Nikolai Ryzhikov propôs sua versão da resposta para a pergunta: por que é tão difícil desenvolver uma interface com o usuário? No exemplo de seu projeto, ele mostrará que o aplicativo no frontend de algumas idéias do back-end afeta tanto a redução da complexidade do desenvolvimento quanto a testabilidade do front-end.
O material foi preparado com base em um relatório de Nikolai Ryzhikov na conferência de primavera de
HolyJS 2018 Piter .
Atualmente, Nikolai Ryzhikov está trabalhando no setor de Saúde-TI para criar sistemas de informação médica. Membro da comunidade de programadores funcionais de São Petersburgo FPROG. Membro ativo da comunidade Online Clojure, membro do padrão de troca de informações médicas HL7 FHIR. Programa há 15 anos.
- Eu sempre fui atormentado pela pergunta: por que a interface gráfica do usuário era sempre difícil de fazer? Por que isso sempre levantou muitas perguntas?
Hoje vou tentar especular se é possível desenvolver efetivamente uma interface de usuário. Podemos reduzir a complexidade do seu desenvolvimento.
O que é eficiência?
Vamos definir o que é eficiência. Do ponto de vista do desenvolvimento de uma interface do usuário, eficiência significa:
- velocidade de desenvolvimento
- número de bugs
- quantidade de dinheiro gasto ...
Há uma definição muito boa:
Eficiência está fazendo mais com menos
Após essa determinação, você pode colocar o que quiser - gastando menos tempo, menos esforço. Por exemplo, "se você escrever menos código, permita menos erros" e alcance o mesmo objetivo. Em geral, dedicamos muito esforço em vão. E a eficiência é um objetivo bastante alto - livrar-se dessas perdas e fazer apenas o necessário.
O que é complexidade?
Na minha opinião, a complexidade é o principal problema no desenvolvimento.
Fred Brooks escreveu um artigo em 1986 chamado Sem bala de prata. Nele, ele reflete sobre o software. No hardware, o progresso é aos trancos e barrancos, e com o software tudo é muito pior. A principal questão de Fred Brooks - pode haver uma tecnologia que nos acelere imediatamente por uma ordem de magnitude? E ele próprio dá uma resposta pessimista, afirmando que no software não é possível conseguir isso, explicando sua posição. Eu recomendo a leitura deste artigo.
Um amigo meu disse que a programação da interface do usuário é um "problema sujo". Você não pode sentar uma vez e encontrar a opção certa para que o problema seja resolvido para sempre. Além disso, nos últimos 10 anos, a complexidade do desenvolvimento aumentou apenas.
12 anos atrás ...
Começamos a desenvolver um sistema de informações médicas há 12 anos. Primeiro com flash. Depois, analisamos o que o Gmail começou a fazer. Gostamos e queríamos mudar para JavaScript com HTML.
De fato, estávamos muito adiantados. Demos um dojo e, na verdade, tínhamos tudo igual ao que temos agora. Havia componentes que eram muito bons em widgets de dojo, havia um sistema de compilação modular e requer que o Google Clojure Compiler seja construído e minificado (RequireJS e CommonJS nem cheiravam).
Tudo deu certo. Olhamos para o Gmail, ficamos inspirados, pensamos que estava tudo bem. Inicialmente, escrevemos apenas um leitor de cartão de paciente. Depois, eles mudaram gradualmente para a automação de outros fluxos de trabalho no hospital. E tudo ficou complicado. A equipe parece ser profissional - mas cada recurso começou a ranger. Essa sensação apareceu há 12 anos - e ainda não me deixa.
Caminho dos trilhos + jQuery
Fizemos a certificação do sistema e era necessário escrever um portal do paciente. Este é um sistema em que o paciente pode ir e ver seus dados médicos.
Nosso back-end foi então escrito em Ruby on Rails. Embora a comunidade Ruby on Rails não seja muito grande, ela teve um enorme impacto no setor. Da sua pequena comunidade apaixonada, todos os seus gerenciadores de pacotes, GitHub, Git, maquiagem automática etc. vieram.
A essência do desafio que enfrentamos foi que tivemos que implementar o portal do paciente em duas semanas. E decidimos tentar a maneira Rails - fazer tudo no servidor. Uma web tão clássica 2.0. E eles fizeram - eles realmente fizeram isso em duas semanas.
Estávamos à frente de todo o planeta: criamos o SPA, tínhamos uma API REST, mas, por algum motivo, era ineficaz. Alguns recursos já podiam criar unidades, porque somente eles eram capazes de acomodar toda essa complexidade de componentes, o relacionamento do back-end com o front-end. E quando seguimos o caminho do Rails - um pouco desatualizado por nossos padrões, os recursos de repente começaram a rebitar. O desenvolvedor médio começou a lançar o recurso em alguns dias. E nós até começamos a escrever testes simples.
Com base nisso, na verdade ainda tenho uma lesão: houve perguntas. Quando passamos do Java para o Rails no back-end, a eficiência do desenvolvimento aumentou cerca de 10 vezes. Mas quando pontuamos no SPA, a eficiência do desenvolvimento também aumentou significativamente. Como assim?
Por que a Web 2.0 foi eficaz?
Vamos começar com outra pergunta: por que fazemos um aplicativo de página única, por que acreditamos nele?
