
Infelizmente, na Internet, não há informações suficientes sobre a migração de aplicativos reais e a operação de produção do Percona XtraDB Cluster (a seguir designado PXC). Vou tentar corrigir essa situação e contar sobre a nossa experiência com a minha história. Não haverá instruções de instalação passo a passo e o artigo não deve ser considerado como um substituto para a documentação insuficiente, mas como um conjunto de recomendações.
O problema
Eu trabalho como administrador de sistema no
ultimate-guitar.com . Como fornecemos um serviço da Web, naturalmente possuímos back-end e um banco de dados, que é o núcleo do serviço. O tempo de atividade do serviço depende diretamente do desempenho do banco de dados.
O Percona MySQL 5.7 foi usado como banco de dados. A reserva foi implementada usando o mestre do esquema de replicação mestre. Escravos foram usados para ler alguns dados.
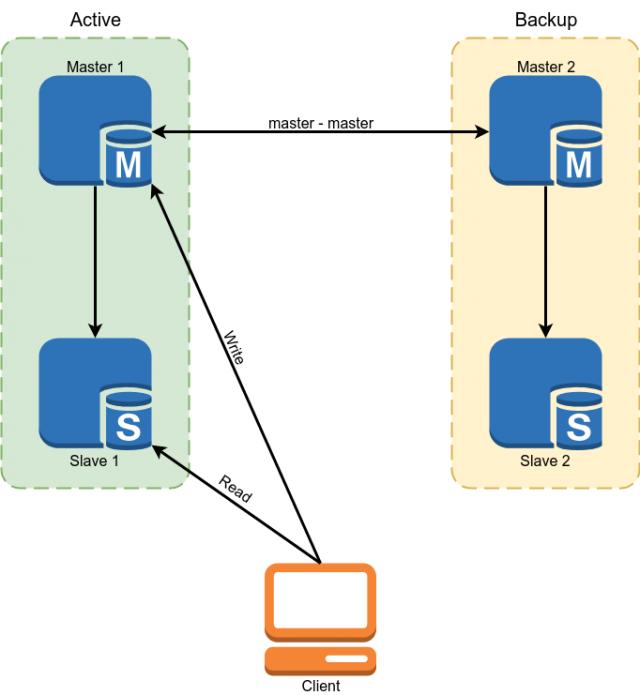
Mas esse esquema não nos serviu das seguintes desvantagens:
- Devido ao fato de que na replicação do MySQL, os escravos assíncronos podem ficar indefinidamente. Todos os dados críticos tiveram que ser lidos do mestre.
- A partir do parágrafo anterior segue a complexidade do desenvolvimento. O desenvolvedor não pôde apenas fazer uma solicitação ao banco de dados, mas foi obrigado a pensar se ele estava pronto em cada caso específico para o backlog do escravo e, se não, ler os dados no assistente.
- Comutação manual em caso de acidente. A implementação da comutação automática foi problemática devido ao fato de a arquitetura MySQL não possuir proteção integrada contra o cérebro dividido. Teríamos que nos escrever um árbitro com uma lógica complexa de escolha de um mestre. Ao escrever para os dois mestres, os conflitos podem surgir ao mesmo tempo, interrompendo a replicação principal e levando ao cérebro dividido clássico.
Alguns números secos, para que você entenda com o que trabalhamos:
Tamanho do banco de dados: 300 GB
QPS: ~ 10k
Relação RW: 96/4%
Configuração do servidor principal:
CPU: 2x E5-2620 v3
RAM: 128 Gb
SSD: Intel Optane 905p 960 Gb
Rede: 1 Gbps
Temos um carregamento OLTP clássico com muita leitura, o que precisa ser feito muito rapidamente e com uma pequena quantidade de escrita. A carga no banco de dados é muito pequena devido ao fato de o cache ser usado ativamente no Redis e no Memcached.
Seleção de decisão
Como você deve ter adivinhado no título, escolhemos o PXC, mas aqui vou explicar por que o escolhemos.
Tivemos 4 opções:
- Alterar DBMS
- Replicação de Grupo MySQL
- Dane-se a funcionalidade necessária usando scripts em cima do mestre de replicação principal.
