O espaço do mundo ao redor é preenchido com eventos individuais e suas cadeias - esses eventos são refletidos na mídia, nas contas de blogueiros e pessoas comuns nas redes sociais. Uma imagem da realidade circundante, reivindicando um certo grau de objetividade, só pode ser obtida se coletarmos pontos de vista diferentes sobre o mesmo problema. O categorizador de eventos é a ferramenta que “reúne” as informações coletadas: versões da descrição dos eventos. Em seguida, forneça acesso a informações sobre eventos para os usuários por meio de ferramentas de pesquisa, recomendações e representações visuais de seqüências de tempo de eventos.
Hoje falaremos sobre o nosso sistema, mais precisamente sobre o núcleo do software, sob o codinome "Varya" - em homenagem ao desenvolvedor principal.
Ainda não podemos mencionar o nome da nossa inicialização, a pedido da administração Habrahabr, agora enviamos uma solicitação para nos atribuir o status de Inicialização. No entanto, podemos falar sobre a funcionalidade e nossas idéias agora. Nosso sistema garante a relevância das informações do evento para o usuário e o gerenciamento de dados competente - no sistema, cada usuário determina o que assistir e ler, controla a pesquisa e as recomendações.
Nosso projeto é uma startup com uma equipe de 8 pessoas com competências no projeto de sistemas, programação, marketing e gerenciamento de complexidade técnica e algorítmica.
Juntos, todos os dias a equipe trabalha no projeto - algoritmos para categorizar, pesquisar e apresentar informações já foram implementados. A implementação de algoritmos relacionados a recomendações para o usuário ainda está à frente: com base no relacionamento de eventos, pessoas e análise de atividades e interesses do usuário.
Que tarefas resolvemos e por que falamos sobre isso? Ajudamos as pessoas a obter informações detalhadas sobre eventos de qualquer escala, não importa onde e quando eles ocorreram.
O projeto fornece aos usuários uma plataforma para discutir eventos em um círculo de pessoas afins, permite que você compartilhe um comentário ou sua própria versão do que aconteceu. A plataforma de mídia social foi criada para quem quer saber “acima da média” e ter uma opinião pessoal sobre os principais eventos do passado, presente e futuro.
Os próprios usuários encontram e criam conteúdo útil no espaço da mídia e monitoram sua confiabilidade. Mantemos uma memória dos eventos de sua vida.
Agora que o projeto está no estágio MVP, estamos testando hipóteses sobre a funcionalidade e o trabalho do categorizador, a fim de determinar a direção certa para o desenvolvimento. Neste artigo, falaremos sobre as tecnologias com as quais resolvemos nossas tarefas e compartilhamos nossas melhores práticas.
A tarefa de processamento de texto da máquina é resolvida pelos mecanismos de pesquisa: Yandex, Google, Bing, etc. Um sistema ideal para trabalhar com fluxos de informações e isolar eventos neles poderia ter a seguinte aparência.
Uma infraestrutura semelhante à Yandex e ao Google é construída para o sistema, toda a Internet é verificada em tempo real para atualizações e, em seguida, no fluxo de informações são alocados os kernels de eventos, em torno dos quais são formadas as aglomerações de suas versões e conteúdo relacionado. A implementação de software do serviço é baseada em uma rede neural de aprendizado profundo e / ou em uma solução baseada na biblioteca Yandex - CatBoost.
Cool No entanto, ainda não temos esse volume de dados e não há recursos de computação correspondentes para assimilação.
A classificação por tópico é uma tarefa popular, existem muitos algoritmos para resolvê-lo: classificadores Bayes ingênuos, colocação latente de Dirichlet, aumento de árvores de decisão e redes neurais. Como, provavelmente, em todos os problemas de aprendizado de máquina, ao usar os algoritmos descritos, dois problemas surgem:
Primeiro, onde obter muitos dados?
Em segundo lugar, como colocá-los de forma barata e com raiva?
Que abordagem escolhemos para um sistema baseado em eventos?
Nosso produto trabalha com eventos. Os eventos são um pouco diferentes dos artigos regulares.
Para superar o “começo a frio”, decidimos usar dois projetos do WikiMedia: Wikipedia e Wikinews. Um artigo da Wikipedia pode descrever vários eventos (por exemplo, a história do desenvolvimento da Sun Microsystems, uma biografia de Mayakovsky ou o curso da Grande Guerra Patriótica).
Outras fontes de informações de eventos são feeds RSS. As notícias acontecem de diferentes maneiras: grandes artigos analíticos contêm vários eventos, como textos da Wikipedia, e pequenas mensagens informativas de várias fontes representam o mesmo evento.
