
Este artigo é dedicado ao estudo da estrutura de arquivos do disco rígido de um gravador de vídeo de oito canais para fins de extração em massa de arquivos de vídeo. No final do artigo, está a implementação do programa correspondente em C.
Gravador de vídeo (DVR abreviado) O QCM-08DL é usado em sistemas de vigilância por vídeo e permite gravação de áudio e vídeo em oito canais. Este modelo, na minha opinião, é um dos mais baratos e ao mesmo tempo confiáveis em operação. O formato de compactação de vídeo é o popular formato H264. Para áudio, o formato de compactação é ADPCM. Vídeo e áudio são gravados em um disco rígido SATA (HDD) de computador padrão instalado dentro do DVR. Usando o próprio DVR, é possível visualizar gravações pesquisando-as por data e hora. Além disso, é possível extrair dados para um arquivo em uma mídia externa. Em primeiro lugar, a uma unidade USB conectada à interface USB do DVR. Em segundo lugar - para o computador através da interface WEB do DVR. O nome do arquivo resultante é longo e inclui a data de gravação, hora de início e término, canal de gravação e outras informações adicionais. A extensão do arquivo é ".264". Um exame do conteúdo desse arquivo deixou claro para mim que o contêiner de mídia no qual os fluxos de áudio e vídeo são compactados está longe de ser padrão. Esse arquivo pode ser aberto usando o player que acompanha o DVR. O jogador está muito desconfortável. Mas também, você pode usar o programa repacker no contêiner AVI, que também está incluído. Este programa reembala novamente o fluxo de vídeo, deixando-o no formato H264. E o fluxo de som é convertido de ADMCM para PCM, aumentando em 4 vezes o tamanho. O resultado é um arquivo .avi que pode ser reproduzido por qualquer player padrão. Percebo imediatamente que esse programa de reembalagem é muito inconveniente. Permite executar operações em apenas um arquivo. Para reembalar um conjunto de arquivos, você deve abri-los por vez.
As seguintes tarefas foram definidas.
- Obtenha acesso a todos os arquivos .264 no disco rígido do DVR, conectando o disco rígido ao computador.
- Estudar o algoritmo pelo qual o programa repacker 264-avi padrão funciona e criar o mesmo programa que executaria as mesmas operações, mas não em um, mas em um grupo inteiro de arquivos, com um clique.
A primeira tarefa, à primeira vista, pode parecer muito simples: você só precisa conectar o disco rígido ao computador e abrir as partições no Explorer. No entanto, existem armadilhas. Este artigo é dedicado à primeira tarefa.
Eu já sabia de antemão que o shell do software do microcontrolador DVR é baseado em um sistema operacional semelhante ao Linux. Portanto, o particionamento do disco rígido provavelmente também será semelhante ao Linux. Portanto, você precisa de um computador Linux. No meu caso, a capacidade do disco rígido é de 1 TB, um computador com OS Xubuntu. Depois de conectar o disco rígido ao computador, eu consegui ver apenas uma partição por vários gigabytes. Isso claramente não é o que você precisa. Dentro da seção, existem muitas pastas com o formato de nome “AAAA-MM-DD” correspondentes às datas dos registros. Dentro de cada pasta, existem muitos arquivos correspondentes às entradas. Arquivos com o mesmo nome daqueles obtidos ao extrair do DVR. No entanto, seu tamanho é muitas vezes menor e a extensão não é .264, mas .nvr. Deve-se supor que esses mesmos arquivos nvr são chaves para os 264 arquivos correspondentes (ou seus fluxos de mídia), cujo conteúdo está localizado no espaço principal do disco rígido. Copiei os dados da pasta do arquivo para um meio separado para futuras pesquisas.
Usei muitas ferramentas de software para pesquisa: um editor de disco (também é um editor de arquivos binários) DiskExplorer (usei o WinHex posteriormente), MS Excel para cálculos auxiliares e fixação de resultados, ambiente de programação Dev-C ++ para escrever programas de console auxiliares e finais, etc. Neste artigo, tentarei falar sobre esse procedimento.
Primeiro, observe o primeiro setor do disco rígido (um setor (1 LBA) ocupa 512 bytes). Este setor, como regra, contém uma estrutura MBR. Ele inclui um gerenciador de inicialização e uma seção básica do sumário. A estrutura deste setor, bem como a estrutura da descrição da seção, é fornecida abaixo (retirada da Wikipedia).

