem se adaptar rapidamente a novas condições é chamada meta-aprendizagem e, nos últimos anos, vem se desenvolvendo ativamente.
Além disso, em contraste com as competições normais do kaggle, em que todo o envio se resume ao envio do seu arquivo de resposta, nesta competição (e de fato nas competições de RL) a equipe era obrigada a agrupar sua solução em um contêiner de docker com a API especificada, coletá-la e enviá-la imagem do docker. Isso aumentou o limiar para entrar na competição, mas tornou o processo de decisão muito mais honesto - os recursos e o tempo para a imagem do docker eram limitados, respectivamente, algoritmos muito pesados e / ou lentos simplesmente não passaram na seleção. Parece-me que essa abordagem de avaliação é muito mais preferível, pois permite que pesquisadores sem um “cluster doméstico de DGX e AWS” competam em pé de igualdade com os amantes dos modelos 50000 de vidro. Espero ver mais desse tipo de competição no futuro.
A equipe
Kolesnikov Sergey ( scitator )
Entusiasta da RL. Na época da competição, um estudante do Instituto de Física e Tecnologia de Moscou, MIPT, escreveu e defendeu um diploma do NIPS do ano passado: Aprendendo a Executar a competição (um artigo sobre o qual também deveria ser escrito).
Senior Data Scientist @ Dbrain - Apresentamos concursos prontos para produção com docker e recursos limitados para o mundo real.
Pavlov Mikhail ( fgvbrt )
Desenvolvedor de pesquisa sênior DiphakLab . Participou e ganhou repetidamente prêmios em hackathons e competições de treinamento reforçadas.
Sergeev Ilya ( sergeevii123 )
Entusiasta da RL. Eu bati em um dos hackathons RL do Deephack e tudo começou. Data Scientist @ Avito.ru - visão computacional para vários projetos internos.
Sorokin Ivan ( lítico )
Envolvido no reconhecimento de fala em speechpro.ru .
Abordagens e Solução
Após testes rápidos das linhas de base propostas, nossa escolha recaiu sobre a abordagem OpenAI - PPO, como uma opção mais formada e interessante para o desenvolvimento de nossa solução. Além disso, a julgar pelo artigo desta competição, o agente da OPP lidou com a tarefa um pouco melhor. Do mesmo artigo, nasceram as primeiras melhorias que usamos em nossa solução, mas as primeiras coisas primeiro:
Treinamento colaborativo de PPO em todos os níveis disponíveis
A linha de base estabelecida foi treinada em apenas um dos 27 níveis Sonic disponíveis. No entanto, com a ajuda de pequenas modificações, foi possível paralelizar o treinamento de uma só vez para todos os 27 níveis. Devido à maior diversidade no treinamento, o agente resultante teve uma generalização muito maior e uma melhor compreensão do dispositivo do mundo Sonic e, portanto, lidou melhor com uma ordem de magnitude.
Treinamento adicional durante o teste
Voltando à idéia principal da competição, o meta-aprendizado, foi necessário encontrar uma abordagem que tivesse a máxima generalização e pudesse se adaptar facilmente a novos ambientes. E para a adaptação, foi necessário treinar novamente o agente existente para o ambiente de teste, o que, de fato, foi realizado (em cada nível de teste, o agente executava 1 milhão de etapas, o que era suficiente para se adaptar a um nível específico). No final de cada um dos jogos de teste, o agente avaliou o prêmio recebido e otimizou sua política usando a história recém-recebida. É importante observar aqui que, com essa abordagem, é importante não esquecer toda a sua experiência anterior e não se degradar em condições específicas, o que, em essência, é o principal interesse do meta-aprendizado, pois esse agente perde imediatamente toda a sua capacidade de generalização.
Bônus de exploração
Ao aprofundar-se nas condições de remuneração de um nível, o agente recebeu uma recompensa por seguir adiante na coordenada x, respectivamente, ele poderia ficar preso em alguns níveis, quando era necessário avançar e voltar. Foi decidido adicionar uma recompensa ao agente, a chamada exploração baseada em contagem , quando o agente receberia uma pequena recompensa se estivesse em um estado em que ainda não estava. Dois tipos de bônus de exploração foram implementados: com base na figura e com a coordenada x do agente. Uma recompensa baseada em uma imagem foi calculada da seguinte forma: para cada local de pixel na imagem, era contada quantas vezes cada valor ocorreu para um episódio, a recompensa era inversamente proporcional ao produto em todos os locais de pixel de quantas vezes os valores nesses locais foram encontrados para um episódio. A recompensa baseada na coordenada x foi considerada de maneira semelhante: para cada coordenada x (com uma certa precisão) era contada quantas vezes o agente estava nessa coordenada para o episódio, a recompensa é inversamente proporcional a esse valor para a coordenada x atual.