- Cluster MySQL Galera (ou seus garfos, por exemplo, PXC)
A opção de alterar o banco de dados praticamente não foi considerada, porque o aplicativo é grande, em muitos lugares está vinculado à funcionalidade ou sintaxe do mysql, e a migração para o PostgreSQL, por exemplo, levará muito tempo e recursos.
A segunda opção foi replicação de grupo do MySQL. Uma vantagem incontestável disso é que ele se desenvolve no ramo de baunilha do MySQL, o que significa que no futuro se tornará generalizado e terá um grande conjunto de usuários ativos.
Mas ele tem algumas desvantagens. Em primeiro lugar, impõe mais restrições ao esquema do aplicativo e do banco de dados, o que significa que será mais difícil migrar. Segundo, a replicação de grupo resolve o problema da tolerância a falhas e do cérebro dividido, mas a replicação no cluster ainda é assíncrona.
Também não gostamos da terceira opção para muitas bicicletas, que inevitavelmente precisamos implementar ao resolver o problema dessa maneira.
Galera permitiu resolver completamente o problema de failover do MySQL e parcialmente o problema com a relevância dos dados nos escravos. Em parte porque a assincronia de replicação é mantida. Depois que uma transação é confirmada em um nó local, as alterações são enviadas para os nós restantes de forma assíncrona, mas o cluster garante que os nós não fiquem muito atrasados e, se começarem a ficar lentos, diminui artificialmente o trabalho. O cluster garante que, após a confirmação da transação, ninguém possa confirmar alterações conflitantes, mesmo no nó que ainda não as replicou.
Após a migração, o esquema de operação do banco de dados deve ficar assim:
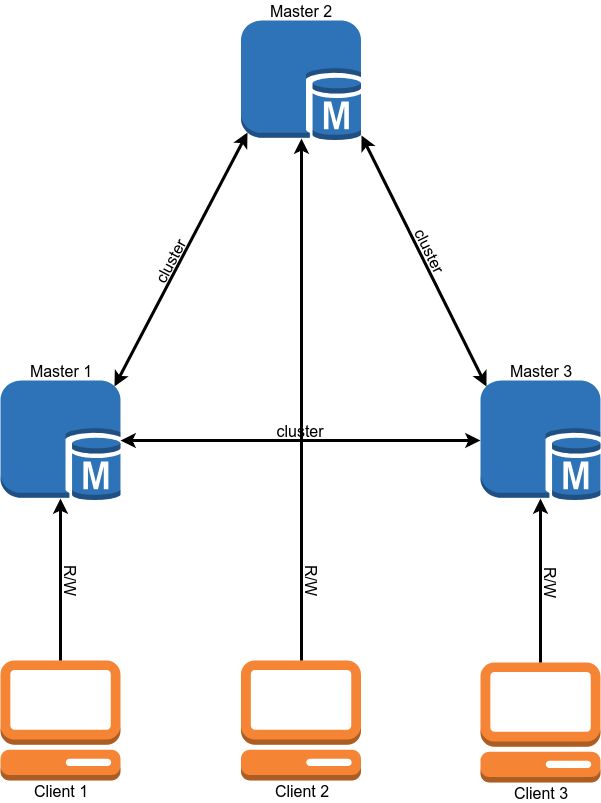
A migração
Por que a migração é o segundo item depois de escolher uma solução? É simples - o cluster contém vários requisitos que o aplicativo e o banco de dados devem seguir, e precisamos atendê-los antes da migração.
- Mecanismo InnoDB para todas as tabelas. MyISAM, Memory e outros back-end não são suportados. É corrigido de maneira simples - convertemos todas as tabelas para o InnoDB.
- Binlog em formato ROW. O cluster não precisa de um binlog para funcionar e, se você não precisar de escravos clássicos, pode desativá-lo, mas o formato do binlog deve ser ROW.
- Todas as tabelas devem ter uma CHAVE PRIMÁRIA / ESTRANGEIRA. Isso é necessário para a gravação simultânea correta na mesma tabela de nós diferentes. Para as tabelas que não contêm uma chave exclusiva, você pode usar a chave primária composta ou o incremento automático.
- Não use 'LOCK TABLES', 'GET_LOCK () / RELEASE_LOCK ()', 'FLUSH TABLES {{table}} COM LER LOCK' ou o nível de isolamento 'SERIALIZABLE' para transações.
