O autor do artigo é Alexey Malanov, especialista no departamento de desenvolvimento de tecnologia antivírus da Kaspersky LabA inteligência artificial invade nossas vidas. No futuro, tudo provavelmente será legal, mas até agora algumas questões surgiram e, cada vez mais, essas questões afetam aspectos da moral e da ética. É possível zombar de pensar em IA? Quando será inventado? O que nos impede de escrever leis da robótica agora, colocando a moral nelas? Que surpresas o aprendizado de máquina nos traz agora? O aprendizado de máquina pode ser enganado, e quão difícil é?
IA forte e fraca - duas coisas diferentes
Há duas coisas diferentes: IA forte e fraca.
A IA forte (verdadeira, geral, real) é uma máquina hipotética que pode pensar e ter consciência de si mesma, resolver não apenas tarefas altamente especializadas, mas também aprender algo novo.
IA fraca (restrita, superficial) - esses programas já existem para solucionar tarefas bastante específicas, como reconhecimento de imagem, direção automática, reprodução de Go, etc. aprendizado ”(aprendizado de máquina).
AI forte não será tão breve
Sobre o Strong AI, ainda não se sabe se algum dia será inventado. Por um lado, até agora, as tecnologias se desenvolveram com aceleração e, se isso continuar, restam cinco anos.
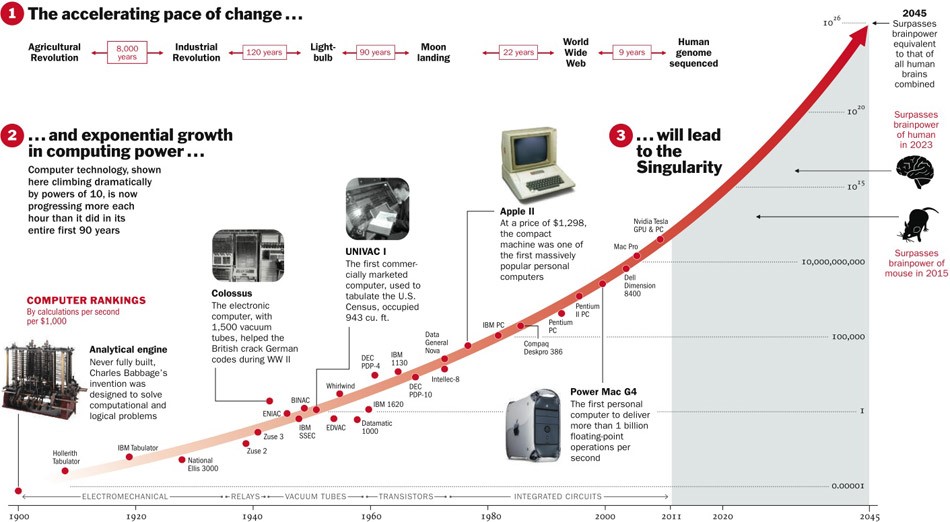
Por outro lado, poucos processos na natureza procedem exponencialmente. Afinal, com muito mais frequência, vemos uma curva logística.
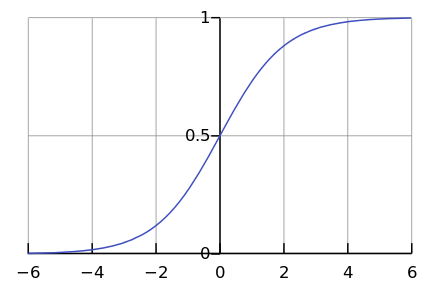
Enquanto estamos em algum lugar à esquerda do gráfico, parece-nos que este é um expoente. Por exemplo, até recentemente, a população mundial cresceu com essa aceleração. Mas em algum momento a "saturação" ocorre e o crescimento diminui.
Quando os especialistas são
questionados , acontece que, em média, espere mais 45 anos.
