Como parte do suporte ao produto, atendemos constantemente as solicitações dos usuários. Este é um processo padrão. E, como qualquer processo, ele precisa ser regularmente avaliado e aprimorado criticamente.
Conhecemos alguns problemas sistemáticos que seriam bons de resolver e, se possível, sem atrair recursos adicionais:
- Erros no envio de aplicativos: recebemos algo "estranho", outras equipes às vezes recebem algo "nosso".
- é difícil avaliar a "complexidade" do aplicativo. Se o aplicativo for complexo, poderá ser repassado a um analista forte e, com um simples, o iniciante lidará com isso.
A solução para qualquer um desses problemas afetará positivamente a velocidade dos aplicativos de processamento.
A aplicação do aprendizado de máquina, aplicada à análise do conteúdo do aplicativo, parece uma oportunidade real para melhorar o processo de despacho.
No nosso caso, o problema pode ser formulado pelos seguintes problemas de classificação:
- Verifique se a solicitação está atribuída corretamente a:
- unidade de configuração (uma das 5 da aplicação ou "outras")
- categorias de serviço (incidente, solicitação de informações, solicitação de serviço)
- Estime o tempo esperado para fechar a solicitação (como um indicador de alto nível de "complexidade").
O que e como vamos trabalhar
Para criar o algoritmo, usaremos o "conjunto padrão": Python com a biblioteca scikit-learn.
Para uma aplicação real, serão implementados 2 cenários:
Treinamento:
- obtendo dados de "treinamento" do rastreador de aplicativos
- executando um algoritmo para treinar um modelo, salvando um modelo
Uso:
- recebendo dados do rastreador de aplicativos para classificação
- carregamento de modelo, classificação de aplicativos, salvamento de resultados
- atualização de aplicativos no rastreador com base na classificação
Tudo relacionado ao pipeline (interação com o rastreador) pode ser implementado em qualquer coisa. Nesse caso, os scripts do PowerShell foram escritos, embora fosse possível continuar em python.
O algoritmo de aprendizado de máquina receberá dados de classificação / treinamento na forma de um arquivo .csv. Os resultados processados também serão gerados em um arquivo .csv.
Dados de entrada
Para tornar o algoritmo o mais independente possível da opinião das equipes de serviço, levaremos em consideração apenas os dados recebidos do criador do aplicativo como parâmetros de entrada do modelo:
- Breve descrição / título (texto)
- Uma descrição detalhada do problema, se houver (texto). Esta é a primeira mensagem no fluxo de comunicação do aplicativo.
- Nome do cliente (funcionário, categoria)
- Nomes de outros funcionários incluídos na lista de observação a pedido (lista de funcionários)
- Hora de apresentação do pedido (data / hora).
Conjunto de dados de treinamento
Para o treinamento dos algoritmos, foram utilizados dados de chamadas fechadas nos últimos 3 anos - ~ 3.500 registros.
Além disso, para ensinar ao classificador o reconhecimento de "outras" unidades de configuração, aplicativos fechados processados por outros departamentos para outras unidades de configuração foram adicionados ao conjunto de treinamento. Total de registros adicionais - cerca de 17.000.
Para todos esses pedidos adicionais, a unidade de configuração será definida como "outro"
Pré-tratamento
Text
O pré-processamento de texto é extremamente simples:
- Traduzimos tudo para minúsculas
- Deixe apenas números e letras - substitua o resto por espaços
Lista de notificações (watchlist)
A lista está disponível para análise na forma de uma sequência na qual os nomes são apresentados na forma de Sobrenome, Nome e são separados por ponto e vírgula. Para análise, vamos convertê-lo em uma lista de strings.
Ao combinar as listas, obtemos um conjunto de nomes exclusivos com base em todos os aplicativos do conjunto de treinamento. Esta lista geral formará um vetor de nomes.
