Alguns anos atrás, os sistemas de recomendação estavam começando a conquistar seus consumidores. As lojas online estão ativamente usando algoritmos de recomendação, oferecendo a seus clientes mais e mais novos produtos com base em seu histórico de compras.
No atendimento ao cliente, os sistemas de recomendação se tornaram relevantes não faz muito tempo. Devido ao aumento no conteúdo oferecido, os clientes começaram a se perder no fluxo de informações sobre o que, onde e quando precisam ver. Operadoras de TV paga e cinemas on-line sofreram dores de cabeça dos amantes de conteúdo de vídeo.

Como uma maneira eficaz de resolver o eterno problema de "o que ver?" surgiram sistemas de recomendação que funcionam com base em um modelo matemático específico.
Há dois anos, introduzimos um sistema de recomendação, posteriormente o complementamos com seleções editoriais e sentimos um efeito notável nas vendas e na duração do uso de nosso serviço.
O que são sistemas de recomendação
Um sistema de recomendação é quando você deseja ver algo, mas não sabe exatamente o que é, e a TV adivinha com muito sucesso suas preferências. Essa é uma filtragem de conteúdo que seleciona filmes e programas de TV com base nas preferências e na análise do comportamento do usuário. O sistema usado pelo operador deve prever a reação do espectador a um elemento específico e oferecer o conteúdo que ele desejar.
Ao programar sistemas de recomendação, três métodos principais são usados: filtragem colaborativa, filtragem baseada em conteúdo e sistemas especialistas (sistemas baseados em conhecimento).
A filtragem colaborativa é baseada em três estágios: coleta de informações do usuário, construção de uma matriz para o cálculo de associações e emissão de recomendações confiáveis.
Um bom exemplo de filtragem colaborativa é o Cinematch, usado pela Netflix. Os usuários dão explícita ou implicitamente classificações aos filmes assistidos, e as recomendações são formadas levando em consideração as classificações dos usuários e as de outros espectadores. Para fazer isso, o sistema seleciona usuários com preferências semelhantes, cujas classificações são próximas às suas. Com base na opinião deste círculo de pessoas, o espectador recebe automaticamente a recomendação: assistir a um filme em particular.
Para a máxima operação correta do sistema de recomendação, os dados acumulados e coletados desempenham um papel fundamental. Quanto mais dados forem acumulados sobre o perfil de consumo de um assinante específico, mais recomendações são emitidas com mais precisão.
O sistema de recomendação de conteúdo é formulado com base nos atributos atribuídos a cada elemento. Se você assistir a filmes de um determinado gênero, o sistema oferecerá automaticamente conteúdo próximo ao seu gênero em determinadas posições. É com base nesse sistema de recomendação que o site da Pandora funciona.
Os sistemas especialistas de recomendação oferecem recomendações não baseadas em classificações, mas com base em semelhanças entre os requisitos do usuário e as descrições do produto, ou dependendo das restrições definidas pelo usuário ao especificar o produto desejado. Portanto, esse tipo de sistema é único, pois permite ao cliente indicar explicitamente o que ele deseja.
Os sistemas especialistas são mais eficazes em contextos em que a quantidade de dados disponíveis é limitada e a filtragem colaborativa funciona melhor em ambientes onde existem grandes quantidades de dados. Mas quando os dados são diversificados, é possível resolver o mesmo problema por métodos diferentes. Isso significa que ele combinará de maneira ideal as recomendações recebidas de várias maneiras, melhorando assim a qualidade do sistema como um todo.
É um sistema híbrido da E-Contenta que funciona em nosso serviço de
TV WiFire . Foi colocado em operação e depurado em dezembro de 2016 e funciona de acordo com o seguinte princípio: se o sistema sabe muito sobre o usuário ou sobre o conteúdo, prevalecem os algoritmos de filtragem colaborativa. Se o conteúdo for novo ou forem coletadas informações suficientes sobre a interação dos usuários com ele, os algoritmos de conteúdo serão usados para avaliar a similaridade do conteúdo com base nos metadados existentes.
Como os algoritmos de recomendações foram criados
Para criar uma seleção personalizada no E-Contenta, era necessário classificar todo o conteúdo disponível pela probabilidade de um usuário específico estar interessado nesse conteúdo.
