Bom para todos! Bem, chegou a hora de
nosso próximo
curso de Devops . Provavelmente, este é um dos cursos mais estáveis e de referência, mas ao mesmo tempo o mais diversificado em termos de alunos, já que nenhum grupo se parece com o outro: em um, os desenvolvedores são quase completamente, depois nos próximos engenheiros, depois em administradores e assim por diante. E isso também significa que chegou a hora de materiais interessantes e úteis, além de reuniões on-line.

Este artigo contém recomendações sobre o lançamento de um cluster Kubernetes de nível de produção em um data center local ou localização periférica (localização da borda).
O que significa grau de produção?
- Instalação segura
- O gerenciamento de implantação é realizado usando um processo repetido e gravado;
- O trabalho é previsível e consistente;
- É seguro realizar atualizações e ajustes;
- Para detectar e diagnosticar erros e falta de recursos, há registro e monitoramento;
- O serviço tem "alta disponibilidade" suficiente, levando em consideração os recursos disponíveis, incluindo restrições de dinheiro, espaço físico, energia etc.
- O processo de recuperação está disponível, documentado e testado para uso no caso de uma falha.
Em resumo, o grau de produção significa antecipar erros e preparar a recuperação com o mínimo de problemas e atrasos.

Este artigo é sobre a implantação local do Kubernetes em uma plataforma hipervisor ou bare-metal, dada a quantidade limitada de recursos de suporte em comparação com o aumento nas principais nuvens públicas. No entanto, algumas dessas recomendações podem ser úteis para a nuvem pública se o orçamento limitar os recursos selecionados.
A implantação de um Minikube de um único metal sem metal pode ser um processo simples e barato, mas não é de nível de produção. Por outro lado, você não poderá atingir o nível do Google com a Borg em uma loja offline, filial ou local periférico, embora seja improvável que você precise.
Este artigo descreve dicas para obter uma implantação do Kubernetes no nível de produção, mesmo em situações com recursos limitados.
Componentes importantes no cluster KubernetesAntes de aprofundar nos detalhes, é importante entender a arquitetura geral do Kubernetes.
O cluster Kubernetes é um sistema altamente distribuído baseado no plano de controle e na arquitetura dos nós do trabalhador em cluster, conforme mostrado abaixo:
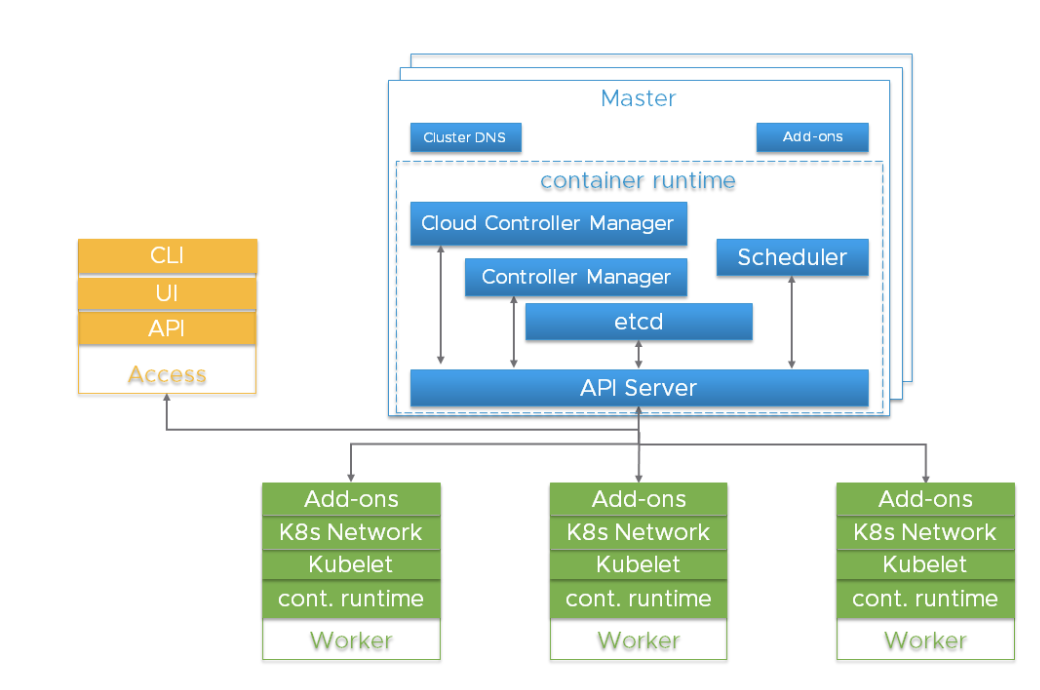
Normalmente, os componentes do API Server, do Controller Manager e do Scheduler estão localizados em várias instâncias dos nós no nível de controle (chamados Master). Os nós principais também incluem o etcd, no entanto, existem scripts grandes e altamente acessíveis que exigem a execução do etcd em hosts independentes. Os componentes podem ser executados como contêineres e, opcionalmente, sob a supervisão do Kubernetes, ou seja, funcionar como lareiras estáticas.