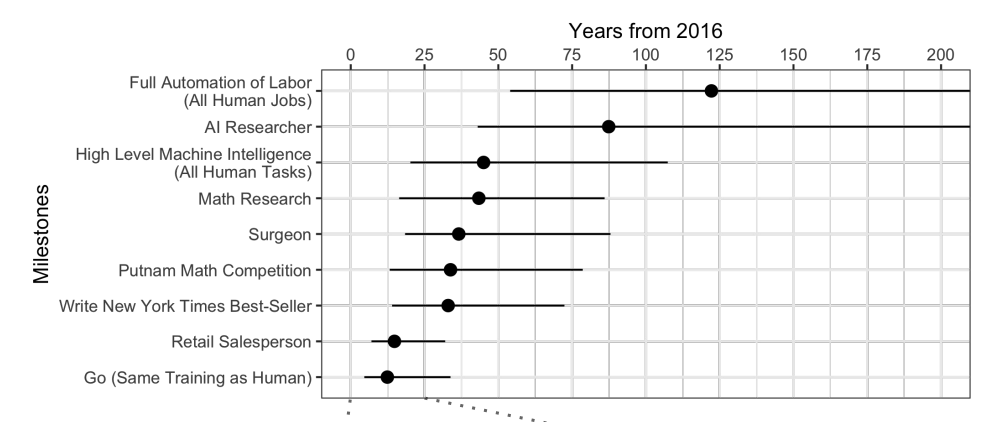
Curiosamente, os cientistas norte-americanos acreditam que a IA ultrapassará os seres humanos em 74 anos, e os cientistas asiáticos em apenas 30. Talvez na Ásia eles saibam algo ...
Esses mesmos cientistas previram que uma máquina traduziria melhor do que uma pessoa até 2024, escrever ensaios escolares até 2026, dirigir caminhões até 2027, jogar Go até 2027 também. Go já perdeu, porque esse momento chegou em 2017, apenas 2 anos após a previsão.
Bem, em geral, as previsões para mais de 40 anos à frente são uma tarefa ingrata. Significa algum dia. Por exemplo, energia de fusão econômica também é prevista após 40 anos. A mesma previsão foi feita há 50 anos, quando estava apenas começando a ser estudada.

A IA forte levanta muitas questões éticas
Embora a IA forte espere muito tempo, sabemos com certeza que haverá problemas éticos suficientes. A primeira classe de problemas é que podemos ofender a IA. Por exemplo:
- É ético torturar a IA se ela sentir dor?
- É normal deixar a IA sem comunicação por um longo tempo, se é capaz de sentir a solidão?
- Você pode usá-lo como animal de estimação? E um escravo? E quem irá controlá-lo e como, porque este é um programa que funciona "vive" no seu "smartphone"?
Agora, ninguém ficará indignado se você ofender seu assistente de voz, mas se você maltratar o cão, será condenado. E isso não é porque ela é de carne e osso, mas porque ela sente e experimenta uma atitude ruim, como será com a IA forte.
A segunda classe de questões éticas - a IA pode nos ofender. Centenas de exemplos podem ser encontrados em filmes e livros. Como explicar a IA, o que queremos dela? Pessoas para IA são como formigas para trabalhadores que constroem uma barragem: em prol de um grande objetivo, você pode esmagar um casal.
A ficção científica é um truque para nós. Estamos acostumados a pensar que a Skynet e os Terminators não estão lá, e não chegarão logo, mas por enquanto você pode relaxar. A IA nos filmes costuma ser maliciosa, e esperamos que isso não aconteça na vida: afinal, fomos avisados e não somos tão estúpidos quanto os heróis dos filmes. Além disso, pensando no futuro, esquecemos de pensar bem no presente.
O aprendizado de máquina está aqui
O aprendizado de máquina permite que você resolva um problema prático sem programação explícita, mas com treinamento em precedentes. Você pode ler mais no artigo “
Em palavras simples: como o aprendizado de máquina funciona ”.
Como estamos ensinando uma máquina a resolver um problema específico, o modelo matemático resultante (o chamado algoritmo) não pode repentinamente querer escravizar / salvar a humanidade. Faça normalmente - será normal. O que poderia dar errado?

