
Migrar sistemas de TI não é uma tarefa fácil. Mas a dificuldade específica é a situação em que você precisa não apenas mudar do ferro velho para o novo, mas também mudar para um novo sistema operacional no equipamento existente e sem migrar dados produtivos. Uma dessas medidas durou cerca de um ano, a maioria das quais foi preparada.
O cliente possui dois sites em cidades diferentes e cada um possui dois sistemas de armazenamento de dados conectados. As informações de um sistema de armazenamento usando as ferramentas de replicação internas são enviadas para o segundo. O gerenciamento é realizado usando um sistema de backup externo. Em uma cidade, dois sistemas NetApp 3250 estão instalados, na outra - o NetApp 6220 principal e o NetApp 3250 de backup. O cliente planeja expandir esse complexo no futuro, adicionar discos e atualizar controladores.
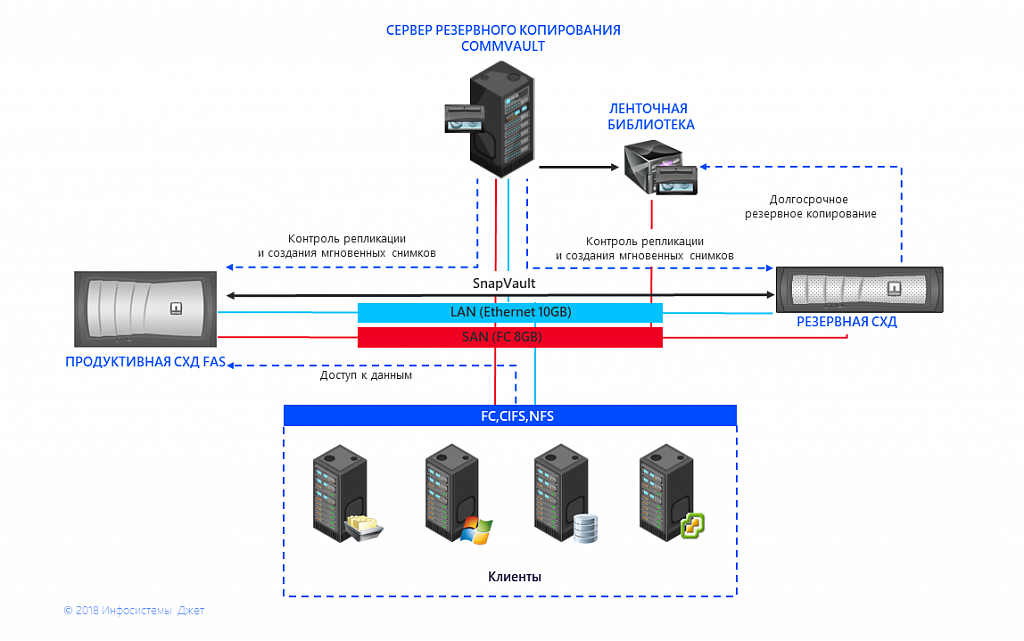 Fig. 1 Esquema de interação de sistemas de armazenamento e IBS
Fig. 1 Esquema de interação de sistemas de armazenamento e IBSE o principal problema está relacionado a isso - o fim do suporte. Para o sistema operacional Data ONTAP 8.2 de 7 modos instalado no sistema de armazenamento, não há grandes atualizações há alguns anos, e o lançamento de correções de erros críticos será interrompido em 2021. Unidades e controladores mais novos não são compatíveis com o sistema operacional herdado.
A solução é a transição para o sistema de cluster ONTAP 9.1 como o último suportado para esses controladores de armazenamento. Suas principais vantagens são:
- Escalonamento horizontal combinando-se em um único cluster tolerante a falhas, o que permitirá criar um sistema único com base no armazenamento produtivo e no SRK.
- Balanceamento de carga entre controladores, discos e movimentação de dados dentro do sistema de armazenamento sem interromper o serviço e interromper o acesso aos aplicativos.
- Manutenção de hardware e software de sistemas de armazenamento de dados sem interrupção de seu trabalho e interrupção de serviço.
- A capacidade de criar configurações heterogêneas de cluster, incluindo controladores e discos de vários tipos, incluindo sistemas de armazenamento de terceiros, sujeitos ao uso de licenças para virtualização de sua capacidade de disco.
