
No
artigo anterior sobre o tópico gerenciamento de risco do estado, examinamos o básico: por que as autoridades estaduais devem gerenciar riscos, onde procurá-los e quais são as abordagens para avaliar. Hoje falaremos sobre o processo de análise de risco: como identificar as causas de sua ocorrência e identificar violadores.
Avaliação de risco
Para avaliar o risco - mesmo dentro da estrutura de uma abordagem estática, embora dinâmica - você precisa encontrar suas causas, condições de ocorrência e determinar as principais características: a probabilidade e o dano potencial da implementação.
Tomemos, por exemplo, o desembaraço aduaneiro: ao importar qualquer produto para o país, exceto por uma variedade de informações diferentes (custo, peso, embalagem, remetente, destinatário etc.), uma declaração deve ser feita na declaração de acordo com um classificador especial - a nomenclatura de commodity da atividade econômica estrangeira (FEA). Esse código para as mercadorias determina o imposto de acordo com a tarifa alfandegária (taxas TN FEA +).
A tarifa alfandegária é um classificador complexo: à primeira vista, algumas mercadorias podem ser atribuídas a diferentes códigos com diferentes taxas de imposto. Por exemplo, você pode lidar com equipamentos de mineração complexos apenas explorando seus desenhos. Daí a tentação do importador de declarar o código errado (mas semelhante à verdade) para pagar menos dinheiro ao orçamento.
Por isso,
identificamos o risco - a declaração de um código de produto não confiável na declaração para subestimar os pagamentos alfandegários. O motivo é a presença no classificador de posições “limítrofes” com diferentes taxas de imposto.
É mais difícil detectar as condições para a ocorrência de tal risco - quando e com que bens acontece na prática. Para fazer isso, é necessário realizar
uma análise de risco : estudar o histórico de observações de objetos de controle, descobrir quando e quem declarou o código do produto errado e identificar algumas características gerais desses casos. Isso permitirá formular
regras para o gerenciamento futuro de riscos: quais objetos atribuiremos ao risco e a que auditoria sujeitar.
A maneira mais fácil de obter essas regras é confiar no julgamento especializado de seus funcionários.
Regras do especialista
Tais regras para identificar riscos são especialistas no assunto. Eles são guiados por sua experiência profissional ou resumem as opiniões de colegas que todos os dias encontram violadores. O resultado são julgamentos simples da forma "se ... então ...".
A probabilidade de ocorrência de risco e o dano potencial da ameaça nesse caso são determinados "a olho" ou por estimativas aproximadas.
A vantagem das regras especializadas é a facilidade de compilação e interpretação pelo homem. A desvantagem é que um grande número de pessoas, violadores e sujeitos respeitáveis da atividade econômica, pode simultaneamente se enquadrar na regra. Portanto, a eficácia do controle será baixa. Ao mesmo tempo, alguns infratores passarão, pelos quais o especialista não pôde detectar e levar em conta os padrões.
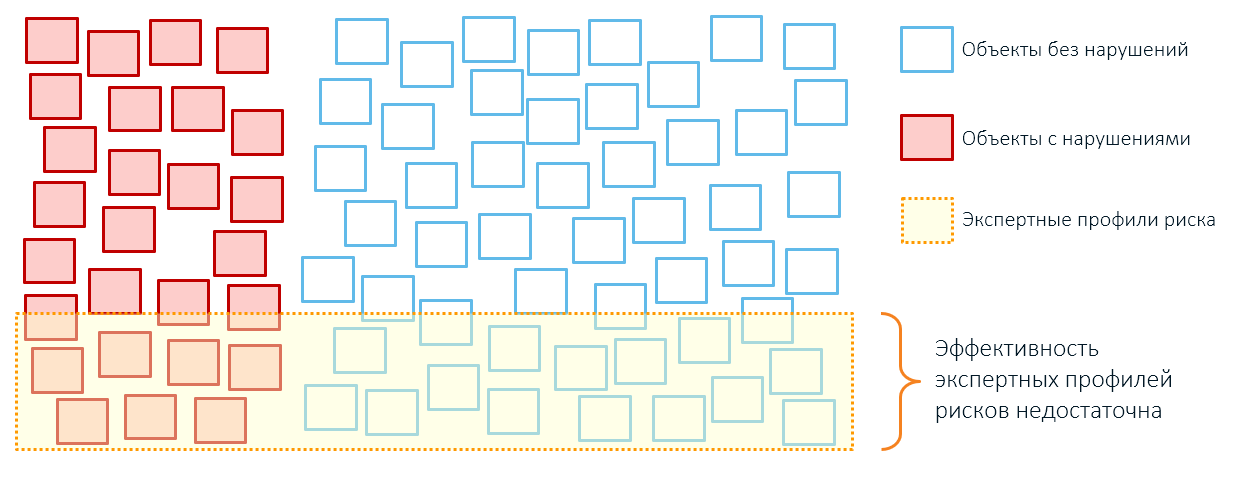
Por exemplo, uma regra especializada para controle alfandegário nos diz que todos os lotes de maçãs com um valor abaixo de um determinado limite estão relacionados a entregas de risco:

Quando realizamos o controle, encontraremos mercadorias com irregularidades (vermelho) e entregas bastante normais (verde), cujo baixo custo é explicado por descontos individuais, pela luta do remetente com o excesso de estoque ou pelo modelo econômico de empresas.