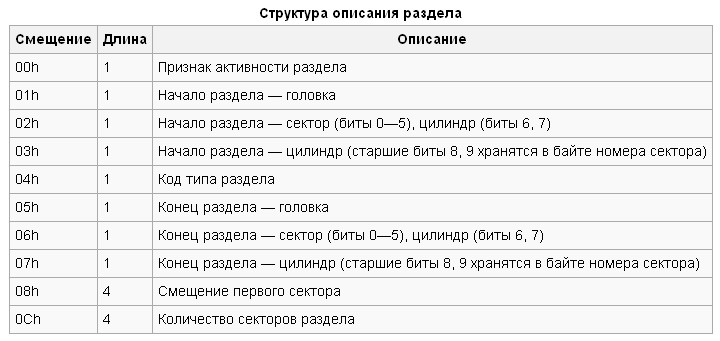
No caso do disco rígido investigado, temos o seguinte. Observando a figura abaixo e seguindo as tabelas acima, vemos que o carregador de inicialização está ausente. Mas estamos mais interessados na tabela de partição. É destacado em uma moldura vermelha. Os últimos dois bytes (preenchimento azul) - assinatura MBR. Você pode ver na tabela de partição que o disco está dividido em duas seções. O código para o tipo da primeira seção (preenchimento amarelo) é 0x0B. Esta é uma partição FAT32. O código para o tipo do segundo (preenchimento laranja) é 0x83. Esta é uma das partições Linux (no sentido de EXT). Os bytes do código do tipo de partição estão circulados em azul.
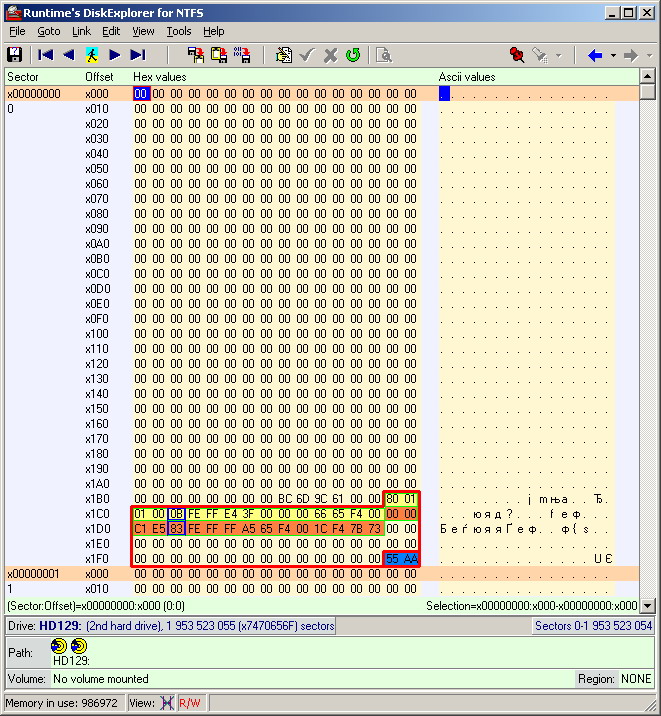
Uma descriptografia completa do setor MBR com uma tabela de seções e seus parâmetros é fornecida abaixo.
Prestando atenção ao tamanho das partições (contando o número de setores em gigabytes), é fácil adivinhar que no computador com o sistema operacional Xubuntu foi a primeira partição que ocupou uma pequena parte do espaço em disco. A propósito, no Windows XP, apenas a primeira partição também foi exibida, mas não foi aberta no explorer. E por que, então, a segunda partição Linux não apareceu no sistema operacional Xubuntu?
Tendo estudado anteriormente a estrutura e organização do sistema de arquivos Linux usando EXT2 como exemplo, comecei a estudar a segunda seção.
Como você pode ver na tabela de seções, a segunda seção começa com o setor 16016805. O manual do sistema de arquivos EXT2 indica a presença do chamado superbloco, localizado a 1024 bytes desde o início da seção (ou seja, dois setores desde o início). No entanto, o setor 16016805 + 2 = 16016807 estava vazio. Mas o primeiro setor 16016805 em sua estrutura parecia um superbloco. Mas seu conteúdo não correspondia totalmente à descrição do conteúdo do superbloco do manual. O superbloco é o bloco principal, que contém um tipo de tabela de várias constantes e parâmetros para o funcionamento do sistema de arquivos: endereços de posições e tamanhos de outros blocos necessários, em particular cabeçalhos de registros e diretórios de arquivos. Mais pesquisas nesta seção me levaram a apenas uma conclusão: o DVR usa seu próprio sistema de arquivos.
