Uma característica importante das tarefas de aprendizado de máquina é que resultados igualmente bons podem ser alcançados usando métodos diferentes. Isso empolga os concursos de ML: mesmo tendo outras competências além de um oponente obviamente forte, você ainda pode vencer. As equipes de Tensorborne e Neurobotics tiveram chances quase iguais de ganhar o hackathon DeepHack e, eventualmente, ocuparam os dois primeiros lugares. No
treinamento da
Yandex, representantes de ambas as equipes fizeram um relatório volumoso. Na decodificação, você encontrará análises detalhadas de soluções e dicas para os concorrentes iniciantes.
E, claro, tire férias de hackathon. Quando você participa de um hackathon semanal e também trabalha ao mesmo tempo, é ruim. Você chega às 19h, depois de trabalhar um pouco, senta e compila o Docker com o TensorFlow, Keras, para que tudo isso comece em alguns servidores remotos aos quais você nem sequer tem acesso. Em algum lugar em duas noites, você pega a catarse e funciona para você - sem o Docker, sem tudo, porque você entendeu que é possível e assim.
Vitaly Davydov:
- Olá pessoal! Deveríamos ter dois relatórios, mas decidimos combiná-los em um grande, porque estamos falando do primeiro e do segundo lugar na competição DeepHack. Nós representamos duas equipes. Nossa equipe de Tensorborne ficou em 2º lugar, e a equipe de Gregory Neurobotics - a primeira.

O relatório consistirá em três partes principais. Na introdução, falarei sobre a história do DeepHack, o que é, quais eram as métricas, etc. Em seguida, os caras falarão sobre soluções, sobre quais problemas, exemplos etc.
Antes de falar sobre o DeepHack, deve-se notar que é um pequeno subconjunto de outra grande competição global ConvAI2, que lançou o Facebook no ano passado. Este ano é a segunda iteração. Em algum momento, o Facebook patrocinou o Instituto de Física e Tecnologia de Moscou, e o concurso DeepHack foi criado com base no laboratório PhysTech.

Leia mais sobre o próprio ConvAI. Que problema ele está tentando resolver? Ele é especialista em sistemas interativos. O problema com os sistemas de diálogo é que não existe uma única ferramenta de avaliação, uma ferramenta de avaliação, para entender a qualidade dos diálogos. Isso é muito subjetivo de pessoa para pessoa: alguém pode gostar da conversa, alguém não. A tarefa global geral do ConvAI é criar uma métrica unificada comum para avaliar diálogos, que ainda não está disponível. Prêmio - US $ 20.000 para o AWS Mechanical Turk. Estes não são empréstimos para a Amazon, são apenas empréstimos para o Mechanical Turk, que na verdade é um análogo do Yandex.Tolki. Este é um serviço de crowdsourcing que permite fazer marcações nos dados.
A tarefa, criada no ConvAI, é criar um chit-chat-bot com o qual você possa fazer algum tipo de diálogo. Eles escolheram três métricas: Perplexidade, Hits @ 1 e F1. A seguir, mostrarei a tabela que estava no momento da nossa submissão.
A avaliação pela qual eles tentaram fazer isso passou por três etapas. O primeiro estágio são as métricas automáticas, a avaliação do AWS Mechanical Turk e o bate-papo ao vivo com voluntários.
Como o ConvAI é patrocinado pelo Facebook, ele está promovendo ativamente sua biblioteca para a criação de sistemas de conversação do ParlAI. É bastante complicado, mas acho que todos os participantes usaram esta biblioteca. Nós lidamos com isso por um bom tempo, não é compatível com o Python 3.6, por exemplo, e há vários problemas com ele.
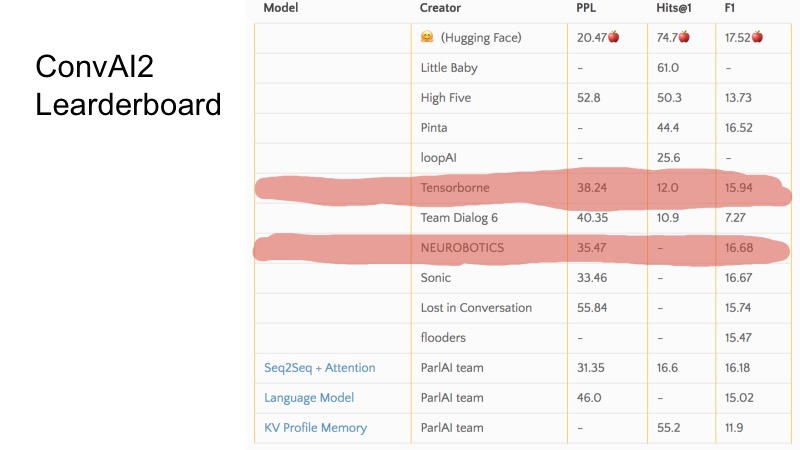
Nestas poucas linhas, você pode ver quais posições ocupamos no momento da submissão. Em geral, o ConvAI é estranhamente organizado no sentido de que existem três métricas e não está muito claro como está indo a classificação nesta tabela. Pode-se observar que, para algumas métricas, algumas equipes são mais altas, para outras mais baixas. A organização de todo o ConvAI foi um pouco estranha.
Mas existem três linhas de base básicas. Para se qualificar para o DeepHack, foi necessário quebrar essa linha de base, e as 10 melhores equipes chegaram à final. Em segredo, direi que apenas 8 equipes enviaram decisões e todos chegaram à final. Não foi muito difícil.