Instâncias redundantes desses componentes são usadas para alta disponibilidade. O significado e o nível exigido de redundância podem variar.
| Componente | Funções | Consequências da perda | Instâncias recomendadas |
|---|
| etcd | Mantém o estado de todos os objetos Kubernetes | Perda catastrófica de armazenamento. Perda da maioria = o Kubernetes perde o nível de controle, o API Server depende do etcd, as chamadas de API somente leitura que não precisam de quorum, como as cargas de trabalho já criadas, podem continuar funcionando. | número ímpar, 3+ |
| Servidor API | Fornece API para uso externo e interno | Não foi possível parar, iniciar, atualizar novos pods. O Scheduler e o Controller Manager dependem do servidor de API. As cargas continuam se não dependerem de chamadas de API (operadores, controladores personalizados, CRD etc.) | 2+ |
| kube-scheduler | Coloca pods em nós | Os pods não podem ser colocados, priorizados ou movidos entre eles. | 2+ |
| kube-controller-manager | Controla muitos controladores | Os principais circuitos de controle responsáveis pelo estado param de funcionar. A integração na árvore do provedor de nuvem é interrompida. | 2+ |
| gerenciador de controlador de nuvem (CCM) | Integração de provedor de nuvem fora da árvore | Quebras de integração do provedor de nuvem | 1 |
| Adições (por exemplo, DNS) | Diferente | Diferente | Depende do complemento (por exemplo, 2+ para DNS) |
Os riscos desses componentes incluem falhas de hardware, bugs de software, atualizações incorretas, erros humanos, interrupções de rede e sobrecarga do sistema, resultando em exaustão de recursos. A redundância pode reduzir o impacto desses perigos. Além disso, graças aos recursos da plataforma do hipervisor (planejamento de recursos, alta disponibilidade), você pode multiplicar os resultados usando o sistema operacional Linux, o Kubernetes e o tempo de execução do contêiner.
O servidor da API usa várias instâncias do balanceador de carga para obter escalabilidade e disponibilidade. Um balanceador de carga é um componente essencial para alta disponibilidade. Vários registros A do servidor da API DNS podem servir como alternativa na ausência de um balanceador.
O kube-scheduler e o kube-controller-manager estão envolvidos no processo de seleção de um líder em vez de usar um balanceador de carga. Como o
gerenciador de controlador de nuvem é usado para certos tipos de infraestrutura de hospedagem, cuja implementação pode variar, não os discutiremos - apenas indicamos que eles são um componente do nível de gerenciamento.
Os pods em execução no Kubernetes são gerenciados pelo agente kubelet. Cada instância do trabalhador executa um agente kubelet e um ambiente de inicialização de contêiner compatível com CRI. O próprio Kubernetes foi projetado para monitorar e se recuperar de falhas no nó do trabalhador. Porém, para funções críticas de carga, gerenciamento de recursos do hipervisor e isolamento de carga, ela pode ser usada para melhorar a acessibilidade e aumentar a previsibilidade de seu trabalho.
etcdO etcd é um armazenamento persistente para todos os objetos do Kubernetes. A disponibilidade e a capacidade de recuperação do cluster etcd devem ser a principal prioridade ao implantar o Kubernetes com nível de produção.
O cluster etcd composto por cinco nós é a melhor opção se você pode permitir. Porque Porque você pode atender a um e, ao mesmo tempo, suportar falhas. Um cluster de três nós é o mínimo que podemos recomendar para um serviço de nível de produção, mesmo que apenas um hipervisor host esteja disponível. Mais de sete nós também não são recomendados, com exceção de
instalações muito grandes que cobrem várias zonas de acesso.
As recomendações mínimas para hospedar um nó de cluster etcd são 2 GB de RAM e um disco rígido de 8 GB SSD. Normalmente, 8 GB de RAM e 20 GB de espaço em disco rígido são suficientes. O desempenho do disco afeta o tempo de recuperação de um nó após uma falha.
Confira para mais detalhes.