- Não use as consultas 'CREATE TABLE ... AS SELECT' , pois eles combinam mudança de esquema e dados. É facilmente dividido em duas consultas, a primeira das quais cria uma tabela e a segunda é preenchida com dados.
- Não use 'DISCARD TABLESPACE' e 'IMPORT TABLESPACE' , pois eles não são replicados
- Defina as opções 'innodb_autoinc_lock_mode' como '2'. Essa opção pode corromper os dados ao trabalhar com a replicação STATEMENT, mas como apenas a replicação ROW é permitida no cluster, não haverá problemas.
- Como 'log_output', apenas 'FILE' é suportado. Se você tiver uma entrada de log na tabela, será necessário removê-la.
- Transações XA não são suportadas. Se eles foram usados, você terá que reescrever o código sem eles.
Devo observar que quase todas essas restrições podem ser removidas se você definir a variável 'pxc_strict_mode = PERMISSIVE', mas se seus dados forem importantes para você, é melhor não fazer isso. Se você tiver definido 'pxc_strict_mode = ENFORCING', o MySQL não permitirá que você execute as operações acima ou impede que o nó seja iniciado.
Depois de cumprir todos os requisitos do banco de dados e testar exaustivamente a operação de nosso aplicativo no ambiente de desenvolvimento, podemos prosseguir para o próximo estágio.
Implantação e configuração de cluster
Temos vários bancos de dados em execução em nossos servidores e outros bancos de dados não precisam migrar para o cluster. Mas um pacote com cluster MySQL substitui o mysql clássico. Tivemos várias soluções para esse problema:
- Use a virtualização e inicie o cluster na VM. Não gostamos dessa opção devido aos grandes custos indiretos (em comparação com o restante) e à aparência de outra entidade que precisa ser atendida
- Crie sua versão do pacote, que colocará o mysql em um local não padrão. Assim, será possível ter várias versões do mysql em um servidor. Uma boa opção se você tiver muitos servidores, mas o suporte constante ao seu pacote, que precisa ser atualizado regularmente, pode levar bastante tempo.
- Use o Docker.
Escolhemos o Docker, mas o usamos na opção mínima. Para armazenamento de dados, o volume local é usado. O modo operacional '--net host' é usado para reduzir a latência da rede e a carga da CPU.
Também tivemos que criar nossa própria versão da imagem do Docker. O motivo é que a imagem padrão da Percona não suporta a posição de restauração na inicialização. Isso significa que cada vez que a instância é reiniciada, ela não executa a sincronização rápida do IST, que carrega apenas as alterações necessárias, mas um SST lento, que recarrega completamente o banco de dados.
Outra questão é o tamanho do cluster. Em um cluster, cada nó armazena todo o conjunto de dados. Portanto, a leitura é dimensionada perfeitamente com o aumento do tamanho do cluster. Com o registro, a situação é oposta - ao confirmar, cada transação é validada pela ausência de conflitos em todos os nós. Naturalmente, quanto mais nós, mais tempo levará a confirmação.
Aqui também temos várias opções:
- 2 nós + árbitro. 2 nós + árbitro. Uma boa opção para testes. Durante a implantação do segundo nó, o mestre não deve registrar.
- 3 nós. A versão clássica. Equilíbrio de velocidade e confiabilidade. Observe que nesta configuração um nó deve esticar toda a carga, porque no momento da adição do terceiro nó, o segundo será o doador.
- 4+ nós. Com um número par de nós, é necessário adicionar um árbitro para evitar o cérebro dividido. Uma opção que funciona bem para uma quantidade muito grande de leitura. A confiabilidade do cluster também está aumentando.
Até o momento, optamos pela opção com 3 nós.
A configuração do cluster copia quase completamente a configuração independente do MySQL e difere apenas em algumas opções:
"Wsrep_sst_method = xtrabackup-v2" Esta opção define o método de copiar nós. Outras opções são mysqldump e rsync, mas elas bloqueiam o nó pela duração da cópia. Não vejo razão para usar o método de cópia não-xtrabackup-v2.