A tarefa do DeepHack era um pouco mais compreensível e direta. Tivemos que construir novamente um robô falador, mas que simularia uma certa personalidade. Ou seja, o robô recebeu uma descrição de uma pessoa na entrada e, durante uma conversa com ele, ele teve que revelar. O prêmio foi bastante interessante - uma viagem ao NIPS neste outono, que é totalmente patrocinada.
A métrica, diferente da ConvAI, já era diferente. Havia duas métricas e a métrica total é ponderada entre as duas. A primeira métrica é a qualidade geral, uma avaliação de como o bot respondeu adequadamente, o quão interessante foi se comunicar com ele, se estava escrevendo algum lixo etc. A segunda métrica é a interpretação de papéis, 0 ou 1. Isso significa O bot entrou na descrição que lhe foi dada. A pessoa que se comunica com o bot não vê a descrição. A avaliação ocorreu no Telegram, ou seja, havia um único bot de Telegram e, quando o usuário começou a se comunicar com ele, ele recebeu um bot aleatório de todas as inscrições, para ser honesto. Yandex e MIPT, aparentemente, despejaram um pouco de tráfego lá, e havia cerca de 10 mil diálogos, pelo que me lembro.
Eu já falei sobre a rodada de qualificação. A final foi em tempo integral. Ocorreu durante sete dias de trabalho no Instituto de Física e Tecnologia de Moscou, um aglomerado foi fornecido, um local, onde nos sentamos e trabalhamos lá. A avaliação era de fato todos os dias, e a pontuação final, a classificação do bot no final, era calculada dessa maneira. A competição começou na segunda-feira, a primeira finalização foi na terça-feira e a avaliação ocorreu no dia seguinte. A solução que você postou na terça-feira foi avaliada na quarta-feira com um peso de 1,5. O que você enviou na quarta-feira - com um peso de 1,4 etc.