Em casos especiais, pense em vários clusters etcdPara clusters Kubernetes muito grandes, considere usar um cluster etcd separado para eventos Kubernetes, para que muitos eventos não afetem o serviço principal da API Kubernetes. Ao usar a rede Flannel, a configuração é salva no etcd, e os requisitos de versão podem diferir dos Kubernetes. Isso pode complicar o backup do etcd, por isso recomendamos o uso de um cluster etcd separado especificamente para a flanela.
Implantação de host únicoA lista de riscos de acessibilidade inclui hardware, software e o fator humano. Se você estiver limitado a um único host, o uso de armazenamento redundante, memória de correção de erros e uma fonte de alimentação dupla podem melhorar a proteção contra falhas de hardware. A execução de um hipervisor em um host físico permite o uso de componentes de software redundantes e adiciona benefícios operacionais associados à implantação, atualização e monitoramento do uso de recursos. Mesmo em situações estressantes, o comportamento permanece repetível e previsível. Por exemplo, mesmo que você possa permitir apenas o lançamento de singletones a partir de serviços principais, eles devem estar protegidos contra sobrecarga e esgotamento de recursos, competindo com a carga de trabalho do seu aplicativo. Um hipervisor pode ser mais eficiente e fácil de usar do que a priorização no agendador do Linux, cgroups, sinalizadores do Kubernetes etc.
Você pode implantar três máquinas virtuais etcd, se os recursos do host permitirem. Cada VM deve ser suportada por um dispositivo de armazenamento físico separado ou usar partes separadas do armazenamento usando redundância (espelhamento, RAID etc.).
Instâncias redundantes duplas da API do servidor, planejador e gerenciador de controladores são a próxima atualização se seu único host tiver recursos suficientes para isso.
Opções de implantação de host único, do menos adequado para produção à maioria| Tipo | Características | Resultado |
|---|
| Equipamento mínimo | Etd Singleton e componentes principais. | Laboratório doméstico, nem um nível de produção. Ponto único de falha múltiplo (SPOF). A recuperação é lenta e, quando o armazenamento é perdido, está completamente ausente. |
| Melhoria da redundância de armazenamento | etcd singleton e componentes principais, etcd armazenamento é redundante. | No mínimo, você pode se recuperar de uma falha no dispositivo de armazenamento. |
| Redundância de nível gerenciado | Não há hipervisor, várias instâncias de componentes de nível gerenciado em pods estáticos. | A proteção contra bugs de software apareceu, mas o sistema operacional e o ambiente de inicialização do contêiner ainda são o mesmo ponto de falha com atualizações devastadoras. |
| Incluindo um Hypervisor | Executando três instâncias redundantes de nível gerenciado na VM. | Há proteção contra bugs de software e erros humanos e uma vantagem operacional na instalação, gerenciamento de recursos, monitoramento e segurança. As atualizações do SO e os ambientes de lançamento de contêiner são menos perturbadores. O hypervisor é o único ponto único de falha. |
Implantação de host duploCom dois hosts, os problemas de armazenamento etcd são semelhantes à opção de host único - você precisa de redundância. É preferível executar três instâncias de encd. Pode parecer pouco intuitivo, mas é melhor concentrar todos os nós etcd em um host. Você não aumentará a confiabilidade dividindo-os por 2 + 1 entre dois hosts - a perda de um nó com a maioria das instâncias de encd levará a uma falha, independentemente de ser a maioria de 2 ou 3. Se os hosts não forem iguais, coloque o cluster etcd inteiro no mais confiável.
É recomendável que você execute servidores de API redundantes, planejadores de kube e gerenciadores de controladores de kube. Eles devem ser compartilhados entre os hosts para minimizar os riscos de falhas no ambiente de inicialização do contêiner, sistema operacional e hardware.
O lançamento de uma camada de hipervisor em hosts físicos permitirá trabalhar com componentes de programa redundantes, fornecendo gerenciamento de recursos. Ele também tem a vantagem operacional da manutenção programada.