Qualquer coisa acima desse limite de valor condicional (linha vermelha) ficará fora de controle (círculos em cinza). Mas se as verificarmos também, encontraremos entregas verdadeiramente legítimas e entregas cujo valor real é ainda maior do que o declarado na declaração (círculos cinzentos com um contorno tracejado vermelho) e pelas quais os pagamentos alfandegários não são pagos integralmente.
Portanto, a aplicação de regras especializadas geralmente leva a cobertura excessiva de objetos de controle e baixo desempenho (lembra-se, nossas caixas do primeiro artigo?):
Especialistas não devem ser responsabilizados: a consciência humana é limitada nos objetos com os quais pode operar (um artigo curioso foi publicado no Habr uma vez, cujo autor sugeriu que seu número é limitado a sete). Daí as grandes pancadas em vez dos detalhes exatos: digamos, o risco de incêndio é determinado apenas pelo ano em que o prédio foi construído, a área de localização e a categoria de moradores. Todas essas características "brincaram": um incêndio explodiu em uma casa antiga, um quarto pegou fogo em uma área disfuncional. Portanto, os especialistas esperam ameaças futuras precisamente de objetos desse tipo.
Mas nem todos esses edifícios "perigosos" vão realmente queimar, mesmo que caiam sob a regra dos especialistas: muitas casas antigas e de madeira permanecem como se nada tivesse acontecido. Algumas casas disfuncionais permanecem sem fogo há anos. Só que o especialista não pode levar em consideração algumas características individuais sutis de objetos perigosos.
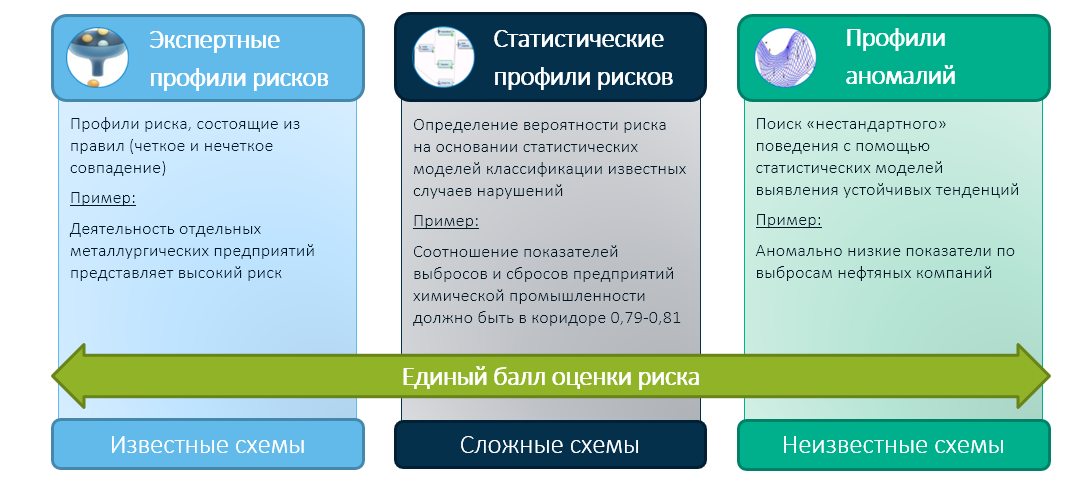
É aqui que o aprendizado de máquina entra em jogo, ajudando a criar
perfis estatísticos de risco . Eles são formados quando aplicamos tecnologias de análise de dados ao histórico de violações e informações sobre objetos controlados.
Perfis estatísticos de risco
Nesse caso, resolvemos o problema de classificação binária: um algoritmo analítico especializado determina por si mesmo quais características dos objetos tornam possível atribuí-los a "ruim" ou "bom". Se tudo for feito corretamente, no final, obteremos avaliações de risco bastante precisas: condições detalhadas e probabilidade calculada automaticamente, além de possíveis danos (que, com uma abordagem especializada, também são determinados de alguma forma "habilmente"). Essas características definem um "perfil de risco" - o que, onde, quando e quão assustador.