Sobre o conjunto de dados que o Facebook forneceu para treinamento. Chama-se Persona-Chat e é uma descrição de duas personalidades e um conjunto de diálogos. Há uma descrição da primeira pessoa e da segunda. No processo de descrever o diálogo, eles tentam se revelar. Isso é tudo o que foi dado. No entanto, como sempre, na competição não era proibido o uso de outros conjuntos de dados de terceiros.
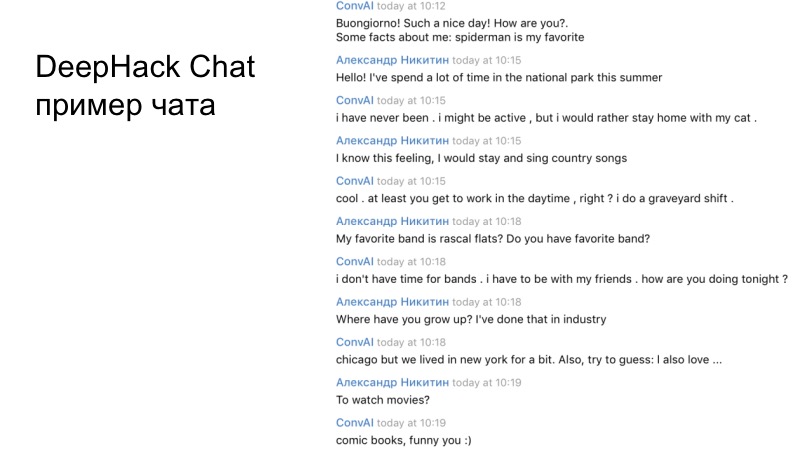
Um exemplo do diálogo da nossa equipe. Se você ler com atenção, fica claro que o bot resultante funciona adequadamente e responde corretamente.
Gregory vai falar sobre o primeiro lugar.
Grigory Rashkov:
- Gostaria de falar sobre nossa experiência em participar da competição, nossa estratégia e nossa decisão.

Em primeiro lugar, a peculiaridade da competição é que é uma longa duração, não tivemos dois dias, como em um hackathon comum, mas cinco dias, pelos quais poderíamos tomar muitas decisões.

Avaliações muito subjetivas, porque pessoas completamente diferentes com seus critérios avaliaram, em particular, o organizador do hackathon Mikhail Bubtsev disse que se ele adivinhava qual perfil estava falando, mas o bot em algum momento contradiz seu perfil, ele respondeu à pergunta não tão , como está escrito, ele escolheu um perfil diferente, mesmo que soubesse do que se tratava.
E o terceiro é a falta de validação. Os participantes não puderam fazer uma pequena alteração e receber feedback imediatamente.
Como em todos os filmes de terror, nossa equipe desde o início decidiu se separar. O primeiro grupo participou da nossa solução principal, com base no Wasserstein GAN, o segundo grupo participou do bot, o painel de administração do bot com base na linha de base. Porque tivemos que enviar algo no primeiro e no segundo dia.

Brevemente sobre a linha de base: Seq2Seq mais atenção, que é ligeiramente adaptada para esta tarefa específica. Como exatamente? Uma frase é enviada para a entrada, a incorporação é obtida do GloVe, mas a apresentação de cada frase como uma incorporação ponderada é considerada ainda mais. Os pesos são selecionados com base na frequência inversa da palavra. Quanto mais raramente uma palavra aparece, mais peso ela traz.

Isso é necessário para refletir a singularidade dessas características. Tudo estava indo para um conjunto, uma matriz, uma máscara foi construída com base nesse conjunto e um estado oculto, em seguida, essa máscara foi sobreposta ao conjunto, um contexto foi obtido e, em seguida, foi conectado, por não linearidade, foi alimentado à entrada dos decodificadores.

No primeiro dia, ainda não escrevemos nossa decisão, tivemos que enviar alguma coisa, por isso escrevemos um agente com base na linha de base, mas nos propusemos a tarefa de, de alguma forma, nos destacar da massa cinzenta de agentes. Para fazer isso, usamos heurísticas simples, nosso bot foi o primeiro a iniciar um diálogo e ele sorriu nessa frase. E funcionou.
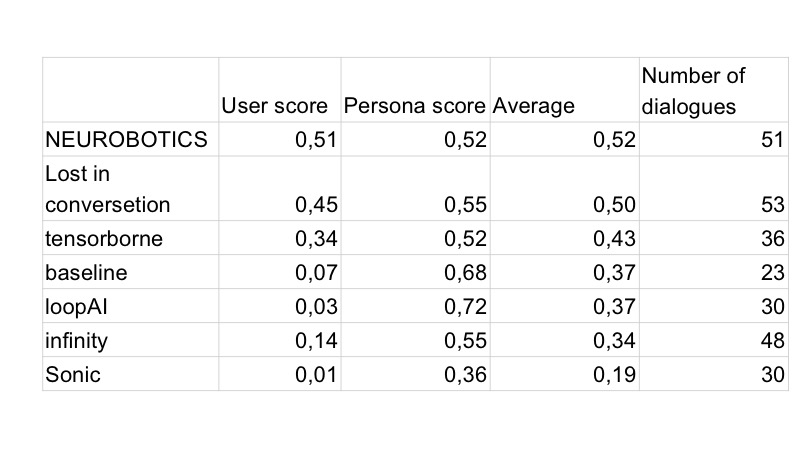
Naturalmente, no dia seguinte, todos os bots começaram a ser feitos primeiro e todos tinham emoticons. No segundo dia, os moradores de Vilabaggio continuaram trabalhando com o GAN, os moradores de Vilaribo tentaram outras heurísticas.
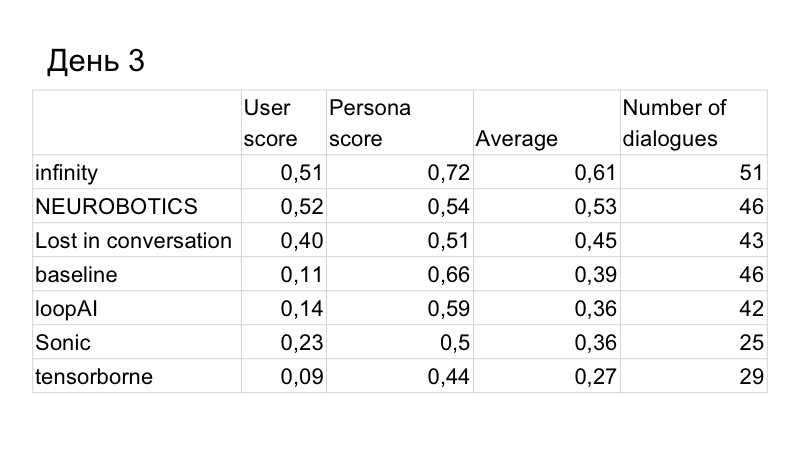
Como resultado, a pontuação na qualidade do diálogo melhorou um pouco, mas fomos superados pela pessoa. Estes são os resultados do terceiro dia, restavam apenas dois dias. Entendemos que não haveria tempo suficiente para escrevermos um GAN e testá-lo normalmente, porque ele estuda há muito tempo, muito, temos que selecionar muitos hiperparâmetros. Então, decidimos mudar para a linha de base, porque funciona muito bem.

