Olá Habr!
Hoje eu quero falar sobre a segunda parte do projeto de serviço para a identificação e classificação de obras de arte. Deixe-me lembrá-lo de que resolvemos duas tarefas principais:
- procure uma foto no banco de dados a partir de uma fotografia tirada por um telefone celular;
- determinação do estilo e gênero de uma imagem que não está no banco de dados.
Hoje vamos considerar o uso de uma rede neural convolucional para classificar imagens por estilo e gênero.

Ajuda o Dasha a entender a arte contemporânea?
Determinando o estilo das pinturas
Das quase 250.000 pinturas no banco de dados da Arthive, menos de 20% é atribuído a um gênero, estilo ou técnica, geralmente as classes exibidas no banco de dados não correspondem aos valores reais, muitas classes contendo poucas imagens. Parece que existem até classes contendo unidades de imagens. Aparentemente, alguns autores consideram necessário criar um nome para seu próprio estilo.
No total, cerca de 75 estilos foram alocados no banco de dados; no entanto, para o nosso trabalho, o cliente selecionou 27 estilos obrigatórios (aos quais outro foi posteriormente adicionado), que o sistema deve reconhecer.
Para eles, a distribuição do recheio acabou sendo muito desigual.
| Estilo | qtde | Estilo | qtde |
|---|
| Realismo | 19594 | Primitivismo | 1234 |
| Impressionismo | 15864 | Art Déco | 1092 |
| Romantismo | 8963 | Renascença do Norte | 921 |
| Barroco | 7726 | Cubismo | 902 |
| Moderno | 4882 | Academicism | 707 |
| Surrealismo | 4793 | Gótico | 608 |
| Renascimento | 4709 | Modernismo | 539 |
| Expressionismo | 4329 | Realismo socialista | 481 |
| Simbolismo | 4321 | Arte pop | 475 |
| Pós-impressionismo | 3951 | Pontilhismo | 275 |
| Arte abstrata | 3664 | Fauvismo | 217 |
| Ukiyo-e | 3136 | Vanguard | 174 |
| Classicismo | 1730 | Hiperrealismo | 13 |
| Rococó | 1600 | Fantasia | 8 |
| | Total | 96908 |
Todos os estilos| Estilo | qtde | Estilo | qtde | Estilo | qtde |
|---|
| Realismo | 19594 | Arte pop | 475 | Decorativeism | 66. |
| Impressionismo | 15864 | Biedermeier | 471 | Minimalismo | 66. |
| Romantismo | 8963 | Realismo fantástico | 386 | Sentimentalismo | 66. |
| Barroco | 7726 | Expressionismo abstrato | 358 | Cloisonismo | 60 |
| Moderno | 4882 | Nabis | 339 | Pintura metafísica | 56. |
| Surrealismo | 4793 | Pontilhismo | 275 | Machiaioli | 52 |
| Renascimento | 4709 | Suprematismo | 273 | Orphism | 51 |
| Expressionismo | 4329 | Pré-rafaelitas | 252 | Dada | 50. |
| Simbolismo | 4321 | Realismo mágico | 248 | Neo-impressionismo | 49. |
| Pós-impressionismo | 3951 | Renascença | 232 | Luminismo | 41. |
| Arte abstrata | 3664 | Neo-expressionismo | 230 | Proto-renascimento | 39. |
| A Era de Ouro da Holanda | 3292 | Fauvismo | 217 | Plantanismo | 37. |
| Ukiyo-e | 3136 | Pós-modernismo | 192 | Tenebrizm | 35 |
| Classicismo | 1730 | Vanguard | 174 | Impressionismo abstrato | 34 |
| Rococó | 1600 | Arte contemporânea | 149 | Conceitualismo | 29 |
| Primitivismo | 1234 | Precisão | 138 | Japanism | 24 |
| Art Déco | 1092 | Cubofuturismo | 108 | Pós-moderno | 24 |
| Renascença do Norte | 921 | Construtivismo | 104 | Luchism | 24 |
| Cubismo | 902 | Tonalismo | 103 | Bizantino | 20 |
| Academicism | 707 | Orphism | 94 | Realismo romântico | 19 |
| Gótico | 608 | Regionalismo | 93 | Hiperrealismo | 13 |
| Neoclassicismo | 601 | Realismo analítico | 89 | Verism | 11 |
| Maneirismo | 544 | Naturalismo | 73 | Neo-primitivismo | 10 |
| Modernismo | 539 | Neo-modernismo | 70 | Fantasia | 8 |
| Realismo socialista | 481 | Futurismo | 67 | Metarealismo | 7 |
| | | | Total | 106284 |
Somos confrontados com a tarefa de classificar imagens, mas não podemos selecionar nenhum recurso simples manualmente. Portanto, usaremos o profundo aprendizado de máquina, no qual esses recursos complexos são identificados automaticamente no processo de aprendizado.
