 Processador tensor de 3ª geraçãoO processador tensor do Google
Processador tensor de 3ª geraçãoO processador tensor do Google é um circuito integrado de propósito específico (
ASIC ) desenvolvido desde o início pelo Google para executar tarefas de aprendizado de máquina. Ele trabalha em vários produtos principais do Google, incluindo Traduzir, Fotos, Assistente de Pesquisa e Gmail. O Cloud TPU oferece os benefícios da escalabilidade e facilidade de uso a todos os desenvolvedores e cientistas de dados que lançam modelos de aprendizado de máquina de ponta no Google Cloud. No Google Next '18, anunciamos que o Cloud TPU v2 agora está disponível para todos os usuários, incluindo
contas de avaliação gratuita , e o Cloud TPU v3 está disponível para teste alfa.

Mas muitas pessoas perguntam - qual é a diferença entre CPU, GPU e TPU? Criamos um
site de demonstração onde estão localizadas a apresentação e a animação que respondem a essa pergunta. Neste post, gostaria de abordar alguns recursos do conteúdo deste site.
Como as redes neurais funcionam?
Antes de começar a comparar CPU, GPU e TPU, vamos ver que tipo de cálculos são necessários para o aprendizado de máquina - e especificamente, para redes neurais.
Imagine, por exemplo, que usamos uma rede neural de camada única para reconhecer números manuscritos, conforme mostrado no diagrama a seguir:
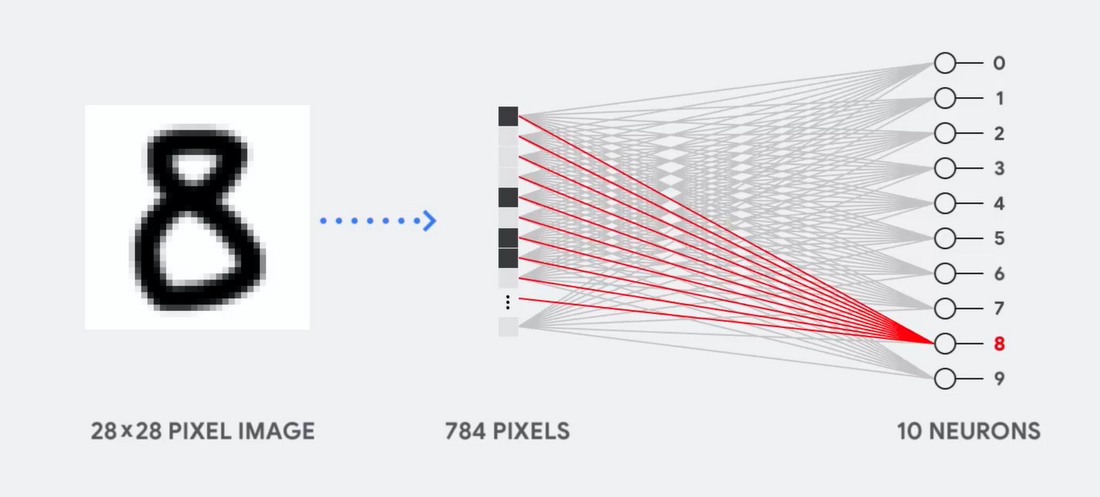
Se a imagem for uma grade de 28x28 pixels em escala de cinza, ela poderá ser convertida em um vetor de 784 valores (medidas). Um neurônio que reconhece o número 8 pega esses valores e os multiplica pelos valores dos parâmetros (linhas vermelhas no diagrama).
O parâmetro funciona como um filtro, extraindo recursos dos dados que indicam a semelhança de imagem e forma 8:

Esta é a explicação mais simples da classificação de dados por redes neurais. Multiplicação de dados com os parâmetros correspondentes a eles (coloração de pontos) e sua adição (soma de pontos à direita). O resultado mais alto indica a melhor correspondência entre os dados inseridos e o parâmetro correspondente, que provavelmente será a resposta correta.
Simplificando, as redes neurais precisam fazer um grande número de multiplicações e adições de dados e parâmetros. Freqüentemente, nós os organizamos na forma de
multiplicação de
matrizes , que você pode encontrar em álgebra na escola. Portanto, o problema é realizar um grande número de multiplicações de matrizes o mais rápido possível, gastando o mínimo de energia possível.
Como uma CPU funciona?