Os perfis estatísticos de risco são criados de maneiras diferentes. Pode ser baseado em uma árvore de decisão ou em uma floresta aleatória. Você pode aplicar uma rede neural complicada com um grande número de camadas ocultas.
Porém, na SAS acreditamos que, para fins de controle de estado, é melhor criar perfis estatísticos de risco com base em algoritmos interpretados, por exemplo,
regressão ou
árvore de decisão . A prática mostrou que é difícil para um organismo estatal se orientar, mesmo que seja uma previsão precisa, mas incompreensível, de uma máquina, se não explicar por que essa pessoa respeitada é marcada como um vilão.
O órgão estadual precisa entender exatamente quais fatores indicam uma ameaça e quais dos infratores têm as mesmas características, uma vez que existem procedimentos para a aprovação de decisões gerenciais (um caso específico dos quais são perfis de risco). O oficial deve entender exatamente o que ele lança "em batalha", uma vez que é responsável pelo resultado do perfil de risco.
Qualquer verificação deve ser justificada e essa justificação deve ser expressa em palavras. Caso contrário, você terá que corar diante do promotor e explicar como a agência estatal "aperta" os negócios domésticos com base nas instruções misteriosas de deus ex machina.
Portanto, o perfil de risco estatístico também parece uma regra que pode ser lida e compreendida. Somente a lista de características que descrevem possíveis violadores é maior e mais complexa do que a de perfis de especialistas:
 * os valores dos parâmetros do perfil são alterados e não correspondem aos reais
* os valores dos parâmetros do perfil são alterados e não correspondem aos reaisUm conjunto de
indicadores de
risco (condições) pode parecer um pouco bizarro. Mas isso não é uma “grande feitiçaria” - simplesmente com a ajuda das tecnologias de aprendizado de máquina e as informações limitadas que temos, descrevemos algum padrão oculto do comportamento humano que leva à interrupção.
O mesmo está no controle tributário - os infratores podem distinguir da massa total de contribuintes certos intervalos de quantidades de determinadas transações, prazos para apresentação de declarações, número de funcionários na equipe da empresa, número de contas e outro conjunto de 30 parâmetros diferentes que descrevem coletivamente empresários inescrupulosos que subestimam o IVA.
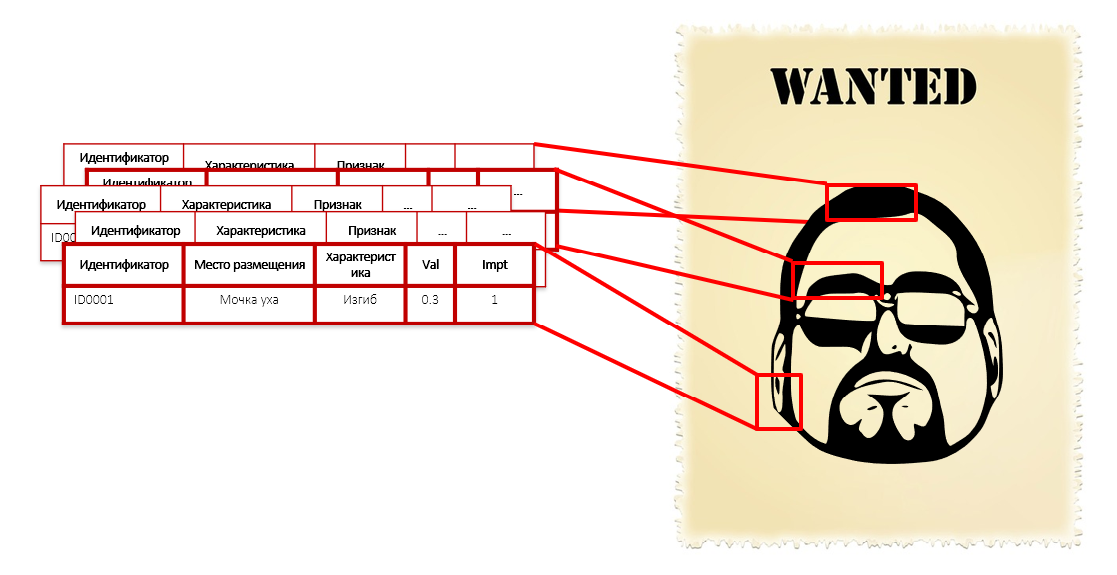
Uma pessoa não será capaz de comparar todas essas características, ela administrará com três ou cinco, que são mais fáceis de entender. E o programa pode. Tão detalhado quanto necessário. Ao construir um modelo, o algoritmo itera automaticamente sobre uma massa de dados e descobre o que os criminosos têm em comum - mesmo que seja um amor por laços vermelhos em uma rede amarela.