Transferência de aprendizado
Considere a rede v3 inicial.
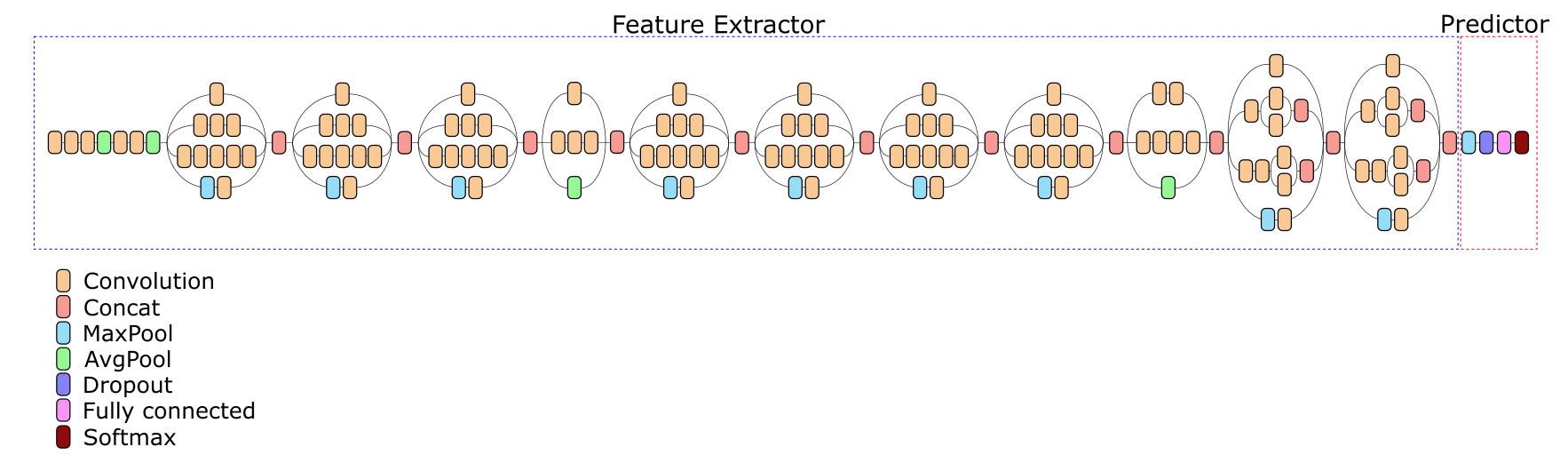
Em sua arquitetura (e em qualquer outra rede profunda), dois componentes principais podem ser distinguidos condicionalmente - Feature Extractor e Predictor.
O Extrator de recursos mapeia a imagem colorida de entrada em um espaço de recursos multidimensional (mapa de recursos multicanais). O mapa de recursos armazena informações espaciais - ou seja, é um tensor tridimensional com dimensões em largura, altura e número de canais de recursos; o pool final ainda não foi aplicado aqui, o que elimina completamente as informações sobre a posição relativa dos recursos na imagem original. A rede Extractor de recursos v3 da Iniciação recebe 299 imagens de entrada 299 3, e na saída forma um mapa de sinais de tamanho 17 17 2048. O tamanho da entrada pode variar, o que levará a alterações no tamanho do mapa de recursos e pode ser útil para reduzir os custos computacionais ao trabalhar com a rede.
O Predictor é uma rede que gera saída com base em um mapa de recursos gerado pelo Feature Extractor. Como regra, para a tarefa de classificação, o Predictor é uma camada de neurônios totalmente conectada, cujo número de saídas coincide com o número de classes do problema.
O aprendizado de transferência clássica pressupõe que tomamos uma rede treinada, separamos o Extrator de recursos e o complementamos com um novo preditor com o número de classes de que precisamos. A rede resultante é treinada em baixa velocidade com pesos parcialmente ou completamente congelados das camadas do Feature Extractor.
Aplicamos o aprendizado de transferência para classificar estilos. Pegue a rede Inception-v3 treinada em um conjunto de dados imagenet e substitua a camada de saída de neurônios nela, que classifica as imagens de entrada no número de estilos selecionados. Treinamos a rede em imagens de diferentes estilos, congelando o treinamento de todas as camadas, exceto a última.