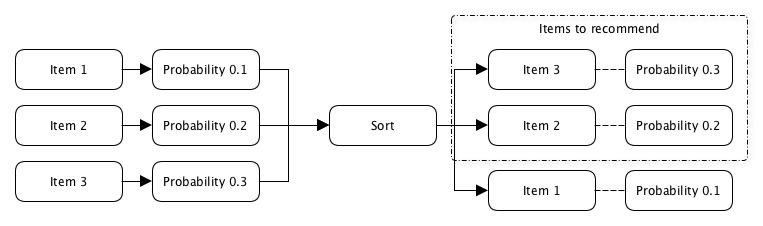
O interesse do usuário é determinado principalmente no momento em que ele clica no conteúdo recomendado para ele, e a probabilidade é determinada como a razão entre o número de cliques e o número de vezes que esse conteúdo foi recomendado para esse usuário.
p (clique) = N cliques / N exibeA dificuldade está no fato de que você precisa recomendar ao usuário algo que ele nunca viu, o que significa que simplesmente não há dados sobre o número de cliques ou impressões para calcular essa probabilidade.
Portanto, em vez da probabilidade real, decidiu-se usar uma estimativa dessa probabilidade, ou seja, o valor previsto.
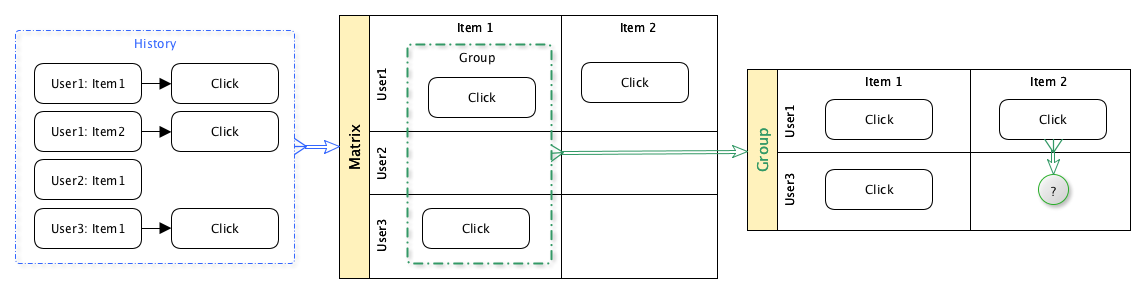
A ideia de um filtro colaborativo é simples:
- Obtenha dados históricos sobre usuários que visualizam conteúdo
- Com base nesses dados, agrupe os usuários pelo conteúdo que visualizaram
- Para um determinado usuário prever a probabilidade de seu interesse em uma determinada unidade de conteúdo, com base em dados históricos de outros usuários no mesmo grupo.
Assim, os usuários participam em conjunto no processo de seleção de conteúdo.
Existem muitas opções diferentes para implementar essa abordagem:
1. Crie um modelo usando diretamente os identificadores de unidades de conteúdo:
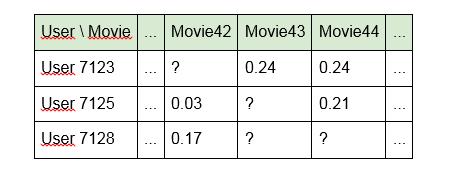
A desvantagem dessa abordagem é que o modelo "não vê" nenhum link entre as unidades de conteúdo. Por exemplo, "Terminator" e "Terminator 2" para ela estarão tão distantes um do outro quanto "Alien" e "Good night, Kids!". Além disso, a própria matriz acaba sendo muito escassa (muitas células vazias e um pouco cheias).
2. Em vez de identificadores, use as palavras incluídas no título dos artigos, programas ou filmes:
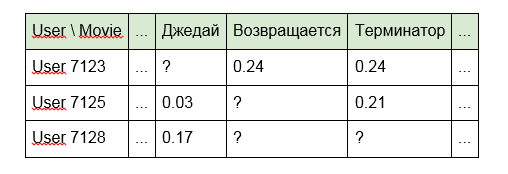
3. Para filmes, nomes de atores, diretores ou dados da IMDb:
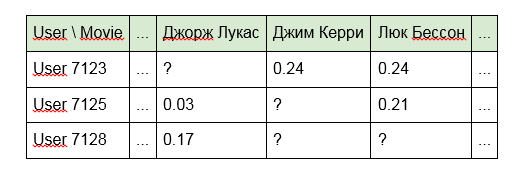
A segunda e terceira opções eliminam parcialmente as desvantagens da primeira abordagem, dada a conexão de conteúdo que possui características comuns (do mesmo diretor ou das mesmas palavras no título). No entanto, a escarsidade da matriz também é reduzida, mas como eles dizem, não há limite para a perfeição.
Manter uma gama completa de classificações de usuários na memória é bastante caro. Tomando estimativas aproximadas do número de usuários de Runet em 80 milhões de pessoas e o tamanho do banco de dados da IMDb em 370 mil filmes, obtemos o tamanho necessário de 27 Terabytes. A decomposição singular é um método de reduzir a dimensão da matriz.
