A introdução da IA no nível do chip permite processar mais dados localmente, porque um aumento no número de dispositivos não causa mais o mesmo efeito
Os fabricantes de chips estão trabalhando em novas arquiteturas que aumentam significativamente a quantidade de dados processados por watt e ciclo. O terreno está preparado para uma das maiores revoluções na arquitetura de chips nas últimas décadas.
Todos os principais fabricantes de chips e sistemas estão mudando a direção do desenvolvimento. Eles entraram na corrida das arquiteturas, que prevê uma mudança de paradigma em tudo: dos métodos de leitura e gravação à memória, ao processamento e, finalmente, ao layout de vários elementos em um chip. Embora a miniaturização continue, ninguém está apostando no dimensionamento para lidar com o crescimento explosivo de dados de sensores e aumentar o volume de tráfego entre máquinas.
Entre as mudanças nas novas arquiteturas:
- Novos métodos para processar uma quantidade maior de dados em 1 ciclo de clock, às vezes com menos precisão ou com prioridade de determinadas operações, dependendo da aplicação.
- Novas arquiteturas de memória que alteram a maneira como armazenamos, lemos, escrevemos e acessamos dados.
- Módulos de processamento mais especializados, localizados em todo o sistema, perto da memória. Em vez de um processador central, os aceleradores são selecionados dependendo do tipo de dados e aplicativo.
- No campo da IA, está em andamento o trabalho para combinar vários tipos de dados na forma de modelos, o que aumenta efetivamente a densidade dos dados e minimiza discrepâncias entre os diferentes tipos.
- Agora, o layout do gabinete é o principal componente da arquitetura, com mais e mais atenção sendo prestada à facilidade de alterar esses projetos.
"Existem várias tendências que afetam os avanços tecnológicos", disse Stephen Wu, um distinto engenheiro da Rambus. - Nos data centers, você aproveita ao máximo o hardware e o software. Sob esse ângulo, os proprietários do data center estão olhando para a economia. Introduzir algo novo é caro. Mas os gargalos estão mudando, então chips especializados estão sendo introduzidos para uma computação mais eficiente. E se você reduzir os fluxos de dados para a E / S e a memória, isso poderá ter um grande impacto. ”
As mudanças são mais óbvias na borda da infraestrutura de computação, ou seja, entre os sensores finais. De repente, os fabricantes perceberam que dezenas de bilhões de dispositivos gerariam muitos dados: esse volume não poderia ser enviado à nuvem para processamento. Mas o processamento de todos esses dados no limite apresenta outros problemas: exige grandes melhorias de desempenho sem um aumento significativo no consumo de energia.
"Há uma nova tendência para menor precisão", disse Robert Ober, arquiteto líder de plataforma da Tesla na Nvidia. - Estes não são apenas ciclos computacionais. É um empacotamento de dados mais intensivo na memória, onde o formato das instruções de 16 bits é usado. ”
Aubert acredita que, graças a uma série de otimizações arquiteturais no futuro próximo, você pode dobrar a velocidade de processamento a cada dois anos. "Veremos um aumento dramático na produtividade", disse ele. - Para isso, você precisa fazer três coisas. O primeiro é a computação. O segundo é a memória. A terceira área é a largura de banda do host e a largura de banda de E / S. Muito trabalho precisa ser feito para otimizar o armazenamento e a pilha de rede. ”
Algo já está sendo implementado. Em uma apresentação na conferência Hot Chips de 2018, Jeff Rupley, arquiteto-chefe do Austin Research Center da Samsung, apontou várias mudanças importantes na arquitetura do processador M3. Um inclui mais instruções por batida - seis em vez de quatro no último chip M2. Além disso, a previsão de ramificação em redes neurais foi implementada e a fila de instruções foi duplicada.
Tais mudanças mudam o ponto de inovação da fabricação direta de microcircuitos para a arquitetura e o design, por um lado, e para o layout dos elementos do outro lado da cadeia de produção. Embora as inovações continuem sendo continuadas nos processos tecnológicos, é apenas às custas disso que é incrivelmente difícil alcançar um aumento de 15 a 20% na produtividade e potência em cada novo modelo de chip - e isso não é suficiente para lidar com o rápido crescimento no volume de dados.
"As mudanças estão ocorrendo a uma taxa exponencial", disse Victor Pan, presidente e CEO da Xilinx, em um discurso na conferência Hot Chips, "10 zettabytes [10
21 bytes] de dados serão gerados a cada ano, e a maioria é desestruturada".
Novas abordagens para a memória
Trabalhar com tantos dados requer repensar cada componente do sistema, desde os métodos de processamento de dados até o armazenamento.