Eles apenas nos dizem: precisamos fazer isso - e fazemos. E muito raramente questiona. A arquitetura REST API e SPA está correta? É realmente adequado para o caso em que o usamos? Nós não pensamos.
Por outro lado, existem excelentes exemplos inversos. Todo mundo usa o GitHub. Você sabia que o GitHub não é um aplicativo de página única? O GitHub é um aplicativo "ferroviário" comum que é renderizado no servidor e onde existem poucos widgets. Alguém já experimentou farinha disso? Eu acho que tem três pessoas. O resto nem percebeu. Isso não afetou o usuário de nenhuma maneira, mas, ao mesmo tempo, por algum motivo, temos que pagar 10 vezes mais pelo desenvolvimento de outros aplicativos (força, complexidade etc.). Outro exemplo é o Basecamp. O Twitter já foi apenas um aplicativo Rails.
De fato, existem muitas aplicações Rails. Isso foi parcialmente determinado pelo gênio DHH (David Heinemeier Hansson, criador do Ruby on Rails). Ele conseguiu criar uma ferramenta focada nos negócios, que permite fazer imediatamente o que você precisa, sem se distrair com problemas técnicos.
Quando usamos o caminho Rails, é claro, havia muita magia negra. À medida que evoluímos gradualmente, mudamos de Ruby para Clojure, praticamente mantendo a mesma eficiência, mas simplificando tudo em uma ordem de magnitude. E foi maravilhoso.
12 anos se passaram
Com o tempo, novas tendências começaram a aparecer no frontend.
Ignoramos completamente o Backbone, porque o aplicativo dojo que escrevemos antes era ainda mais sofisticado do que o que o Backbone oferecia.
Então veio Angular. Era um "raio de luz" bastante interessante - do ponto de vista da eficiência, Angular é muito bom. Você pega o desenvolvedor médio e ele rebita o recurso. Mas, do ponto de vista da simplicidade, o Angular traz muitos problemas - é opaco, complexo, há observação, otimização etc.
O React apareceu, o que trouxe um pouco de simplicidade (pelo menos a franqueza da renderização, que, devido ao DOM virtual, nos permite sempre como redesenhar, entender e escrever. Mas em termos de eficiência, para ser honesto, o React nos empurrou significativamente de volta.
O pior é que nada mudou em 12 anos. Ainda estamos fazendo a mesma coisa que então. É hora de pensar - algo está errado aqui.
Fred Brooks diz que há dois problemas com o desenvolvimento de software. Obviamente, ele vê o principal problema da complexidade, mas o divide em dois grupos:
- complexidade significativa que vem da própria tarefa. Simplesmente não pode ser jogado fora, porque faz parte da tarefa.
- complexidade aleatória é a que trazemos tentando resolver esse problema.
A questão é: qual é o equilíbrio entre eles. É exatamente isso que estamos discutindo agora.
Por que é tão doloroso fazer a interface do usuário?
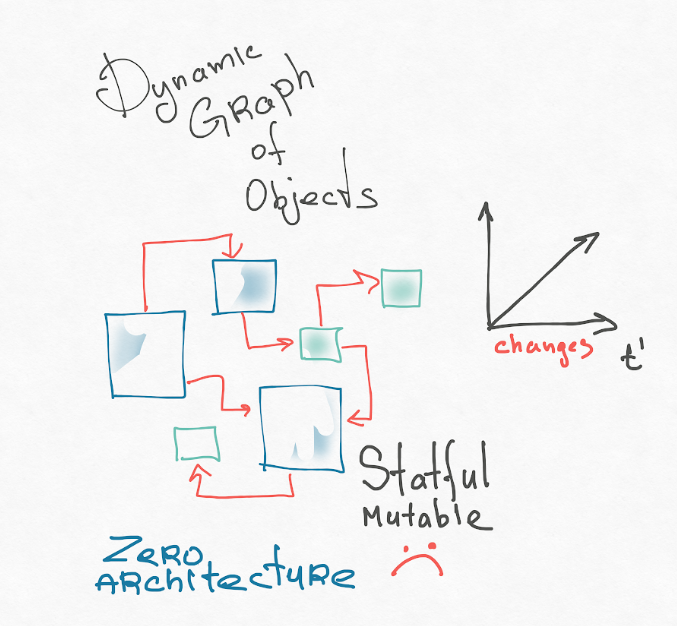
Parece-me que a primeira razão é o nosso modelo de aplicação mental. Os componentes de reação são uma abordagem puramente OOP. Nosso sistema é um gráfico dinâmico de objetos mutáveis interconectados. Tipos completos de Turing geram constantemente nós deste gráfico, alguns nós desaparecem. Você já tentou imaginar sua aplicação na sua cabeça? Isso é assustador! Normalmente, apresento um aplicativo OOP como este:

Eu recomendo a leitura das teses de Roy Fielding (autor da arquitetura REST). Sua dissertação é intitulada "Estilos arquitetônicos e design de software baseado em rede". No início, há uma introdução muito boa, onde ele fala sobre como chegar à arquitetura em geral e apresenta os conceitos: divide o sistema em componentes e os relacionamentos entre esses componentes. Possui uma arquitetura "zero", na qual todos os componentes podem ser potencialmente associados a todos. Isso é um caos arquitetônico. Esta é a nossa representação de objeto da interface do usuário.
