Quando as pessoas pesquisam na Internet uma foto ou um vídeo, geralmente adicionam a frase "de boa qualidade". A qualidade geralmente se refere à resolução - os usuários desejam que a imagem seja grande e, ao mesmo tempo, pareça boa na tela de um computador, smartphone ou TV moderno. Mas e se a fonte de boa qualidade simplesmente não existir?
Hoje, contaremos aos leitores da Habr como, com a ajuda das redes neurais, podemos aumentar a resolução do vídeo em tempo real. Você também aprenderá como a abordagem teórica para resolver esse problema difere da prática. Se você não estiver interessado em detalhes técnicos, poderá rolar com segurança pela postagem - no final, você encontrará exemplos de nosso trabalho.

Há muito conteúdo de vídeo na Internet em baixa qualidade e resolução. Pode ser filmado há décadas ou transmitido canais de TV que, por várias razões, não são da melhor qualidade. Quando os usuários esticam esse vídeo para tela cheia, a imagem fica nublada e confusa. Uma solução ideal para filmes antigos seria encontrar o filme original, digitalizá-lo com equipamentos modernos e restaurar manualmente, mas isso nem sempre é possível. As transmissões são ainda mais complicadas - elas precisam ser processadas ao vivo. Nesse sentido, a opção mais aceitável para trabalharmos é aumentar a resolução e limpar artefatos usando a tecnologia de visão computacional.
Na indústria, a tarefa de aumentar fotos e vídeos sem perda de qualidade é chamada de super-resolução. Muitos artigos já foram escritos sobre esse tópico, mas as realidades do aplicativo "combate" se mostraram muito mais complicadas e interessantes. Brevemente sobre os principais problemas que tivemos que resolver em nossa própria tecnologia DeepHD:
- Você precisa restaurar detalhes que não estavam no vídeo original devido à sua baixa resolução e qualidade, para finalizá-los.
- As soluções da área de super-resolução restauram os detalhes, mas tornam claros e detalhados não apenas os objetos no vídeo, mas também artefatos de compactação, o que causa aversão ao público.
- Há um problema com a coleta da amostra de treinamento - é necessário um grande número de pares em que o mesmo vídeo está presente em baixa resolução e qualidade e em alta. Na realidade, geralmente não há par de qualidade para conteúdo ruim.
- A solução deve funcionar em tempo real.
Seleção de tecnologia
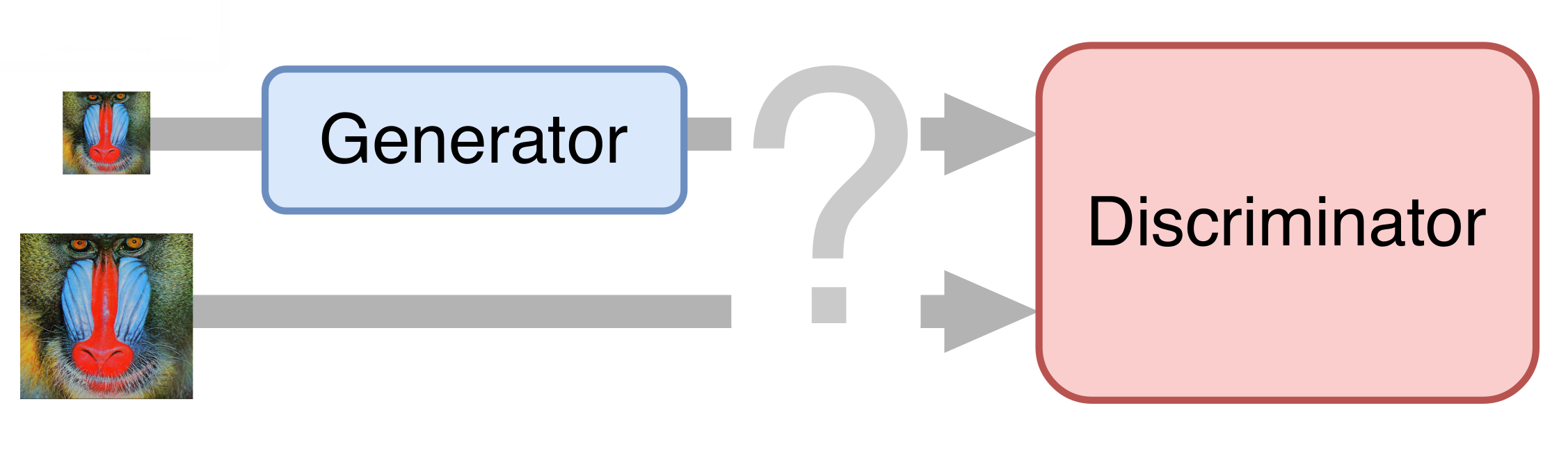
Nos últimos anos, o uso de redes neurais levou a um sucesso significativo na resolução de quase todas as tarefas de visão computacional, e a tarefa de super-resolução não é exceção. Encontramos as soluções mais promissoras baseadas na GAN (Redes Adversárias Generativas, redes rivais generativas). Eles permitem obter imagens fotorrealistas de alta definição, complementando-as com os detalhes ausentes, por exemplo, desenhando cabelos e cílios nas imagens das pessoas.