"Gcache" é um análogo do
binlog do cluster. É um buffer circular (em um arquivo) de tamanho fixo no qual todas as alterações são gravadas. Se você desativar um dos nós do cluster e ativá-lo novamente, ele tentará ler as alterações ausentes no Gcache (sincronização IST). Se não houver as alterações exigidas pelo nó, será necessário recarregar completamente o nó (sincronização SST). O tamanho do gcache é definido da seguinte forma: wsrep_provider_options = 'gcache.size = 20G;'.
wsrep_slave_threads Ao contrário da replicação clássica em um cluster, é possível aplicar vários "conjuntos de gravação" ao mesmo banco de dados em paralelo. Esta opção indica o número de trabalhadores que aplicam as alterações. É melhor não deixar o valor padrão de 1, porque durante a aplicação do trabalhador de um conjunto de gravação grande, o restante aguardará na fila e a replicação do nó começará a ficar lenta. Alguns aconselham definir esse parâmetro como 2 * CPU THREADS, mas acho que você precisa examinar o número de operações de gravação simultâneas que possui.
Definimos o valor 64. Em um valor mais baixo, o cluster às vezes não conseguiu aplicar todos os conjuntos de gravação da fila durante rajadas de carga (por exemplo, ao iniciar coroas pesadas).
wsrep_max_ws_size O tamanho de uma única transação em um cluster é limitado a 2 GB. Mas grandes transações não se encaixam bem com o conceito PXC. É melhor concluir 100 transações de 20 MB cada uma do que uma por 2 GB. Portanto, primeiro limitamos o tamanho da transação no cluster a 100 MB e depois reduzimos o limite para 50 MB.
Se você tiver o modo estrito ativado, poderá definir a variável "
binlog_row_image " como "minimal". Isso reduzirá o tamanho das entradas no binlog em várias vezes (10 vezes no teste da Percona). Isso economizará espaço em disco e permitirá transações que não se enquadram no limite com "binlog_row_image = full".
Limites para SST. Para o Xtrabackup, usado para preencher nós, você pode definir um limite para o uso da rede, número de threads e método de compactação. Isso é necessário para que, quando o nó estiver preenchido, o servidor doador não comece a ficar lento. Para fazer isso, a seção "sst" é adicionada ao arquivo my.cnf:
[sst] rlimit = 80m compressor = "pigz -3" decompressor = "pigz -dc" backup_threads = 4
Limitamos a velocidade da cópia a 80 Mb / s. Usamos pigz para compactação, esta é uma versão multithread do gzip.
GTID Se você usa escravos clássicos, recomendo ativar o GTID no cluster. Isso permitirá que você conecte o escravo a qualquer nó do cluster sem recarregar o escravo.
Além disso, quero falar sobre dois mecanismos de cluster, seu significado e configuração.
Controle de fluxo
O controle de fluxo é uma maneira de gerenciar a carga de gravação em um cluster. Ele não permite que os nós demorem muito na replicação. Dessa maneira, a replicação “quase síncrona” é alcançada. O mecanismo de operação é bastante simples - assim que o comprimento da fila de recepção atinge o valor definido, ele envia a mensagem "Pausa de controle de fluxo" para os outros nós, que os informam para fazer uma pausa na confirmação de novas transações até que o nó atrasado termine a limpeza da fila .
Várias coisas se seguem disso:
- A gravação no cluster ocorrerá na velocidade do nó mais lento. (Mas pode ser reforçado.)
- Se você tiver muitos conflitos ao confirmar transações, poderá configurar o Flow Control de forma mais agressiva, o que deve reduzir o número deles.
- O atraso máximo de um nó em um cluster é uma constante, mas não por tempo, mas pelo número de transações na fila. O tempo de espera depende do tamanho médio da transação e do número de wsrep_slave_threads.
Você pode visualizar as configurações de controle de fluxo assim:
mysql> SHOW GLOBAL STATUS LIKE 'wsrep_flow_control_interval_%';
wsrep_flow_control_interval_low | 36
wsrep_flow_control_interval_high | 71
Primeiro de tudo, estamos interessados no parâmetro wsrep_flow_control_interval_high. Ele controla o comprimento da fila, após o qual a pausa do FC é ativada. Este parâmetro é calculado pela fórmula: gcs.fc_limit * √N (onde N = o número de nós no cluster.).