No futuro, decidi olhar para o primeiro setor da primeira seção (setor 63) e rolar para baixo. Foi encontrado no conteúdo do setor 65 (dois setores abaixo) que é completamente semelhante ao conteúdo do superbloco FS EXT2, descrito no manual. Mais pesquisas levaram à conclusão de que a primeira partição do HDD DVR é a partição EXT2, exibida no sistema operacional Xubuntu, independentemente da marca 0x08 (e não EXT) no índice! Assim, a primeira partição do disco rígido do DVR é a partição EXT2, na qual os arquivos nvr são gravados, que são as chaves para as gravações de vídeo necessárias.
Escreverei brevemente sobre a estrutura dos arquivos .264, que também examinei anteriormente. Esta informação será necessária no futuro para estudar a segunda seção do HDD. Como em qualquer contêiner de mídia, em "264" há um cabeçalho com informações de serviço e tags de mídia, bem como fluxos de áudio e vídeo que seguem em pequenos blocos um após o outro. Em um deslocamento de 0x84 bytes desde o início do arquivo, a palavra-chave "MDVR96NT_2_R" é registrada. Antes desta palavra, existem bytes relacionados à data e hora da gravação. Mas essa informação está contida no nome do arquivo, portanto, não merece atenção especial aqui. Depois disso, vêm muitos bytes de zeros. As informações principais com fluxos de áudio e vídeo são originadas em um deslocamento de 65.536 bytes. Os blocos de fluxo de vídeo começam com um cabeçalho de 8 bytes "01dcH264" (também encontrado "00dcH264"). Os 4 bytes a seguir descrevem o tamanho do bloco atual do fluxo de vídeo em bytes. Após 4 bytes de zeros (00 00 00 00), o próprio bloco de fluxo de vídeo é iniciado. Os blocos de fluxo de áudio têm o título "03wb" (embora, de acordo com minhas observações, o primeiro caractere do cabeçalho em alguns casos não tenha sido necessariamente "0"). Depois - 12 bytes de informações que ainda não descobri. E começando com o 17º byte - um fluxo de áudio com um comprimento fixo de 160 bytes. Não há tags no final do arquivo.
Continuamos estudando a estrutura dos arquivos e diretórios localizados na primeira partição do disco rígido. Como mencionado acima, o conteúdo da seção foi copiado para uma mídia separada por meio de um explorador regular no sistema operacional Xununtu. Em cada diretório (diretório), além dos arquivos nvr, há um arquivo binário chamado "lista_de_arquivo". A julgar pelo nome, ele contém informações sobre a lista de arquivos no diretório atual. Abra este arquivo no editor binário (veja a figura abaixo). Eu investiguei a estrutura desse arquivo, e basicamente não há nada interessante aqui. O arquivo não possui nenhuma informação sobre o local dos fluxos de mídia desejados. No entanto, escreverei brevemente sobre essa estrutura. Os primeiros 32 bytes são um cabeçalho com algumas constantes. Os próximos 16 bytes estão relacionados à data e hora e ao número de arquivos no diretório atual. Isto é seguido por 48 bytes de constantes. Próximo - 8 bytes de constantes, indicando o início do registro do arquivo. Em seguida, 96 bytes indicando o caminho completo para o arquivo nvr, incluindo seu nome. Próximo - 24 bytes relacionados ao horário (o número de segundos decorridos desde o início do dia, o início e o final do vídeo) e outros atributos do vídeo. E assim por diante, por analogia, para todos os arquivos nvr no diretório atual. O número deles é igual ao número de vídeos do dia atual, indicado pelo nome do diretório atual. Para que serve esse arquivo? Aparentemente, para acelerar a pesquisa de vídeo na interface do DVR.
