Neste artigo, gostaria de falar sobre algumas técnicas para trabalhar com dados ao treinar um modelo. Em particular, como puxar a segmentação de objetos nas caixas, bem como treinar o modelo e obter a marcação do conjunto de dados, marcando apenas algumas amostras.
Desafio
Há um certo processo de fazer pizza e fotos a partir de seus vários estágios (incluindo não apenas pizza). Sabe-se que, se a receita da massa estiver estragada, haverá espinhas brancas na crosta. Há também uma marcação binária da qualidade do teste para cada instância de pizza, feita por especialistas. É necessário desenvolver um algoritmo que determine a qualidade do teste de acordo com a fotografia.
O conjunto de dados consiste em fotografias tiradas de diferentes telefones, em diferentes condições, diferentes ângulos. Instâncias de pizza - 17k. Total de fotos - 60k.
Na minha opinião, a tarefa é bastante típica e adequada para mostrar diferentes abordagens ao tratamento de dados. Para resolvê-lo, você deve:
1. Escolha fotos onde há uma crosta de pizza;
2. Nas fotos selecionadas, realce o bolo;
3. Treine a rede neural nas áreas selecionadas.
Filtrando fotos
À primeira vista, parece que a maneira mais fácil seria entregar essa tarefa aos escribas e depois treinar o conjunto de dados em dados limpos. No entanto, decidi que era mais fácil para mim marcar uma pequena parte do que explicar com um escriba qual ângulo estava correto. Além disso, eu não tinha um critério rígido para o ângulo reto.
Então aqui está o que eu fiz:
1. Marcou 100 fotos de borda;

2. Calculei os recursos após a retirada global da grade resnet-152 com pesos do imagenet11k_places365;
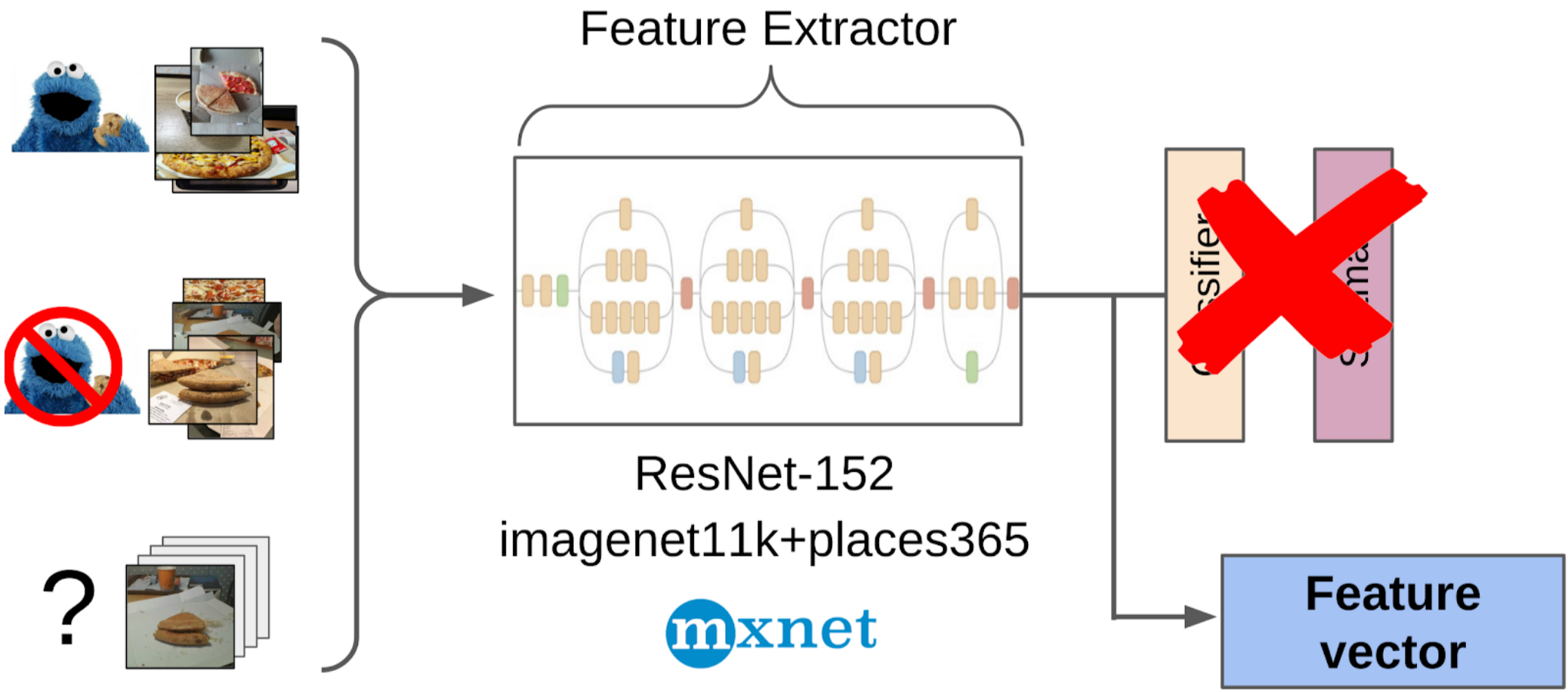
3. Tomou a média das características de cada classe, recebendo duas âncoras;
4. Calculei a distância de cada âncora a todos os recursos das 50 mil fotos restantes;
5. Os 300 primeiros na proximidade de uma âncora são relevantes para a classe positiva; os 500 primeiros mais próximos da outra âncora são negativos;
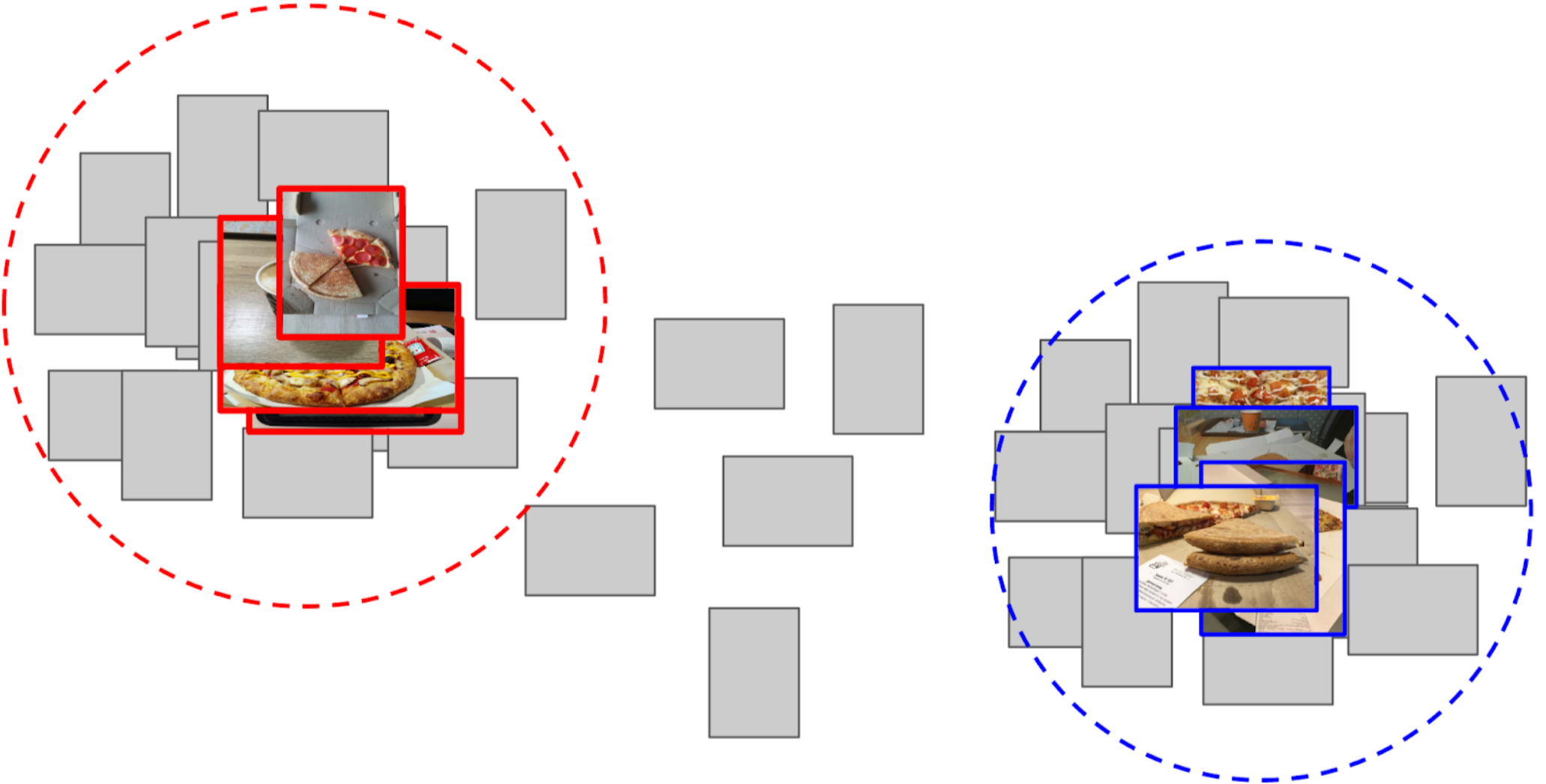
6. Nestas amostras, treinei o LightGBM com os mesmos recursos (o XGboost é indicado na imagem, porque possui um logotipo e é mais reconhecível, mas o LightGBM não possui um logotipo);