Opções de implantação para dois hosts, desde o menos adequado para produção até o mais| Tipo | Características | Resultado |
|---|
| Equipamento mínimo | Dois hosts, sem armazenamento redundante. Etd Singleton e componentes principais no mesmo host. | etcd - um único ponto de falha, não faz sentido executar dois em outros serviços principais. O compartilhamento entre dois hosts aumenta o risco de falhas na camada gerenciada. O benefício potencial de isolar recursos executando uma camada gerenciada em um host e cargas de trabalho de aplicativos em outro. Se o armazenamento for perdido, não há recuperação. |
| Melhoria da redundância de armazenamento | Etd Singleton e componentes principais no mesmo host, armazenamento etcd redundante. | No mínimo, você pode se recuperar de uma falha no dispositivo de armazenamento. |
| Redundância de nível gerenciado | Não há hipervisor, várias instâncias de componentes de nível gerenciado em pods estáticos. etcd em um host, outros componentes de nível gerenciado são separados. | Uma falha de hardware, a atualização do firmware, sistema operacional e ambiente de inicialização do contêiner em um host sem o etcd são menos prejudiciais. |
| Incluindo um Hipervisor nos Dois Hosts | Três componentes redundantes de nível gerenciado estão sendo executados em máquinas virtuais, cluster etcd em um host e os componentes de nível gerenciado são separados. As cargas de trabalho do aplicativo podem residir nos dois nós da VM. | Melhor isolamento da carga do aplicativo. As atualizações no sistema operacional e no ambiente de inicialização do contêiner são menos perturbadoras. A manutenção agendada de hardware / firmware se torna não destrutiva se o hipervisor suportar a migração da VM. |
Implantação em três (ou mais) hostsTransição para um serviço de nível de produção intransigente. Recomendamos dividir o etcd entre os três hosts. Uma falha de hardware reduzirá a quantidade possível de cargas de trabalho de aplicativos, mas não resultará em uma interrupção completa do serviço.
Clusters muito grandes exigirão mais instâncias.
O lançamento de uma camada de hipervisor fornece benefícios operacionais e melhor isolamento das cargas de trabalho do aplicativo. Isso está além do escopo do artigo, mas, no nível de três ou mais hosts, podem estar disponíveis funções aprimoradas (armazenamento compartilhado redundante em cluster, gerenciamento de recursos com um balanceador de carga dinâmico, monitoramento automático de estado com migração ao vivo e failover).
Opções de implantação para três (ou mais) hosts, do menos adequado à produção ao mais| Tipo | Características | Resultado |
|---|
| Mínimo | Três anfitriões. Instância etcd em cada nó. Componentes principais em cada nó. | Perder um nó reduz o desempenho, mas não leva a uma queda no Kubernetes. A possibilidade de recuperação permanece. |
| Incluindo um Hipervisor nos Hosts | Nas máquinas virtuais em três hosts, etcd, um servidor de API, agendadores e um gerenciador de controladores estão em execução. As cargas de trabalho estão em execução na VM em cada host. | Adicionado proteção contra bugs do SO / ambiente de inicialização de contêiner / software e erros humanos. Benefícios operacionais da instalação, atualização, gerenciamento de recursos, monitoramento e segurança. |
Configurar o KubernetesOs nós mestre e trabalhador devem ser protegidos contra sobrecarga e esgotamento de recursos. As funções do hipervisor podem ser usadas para isolar componentes críticos e reservar recursos. Também existem definições de configuração do Kubernetes que podem diminuir a velocidade da chamada da API. Alguns kits de instalação e distribuições comerciais cuidam disso, mas se você estiver implantando o Kubernetes, as configurações padrão podem não ser adequadas, especialmente para recursos pequenos ou para um cluster muito grande.
O consumo de recursos em nível gerenciado se correlaciona com o número de lareiras e a taxa de saída de lareiras. Clusters muito grandes e muito pequenos se beneficiarão das configurações modificadas de solicitação e redução de memória do kube-apiserver.
O nó alocável deve ser configurado nos
nós do
trabalhador com base na densidade de carga suportada razoável para cada nó. Os espaços para nome podem ser criados para dividir um cluster de nós de trabalho em vários clusters virtuais com
cotas de CPU e memória.
SegurançaCada cluster Kubernetes possui uma autoridade de certificação raiz (CA). Os certificados Controller Manager, API Server, Scheduler, cliente kubelet, kube-proxy e administrador devem ser gerados e instalados. Se você usa uma ferramenta de instalação ou distribuição, pode não ter que lidar com isso sozinho. O processo manual é descrito
aqui . Você deve estar preparado para reinstalar certificados se expandir ou substituir os nós.
Como o Kubernetes é totalmente gerenciado pela API, é imperativo controlar e limitar a lista daqueles que têm acesso ao cluster. As opções de criptografia e autenticação são discutidas nesta documentação.
As cargas de trabalho do aplicativo Kubernetes são baseadas em imagens de contêiner. Você precisa que a fonte e o conteúdo dessas imagens sejam confiáveis. Quase sempre, isso significa que você hospedará a imagem do contêiner no repositório local. O uso de imagens da Internet pública pode causar problemas de confiabilidade e segurança. Você deve selecionar um repositório que tenha suporte para assinar a imagem, verificar a segurança, controlar o acesso para enviar e baixar imagens e registrar atividades.