Roy Fielding recomenda procurar e impor um conjunto de restrições, porque é um conjunto de restrições que define sua arquitetura.
Provavelmente a coisa mais importante é que as restrições são amigas do arquiteto. Procure essas limitações reais e crie um sistema a partir delas. Porque a liberdade é má. Liberdade significa que você tem um milhão de opções dentre as quais pode escolher, e não um critério único para determinar se a escolha foi correta. Procure por restrições e desenvolva-as.
Existe um excelente artigo chamado OUT OF THE TAR PIT ("Mais fácil que um poço de alcatrão"), no qual os caras depois de Brooks decidiram analisar o que exatamente contribui para a complexidade do aplicativo. Eles chegaram à conclusão decepcionante de que um sistema mutável e espalhado pelo estado é a principal fonte de complexidade. Aqui é possível explicar de forma puramente combinatória - se você tem duas células, e em cada uma delas uma bola pode mentir (ou não mentir), quantos estados são possíveis? Quatro.
Se três células - 2
3 , se 100 células - 2
100 . Se você apresentar seu aplicativo e entender quanto estado está desfocado, perceberá que há um número infinito de estados possíveis do seu sistema. Se ao mesmo tempo você não estiver limitado por nada, é muito difícil. E o cérebro humano está fraco, isso já foi comprovado por vários estudos. Somos capazes de armazenar até três elementos em nossas cabeças ao mesmo tempo. Alguns dizem sete, mas mesmo para isso o cérebro usa um hack. Portanto, a complexidade é realmente um problema para nós.
Eu recomendo a leitura deste artigo, onde os caras chegam à conclusão de que algo precisa ser feito com esse estado mutável. Por exemplo, existem bancos de dados relacionais, você pode remover todo o estado mutável lá. E o resto é feito em um estilo puramente funcional. E eles apenas têm a ideia de uma programação funcional-relacional.
Portanto, o problema vem do fato de que:
- Em primeiro lugar, não temos um bom modelo de interface de usuário fixo. As abordagens componentes nos levam ao inferno existente. Não impomos nenhuma restrição, espalhamos o estado mutável; como resultado, a complexidade do sistema em algum momento simplesmente nos esmaga;
- segundo, se estamos escrevendo um aplicativo backend - frontend clássico, ele já é um sistema distribuído. E a primeira regra dos sistemas distribuídos é não criar sistemas distribuídos (Primeira Lei do Design de Objetos Distribuídos: não distribua seus objetos - por Martin Fowler), pois você aumenta imediatamente a complexidade por uma ordem de magnitude. Qualquer pessoa que tenha escrito alguma integração entende que, assim que você entra na interação entre os sistemas, todas as estimativas de projeto podem ser multiplicadas por 10. Mas simplesmente esquecemos disso e passamos para sistemas distribuídos. Essa foi provavelmente a principal consideração quando mudamos para o Rails, retornando todo o controle ao servidor.
Tudo isso é muito duro para um cérebro humano pobre. Vamos pensar sobre o que podemos fazer com esses dois problemas - a falta de restrições na arquitetura (o gráfico de objetos mutáveis) e a transição para sistemas distribuídos que são tão complexos que os acadêmicos ainda estão intrigados sobre como fazê-los corretamente (ao mesmo tempo, nós nos condenamos a esses tormentos nos aplicativos de negócios mais simples)?
Como o back-end evoluiu?
Se escrevermos o back-end no mesmo estilo em que estamos criando a interface do usuário agora, haverá a mesma "bagunça sangrenta". Vamos gastar tanto tempo nisso. Então, realmente, uma vez tentei fazer. Então, gradualmente, começaram a impor restrições.
A primeira grande invenção de back-end é o banco de dados.
No início, no programa, todo o estado pendia inexplicavelmente onde, e era difícil gerenciá-lo. Com o tempo, os desenvolvedores criaram um banco de dados e removeram todo o estado de lá.
A primeira diferença interessante entre o banco de dados é que os dados não existem alguns objetos com seu próprio comportamento, isso é pura informação. Existem tabelas ou outras estruturas de dados (por exemplo, JSON). Eles não têm comportamento, e isso também é muito importante. Porque o comportamento é uma interpretação da informação e pode haver muitas interpretações. E os fatos básicos - eles permanecem básicos.
Outro ponto importante é que, nesse banco de dados, temos uma linguagem de consulta como SQL. Do ponto de vista das limitações, na maioria dos casos o SQL não é uma linguagem completa de Turing, é mais simples. Por outro lado, é declarativo - mais expressivo, porque no SQL você diz "o que", não "como". Por exemplo, quando você combina dois rótulos no SQL, o SQL decide como executar essa operação com eficiência. Quando você está procurando algo, ele pega um índice para você. Você nunca declara explicitamente isso. Se você tentar combinar algo em JavaScript, precisará escrever um monte de código para isso.
Aqui, novamente, é importante que impusamos restrições e agora vamos a essa base através de uma linguagem mais simples e expressiva. Complexidade redistribuída.
Depois que o back-end entrou na base, o aplicativo tornou-se sem estado. Isso leva a efeitos interessantes - agora, por exemplo, podemos não ter medo de atualizar o aplicativo (o estado não fica na camada do aplicativo na memória, que desaparecerá se o aplicativo reiniciar). Para uma camada de aplicativo, o stateless é um bom recurso e uma excelente restrição. Coloque se puder. Além disso, um novo aplicativo pode ser colocado na base antiga, porque fatos e sua interpretação não são coisas relacionadas.