O segundo parâmetro é wsrep_flow_control_interval_low. É responsável pelo valor do comprimento da fila, ao atingir o FC desativado. Calculado pela fórmula: wsrep_flow_control_interval_high * gcs.fc_factor. Por padrão, gcs.fc_factor = 1.
Assim, alterando o comprimento da fila, podemos controlar o atraso da replicação. Reduzir o comprimento da fila aumentará o tempo que o cluster gasta na pausa do FC, mas reduzirá o atraso dos nós.
Você pode definir a variável de sessão "
wsrep_sync_wait = 7". Isso forçará o PXC a executar solicitações de leitura ou gravação somente após aplicar todos os conjuntos de gravação na fila atual. Naturalmente, isso aumentará a latência de solicitações. O aumento da latência é diretamente proporcional ao comprimento da fila.
Também é desejável reduzir o tamanho máximo da transação ao mínimo possível, para que transações longas não ocorram acidentalmente.
EVS ou Despejo automático
Esse mecanismo permite eliminar nós instáveis (por exemplo, perda de pacotes ou atrasos longos) ou que respondem lentamente. Graças a isso, problemas de comunicação com um nó não colocam o cluster inteiro, mas permitem que o nó seja desativado e continue trabalhando no modo normal. Esse mecanismo é especialmente útil quando o cluster está operando através da WAN ou partes da rede que não estão sob seu controle. Por padrão, o EVS está desativado.
Para habilitá-lo, adicione a opção "evs.version = 1;" ao parâmetro
wsrep_provider_options e "evs.auto_evict = 5;" (o número de operações após as quais o nó é desativado. Um valor 0 desativa o EVS.) Há também vários parâmetros que permitem ajustar o EVS:
- evs.delayed_margin O tempo que leva para um nó responder. Por padrão, 1 segundo, mas ao trabalhar em uma rede local, ele pode ser reduzido para 0,05-0,1 segundos ou menos.
- evs.inactive_check_period Período de verificações. Padrão 0,5 s
De fato, o tempo que um nó pode funcionar em caso de problemas antes que o EVS seja acionado é evs.inactive_check_period * evs.auto_evict. Você também pode definir "evs.inactive_timeout" e um nó que não responder será imediatamente descartado, por padrão 15 segundos.
Uma nuance importante é que esse mecanismo em si não retornará o nó ao restaurar a comunicação. Ele deve ser reiniciado manualmente.
Montamos o EVS em casa, mas não tivemos a chance de testá-lo em batalha.
Balanceamento de carga
Para que os clientes usem os recursos de cada nó uniformemente e executem solicitações apenas em nós do cluster ativo, precisamos de um balanceador de carga. A Percona oferece 2 soluções:
- ProxySQL. Este é o proxy L7 para MySQL.
- Haproxy. Mas o Haproxy não sabe como verificar o status de um nó do cluster e determinar se está pronto para executar solicitações. Para resolver esse problema, propõe-se usar um script adicional percona-clustercheck
Inicialmente, queríamos usar o ProxySQL, mas após o benchmarking, a latência perde para o Haproxy em cerca de 15 a 20%, mesmo quando se usa o modo fast_forward (reescrita de consultas, roteamento e muitas outras funções do ProxySQL não funcionam nesse modo, as solicitações são proxy como estão) .
Haproxy é mais rápido, mas o script Percona tem algumas desvantagens.
Primeiramente, ele é escrito em bash, o que não contribui para sua personalização. Um problema mais sério é que ele não armazena em cache o resultado da verificação do MySQL. Portanto, se tivermos 100 clientes, cada um deles verificando o estado do nó uma vez a cada 1 segundo, o script fará uma solicitação ao MySQL a cada 10 ms. Se, por algum motivo, o MySQL começar a funcionar lentamente, o script de validação começará a criar um grande número de processos, o que definitivamente não melhorará a situação.
Foi decidido escrever
uma solução em que a verificação do status do MySQL e a resposta do Haproxy não estejam relacionadas uma à outra. O script verifica o estado do nó em segundo plano em intervalos regulares e armazena em cache o resultado. O servidor da Web fornece ao Haproxy o resultado em cache.