"Houve muitas tentativas de criar novas arquiteturas de memória", disse Carlos Machin, diretor sênior de inovação da eSilicon EMEA. - O problema é que você precisa ler todas as linhas e selecionar um bit em cada uma. Uma opção é criar uma memória que possa ser lida da esquerda para a direita, bem como para cima e para baixo. Você pode ir ainda mais longe e adicionar computação à memória. ”
Essas mudanças incluem a alteração dos métodos de leitura da memória, a localização e o tipo de elementos de processamento, bem como a introdução da IA para priorizar o armazenamento, o processamento e a movimentação de dados em todo o sistema.
“E se, no caso de dados esparsos, pudermos ler apenas um byte dessa matriz por vez - ou talvez oito bytes consecutivos do mesmo caminho, sem desperdiçar energia em outros bytes ou caminhos de bytes nos quais não estamos interessados? ? "Pergunta a Mark Greenberg, diretor de marketing de produtos da Cadence." - No futuro, isso é possível. Se você observar a arquitetura do HBM2, por exemplo, a pilha será organizada em 16 canais virtuais de 64 bits cada, e você precisará obter apenas 4 palavras consecutivas de 64 bits para acessar qualquer canal virtual. Assim, é possível criar matrizes de dados com uma largura de 1024 bits, escrever horizontalmente, mas ler verticalmente quatro palavras de 64 bits por vez. "
A memória é um dos principais componentes da arquitetura de von Neumann, mas agora também se tornou uma das principais arenas para experimentos. "O principal inimigo são os sistemas de memória virtual, onde os dados são movidos de maneiras menos naturais", disse Dan Bouvier, arquiteto-chefe de produtos para clientes da AMD. - Esta é uma transmissão de transmissão. Estamos acostumados a isso no campo dos gráficos. Mas se resolvermos os conflitos no banco de memória DRAM, obteremos um fluxo muito mais eficiente. Em seguida, uma GPU separada pode usar DRAM na faixa de 90% de eficiência, o que é muito bom. Mas se você configurar o streaming sem interrupções, a CPU e a APU também cairão na faixa de eficiência de 80% a 85%. ”
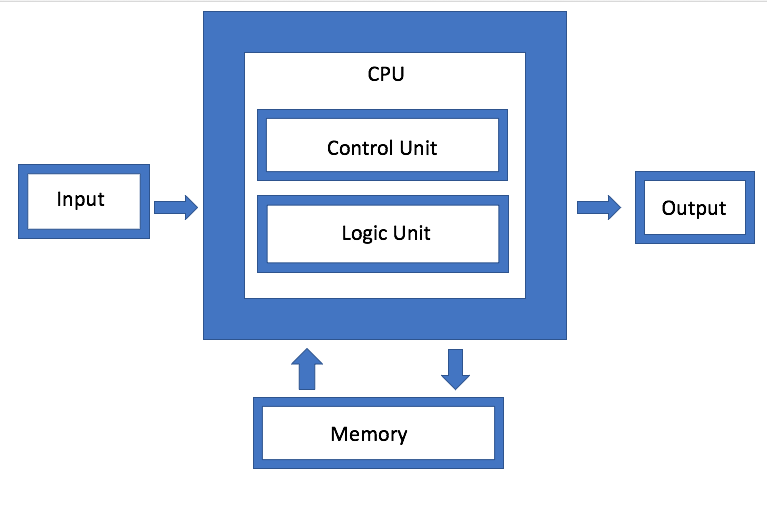 Fig. 1. Arquitetura von Neumann. Fonte: Engenharia de Semicondutores
Fig. 1. Arquitetura von Neumann. Fonte: Engenharia de SemicondutoresA IBM está desenvolvendo um tipo diferente de arquitetura de memória, que é essencialmente uma versão atualizada da agregação de disco. O objetivo é que, em vez de usar uma única unidade, o sistema possa usar arbitrariamente qualquer memória disponível por meio de um conector, que Jeff Stucheli, arquiteto de hardware da IBM, chama de "canivete suíço" para conectar elementos. A vantagem da abordagem é que ela permite misturar e combinar diferentes tipos de dados.
"O processador está se transformando no centro de uma interface de sinalização de alto desempenho", diz Stucelli. "Se você alterar a microarquitetura, o núcleo realiza mais operações por ciclo na mesma frequência."