Como a CPU aborda essa tarefa? CPU é um processador de uso geral baseado na
arquitetura von Neumann . Isso significa que a CPU trabalha com software e memória da seguinte maneira:
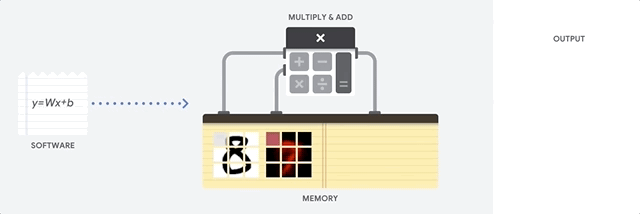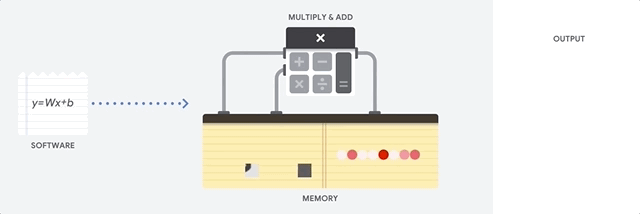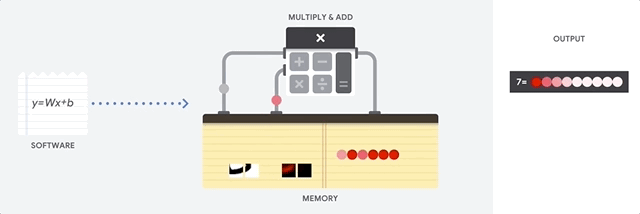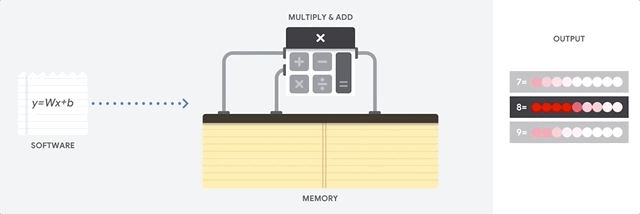
A principal vantagem da CPU é a flexibilidade. Graças à arquitetura von Neumann, você pode baixar softwares completamente diferentes para milhões de finalidades diferentes. A CPU pode ser usada para processamento de texto, controle de mecanismo de foguete, transações bancárias, classificação de imagens usando uma rede neural.
Mas como a CPU é muito flexível, o equipamento nem sempre sabe com antecedência qual será a próxima operação até que leia a próxima instrução do software. A CPU precisa armazenar os resultados de cada cálculo na memória localizada dentro da CPU (os chamados registradores ou
cache L1 ). O acesso a essa memória torna-se menos a arquitetura da CPU, conhecida como gargalo da arquitetura von Neumann. E embora uma enorme quantidade de cálculos para redes neurais torne previsíveis as etapas futuras, cada CPU
lógica aritmética (ALU, um componente que armazena e controla multiplicadores e somadores) executa operações sequencialmente, acessando a memória sempre, o que limita a taxa de transferência geral e consome uma quantidade significativa de energia .
Como funciona a GPU
Para aumentar a taxa de transferência em comparação com a CPU, a GPU usa uma estratégia simples: por que não integrar milhares de ALUs no processador? A GPU moderna contém cerca de 2500 - 5000 ALU no processador, o que torna possível realizar milhares de multiplicações e adições por vez.

Essa arquitetura funciona bem com aplicativos que exigem paralelização massiva, como, por exemplo, multiplicação de matrizes em uma rede neural. Com uma carga de treinamento típica de aprendizado profundo (GO), a taxa de transferência nesse caso aumenta em uma ordem de magnitude em comparação com a CPU. Portanto, hoje a GPU é a arquitetura de processador mais popular do GO.
Mas a GPU continua sendo um processador de uso geral que deve suportar um milhão de aplicativos e software diferentes. E isso nos leva de volta ao problema fundamental do gargalo da arquitetura von Neumann. Para cada cálculo em milhares de ALUs, GPUs, é necessário recorrer a registradores ou memória compartilhada para ler e salvar resultados de cálculos intermediários. Como a GPU executa mais computação paralela em milhares de suas ALUs, também gasta proporcionalmente mais energia no acesso à memória e ocupa uma grande área.
Como o TPU funciona?
Quando desenvolvemos o TPU no Google, construímos uma arquitetura projetada para uma tarefa específica. Em vez de desenvolver um processador de uso geral, desenvolvemos um processador de matriz especializado para trabalhar com redes neurais. O TPU não poderá trabalhar com um processador de texto, controlar motores de foguetes ou realizar transações bancárias, mas pode processar um grande número de multiplicações e adições para redes neurais a uma velocidade incrível, consumindo muito menos energia e ajustando-se a um volume físico menor.
A principal coisa que lhe permite fazer isso é a eliminação radical do gargalo da arquitetura von Neumann. Como a principal tarefa do TPU é o processamento matricial, os desenvolvedores de circuitos estavam familiarizados com todas as etapas de cálculo necessárias. Portanto, eles foram capazes de colocar milhares de multiplicadores e somadores e conectá-los fisicamente, formando uma grande matriz física. Isso é chamado de
arquitetura de matriz em pipeline . No caso do Cloud TPU v2, duas matrizes de pipeline de 128 x 128 são usadas, o que totaliza 32.768 ALUs para valores de ponto flutuante de 16 bits em um processador.
