Na apresentação do NVIDIA SIGGRAPH 2018, o CEO da empresa, Jensen Juan, revelou oficialmente a tão aguardada arquitetura de GPU Turing (e rumores e especulações). A próxima geração de GPUs NVIDIA, Turing, incluirá vários novos recursos e visitará o mundo ainda este ano. Embora a visualização profissional (ProViz) tenha sido o foco dos anúncios de hoje, esperamos que a nova arquitetura seja usada em outros produtos NVIDIA futuros. A análise de hoje não é apenas uma lista de todos os recursos de Turing.

Renderização híbrida e redes neurais: núcleos RT e tensor
Então, o que há de tão especial e novo na arquitetura de Turing? O letreiro, pelo menos para a comunidade NVIDIA ProViz, foi projetado para renderização híbrida, que combina o traçado de raios com a rasterização tradicional.

Mudança importante: a NVIDIA incluiu ainda mais equipamentos de rastreamento de raios em Turing para oferecer o rastreamento de raios acelerado por hardware mais rápido. A novidade da arquitetura Turing é a unidade de computação RT Core especializada, como a NVIDIA a chama, atualmente não há informações suficientes sobre ela, sabe-se apenas que sua função é o suporte ao traçado de raios. Essas unidades de processador aceleram a verificação da interseção de raios e triângulos, bem como manipulam BVH (hierarquias de volumes delimitadores).
A NVIDIA alega que os componentes Turing mais rápidos podem contar com 10 bilhões de raios (Giga) por segundo, o que representa uma melhoria de 25 vezes no desempenho do rastreamento de raios em comparação com o Pascal não acelerado.
A arquitetura de Turing inclui núcleos tensoriais Volta que foram reforçados. Núcleos tensores são um aspecto importante de várias iniciativas da NVIDIA. Juntamente com a aceleração do rastreamento de raios, uma ferramenta importante na “bolsa mágica” da NVIDIA é reduzir o número de raios necessários na cena usando a redução de ruído de AI para limpar a imagem. Aqui os núcleos dos tensores se saem melhor. Obviamente, essa não é a única área em que são boas - todas as redes neurais e impérios de IA da NVIDIA são construídos sobre elas.
Turing é caracterizado pelo suporte a uma faixa mais ampla de precisão, o que significa a possibilidade de aceleração significativa em cargas de trabalho que não possuem requisitos de alta precisão. Além do modo de precisão Volta FP16, os núcleos tensores de Turing suportam INT8 e até INT4. Isso é 2 e 4 vezes mais rápido que o FP16, respectivamente. Embora a NVIDIA não queira entrar em detalhes na apresentação, sugiro que eles implementem algo semelhante ao empacotamento de dados, usado para operações de baixa precisão nos núcleos CUDA. Apesar da precisão reduzida da rede neural (o retorno é reduzido - de acordo com o INT4, obtemos apenas 16 (!) Valores) - existem alguns modelos que realmente precisam desse baixo nível de precisão. Como resultado, os modos de precisão reduzida mostrarão uma boa taxa de transferência, especialmente nas tarefas de saída, o que sem dúvida agradará alguns usuários.
Voltando à renderização híbrida em geral, é interessante que, apesar dessas grandes acelerações individuais, a promessa geral da NVIDIA de ganhos de desempenho pareça um pouco mais modesta. Embora a empresa prometa aumentar a produtividade em 6 vezes em comparação com Pascal, é hora de perguntar quais peças são aceleradas e em comparação com quais. O tempo dirá.
Enquanto isso, para fazer melhor uso dos núcleos tensores fora do traçado de raios e das tarefas de aprendizado profundo com foco restrito, a NVIDIA implementará um SDK, NVIDIA NGX, que integrará redes neurais ao processamento de imagens. A NVIDIA espera o uso de redes neurais e núcleos tensores para processamento adicional de imagem e vídeo, incluindo métodos como o próximo Deep-Anti-Aliasing (DLAA).
Turing SM: núcleos INT dedicados, cache único, sombreamento de taxa variável
Juntamente com os kernels RT e tensor, a própria arquitetura Turing Streaming Multiprocessor (SM) introduz novos truques. Em particular, uma das alterações mais recentes de Volta foi herdada, como resultado dos núcleos de número inteiro alocados em seus próprios blocos e não fazem parte dos núcleos de ponto flutuante da CUDA. A vantagem é a geração mais rápida de endereços e o desempenho do Fused Multiply Add (FMA).