Assim, o artigo e os eventos formam relacionamentos muitos para muitos. Mas, no estágio do MVP, assumimos que um artigo é um evento.
Observando a interface do Google ou Yandex, você pode pensar que os mecanismos de pesquisa procuram apenas palavras-chave. Isso é apenas para varejistas on-line muito simples. A maioria dos mecanismos de pesquisa possui vários critérios, e o mecanismo do nosso projeto não é uma exceção. Além disso, longe de todos os parâmetros levados em consideração durante a pesquisa são exibidos na interface do usuário. Nosso projeto possui uma lista de parâmetros que o usuário seleciona, como:
tópicos e palavras-chave -
"o quê?" ; localização -
"onde?" ; data -
"quando?" ;
Quem escreve motores de busca sabe que apenas as palavras-chave causam muitos problemas. Bem, o restante das opções também não é tão simples.
O assunto do evento é uma coisa muito difícil. O cérebro humano é projetado para que ele ame categorizar tudo, e o mundo real discorda disso. Os artigos recebidos desejam formar seus próprios grupos de tópicos e não são de forma alguma aqueles para os quais nossos usuários entusiastas os distribuem.
Agora temos 15 tópicos principais de eventos, e essa lista foi revisada várias vezes e, no mínimo, aumentará.
Locais e datas são organizados um pouco mais formalmente, mas aqui existem armadilhas.
Portanto, temos um conjunto de critérios formalizados e dados brutos que precisamos mapear para esses critérios. E aqui está como fazemos.
Aranha
A tarefa da aranha é dobrar os artigos recebidos para que possam ser pesquisados rapidamente. Para isso, a aranha deve poder atribuir o tópico, a localização e a data aos artigos, além de outros parâmetros necessários para a classificação. Nossa aranha de entrada recebe um modelo de texto do artigo criado pelo rastreador. Um modelo de texto é uma lista de partes de um artigo e seus textos correspondentes. Por exemplo, quase todos os artigos têm pelo menos um título e um texto no corpo. Na verdade, ela ainda possui o primeiro parágrafo, um conjunto de categorias às quais esse texto se refere à sua origem e uma lista de campos da caixa de informações (para Wikipedia e fontes que possuem essas tags de metadados). Ainda há uma data de publicação. Para classificar em um mecanismo de pesquisa, será importante saber se, por exemplo, uma data é encontrada no cabeçalho ou em algum lugar no final do texto. Um modelo de texto é usado para criar um modelo de tópico, um modelo de local e um modelo de data e, em seguida, o resultado é adicionado ao índice. Um artigo separado pode ser escrito sobre cada um desses modelos; portanto, aqui apenas descreveremos brevemente as abordagens.
Theme
Determinar o assunto dos documentos é uma tarefa comum. Os assuntos podem ser atribuídos manualmente pelo autor do documento ou podem ser determinados automaticamente. Obviamente, temos tópicos que fontes de notícias e Wikipedia atribuíram aos nossos documentos, mas esses tópicos não são sobre eventos. Você costuma encontrar o tópico "Feriados" nos feeds de notícias? Em vez disso, você conhecerá o tema "Sociedade". Também tivemos isso em uma das primeiras edições. Não foi possível determinar o que deveria estar relacionado a isso e fomos forçados a removê-lo. Além disso, todas as fontes têm seu próprio conjunto de tópicos.
Queremos gerenciar a lista de tópicos que são exibidos para nossos usuários na interface. Portanto, para nós, a tarefa de determinar o tópico do documento é a tarefa de classificação difusa. A tarefa de classificação requer exemplos rotulados, ou seja, uma lista de documentos aos quais nossos tópicos desejados já foram atribuídos. Nossa lista é semelhante a todas as listas semelhantes de tópicos, mas não coincide com eles, portanto, não tivemos uma amostra rotulada. Você também pode obtê-lo manualmente ou automaticamente, mas se nossa lista de tópicos mudar (e será!), Então manualmente não é uma opção.
Se você não tiver uma amostra rotulada, poderá usar o posicionamento Dirichlet latente e outros algoritmos de modelagem temática; no entanto, o conjunto dos que obtiver será o que acabou sendo o que você deseja.
Aqui devemos mencionar mais um ponto: nossos artigos são de diferentes fontes. Todos os modelos temáticos são construídos de uma maneira ou de outra no vocabulário usado. Para notícias e Wikipedia, é diferente, diferentes até altas frequências peneiradas.