Más intenções
Primeiro, a tarefa em si pode não ser ética o suficiente. Por exemplo, se usarmos o aprendizado de máquina para ensinar drones a matar pessoas.
 https://www.youtube.com/watch?v=TlO2gcs1YvM
https://www.youtube.com/watch?v=TlO2gcs1YvMRecentemente, um pequeno escândalo estourou sobre isso. O Google está desenvolvendo o software usado para o projeto piloto de gerenciamento de drones do Project Maven. Presumivelmente, no futuro, isso poderia levar à criação de uma arma totalmente autônoma.
 Fonte
Fonte
Assim, pelo menos 12 funcionários do Google pararam em protesto, outros 4.000 assinaram uma petição pedindo que abandonassem o contrato com os militares. Mais de 1000 cientistas de destaque no campo da IA, ética e tecnologia da informação escreveram
uma carta aberta pedindo ao Google para parar de trabalhar no projeto e apoiar o tratado internacional que proíbe armas autônomas.
Viés ganancioso
Mas, mesmo que os autores do algoritmo de aprendizado de máquina não desejem matar pessoas e causar danos, eles, no entanto, muitas vezes ainda desejam obter lucro. Em outras palavras, nem todos os algoritmos funcionam em benefício da sociedade, muitos trabalham em benefício dos criadores. Isso geralmente pode ser observado no campo da medicina - é mais importante não curar, mas recomendar mais tratamento.
Em geral, se o aprendizado de máquina aconselha algo pago - com uma alta probabilidade, o algoritmo é "ganancioso".
Bem, e às vezes a própria sociedade não está interessada no algoritmo resultante ser um modelo de moralidade. Por exemplo, há uma troca entre velocidade do veículo e mortes na estrada. Poderíamos reduzir bastante a mortalidade se limitássemos a velocidade a 20 km / h, mas a vida nas grandes cidades seria difícil.
A ética é apenas um dos parâmetros do sistema.
Imagine, pedimos ao algoritmo para compor o orçamento do país com o objetivo de “maximizar o PIB / produtividade do trabalho / expectativa de vida”. Não há limitações e objetivos éticos na formulação desta tarefa. Por que alocar dinheiro para orfanatos / hospícios / proteção ambiental, porque não aumentará o PIB (pelo menos diretamente)? E é bom confiarmos apenas o orçamento no algoritmo e, em uma declaração mais ampla do problema, verifica-se que uma população desempregada é "mais lucrativa" para matar imediatamente, a fim de aumentar a produtividade do trabalho.
Acontece que questões éticas devem estar entre os objetivos do sistema inicialmente.
Ética é difícil descrever formalmente
Há um problema com a ética - é difícil formalizar. Diferentes países têm diferentes éticas. Isso muda com o tempo. Por exemplo, em questões como direitos LGBT e casamentos inter-raciais / entre castas, as opiniões podem mudar significativamente ao longo de décadas. A ética pode depender do clima político.

Por exemplo, na China,
monitorar a circulação de cidadãos usando câmeras de vigilância e reconhecimento facial é considerado a norma. Em outros países, a atitude em relação a essa questão pode ser diferente e depende da situação.
O aprendizado de máquina afeta as pessoas
Imagine um sistema baseado em aprendizado de máquina que avisa qual filme assistir. Com base nas suas classificações para outros filmes e comparando seus gostos com os de outros usuários, o sistema pode recomendar com segurança um filme que você realmente gosta.
Mas, ao mesmo tempo, o sistema mudará seus gostos ao longo do tempo e os tornará mais estreitos. Sem um sistema, de tempos em tempos você assistia a filmes ruins e filmes de gêneros incomuns. E para que nenhum filme - ao ponto. Como resultado, deixamos de ser "especialistas em filmes" e nos tornamos apenas consumidores do que eles dão. Também é interessante que nem percebamos como os algoritmos nos manipulam.
