
Em 28 de agosto, o CNCF (Cloud Native Computing Foundation), por trás do Kubernetes, Prometheus e outros projetos de código aberto para aplicativos modernos em nuvem,
anunciou a adoção de um novo produto em sua sandbox -
TiKV .
Esse banco de dados transacional distribuído e com valor-chave nasceu como uma adição ao
TiDB , um sistema de gerenciamento de banco de dados distribuído que oferece recursos OLTP e OLAP e oferece compatibilidade com o protocolo MySQL ... Mas vamos falar sobre isso um após o outro.
TiDB como pai
Vamos começar com o projeto TiDB "pai", criado pela empresa chinesa PingCAP Inc.

O primeiro grande lançamento público deste DBMS - 1.0 -
ocorreu menos de um ano atrás. Suas principais características são “hibridismo”, combinando processamento de dados transacionais e analíticos (processamento transacional / analítico híbrido, HTAP), bem como a compatibilidade já mencionada com o protocolo MySQL. Uma imagem mais completa do TiDB surge ao mencionar outros recursos que já são comuns para novos DBMSs, como escalabilidade horizontal, alta disponibilidade e conformidade estrita com o ACID.
A arquitetura geral do TiDB é a seguinte:
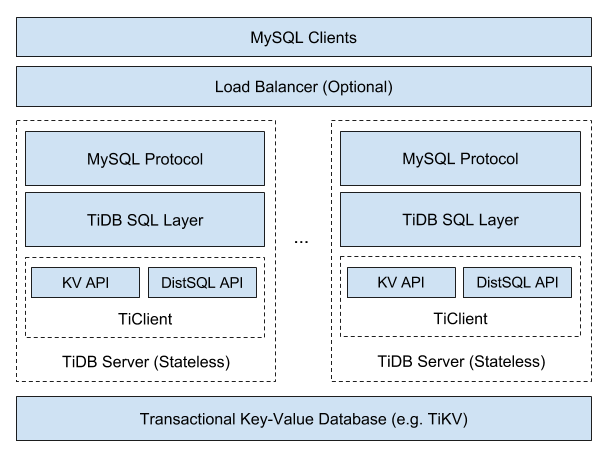
Como o TiDB oferece escalabilidade NoSQL e garantias ACID, ele é classificado como
NewSQL . Os autores não escondem o fato de terem criado o produto sob a inspiração de outros representantes do NewSQL:
Google Spanner e
F1 . No entanto, os desenvolvedores chineses insistiram em "suas melhores práticas e soluções ao escolher a tecnologia". Em particular, eles escolheram um algoritmo para resolver problemas de consenso do
Raft (em vez do
Paxos , que é usado no Spanner), armazenamento
RocksDB (em vez de um sistema de arquivos distribuído) e Go (e Rust) como linguagem de programação.
Muitos detalhes sobre o dispositivo TiDB podem ser encontrados no relatório “
How build build TiDB ” do co-fundador e CEO da PingCAP - Max Liu - e retornaremos a alguns deles intimamente relacionados ao TiKV. O código-fonte TiDB é
distribuído sob a Licença Apache gratuita v2. Entre seus
principais usuários , Lenovo, Meizu, Banco de Pequim, Banco Industrial e Comercial da China, etc. são mencionados.
O que é o TiKV e qual o papel do TiDB (e não apenas) no mundo?
Arquitetura e recursos do TiKV
Vamos voltar à arquitetura geral do TiDB, em uma apresentação ligeiramente diferente:

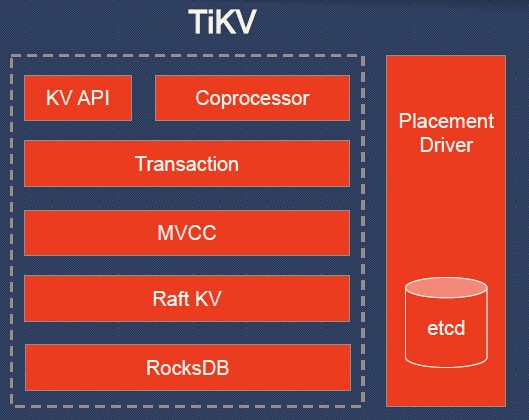
Você pode ver que o próprio TiDB fornece implementação SQL e compatibilidade com MySQL *, enquanto o restante do trabalho é atribuído ao cluster TiKV. O que é esse "resto do trabalho"? Aqui está um diagrama mais detalhado:
* Em duas fotos sobre a camada de compatibilidade com o MySQL no TiDB.A conversão de tabelas em valor-chave ocorre para que, a partir das consultas:
INSERT INTO user VALUES (1, "bob", "huang@pingcap.com"); INSERT INTO user VALUES (2, "tom", "tom@pingcap.com");
... acontece:

Os índices no TiDB são pares comuns, cujos valores indicam uma linha de dados:

Explicações para o esquema TiKV:
- API KV - um conjunto de interfaces de programa para gravação / leitura de dados;
- Coprocessador - uma estrutura de coprocessador para suportar computação distribuída (comparada com a mesma para o HBase);
- Transação - um modelo de transação semelhante ao Google Percolator (protocolo de confirmação em 2 fases; usa alocador de carimbo de data / hora; veja também comparação com o Spanner );
- MVCC (MultiVersion Concurrency Control) para leitura sem bloqueios e transações ACID (os dados são marcados com versões; quaisquer alterações feitas na transação atual não são visíveis para outras transações até o momento da confirmação);
- Raft KV - o já mencionado algoritmo Raft usado para dimensionamento horizontal e consistência dos dados; sua implementação no Rust é portada do etcd (verificada por exploração extensiva); A propósito, os autores do TiKV declararam "escalabilidade simples para mais de 100 TB de dados";
- RocksDB - armazenamento local do tipo de valor-chave, também já bem estabelecido em projetos de produção em larga escala (Facebook);
- Driver de posicionamento - o "cérebro" do cluster, criado de acordo com o conceito do Google Spanner e responsável por armazenar metadados sobre as regiões, suportando o número necessário de réplicas e até a distribuição de carga (usando o Raft).

