As pessoas sempre desejaram ensinar uma máquina a entender uma pessoa. No entanto, só agora estamos um pouco mais próximos das tramas de filmes de ficção científica: podemos pedir a Alice para diminuir o volume, o Assistente do Google - pedir um táxi ou Siri - acionar um alarme. As tecnologias de processamento de idiomas são demandadas em desenvolvimentos relacionados à construção da inteligência artificial: nos mecanismos de busca, para extrair fatos, avaliar a tonalidade do texto, tradução automática e diálogo.
Falaremos sobre as duas últimas áreas: elas têm um histórico rico e tiveram um impacto significativo no processamento de idiomas. Além disso, abordaremos as possibilidades básicas de processamento da linguagem natural ao criar um robô de bate-papo junto com o palestrante do nosso curso
AI Weekend, a linguista da computação Anna Vlasova.
Como tudo começou?
A primeira conversa sobre o processamento da linguagem natural com um computador começou nos anos 30 do século XX com o raciocínio filosófico de Ayer - ele propôs distinguir uma pessoa inteligente de uma máquina estúpida usando um teste empírico. Em 1950, Alan Turing, na revista filosófica
Mind, propôs um teste em que o juiz deve determinar com quem está falando: uma pessoa ou um computador. Utilizando o teste, foram estabelecidos critérios para avaliar o trabalho da inteligência artificial, a possibilidade de sua construção não foi questionada. O teste tem muitas limitações e desvantagens, mas teve um impacto significativo no desenvolvimento de bots de bate-papo.
A primeira área em que o processamento do idioma foi aplicado com sucesso foi a tradução automática. Em 1954, a Universidade de Georgetown, juntamente com a IBM, demonstrou um programa de tradução automática do russo para o inglês, que funcionava com base em um dicionário de 250 palavras e um conjunto de 6 regras gramaticais. O programa estava longe do que realmente poderia ser chamado de tradução automática e traduziu 49 ofertas pré-selecionadas em uma demonstração. Até meados dos anos 60, muitas tentativas foram feitas para criar um programa de tradução totalmente funcional, mas em 1966 a Comissão Consultiva para o Processamento Automático da Língua
(ALPAC) declarou a tradução automática como uma direção fútil. Os subsídios estatais cessaram por algum tempo, o interesse público em tradução automática diminuiu, mas a pesquisa não parou por aí.

Paralelamente às tentativas de ensinar um computador a traduzir texto, cientistas e universidades inteiras estavam pensando em criar um robô que pudesse imitar o comportamento da fala humana. A primeira implementação bem-sucedida do chatbot foi o interlocutor virtual ELIZA, escrito em 1966 por Joseph Weizenbaum. Eliza parodiou o comportamento do psicoterapeuta, extraindo palavras significativas da frase do interlocutor e fazendo uma contra-pergunta. Podemos assumir que esse foi o primeiro bot de bate-papo baseado em regras (bot baseado em regras) e estabeleceu as bases para toda uma classe de tais sistemas. Entrevistadores como Cleverbot, WeChat Xiaoice, Eugene Goostman - passaram formalmente no teste de Turing em 2014 - e nem Siri, Jarvis e Alexa teriam aparecido sem Eliza.
Em 1968, Terry Grapes desenvolveu o programa SHRDLU no LISP. Ela moveu objetos simples sob comando: cones, cubos, bolas e podia suportar o contexto - ela entendeu qual elemento precisava ser movido, se mencionado anteriormente. O próximo passo no desenvolvimento de bots de bate-papo foi o programa ALICE, para o qual Richard Wallace desenvolveu uma linguagem de marcação especial - AIML
(English Artificial Intelligence Markup Language) . Então, em 1995, as expectativas do chatbot foram exageradas: eles pensaram que ALICE seria ainda mais inteligente que uma pessoa. Obviamente, o chatbot não conseguiu ser mais inteligente e, por algum tempo, os negócios em chatbots ficaram desapontados, e os investidores por um longo tempo contornaram o tópico dos assistentes virtuais.
Questões linguísticas
Hoje, os chatbots ainda funcionam com base em um conjunto de regras e cenários comportamentais; no entanto, uma linguagem natural é nebulosa e ambígua, um pensamento pode ter várias formas de apresentação; portanto, o sucesso comercial dos sistemas de diálogo depende da solução de problemas de processamento de linguagem. A máquina deve ser ensinada a classificar claramente toda a variedade de perguntas recebidas e interpretá-las claramente.