Exemplo de configuração do Haproxylisten db
bind 127.0.0.1:3302
mode tcp
balance first
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 id 1
server node2 192.168.0.2:3302 check port 9200 backup id 2
server node3 192.168.0.3:3302 check port 9200 backup id 3
listen db_slave
bind 127.0.0.1:4302
mode tcp
balance leastconn
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 backup
server node2 192.168.0.2:3302 check port 9200
server node3 192.168.0.3:3302 check port 9200
Este exemplo mostra uma única configuração do assistente. Os servidores de cluster restantes atuam como escravos.
Monitoramento
Para monitorar o status do cluster, usamos Prometheus + mysqld_exporter e Grafana para visualizar os dados. Porque O mysqld_exporter coleta várias métricas para criar painéis você mesmo é bastante tedioso. Você pode pegar os
painéis prontos
da Percona e personalizá-los para si mesmo.
Também usamos o Zabbix para coletar métricas e alertas básicos de cluster.
As principais métricas de cluster que você deseja monitorar:
- wsrep_cluster_status Deve ser definido como Primário em todos os nós. Se o valor for "não primário", esse nó perdeu o contato com o quorum do cluster.
- wsrep_cluster_size O número de nós no cluster. Isso também inclui nós "perdidos", que devem estar no cluster, mas, por algum motivo, não estão disponíveis. Quando o nó é desligado suavemente, o valor dessa variável diminui.
- wsrep_local_state Indica se o nó é um membro ativo do cluster e está pronto para ser usado .
- wsrep_evs_state Um parâmetro importante se você tiver o Despejo Automático ativado (desativado por padrão). Essa variável indica que o EVS considera esse nó íntegro.
- wsrep_evs_evict_list A lista de nós que foram lançados pelo EVS a partir do cluster. Em uma situação normal, a lista deve estar vazia.
- wsrep_evs_delayed Lista de candidatos para remoção do EVS. Também deve estar vazio.
Principais métricas de desempenho:
- wsrep_evs_repl_latency Mostra o atraso de comunicação (tamanho mínimo / médio / máximo / desvio sênior / tamanho do pacote) dentro do cluster. Ou seja, mede a latência da rede. Valores crescentes podem indicar sobrecarregar os nós da rede ou do cluster. Essa métrica é registrada mesmo quando o EVS está desligado.
- wsrep_flow_control_paused_ns O tempo (em ns) desde o início do nó que passou na pausa do controle de fluxo. Idealmente, deve ser 0. O crescimento desse parâmetro indica problemas com o desempenho do cluster ou a falta de "wsrep_slave_threads". Você pode determinar qual nó fica mais lento com o parâmetro " wsrep_flow_control_sent ".
- wsrep_flow_control_paused A porcentagem de tempo desde a última execução de "FLUSH STATUS;" que o nó passou no controle de fluxo pausou. Assim como a variável anterior, ela deve tender a zero.
- wsrep_flow_control_status Indica se o Flow Control está em execução no momento. No nó inicial da pausa do FC, o valor dessa variável estará LIGADO.
- wsrep_local_recv_queue_avg Comprimento médio da fila de recebimento. O crescimento desse parâmetro indica problemas com o desempenho do nó.
- wsrep_local_send_queue_avg O comprimento médio da fila de envio. O crescimento desse parâmetro indica problemas de desempenho da rede.
Não há recomendações universais sobre os valores desses parâmetros. É claro que eles devem tender a zero, mas em carga real provavelmente não será esse o caso e você deverá determinar por si mesmo onde passa o limite do estado normal do cluster.
Backup
O backup de cluster praticamente não é diferente do mysql independente. Para uso em produção, temos várias opções.
- Remova o backup de um dos nós "gain" usando xtrabackup. A opção mais fácil, mas durante o desempenho do cluster de backup será desperdiçada.
- Use escravos clássicos e faça backup de réplicas.
Os backups independentes e com a versão do cluster criada usando o xtrabackup são portáteis entre si. Ou seja, o backup obtido do cluster pode ser implantado no mysql independente e vice-versa. Naturalmente, a versão principal do MySQL deve corresponder, de preferência a menor. Os backups feitos usando o mysqldump também são naturalmente portáteis.
A única ressalva é que, após implantar o backup, você deve executar o script mysql_upgrade, que verificará e corrigirá a estrutura de algumas tabelas do sistema.
Migração de dados
Agora que descobrimos a configuração, o monitoramento e outras coisas, podemos começar a migrar para o prod.