Quanto à ALU (ainda estou aguardando a confirmação de Turing) - suporte para operações mais rápidas com baixa precisão (por exemplo, FP16 rápido). Em Volta, isso é implementado como operações do FP16 em dupla frequência em relação ao FP32, e operações INT8 em velocidade 4x. Os kernels tensores já suportam esse conceito; portanto, seria lógico transferi-lo para os kernels CUDA.
O FP16 rápido, a tecnologia Rapid Packed Math e outras maneiras de agrupar várias pequenas operações em uma grande operação são todos os principais componentes para melhorar o desempenho da GPU no momento em que a Lei de Moore está diminuindo.
Usando tipos de dados grandes (exatos) somente quando necessário, eles podem ser empacotados juntos para realizar mais trabalhos no mesmo período. Isso é importante principalmente para a saída de redes neurais, bem como para o desenvolvimento de jogos. O fato é que nem todos os programas de sombreador precisam da precisão do FP32, e a redução da precisão pode melhorar o desempenho e reduzir a largura de banda da memória útil e o uso do arquivo de registro.
O Turing SM inclui algo que a NVIDIA chama de “arquitetura de cache unificado”. Como ainda estou esperando diagramas SMID oficiais da NVIDIA, não está claro se essa é a mesma unificação que vimos em Volta - onde o cache L1 foi combinado com memória compartilhada - ou a NVIDIA deu um passo adiante. De qualquer forma, a NVIDIA alega que agora ofereceu o dobro da largura de banda em relação à "geração anterior", mas não está claro se significa "Pascal" ou "Volta" (a última é mais provável).
Finalmente, profundamente oculto no comunicado à imprensa de Turing, foi mencionada a possibilidade de suporte a sombreamento de taxa variável. Essa é uma tecnologia de renderização gráfica relativamente nova e em evolução, sobre a qual há pouca informação (especialmente sobre como exatamente ela é implementada pela NVIDIA). Mas, em um nível muito alto de abstração, soa como “a tecnologia de próxima geração da NVIDIA que permite aplicar sombreamento com diferentes resoluções, o que permite aos desenvolvedores exibir diferentes áreas da tela em diferentes resoluções efetivas para concentrar a qualidade (e o tempo de renderização) nas áreas onde é mais necessário” .
Feed the Beast: Suporte para GDDR6
Como a memória usada pelas GPUs é desenvolvida por empresas de terceiros, não há segredos. A JEDEC e sua grande Samsung, SK Hynix e Micron, com três membros, estão desenvolvendo a memória GDDR6 como sucessora de GDDR5 e GDDR5X. A NVIDIA confirmou que Turing o apoiará. Dependendo do fabricante, a GDDR6 de primeira geração é anunciada como tendo uma largura de banda de memória de até 16 Gb / s por barramento, que é o dobro das placas NVIDIA GDDR5 de última geração e 40% mais rápida que as placas NVIDIA GDDR5X mais recentes.
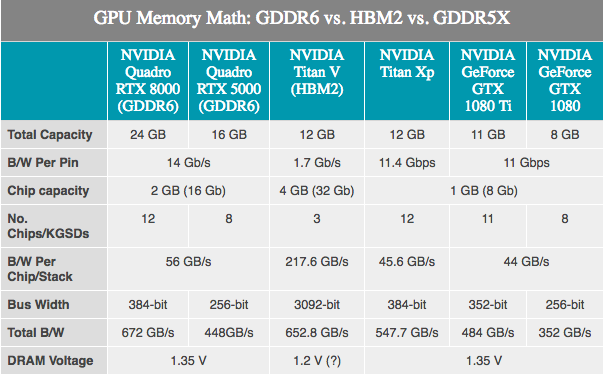
Comparado ao GDDR5X, o GDDR6 não parece um grande avanço, pois muitas das inovações do GDDR6 já foram aplicadas ao GDDR5X. As mudanças fundamentais aqui incluem tensões operacionais mais baixas (1,35 v) e a memória interna agora está dividida: dois canais de memória por microcircuito. Para um chip de 32 bits padrão - dois canais de memória de 16 bits, no total, temos 16 desses canais em um cartão de 256 bits. Embora isso, por sua vez, diga que há um número muito grande de canais, as GPUs obterão o máximo benefício da inovação, porque historicamente são os dispositivos mais "paralelos".

A NVIDIA, por sua vez, confirmou que as primeiras placas Turing Quadro usarão GDDR6 a 14 Gb / s. Ao mesmo tempo, a NVIDIA também confirmou o uso da memória da Samsung, especialmente para seus avançados dispositivos de 16 gigabytes. Isso é importante porque significa que uma GPU NVIDIA típica de 256 bits pode ser equipada com 8 módulos padrão e obter 16 GB de capacidade total de memória, ou até 32 GB se usar o modo clamshell (permite endereçar 32 GB de memória em 256 bits padrão ônibus).