7. Usando esse modelo, obtive a marcação de todo o conjunto de dados.

Eu usei aproximadamente a mesma abordagem nas competições do kaggle como
linha de base .
Uma explicação nos dedos porque essa abordagem funcionaUma rede neural pode ser percebida como uma transformação fortemente não linear de uma imagem. No caso de classificação, a imagem é convertida nas probabilidades das classes que estavam no conjunto de treinamento. E essas probabilidades podem essencialmente ser usadas como recursos para o Light GBM. No entanto, essa é uma descrição bastante pobre e, no caso da pizza, diremos que a classe do bolo é condicionalmente 0,3 gatos e 0,7 cães, e o lixo é o resto. Em vez disso, você pode usar recursos menos esparsos após o pool médio global. Eles possuem uma propriedade que gera recursos a partir das amostras do conjunto de treinamento, que devem ser separadas por uma transformação linear (uma camada totalmente conectada ao Softmax). No entanto, devido ao fato de não haver pizza explícita no trem imagenet, é melhor fazer uma transformação não linear na forma de árvores para separar as classes do novo conjunto de treinamento. Em princípio, você pode ir ainda mais longe e obter recursos de algumas camadas intermediárias da rede neural. Eles serão melhores, pois ainda não perderam a localidade dos objetos. Mas eles são muito piores devido ao tamanho do vetor de recurso. Além disso, eles são menos lineares do que na frente de uma camada totalmente conectada.
Uma ligeira digressão
A ODS reclamou recentemente que ninguém escreve sobre suas falhas. Corrigindo a situação. Há cerca de um ano, participei do
concurso Kaggle Sea Lions com
Eugene Nizhibitsky . A tarefa era contar as focas nas imagens do zangão. A marcação foi simplesmente dada na forma de coordenadas de carcaça, mas em algum momento
Vladimir Iglovikov as marcou com caixas e generosamente compartilhou isso com a comunidade. Naquela época, eu me considerava pai da segmentação semântica (depois de
Kaggle Dstl ) e decidi que a Unet facilitaria muito a tarefa de contar se eu aprendesse a distinguir classicamente os gatos.
Explicação da segmentação semânticaA segmentação semântica é essencialmente uma classificação pixel por pixel de uma imagem. Ou seja, cada pixel de origem da imagem precisa estar associado a uma classe. No caso de segmentação binária (caso do artigo), será uma classe positiva ou negativa. No caso de segmentação multiclasse, a cada pixel será atribuída uma classe do conjunto de treinamento (fundo, grama, gato, homem, etc.). No caso da segmentação binária, a arquitetura da rede neural da rede
U-net funcionou bem naquele momento. Essa rede neural é semelhante em estrutura a um codificador-decodificador convencional, mas com recursos encaminhados da parte do codificador para o decodificador nos estágios de tamanho apropriado.

Na forma de baunilha, no entanto, ninguém mais usa, mas pelo menos eles adicionam a Norma de Lote. Bem, como regra, eles pegam um
codificador de gordura e inflam o decodificador. As arquiteturas do tipo U-net foram substituídas por novas grades de segmentação
FPN , que mostram bom desempenho em algumas tarefas. No entanto, arquiteturas do tipo Unet não perderam sua relevância até hoje. Eles funcionam bem como uma linha de base, são fáceis de treinar e é muito simples variar a profundidade / tamanho da neurociência alterando diferentes codificadores.
Nesse sentido, comecei a ensinar segmentação, tendo como objetivo, no primeiro estágio, apenas gatos de boxe. Após a primeira etapa do treinamento, previ o trem e observei como as previsões são. Com a ajuda das heurísticas, pode-se selecionar a confiança abstrata da máscara e dividir condicionalmente as previsões em dois grupos: onde tudo é bom e onde tudo é ruim.