Todos os idiomas são organizados de maneira diferente, e isso é muito importante para a análise. Do ponto de vista da composição morfológica, os elementos significativos da palavra podem se juntar à raiz seqüencialmente, como, por exemplo, nas línguas turcas, ou podem quebrá-la, como em árabe e hebraico. Do ponto de vista da sintaxe, alguns idiomas permitem a ordem livre das palavras em uma frase, enquanto outros são organizados de forma mais rígida. Nos sistemas clássicos, a ordem das palavras desempenha um papel essencial. Para os métodos estatísticos modernos da PNL, ele não possui esse valor, pois o processamento não ocorre no nível das palavras, mas de sentenças inteiras.
Outras dificuldades no desenvolvimento de bots de bate-papo surgem em conexão com o desenvolvimento da comunicação multilíngue. Agora, as pessoas geralmente não se comunicam em seus idiomas nativos, elas usam palavras incorretamente. Por exemplo, na frase “eu enviei há dois dias, mas as mercadorias não chegaram”, do ponto de vista do vocabulário, deveríamos falar sobre a entrega de objetos físicos, por exemplo, mercadorias, e não sobre a transação com dinheiro eletrônico, descrita por essas pessoas por essas pessoas que não fala nada no idioma nativo. Mas na comunicação real, uma pessoa entenderá o interlocutor corretamente e o bot de bate-papo pode ter problemas. Em certos tópicos, como investimentos, bancos ou TI, as pessoas costumam mudar para outros idiomas. Mas é improvável que o chatbot entenda o que está em jogo, pois provavelmente é treinado em um idioma.
Caso de sucesso: tradutores de máquina
Antes do advento dos assistentes de voz e da ampla disseminação de chatbots, a tradução automática era a tarefa intelectual mais exigida, que exigia o processamento de um idioma natural. A conversa sobre redes neurais e aprendizado profundo remonta aos anos 90, e o primeiro neurocomputador Mark-1 apareceu em geral em 1958. Mas em todos os lugares não foi possível usá-los devido ao baixo desempenho dos computadores e à falta de corpus de linguagem suficiente. Somente grandes equipes de pesquisa poderiam se dar ao luxo de fazer pesquisas no campo das redes neurais.
Os tradutores automáticos em meados do século 20 estavam longe do Google Translate e Yandex.Translator, mas a cada novo método de tradução surgiam idéias que eram aplicadas de uma forma ou de outra ainda hoje.
1970 A tradução
automática baseada em regras (RBMT) foi a primeira tentativa de ensinar uma máquina a traduzir. A tradução foi obtida como em uma quinta série com um dicionário, mas de uma forma ou de outra, as regras para um tradutor de máquina ou um robô de bate-papo ainda estão sendo usadas.
1984 A tradução automática por exemplo
(EBMT) foi capaz de traduzir até mesmo idiomas completamente diferentes entre si, onde era inútil definir regras. Todos os tradutores de máquina modernos e robôs de bate-papo usam exemplos e padrões prontos.
1990. A tradução automática estatística
(SMT em
inglês), na era do desenvolvimento da Internet, tornou possível o uso não apenas de um corpo de idiomas já pronto, mas também de livros e artigos traduzidos livremente. Mais dados disponíveis aumentaram a qualidade da tradução. Os métodos estatísticos agora são usados ativamente no processamento de idiomas.
Redes neurais ao serviço da PNL
Com o desenvolvimento do processamento de linguagem natural, muitos problemas foram resolvidos por métodos estatísticos clássicos e por muitas regras, mas isso não resolveu o problema de imprecisão e ambiguidade na linguagem. Se dizemos "curvar-se" sem qualquer contexto, é improvável que mesmo um interlocutor vivo entenda o que está sendo dito. A semântica da palavra no texto é determinada pelas palavras vizinhas. Mas como explicar isso a uma máquina se ela entende apenas uma representação numérica? Assim nasceu o método estatístico de análise de texto
word2vec (palavra em inglês para vetor) .
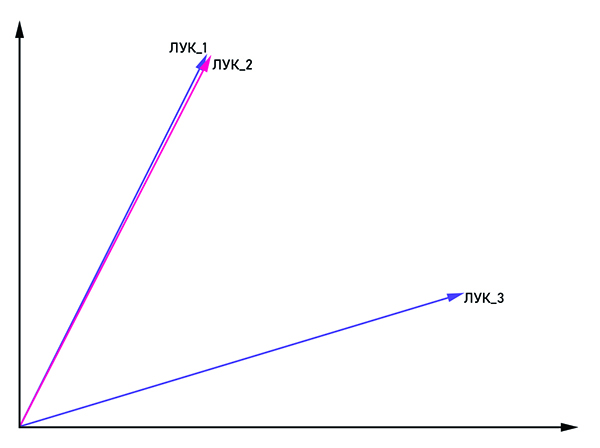 Os vetores bow_1 e bow_2 são paralelos, portanto, essa é uma palavra e bow_3 é um homônimo.