No caso mais simples, uma rede neural consiste em duas partes. A primeira parte - o gerador - obtém uma imagem de entrada e retorna uma ampliação dobrada. A segunda parte - o discriminador - recebe a imagem gerada e "real" como entrada e tenta distingui-la.
Preparação do conjunto de treinamento
Para treinamento, reunimos dezenas de clipes com qualidade UltraHD. Primeiro, reduzimos para uma resolução de 1080p, obtendo assim exemplos de referência. Em seguida, reduzimos pela metade esses vídeos, compactando-os com uma taxa de bits diferente ao longo do caminho para obter algo semelhante a um vídeo real em baixa qualidade. Dividimos os vídeos resultantes em quadros e os usamos de maneira a treinar a rede neural.
Desbloqueio
Obviamente, queríamos obter uma solução completa: treinar a rede neural para gerar vídeo e qualidade de alta resolução diretamente do original. No entanto, os GANs eram muito caprichosos e tentavam constantemente refinar os artefatos de compactação, em vez de eliminá-los. Portanto, tive que dividir o processo em várias etapas. O primeiro é a supressão de artefatos de compactação de vídeo, também conhecido como desbloqueio.
Um exemplo de um dos métodos de lançamento:

Nesse estágio, minimizamos o desvio padrão entre o quadro gerado e o quadro original. Assim, embora tenhamos aumentado a resolução da imagem, não obtivemos um aumento real na resolução devido à regressão à média: a rede neural, sem saber em quais pixels específicos uma determinada borda da imagem passa, foi forçada a calcular a média de várias opções, obtendo