Previsões onde tudo está bem podem ser usadas para treinar a próxima iteração do modelo. As previsões, onde tudo está ruim, podem ser escolhidas com grandes áreas sem selos, mãos mascaradas e também jogadas no trem. E, iterativamente, Eugene e eu treinamos um modelo que até aprendeu a segmentar barbatanas de focas para indivíduos grandes.
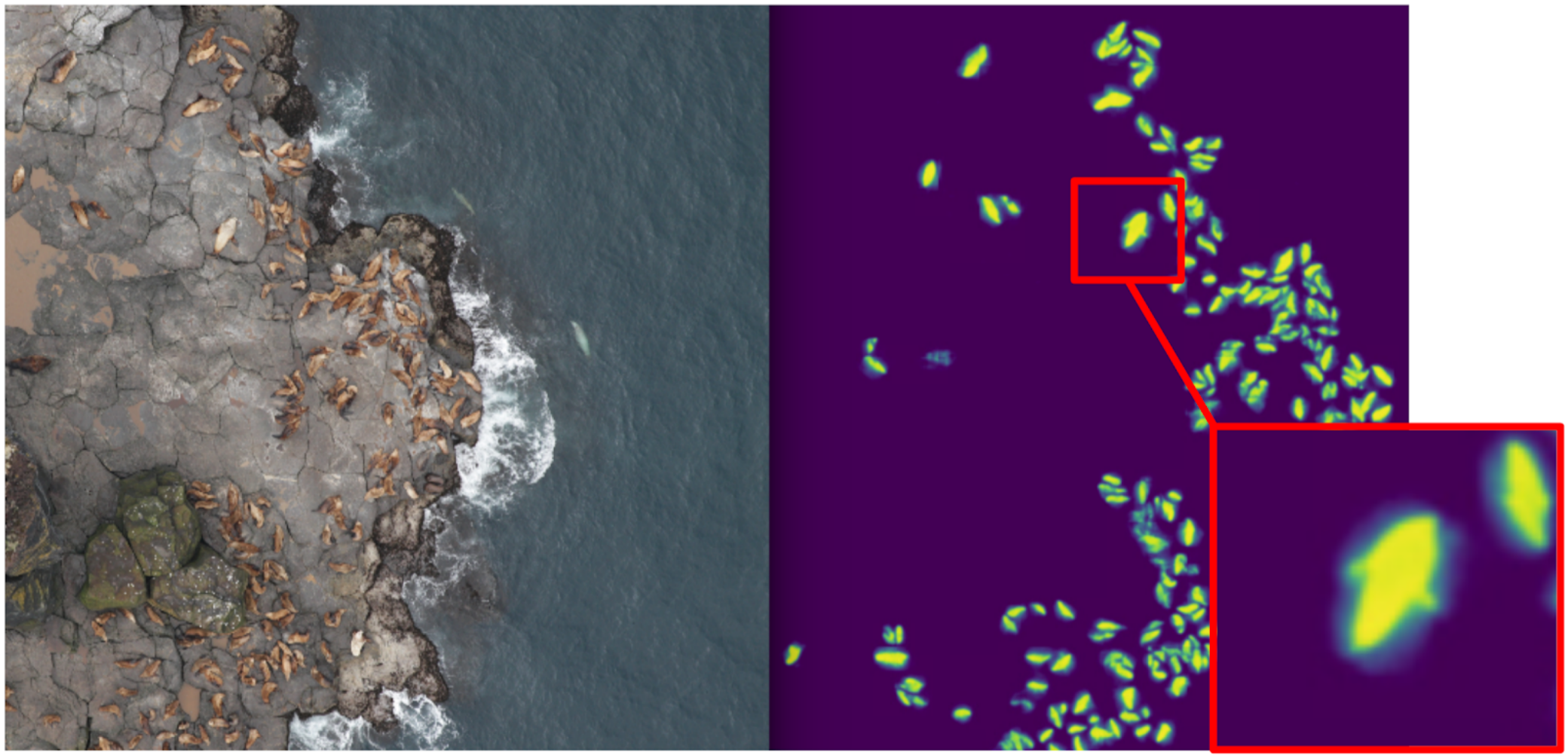
Mas foi um fracasso feroz: passamos muito tempo aprendendo a segmentar gatos legais e ... Quase não ajudou no cálculo. A suposição de que a densidade dos selos (o número de indivíduos por unidade de área da máscara) é constante não funcionou, porque o drone voou em alturas diferentes e as imagens tinham escalas diferentes. E, ao mesmo tempo, a segmentação ainda não destacava indivíduos individuais se eles estivessem firmes - o que acontecia com bastante frequência. E antes da
abordagem inovadora para a separação dos objetos da equipe Tocoder no DSB2018, ainda havia outro ano. Como resultado, ficamos com nada além de terminar em 40º lugar entre 600 equipes.