Isso é semelhante à descrição do criminoso em seus traços individuais: o formato do nariz, orelhas, curvatura das sobrancelhas, as cores das camisas e o comprimento do pé. Não conhecemos o rosto, a altura e o peso, mas temos milhares de características, incluindo o comprimento dos pelos da falange do dedo mindinho esquerdo. Cada um desses parâmetros individualmente não fornece intenções criminais - você não precisa algemar uma pessoa apenas pelo raio de curvatura de suas aurículas. Mas todo o conjunto dessas características forma um retrato bastante preciso do intruso:
Quando passamos de aplicar regras especializadas a perfis estatísticos com base em uma análise de padrões ocultos, eliminamos as verificações deliberadamente ineficazes. O enorme campo de controle contínuo reduz-se a um impacto pontual em objetos que se enquadram no
padrão revelado
de comportamento injusto .
Lembre-se de maçãs do exemplo da alfândega acima. Ao submeter o histórico dos cheques à entrada do modelo estatístico, obtemos um perfil de risco que leva em consideração as características comportamentais dos importadores-infratores, independentemente do preço pelo qual eles declaram as mercadorias:
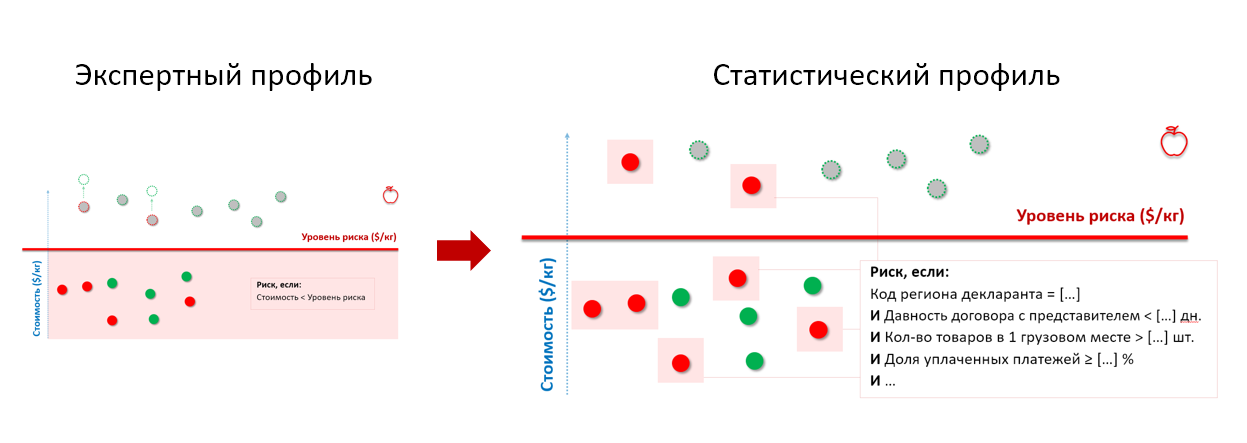 * o conjunto de parâmetros do perfil de risco foi alterado e não corresponde ao real
* o conjunto de parâmetros do perfil de risco foi alterado e não corresponde ao realÉ assim que o perfil de risco estatístico é construído usando os algoritmos da classe "árvore de decisão" - cada nível separa cada vez mais o conjunto de entidades testadas em "bom" e "ruim" e mostra qual característica de separação acabou sendo a mais significativa (na captura de tela do SAS Visual Statistics):
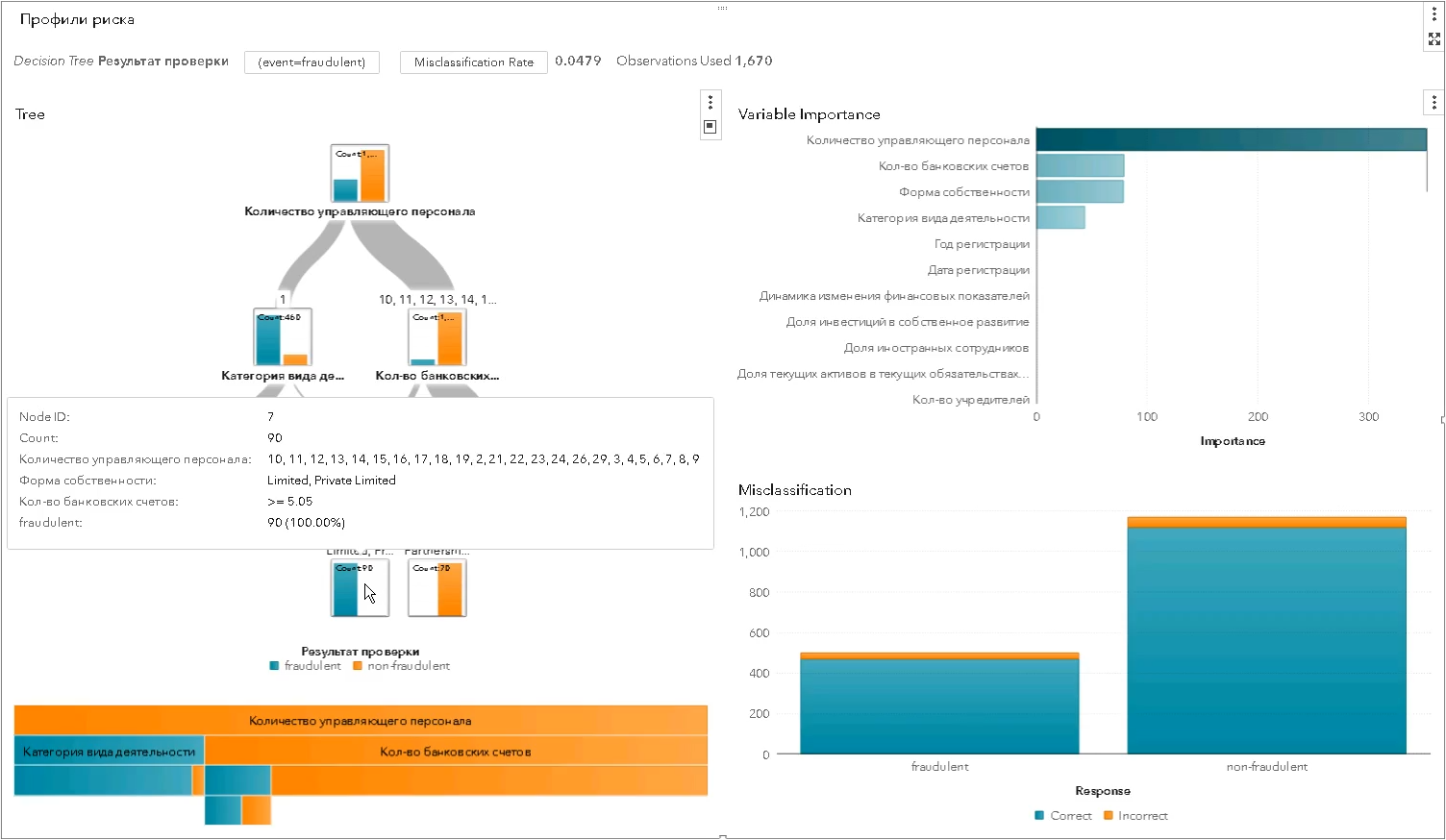
Os perfis estatísticos são melhores que os especialistas - mais precisamente, mais seletivos, imparciais. Eles ajudam a aumentar a eficácia das inspeções, reduzindo o número de "exercícios" ociosos:
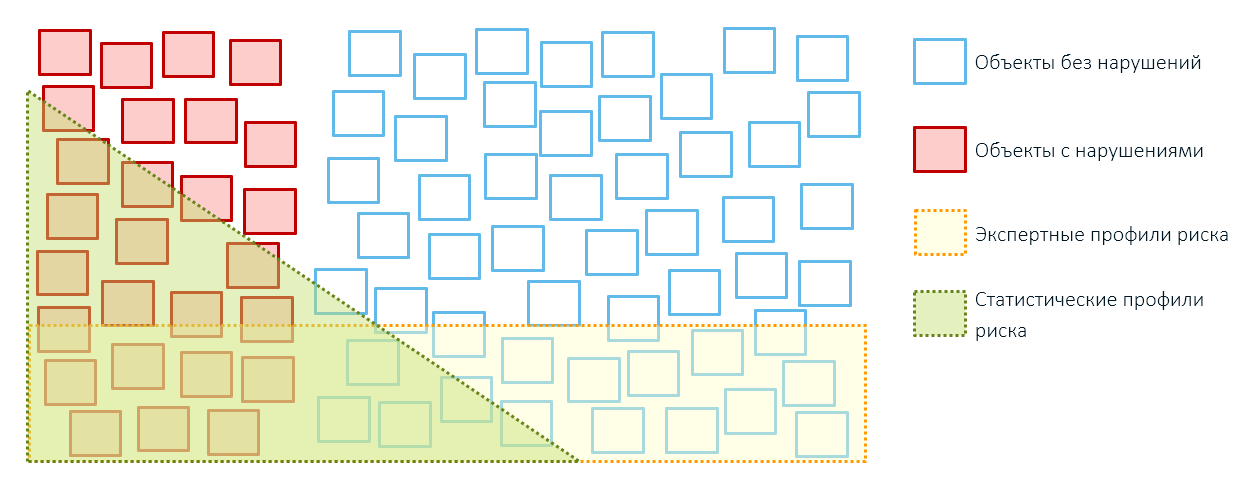
A desvantagem dos perfis estatísticos é que eles são guiados por experiências anteriores na identificação de violações. Para esquemas bem conhecidos.