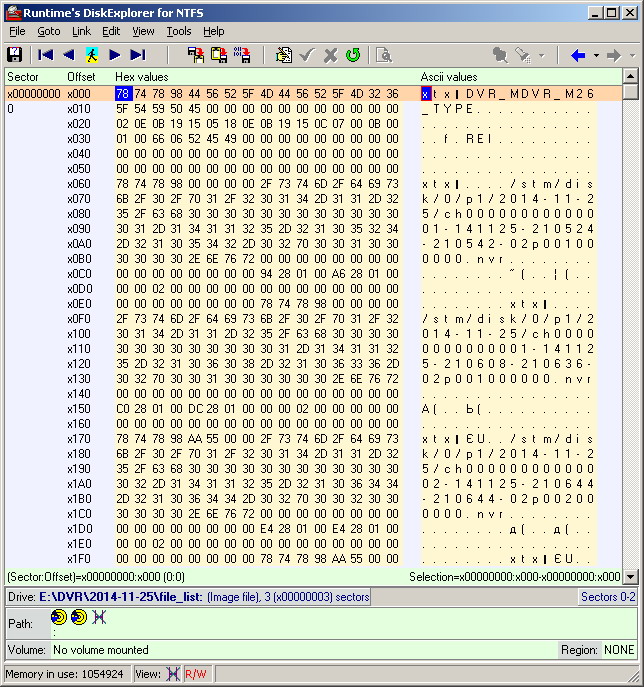
Vamos continuar estudando a estrutura dos arquivos nvr. A aparência de um desses arquivos em um editor binário (mais precisamente, em um hexadecimal) é mostrada na figura abaixo. Sem entrar em detalhes da descrição da estrutura de conteúdo (parte da qual permaneceu um mistério para mim), destaquei os parâmetros mais básicos, que são a chave a ser encontrada. Esses são valores de 32 bits (4 bytes), localizados a cada 32 bytes, iniciando no byte no deslocamento 40. Na figura, eles são destacados em vermelho. No futuro, fiquei convencido de que isso é suficiente para a chave dos vídeos. Lembro que 4 bytes do valor desse parâmetro-chave estão localizados do menor para o maior, mas não vice-versa! Essa notação se deve à arquitetura do processador do PC. O exemplo na figura mostra o primeiro arquivo nvr do primeiro diretório. Corresponde à primeira gravação de vídeo feita pelo DVR. Obviamente, os valores dos parâmetros, que chamei de chave, no exemplo acima, formam uma sequência de números inteiros, começando do zero e indo em ordem crescente. Examinando outros arquivos nvr e olhando exatamente para esses bytes especificados, também foram vistos números inteiros, ascendentes. Mas essa sequência naturalmente não começou mais do zero e, em alguns casos, lacunas em um ou dois números foram observadas em alguns lugares. Por exemplo (números do trator): 435, 436, 438, 439, 442, ... (ou em hexadecimal: B3010000, B4010000, B6010000, B7010000, BA010000, ...).
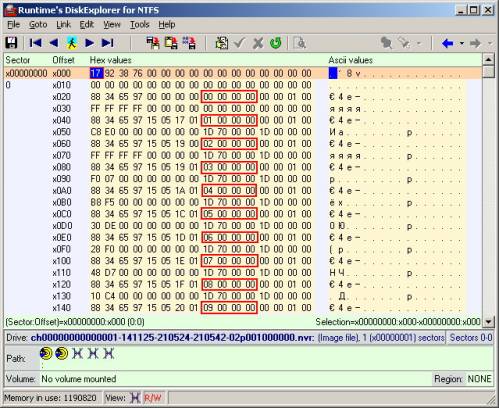
Essa sequência com omissões ocorreu nos arquivos nvr correspondentes aos vídeos que o DVR gravou simultaneamente de dois ou mais canais. Ou seja, por exemplo, se a sequência "435, 436, 438, 439, 442, ..." se refere ao vídeo de um canal, os valores ausentes (437, 440, 441) se relacionam ao vídeo de outro canal, realizado na mesma ponto no tempo. Eu mesmo estava convencido disso vendo e comparando os arquivos nvr correspondentes, com base no nome deles. Não há dúvida de que os números acima formam os números de algumas partes relacionadas aos vídeos. Resta apenas desvendar o relacionamento entre esses números e as coordenadas do espaço em disco no qual os dados estão localizados.