No entanto, tirei duas conclusões: a segmentação semântica é uma abordagem conveniente para visualizar e analisar a operação do algoritmo, e as máscaras podem ser soldadas das caixas com algum esforço.
Mas voltando à pizza. Para destacar o bolo nas fotos selecionadas e filtradas, a opção mais correta seria entregar a tarefa aos escribas. Naquela época, já tínhamos implementado as caixas e o algoritmo de consenso para elas. Então, eu apenas dei alguns exemplos e dei à marcação. Como resultado, obtive 500 amostras com uma área de crosta selecionada com precisão.
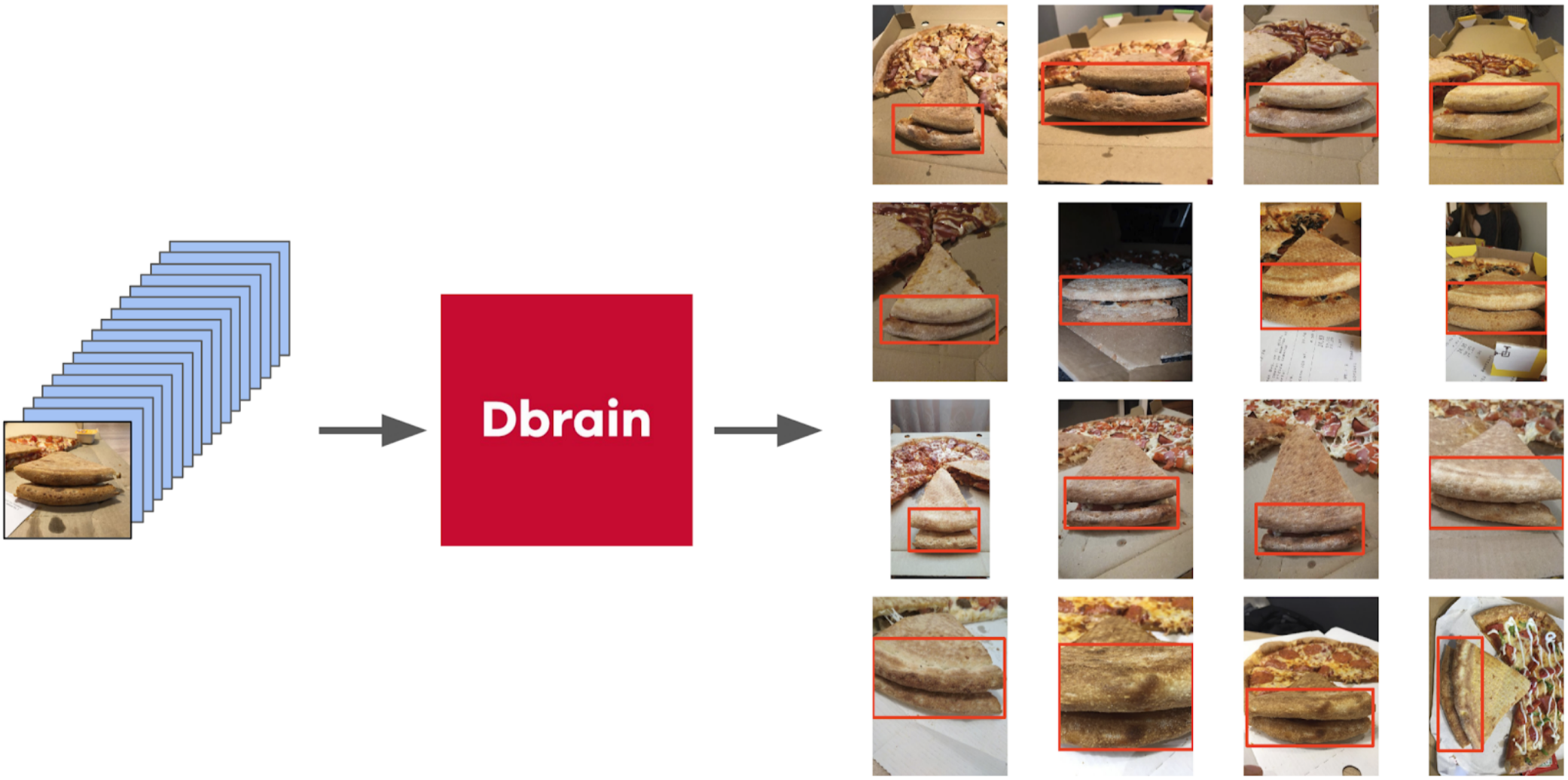