Vamos ver como um array em pipeline realiza cálculos para uma rede neural. Primeiro, o TPU carrega os parâmetros da memória em uma matriz de multiplicadores e somadores.

O TPU carrega os dados da memória. Após a conclusão de cada multiplicação, o resultado é transmitido aos seguintes fatores, ao executar adições. Portanto, a saída será a soma de todas as multiplicações dos dados e parâmetros. Durante todo o processo de computação volumétrica e transferência de dados, o acesso à memória é completamente desnecessário.
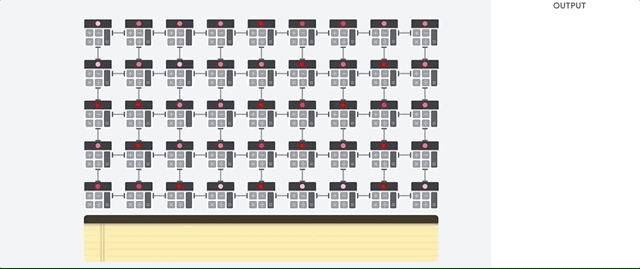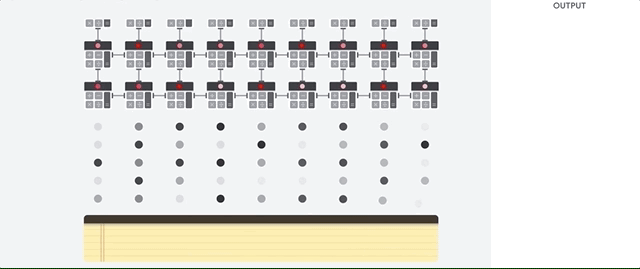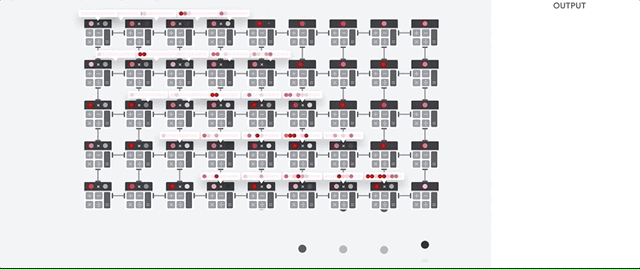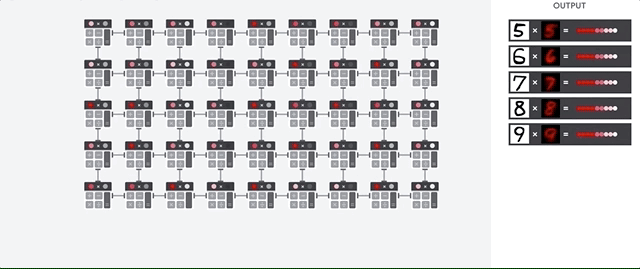
Portanto, o TPU demonstra maior rendimento ao calcular redes neurais, consumindo muito menos energia e ocupando menos espaço.
Vantagem: 5 vezes menos custo
Quais são os benefícios da arquitetura TPU? Custo. Aqui está o custo do Cloud TPU v2 para agosto de 2018, no momento da redação deste documento:
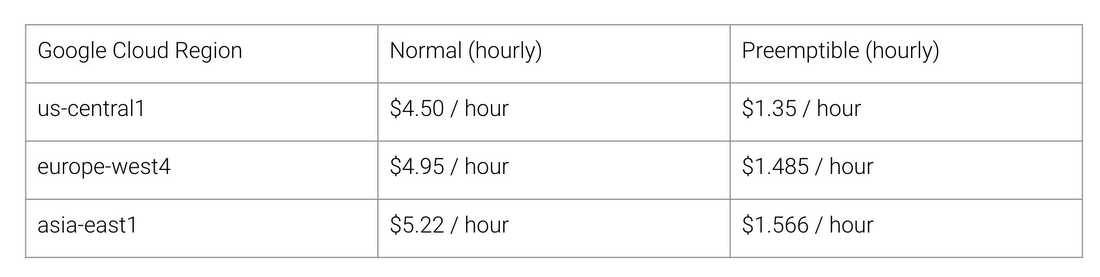
Custo normal e TPU do trabalho para diferentes regiões do Google Cloud
A Universidade de Stanford está distribuindo um conjunto de testes
DAWNBench que medem o desempenho de sistemas de aprendizado profundo. Lá você pode ver várias combinações de tarefas, modelos e plataformas de computação, bem como os resultados dos testes correspondentes.
No final da competição, em abril de 2018, o custo mínimo de treinamento em processadores com arquitetura diferente de TPU era de US $ 72,40 (para o treinamento do ResNet-50 com precisão de 93% no ImageNet em
instâncias spot ). Com o Cloud TPU v2, esse treinamento pode ser realizado por US $ 12,87. Isso é menos de 1/5 do custo. Esse é o poder da arquitetura projetada especificamente para redes neurais.