Nossa tarefa era melhorar o reconhecimento do perfil do usuário. Propusemos uma heurística. Qual foi o problema? O usuário conversou alegremente com o bot, perguntando que tipo de trabalho ele tinha, hobbies, que tipo de carro ele dirigia, o bot respondeu tudo isso bem, porque o bot geralmente respondia bem. Como resultado, no final do diálogo, o usuário viu dois perfis que nada tinham a ver com o que estava no diálogo, simplesmente porque outras coisas foram indicadas lá além daquelas que o usuário solicitou. Portanto, decidimos que era necessário fornecer de alguma forma informações do perfil.
Como fazer isso da maneira mais lógica? Se uma pessoa tem algum interesse, provavelmente ele falará sobre ela, procure interesses em comum. Portanto, decidimos que o bot em alguns momentos fará perguntas com base em seu perfil. Houve um efeito interessante de que o gerador, que foi escrito simplesmente de acordo com as regras lingüísticas de G, usa algum fato A do perfil, como resultado, G (A) é inserido no diálogo, tudo isso é enviado para a memória do bot e, na próxima vez em que o modelo gerar informações, procedendo tanto do perfil quanto desse diálogo, ou seja, com maior probabilidade ele dirá algo relacionado ao perfil.
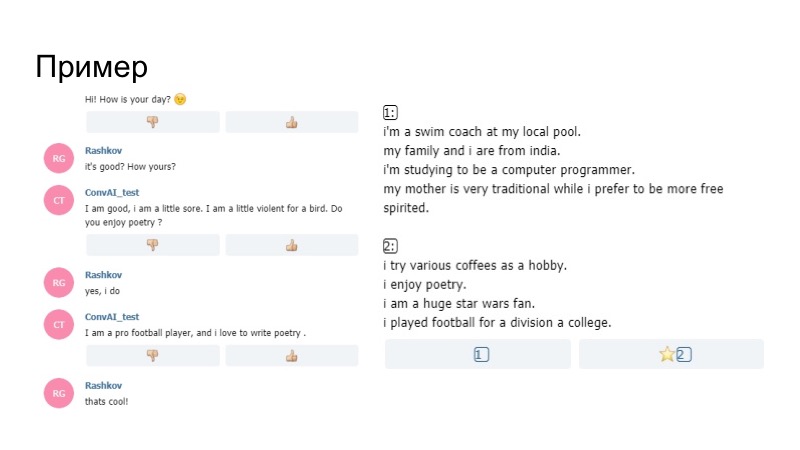
Como era na realidade? O bot no perfil diz que está encantado com a poesia, e durante a conversa ele pergunta se eu gosto de poesia. Eu digo que sim, e mais adiante no modelo dele, não no gerador que construímos de acordo com as regras, diz que ele gosta de escrever poesia. Assim, o bot focou em seu perfil e funcionou.

Voltamos ao primeiro lugar novamente. O último dia permaneceu. Percebemos que, no entanto, estamos perdendo como um diálogo.

Aproveitamos várias outras soluções. Primeiro, eles usaram a paráfrase, analisaram o que as outras pessoas disseram, porque os organizadores criaram esse banco de dados e perceberam que muitas pessoas se comunicam com o bot não está totalmente correto.
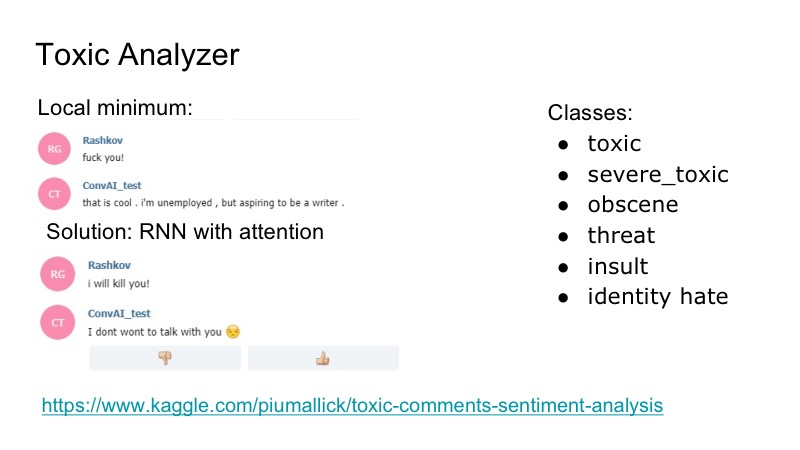
Existe um mínimo local interessante no bot: ele responde muito bem a qualquer insulto, ele concorda com eles e, para consertar isso, decidimos usar a competição Kaggle para analisador de comentários tóxicos, escrevemos um classificador muito simples, também com atenção na RNN. Nesse conjunto de dados, havia as seguintes classes, sobrepostas: insultos, ameaças ... Decidimos não estudar o modelo separadamente, quem irá falar, porque esse problema foi encontrado, mas não foi muito frequente. Portanto, acabamos de escrever algum tipo de piada que o bot respondeu e todos ficaram felizes.

Além disso, usamos a paráfrase para enriquecer o discurso do nosso bot. Isso também não foi muito difícil, substituímos as palavras da frase por sinônimos, examinamos os n-gramas resultantes na frase, para que não diferissem muito daqueles que eram originalmente e, em seguida, escolhemos a combinação mais adequada para a frase com maior probabilidade.
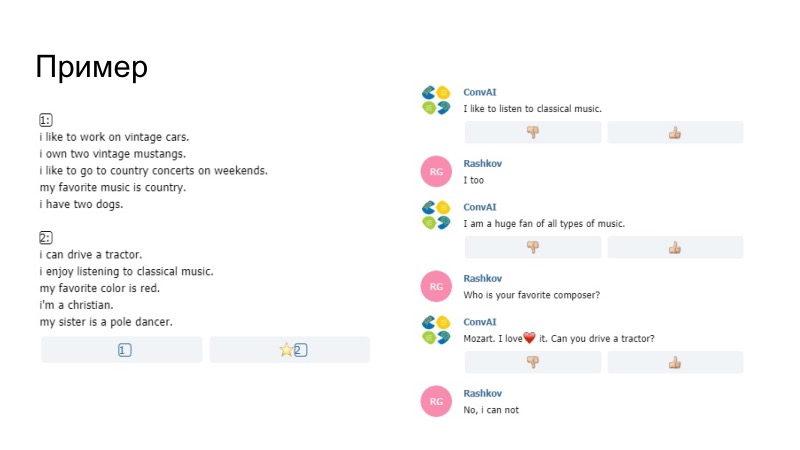
Como exemplo do que aconteceu, o bot aqui diz que gosta de ouvir música, diz curtir no perfil, foi substituído por gostar conosco. Não temos certeza se o modelo em si ou o nosso Paraphraser o geraram, mas isso passou. Outra observação de que era impossível enviar apenas dados do perfil. Pentagramas foram comparados lá. Se os pentagramas coincidiram com sua observação e seu perfil, simplesmente essa frase não passou, os organizadores a organizaram. Além disso, entre outras coisas, adicionamos um dicionário de smiley.

O segundo exemplo, temos muitos sorrisos. Havia heurísticas, quando o bot reagiu ao seu comportamento que você não escreveu por muito tempo. Parafraseador também trabalhou aqui, e deu um bom resultado.

A qualidade do diálogo foi a melhor, a qualidade de desempenhar o papel também.
Tentamos fazer o modelo gerar um conjunto de opções e as comparamos com o perfil. Mas me pareceu que, nesse caso, o bot funciona pior, não poderíamos realizar a validação, apenas avaliações subjetivas em duas ou três conversas. Portanto, eles decidiram não colocar isso, porque o perfil já era bem reconhecido.
Em seguida, escrevemos uma solução para o problema inverso, o segundo modelo, que selecionou o perfil desejado no diálogo. Planejamos usá-lo inicialmente para treinamento, a fim de ler a função de perda e distribuí-la ainda mais na grade. Mas isso poderia piorar o falador, então eles decidiram não colocar dessa maneira. Também pensamos em usar isso para o comportamento do bot, mas não tivemos tempo para testar tudo e decidimos recusar. Além disso, decidimos colocar emoticons com base na coloração emocional da frase, escrevemos um modelo, mas não encontramos um conjunto de dados adequado, e os que foram usados não são um pouco sobre isso.

Nossa equipe
Mesmo que seu modelo principal, que você espera, não consiga escrevê-lo ou dê um resultado ruim, não desista imediatamente, você precisa tentar algumas coisas mais simples, o que é bastante natural. E a segunda coisa, às vezes vale a pena observar o que falta ao seu modelo e pensar em tarefas específicas, decompô-las e resolver áreas problemáticas específicas, o que fizemos. Obrigado pela atenção.
Sergey Kolesnikov:
- Meu nome é Sergey Kolesnikov, representarei a decisão de Tensorborne.