Então eu peguei meu código dos selos e me aproximei mais formalmente do procedimento atual. Após a primeira iteração do treinamento, também ficou claramente visível onde o modelo estava errado. E a confiança das previsões pode ser definida da seguinte forma:
1 - (área cinza) / (área da máscara) # haverá uma fórmula, prometo
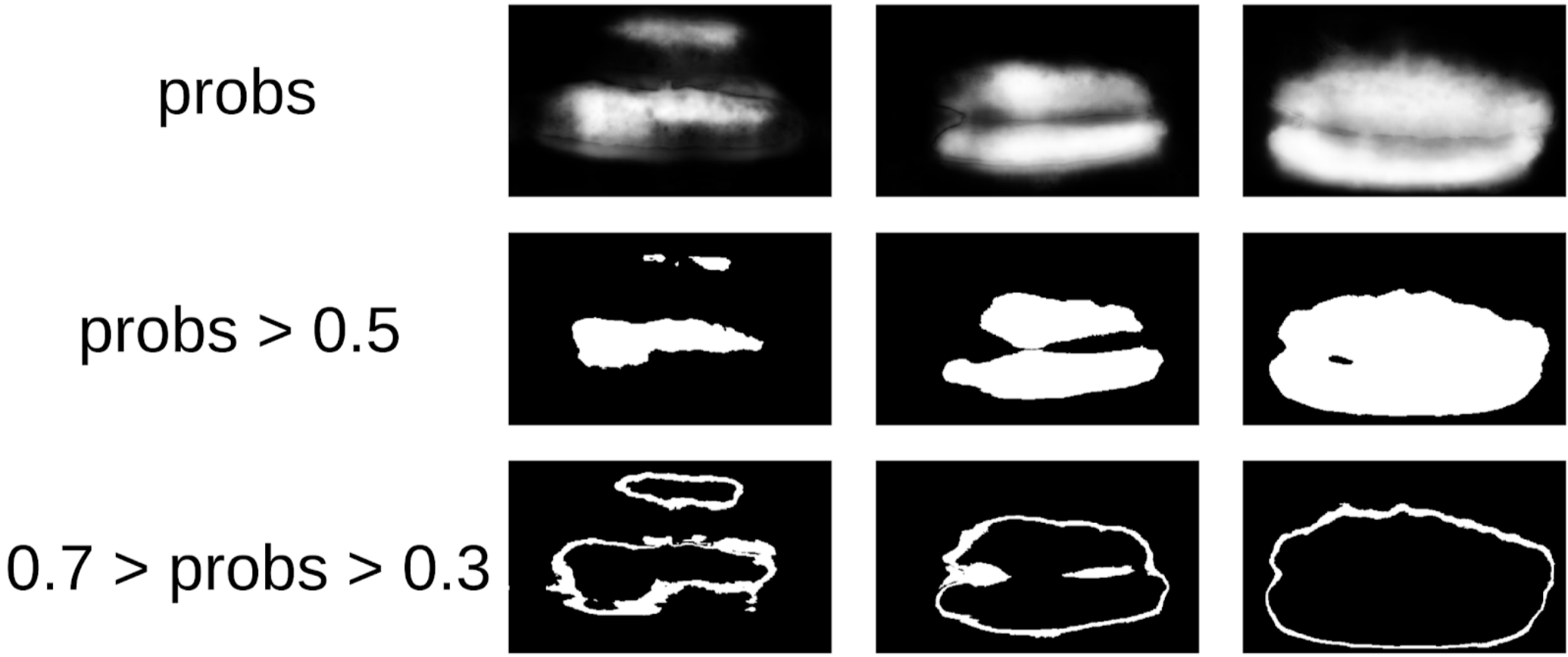
Agora, para fazer a próxima iteração de puxar as caixas nas máscaras, um pequeno conjunto preverá o trem TTA. Isso pode ser considerado, até certo ponto, na destilação do conhecimento WAAAAGH, mas é mais correto chamar Pseudo Labeling.