- Capacidade de usar o SSD como uma camada de cache para agregados.
- Operação otimizada dos mecanismos de compactação de dados (compactação e desduplicação).
Existem 3 opções para migrar do modo 7 para o modo de cluster:
- Migrando com replicação de dados usando a Netapp 7-Mode Transition Tool (7MTT) e a transição baseada em cópia (CBT). Para isso, é necessário um segundo sistema de armazenamento com um espaço em disco menor e replicação em fases com base no SnapMirror. Para cada serviço, a comutação é coordenada e executada em um determinado momento.
Em um de nossos clientes, já fizemos esse procedimento no cluster do metrô. Devido ao grande número de volumes, LUNs (> 400) e à longa coordenação de detalhes, paradas, etc. a migração levou cerca de 3 meses, excluindo o treinamento. - Migre sem mover dados usando a Netapp 7-Mode Transition Tool (7MTT) e a transição sem cópia (CFT). Para fazer isso, você precisa de um segundo sistema de armazenamento com um número mínimo de discos que, após preparação preliminar, alterne o subsistema de disco produtivo. Para todos os serviços, um grande tempo de inatividade é acordado.
- Migração com cópia de dados usando ferramentas de host. Esse é o caminho de migração tradicional entre os sistemas de armazenamento de qualquer fabricante.
Como os sistemas de armazenamento existentes ainda estavam sob o suporte do fornecedor e o desempenho dos controladores no futuro próximo era suficiente, o orçamento para a compra de novos controladores não foi alocado. Nesse sentido, foi decidido migrar os controladores para o modo de cluster usando o 7MTT CFT. Um dos principais requisitos foi a ausência de interrupções visíveis na operação dos sistemas de armazenamento: a maioria dos sistemas deve funcionar sem problemas nos dias úteis. Portanto, o principal trabalho de migração em um sistema de armazenamento produtivo foi agendado para o fim de semana.
A fase de preparação começou com a coleta de informações do sistema de armazenamento e a realização de verificações preliminares. O software especializado da NetApp 7MTT gera uma lista de alertas que podem interferir na migração ou falhar ao concluí-la. Por exemplo, para um dos sistemas, essa lista consistia em mais de 200 itens. Era necessário atualizar todos os sistemas para as últimas versões suportadas do sistema operacional, atualizar o firmware dos controladores, prateleiras de disco e os próprios discos. Além disso, o novo sistema operacional possui uma lógica de operação diferente, exigindo endereços IP e conexões adicionais entre os sistemas de armazenamento.
O fator de parada foi descoberto rapidamente - o cliente usou a tecnologia baseada não em toda a replicação do volume, mas na replicação qtree (uma subseção à qual se aplicam restrições de acesso, volume etc.) E é impossível migrar esses relacionamentos do SnapVault para o novo sistema operacional . Como resultado, antes de iniciar o trabalho, seria necessário remover completamente todas as cópias de replicação. Para garantir que o cliente após a movimentação não tenha sido deixado sem backups, um backup com base em toda a replicação de volume foi iniciado antes da migração. Usando o SnapMirror, novos backups foram criados próximos aos antigos e um log de alterações foi acumulado ao longo de quatro semanas. E se em um dos sites havia espaço suficiente para isso, no segundo espaço era limitado, era necessário fazer gradualmente cópias de um dos volumes. Após quatro semanas, os relacionamentos antigos foram removidos e os novos, criados. Um processo em fases bastante demorado, que levou cerca de 1,5 meses no caso de um site e mais de 3 no segundo. Além disso, quero observar que o procedimento para interromper o relacionamento do Snapvault é acompanhado pela remoção do qtree de destino e sua velocidade de execução depende fortemente do número de arquivos e, em menor grau, do seu tamanho. Por exemplo, qtree com 4 milhões de arquivos e um tamanho de 500 GB foi excluído em 24 horas.
No processo, várias dificuldades surgiram. A burocratização dos processos de mudanças nos sistemas dos clientes aumentou os termos de coordenação do trabalho. Felizmente, conseguimos concordar em resolver problemas técnicos diretamente, discutindo em um nível superior apenas questões “ideológicas” importantes, como concordar com um plano de trabalho e escolher datas específicas para a migração.