Os vetores bow_1 e bow_2 são paralelos, portanto, essa é uma palavra e bow_3 é um homônimo.A idéia é bastante óbvia no nome: apresentar a palavra na forma de um vetor com coordenadas (x
1 , x
2 , ..., x
n ). Para combater a homonímia, as mesmas palavras são associadas à tag: "bow_1", "bow_2" e assim por diante. Se os vetores bow_n e bow_m forem paralelos, eles poderão ser considerados como uma palavra. Caso contrário, essas palavras são homônimos. Na saída, cada palavra tem sua própria representação vetorial no espaço multidimensional (a dimensão do espaço vetorial pode variar de 50 a 1000).

A questão permanece: que tipo de rede neural usar para treinar um bot de bate-papo condicional. A consistência é importante no discurso humano: tiramos conclusões e tomamos decisões com base no que foi mencionado na frase anterior ou até no parágrafo. Uma rede neural recorrente (RNN) é perfeita para esses critérios, no entanto, à medida que a distância entre as partes conectadas do texto aumenta, o tamanho da RNN precisa ser aumentado, o que resulta em uma diminuição na qualidade do processamento de informações. Esse problema foi resolvido pela rede LSTM
(inglês Long short term memory) . Ele tem uma característica importante - o estado da célula, que pode permanecer constante ou mudar, se necessário. Assim, as informações na cadeia não são perdidas, o que é essencial para o processamento da linguagem natural.
Hoje, existe um grande número de bibliotecas para o processamento de linguagem natural. Se falamos da linguagem Python, que é frequentemente usada para análise de dados, essas são
NLTK e
Spacy . Grandes empresas também participam do desenvolvimento de bibliotecas para a PNL, como o
NLP Architect da Intel ou
PyTorch de pesquisadores do Facebook e Uber. Apesar do grande interesse das empresas de grande escala nos métodos de processamento de linguagem das redes neurais, os diálogos coerentes são construídos principalmente com base nos métodos clássicos, e a rede neural desempenha um papel de apoio na solução dos problemas de pré-processamento e classificação da fala.
Como a PNL pode ser usada nos negócios?
As aplicações mais óbvias para processamento de linguagem natural incluem tradutores automáticos, bots de bate-papo e assistentes de voz - algo que encontramos todos os dias. A maioria dos funcionários do call center pode ser substituída por assistentes virtuais, uma vez que cerca de 80% das solicitações de clientes aos bancos estão relacionadas a problemas bastante comuns. O chatbot também lidará com calma com a entrevista inicial do candidato e a gravará em uma reunião "ao vivo". Curiosamente, a jurisprudência é uma direção bastante precisa, então mesmo aqui o robô de bate-papo pode se tornar um consultor de sucesso.

A direção b2c não é a única onde os bots de bate-papo podem ser usados. Nas grandes empresas, a rotação de funcionários é bastante ativa; portanto, todos precisam ajudar na adaptação ao novo ambiente. Como as perguntas do novo funcionário são bastante típicas, todo o processo é facilmente automatizado. Não é necessário procurar uma pessoa que explique como reabastecer a impressora, com quem entrar em contato sobre qualquer problema. O bot de bate-papo interno da empresa se sairá bem com isso.
Usando a PNL, você pode medir com precisão a satisfação do usuário com um novo produto, analisando análises na Internet. Se o programa identificou a revisão como negativa, o relatório é automaticamente enviado ao departamento apropriado, onde as pessoas vivas já estão trabalhando com ela.
As possibilidades de processamento de idiomas serão expandidas apenas e com elas o escopo de sua aplicação. Se 40 pessoas trabalham no call center da sua empresa, vale a pena considerar: talvez seja melhor substituí-las por uma equipe de programadores que organizarão um bot de bate-papo para você?
Você pode aprender mais sobre as possibilidades de processamento de idiomas em nosso curso
AI Weekend , onde Anna Vlasova falará em detalhes sobre bots de bate-papo no âmbito do tópico de inteligência artificial.