Experimentos de mistura
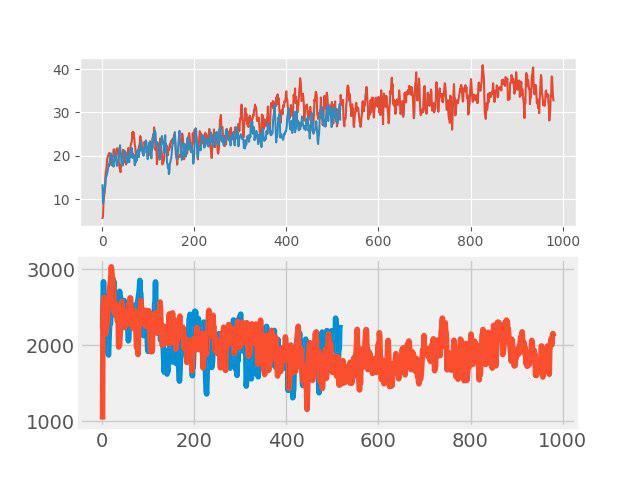
Recentemente, ao “ensinar com um professor” um método simples mas eficaz de aumento de dados, o chamado confusão. A idéia é muito simples: a adição de duas imagens de entrada arbitrárias é feita e uma soma ponderada dos rótulos correspondentes é atribuída a essa nova imagem (por exemplo, 0,7 cão + 0,3 gato). Em tarefas como classificação de imagem e reconhecimento de fala, a mixagem mostra bons resultados. Portanto, foi interessante testar esse método para RL. O aumento foi feito em todos os lotes grandes, consistindo em vários episódios. As imagens de entrada eram misturadas em pixels, mas com tags nem tudo era tão simples. Os valores retornos, valores e neglogpacs foram combinados por uma soma ponderada, mas a ação (ações) foi escolhida no exemplo com o coeficiente máximo. Essa solução não mostrou um aumento tangível (embora, ao que parece, devesse ter havido um aumento na generalização), mas não piorou a linha de base. Os gráficos abaixo comparam o algoritmo PPO com confusão (vermelho) e sem confusão (azul): na parte superior é a recompensa durante o treinamento, na parte inferior é a duração do episódio.
Seleção da melhor política inicial
Essa melhoria foi uma das últimas e deu uma contribuição muito significativa para o resultado final. No nível do treinamento, várias políticas diferentes com diferentes hiperparâmetros foram treinadas. No nível do teste, nos primeiros episódios, cada um deles foi testado e, para treinamento adicional, foi escolhida a política que dava a recompensa máxima do teste pelo episódio.
Choque
E agora sobre a questão do que foi tentado, mas "não voou". Afinal, este não é um novo artigo da SOTA para ocultar algo.
- Mudança na arquitetura da rede: ativação SELU , atenção própria, blocos SE
- Neuroevolução
- Criando seus próprios níveis de Sonic - tudo foi preparado, mas não havia tempo suficiente
- Meta-treinamento através de MAML e REPTILE
- Conjunto de vários modelos e treinamento adicional durante o teste de cada modelo usando amostragem importante
Sumário
Após três semanas do final da competição, a OpenAI divulgou os resultados . Em 11 níveis adicionais criados adicionalmente, nossa equipe recebeu um 4º lugar honroso, depois de saltar do 8º em um teste público e ultrapassar as linhas de base obscurecidas da OpenAI.
Os principais pontos distintivos que "voaram" nos primeiros 3ki:
- Sistema de ações aprimorado (veio com seus próprios botões, removeu outros);
- Investigação de estados através de hash a partir da imagem de entrada;
- Mais níveis de treinamento;
Além disso, quero observar que, neste concurso, além de vencer, a descrição de suas decisões, bem como materiais que ajudaram outros participantes foram ativamente encorajados - houve também uma indicação separada para isso. O que, novamente, aumentou o concurso de lâmpadas.
Posfácio
Pessoalmente, gostei muito desta competição, bem como do tema de meta-aprendizado. Durante a participação, eu me familiarizei com uma grande lista de artigos (eu nem esqueci alguns deles) e aprendi um grande número de diferentes abordagens que espero aplicar no futuro.
Na melhor tradição de participar da competição, todo o código está disponível e publicado no github .