Todos os tipos de detalhes: NVLink, VirtualLink e 8K HEVC
Já terminando com uma revisão da arquitetura Turing, a NVIDIA confirmou casualmente o suporte para alguns dos novos recursos externos de E / S. O suporte ao NVLink estará presente em pelo menos vários produtos da Turing. Lembre-se de que a NVIDIA a utiliza nas três novas placas Quadro. A NVIDIA oferece uma configuração de GPU bidirecional.
Um ponto importante (antes que uma parte do nosso público-alvo dos jogos seja aprofundada na leitura): a presença do NVLink no equipamento de Turing não significa que ele será usado nas placas de vídeo do consumidor. Talvez tudo se limite apenas aos cartões Quadro e Tesla.
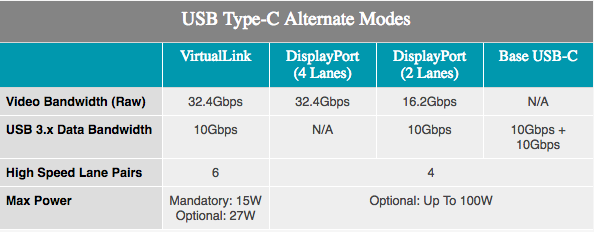
Com a adição do suporte do VirtualLink, os jogadores e usuários do ProViz terão o que esperar da VR. Um modo alternativo USB Type-C foi anunciado no mês passado e suporta transferência de dados de 15 W + potência e 10 Gb / s, graças às bandas USB 3.1 Gen 2 e 4 DisplayPort HBR3 em um cabo. Em outras palavras, esta é uma conexão DisplayPort 1.4 com dados e energia adicionais. Isso permite que a placa de vídeo controle diretamente o fone de ouvido VR. O padrão é suportado pela NVIDIA, AMD, Oculus, Valve e Microsoft, portanto, os produtos Turing serão os primeiros de um número de produtos que suportarão o novo padrão.
Embora a NVIDIA mal tenha abordado o assunto, sabemos que a unidade codificadora de vídeo NVENC foi atualizada em Turing. A mais recente iteração NVENC adiciona suporte especial à codificação HEKC 8K. Enquanto isso, a NVIDIA conseguiu melhorar a qualidade do seu codificador, permitindo obter a mesma qualidade de antes, com uma taxa de bits de vídeo 25% menor.
Indicadores de desempenho
Juntamente com as especificações de hardware anunciadas, a NVIDIA mostra vários números do desempenho do equipamento Turing. Note-se que aqui sabemos muito, muito pouco. Aparentemente, os componentes são baseados nos SKUs de Turing total e parcialmente incluídos, com 4608 núcleos CUDA e 576 núcleos tensores. As frequências não foram divulgadas, no entanto, como esses números são perfilados para o hardware Quadro, é provável que vejamos velocidades de clock mais baixas do que em qualquer equipamento de consumo.

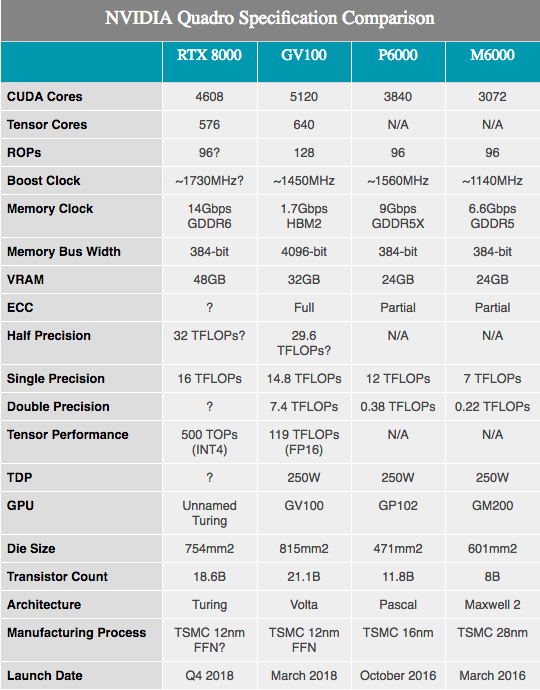
Juntamente com os 10GigaRays / s acima mencionados para núcleos RT, o desempenho dos núcleos de tensores NVIDIA é de 500 trilhões de operações de tensores por segundo (500T TOPs). Para referência, a NVIDIA frequentemente menciona a GPU GV100 como capaz de fornecer no máximo 120T TOP, mas isso não é a mesma coisa. Em particular, enquanto o GV100 é mencionado no processamento de operações do FP16, o desempenho de Turing é citado com uma precisão extremamente baixa INT4, que é apenas um quarto do tamanho do FP16 e, portanto, aumenta a taxa de transferência quatro vezes. Se normalizarmos a precisão, os núcleos de tensores de Turing parecem não ter a melhor taxa de transferência por núcleo, mas oferecem mais opções de precisão do que Volta. De qualquer forma, 576 núcleos tensor neste chip o equiparam quase ao mesmo nível do GV100, que possui 640 núcleos.