Se no histórico do controle aduaneiro houver casos de subavaliação na importação de mercadorias, o algoritmo encontrará sinais de infratores e formará um perfil estatístico de risco. Se estamos procurando alguma nova violação que ainda não tenha chegado ao conhecimento da agência estatal, e não conhecemos suas características, temos que agir “por toque” - por tentativa e erro.
Pesquisa desconhecida
Você pode sentir o desconhecido de várias maneiras.
O primeiro é
a amostragem aleatória . Tomamos um objeto arbitrário (dentro de nossos poderes) - um produto, empresa, edifício ou cidadão - e o consideramos cuidadosamente. A abordagem é razoavelmente imparcial, mas não muito eficaz - um sujeito respeitável também pode se enquadrar em "interrogatório". A força da agência estatal e o dinheiro do orçamento serão gastos em vão.
O segundo é a
identificação de anomalias . Nesse caso, um objeto é levado para verificação, cujos parâmetros são diferenciados dos demais. Quando analisamos eventos anormais, e não apenas "cutucamos" aleatoriamente um monte de objetos, a probabilidade de encontrar uma violação é maior.
Por exemplo, ao realizar a supervisão ambiental, verifica-se que a usina consome inesperadamente muita eletricidade:
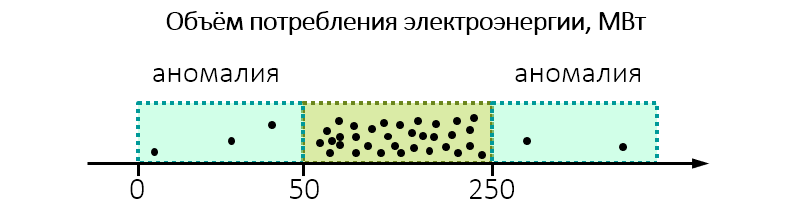
Talvez valha a pena dar uma olhada mais de perto e verificar se a usina não despeja na água ou no ar mais do que o permitido.
Ou as mercadorias na alfândega têm uma relação incomum entre o peso das mercadorias e da embalagem:
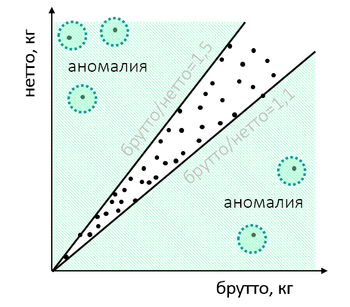
Após a verificação, pode ser que o importador tenha “brincado” com o peso, a fim de encobrir algumas violações: subestimou o custo e, portanto, queria restringir um dos valores do teste ou emitir alguns produtos sob o pretexto de outros. As características de peso "naturais", se você cavar bem, diferem das características fictícias.