Se generalizarmos as interconexões dos componentes principais, obtemos o seguinte:
- Cada nó do cluster TiKV possui um ou mais repositórios (RocksDB).
- Cada repositório tem muitas regiões .
- Uma região é uma "unidade básica de movimentação de dados com valores-chave", é replicada (usando o Raft) para muitos nós. Esses conjuntos de réplicas formam grupos de jangada .
- Por fim, o Placement Driver que gerencia esse cluster, como você pode ver, é um cluster.
Instalação e teste de TiKV
A base de código TiKV é escrita principalmente no Rust, mas também possui vários componentes de terceiros em outros idiomas (RocksDB em C ++ e gRPC no Go).
Distribuído sob a mesma licença gratuita do Apache v2.
Conforme mencionado no início do artigo, o TiKV apareceu inicialmente como um componente importante do TiDB, mas hoje pode ser operado dentro deste DBMS e separadamente. (Mas, em qualquer caso, sua operação requer um
driver de posicionamento escrito em Go e distribuído como um componente separado).
A
instrução mais curta para
iniciar o TiKV junto com o DBMS do TiDB requer Git, Docker (17.03+), Docker Compose (1.6.0+), MySQL Client e se resume ao seguinte:
git clone https://github.com/pingcap/tidb-docker-compose.git cd tidb-docker-compose && docker-compose pull docker-compose up -d
O resultado desses comandos será a implantação de um cluster TiDB, que por padrão consiste nos seguintes componentes:
- 1 cópia do TiDB real;
- 3 cópias de TiKV;
- 3 instâncias do driver de posicionamento;
- Prometeu e Grafana (para monitoramento e gráficos) ;
- 2 cópias (master + slave) TiSpark (camada para iniciar o Apache Spark em cima do TiDB / TiKV para executar solicitações OLAP complexas) ;
- 1 instância do TiDB-Vision (para visualização do driver de posicionamento) .
Trabalho adicional com o DBMS expandido:
- conexão via cliente MySQL:
mysql -h 127.0.0.1 -P 4000 -u root ; - Interface da web da Grafana para exibir o status do cluster -
http://localhost:3000 em admin / admin; - Interface da web TiDB-Vision para obter informações sobre balanceamento de carga em um cluster e migração de dados por nós -
http://localhost:8010 ; - Interface da web do Spark -
http://localhost:8080 (acesso ao TiSpark - através do spark://127.0.0.1:7077 ).
Se você deseja um
cluster TiDB não muito padrão (ou seja, redimensioná-lo, as imagens do Docker usadas, portas etc.), depois de clonar o
repositório tidb-docker-compose , você pode editar a configuração do Docker Compose:
$ cd tidb-docker-compose $ vi compose/values.yaml $ helm template compose > generated-docker-compose.yaml $ docker-compose -f generated-docker-compose.yaml pull $ docker-compose -f generated-docker-compose.yaml up -d
Para obter ainda mais personalização, consulte “
Personalizar o TiDB Cluster ” para obter informações sobre de onde vêm as configurações do TiDB, TiKV, Placement Driver e outras especificações.
Para uma
implantação conveniente
do TiDB no cluster Kubernetes, o operador com o mesmo nome foi preparado -
Operador TiDB . Está nos gráficos do Helm, portanto, a instalação pode ser reduzida aos seguintes comandos (slide da
apresentação no TiDB DevConf 2018):

A propósito, a mesma apresentação fala sobre as opiniões dos desenvolvedores de TiDB sobre o monitoramento desse DBMS. Infelizmente, a descrição do texto está em chinês, mas uma idéia geral pode ser obtida nesses slides:

Retornando ao tópico diretamente TiKV - este projeto publicou seus guias de lançamento para fins de teste:
E para a
implantação do
TiKV na produção, há desenvolvimentos prontos com o Ansible - novamente,
com e
sem o TiDB .
Finalmente, como as interfaces para trabalhar com o TiKV são oferecidas:
Os
planos dos desenvolvedores também incluem a criação de um cliente no Rust.
Sumário
Tendo surgido como um componente de um projeto maior de código aberto de uma empresa chinesa, a TiKV já conseguiu ganhar fama em círculos bastante amplos.
As estatísticas do GitHub mostram não apenas mais de 3600 estrelas, mas também quase 500 garfos e quase 100 colaboradores (embora apenas duas dúzias deles tenham feito mais de 10 confirmações).
Associar a TiKV ao número
de projetos CNCF e o fato de este ser o primeiro projeto desse tipo também indica claramente o reconhecimento do produto pela comunidade nativa da nuvem ... e deve incentivar o desenvolvimento mais ativo de sua base de códigos por terceiros (ou seja, fora da empresa-mãe e do DBMS ) por especialistas.
PS
Leia também em nosso blog: