Você já analisou vagas?
Eles fizeram a pergunta: em quais tecnologias a demanda do mercado de trabalho é mais atual? Há um mês? Um ano atrás?
Com que frequência as novas vagas de emprego Java são abertas em uma área específica da sua cidade e com que intensidade elas fecham?
Neste artigo, mostrarei como você pode alcançar o resultado desejado e criar um sistema de relatórios sobre um tópico de nosso interesse. Vamos lá!
(Fonte da imagem)Provavelmente muitos de vocês estão familiarizados e até usaram um recurso como o
Headhunter.ru . Milhares de novas vagas em vários campos são postadas neste site diariamente. O HeadHunter também possui uma API que permite ao desenvolvedor interagir com os dados desse recurso.
Toolkit
Usando um exemplo simples, consideramos a construção do processo de obtenção de dados para o sistema de relatórios, baseado no trabalho com o site da API Headhunter.ru. Como um armazenamento intermediário de informações, usaremos o SQLite DBMS incorporado, os dados processados serão armazenados no banco de dados NoSQL do MongoDB, o Python 3.4 como idioma principal.
API HHOs recursos da API do HeadHunter são bastante amplos e bem descritos na documentação oficial do
GitHib . Antes de tudo, essa é a capacidade de enviar solicitações anônimas que não exigem autorização para receber informações sobre tarefas no formato JSON. Recentemente, vários métodos foram pagos (métodos do empregador), mas eles não serão considerados nesta tarefa.
Cada vaga permanece no site por 30 dias, após o que, se não for renovada, será arquivada. Se a vaga foi arquivada antes da expiração de 30 dias, foi encerrada pelo empregador.
A API do HeadHunter (doravante denominada API do HH) permite que você receba uma variedade de vagas publicadas para qualquer data nos últimos 30 dias, que usaremos - coletaremos diariamente as vagas publicadas para cada dia.
Implementação
- Conectar banco de dados SQLite
import sqlite3 conn_db = sqlite3.connect('hr.db', timeout=10) c = conn_db.cursor()
- Tabela para armazenar alterações no status do trabalho
Por conveniência, salvaremos o histórico da alteração do status da vaga (disponibilidade por data) em uma tabela especial do banco de dados SQLite. Graças à tabela vacancy_history, estaremos cientes da disponibilidade de vagas no site em qualquer data do upload, ou seja, em que datas ela estava ativa.
c.execute(''' create table if not exists vacancy_history ( id_vacancy integer, date_load text, date_from text, date_to text )''')
- Filtragem de vagas
Há uma restrição de que uma solicitação não pode retornar mais de 2000 coleções e, como pode haver muito mais vagas publicadas no site em um dia, colocaremos um filtro no corpo da solicitação, por exemplo: vagas apenas em São Petersburgo (área = 2) , por especialização em TI (especialização = 1)
path = ("/vacancies?area=2&specialization=1&page={}&per_page={}&date_from={}&date_to={}".format(page, per_page, date_from, date_to))
- Condições de seleção adicionais
O mercado de trabalho está crescendo rapidamente e, mesmo levando em consideração o filtro, o número de vagas pode exceder 2000, portanto, definiremos um limite adicional na forma de um lançamento separado para cada dia: vagas na primeira metade do dia e vagas na segunda metade do dia
def get_vacancy_history(): ... count_days = 30 hours = 0 while count_days >= 0: while hours < 24: date_from = (cur_date.replace(hour=hours, minute=0, second=0) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') date_to = (cur_date.replace(hour=hours + 11, minute=59, second=59) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') while count == per_page: path = ("/vacancies?area=2&specialization=1&page={} &per_page={}&date_from={}&date_to={}" .format(page, per_page, date_from, date_to)) conn.request("GET", path, headers=headers) response = conn.getresponse() vacancies = response.read() conn.close() count = len(json.loads(vacancies)['items']) ...
Primeiro caso de usoSuponha que tenhamos a tarefa de identificar vagas que foram fechadas por um determinado intervalo de tempo, por exemplo, para julho de 2018. Isso é resolvido da seguinte maneira: o resultado de uma consulta SQL simples para a tabela vacancy_history retornará os dados que precisamos, que podem ser passados para o DataFrame para análises adicionais:
c.execute(""" select a.id_vacancy, date(a.date_load) as date_last_load, date(a.date_from) as date_publish, ifnull(a.date_next, date(a.date_load, '+1 day')) as date_close from ( select vh1.id_vacancy, vh1.date_load, vh1.date_from, min(vh2.date_load) as date_next from vacancy_history vh1 left join vacancy_history vh2 on vh1.id_vacancy = vh2.id_vacancy and vh1.date_load < vh2.date_load where date(vh1.date_load) between :date_in and :date_out group by vh1.id_vacancy, vh1.date_load, vh1.date_from ) as a where a.date_next is null """, {"date_in" : date_in, "date_out" : date_out}) date_in = dt.datetime(2018, 7, 1) date_out = dt.datetime(2018, 7, 31) closed_vacancies = get_closed_by_period(date_in, date_out) df = pd.DataFrame(closed_vacancies, columns = ['id_vacancy', 'date_last_load', 'date_publish', 'date_close']) df.head()
Nós obtemos o resultado deste tipo:
Se quisermos analisar usando ferramentas do Excel ou ferramentas de BI de terceiros, podemos fazer upload da tabela vacancy_history em um arquivo csv para análise posterior:
Artilharia pesada
Mas e se precisarmos fazer uma análise de dados mais complexa? Aqui, o banco de dados NoSQL orientado a documentos do
MongoDB é resgatado, o que permite armazenar dados no formato JSON.
As ações acima mencionadas para a coleta de vagas são lançadas diariamente, portanto, não é necessário visualizar todas as vagas a cada vez e receber informações detalhadas sobre cada uma delas. Aceitaremos apenas os que foram recebidos nos últimos cinco dias.
- Obtendo uma matriz de vagas nos últimos 5 dias em um banco de dados SQLite:
def get_list_of_vacancies_sql(): conn_db = sqlite3.connect('hr.db', timeout=10) conn_db.row_factory = lambda cursor, row: row[0] c = conn_db.cursor() items = c.execute(""" select distinct id_vacancy from vacancy_history where date(date_load) >= date('now', '-5 day') """).fetchall() conn_db.close() return items
- Obtendo uma variedade de tarefas nos últimos cinco dias do MongoDB:
def get_list_of_vacancies_nosql(): date_load = (dt.datetime.now() - td(days=5)).strftime('%Y-%m-%d') vacancies_from_mongo = [] for item in VacancyMongo.find({"date_load" : {"$gte" : date_load}}, {"id" : 1, "_id" : 0}): vacancies_from_mongo.append(int(item['id'])) return vacancies_from_mongo
- Resta encontrar a diferença entre as duas matrizes, para as vagas que não estão no MongoDB, obtenha informações detalhadas e grave-as no banco de dados:
sql_list = get_list_of_vacancies_sql() mongo_list = get_list_of_vacancies_nosql() vac_for_pro = [] s = set(mongo_list) vac_for_pro = [x for x in sql_list if x not in s] vac_id_chunks = [vac_for_pro[x: x + 500] for x in range(0, len(vac_for_pro), 500)]
- Portanto, temos uma matriz com novas vagas que ainda não estão disponíveis no MongoDB. Para cada uma delas, receberemos informações detalhadas usando uma solicitação na API HH. Antes de processá-las diretamente no MongoDB, processaremos cada documento:
- Trazemos a quantidade de salários para o equivalente ao rublo;
- Adicione uma graduação de nível de especialista a cada vaga (Junior / Middle / Senior etc)
Tudo isso é implementado na função vacancies_processing:
from nltk.stem.snowball import SnowballStemmer stemmer = SnowballStemmer("russian") def vacancies_processing(vacancies_list): cur_date = dt.datetime.now().strftime('%Y-%m-%d') for vacancy_id in vacancies_list: conn = http.client.HTTPSConnection("api.hh.ru") conn.request("GET", "/vacancies/{}".format(vacancy_id), headers=headers) response = conn.getresponse() if response.status != 404: vacancy_txt = response.read() conn.close() vacancy = json.loads(vacancy_txt)
- Obtendo informações detalhadas acessando a API HH, pré-processamento recebido
O MongoDB realiza os dados e os insere em vários fluxos, com 500 vagas em cada um:
t_num = 1 threads = [] for vac_id_chunk in vac_id_chunks: print('starting', t_num) t_num = t_num + 1 t = threading.Thread(target=vacancies_processing, kwargs={'vacancies_list': vac_id_chunk}) threads.append(t) t.start() for t in threads: t.join()
A coleção preenchida no MongoDB é mais ou menos assim:
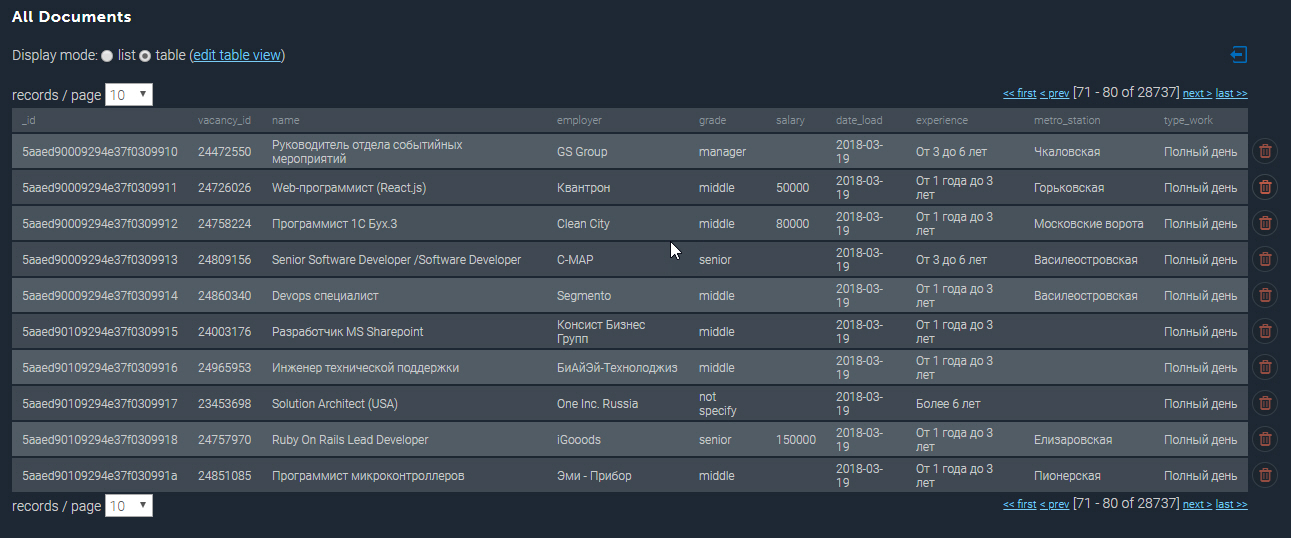
Mais alguns exemplos