Criamos um nome bonito, fomos ao concurso, criamos várias peças diferentes para lançar dois artigos depois disso, mas não vencemos o hackathon. Portanto, será chamado: "Como não ganhar o hackathon, mas ainda publicar os malditos dois artigos". Acadêmicos, senhor.
As características da competição em que participamos excederam nossa motivação. Devido ao fato de a avaliação ser realizada diariamente, os pacotes também precisavam ser feitos diariamente, e a recompensa final era determinada, como gostamos na RL, pelo somatório descontado. Tudo isso se transformou no fato de que tivemos que enviar pelo menos algo todos os dias para que funcionasse, e obtivemos pelo menos algum tipo de pontuação. Como resultado, ele realmente cresceu para o que você quer - você não quer, mas teve que remar.
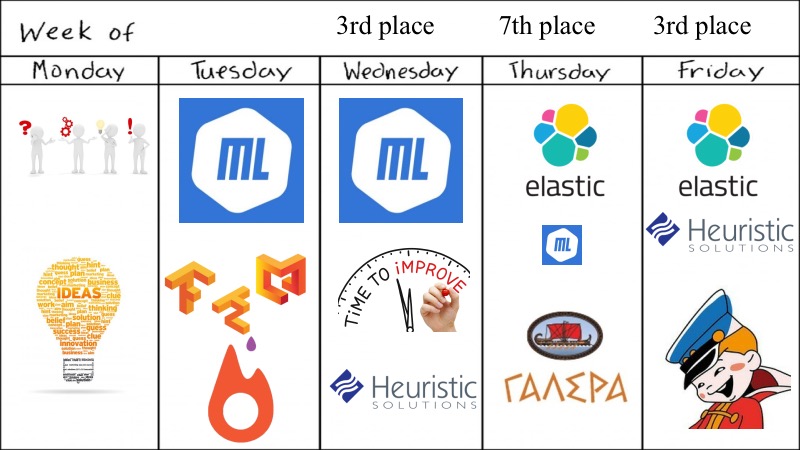
O que nós tínhamos? Visualização para toda a semana.
Apesar do hackathon dizer que ele era semanal, tudo foi decidido em quatro dias, o que parece não ser suficiente para esta tarefa ConvAI.
Inicialmente, éramos cinco de nós, todos bons graduados acadêmicos, ou seja, Fiztekh. Então, na segunda-feira, viemos apresentar muitas sugestões, idéias que você pode tentar e quais modelos de aprendizado profundo tentar. É verdade que não experimentamos o GAN, porque já o experimentamos para textos e isso não funciona, por isso tomamos algo mais simples, além disso, havia competições muito semelhantes e tínhamos modelos pré-treinados. Na terça-feira, conseguimos lançar algo sobre aprendizado profundo, ML sempre que possível, lançamos dockers maravilhosos com suporte a GPU e outras coisas para o Tensorflow e Keras, precisamos dar uma medalha separada por isso, já que isso não é tão trivial como eu gostaria.
De acordo com os resultados de terça-feira, eles foram promissores e decidimos melhorar levemente nosso ML com pequenas heurísticas e similares, e falhámos em sétimo lugar. Mas, graças aos nossos colegas de equipe, alguém encontrou o ElasticSearch e o experimentou. Houve um momento muito embaraçoso em que o ElasticSearch funcionou bem, e os modelos DL e ML, e assim por diante, eram um pouco menos robustos. O fim do concurso estava próximo. E, como observado pelo orador anterior, decidimos remar na direção que funciona. Adotamos o ElasticSearch, pequenas heurísticas e achamos isso bom o suficiente, e realmente bom o suficiente, porque ficamos em segundo lugar.
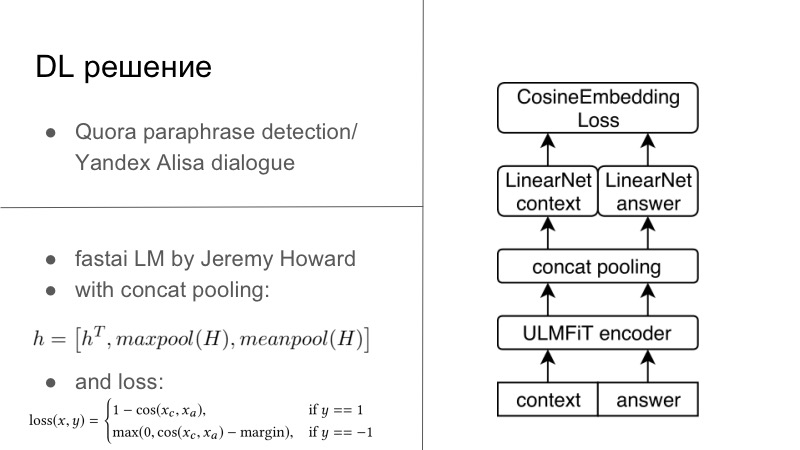
Mais detalhes. Na verdade, havia várias soluções de DL. A primeira solução de DL foi bastante simples. Quem se lembra, no ano anterior ao último ou no ano passado, houve um concurso de detecção de paráfrase do Quora, e este ano houve um concurso do Yandex para Alice para criar diálogos e muito mais. Você pode perceber que as tarefas são muito próximas. No primeiro, era necessário dizer se essas duas frases eram paráfrases e, no segundo, era necessário continuar o diálogo. Pensamos que, uma vez que estamos desenvolvendo sistemas de diálogo, vamos também continuar bem o diálogo. E funcionou perfeitamente, o diálogo com o Quora foi muito pessoal.
Basicamente, tudo parecia ter algum codificador, geralmente todos treinamos em nossas RNNs habituais e, de preferência, LSTM com atenção e outras coisas.
E então usamos normalmente a perda de incorporação de cosaína, apresentada abaixo no slide, ou outra perda de incorporação do tipo Tripler Loss ou qualquer outra coisa que incorpora paráfrase ou respostas a um diálogo específico reúne, e não atrasos de paráfrase, e assim por diante. Esta foi a primeira solução, foi no Tensorflow, Keras, estava pronta, tentamos e foi muito boa.. , DL ML , , , FastAI. PyTorch, PyTorch, . , , , LSTM FastAI, , , SOTA .
PyTorch, - FastAI, , , PyTorch, . , , , . answer, . FastAI, Universal Language Model — — Encoder.
, , , 1 , seq2seq. . , , FastAI — Concat poolling. ? seq2seq, attention. maxpool minpool , , .
, , , , maxpool minpool, . , — H, Hc Ha. , feedforward , . , , , , metric learning. — CosineEmbedding Loss, PyTorch.
, loss . , contrastive loss, , . , .
DL-. ElasticSearch, .
? , - ElasticSearch . - - Persona Dataset , , Facebook, , , - . - . , , , , , Persona Dataset , Amazon Mechanical Turk , .
ElasticSearch, , . , Persona Dataset , , 10 . , . , , , , .
- . , Persona , , , , , evaluation. heuristic solutions.
, , , , . . , , , , , . .
— . , — -, -, , .
dirty hack. , , . . — , .