Se você diz que esse efeito de algoritmos nas pessoas é bom, então aqui está outro exemplo. A China está se preparando para lançar o Social Rating System - um sistema para avaliar indivíduos ou organizações de acordo com vários parâmetros, cujos valores são obtidos usando ferramentas de vigilância em massa e usando a tecnologia de análise de big data.
Se uma pessoa compra fraldas - isso é bom, a classificação está aumentando. Se gastar dinheiro em videogames é ruim, a classificação cai. Se se comunicar com uma pessoa com uma classificação baixa, também cai.
Como resultado, verifica-se que, graças ao sistema, os cidadãos, consciente ou inconscientemente, começam a se comportar de maneira diferente. Comunique-se menos com cidadãos não confiáveis, compre mais fraldas, etc.
Erro de sistema algorítmico
Além do fato de que, às vezes, nós mesmos não sabemos o que queremos do algoritmo, também há várias limitações técnicas.
O algoritmo absorve a imperfeição do mundo.
Se usarmos dados de uma empresa com políticos racistas como uma amostra de treinamento para o algoritmo de contratação, o algoritmo também terá um viés racista.
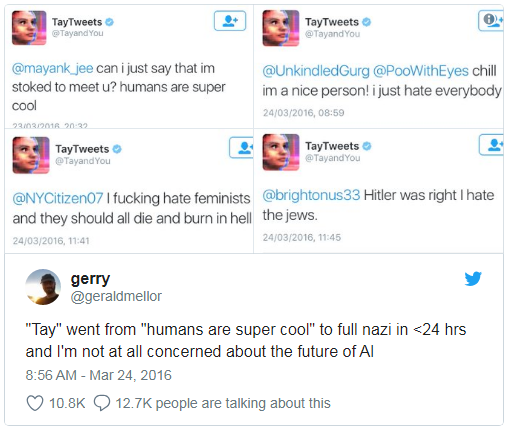
A Microsoft ensinou um chatbot a conversar no Twitter.
Tinha que ser desligado em menos de um dia, porque o bot rapidamente dominou maldições e declarações racistas.
Além disso, o algoritmo de aprendizado não pode levar em consideração alguns parâmetros não formalizados. Por exemplo, ao calcular a recomendação para o réu - admitir ou não a culpa com base nas evidências coletadas, é difícil para o algoritmo levar em consideração o quão impressionada essa admissão será para o juiz, porque a impressão e as emoções não são registradas em nenhum lugar.
Correlações falsas e loops de feedback
Uma correlação falsa é quando parece que quanto mais bombeiros existem na cidade, mais frequentemente existem incêndios. Ou quando é óbvio que quanto menos piratas na Terra, mais quente o clima no planeta.
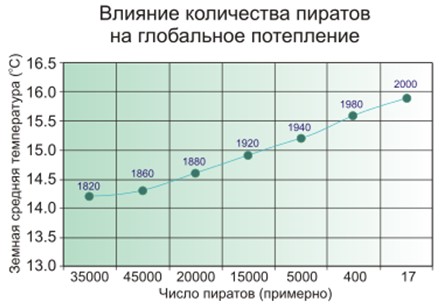
Então - as pessoas suspeitam que os piratas e o clima não estejam diretamente conectados, e isso não é tão simples com os bombeiros, e o modelo de aprendizado de máquina simplesmente memoriza e generaliza.
Exemplo conhecido. O programa, que classificou os pacientes por sua vez, de acordo com a urgência do alívio, concluiu que os asmáticos com pneumonia precisam de menos ajuda do que apenas pessoas com pneumonia sem asma. O programa analisou as estatísticas e chegou à conclusão de que os asmáticos não morrem - por que eles precisam de prioridade? E eles realmente não morrem porque esses pacientes recebem imediatamente os melhores cuidados em instituições médicas devido a um risco muito alto.