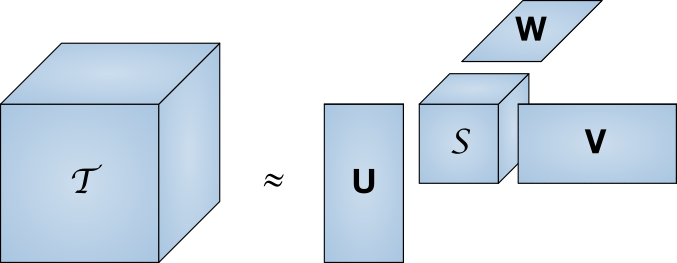 Uma matriz grande T é representada como o produto de um conjunto de matrizes menores
Uma matriz grande T é representada como o produto de um conjunto de matrizes menoresEm outras palavras, a busca pela matriz "core", que possui as mesmas propriedades que a matriz completa, mas muito menor. Juntamente com uma diminuição na dimensão, a descarga também diminui. Neste artigo, não abordaremos os meandros da implementação, especialmente porque já existem bibliotecas prontas para várias linguagens de programação.
Dificuldades técnicas
Arranque a frioA situação em que a falta de dados para o novo conteúdo ou o usuário não permite fornecer recomendações de alta qualidade, também conhecidas como “Cold Start”, é um problema típico da filtragem colaborativa.
Uma solução é misturar várias unidades de conteúdo nas recomendações que não coletam dados suficientes. Ao mesmo tempo, o conteúdo mais popular será recomendado para o novo usuário.
Mais popularesUtilizando a abordagem acima, é importante não esquecer que sua conseqüência será um aumento sistemático na frequência de ocorrência dos “mais populares” na lista recomendada. Aprendendo com o comportamento dos usuários que frequentemente oferecem o “mais popular”, o sistema de recomendação corre o risco de aprender a recomendar exclusivamente o conteúdo mais popular.
A principal diferença entre as recomendações pessoais e as recomendações banais do conteúdo mais popular é que elas levam em consideração os gostos individuais, que podem diferir significativamente dos "médios".
Assim, a amostra de reações do usuário ao conteúdo usado para treinar o modelo de recomendação deve ser normalizada.
Disponibilidade, Failover e EscalabilidadeO número de usuários do recurso pode criar uma carga de centenas e milhares de solicitações ao sistema de recomendação por segundo. Além disso, a falha de um ou vários servidores não deve levar à negação de serviço.
Nesse caso, a solução clássica é usar um balanceador de carga que envie uma solicitação para um dos servidores de cluster. Além disso, cada um dos servidores é capaz de processar uma solicitação de entrada. No caso de falha de qualquer um dos servidores no cluster, o balanceador alterna automaticamente a carga para os servidores restantes no sistema. Ao escolher HTTP como o protocolo de transporte, podemos usar o Nginx como um balanceador de carga.
À medida que a audiência do recurso aumenta, o número de servidores no cluster pode aumentar. Nesse caso, é importante minimizar o custo de preparar um novo servidor.
O sistema de recomendação requer a instalação de vários componentes nos quais depende funcionalmente. O Docker é usado para automatizar a implantação de um sistema de recomendação com todas as suas dependências.
O Docker permite coletar todos os componentes necessários, “empacotá-los” em uma imagem e colocá-la em um repositório (registro); depois, faça o download e implante-o em um novo servidor em questão de minutos. Uma vantagem importante do Docker é que a “sobrecarga” ao usá-lo é mínima: o tempo de chamada do aplicativo no contêiner do docker aumenta em alguns nanossegundos em comparação com o aplicativo em execução em um sistema operacional regular.
Outra vantagem importante é a capacidade de retornar rapidamente à versão estável anterior do aplicativo no caso de uma nova falha (basta retirar a versão antiga do registro).
O segundo tipo de solicitações do sistema que você precisa cuidar são solicitações que rastreiam a atividade do usuário. Para que o usuário não precise esperar até que o sistema processe completamente a ação que ele executou, o processo de processamento é executado independentemente do processo de registro de ações.
O Apache Kafka foi escolhido na E-Contenta como uma plataforma que fornece transferência de dados de ações do usuário para processadores. O Kafka implementa o padrão arquitetural Message-Oriented Middleware), capaz de fornecer entrega garantida de dezenas e centenas de milhares de mensagens por segundo e atua como um buffer que protege os processadores do volume excessivo de dados nos horários de pico.