um resultado desfocado. O principal que alcançamos nesse estágio é a eliminação dos artefatos de compactação de vídeo; portanto, no estágio seguinte, a rede generativa precisava apenas aumentar a clareza e adicionar os pequenos detalhes ausentes, texturas. Após centenas de experimentos, selecionamos a arquitetura ideal em termos de desempenho e qualidade, que lembra vagamente a arquitetura
DRCN :
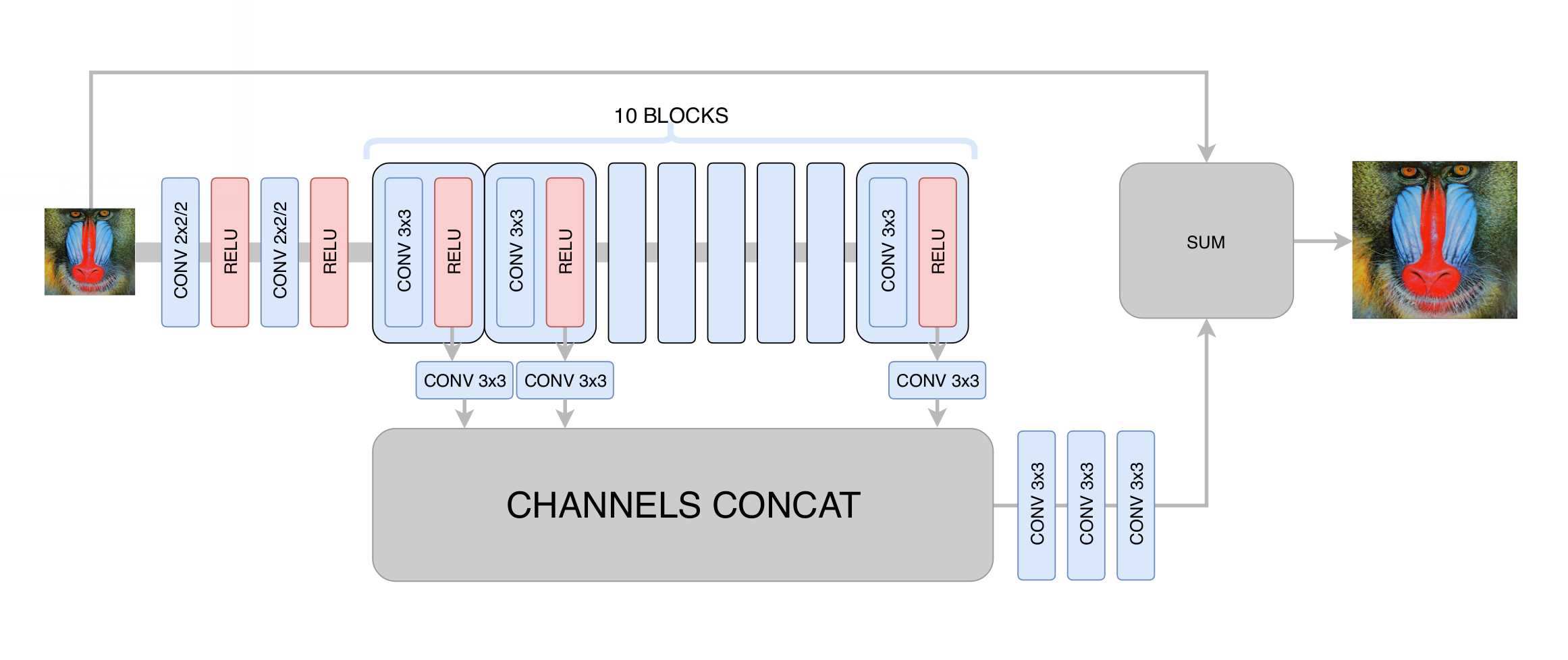
A idéia principal de uma arquitetura desse tipo é o desejo de obter a arquitetura mais profunda, sem ter problemas com a convergência em seu treinamento. Por um lado, cada camada convolucional subsequente extrai recursos cada vez mais complexos da imagem de entrada, o que permite determinar que tipo de objeto está em um determinado ponto da imagem e restaurar peças complexas e gravemente danificadas. Por outro lado, a distância no gráfico da rede neural de qualquer camada até a saída permanece pequena, o que melhora a convergência da rede neural e torna-se possível o uso de um grande número de camadas.
Treinamento de rede generativa
Tomamos a arquitetura
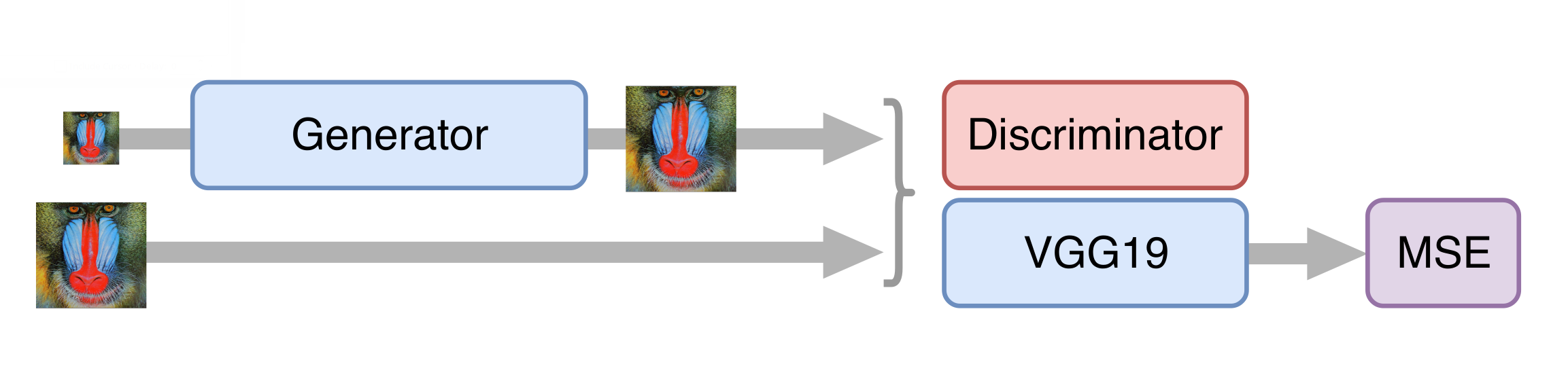
SRGAN como base de uma rede neural para aumentar a resolução. Antes de treinar uma rede competitiva, você precisa pré-treinar o gerador - treiná-lo da mesma maneira que no estágio de desbloqueio. Caso contrário, no início do treinamento, o gerador retornará apenas ruído, o discriminador começará imediatamente a "vencer" - aprenderá facilmente a distinguir o ruído dos quadros reais e nenhum treinamento funcionará.