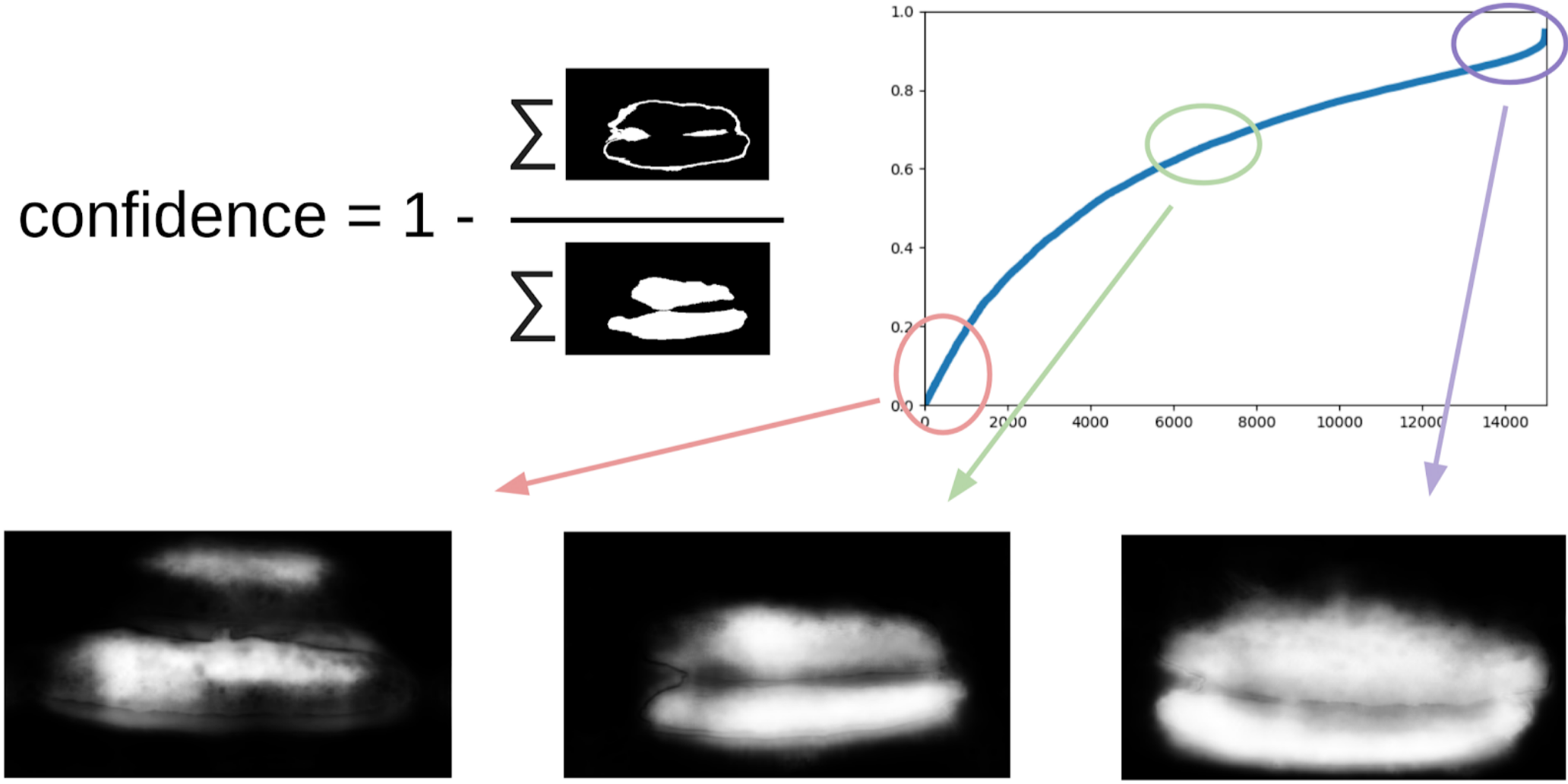
Em seguida, você precisa escolher com seus olhos um certo limiar de confiança, a partir do qual formamos um novo trem. E, opcionalmente, você pode marcar as amostras mais complexas que o conjunto não pôde manipular. Decidi que seria útil e pintei cerca de 20 figuras em algum lugar enquanto digeria o almoço.