Os processos devem ser configurados para dar suporte ao uso de host, hypervisor, OS6, Kubernetes e outras atualizações de firmware de dependência. O monitoramento de versão é necessário para dar suporte à auditoria.
Recomendações:
- Fortalecer as configurações de segurança padrão para componentes de nível gerenciado (por exemplo, bloquear nós do trabalhador );
- Use a Política de Segurança do Lar ;
- Pense na integração do NetworkPolicy disponível para sua solução de rede, incluindo rastreamento, monitoramento e solução de problemas;
- Use o RBAC para tomar decisões de autorização;
- Pense em segurança física, especialmente ao implantar em locais periféricos ou remotos que podem ser negligenciados. Adicione criptografia de armazenamento para limitar as conseqüências do roubo de dispositivos e proteção contra a conexão de dispositivos maliciosos, como chaves USB;
- Proteja as credenciais de texto do provedor de nuvem (chaves de acesso, tokens, senhas etc.).
Os objetos
secretos do Kubernetes são adequados para armazenar pequenas quantidades de dados confidenciais. Eles são armazenados no etcd. Eles podem ser usados com segurança para armazenar credenciais da API Kubernetes, mas há momentos em que uma carga de trabalho ou expansão do próprio cluster requer uma solução mais completa. O projeto HashiCorp Vault é uma solução popular se você precisar de mais do que os objetos secretos internos podem fornecer.
Recuperação de desastres e backup
A implementação de redundância por meio do uso de vários hosts e VMs ajuda a reduzir o número de certos tipos de falhas. Mas cenários como um desastre natural, uma atualização ruim, um ataque de hackers, bugs de software ou um erro humano ainda podem resultar em falhas.
Uma parte crítica de uma implantação de produção é a expectativa de uma recuperação futura.
Também é importante notar que parte do seu investimento em design, documentação e automação do processo de recuperação pode ser reutilizada se você precisar de implantações replicadas em larga escala em vários sites.
Entre os elementos de recuperação de desastres, vale ressaltar os backups (e possivelmente réplicas), substituições, o processo planejado, as pessoas que executarão esse processo e o treinamento regular.
Os frequentes exercícios e princípios de teste da
Chaos Engineering podem ser usados para testar sua prontidão.
Devido aos requisitos de disponibilidade, pode ser necessário armazenar cópias locais do sistema operacional, componentes do Kubernetes e imagens de contêineres para permitir a recuperação, mesmo se a Internet travar. A capacidade de implantar hosts e nós de substituição em uma situação de "isolamento físico" melhora a segurança e aumenta a velocidade de implantação.
Todos os objetos do Kubernetes são armazenados no etcd. O backup periódico dos dados do cluster etcd é um elemento importante na restauração de clusters do Kubernetes durante cenários de emergência, por exemplo, quando todos os nós principais são perdidos.
etcd
etcd . Kubernetes . , Kubernetes.
, Kubernetes etcd , - . , .
etcd. , , , , /. , . :
- : CA, API Server, Apiserver-kubelet-client, ServiceAccount, “Front proxy”, Front proxy;
- DNS;
- IP/;
- ;
- kubeconfig;
- LDAP ;
- .
Anti-affinity . , . , Kubernetes , . , , - .
, .
stateful-, — Kubernetes (, SQL ). , , Kubernetes,
roadmap feature request , , , Container Storage Interface (CSI). , - , , . , Kubernetes , , , Kubernetes .
stateful- (, Cassandra) , , . - Kubernetes ( -) .
( ) , , . , , .
, (,
Ansible ,
BOSH ,
Chef ,
Juju ,
kubeadm ,
Puppet .). , .
, , , , , , . , Git, .
, , — . 2 , — . — , .

— . - , Airbus A320 — . , . , .
, . , , , . Kubernetes , - , , (, FedEx, Amazon).
production-grade Kubernetes . . , , , , . , (, Kubernetes
self-hosting, não estáticas). Talvez eles devam ser discutidos nos seguintes artigos, se houver interesse suficiente. Além disso, devido à alta velocidade da melhoria do Kubernetes, se o seu mecanismo de pesquisa encontrou este artigo após 2019, alguns de seus materiais já podem estar muito desatualizados.O FIM
Como sempre, estamos aguardando suas perguntas e comentários aqui, e você pode ir para o Open Day de Alexander Titov .