No início da minha carreira, trabalhei para uma empresa que lançou um sistema de gerenciamento de conteúdo. Esse CMS ajudou os departamentos de marketing a gerenciar seus sites por conta própria, em vez de depender dos desenvolvedores para cada alteração. O sistema ajudou os clientes a reduzir os custos operacionais e, para mim - aprender como criar aplicativos da web.
Embora o produto em si tenha uma finalidade muito geral, os clientes geralmente o usam para tarefas específicas. Essas tarefas reduziram ao máximo o CMS e os desenvolvedores tiveram que procurar uma solução para os problemas. Depois de dez anos trabalhando em um ambiente como esse, aprendi várias maneiras de como um aplicativo Web em produção pode quebrar. Alguns deles serão discutidos neste artigo.
Uma das lições aprendidas ao longo dos anos é que engenheiros individuais geralmente mergulham profundamente na área de seu interesse e estudam o restante superficialmente. O esquema funciona normalmente em uma equipe de engenheiros com boa comunicação, onde o conhecimento se sobrepõe e preenche lacunas individuais para cada um deles. Mas em equipes com pouca experiência ou para engenheiros individuais, ocorre uma falha.
Se você começou a trabalhar em um ambiente assim e começou a criar e implantar um aplicativo Web a partir do zero, aprenderá rapidamente o que é "conhecimento perigoso da superfície".
Existem várias soluções no setor para resolver esse problema: aplicativos da web gerenciados (Beanstalk, AppEngine etc.), gerenciamento de contêineres (Kubernetes, ECS etc.) e muitos outros. Eles funcionam bem fora da caixa e podem resolver o problema perfeitamente. Mas isso é complexidade desnecessária ao iniciar um aplicativo da Web e, geralmente, essas soluções "simplesmente funcionam".
Infelizmente, eles nem sempre “apenas funcionam”. Se houver alguma nuance, quero saber um pouco mais sobre essa sinistra caixa preta.
No artigo, pegamos um sistema não confiável e o modificamos para um nível razoável de confiabilidade. A cada passo, um problema real é usado, cuja solução nos leva ao próximo estágio. Eu acredito que é mais eficiente não analisar todas as partes do design final, mas usar apenas uma abordagem em fases. Ele demonstra melhor quando e em que ordem tomar certas decisões. No final, construiremos do zero a estrutura básica do serviço de hospedagem para aplicativos da web gerenciados, e espero explicar detalhadamente as razões da existência de cada uma de suas partes.
Iniciar
Imagine que seu orçamento para hospedagem é de US $ 500 por ano, então você decidiu alugar um servidor t2.medium no Amazon AWS. No momento da redação deste artigo, isso é cerca de US $ 400 por ano.
Você sabe com antecedência que terá um sistema de autorização e que precisará armazenar informações sobre os usuários, portanto, precisa de um banco de dados. Devido ao orçamento limitado, o colocaremos em nosso único servidor. No final, obtemos a seguinte infraestrutura:
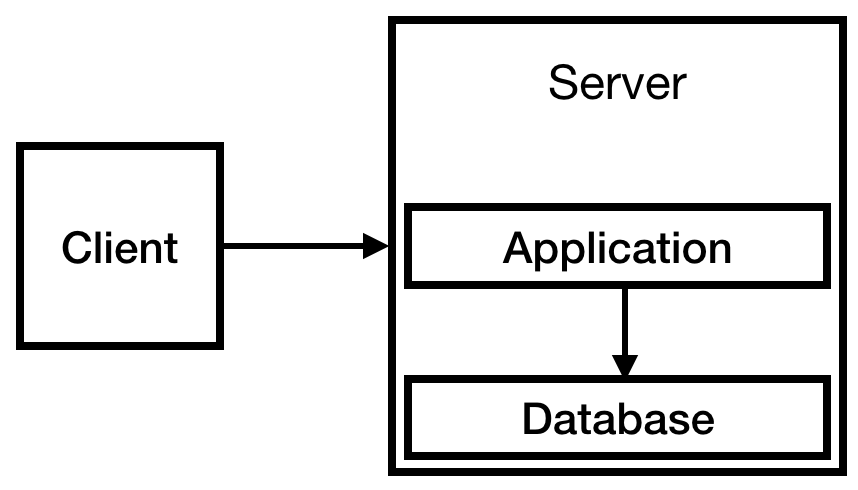 Fig. 1
Fig. 1Isso é o suficiente por enquanto. De fato, esse sistema pode funcionar por algum tempo. O serviço é pequeno, com menos de 10 visitas por dia. Talvez uma pequena instância tenha sido suficiente, mas estamos otimistas com o crescimento da empresa, por isso, prudentemente, tomamos t2.medium.