Deste ponto de vista, objetos e classes são terríveis porque colam comportamento e informação. A informação é mais rica, vive mais. Bancos de dados e fatos sobrevivem ao código escrito em Delphi, Perl ou JavaScript.
Quando o back-end chegou a essa arquitetura, tudo se tornou muito mais simples. A era de ouro da Web 2.0 chegou. Foi possível obter algo do banco de dados, sujeitar os dados a modelos (função pura) e retornar o HTML-ku, que é enviado ao navegador.
Aprendemos como escrever aplicativos bastante complexos no back-end. E a maioria dos aplicativos é escrita nesse estilo. Mas assim que o back-end dá um passo para o lado - na incerteza -, os problemas começam novamente.
As pessoas começaram a pensar sobre isso e tiveram a idéia de jogar fora a OLP e os rituais.
O que nossos sistemas realmente fazem? Eles pegam informações de algum lugar - do usuário, de outro sistema e similares - colocam no banco de dados, transformam, de alguma forma verificam. A partir da base, eles o retiram com consultas astutas (analíticas ou sintéticas) e o retornam. Isso é tudo. E isso é importante para entender. Deste ponto de vista, simulações são um conceito muito errado e ruim.
Parece-me que, em geral, todo o POO realmente nasceu da interface do usuário. As pessoas tentaram simular e simular uma interface de usuário. Eles viram um determinado objeto gráfico no monitor e pensaram: seria bom estimulá-lo em nosso tempo de execução, juntamente com suas propriedades, etc. Toda essa história está intimamente ligada ao POO. Mas a simulação é a maneira mais direta e ingênua de resolver a tarefa. Coisas interessantes são feitas quando você se afasta. Desse ponto de vista, é mais importante separar as informações do comportamento, livrar-se desses objetos estranhos e tudo ficará muito mais fácil: o servidor da Web recebe uma string HTTP, retorna uma string de resposta HTTP. Se você adicionar uma base à equação, obtém uma função geralmente pura: o servidor aceita a base e a solicitação, retorna uma nova base e resposta (dados inseridos - dados restantes).
No caminho dessa simplificação, os funcionários jogaram fora ⅔ da bagagem acumulada no back-end. Ele não era necessário, era apenas um ritual. Ainda não somos um desenvolvedor de jogos - não precisamos que o paciente e o médico vivam em tempo de execução, movam e acompanhem suas coordenadas. Nosso modelo de informação é outra coisa. Não pretendemos ser remédios, vendas ou qualquer outra coisa. Estamos criando algo novo no cruzamento. Por exemplo, o Uber não simula o comportamento de operadores e máquinas - ele introduz um novo modelo de informação. Em nosso campo, também estamos criando algo novo, para que você possa sentir a liberdade.
Não é necessário tentar simular completamente - criar.
Clojure = JS--
É hora de dizer exatamente como você pode jogar tudo fora. E aqui eu quero mencionar Clojure Script. De fato, se você conhece JavaScript, conhece Clojure. No Clojure, não adicionamos recursos ao JavaScript, mas os removemos.
- Jogamos fora a sintaxe - no Clojure (no Lisp) não há sintaxe. Em uma linguagem comum, escrevemos algum código, que é então analisado e um AST é obtido, que é compilado e executado. No Lisp, escrevemos imediatamente um AST que pode ser executado - interpretado ou compilado.
- Jogamos fora a mutabilidade. Não há objetos ou matrizes mutáveis no Clojure. Cada operação gera como se uma nova cópia. Além disso, esta cópia é muito barata. Isso é tão inteligentemente feito para ser barato. E isso nos permite trabalhar, como na matemática, com valores. Não estamos mudando nada - estamos criando algo novo. Seguro, fácil.
- Damos aulas, jogos com protótipos, etc. Isso simplesmente não está lá.
Como resultado, ainda temos funções e estruturas de dados sobre as quais operamos, além de primitivas. Aqui está o Clojure inteiro. E, nele, você pode fazer o mesmo em outras línguas, onde existem muitas ferramentas extras que ninguém sabe usar.
Exemplos
Como chegamos ao Lisp através do AST? Aqui está uma expressão clássica:
(1 + 2) - 3
Se tentarmos escrever seu AST, por exemplo, na forma de uma matriz, em que a cabeça é o tipo de nó e o próximo parâmetro é um parâmetro, obteremos algo semelhante (estamos tentando escrever isso em Java Script):
['minus', ['plus', 1, 2], 3]
Agora jogue fora as aspas extras, podemos substituir o sinal de menos por
- e o sinal de mais por
+ . Jogue fora as vírgulas que estão em branco no Lisp. Obteremos o mesmo AST:
(- (+ 1 2) 3)
E no Lisp, todos escrevemos assim. Podemos verificar - esta é uma função matemática pura (meu emacs está conectado ao navegador; eu largo o script lá, ele avalia o comando e o envia de volta para o emacs - você vê o valor após o símbolo
=> ):
(- (+ 1 2) 3) => 0
Também podemos declarar uma função:
(defn xplus [ab] (+ ab)) ((fn [xy] (* xy)) 1 2) => 2
Ou uma função anônima. Talvez isso pareça um pouco assustador:
(type xplus)
O tipo dela é uma função JavaScript:
(type xplus) => #object[Function]
Podemos chamá-lo passando o parâmetro:
(xplus 1 2)
Ou seja, tudo o que fazemos é escrever AST, que é então compilado em JS ou bytecode ou interpretado.