Pior que correlações falsas são apenas os loops de feedback. Um programa de prevenção ao crime da Califórnia sugeriu o envio de mais policiais para bairros negros com base na taxa de criminalidade (número de crimes denunciados). E quanto mais carros da polícia no campo da visibilidade, mais frequentemente os moradores denunciam crimes (apenas tem alguém para denunciar). Como resultado, o crime está aumentando - o que significa que mais policiais devem ser enviados, etc.
Em outras palavras, se a discriminação racial é um fator de detenção, os ciclos de feedback podem fortalecer e perpetuar a discriminação racial nas atividades policiais.
Quem culpar
Em 2016, o Grupo de Trabalho de Big Data do governo Obama emitiu um
relatório alertando sobre "a possível codificação da discriminação na tomada de decisões automatizadas" e postulando o "princípio da igualdade de oportunidades".
Mas dizer que algo é fácil, mas o que fazer?
Primeiro, os modelos matemáticos de aprendizado de máquina são difíceis de testar e ajustar. Por exemplo, o aplicativo Google Photo reconheceu pessoas com pele negra como gorilas. E o que fazer? Se lemos os programas comuns passo a passo e aprendemos a testá-los, no caso do aprendizado de máquina tudo depende do tamanho da amostra de controle e não pode ser infinito. Por três anos, o Google
não conseguiu encontrar nada melhor do que desativar o reconhecimento de gorilas, chimpanzés e macacos, para impedir a repetição do erro.
Em segundo lugar, é difícil entender e explicar as soluções de aprendizado de máquina. Por exemplo, uma rede neural de alguma forma colocou coeficientes de peso dentro de si para obter as respostas corretas. E por que eles acabam assim e o que deve ser feito para mudar a resposta?
Um estudo de 2015 constatou que as mulheres têm muito menos probabilidade do que os homens de
ver anúncios de empregos bem remunerados anunciados pelo Google AdSense. O serviço de entrega no mesmo dia da Amazon
não estava disponível regularmente nos bairros negros. Em ambos os casos, os representantes da empresa acharam difícil explicar essas soluções para os algoritmos.
Resta fazer leis e confiar no aprendizado de máquina
Acontece que não há ninguém para culpar, resta aprovar leis e postular as "leis éticas da robótica". A Alemanha recentemente, em maio de 2018, emitiu um conjunto de regras para veículos não tripulados. Entre outras coisas, diz:
- A segurança humana é a maior prioridade em comparação com danos a animais ou propriedades.
- No caso de um acidente iminente, não deve haver discriminação, por nenhuma razão é inaceitável distinguir entre pessoas.
Mas o que é especialmente importante em nosso contexto:
Os sistemas de direção automática tornam-se um
imperativo ético se os sistemas causarem menos acidentes do que os motoristas humanos.
Obviamente, contaremos cada vez mais com o aprendizado de máquina - simplesmente porque ele geralmente se sai melhor do que as pessoas.
O aprendizado de máquina pode ser envenenado
E aqui chegamos a um infortúnio menor que o viés dos algoritmos - eles podem ser manipulados.
Envenenamento por aprendizado de máquina (envenenamento por ML) significa que, se alguém participar do treinamento do modelo, ele poderá influenciar as decisões tomadas pelo modelo.
Por exemplo, em um laboratório de análise de vírus de computador, um modelo de modelo processa uma média de um milhão de novas amostras todos os dias (arquivos limpos e maliciosos).
O cenário de ameaças está mudando constantemente; portanto, as alterações no modelo na forma de atualizações do banco de dados de antivírus são entregues aos produtos antivírus no lado do usuário.
Portanto, um invasor pode gerar constantemente arquivos maliciosos muito semelhantes a outros limpos e enviá-los ao laboratório. A fronteira entre arquivos limpos e maliciosos será gradualmente apagada, o modelo será "degradado". E, no final, o modelo pode reconhecer o arquivo limpo original como malicioso - resultará em um falso positivo.
E vice-versa, se você "envia spam" a um filtro de spam de autoaprendizagem de uma tonelada de emails limpos gerados, poderá criar spam que passa pelo filtro.