Além disso, foi descobrir exatamente quais dados são divididos nos segmentos numerados acima? A primeira suposição - os dados são fluxos de áudio e vídeo, que no contêiner 264 são representados por blocos curtos e, como foi dito, os blocos do fluxo de vídeo têm tamanhos diferentes. Ao mesmo tempo, o DVR coleta esses fluxos e os empacota em um contêiner 264 no estágio de extração de gravações de vídeo em mídia externa. A segunda suposição é que o DVR empacota fluxos de áudio e vídeo em um contêiner 264 no início e durante a captura de vídeo. E, ao mesmo tempo, os dados do arquivo .264 já gerados são gravados no HDD, o que resultaria da extração para um meio externo. Explorando o espaço do HDD em algum lugar no meio da segunda seção, junto com bytes de fluxos de áudio e vídeo e seus cabeçalhos do mesmo tipo que no contêiner 264, também me deparei com os cabeçalhos do próprio contêiner: MDVR96NT_2_R. Após esse cabeçalho, havia também muitos bytes de zeros. Em geral, o estudo mostrou que existe uma segunda opção das duas acima. Portanto, para obter o arquivo .264 desejado, provavelmente, você só precisa conectar todos os segmentos cujos números estão contidos no arquivo nvr correspondente.
Vamos começar a busca pela relação entre o número do segmento e as coordenadas no disco rígido.
O início dos dados do contêiner 264 correspondente à primeira gravação de vídeo (onde a numeração dos segmentos começa do zero) com as ferramentas de pesquisa que encontrei no setor 16046629 (29824 setores desde o início da seção). Podemos fazer uma suposição sobre o chamado parâmetro viés inicial, que participará da fórmula que descreve a dependência desejada.
Vamos pegar dois arquivos nvr correspondentes a vídeos de diferentes canais que o DVR capturou ao mesmo tempo. Para fazer isso, dê uma olhada nos nomes dos arquivos. Por exemplo, os vídeos apontados pelos arquivos "ch00000000000001-150330-160937-161035-02p101000000.nvr" e "ch00000000000004-150330-160000-163000-00p004000000.nvr" foram gravados simultaneamente. O primeiro registro é a gravação do 1º canal, das 16:09:37 às 16:10:35. O segundo registro é um registro do 4º canal, das 16:00:00 às 16:30:00, horário. Ambas as entradas foram feitas em 30 de março de 2015. Na linha do tempo, obviamente, o intervalo de tempo do primeiro registro é um subconjunto do intervalo de tempo do segundo registro. Também levo em conta o fato de que, em um intervalo de tempo menor (na interseção de dois intervalos), o DVR não realizou captura de vídeo em nenhum dos outros seis canais. Navegue pelo conteúdo desses arquivos nvr. Garantiremos que os números ausentes (números de segmento) no segundo arquivo longo estejam necessariamente presentes no primeiro arquivo curto, completa e completamente. Usando o DVR da maneira usual, você precisa extrair pelo menos um dos arquivos .264 mencionados pelos arquivos nvr investigados com antecedência. Digamos que "ch00000000000001-150330-160937-161035-02p101000000.264" foi extraído. Abra-o no editor binário. Como já mencionado, no início deste arquivo, antes da palavra-chave “MDVR96NT_2_R”, existem bytes únicos correspondentes à data e hora da gravação de vídeo contida neste arquivo. Escrevemos todos esses bytes, começando de diferente de zero e terminando com o cabeçalho (quanto menor a cadeia de bytes exclusiva para esta gravação de vídeo, melhor). Além disso, escreva o deslocamento dessa cadeia de bytes desde o início do arquivo. Deve-se observar que no início do arquivo .264 extraído, existem 4 bytes de zeros extras. Isso se tornou visível ao comparar os primeiros 512 bytes do arquivo .264 e o setor de espaço em disco a partir do qual o conteúdo de um dos arquivos .264 começa (um arquivo de quase qualquer sistema de arquivos sempre inicia no início do setor, além disso, um cluster). Ou seja, as informações no arquivo .264 são deslocadas antecipadamente em 4 bytes para a direita. O tamanho (em bytes) de qualquer arquivo .264 é um múltiplo de 512 somente após subtrair primeiro o número 4 do tamanho. Vamos começar a busca pelo setor no qual o arquivo .264 investigado começa. No editor de disco, inicie a função de pesquisa. No campo do valor desejado, insira uma sequência exclusiva de bytes baixados antecipadamente. Para acelerar a pesquisa, insira o valor do deslocamento no campo "pesquisar por deslocamento", subtraindo anteriormente 4. Inicie a pesquisa. Poucas horas depois, a pesquisa foi bem-sucedida. Anotamos o número do setor em que o título exclusivo é encontrado. Seja este o valor de s. Examinamos o conteúdo do arquivo nvr para este vídeo. Escrevemos o número do primeiro segmento (4 bytes no deslocamento 40). Seja esse o valor de b. No total, enquanto sabemos o número do setor de disco (16046629) para o número de segmento zero (na primeira gravação de vídeo) e o número do setor encontrado do disco s para o número de segmento b acabado de ser baixado. Você pode calcular o tamanho estimado do segmento: (s-16046629) / (b-0). Após calcular, obtive o valor 128. Assim, o tamanho do segmento é igual a 128 setores de disco (LBA), ou 128 * 512 = 65536 bytes!