Conectividade e taxa de transferência devem garantir o processamento de um volume radicalmente aumentado de dados gerados. "Os principais gargalos estão agora nos locais de movimentação de dados", disse Wu, da Rambus. "A indústria fez um ótimo trabalho aumentando a velocidade da computação". Mas se você espera dados ou modelos de dados especializados, precisa executar a memória mais rapidamente. Portanto, se você observar DRAM e NVM, o desempenho depende do padrão de tráfego. Se os dados estiverem fluindo, a memória fornecerá um desempenho muito bom. Mas se os dados chegarem aleatoriamente, será menos eficiente. E não importa o que você faça, com um aumento no volume, você ainda precisará fazê-lo mais rapidamente. ”
Mais computação, menos tráfego.
O problema é agravado pelo fato de que existem vários tipos diferentes de dados gerados em diferentes frequências e velocidades por dispositivos na borda. Para que esses dados se movam livremente entre diferentes módulos de processamento, o gerenciamento deve se tornar muito mais eficiente do que no passado.
"Existem quatro configurações principais: muitos para muitos, subsistemas de memória, E / S de baixa potência e topologias de grades e anéis", diz Charlie Janak, presidente e CEO da Arteris IP. - Você pode colocar todos os quatro em um chip, o que acontece com os principais chips IoT. Ou você pode adicionar subsistemas HBM de alto rendimento. Mas a complexidade é enorme, porque algumas dessas cargas de trabalho são muito específicas e o chip possui várias tarefas de trabalho diferentes. Se você olhar para alguns desses microchips, eles obtêm grandes quantidades de dados. Isso ocorre em sistemas como radares de automóveis e lidares. Eles não podem existir sem algumas interconexões avançadas. ”
A tarefa é como minimizar a movimentação de dados, mas ao mesmo tempo maximizar o fluxo de dados quando necessário - e de alguma forma encontrar um equilíbrio entre o processamento local e o centralizado, sem aumentar desnecessariamente o consumo de energia.
"Por um lado, esse é um problema de largura de banda", disse Rajesh Ramanujam, gerente de marketing de produtos da NetSpeed Systems. - Você deseja reduzir o tráfego o máximo possível, portanto transfira os dados para mais perto do processador. Mas se você ainda precisar mover os dados, é recomendável compactá-los o máximo possível. Mas nada existe por si só. Tudo precisa ser planejado a partir do nível do sistema. Em cada etapa, vários eixos interdependentes devem ser considerados. Eles determinam se você usa a memória da maneira tradicional de ler e escrever ou se utiliza novas tecnologias. Em alguns casos, pode ser necessário alterar a maneira como você armazena os dados. Se você precisar de um desempenho mais alto, isso geralmente significa um aumento na área do chip, o que afeta a dissipação de calor. E agora, considerando a segurança funcional, a sobrecarga de dados não pode ser permitida. ”
É por isso que tanta atenção é dada ao processamento de dados na borda e na largura de banda do canal por vários módulos de processamento de dados. Mas, à medida que você desenvolve arquiteturas diferentes, é muito diferente como e onde esse processamento de dados é implementado.
Por exemplo, a Marvell introduziu um controlador SSD com IA incorporada para lidar com a pesada carga de computação no limite. O mecanismo de IA pode ser usado para análises dentro da unidade SSD.
"Você pode carregar modelos diretamente no hardware e processar o hardware no controlador SSD", disse Ned Varnitsa, engenheiro-chefe da Marvell. - Hoje faz o servidor na nuvem (host). Mas se cada disco enviar dados para a nuvem, isso criará uma enorme quantidade de tráfego de rede. É melhor fazer o processamento no limite, e o host emite apenas um comando, que são apenas metadados. Quanto mais unidades você tiver, mais poder de processamento. Este é um grande benefício da redução de tráfego. ”
Essa abordagem é particularmente interessante porque se adapta a dados diferentes, dependendo da aplicação. Portanto, o host pode gerar uma tarefa e enviá-la ao dispositivo de armazenamento para processamento, após o qual apenas os resultados de metadados ou cálculos são enviados de volta. Em outro cenário, um dispositivo de armazenamento pode armazenar dados, pré-processá-los e gerar metadados, tags e índices, que são recuperados pelo host conforme necessário para análises adicionais.
Essa é uma das opções possíveis. Tem outros O Rupli da Samsung enfatizou a importância de processar e mesclar idiomas que podem decodificar duas instruções e combiná-las em uma única operação.
A IA lida com controle e otimização
Em todos os níveis de otimização, a Inteligência Artificial é usada - este é um dos elementos verdadeiramente novos na arquitetura de chips. Em vez de permitir que o sistema operacional e o middleware gerenciem funções, essa função de monitoramento é distribuída pelo chip, entre os chips e no nível do sistema. Em alguns casos, redes neurais de hardware são introduzidas.