As dificuldades foram causadas pelo uso de armazenamento temporário. Sob a orientação do 7MTT, configuramos os dois sistemas de armazenamento de acordo com os requisitos e as pré-verificações. Depois, desligaram o armazenamento antigo e conectaram as prateleiras do disco ao novo. Verifiquei tudo novamente. Do ponto de vista do software NetApp, o processo de migração é concluído e todos se dispersam
atrás do champanhe . Mas o próximo passo foi retornar tudo aos antigos controladores de clientes. O fato é que essa transição - de novos controladores para antigos - não é oficialmente suportada. Depois de voltar, o sistema operacional começou a apresentar erros e reclamar de problemas com o cluster. Após a pesquisa, pude descobrir que o problema se deve ao fato de o cluster ter mudado repentinamente para o modo comutado e não querer retornar ao switchless. Demorou muito tempo para corrigir o erro. Os problemas com o lançamento do cluster foram resolvidos ao não conectar os cabos que levavam à rede de combate na inicialização, a rede intra-cluster foi levantada em um cabo e o segundo foi adicionado. A propósito, deve-se lembrar que em controladores mais antigos e versões mais antigas do sistema operacional, a rede intra-cluster só pode ser aumentada em determinadas portas de um intervalo limitado de adaptadores, por exemplo, no FAS3250, são e1a e e2a (o cliente precisou comprar placas Ethernet de 10GB).
Eles reservaram tempo extra para o trabalho no segundo local, na esperança de evitar pelo menos alguns dos problemas, mas isso não ajudou - o sistema operacional se comportou de forma imprevisível. O gráfico foi deslocado duas vezes. No primeiro caso, quando estávamos trabalhando com o FAS3250, não foi possível migrar sistemas de combate operando 24 horas por dia, 7 dias por semana, devido a um erro nas configurações recentemente alteradas da infraestrutura de rede do cliente (embora ao testar a migração uma semana antes do início do trabalho, tudo voou). O vMotion copiou máquinas virtuais a uma velocidade inferior a 1 Mbps para um sistema de armazenamento remoto.
Durante a migração, o cliente mudou parcialmente a arquitetura. Os volumes distribuídos em sua infraestrutura VMware vSphere foram emitidos anteriormente pela NFS Ethernet. O cliente os refez e eles foram para o Fibre Channel. Durante o processo de migração, o LUN mudou completamente seu ID e, consequentemente, a VMware viu novos LUNs endereçados a ele com dados antigos e recusou-se a conectá-los permanentemente. Como resultado, graças à ajuda de especialistas da VMware, foi possível conectar esses LUNs por meio do console continuamente, indicando que este é um instantâneo dos antigos datastores. Então eu tive que reiniciar os hosts VMware. Como resultado, eles conseguiram ver máquinas virtuais e aumentar a infraestrutura virtual. E se o cliente continuasse usando o NFS, esse problema não teria surgido - o endereço IP e o nome DNS permaneceriam os mesmos de antes.
O plano de trabalho diretamente nos dias de migração:
Sexta-feira: trabalhe com sistemas de armazenamento e IBS
- Eles interromperam todas as relações entre o SnapVault e o SnapMirror, trocaram o armazenamento temporário e verificaram se os sistemas estavam prontos para a migração. Iniciamos os procedimentos para migrar o armazenamento para o 7MTT usando o método Transição livre de cópia. Regimentos de disco de combate reconectados ao controlador temporário.
- Migrado para 7MTT, migrou o volume raiz dos controladores de substituição para as prateleiras de disco do sistema de armazenamento do SRK. Instalamos novos adaptadores Ethernet, lançamos o sistema de armazenamento SRK, apagamos a configuração e baixamos a imagem do sistema operacional pela rede a partir do servidor HTTP. Instalamos novas versões do firmware e do sistema operacional (neste momento, havia problemas inexplicáveis com o download da imagem pela rede. No final, ele foi baixado diretamente do laptop).
- Substituímos os controladores no cluster pelos antigos e conectamos as prateleiras do disco de batalha ao sistema de armazenamento usando a atualização movendo o procedimento de armazenamento. Restauramos o cluster, reconfiguramos as interfaces de rede (tive que resolver problemas associados à operação incorreta do cluster) e instalamos as chaves de licença.
Sábado: trabalhe com o armazenamento principal
- Conectamos prateleiras de disco temporárias ao armazenamento temporário e as configuramos novamente.
- Máquinas virtuais importantes migraram para o armazenamento em um data center remoto usando o VMware vMotion.