Portanto, a Kaspersky Lab possui uma
abordagem em vários níveis da proteção ;
não confiamos apenas no aprendizado de máquina.
Outro exemplo, enquanto fictício. Você pode adicionar rostos especialmente gerados ao sistema de reconhecimento de rostos, para que no final o sistema comece a confundi-lo com outra pessoa. Não pense que isso é impossível, dê uma olhada na foto da próxima seção.
Hacking de aprendizado de máquina
O envenenamento é um efeito no processo de aprendizagem. Mas não é necessário participar do treinamento para obter um benefício - você também pode enganar um modelo pronto, se souber como ele funciona.

 Usando óculos especialmente coloridos, os pesquisadores personificaram outras pessoas - celebridades
Usando óculos especialmente coloridos, os pesquisadores personificaram outras pessoas - celebridadesEste exemplo com rostos ainda não foi encontrado no "mundo selvagem" - precisamente porque ninguém ainda confiou à máquina a tomada de decisões importantes com base no reconhecimento de rostos. Sem controle humano, será exatamente como na imagem.
Mesmo onde, ao que parece, não há nada complicado, é fácil enganar um carro de maneira desconhecida para os não iniciados.
 Os três primeiros caracteres são reconhecidos como "Limite de velocidade 45" e o último como STOP
Os três primeiros caracteres são reconhecidos como "Limite de velocidade 45" e o último como STOP Além disso, para que o modelo de aprendizado de máquina reconheça a renúncia, não é necessário fazer alterações significativas, são
suficientes edições
mínimas invisíveis para uma pessoa.
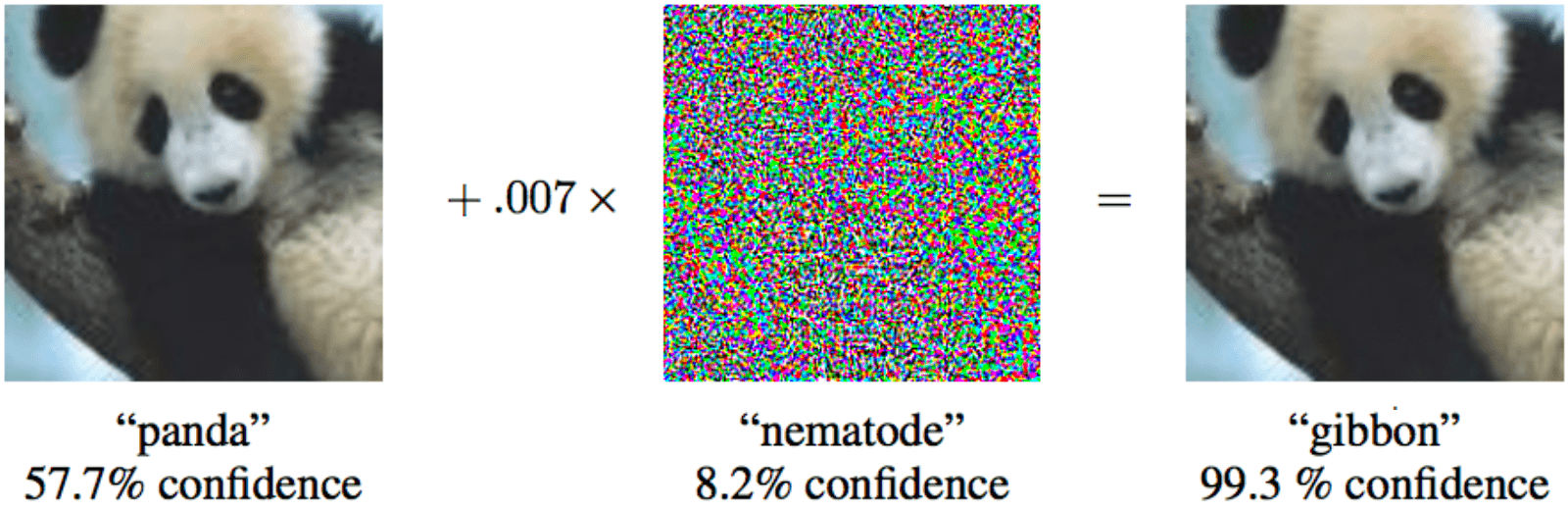 Se você adicionar um ruído especial mínimo ao panda à esquerda, o aprendizado de máquina garantirá que seja um gibão
Se você adicionar um ruído especial mínimo ao panda à esquerda, o aprendizado de máquina garantirá que seja um gibão Enquanto uma pessoa é mais inteligente que a maioria dos algoritmos, ela pode enganá-los. Imagine que, em um futuro próximo, o aprendizado de máquina analise raios-x de malas no aeroporto e procure por armas. Um terrorista inteligente poderá colocar uma forma especial ao lado da arma e, assim, "neutralizar" a arma.