(defn mymin [ab] (if (a > b) ba))
Clojure é um idioma hospedado. Portanto, são necessárias primitivas do tempo de execução pai, ou seja, no caso do Clojure Script, teremos tipos JavaScript:
(type 1) => #object[Number]
(type "string") => #object[String]
Então, regexp está escrito:
(type #"^Cl.*$") => #object[RegExp]
As funções que temos são funções:
(type (fn [x] x)) => #object[Function]
Em seguida, precisamos de algum tipo de tipo composto.
(def user {:name "niquola" :address {:city "SPb"} :profiles [{:type "github" :link "https://….."} {:type "twitter" :link "https://….."}] :age 37} (type user)
Isso pode ser lido como se você estivesse criando um objeto em JavaScript:
(def user {name: "niquola" …
No Clojure, isso é chamado de hashmap. Este é um contêiner no qual os valores estão. Se colchetes forem usados - então isso é chamado de vetor - esta é sua matriz:
(def user {:name "niquola" :address {:city "SPb"} :profiles [{:type "github" :link "https://….."} {:type "twitter" :link "https://….."}] :age 37} => #'intro/user (type user)
Registramos qualquer informação com hashmaps e vetores.
Nomes de dois pontos estranhos (
:name ) são os chamados caracteres: cadeias constantes criadas para serem usadas como chaves em hashmaps. Em diferentes idiomas, eles são chamados de formas diferentes - símbolos, algo mais. Mas isso pode ser tomado simplesmente como uma cadeia constante. Eles são bastante eficazes - você pode escrever nomes longos e não gastar muitos recursos nele, porque eles estão conectados (ou seja, não são repetidos).
O Clojure fornece centenas de funções para lidar com essas estruturas de dados genéricas e primitivas. Podemos adicionar, adicionar novas chaves. Além disso, sempre temos semântica de cópia, ou seja, toda vez que obtemos uma nova cópia. Primeiro, você precisa se acostumar com isso, porque não poderá mais salvar algo, como antes, em algum lugar da variável e depois alterar esse valor. Seu cálculo deve sempre ser direto - todos os argumentos devem ser passados para a função explicitamente.
Isso leva a uma coisa importante. Nas linguagens funcionais, uma função é um componente ideal porque recebe tudo explicitamente na entrada. Nenhum link oculto diverge no sistema. Você pode pegar uma função de um lugar, transferi-la para outro e usá-la lá.
No Clojure, temos excelentes operações de igualdade em valor, mesmo para tipos compostos complexos:
(= {:a 1} {:a 1}) => true
E essa operação é barata devido ao fato de que estruturas imutáveis e astutas podem ser comparadas simplesmente por referência. Portanto, mesmo um hashmap com milhões de chaves, podemos comparar em uma operação.
A propósito, os caras do React simplesmente copiaram a implementação do Clojure e criaram o JS imutável.
O Clojure também possui várias operações, por exemplo, obtendo algo de um caminho aninhado no hashmap:
(get-in user [:address :city])
Coloque algo no caminho aninhado no hashmap:
(assoc-in user [:address :city] "LA") => {:name "niquola", :address {:city "LA"}, :profiles [{:type "github", :link "https://….."} {:type "twitter", :link "https://….."}], :age 37}
Atualize algum valor:
(update-in user [:profiles 0 :link] (fn [old] (str old "+++++")))
Selecione apenas uma chave específica:
(select-keys user [:name :address])
A mesma coisa com vetor:
(def clojurists [{:name "Rich"} {:name "Micael"}]) (first clojurists) (second clojurists) => {:name "Michael"}
Existem centenas de operações da biblioteca base que permitem operar nessas estruturas de dados. Há uma interoperabilidade com o host. Você precisa se acostumar um pouco com isso:
(js/alert "Hello!") => nil </csource> "". location window: <source lang="clojure"> (.-location js/window)
Há todo açúcar para ir ao longo das correntes:
(.. js/window -location -href) => "http://localhost:3000/#/billing/dashboard"
(.. js/window -location -host) => "localhost:3000"
Posso pegar a data JS e retornar o ano a partir dela:
(let [d (js/Date.)] (.getFullYear d)) => 2018
Rich Hickey, o criador de Clojure, nos limitou severamente. Realmente não temos mais nada, então fazemos tudo por meio de estruturas de dados genéricas. Por exemplo, quando escrevemos SQL, geralmente escrevemos com uma estrutura de dados. Se você olhar com cuidado, verá que este é apenas um hashmap no qual algo está incorporado. Depois, há alguma função que traduz tudo isso em uma string SQL:
{select [:*] :from [:users] :where [:= :id "user-1"]} => {:select [:*], :from [:users], :where [:= :id "user-1"]}
Também escrevemos roteiros com uma estrutura de dados e estruturas de dados tipográficas:
{"users" {:get {:handler :users-list}} :get {:handler :welcome-page}}
[:div.row [:div {:on-click #(.log js/console "Hello")} "User "]]
DB na interface do usuário
Então, discutimos o Clojure. Mas mencionei anteriormente que uma grande conquista no back-end foi o banco de dados. Se você observar o que está acontecendo no front-end agora, veremos que os caras usam o mesmo padrão - eles entram no banco de dados na Interface do Usuário (em um aplicativo de página única).