Duração do processamento do aplicativo
Para nossos propósitos (gerenciamento de prioridades, planejamento de liberação), basta atribuir o aplicativo a uma determinada classe pela duração do serviço. Também permite transferir a tarefa da regressão para a classificação com um pequeno número de classes.
Text
- Combine o "título" e "descrição do problema".
- Passe para TfidfVectoriser para formar um vetor de palavras
Nome do solicitante
Como é esperado que a pessoa que criou o aplicativo seja um atributo importante de classificação adicional - o traduziremos em um dos códigos individualmente usando o DictionaryVectorisor
Nomes das pessoas incluídas na lista de notificações
A lista de pessoas incluídas nos aplicativos da lista de observação será convertida em um vetor com base em todos os nomes preparados anteriormente: se a pessoa estava na lista, o componente correspondente será definido como 1, caso contrário - como 0. Um aplicativo pode ter várias pessoas na lista de observação - respectivamente, vários componentes terá um único valor.
Data de criação
A data de criação será apresentada como um conjunto de atributos numéricos - ano, mês, dia do mês, dia da semana.
Isso é feito sob a suposição de que:
- A velocidade de processamento do aplicativo varia ao longo do tempo
- A velocidade de processamento tem um fator sazonal
- O dia da semana (especialmente aplicativos de final de semana) pode ajudar a identificar a unidade de configuração e a categoria de serviço
Modelo de treinamento
Algoritmo de classificação
Para as três tarefas de classificação, foi utilizada regressão logística. Ele suporta a classificação multiclasse (no modelo Um vs Todos), aprende rapidamente.
Para treinar modelos que definem a categoria de serviço e a duração dos aplicativos de processamento, usaremos apenas aplicativos que obviamente pertencem às nossas unidades de configuração.
Resultados de aprendizagem
Definindo unidades de configuração
O modelo demonstra altos indicadores de integridade e precisão ao atribuir aplicativos a unidades de configuração. Além disso, o modelo define bem os eventos quando os aplicativos se referem a unidades de configuração estrangeiras.
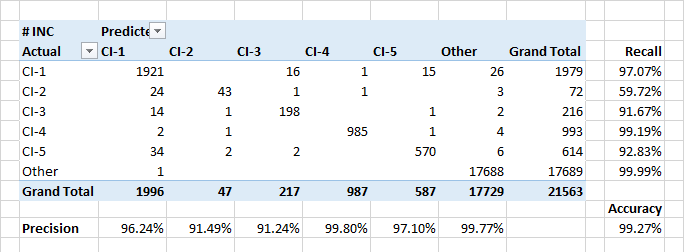
A completude relativamente baixa da classe CI-2 é parcialmente devida a erros reais de classificação nos dados. Além disso, os CI-2 apresentam aplicativos "técnicos" executados para outros ICs. Portanto, em termos de descrição e dos usuários envolvidos, esses aplicativos podem ser semelhantes aos aplicativos de outras classes.
Os atributos mais significativos para classificar aplicativos como CI-? era esperado que os nomes de clientes de aplicativos e pessoas incluídas na folha de alerta. Mas havia algumas palavras-chave que estavam nos primeiros 30 ke em importância. A data de criação do aplicativo não importa.
Definição da categoria de aplicativo
A qualidade da classificação por categorias acabou sendo um pouco menor.
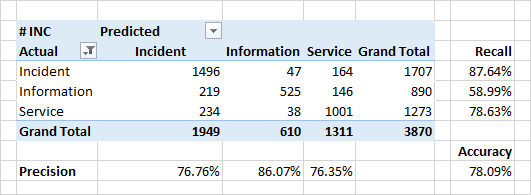
Um motivo muito sério para a incompatibilidade das categorias e categorias previstas nos dados de origem são erros reais nos dados de origem. Por vários motivos organizacionais, a classificação pode estar incorreta. Por exemplo, em vez de um "incidente" (um defeito no sistema, comportamento inesperado do sistema), o aplicativo pode ser marcado como "informações" ("não é um bug - é um recurso") ou "serviço" ("sim, está quebrado, mas apenas o reiniciamos - e tudo ficará bem ").