O valor do negócio está no banco de dados, por isso é muito importante. Você precisa garantir que, se o servidor falhar, você não perderá dados. Provavelmente, verifique se o conteúdo do banco de dados não está armazenado em um disco temporário. Afinal, se a instância for excluída, você perderá seus dados. Este é um pensamento muito assustador.
Você também deve se certificar de ter backups para armazenamento externo. O S3 parece ser um bom lugar para eles, e relativamente barato, então vamos configurá-lo também. E você deve definitivamente verificar se o backup está funcionando, restaurando periodicamente o backup.
Agora o sistema se parece com isso:
 Fig. 2
Fig. 2Você aumentou a confiabilidade do banco de dados e é hora de se preparar para o "efeito habitual" executando um teste de carga no servidor. Tudo corre bem até que 500 erros apareçam e, em seguida, um fluxo de erro 404, então você está investigando o que aconteceu.
Acontece que você não tem idéia do que aconteceu porque gravou logs no console e não direcionou a saída para um arquivo. Você também vê que o processo não funciona, portanto, provavelmente, é por isso que aparecem os erros 404. Uma onda de alívio ocorre porque você executou corretamente o teste de carga local e não causou o efeito Habra real como carga de teste.
Você corrige o problema com a reinicialização automática, criando o serviço
systemd , inicie o servidor da web, que simultaneamente soluciona o problema do log. Em seguida, execute outro teste de carga para verificar.
E novamente vemos erros 500 (felizmente, sem 404). Você verifica os logs. Detecta-se que o conjunto de conexões do banco de dados está cheio porque um pequeno limite de 10 conexões foi definido. Atualize a restrição, reinicie o banco de dados e execute o teste de carga novamente. Tudo está indo bem, então você decide falar sobre o seu site no Habré.
Dia de lançamento
Mãe de Deus! Seu serviço instantaneamente se torna um sucesso. Você chegou à página principal e obteve 5000 visualizações nos primeiros 30 minutos - e vê os comentários. O que eles escrevem lá?
Eu tenho um erro 404, então tive que abrir uma versão em cache da página. Aqui está o link, se alguém precisar: ...
...
Nada se abre. Além disso, tenho o Javascript desativado. Por que as pessoas pensam que eu quero carregar o Javascript de 2 MB ...
...
O download da página inicial leva 4 segundos. Traceroute da Austrália mostra que o servidor está localizado em algum lugar do Texas. Além disso, por que a primeira página carrega 2 megabytes de Javascript?
Em uma corrida louca, você configura o Nginx como um servidor proxy reverso para o seu aplicativo e configura uma página estática 404. Você também altera o procedimento de implantação para enviar arquivos estáticos para o S3: é necessário que o CloudFront CDN funcione para reduzir o tempo de carregamento na Austrália.