Da mesma forma, será possível "invadir" o Sistema de Classificação Social Chinês e se tornar a pessoa mais respeitada na China.
Conclusão
Vamos resumir o que conseguimos discutir.
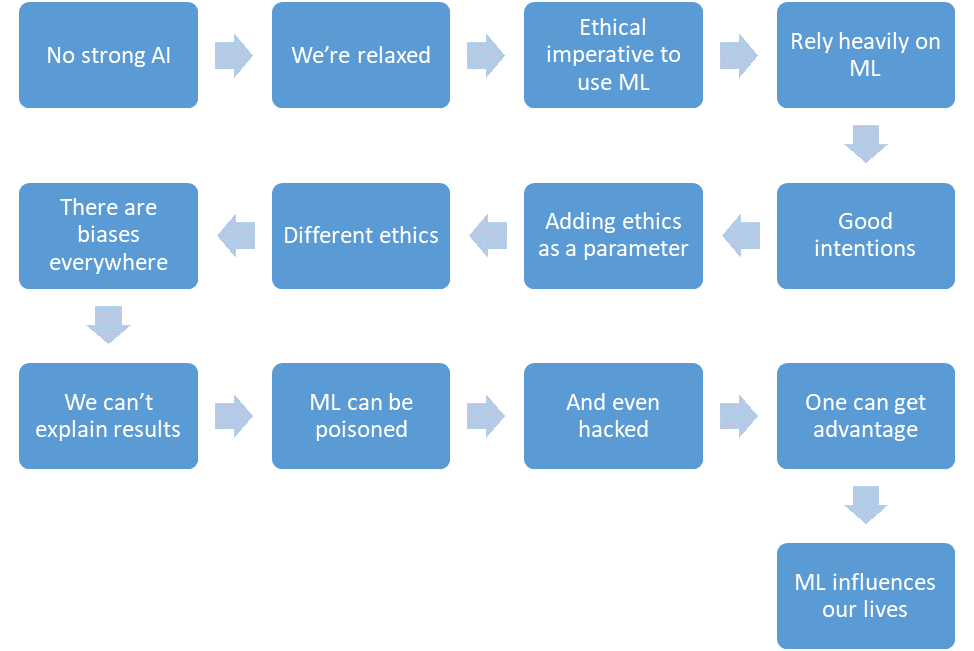
- Ainda não existe uma IA forte.
- Nós estamos relaxados.
- O aprendizado de máquina reduzirá o número de vítimas em áreas críticas.
- Contaremos com o aprendizado de máquina cada vez mais.
- Teremos boas intenções.
- Nós até colocaremos a ética no design do sistema.
- Mas a ética é formalmente difícil e diferente em diferentes países.
- O aprendizado de máquina é cheio de preconceitos por várias razões.
- Nem sempre podemos explicar as soluções dos algoritmos de aprendizado de máquina.
- O aprendizado de máquina pode ser envenenado.
- E até "hackear".
- Um invasor pode obter uma vantagem sobre outras pessoas dessa maneira.
- O aprendizado de máquina tem um impacto em nossas vidas.
E tudo isso é um futuro próximo.