Depois treinamos a GAN, mas existem algumas nuances. É importante para nós que o gerador não apenas crie quadros fotorrealistas, mas também armazene as informações disponíveis neles. Para isso, adicionamos a função de perda de conteúdo à arquitetura GAN clássica. Representa várias camadas da rede neural VGG19 treinadas no conjunto de dados ImageNet padrão. Essas camadas transformam a imagem em um mapa de recursos que contém informações sobre o conteúdo da imagem. A função de perda minimiza a distância entre esses cartões obtidos dos quadros gerados e originais. Além disso, a presença dessa função de perda permite não estragar o gerador nas primeiras etapas do treinamento, quando o discriminador ainda não está treinado e fornece informações inúteis.
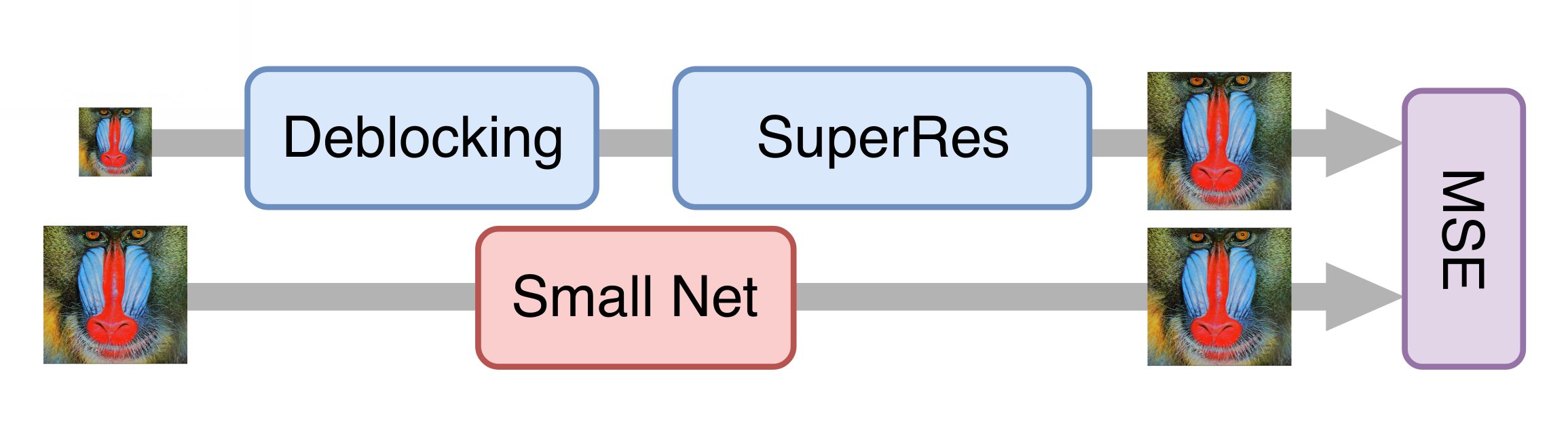
Aceleração de rede neural
Tudo correu bem e, após uma série de experimentos, conseguimos um bom modelo que já podia ser aplicado a filmes antigos. No entanto, ainda era muito lento para processar o streaming de vídeo. Aconteceu que é impossível simplesmente reduzir o gerador sem uma perda significativa na qualidade do modelo final. Então, a abordagem da destilação de conhecimento veio em nosso auxílio. Esse método envolve o treinamento de um modelo mais leve, de modo que repita os resultados de um modelo mais pesado. Pegamos muitos vídeos reais em baixa qualidade, processamos com a rede neural generativa obtida na etapa anterior e treinamos a rede mais leve para obter o mesmo resultado dos mesmos quadros. Devido a essa técnica, obtivemos uma rede que não possui qualidade muito inferior à original, mas é dez vezes mais rápida: para processar um canal de TV com resolução 576p, é necessária uma placa NVIDIA Tesla V100.