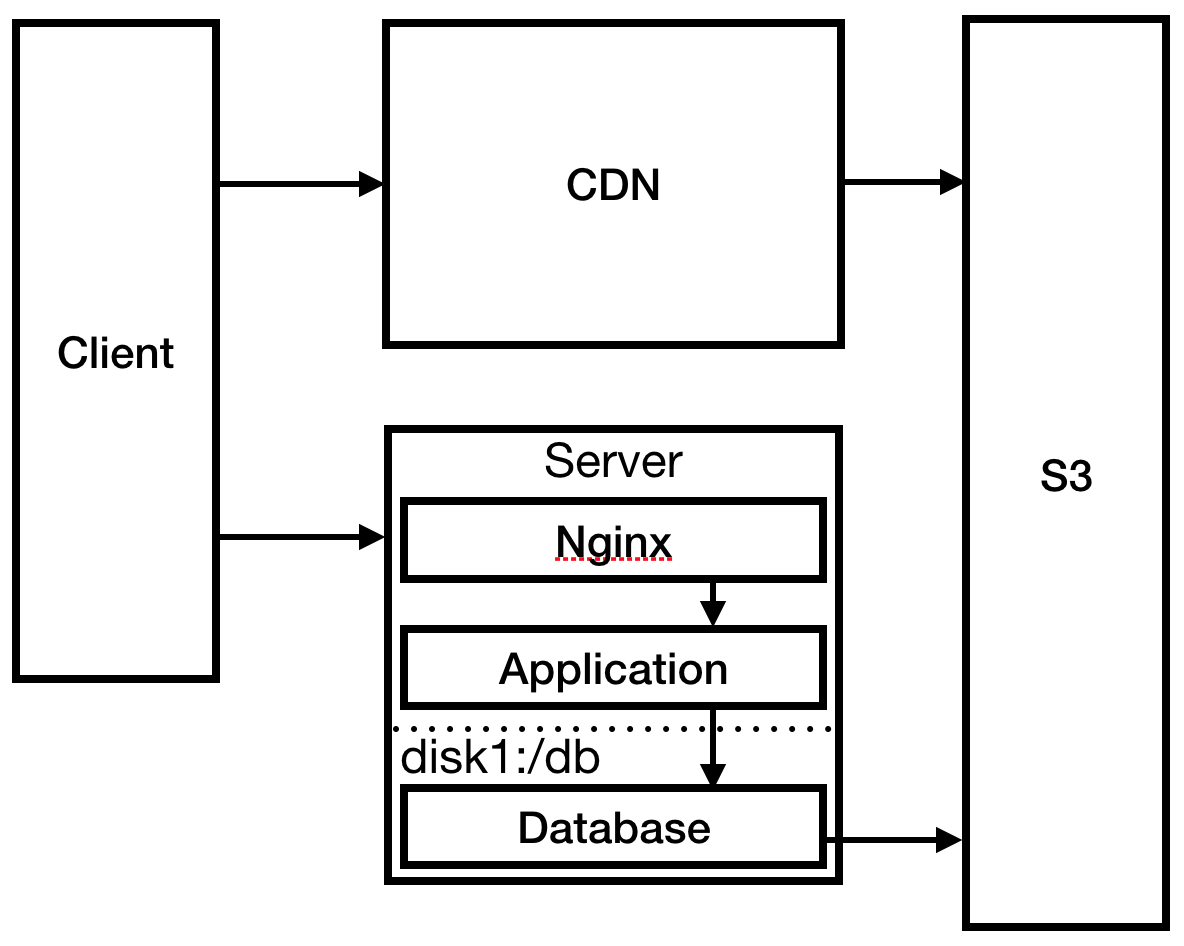 Fig. 3
Fig. 3Você resolveu o problema mais urgente, acesse o servidor e verifique os logs. Sua conexão SSH está invulgarmente atrasada. Após algum estudo, você vê que os arquivos de log esgotaram completamente o espaço em disco, o que levou ao travamento do processo e impediu a reinicialização. Crie um disco muito maior e monte os logs lá. Configure a
logrotate do log para que os arquivos de log não aumentem mais para esses tamanhos.
Problemas de desempenho
Meses se passam. A audiência está crescendo. O site começa a desacelerar. Você notou no monitoramento do CloudWatch que isso acontece apenas entre 00:00 e 12:00 UTC. Devido aos mesmos tempos de atraso de início e de término, você percebe que isso se deve a uma tarefa agendada no servidor. Verifique o crontab e verifique se um trabalho está agendado para meia-noite: backup. Obviamente, o backup leva doze horas e leva à sobrecarga do banco de dados, causando uma desaceleração significativa no site.
Você leu sobre isso antes - e decide executar backups em um banco de dados escravo. Lembre-se: você não possui um banco de dados subordinado, portanto, é necessário criá-lo. Não faz muito sentido executar o banco de dados escravo no mesmo servidor, então você decide expandir. Crie dois novos servidores: um para o banco de dados mestre e outro para o banco de dados escravo. Altere o backup para trabalhar com um banco de dados subordinado.
 Fig. 4
Fig. 4Crescimento da equipe
Por um tempo, tudo está indo bem. Meses se passam. Você está contratando desenvolvedores. Um dos recém-chegados introduz um bug que derruba o servidor de produção. O desenvolvedor culpa o ambiente de desenvolvimento, que é diferente da produção. Há alguma verdade em suas palavras. Como você é uma pessoa racional com um bom caráter, você percebe esse evento como uma lição.