A migração de dados em nosso esquema era bastante simples, mas nós erramos um pouco;).
Legenda - o mestre 1 e o mestre 2 são conectados pelo mestre de replicação mestre. A gravação vai apenas para o master 1. O Master 3 é um servidor limpo.
Nosso plano de migração (no plano, omitirei as operações com escravos por simplicidade e falarei apenas sobre servidores principais).
Tentativa 1
- Remova o backup do banco de dados do mestre 1 usando xtrabackup.
- Copie o backup para o mestre 3 e execute o cluster no modo de nó único.
- Configure a replicação principal entre os mestres 3 e 1.
- Alterne a leitura e a gravação para o mestre 3. Verifique o aplicativo.
- No mestre 2, desative a replicação e inicie o MySQL em cluster. Estamos esperando que ele copie o banco de dados do mestre 3. Durante a cópia, tivemos um cluster de um nó no status “Doador” e um nó ainda não funcionando. Durante a cópia, obtivemos vários bloqueios e, no final, os dois nós caíram com um erro (a criação de um novo nó não pode ser concluída devido a bloqueios). Esse pequeno experimento nos custou quatro minutos de inatividade.
- Volte a ler e escrever para o mestre 1.
A migração não funcionou devido ao fato de que, ao testar o circuito no ambiente de desenvolvimento no banco de dados, praticamente não havia tráfego de gravação, e ao repetir o mesmo circuito sob carga, problemas surgiram.
Alteramos um pouco o esquema de migração para evitar esses problemas e tentamos novamente, pela segunda vez com êxito;).
Tentativa 2
- Reiniciamos o master 3 para que funcione novamente no modo de nó único.
- Nós aumentamos o cluster MySQL novamente no master 2. No momento, o tráfego da replicação foi apenas para o cluster, portanto não houve problemas repetidos com bloqueios e o segundo nó foi adicionado com êxito ao cluster.
- Mais uma vez, mude a leitura e a gravação para o mestre 3. Verificamos o funcionamento do aplicativo.
- Desativar a replicação principal com o mestre 1. Ative o cluster mysql no mestre 1 e aguarde até que ele seja iniciado. Para não pisar no mesmo rake, é importante que o aplicativo não grave no nó Doador (para obter detalhes, consulte a seção sobre balanceamento de carga). Depois de iniciar o terceiro nó, teremos um cluster totalmente funcional de três nós.
- Você pode remover um backup de um dos nós do cluster e criar o número de escravos clássicos necessários.
A diferença entre o segundo esquema e o primeiro é que trocamos o tráfego para o cluster somente depois de aumentar o segundo nó no cluster.
Este procedimento levou cerca de 6 horas para nós.
Multi-mestre
Após a migração, nosso cluster trabalhou no modo de mestre único, ou seja, todo o registro foi para um dos servidores e apenas os dados foram lidos do restante.
Depois de mudar a produção para o modo multimestre, encontramos um problema - os conflitos de transação surgiam com mais frequência do que esperávamos. Foi especialmente ruim com consultas que modificam muitos registros, por exemplo, atualizando o valor de todos os registros em uma tabela. As transações que foram executadas com sucesso no mesmo nó sequencialmente no cluster são executadas em paralelo e uma transação mais longa recebe um erro de deadlock. Não demorarei, após várias tentativas de corrigir isso no nível do aplicativo, abandonamos a ideia de multimestre.
Outras nuances
- Um cluster pode ser um escravo. Ao usar esta função, recomendo adicionar à configuração todos os nós, exceto aquele que é a opção escrava “skip_slave_start = 1”. Caso contrário, cada novo nó iniciará a replicação a partir do mestre, o que causará erros de replicação ou corrupção de dados na réplica.
- Como eu disse doador, um nó não pode atender adequadamente os clientes. Deve-se lembrar que em um cluster de três nós, as situações são possíveis quando um nó sai, o segundo é um doador e apenas um nó permanece para o atendimento ao cliente.
Conclusões
Após a migração e algum tempo de operação, chegamos às seguintes conclusões.
- O cluster Galera funciona e é bastante estável (pelo menos enquanto não houver quedas anormais de nós ou seu comportamento anormal). Em termos de tolerância a falhas, conseguimos exatamente o que queríamos.