Os bancos de dados são introduzidos na arquitetura elm, no re-frame com script Clojure e até de alguma forma limitada no fluxo e no redux (plugins adicionais devem ser configurados aqui para gerar solicitações). A arquitetura, a estrutura e o fluxo do olmo foram lançados na mesma época e emprestados um do outro. Escrevemos no re-frame. A seguir, falarei um pouco sobre como isso funciona.

O evento (é um pouco como redux) sai do view-chi, que é capturado por um determinado controlador. O controlador que chamamos de manipulador de eventos. O manipulador de eventos emite um efeito, que também é alguém interpretado pela estrutura de dados.
Um tipo de efeito está atualizando o banco de dados. Ou seja, ele pega o valor atual do banco de dados e retorna um novo. Também temos assinatura - um análogo de solicitações no back-end. Ou seja, essas são algumas consultas reativas que podemos lançar nesse banco de dados. Esses pedidos reativos, subseqüentemente agrupamos a visão. No caso de reagir, parecemos redesenhar completamente e, se o resultado dessa solicitação foi alterado - isso é conveniente.
O React está presente conosco apenas em algum lugar no final e, em geral, a arquitetura não está de forma alguma conectada a ela. Parece algo como isto:

Aqui é adicionado o que está faltando, por exemplo, no redux-s.
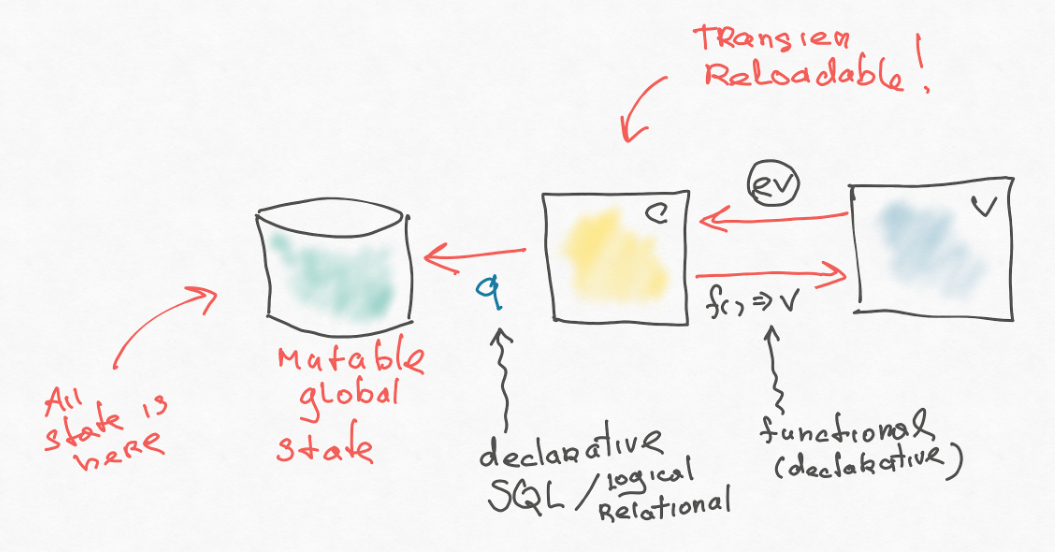
Primeiro, separamos os efeitos. O aplicativo de front-end não é autônomo. Ele tem um certo back-end - um tipo, "fonte de verdade". O aplicativo deve escrever constantemente algo lá e ler algo a partir daí. Pior ainda, se ele tem vários back-ends que deveriam ir. Na implementação mais simples, isso pode ser feito diretamente no criador de ações - no seu controlador, mas isso é ruim. Portanto, o pessoal da nova estrutura introduz um nível adicional de indireção: uma certa estrutura de dados sai do controlador, que diz o que precisa ser feito. E este post tem seu próprio manipulador que faz o trabalho sujo. Esta é uma introdução muito importante, que discutiremos um pouco mais tarde.
Também é importante (às vezes eles esquecem disso) - alguns fatos básicos devem estar na base. Tudo o mais pode ser removido do banco de dados - e as consultas geralmente fazem isso, eles transformam os dados - eles não adicionam novas informações, mas estruturam corretamente as existentes. Precisamos dessa consulta. No redux, na minha opinião, isso agora fornece nova seleção e, no re-frame, nós o tiramos da caixa (embutido).
Dê uma olhada no nosso diagrama de arquitetura. Reproduzimos um pequeno back-end (no estilo da Web 2.0) com uma visualização básica, controladora. A única coisa adicionada é a reatividade. Isso é muito semelhante ao MVC, exceto que tudo está em um só lugar. Uma vez os MVCs iniciais de cada widget criaram seu próprio modelo, mas aqui tudo é dobrado em uma base. Em princípio, você pode sincronizar com o back-end do controlador por meio do efeito, pode criar uma aparência mais genérica para que o banco de dados funcione como um proxy para o back-end. Existe até algum tipo de algoritmo genérico: você escreve no banco de dados local e ele sincroniza com o principal.