Tendo o banco de dados coletado à nossa disposição, podemos executar várias amostras analíticas. Então, mostrarei as 10 vagas mais bem pagas de desenvolvedores de Python em São Petersburgo:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[pP]ython*"}}) df_mongo = pd.DataFrame(list(cursor_mongo)) del df_mongo['_id'] pd.concat([df_mongo.drop(['employer'], axis=1), df_mongo['employer'].apply(pd.Series)['name']], axis=1)[['grade', 'name', 'salary_processed' ]].sort_values('salary_processed', ascending=False)[:10]
Os 10 trabalhos mais bem pagos de Python| nota | nome | nome | salário_processo |
|---|
| sénior | Arquiteto / Líder da equipe da Web (Python / Django / React) | Investex ltd | 293901.0 |
| sénior | Desenvolvedor Python sênior no Montenegro | Betmaster | 277141.0 |
| sénior | Desenvolvedor Python sênior no Montenegro | Betmaster | 275289.0 |
| meio | Desenvolvedor Web de back-end (Python) | Soshace | 250000,0 |
| meio | Desenvolvedor Web de back-end (Python) | Soshace | 250000,0 |
| sénior | Engenheiro Python líder para uma startup suíça | Assaia International AG | 250000,0 |
| meio | Desenvolvedor Web de back-end (Python) | Soshace | 250000,0 |
| meio | Desenvolvedor Web de back-end (Python) | Soshace | 250000,0 |
| sénior | Equipe Python | Digitalhr | 230000.0 |
| sénior | Desenvolvedor Líder (Python, PHP, Javascript) | IK GROUP | 220231.0 |
Agora vamos descobrir qual estação de metrô tem a maior concentração de postagens vagas para desenvolvedores Java. Usando uma expressão regular, filtrei pelo título da tarefa "Java" e também selecionei apenas as tarefas em que o endereço está especificado:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[jJ]ava[^sS]"}, "address" : {"$ne" : None}}) df_mongo = pd.DataFrame(list(cursor_mongo)) df_mongo['metro'] = df_mongo.apply(lambda x: x['address']['metro']['station_name'] if x['address']['metro'] is not None else None, axis = 1) df_mongo.groupby('metro')['_id'] \ .count() \ .reset_index(name='count') \ .sort_values(['count'], ascending=False) \ [:10]
Empregos para desenvolvedores Java em estações de metrô| metro | contar |
|---|
| Vasileostrovskaya | 87 |
| Petrogradskaya | 68 |
| Vyborg | 46. |
| Praça Lenin | 45 |
| Gorkovskaya | 45 |
| Chkalovskaya | 43 |
| Narva | 32. |
| Praça da Revolta | 29 |
| Vila Velha | 29 |
| Elizarovskaya | 27 |
Sumário
Portanto, os recursos analíticos do sistema desenvolvido são realmente amplos e podem ser usados para planejar uma startup ou abrir uma nova direção de atividade.
Observo que, até o momento, apenas a funcionalidade básica do sistema é apresentada; no futuro, ele está planejado para se desenvolver na direção da análise por coordenadas geográficas e prever a aparência de vagas em uma área específica da cidade.
O código fonte completo deste artigo pode ser encontrado no link para o meu
GitHub .
PS Os comentários ao artigo são bem-vindos, terei prazer em responder a todas as suas perguntas e descobrir sua opinião. Obrigada