Assim, enfrentamos duas tarefas:
1. Crie uma maneira de organizar rapidamente nossos documentos em um modo semiautomático.
2. Crie um modelo extensível de nossos tópicos com base nesses documentos.
Para resolvê-los, criamos um algoritmo híbrido contendo os estágios automatizado e manual mostrados na figura.
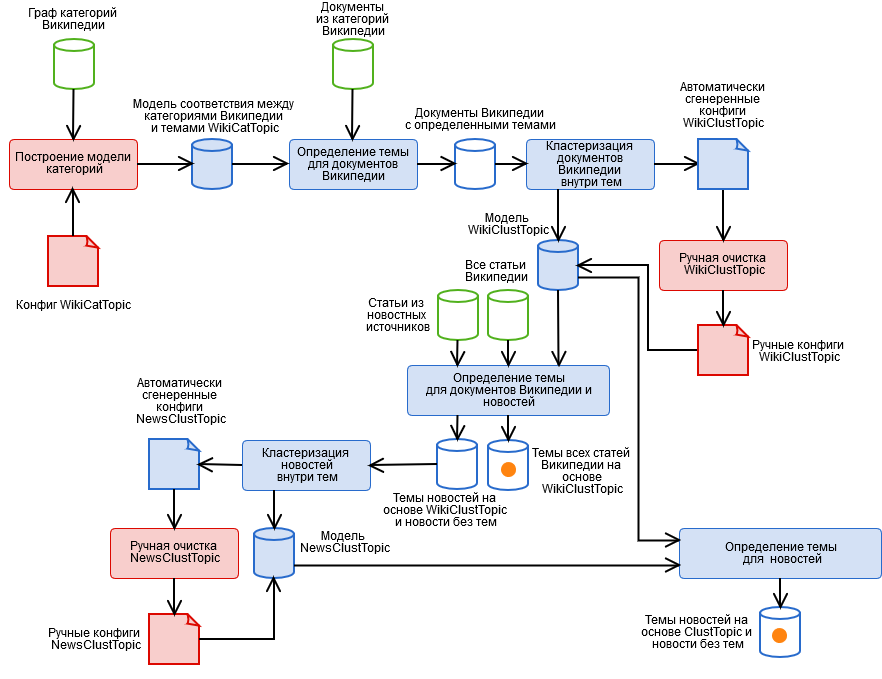
- Marcação manual de categorias da Wikipedia e obtenção de um modelo de tema categórico WikiCatTopic. Nesta fase, é criada uma configuração que atribui um subgráfico das categorias WT da Wikipedia a cada um dos nossos tópicos T. A Wikipedia é uma pseudo-ontologia. Isso significa que, se algo se enquadra na categoria "Ciência", pode não ser sobre ciência, por exemplo, da subcategoria inofensiva "Tecnologias da Informação", você pode realmente acessar qualquer artigo da Wikipedia. É necessário um artigo separado sobre como viver com isso.
- Detecte automaticamente tópicos para documentos da Wikipedia com base no WikiCatTopic. O tópico é atribuído ao documento T se ele se encaixar em uma das categorias do gráfico CT. Observe que esse método se aplica apenas aos artigos da Wikipedia. Para generalizar a definição de tópicos para texto arbitrário, foi possível criar um conjunto de palavras para cada tópico e considerar a distância do cosseno ao tópico (e tentamos, nada de bom), mas aqui três coisas devem ser levadas em consideração.
- Esses tópicos contêm artigos muito diversos, de modo que a imagem do tópico no espaço da palavra não será coerente, o que significa que a "confiança" de um modelo na determinação do tópico é muito baixa (afinal, o artigo é semelhante a um pequeno conjunto de artigos, mas não ao resto).
- Um texto arbitrário, principalmente notícias, difere em sua composição lexical da Wikipedia, o que também não adiciona um modelo de "certeza". Além disso, alguns tópicos não podem ser criados na Wikipedia.
- O estágio 1 é um trabalho muito meticuloso, e todo mundo tem preguiça de fazê-lo.
- Agrupando documentos em tópicos com base nos resultados do parágrafo 2, usando o método k-means e obtendo um modelo de cluster do tema WikiClustTopic. Um movimento bastante simples, que nos permitiu resolver em grande parte dois dos três problemas do parágrafo 2. Para clusters, construímos palavras-chave, e pertencer a um tópico é definido como o máximo das distâncias cosseno para seus clusters. O modelo é descrito em nossos arquivos de configuração de correspondência entre clusters e documentos da Wikipedia.
- Limpeza manual do modelo WikiClustTopic, habilitar-desabilitar-transferência de clusters. Aqui também voltamos ao estágio 1, quando foram descobertos clusters completamente incorretos.