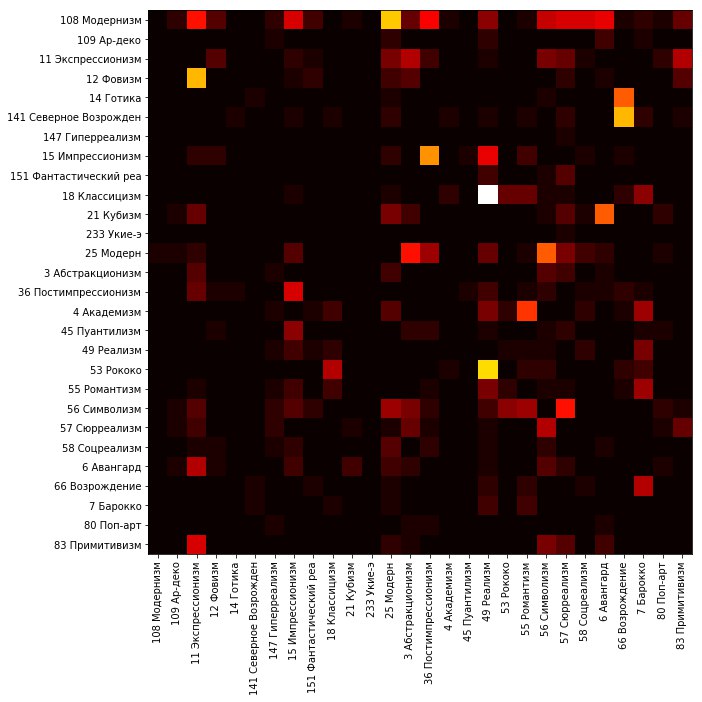
Para análise dos dados, exibimos a distribuição da validação definida por classe.

Cada linha corresponde a uma classe do conjunto de validação. O brilho dos quadrados na linha é proporcional ao número de imagens que caem na classe correspondente à coluna.
Para melhor clareza, excluímos a diagonal principal e normalizamos novamente os valores de cada linha.
Além disso, tentaremos mapear a distribuição de estilos para o espaço bidimensional usando o TSNE.
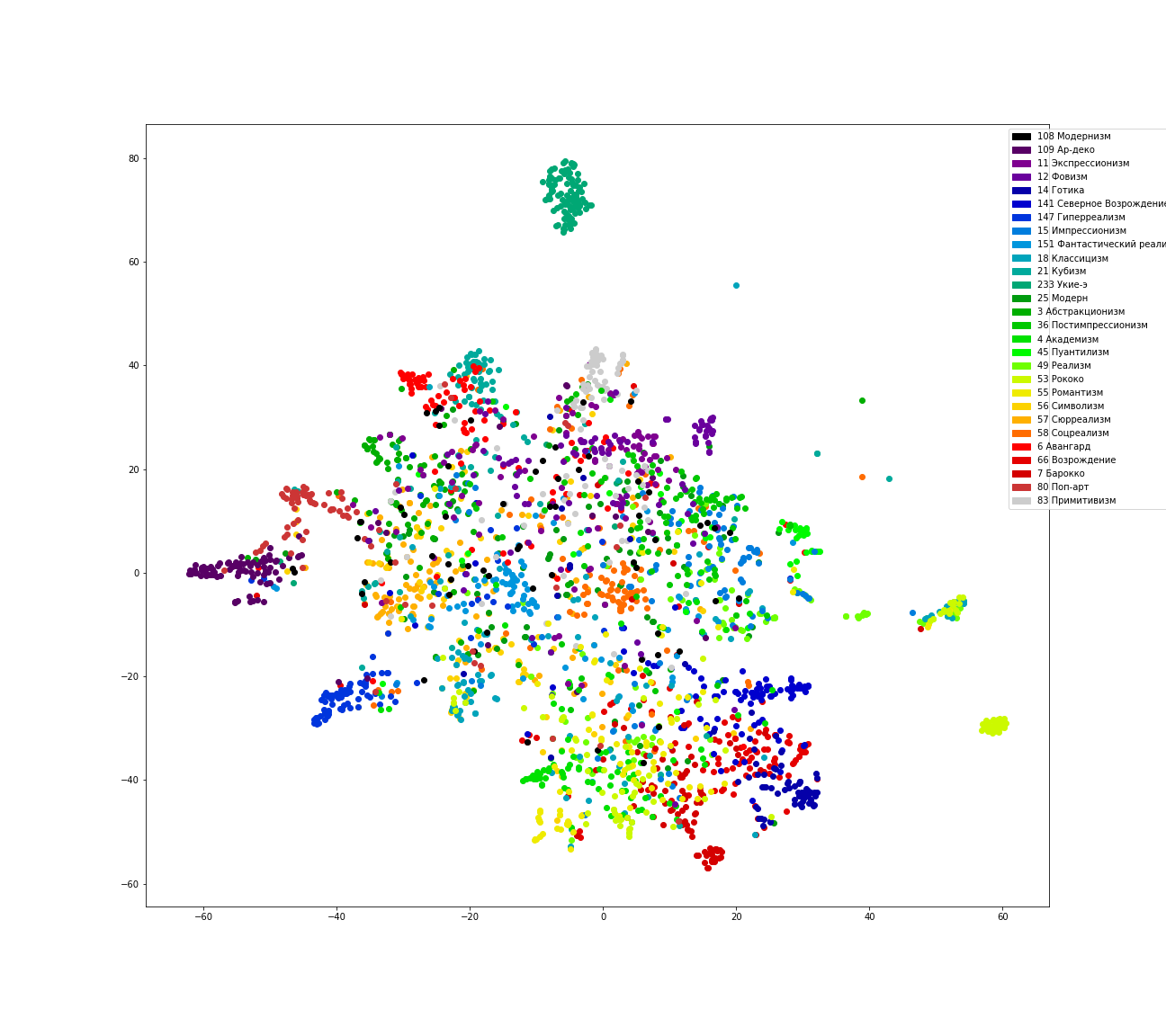
Pode-se observar que muitos erros são observados, por exemplo, na classificação de pinturas no estilo fauvismo - uma parte significativa delas se refere ao expressionismo pela rede. O Renascimento do Norte e o Gótico são freqüentemente chamados de reavivamento. Muitas imagens do estilo rococó e do classicismo estão relacionadas ao realismo. Modernismo e modernidade geralmente se enquadram em muitos estilos.
Depois de lançar um script simples que analisou o banco de dados de treinamento em pastas de acordo com o estilo definido pela rede, realizamos uma análise rápida dos erros. Descobriu-se que a marcação do banco de dados pelo menos levanta questões.
Muitas imagens no estilo do modernismo (que, embora tenham sido marcadas pelo cliente como obrigatórias, mas em geral não são um estilo, e sim uma tendência na arte como um todo) foram na verdade duplicadas em outros estilos, especialmente no modernismo (mas isso já é um estilo).
No estilo do realismo socialista, imagens abstratas estavam presentes, por exemplo, nas obras de Lissitzky. Provavelmente, eles chegaram lá graças ao trabalho de Lissitzky no pôster soviético, que tem uma relação muito indireta com o realismo socialista.