Agora, na maioria dos casos, a base é apenas algum tipo de objeto no qual escrevemos algo em redux. Mas, em princípio, pode-se imaginar que ele se tornará um banco de dados completo com uma rica linguagem de consulta. Talvez com algum tipo de sincronização genérica. Por exemplo, existe o datomic - um banco de dados lógico de armazenamento triplo que é executado diretamente no navegador. Você pega e coloca todo o seu estado lá. O Datomic possui uma linguagem de consulta bastante rica, comparável em poder ao SQL e até mesmo ganhando em algum lugar. Outro exemplo é o Google escreveu lovefield. Tudo vai se mover em algum lugar lá.
A seguir, explicarei por que precisamos de uma assinatura reativa.
Agora temos a primeira percepção ingênua - pegamos o usuário do back-end, colocamos no banco de dados e precisamos desenhá-lo. No momento da renderização, muita lógica acontece, mas nós a misturamos com a renderização, com a visualização. Se começarmos imediatamente a renderizar esse usuário, obteremos uma grande peça complicada que faz algo com o Virtual DOM e outra coisa. E é misturado com o modelo lógico de nossa visão.
Um conceito muito importante que precisa ser entendido: devido à complexidade da interface do usuário, ele também precisa ser modelado. É necessário separar como ele é desenhado (como parece) do seu modelo lógico. Então o modelo lógico ficará mais estável. Você não pode sobrecarregá-lo com dependência de uma estrutura específica - Angular, React ou VueJS. Um modelo é o cidadão de primeira classe usual em seu tempo de execução. Idealmente, se houver apenas alguns dados e um conjunto de funções acima dele.

Ou seja, a partir do modelo de back-end (objeto), podemos obter um modelo de visualização no qual, sem usar nenhuma renderização ainda, podemos recriar o modelo lógico. Se houver algum tipo de menu ou algo semelhante - tudo isso pode ser feito no modelo de exibição.
Porque
Por que todos nós estamos fazendo isso?
Vi bons testes de interface do usuário apenas onde há uma equipe de 10 testadores.
Geralmente não há teste de interface do usuário. Portanto, estamos tentando tirar essa lógica dos componentes no modelo de exibição. A falta de testes é um sinal muito ruim, indicando que algo está errado lá, de alguma forma tudo está mal estruturado.
Por que a interface do usuário é difícil de testar? Por que os funcionários do back-end aprenderam a testar seu código, forneceram uma cobertura enorme e realmente ajuda a conviver com o código de back-end? Por que a interface do usuário está errada? Provavelmente, estamos fazendo algo errado. E tudo o que descrevi acima realmente nos moveu na direção da testabilidade.
Como fazemos testes?
Se você observar atentamente, a parte de nossa arquitetura, que contém o controlador, a assinatura e o banco de dados, nem sequer está relacionada ao JS. Ou seja, esse é algum tipo de modelo que opera simplesmente em estruturas de dados: nós as adicionamos em algum lugar, de alguma forma transformamos, realizamos a consulta. Através dos efeitos, estamos desconectados da interação com o mundo exterior. E esta peça é totalmente portátil. Ele pode ser escrito no chamado cljc - este é um subconjunto comum entre o Clojure Script e o Clojure, que se comporta da mesma maneira, lá e ali. Podemos apenas recortar essa peça do frontend e colocá-lo na JVM - onde o backend mora. Em seguida, podemos escrever outro efeito na JVM, que atinge diretamente o ponto final - ele puxa o roteador sem nenhuma conversão, análise de string http etc.
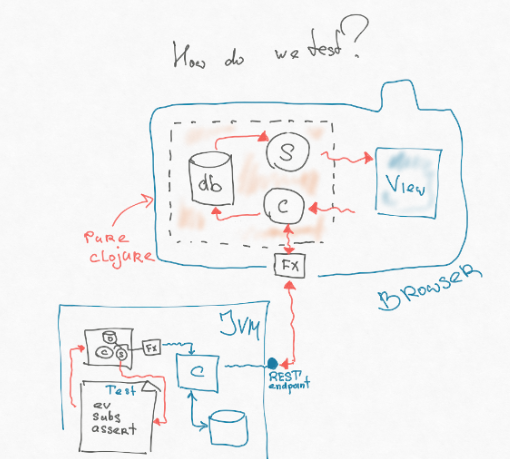
Como resultado, podemos escrever um teste muito simples - o mesmo teste integral funcional que os caras escrevem no back-end. Lançamos um determinado evento, que gera um efeito que atinge diretamente o ponto final no back-end. Ele nos devolve algo, coloca no banco de dados, calcula a assinatura e na assinatura existe uma visão lógica (colocamos a lógica da interface do usuário no máximo). Afirmamos essa visão.
Portanto, podemos testar 80% do código no back-end, enquanto todas as ferramentas de desenvolvimento de back-end estão disponíveis para nós. Usando equipamentos ou algumas fábricas, podemos recriar uma situação específica no banco de dados.
Por exemplo, temos um novo paciente ou algo não é pago, etc. Podemos passar por várias combinações possíveis.
Assim, podemos lidar com o segundo problema - com um sistema distribuído. Como o contrato entre os sistemas é precisamente o principal ponto dolorido, porque esses são dois tempos de execução diferentes, dois sistemas diferentes: o back-end mudou algo e algo quebrou em nosso front-end (você não pode ter certeza de que isso não acontecerá).