Conduzi outro experimento interessante adicional para finalmente dissipar todas as dúvidas. É descrito abaixo.
Desde o início do setor s, selecionamos uma área no disco com um tamanho comparável ao tamanho de um arquivo .264 que começa com esse setor. Se minhas suposições estiverem corretas, os segmentos de outro arquivo .264, que foi capturado no disco rígido simultaneamente com o primeiro, cairão na área selecionada. Salve esta área em um arquivo (crie uma imagem). Recorte a imagem resultante em arquivos de 65.536 bytes (tamanho do segmento). Isso pode ser feito usando a função "arquivo dividido" no Total Commander. Que sejam peças M1, M2, M3, .... Da mesma forma, cortamos o arquivo .264 estudado (que foi extraído de forma amigável do DVR), mas primeiro removendo 4 bytes de zeros primeiro. Que sejam peças K1, K2, K3, .... Usando a função "Comparar por conteúdo" no Total Commander, comparamos as partes da imagem e as do arquivo .264. (M1 com K1, M2 com K2, etc.), guiados pelos números de segmento do arquivo nvr correspondente. O resultado é o seguinte.
Suponha (números do bulldozer), a cadeia de números no nvr é a seguinte: 435, 436, 438, 439, 442, ... Nesta situação, M1 = K1, M2 = K2, M4 = K3, M5 = K4, M8 = K5, .... Ou seja, as partes nas quais o arquivo de imagem e o arquivo .264 foram divididos são iguais, levando em consideração o avanço correspondente no número de partes do arquivo de imagem, de acordo com as omissões na sequência. Aqui está!No total, obtivemos a dependência estimada: S = 16046629 + 128 * d, onde d é o número do segmento no arquivo nvr e S é o número do setor no disco rígido, começando desde o início do disco a partir do qual o conteúdo do segmento começa. Tamanho do segmento - 128 setores. A fórmula acima não leva em consideração a existência da segunda seção. A dependência é encontrada apenas para um exemplo específico de HDD a 1 TB. Talvez se você colocar uma capacidade diferente no DVR HDD, as constantes terão uma aparência diferente.Para verificar a validade da fórmula, calculamos a posição do primeiro segmento de algum outro arquivo .264 arbitrário, guiado pelo arquivo nvr correspondente. Prestando atenção à data e hora no nome do arquivo, compare-os com os primeiros bytes no cabeçalho .264, localizado no setor calculado. Os bytes que codificam individualmente o número, mês, ano, horas, minutos, segundos, correspondem a dados temporários no nome do arquivo. Portanto, "bata na unha"! Calculamos no arquivo nvr correspondente ao arquivo .264 extraído antecipadamente, o número de segmentos cs. Em geral, seu número é cs = sf / 32-1, em que sf é o tamanho do arquivo nvr. Se o arquivo .264 consistir em segmentos cs, seu tamanho deverá ser igual a cs * 65536 + 4 (o número de segmentos vezes o tamanho do segmento em bytes, mais 4 dos mesmos bytes de zeros). E é mesmo!Ainda assim, tente explorar a segunda seção. Como observado anteriormente, algo semelhante a um superbloco está localizado diretamente no primeiro setor da seção (16016805). E sua cópia exata foi descoberta por sete setores abaixo (16016812). Obviamente, informações básicas diferentes de zero estão no primeiro setor do superbloco. Sua aparência no editor de disco é mostrada na figura abaixo.