De muitas maneiras, esses são realmente erros, mas às vezes a razão é a debatibilidade da questão de destacar alguns estilos, especialmente modernos. Vale a pena considerar que o banco de dados é preenchido com vários usuários e, entre eles, às vezes não há consenso.
Erros nos dados levam a erros correspondentes na classificação de imagens pela rede. No processo de limpeza da base, tanto por nós quanto pelo especialista em arte, por parte do cliente, a marcação para a amostra de treinamento foi significativamente aprimorada.
No entanto, a maior parte dos erros de classificação da rede (no total) refere-se a estilos mais ou menos bem estabelecidos, como rococó, classicismo, realismo. A atribuição de obras a esses estilos, em regra, ocorre com base em uma época ou autoria e, ao que parece, não causa dúvidas e disputas. Por que a rede não consegue distinguir seu estilo? O principal motivo está no uso de uma rede pré-treinada para extrair características.
O fato é que essa rede foi treinada para classificar objetos, determinar exatamente o que é representado, enquanto descarta informações que não são essenciais para a tarefa sobre como é representada. Por exemplo, do ponto de vista da rede, em todas as imagens no início do artigo, em geral, uma pessoa é retratada.
Para resolver esse problema, criamos uma rede com saídas intermediárias - acredita-se que os sinais se tornam mais difíceis à medida que se movem ao longo da rede, e informações não essenciais desaparecem gradualmente. Vamos tentar extrair das camadas intermediárias o que não era essencial para a classificação da imagenet.