A identificação de tais inconsistências é uma das tarefas do classificador.
Atributos significativos para classificação no caso de categorias são palavras do conteúdo dos aplicativos. Para incidentes, estas são as palavras "erro", "correção", "quando". Existem também palavras que indicam alguns módulos do sistema - esses são os módulos com os quais os usuários trabalham diretamente e observam o aparecimento de erros diretos ou indiretos.
Curiosamente, para aplicativos definidos como "serviço" - as principais palavras também definem alguns módulos do sistema. Uma ocasião para pensar, verificar e finalmente repará-los.
Determinando o tempo de processamento do aplicativo
O mais fraco foi prever a duração do processamento de aplicativos.
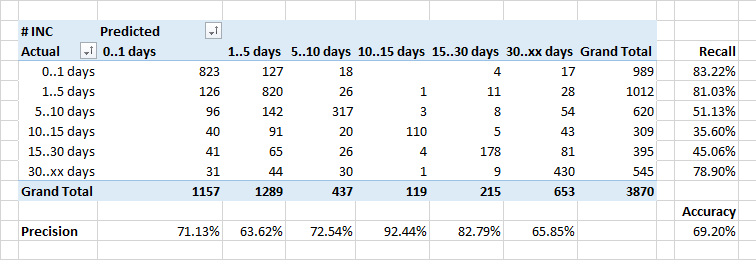
Em geral, a dependência do número de aplicativos que são fechados por um determinado tempo deve parecer idealmente o inverso do expoente. Mas, levando em consideração o fato de que alguns incidentes exigem correções no sistema, e isso é feito como parte de liberações regulares, a duração da execução de alguns aplicativos aumenta artificialmente.
Portanto, talvez o classificador classifique alguns aplicativos "longos" como "mais rápidos" - ele não sabe o tempo das liberações planejadas e acredita que o aplicativo precisa ser fechado mais rapidamente.
Esta também é uma boa razão para pensar ...
Implementação do modelo como uma classe
O modelo é implementado como uma classe que encapsula todas as classes de scikit-learn usadas - escala, vetorização, classificador e configurações significativas.
A preparação, o treinamento e o uso subsequente do modelo são implementados como métodos de classe, com base em objetos auxiliares.
A implementação de objeto permite gerar convenientemente versões derivadas do modelo que usam outras classes de classificadores e / ou prever os valores de outros atributos do conjunto de dados original. Tudo isso é feito sobrescrevendo métodos virtuais.
No entanto, todos os procedimentos de preparação de dados podem permanecer comuns a todas as opções.
Além disso, a implementação do modelo na forma de um objeto tornou possível resolver naturalmente o problema do armazenamento intermediário do modelo treinado entre as sessões de uso - por meio de serialização / desserialização.
Para serializar o modelo, foi utilizado o mecanismo padrão do Python, pickle / unpickle.
Como permite serializar vários objetos no mesmo arquivo, isso ajudará a salvar consistentemente a recuperação de vários modelos incluídos no fluxo de processamento geral.
Conclusão
Os modelos resultantes, mesmo sendo relativamente simples, fornecem resultados muito interessantes:
- identificou "omissões" sistemáticas na classificação por categoria
- ficou claro quais partes do sistema estão associadas a problemas (aparentemente - não sem razão)
- Os tempos de processamento dos aplicativos dependem claramente de fatores externos que precisam ser aprimorados separadamente.
Ainda temos que reconstruir os processos internos com base nas "dicas" recebidas. Mas mesmo esse pequeno experimento tornou possível avaliar o poder dos métodos de aprendizado de máquina. E também, despertou interesse adicional da equipe na análise de seu próprio processo e sua melhoria.