Em relação aos núcleos CUDA, a NVIDIA alega que a GPU Turing pode oferecer desempenho de 16 TFLOPS. Isso está um pouco à frente dos 15 TFLOPS de desempenho com a precisão única do Tesla V100, ou ainda mais à frente dos 13,8 TFLOPS do Titan V. Se você está procurando informações mais amigáveis ao consumidor, isso é cerca de 32% mais que o Titan Xp. Depois de esboçar alguns cálculos aproximados no papel, podemos assumir a velocidade do clock da GPU de cerca de 1730 MHz, já que no nível SM não houve alterações adicionais que alterariam as fórmulas tradicionais de desempenho da ALU.
Enquanto isso, a NVIDIA anunciou que as placas Quadro virão com memória GDDR6 operando a 14 Gb / s. E observando as duas melhores SKUs Quadro que oferecem 48 GB e 24 GB GDDR6, respectivamente, quase vemos o barramento de memória de 384 bits nesta GPU Turing. Por números, isso equivale a 672 GB / s de largura de banda de memória para os dois cartões Quadro topo de linha.
Caso contrário, com uma mudança na arquitetura, é difícil fazer muitas comparações úteis de desempenho, especialmente ao comparar com o Pascal. Pelo que vimos com Volta, o desempenho geral da NVIDIA melhorou, especialmente em cargas de trabalho de computação bem projetadas. Assim, uma melhoria de aproximadamente 33% no desempenho do papel em comparação com o Quadro P6000 pode muito bem ser algo muito maior.
Vou mencionar o tamanho do cristal da nova GPU. Localizado em 754 mm2, não é apenas grande, é enorme. Comparado a outras GPUs, apenas o NVIDIA GV100 é o segundo em tamanho, que atualmente permanece o carro-chefe da NVIDIA. Mas com 18,6 bilhões de transistores, é fácil ver por que o chip resultante deve ser tão grande. Aparentemente, a NVIDIA tem grandes planos para esta GPU, que no final será capaz de justificar a presença de dois grandes processadores gráficos em sua pilha de produtos.
A NVIDIA, por sua vez, não indicou um número de modelo específico para esta GPU - seja uma GPU tradicional da classe 102 ou mesmo da classe 100. Gostaria de saber se veremos uma modificação desse tipo de GPU para um produto de consumo de uma forma ou de outra; é tão grande que a NVIDIA pode querer mantê-lo por suas GPUs Quadro e Tesla mais lucrativas.
Lançado no quarto trimestre de 2018, se não antes
Concluindo, direi que, juntamente com o anúncio da arquitetura Turing, a NVIDIA anunciou que as 4 primeiras placas Quadro baseadas em GPUs Turing - Quadro RTX 8000, RTX 6000 e RTX 5000 começarão a ser distribuídas no quarto trimestre deste ano. Como a própria natureza deste anúncio é um pouco invertida - geralmente a NVIDIA anuncia os componentes do consumidor pela primeira vez - eu não aplicaria a mesma linha do tempo aos cartões do consumidor que não possuem requisitos de validação tão rigorosos. Veremos o equipamento de Turing no quarto trimestre deste ano, se não antes. Quem quiser comprar a Quadro pode começar a economizar agora: o melhor dos novos cartões Quadro RTX 8000 custará cerca de US $ 10.000.
Finalmente, para os consumidores com o Tesla da NVIDIA, o lançamento do Turing deixa Volta no limbo. A NVIDIA não nos disse se Turing acabaria se expandindo para o espaço de ponta de Tesla - substituindo o GV100 - ou se seu melhor processador Volta continuaria sendo o mestre de seu domínio por séculos. No entanto, como os outros cartões da Tesla até agora foram baseados em Pascal, eles são os primeiros candidatos a Turing em 2019.
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD de 1Gbps até dezembro de graça quando pagar por um período de seis meses, você pode fazer o pedido
aqui .
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?