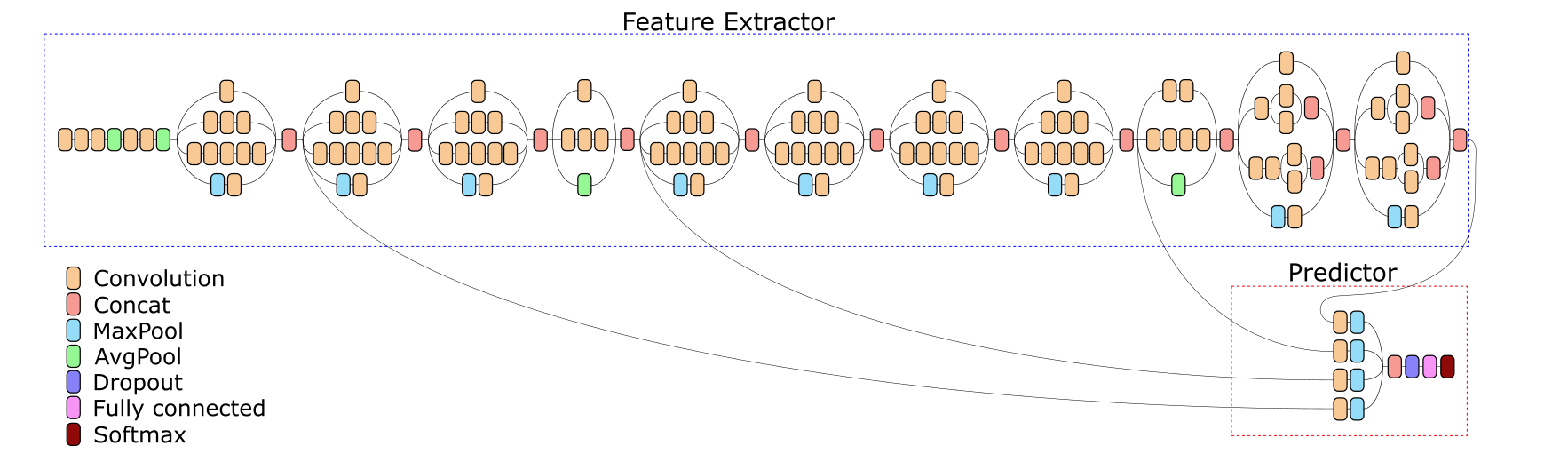
Há outro problema - gráficos, impressões, esboços. Na imagenet, na qual a rede inicial foi pré-treinada, simplesmente não há nada como isso, respectivamente, e os recursos destacados pela rede não são adequados para classificar essas imagens.
Por outro lado, pinturas no estilo de Ukiyo-e , uma espécie de gravura que se espalhou pelo Japão desde o século XVII, foram lindamente penduradas em uma nuvem separada. Embora inicialmente eles não estivessem em nossa lista obrigatória, nós os adicionamos lá.

Após trabalhar com os dados, foi alcançada uma melhor distribuição entre as classes.
Lidamos com gêneros
Do número total de gêneros, 13 foram selecionados (destacados em negrito)
| Género | qtde |
|---|
| Cena alegórica | 2500 |
| Retrato | 2308 |
| Paisagem | 2213 |
| Fantasia | 2191 |
| Cena literária | 2096 |
| Paisagem da cidade | 2048 |
| Nude | 1981 |
| Ainda vida | 1932 |
| Cena de gênero | 1736 |
| Animalism | 1587 |
| Cena religiosa | 1417 |
| Cena mitológica | 1368 |
| Marina | 1210 |
| Arquitetura | 958 |
| O interior | 635 |
| Cena histórica | 534 |
| Cena de batalha | 201 |
| Zakli | 180 |
| Veduta | 124 |
| Paisagem urbana | 16 |
| Total | 27235 |
Basicamente, a redução no número de gêneros foi alcançada reduzindo os gêneros de várias cenas - "religiosa", "mitológica", "alegórica", "literária" e combinando-as sob o nome geral de "cena de gênero". Chegamos à conclusão de que a separação desses gêneros dificilmente pode ser realizada com precisão suficiente sem análise cultural significativa.
Por exemplo, para uma cena alegórica, por definição, supõe-se que exista um significado oculto na imagem, o uso de significados figurativos nos objetos representados. Também há uma dificuldade com a "cena religiosa": é muito provável que uma rede treinada para emitir tal classe também as chame de imagens de caricatura (por exemplo, parodiando a Última Ceia de Da Vinci), e isso pode ofender alguém .
A marcação de dados por gênero inicialmente parece boa, exceto por vários gêneros para os quais existem poucas imagens no banco de dados. Ao pesquisar na Internet, conseguimos expandir um pouco o número de imagens em gêneros (principalmente a cena da batalha, garças e vedutas).
Depois de combinar gêneros difíceis em uma “cena de gênero” comum, tentamos imediatamente treinar a rede “na testa” usando o início das redes de aprendizado por transferência.