É hora de criar ambientes adicionais: preparo, controle de qualidade e produção. Felizmente, desde o primeiro dia, você automatizou a criação da infraestrutura, para que tudo corra bem e com simplicidade. Você também estabeleceu boas práticas de entrega contínua desde o primeiro dia, para montar facilmente um transportador a partir de novas filiais.
O departamento de marketing está pressionando pela versão 2.0. Você não entende bem o que significa 2.0, mas concorda. É hora de se preparar para o próximo aumento no tráfego. Você já está próximo do pico no servidor atual, portanto chegou a hora do balanceamento de carga. O Amazon ELB facilita isso. Nesse período, você percebe que os diagramas em camadas deste artigo devem mostrar camadas de cima para baixo, e não da esquerda para a direita.
 Fig. 5
Fig. 5Confiante de que você vai lidar com a carga, mencione novamente seu site no Habré. Oh milagre, pode suportar o tráfego. Grande sucesso!
Tudo parecia estar indo bem até você checar os registros. Demorou uma hora para testar 12 servidores (quatro servidores em cada ambiente). Um verdadeiro aborrecimento. Felizmente, há dinheiro suficiente para comprar uma pilha ELK (ElasticSearch, LogStash, Kibana). Você o implementa e direciona servidores para todos os ambientes.
 Fig. 6
Fig. 6Agora, você pode acessar os logs novamente, olhar para eles - e perceber algo estranho. Eles estão cheios de tais entradas:
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
Você não está usando PHP ou WordPress, então isso é bastante estranho. Você percebe entradas suspeitas semelhantes nos logs dos servidores de banco de dados e se pergunta como eles se conectaram à Internet. É hora de implementar sub-redes públicas e privadas.
 Fig. 7
Fig. 7Verifique os logs novamente. As tentativas de hackers permaneceram, mas agora estão limitadas à porta 80 no balanceador de carga, o que é um pouco reconfortante, porque servidores de aplicativos, servidores de banco de dados e a pilha ELK não estão mais em domínio público.
Apesar dos logs centralizados, você está cansado de procurar períodos de inatividade, verificando os logs manualmente. Através do Amazon CloudWatch, você configura alertas por email quando a unidade, CPU e rede atingem 80% de utilização. Ótimo!
Operação suave
Brincadeira! Não existe operação suave no software. Algo definitivamente vai quebrar. Felizmente, agora você tem muitas ferramentas para lidar com a situação.
Criamos um aplicativo da Web escalável com backups, reversões (usando implantações em azul / verde entre a produção e o estágio intermediário), logs centralizados, monitoramento e notificação. Uma escala adicional, como regra, depende das necessidades específicas do aplicativo.
Existem muitas opções de hospedagem no mercado que assumem a maioria das tarefas mencionadas. Em vez de desenvolver por conta própria, você pode confiar no Beanstalk, AppEngine, GKE, ECS etc. A maioria desses serviços configura automaticamente permissões razoáveis, subsistemas, sub-redes de balanceamento de carga, etc. Isso elimina uma parte significativa do trabalho de executar um aplicativo da Web de maneira rápida e fácil. back-end confiável que funciona por um longo tempo.
Apesar disso, acho útil entender que funcionalidade cada uma dessas plataformas fornece e por que elas fornecem. Isso facilita a escolha de uma plataforma com base em suas próprias necessidades. Ao hospedar o aplicativo em uma plataforma assim, você já saberá como esses módulos funcionam. Quando algo der errado, é útil conhecer as ferramentas para resolver o problema.
Conclusão
Este artigo omite muitos detalhes. Ele não descreve como automatizar a criação de infraestrutura, como preparar e configurar servidores. Ele não abrange a criação de ambientes de desenvolvimento, a instalação de pipelines de entrega contínua e a implantação e reversão. Não abordamos a segurança da rede, o compartilhamento de chaves e o princípio dos privilégios mínimos. Eles não falaram sobre a importância da infraestrutura imutável, servidores sem estado e migrações. Cada tópico requer um artigo separado.
O objetivo deste post é uma visão geral de como deve ser um aplicativo Web razoável em produção. Artigos futuros podem ser vinculados aqui e expandir o tópico.
Por enquanto é tudo.
Obrigado pela leitura e boa codificação!
Nota: não tome literalmente a sequência deste artigo ilustrativo. Separadamente, todos esses eventos realmente aconteceram comigo, mas em momentos diferentes, em ambientes completamente diferentes e em tarefas diferentes.