Avaliação da qualidade das soluções
Talvez o momento mais difícil ao trabalhar com redes generativas seja a avaliação da qualidade dos modelos resultantes. Não existe uma função de erro clara, como, por exemplo, ao resolver o problema de classificação. Em vez disso, sabemos apenas a precisão do discriminador, que não reflete a qualidade do gerador que nos interessa (um leitor que esteja familiarizado com essa área poderia sugerir o uso
da métrica de Wasserstein , mas, infelizmente, deu um resultado notavelmente pior).
As pessoas nos ajudaram a resolver esse problema. Mostramos aos usuários os pares de imagens do serviço
Yandex.Tolok , um dos quais era a fonte e o outro processado por uma rede neural, ou ambos foram processados por diferentes versões de nossas soluções. Por uma taxa, os usuários escolheram um vídeo melhor de um par, por isso obtivemos uma comparação estatisticamente significativa de versões, mesmo com alterações difíceis de ver com os olhos. Nossos modelos finais vencem em mais de 70% dos casos, o que é bastante, já que os usuários gastam apenas alguns segundos na classificação de alguns vídeos.
Um resultado interessante também foi o fato de o vídeo com resolução 576p, aumentado pela tecnologia DeepHD para 720p, superar o mesmo vídeo original com resolução 720p em 60% dos casos - ou seja, O processamento não apenas aumenta a resolução do vídeo, mas também melhora sua percepção visual.
Exemplos
Na primavera, testamos a tecnologia DeepHD em vários filmes antigos que podem ser assistidos no KinoPoisk: “
Rainbow ” de Mark Donskoy (1943), “
Cranes are Flying ” de Mikhail Kalatozov (1957), “
My Dear Man ” de Joseph Kheifits (1958), “
The Fate of a Man ” Sergei Bondarchuk (1959), “
Ivan Childhood ”, de Andrei Tarkovsky (1962), “
Father of a Soldier ”, Rezo Chkheidze (1964) e “
Tango of Our Childhood ”, de Albert Mkrtchyan (1985).

A diferença entre as versões antes e depois do processamento é especialmente notável se você observar os detalhes: estude as expressões faciais dos heróis em close-ups, considere a textura da roupa ou um padrão de tecido. Foi possível compensar algumas das deficiências da digitalização: por exemplo, remover superexposições nas faces ou tornar mais visíveis os objetos colocados na sombra.
Mais tarde, a tecnologia DeepHD começou a ser usada para melhorar a qualidade das transmissões de
alguns canais no serviço Yandex.Air. É fácil reconhecer esse conteúdo pela tag
dHD .
Agora
em Yandex na melhoria da qualidade, você pode ver o "Snow Queen", "Os Músicos de Bremen", "Antelope Ouro" e outro estúdio de cinema popular desenho animado "Soyuzmultfilm". Alguns exemplos de dinâmica podem ser vistos no vídeo:
Para espectadores exigentes, a diferença será especialmente notável: a imagem ficou mais nítida, folhas de árvores, flocos de neve, estrelas no céu noturno sobre a selva e outros pequenos detalhes são mais visíveis.
Mais é mais.
Links úteis
Jiwon Kim, Jung Kwon Lee, Rede convolucional profundamente recursiva de Kyoung Mu Lee para super-resolução de imagem [
arXiv: 1511.04491 ].
Christian Ledig et al. Super-resolução de imagem única foto-realista usando uma rede adversária generativa [
arXiv: 1609.04802 ].
Mehdi SM Sajjadi, Bernhard Schölkopf, Michael Hirsch EnhanceNet: Super-resolução de imagem única através da síntese automatizada de texturas [
arXiv: 1612.07919 ].