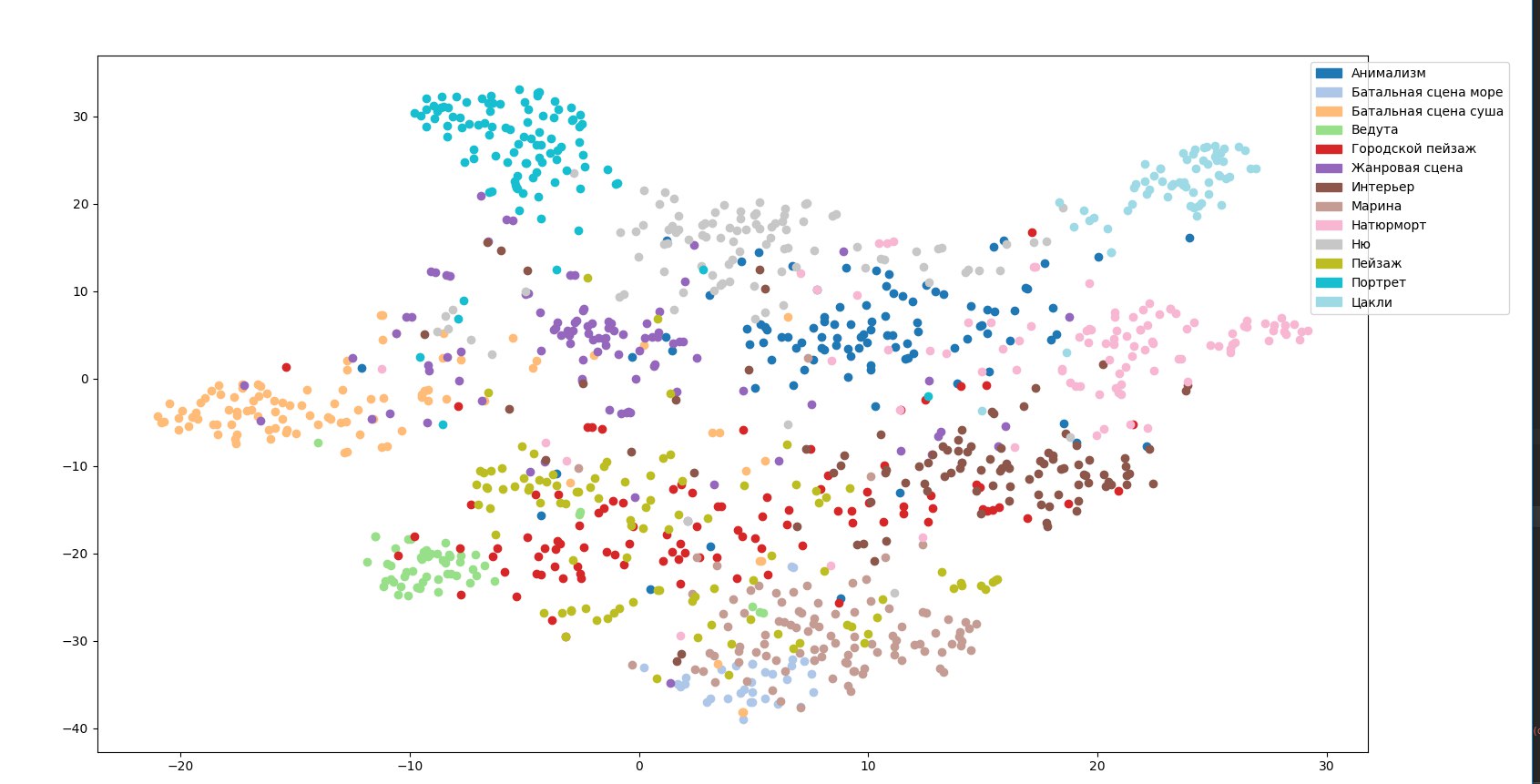
Pode-se ver que os pontos correspondentes a imagens de diferentes gêneros são misturados. Para essas imagens, a rede fornece altos valores das probabilidades de pertencer a vários gêneros ao mesmo tempo, e o gênero com maior probabilidade é determinado quase por acidente. Aparentemente, a razão é que os gêneros, diferentemente dos estilos, têm uma hierarquia mais pronunciada. Tentamos entender essas conexões, temos um mapa de gêneros:
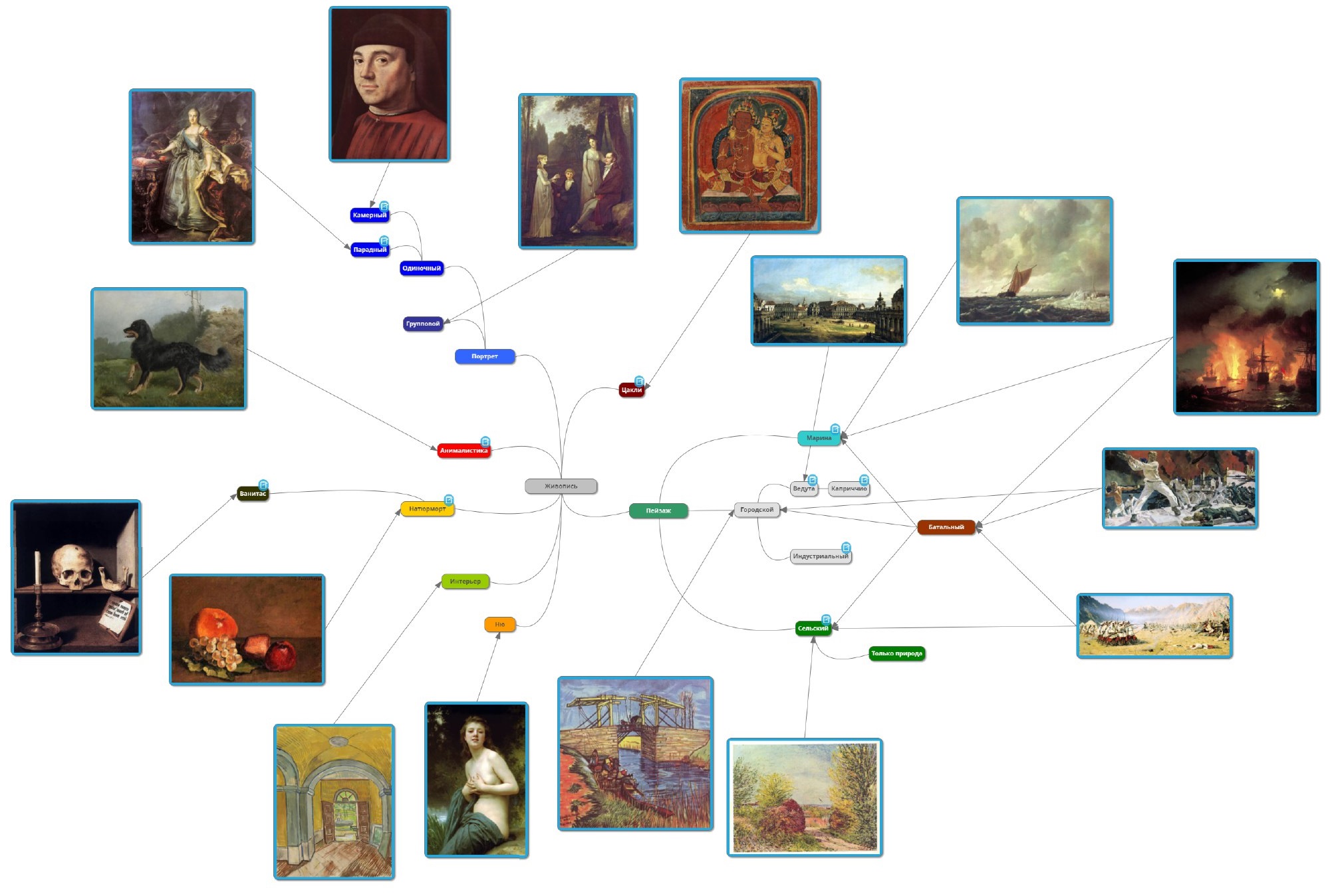
Os gêneros de hierarquia subsidiária e parental geralmente têm características comuns do ponto de vista da rede (e também do nosso ponto de vista). Por exemplo, a cena da batalha em terra como um todo tem as mesmas características da paisagem usual - a imagem de uma grande área aberta ou cidade, e a cena da batalha no mar é mais parecida com o gênero da marina. Portanto, dividimos o gênero da cena da batalha em dois - em terra e no mar. Outro exemplo: retratos, uma cena de gênero e imagens de nus do ponto de vista de uma rede pré-treinada têm um sinal comum - a presença de pessoas.
No banco de dados, imagens com conteúdo semelhante geralmente se referem ao filho ou ao gênero pai, dependendo de onde foi determinado pelo especialista que trouxe as fotos para o banco de dados. Nesse sentido, foi realizada uma limpeza e repartição em larga escala da base, levando em consideração a possível hierarquia de gêneros, o que exigiu muito esforço (conseguimos automatizá-la, mas não muito).
A fim de transferir a hierarquia de gêneros para a rede, abandonamos o envio em um só lugar e configuramos a unidade para imagens não apenas em um gênero, mas também em seu pai, se houver, e também substituímos a função de destino do processo de aprendizado e a função de ativar a camada de saída . Assim, a tarefa passou a ser a classificação Multilabel (a imagem de entrada pode pertencer a várias classes).