No entanto, estes são os exemplos mais simples que uma pessoa é capaz de ver. Na realidade, a busca por anomalias ocorre em um espaço multidimensional de atributos - pode haver centenas deles. O algoritmo faz o que o humano não pode fazer - encontra objetos que diferem significativamente dos outros ao mesmo tempo em um grande número de sinais e determina os chamados outliers multidimensionais (na captura de tela do SAS Visual Statistics):
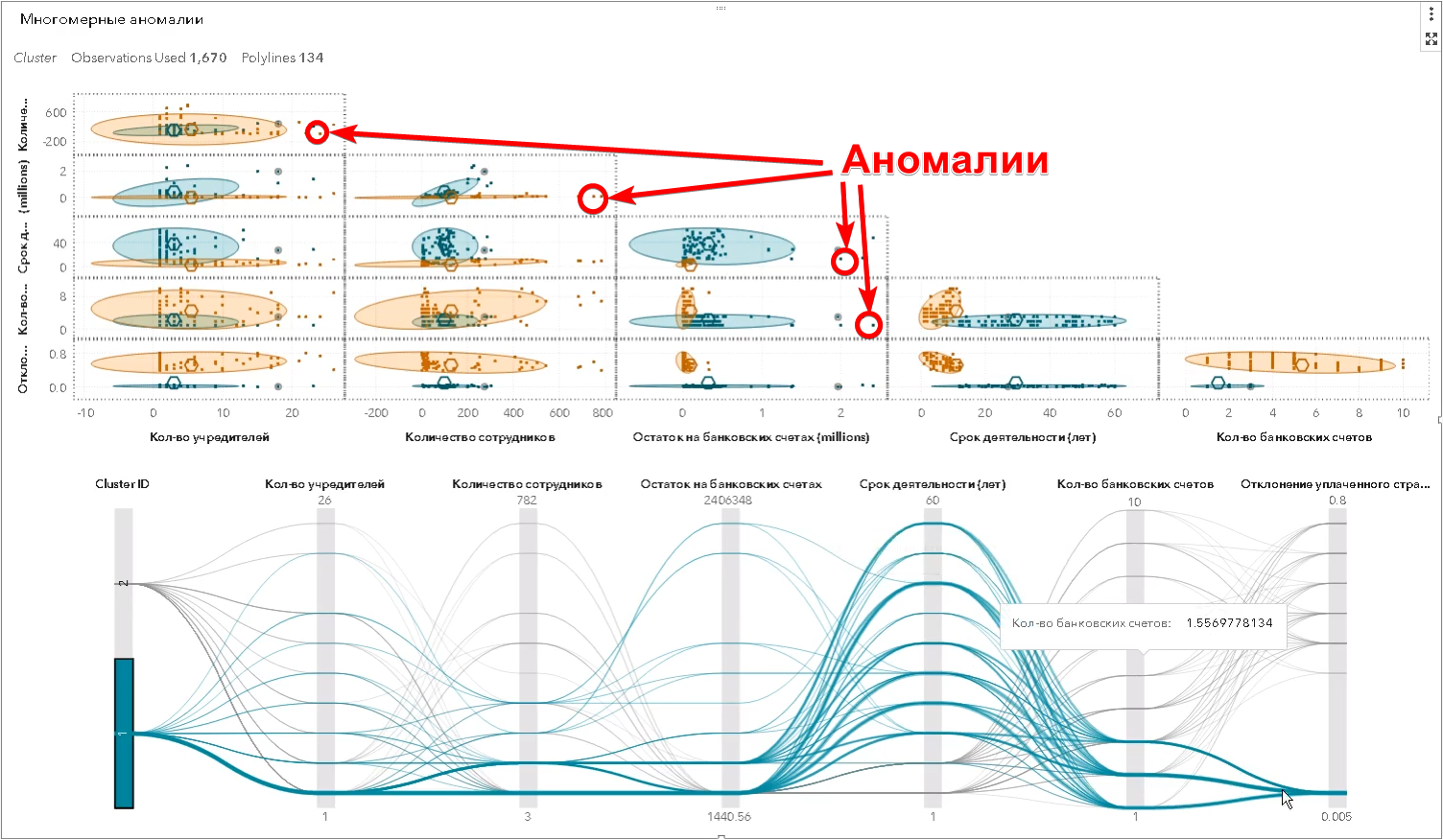
Além disso, além dos limites da percepção humana, há uma variedade de relacionamentos legais entre diferentes empresas que são visualizadas usando um gráfico (na captura de tela do SAS Social Network Analysis):
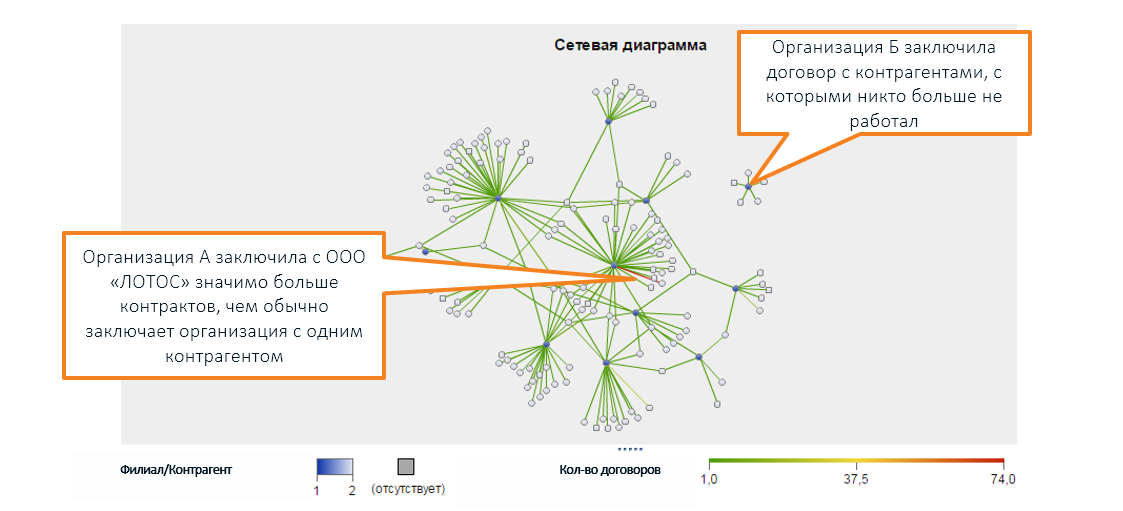 * nomes de organizações são inventados, coincidências com empresas reais são aleatórias
* nomes de organizações são inventados, coincidências com empresas reais são aleatóriasCaracterísticas incomuns não indicam necessariamente um problema. A verificação pode não mostrar nada: sim, os indicadores são estranhos, mas não há violação.