- Detecte automaticamente tópicos do WikiClustTopic para documentos e notícias da Wikipedia.
- Agrupando notícias em tópicos com base nos resultados do parágrafo 5 usando o método k-means, bem como notícias que não receberam tópicos e obtendo um modelo de cluster do tópico NewsClustTopic. Agora, temos um modelo de tema que leva em consideração as especificidades das notícias (além de informações valiosas sobre a qualidade do trabalho do rastreador).
- Limpeza manual do modelo NewsClustTopic.
- Remapeando tópicos de notícias com base no modelo integrado ClustTopic = WikiClustTopic + NewsClustTopic. Com base nesse modelo, os tópicos de novos documentos são determinados.
Localizações
A determinação automática de local é um caso especial da tarefa de procurar entidades nomeadas. Os recursos dos locais são os seguintes:
- Todas as listas de locais são diferentes e não se encaixam bem. Construímos nosso próprio híbrido, que leva em conta não apenas a hierarquia (a Rússia inclui a região de Novosibirsk), mas também as mudanças históricas de nome (por exemplo, o RSFSR se tornou a Rússia) com base em: nomes de nomes, Wikidata e outros fontes abertas. No entanto, ainda tivemos que escrever um conversor de geotag com o Google Maps :)
- Alguns locais consistem em várias palavras, por exemplo, Nizhny Novgorod, e você precisa ser capaz de coletá-los.
- Os locais são semelhantes a outras palavras, especialmente os nomes daqueles em cuja honra eles são nomeados: Kirov, Zhukov, Vladimir. Isso é homonímia. Para curar isso, coletamos estatísticas em artigos da Wikipedia descrevendo assentamentos, em que contextos os nomes dos locais são encontrados e também tentamos criar uma lista desses homônimos usando os dicionários Open Corpora.
- A humanidade não sobrecarregou muito a imaginação, e muitos lugares têm o mesmo nome. Nosso exemplo favorito: Karasuk no Cazaquistão e na Rússia, perto de Novosibirsk. Isso é homonímia dentro da classe de locais. Resolvemos isso, considerando que outros locais são encontrados com este e se eles são pais ou filhos de um dos homônimos. Essa heurística não é universal, mas funciona bem.
Datas
Datas - a incorporação da formalidade em comparação com os Temas e Locais. Fizemos um analisador expansível para eles em expressões regulares e podemos analisar não apenas dia-mês-ano, mas também todo tipo de coisas mais interessantes, como "final do inverno de 1941", "nos anos 90 do século XIX" e "mês passado" ”, Levando em consideração a época e a data-base do documento, além de tentar restaurar o ano que faltava. Sobre datas, você precisa saber que nem todas são boas. Por exemplo, no final de um artigo sobre qualquer batalha da Segunda Guerra Mundial, pode haver uma abertura do memorial quarenta anos depois, para lidar com esses casos, você precisa dividir o artigo em eventos, mas ainda não o estamos fazendo. Portanto, consideramos apenas as datas mais importantes: do cabeçalho e dos primeiros parágrafos.
Mecanismo de pesquisa
O mecanismo de pesquisa é um dispositivo que, em primeiro lugar, procura documentos sob solicitação e, em segundo lugar, organiza-os em ordem decrescente de relevância para a consulta, ou seja, em relevância decrescente. Para calcular a relevância, usamos muitos parâmetros, muito mais do que apenas trivial:
O grau em que o documento pertence ao tópico.
O grau de propriedade do documento do local (quantas vezes e em quais partes do documento o local selecionado foi encontrado).
O grau em que o documento corresponde à data (leva em consideração o número de dias na interseção do intervalo entre a solicitação e as datas do documento, bem como o número de dias na interseção menos a união).
O comprimento do documento. Artigos longos devem ser maiores.
A presença da foto. Todo mundo adora fotos, deve haver mais!
Tipo de artigo da Wikipedia. Podemos separar artigos com descrições de eventos, e eles devem aparecer na amostra.
Fonte do artigo. Notícias e artigos personalizados devem ser maiores que a Wikipedia.
Como mecanismo de pesquisa, usamos o Apache Lucene.
Crawler
A tarefa do rastreador é coletar artigos para a aranha. No nosso caso, aqui também incluímos a limpeza primária do texto e a construção de um modelo de texto do documento. O rastreador merece um artigo separado.
PS Agradecemos qualquer feedback, convidamos você a testar nosso projeto - para receber um link, escrever em mensagens pessoais (não podemos publicar aqui). Deixe seus comentários sob o artigo, ou se você chegar ao nosso serviço - ali mesmo, através do formulário de feedback.