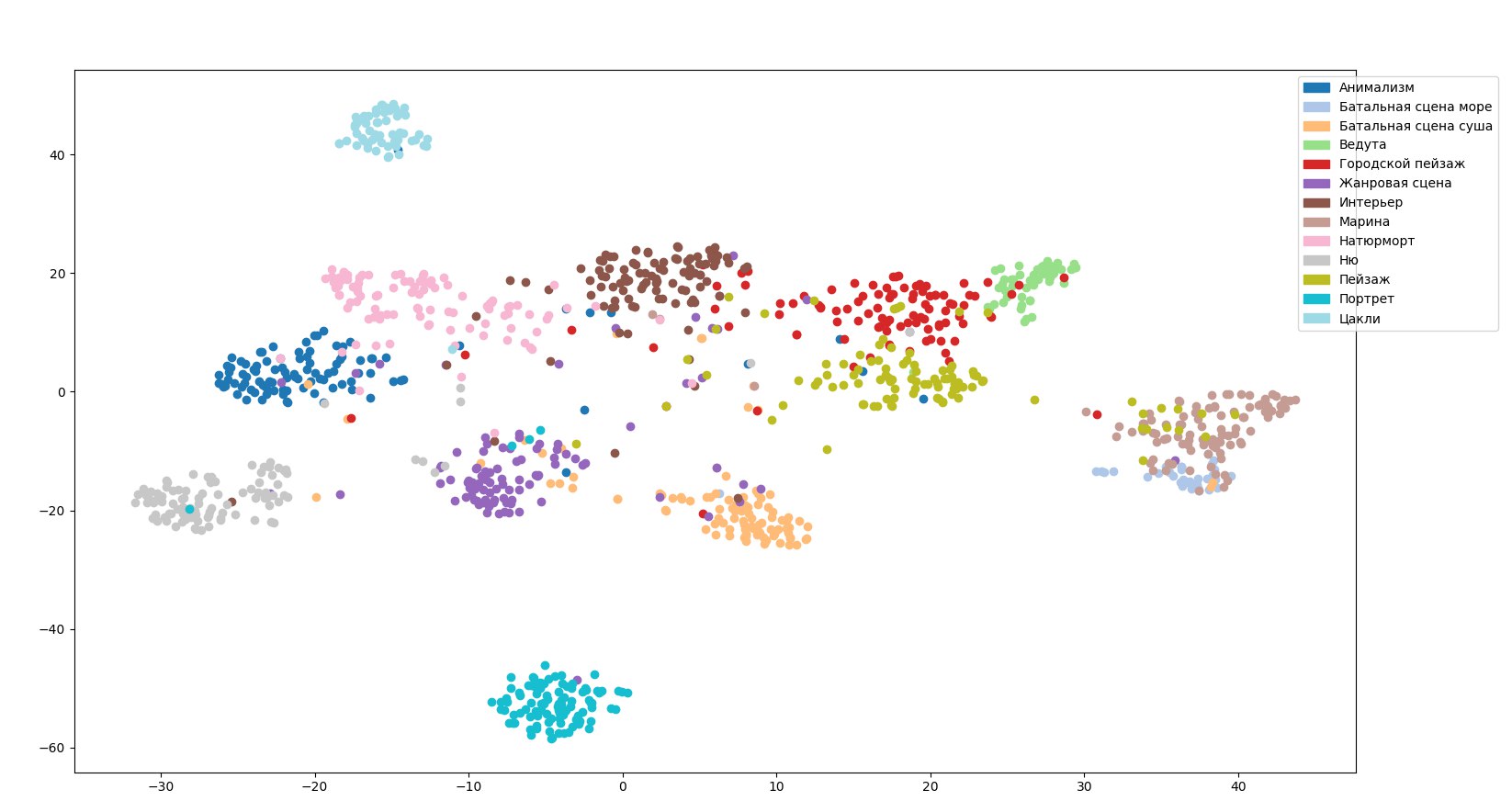
Parece-nos que outro gênero está faltando aqui - abstração. A rigor, esse não é um gênero. Pelo menos especialistas insistiram que não havia esse gênero. Para impedir a rede de dar respostas aleatórias a imagens abstratas, mais uma foi adicionada à divisão geral de gêneros sob o nome "não foi possível determinar", incluindo imagens abstratas e controversas.
Em vez de uma conclusão
Em geral, foi possível obter uma precisão satisfatória na classificação de estilos e gêneros de imagens, mas há muito a melhorar.
Infelizmente, a classificação de estilos e técnicas não foi finalizada - o suporte não foi implementado no serviço.