? , -DL- , DL, . , , , . . , -, , , . , , . . , , . DL , ElasticSearch .
, personality score. , -, 0,25–0,3 , . , , - .

. — , , , Docker ElasticSearch, . , . . . Also, try to guess… , — , funny you. , general, . , , .
, , . . , — , , . , Docker, .

? ConvAI , NIPS, - .
-, ElasticSearch . , , . , , ElasticSearch . , DL.
-, DL-. : , , , . , , , , .
, . , . , . — pre-trained- ( — . .), . .
, proposals , RL bandits . , . — . , . , , , , toxic- . .
— . , DeepHacks . NLP, DeepHack , , « ». , . . , , , , , .
— . distributed- , . , DeepHack. - . . , , , , .
! . pre-trained-. , , .
E, claro, tire férias de hackathon. Quando você participa de um hackathon semanal e também trabalha ao mesmo tempo, é ruim. Você chega às 19h, depois de trabalhar um pouco, senta e compila o Docker com o TensorFlow, Keras, para que tudo isso comece em alguns servidores remotos aos quais você nem sequer tem acesso. Em algum lugar em duas noites, você pega a catarse e funciona para você - sem o Docker, sem tudo, porque você entendeu que é possível e assim.Parece que se você participar de uma grande competição, reserve um pouco mais de tempo do que não consegue dormir em uma semana e participe. Vá e ganhe. Obrigada