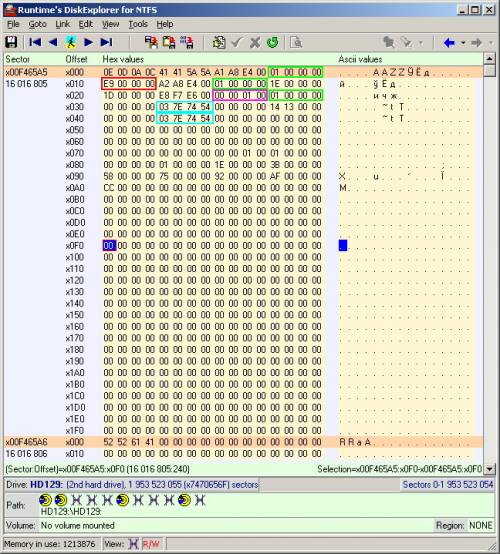 Consegui descriptografar parte dos parâmetros de 4 bytes. A data e hora da montagem da partição são destacadas em azul. A data e a hora são apresentadas na notação de hora especial do Unix (o número de segundos decorridos desde a meia-noite de 1º de janeiro de 1970). No exemplo acima, "03 7E 74 54" (valor decimal 1416920579) corresponde a "Ter, 25 de novembro de 2014 13:02:59 GMT". Para traduzir os valores, usei uma calculadora online especial. O valor 65536 está circulado no quadro roxo.É possível que o intérprete do sistema de arquivos dentro do programa DVR se refira a essa posição do superbloco quando o tamanho do bloco for lido (no contexto anterior, chamei segmentos de blocos). Os valores 1 são destacados no quadro verde e um deles provavelmente indica a posição do início do chamado. bitmap (no número de blocos desde o início da seção). De fatocom antecedência, foi encontrado o início das informações, algo semelhante a um bitmap no setor 16016933 (16016805 + 128 * 1). O valor 233 é destacado no quadro vermelho.Esta é precisamente a posição do início dessas .264 gravações de vídeo desde o início da seção: 16016805 + 128 * 233 = 16046629.Ou seja, a segunda seção pode ser chamada de seção truncada e ligeiramente modificada do EXT2. Tem um superbloco, uma cópia dele, um bitmap. Mas não há os chamados. nós de informações correspondentes aos registros do arquivo. A seção contém dados de arquivos .264 (fluxos de áudio e vídeo), mas os nós de informação (digamos assim) para esses dados estão localizados nos arquivos nvr na primeira seção. Talvez exista uma redação mais competente? Mas isso não é tão importante para mim.Vamos escrever um programa simples para extração em massa de arquivos .264. Devo dizer imediatamente que não tenho muita experiência em programação no Windows. O programa verifica todos os arquivos nvr copiados com antecedência para a seção de 1 TB do novo disco rígido. Ao analisá-los, o programa cria um arquivo .264 com o mesmo nome no mesmo diretório, usando o acesso aos setores do disco rígido original. Anteriormente, uma pasta com o nome “DVR” era criada em uma seção vazia do novo HDD, na qual as pastas por datas são colocadas e copiadas da “maneira usual” no Linux. Foi possível incluir neste programa um algoritmo para trabalhar com a primeira partição Linux para acessar arquivos nvr, de modo a não ter que pré-copiá-los. E você pode adicionar outros recursos convenientes. Sim, era possível, mas naquele momento eu queria fazer tudo o mais rápido possível.Não usei recursão para verificar diretórios, já que o formato dos diretórios é fixo e tem dois níveis de anexo. Consequentemente, apliquei dois ciclos: percorrer as pastas até que elas terminem e percorrer os arquivos em cada pasta com a mesma condição. Para ler arquivos, usei a função fopen. Para trabalhar com setores de disco rígido, usei a funcionalidade WinAPI semelhante ao trabalho com arquivos. Vamos seguir para o código do programa.Bibliotecas precisam disso.