Demonstração
É assim que parece na prática. Este é um auxiliar de back-end que limpou a base e escreveu um pequeno mundo nela:
Em seguida, lançamos a assinatura:

Normalmente, o URL define completamente a página e algum evento é lançado - agora você está nessa e em uma página com um conjunto de parâmetros. Aqui entramos em um novo fluxo de trabalho e nossa assinatura retornou:

Nos bastidores, ele foi para a base, conseguiu algo, colocou em nossa base de interface do usuário. A assinatura funcionou e deduziu do modelo lógico de visualização.
Nós o inicializamos. E aqui está o nosso modelo lógico:

Mesmo sem olhar para a interface do usuário, podemos adivinhar o que será desenhado de acordo com este modelo: algum aviso virá, algumas informações sobre o paciente, encontros e um conjunto de links permanecerão (este é um widget de fluxo de trabalho que lidera a recepção) em certas etapas quando o paciente chega).
Aqui chegamos a um mundo mais complexo. Eles fizeram alguns pagamentos e também testaram após a inicialização:
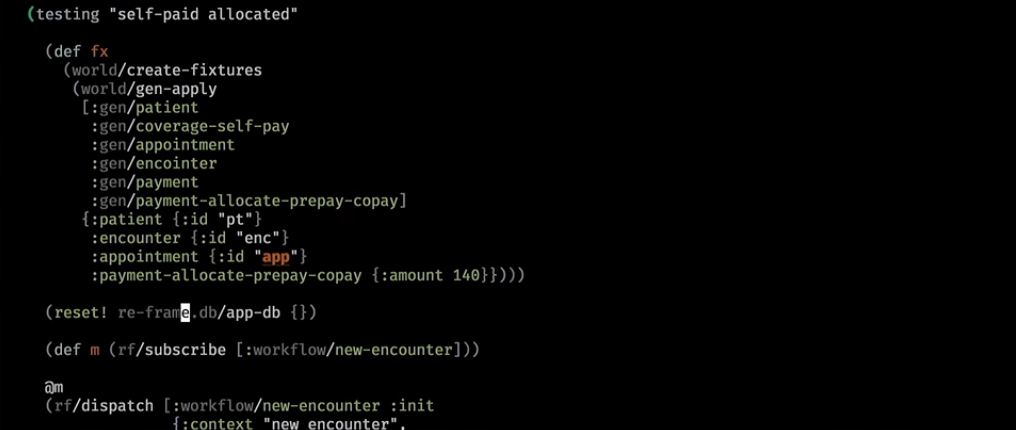
Se ele já pagou pela visita, verá isso na interface do usuário:

Execute testes, defina como CI. A sincronização entre o back-end e o front-end será garantida por testes, e não honestamente.
Voltar para o back-end?
Introduzimos os testes há seis meses e gostamos muito. O problema da lógica turva permanece. Quanto mais inteligente um aplicativo de negócios se comportar, mais informações ele precisará para algumas etapas. Se você tentar executar algum tipo de fluxo de trabalho no mundo real, haverá dependências de tudo: para cada interface do usuário, você precisa obter algo de diferentes partes do banco de dados no back-end. Se escrevermos sistemas de contabilidade, isso não pode ser evitado. Como resultado, como eu disse, toda a lógica está manchada.
Com a ajuda de tais testes, podemos criar a ilusão, pelo menos em tempo de desenvolvimento - no momento do desenvolvimento - de que nós, como nos velhos tempos da web 2.0, estamos sentados no servidor em um tempo de execução e tudo é confortável.
Outra idéia maluca surgiu (ainda não foi implementada). Por que não abaixar esta parte para o back-end? Por que não fugir completamente do aplicativo distribuído agora? Que essa assinatura e nosso modelo de exibição sejam gerados no back-end? Lá a base está disponível, tudo é síncrono. Tudo é simples e claro.
A primeira vantagem que vejo nisso é que teremos o controle em um só lugar. Apenas simplificamos tudo imediatamente em comparação com nosso aplicativo distribuído. Os testes se tornam simples, as validações duplas desaparecem. O mundo da moda dos sistemas interativos para múltiplos usuários se abre (se dois usuários seguem a mesma forma, nós falamos sobre isso; eles podem editá-lo ao mesmo tempo).
Um recurso interessante aparece: indo ao back-end e à perspectiva da sessão, podemos entender quem está atualmente no sistema e o que ele está fazendo. É um pouco como game dev, onde os servidores funcionam assim. Lá, o mundo vive no servidor, e o front-end é processado apenas. Como resultado, podemos obter um determinado thin client.
Por outro lado, isso cria um desafio. Teremos que ter um servidor statefull no qual essas sessões residam. Se tivermos vários servidores de aplicativos, será necessário equilibrar adequadamente a carga ou replicar a sessão. No entanto, há uma suspeita de que esse problema seja menor que o número de vantagens que obtemos.
Portanto, volto ao slogan principal: existem muitos tipos de aplicativos que podem ser gravados e não distribuídos, para eliminar a complexidade deles. E você pode obter um aumento múltiplo de eficiência se revisar novamente os postulados básicos nos quais confiamos no desenvolvimento.
Se você gostou do relatório, preste atenção: de 24 a 25 de novembro, um novo HolyJS será realizado em Moscou e também haverá muitas coisas interessantes por lá. Informações já conhecidas sobre o programa estão no site e os ingressos podem ser comprados no site .