"O objetivo não é tanto empacotar mais juntos, mas mudar a arquitetura tradicional", diz Mike Gianfanya, vice-presidente de marketing da eSilicon. - Com a ajuda da IA e do aprendizado de máquina, você pode distribuir elementos pelo sistema, obtendo um processamento mais eficiente com a previsão. Ou você pode usar chips separados que funcionam independentemente no sistema ou no módulo. ”
A ARM desenvolveu seu primeiro chip de aprendizado de máquina, que planeja lançar ainda este ano para vários mercados. "Este é um novo tipo de processador", disse Ian Bratt, Engenheiro Homenageado da ARM. - Inclui um bloco fundamental - é um mecanismo de computação, bem como um mecanismo MAC, um mecanismo DMA com um módulo de controle e uma rede de transmissão. No total, existem 16 núcleos de computação fabricados usando a tecnologia de processo de 7 nm, que produz 4 TeraOps a uma frequência de 1 GHz. ”
Como o ARM trabalha com um ecossistema de parceiros, seu chip é mais versátil e personalizável do que outros chips de AI / ML que estão sendo desenvolvidos. Em vez de uma estrutura monolítica, ela separa o processamento por função, para que cada módulo de computação funcione em um mapa de recursos separado. Bratt identificou quatro ingredientes principais: planejamento estático, dobragem eficiente, mecanismos de estreitamento e adaptação programada para futuras mudanças no projeto.
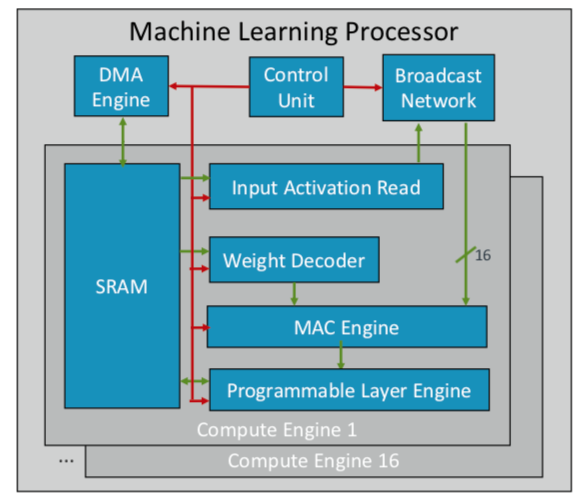 Fig. 2. Arquitetura ML do processador ARM. Fonte: ARM / Hot Chips
Fig. 2. Arquitetura ML do processador ARM. Fonte: ARM / Hot ChipsEnquanto isso, a Nvidia escolheu uma tática diferente: criar um mecanismo de aprendizado profundo dedicado ao lado da GPU para otimizar o processamento de imagem e vídeo.
Conclusão
Usando algumas ou todas essas abordagens, os fabricantes de chips esperam dobrar o desempenho a cada dois anos, acompanhando o crescimento explosivo dos dados, mantendo-se dentro da estrutura rígida dos orçamentos de energia. Mas isso não é apenas mais computação. Essa é uma mudança na plataforma de design de chips e sistemas, quando o crescente volume de dados, em vez de limitações de hardware e software, se torna o principal fator.
"Quando os computadores apareceram nas empresas, parecia para muitos que o mundo ao nosso redor havia se acelerado", disse Aart de Gues, presidente e CEO da Synopsys. - Eles faziam contabilidade em pedaços de papel com pilhas de livros. O livro se transformou em uma pilha de cartões perfurados para impressão e computação. Uma tremenda mudança ocorreu e a vemos novamente. Com o advento de computadores de computação simples mentalmente, o algoritmo de ações não mudou: você pode rastrear todas as etapas. Mas agora está acontecendo outra coisa que pode levar a uma nova aceleração. É como em um campo agrícola incluir a rega e aplicar um certo tipo de fertilizante apenas em um determinado dia, quando a temperatura atingir o nível desejado. Esse uso do aprendizado de máquina é uma otimização que não era óbvia no passado. ”
Ele não está sozinho nesta avaliação. "As novas arquiteturas serão adotadas", disse Wally Raines, presidente e CEO da Mentor, Siemens Business. - Eles serão projetados. O aprendizado de máquina será usado em muitos ou na maioria dos casos, porque seu cérebro aprende com sua própria experiência. Visitei 20 ou mais empresas que desenvolvem processadores de IA especializados de um tipo ou outro, e cada uma delas tem seu próprio nicho. Mas você verá cada vez mais sua aplicação em aplicações específicas, e elas complementarão a arquitetura tradicional de von Neumann. A computação neuromórfica se tornará popular. Este é um grande passo na eficiência da computação e redução de custos. Dispositivos móveis e sensores começarão a fazer o trabalho que os servidores fazem hoje. ”