- Os principais sistemas de armazenamento foram migrados para o 7MTT usando o método CFT. Eles desligaram o armazenamento principal de combate, conectaram suas prateleiras de disco ao controlador e converteram os metadados do SO em 7MTT. O volume raiz dos controladores de swap migrou para as prateleiras de disco do sistema de armazenamento SRK.
- Instalamos novos adaptadores Ethernet e lançamos o armazenamento de batalha em uma configuração sem disco, apagamos as configurações e depois baixamos pela rede a partir do servidor HTTP. Instalou novas versões de firmware e SO. Substituímos os controladores no cluster, conectamos as prateleiras do disco de combate ao sistema de armazenamento usando a atualização movendo o procedimento de armazenamento.
- Restaurou o cluster, reconfigurou as interfaces de rede (mexer com o cluster funcionando incorretamente devido às interfaces de rede de combate conectadas). Chaves de licença instaladas.
- Restauramos as conexões de armazenamento nos servidores VMware, alteramos o zoneamento na rede SAN, configuramos o mapeamento de LUNs, movemos os volumes para um SVM separado para trabalhar com o acesso ao FC. LUN conectado ao ESXi. Como o ID do LUN foi alterado, os datastores não apareceram no modo automático, tive que reiniciar consistentemente os servidores ESXi e conectar os LUNs aos comandos via esxcli.
- Reconfigurou as interfaces de batalha, renomeou os servidores CIFS e recuperou o acesso às bolas CIFS e às exportações NFS.
Domingo: Solução de problemas e configuração do software IBS
- Máquinas virtuais migraram de volta do sistema de armazenamento para o sistema de armazenamento de combate.
- Resolvemos o problema de acessar a pasta no modo de gravação no host do Linux. Implementamos a versão mais recente do software de monitoramento Netapp onCommand Unified Manager 7.3 e conectamos os dois sistemas de armazenamento a ele.
- Analisamos os dados sobre a carga atual nas unidades usando o software Unified Manager; usando o SSD, conectamos a camada de armazenamento em cache às unidades de disco existentes (Flash / Storage Pool).
- Eles desligaram o sistema de armazenamento alternativo, criaram links de cluster (emparelhamento de cluster, emparelhamento SVM) para que a replicação pudesse ser usada. Criamos novos relacionamentos SnapMirror entre o armazenamento principal e o armazenamento SRK com base nos volumes existentes (que foram usados nos relacionamentos no modo SnapMirror 7) com ressincronização dos dados alterados e, em seguida, convertemos os relacionamentos SnapMirror em relacionamentos SnapVault (SnapMirror XDP).
- Conectamos os dois sistemas de armazenamento ao software Commvault SRC no modo NetApp Open Replication usando o suporte técnico do Commvault, mas não funcionou de maneira diferente, embora tenhamos feito tudo de acordo com as instruções. Configurado o envio de logs de suporte automático de armazenamento de combate e sistemas de armazenamento do SRK.
Segunda: moagem
- Verificação da operação dos principais sistemas produtivos de armazenamento e armazenamento do sistema de armazenamento. Solução de possíveis problemas e avarias.
- Desconectar e desmontar equipamentos temporários.
A migração em si levou apenas dois dias. A mudança foi bem-sucedida, todos os dados do cliente são sãos e salvos. O sistema de gerenciamento de backup e a integração com o software SRK existente também foram preservados. Se você usou anteriormente o pacote Commvault com o OnCommand Unified Manager, depois de mudar para o Modo de Cluster, decidiu-se abandoná-lo em favor do Netapp Open Replication para conectar o Commvault diretamente aos controladores de armazenamento.
As principais recomendações que posso dar com base nos resultados dessa migração: alterne do modo 7 para o modo de cluster, além de substituir os controladores. Se você ainda planeja passar para os segundos controladores, como no caso descrito acima, precisará planejar tempo suficiente para resolver vários problemas que necessariamente surgirão ao retornar aos controladores antigos. Usar a migração sem mover dados usando o 7MTT CFT é um procedimento totalmente seguro, se confiável por profissionais.
Guias úteis usados durante esta migração:
Dmitry Kostryukov, Engenheiro Líder de Projeto de Sistemas de Armazenamento
Centro de Design para Complexos de Computadores "Jet Infosystems"