Uma anomalia não é um risco, é apenas "algo incomum". Perfis de anomalia são necessários para fornecer novas “matérias-primas” para a construção de perfis estatísticos ou especializados, uma vez que o resultado da verificação de anomalias está incluído no histórico de observações dos objetos sob controle.
Abordagem híbrida
Os melhores resultados nas atividades de controle e supervisão dos órgãos estaduais (e não apenas nele) podem ser alcançados combinando os três métodos de identificação de riscos: regras de especialistas, perfis estatísticos de riscos baseados em tecnologias de aprendizado de máquina e perfis de anomalias. Ao mesmo tempo, é melhor reduzir a cobertura de objetos com regras de especialistas, deixando-os apenas para influências administrativas específicas (por exemplo, sanções impostas - bloqueamos mercadorias desses países):
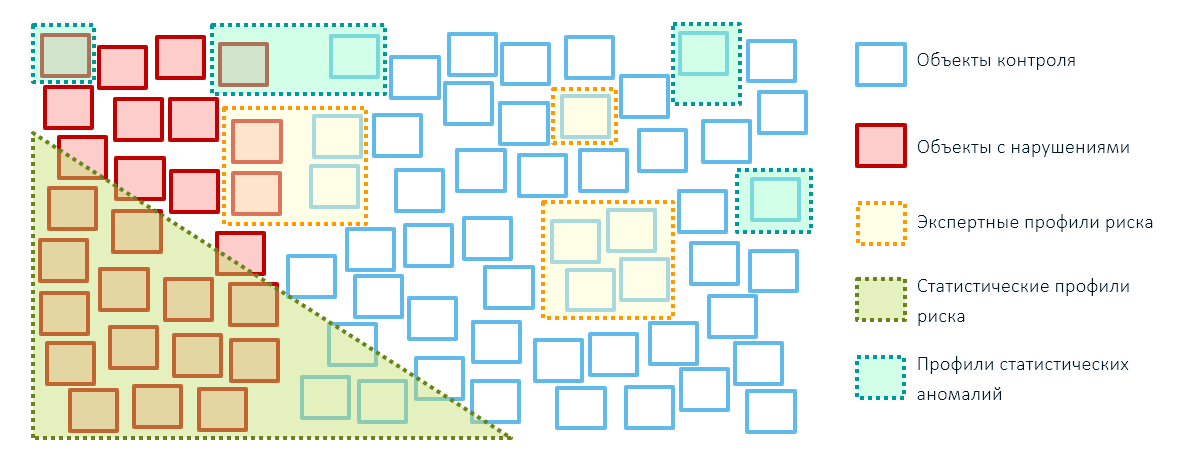
Você não pode prescindir das regras de especialistas no estágio inicial da criação de um sistema de gerenciamento de riscos, pois é necessária uma base precedente para criar modelos analíticos. Para criá-lo, será necessário realizar verificações com base em perfis de risco especializados e somente depois passar para modelos matemáticos.
Na SAS, acreditamos que o futuro da atividade de controle e supervisão do estado se baseia em uma abordagem híbrida que combinará a experiência dos órgãos estaduais e o conhecimento especializado de seus funcionários com as modernas tecnologias de aprendizado de máquina. Nesse caso, reduzimos os resultados dos três módulos em uma avaliação de risco integrada:
E já uma avaliação integrada (por exemplo, com base em uma matriz de decisão especializada) determina a escolha do órgão de controle - em quem verificar e em quem confiar.
No próximo artigo, analisaremos métodos para minimizar as ameaças identificadas e pensaremos por que o feedback e a reavaliação dinâmica de riscos são tão importantes.