- As declarações multimestre da Percona são principalmente de marketing. Sim, é possível usar o cluster nesse modo, mas isso exigirá uma alteração profunda do aplicativo para este modelo de uso.
- Não há replicação síncrona, mas agora controlamos o atraso máximo dos nós (nas transações). Juntamente com a limitação do tamanho máximo de transação de 50 MB, podemos prever com bastante precisão o tempo máximo de atraso dos nós. Tornou-se mais fácil para os desenvolvedores escreverem código.
- No monitoramento, observamos picos de curto prazo no crescimento da fila de replicação. O motivo está na nossa rede de 1 Gbit / s. É possível operar um cluster nessa rede, mas os problemas aparecem durante as explosões de carga. Agora, estamos planejando atualizar a rede para 10 Gbit / s.
Total de três "lista de desejos" que recebemos cerca de um ano e meio. O requisito mais importante é a tolerância a falhas.
Nosso arquivo de configuração PXC para os interessados:
my.cnf[mysqld]
#Main
server-id = 1
datadir = /var/lib/mysql
socket = mysql.sock
port = 3302
pid-file = mysql.pid
tmpdir = /tmp
large_pages = 1
skip_slave_start = 1
read_only = 0
secure-file-priv = /tmp/
#Engine
innodb_numa_interleave = 1
innodb_flush_method = O_DIRECT
innodb_flush_log_at_trx_commit = 2
innodb_file_format = Barracuda
join_buffer_size = 1048576
tmp-table-size = 512M
max-heap-table-size = 1G
innodb_file_per_table = 1
sql_mode = "NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ERROR_FOR_DIVISION_BY_ZERO"
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
#Wsrep
wsrep_provider = "/usr/lib64/galera3/libgalera_smm.so"
wsrep_cluster_address = "gcomm://192.168.0.1:4577,192.168.0.2:4577,192.168.0.3:4577"
wsrep_cluster_name = "prod"
wsrep_node_name = node1
wsrep_node_address = "192.168.0.1"
wsrep_sst_method = xtrabackup-v2
wsrep_sst_auth = "USER:PASS"
pxc_strict_mode = ENFORCING
wsrep_slave_threads = 64
wsrep_sst_receive_address = "192.168.0.1:4444"
wsrep_max_ws_size = 50M
wsrep_retry_autocommit = 2
wsrep_provider_options = "gmcast.listen_addr=tcp://192.168.0.1:4577; ist.recv_addr=192.168.0.1:4578; gcache.size=30G; pc.checksum=true; evs.version=1; evs.auto_evict=5; gcs.fc_limit=80; gcs.fc_factor=0.75; gcs.max_packet_size=64500;"
#Binlog
expire-logs-days = 4
relay-log = mysql-relay-bin
log_slave_updates = 1
binlog_format = ROW
binlog_row_image = minimal
log_bin = mysql-bin
log_bin_trust_function_creators = 1
#Replication
slave-skip-errors = OFF
relay_log_info_repository = TABLE
relay_log_recovery = ON
master_info_repository = TABLE
gtid-mode = ON
enforce-gtid-consistency = ON
#Cache
query_cache_size = 0
query_cache_type = 0
thread_cache_size = 512
table-open-cache = 4096
innodb_buffer_pool_size = 72G
innodb_buffer_pool_instances = 36
key_buffer_size = 16M
#Logging
log-error = /var/log/stdout.log
log_error_verbosity = 1
slow_query_log = 0
long_query_time = 10
log_output = FILE
innodb_monitor_enable = "all"
#Timeout
max_allowed_packet = 512M
net_read_timeout = 1200
net_write_timeout = 1200
interactive_timeout = 28800
wait_timeout = 28800
max_connections = 22000
max_connect_errors = 18446744073709551615
slave-net-timeout = 60
#Static Values
ignore_db_dir = "lost+found"
[sst]
rlimit = 80m
compressor = "pigz -3"
decompressor = "pigz -dc"
backup_threads = 8
Fontes e links úteis
→
Nossa imagem do Docker→
Documentação do Percona XtraDB Cluster 5.7→
Monitorando o status do cluster - Galera Cluster Documentation→
Variáveis de status do Galera - Galera Cluster Documentation