Auto-aprendizagem completaNovos conteúdos e novos usuários aparecem regularmente - sem treinamento regular, a qualidade do modelo diminui. O treinamento deve ser realizado em servidores separados, para que o processo de treinamento, que requer recursos computacionais significativos, não afete o desempenho dos servidores de combate.
A solução clássica para orquestrar tarefas regulares distribuídas é o Jenkins. O serviço agendado começa a receber e normalizar novas amostras de treinamento, treinando um modelo de recomendação, entregando novos modelos e atualizando todos os servidores de cluster, o que permite manter a qualidade das recomendações sem esforços adicionais. No caso de uma falha em qualquer uma das etapas, Jenkins retorna o sistema ao estado estável anterior e notifica o administrador da falha.
Sobre como implementamos na WifireTV
Além disso, para que o sistema funcione corretamente, convidamos um medidor de televisão independente e o convidamos a medir a visualização de telespectadores. Os dados exclusivos resultantes são animados usando algoritmos de ciência de dados. O feedback contínuo do trabalho dos assinantes que interagem com as recomendações preenche a base de precedentes para algoritmos de aprendizado de máquina e permite que as recomendações sejam alteradas dependendo de sinais implícitos de alterações nas preferências dos assinantes, como a época do ano, férias próximas ou alteração da composição familiar.
No processo de teste, tivemos que resolver o problema associado à recomendação de conteúdo de televisão - como ajudar nossos assinantes a entender os fluxos de transmissão. A tarefa também é complicada pelos serviços de exibição adiada. Construímos um sistema que, em vez de uma troca interminável de canais cíclicos, ajuda a encontrar um programa interessante com apenas 2-3 pressionamentos de botão. Para isso, o sistema de recomendação monitora o lançamento de novas séries de programas e prevê o interesse dos telespectadores em programas irregulares e transmissões de filmes. De fato, algoritmos de máquina substituem o trabalho do editor responsável.
O trabalho com streaming de televisão tem suas próprias especificidades. Por exemplo, muitas vezes os mesmos programas de TV populares vão para canais diferentes. Nesse caso, o sistema de recomendação deve entender a duplicação de informações e escolher uma recomendação com base nas preferências do assinante em relação a canais, horário de início da transmissão etc. Essa duplicação de informações também ocorre quando um assinante possui uma assinatura das versões SD e HD dos canais.
Todos esses dois anos, experimentamos diferentes versões de sistemas de recomendação e encontramos um meio termo, o que nos permite melhorar o envolvimento do público e gerar receita com mais eficiência o conteúdo existente. Utilizamos a seleção automática de recomendações descritas acima, juntamente com o ajuste manual - seleções editoriais.
Essa abordagem permitiu aumentar significativamente (10 vezes) a monetização dos serviços VOD e SVOD.
As recomendações editoriais são coleções de filmes e séries temáticos vinculados a estreias, feriados e datas memoráveis. É muito conveniente notificar os assinantes e dar a eles a oportunidade de assistir a novos filmes, sucessos antigos ou impopulares, mas, em nossa opinião, filmes muito interessantes em termos de conteúdo e enredo. Nós nos comunicamos de perto com nossos fornecedores (cinemas on-line e serviços de vídeo adicionais, como ivi, megogo, amediateka) e selecionamos pessoalmente cada filme que será interessante para o assinante assistir.
Nos feriados, fazemos seleções especiais sobre um tópico específico. Por exemplo, no dia da vitória, esses são filmes com temas militares. Em 1º de setembro - uma seleção de conteúdo para crianças, que consiste em programas educacionais, desenhos animados e documentários.
A seleção manual aumenta perfeitamente a lealdade de nossos assinantes. De acordo com nossas estimativas mais conservadoras, cerca de 10% de nossa base de assinantes assiste mensalmente aos filmes que recomendamos e esse indicador está em constante crescimento.
Qual é o resultado?
Atualmente, a Wifire TV opera um sistema inteligente de recomendação da E-Contenta. É baseado em ciência de dados e metadados de 90% dos assinantes da operadora. O algoritmo leva em consideração centenas de dados: o que o assinante está assistindo, quais filmes e programas são populares, quando ele usa o serviço e quem está agora na frente da tela. Queremos transmitir aos nossos assinantes o valor de assinar pacotes de canais premium, misturando-os em recomendações relevantes para o usuário. Também queremos mostrar que adquirir e assistir conteúdo de vídeo legal é normal, conveniente e simples.
O sistema de recomendação informará aos assinantes filmes interessantes, mesmo que eles estejam fora da categoria de novos produtos: assim, o extenso diretório de vídeos deixa de ser uma biblioteca empoeirada e se torna uma vitrine interativa que se ajusta de maneira flexível aos gostos e humor dos assinantes.