Consegui descriptografar parte dos parâmetros de 4 bytes. A data e hora da montagem da partição são destacadas em azul. A data e a hora são apresentadas na notação de hora especial do Unix (o número de segundos decorridos desde a meia-noite de 1º de janeiro de 1970). No exemplo acima, "03 7E 74 54" (valor decimal 1416920579) corresponde a "Ter, 25 de novembro de 2014 13:02:59 GMT". Para traduzir os valores, usei uma calculadora online especial. O valor 65536 está circulado no quadro roxo.É possível que o intérprete do sistema de arquivos dentro do programa DVR se refira a essa posição do superbloco quando o tamanho do bloco for lido (no contexto anterior, chamei segmentos de blocos). Os valores 1 são destacados no quadro verde e um deles provavelmente indica a posição do início do chamado. bitmap (no número de blocos desde o início da seção). De fatocom antecedência, foi encontrado o início das informações, algo semelhante a um bitmap no setor 16016933 (16016805 + 128 * 1). O valor 233 é destacado no quadro vermelho.Esta é precisamente a posição do início dessas .264 gravações de vídeo desde o início da seção: 16016805 + 128 * 233 = 16046629.Ou seja, a segunda seção pode ser chamada de seção truncada e ligeiramente modificada do EXT2. Tem um superbloco, uma cópia dele, um bitmap. Mas não há os chamados. nós de informações correspondentes aos registros do arquivo. A seção contém dados de arquivos .264 (fluxos de áudio e vídeo), mas os nós de informação (digamos assim) para esses dados estão localizados nos arquivos nvr na primeira seção. Talvez exista uma redação mais competente? Mas isso não é tão importante para mim.Vamos escrever um programa simples para extração em massa de arquivos .264. Devo dizer imediatamente que não tenho muita experiência em programação no Windows. O programa verifica todos os arquivos nvr copiados com antecedência para a seção de 1 TB do novo disco rígido. Ao analisá-los, o programa cria um arquivo .264 com o mesmo nome no mesmo diretório, usando o acesso aos setores do disco rígido original. Anteriormente, uma pasta com o nome “DVR” era criada em uma seção vazia do novo HDD, na qual as pastas por datas são colocadas e copiadas da “maneira usual” no Linux. Foi possível incluir neste programa um algoritmo para trabalhar com a primeira partição Linux para acessar arquivos nvr, de modo a não ter que pré-copiá-los. E você pode adicionar outros recursos convenientes. Sim, era possível, mas naquele momento eu queria fazer tudo o mais rápido possível.Não usei recursão para verificar diretórios, já que o formato dos diretórios é fixo e tem dois níveis de anexo. Consequentemente, apliquei dois ciclos: percorrer as pastas até que elas terminem e percorrer os arquivos em cada pasta com a mesma condição. Para ler arquivos, usei a função fopen. Para trabalhar com setores de disco rígido, usei a funcionalidade WinAPI semelhante ao trabalho com arquivos. Vamos seguir para o código do programa.Bibliotecas precisam disso.#include <windows.h> #include <stdio.h> #include <string.h>
E eu copiei completamente essas funções de algum fórum.
HANDLE openDevice(int device) { HANDLE handle = INVALID_HANDLE_VALUE; if (device <0 || device >99) return INVALID_HANDLE_VALUE; char _devicename[20]; sprintf(_devicename, "\\\\.\\PhysicalDrive%d", device);
A função de cópia contém uma fórmula de dependência linear, que apareceu na teoria acima.
void copy(HANDLE device, HANDLE file, unsigned long int s){ LONG HPos; LONG LPos; __int64 sector; sector = 16046629+128*s; HPos = (sector*512)>>32; LPos = (sector*512); SetFilePointer (device, LPos, &HPos, FILE_BEGIN); DWORD dwBytesRead; DWORD dwBytesWritten; unsigned char buf[65536]; ReadFile(device, buf, 65536, &dwBytesRead, NULL); WriteFile(file, buf, dwBytesRead, &dwBytesWritten, NULL); }
A função principal também é bastante simples.
int main(){ HANDLE hdd = openDevice(1);
Em um computador antigo com um processador Pentium 4 e um controlador PCI SATA, o programa transferiu com êxito até o final um disco rígido completo com vários milhares de arquivos .264 em uma média de 7 horas. Em um novo computador - três vezes mais rápido. Como já observei, o programa não é universal, todas as constantes e variáveis são ajustadas ao meu caso específico de HDD a 1TB. No entanto, você pode trabalhar um pouco mais e torná-lo universal, desenhar uma interface gráfica para ele.
Na segunda parte do artigo, escreverei como "fazer você mesmo" para reembalar do contêiner "264" para o contêiner "avi" padrão.