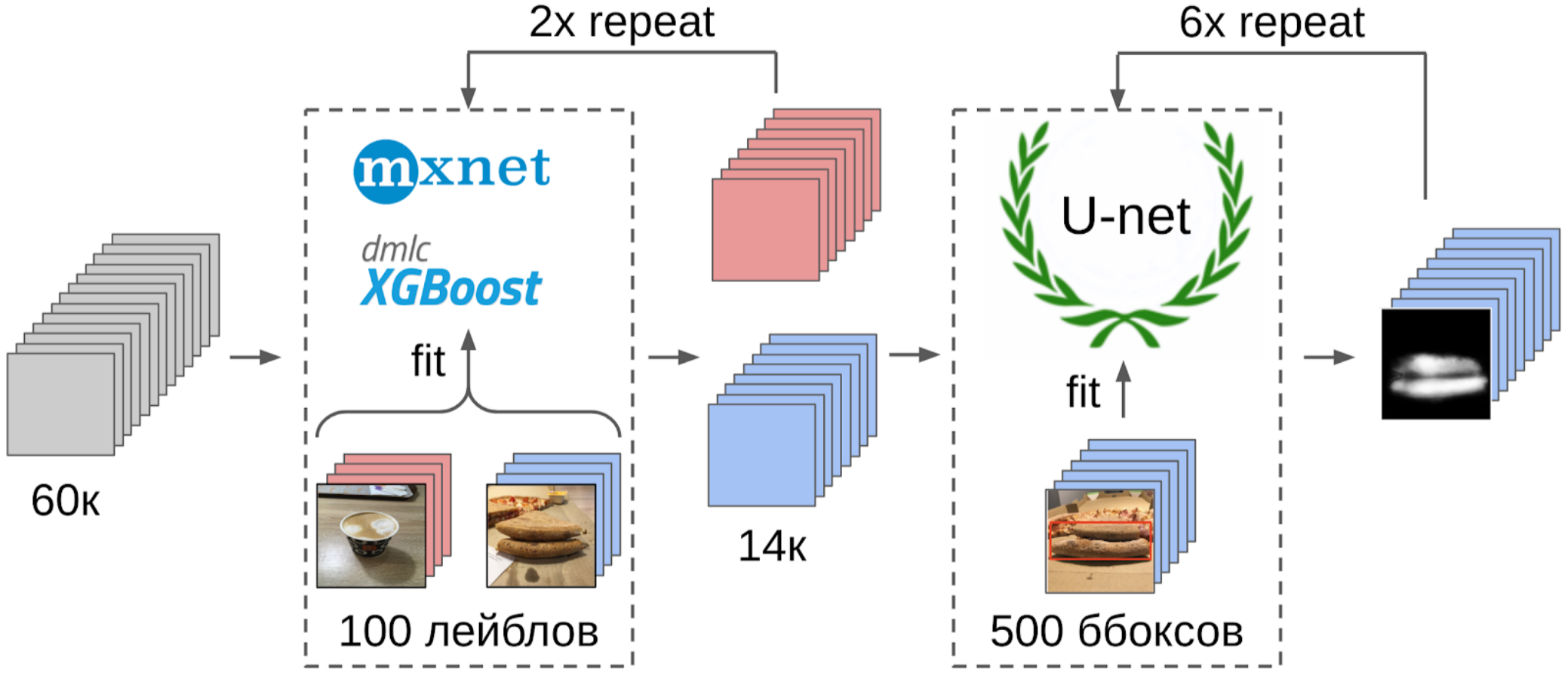
E agora a parte final do pipeline: modelo de treinamento. Para preparar as amostras, extraí a área da máscara do bolo. Também insuflei um pouco a máscara com dilatação e a apliquei na imagem para remover o fundo, pois não deveria haver informações sobre a qualidade do teste. E então acabei de arquivar vários modelos do Zoológico Imagenet. No total, eu fui capaz de coletar cerca de 12k amostras confiáveis. Portanto, eu não ensinei toda a rede neural, mas apenas o último grupo de convoluções, para que o modelo não fosse treinado novamente.
Por que você precisa congelar camadasHá dois lucros com isso: 1. A rede aprende mais rapidamente, porque você não precisa ler gradientes para camadas congeladas. 2. A rede não é treinada novamente, pois agora possui menos parâmetros livres. Argumenta-se que os primeiros grupos de convoluções durante o treinamento na Imagenet geram sinais bastante comuns, como transições de cores nítidas e texturas adequadas para uma classe muito ampla de objetos na fotografia. Isso significa que você não pode treiná-los durante o Transer Learning.
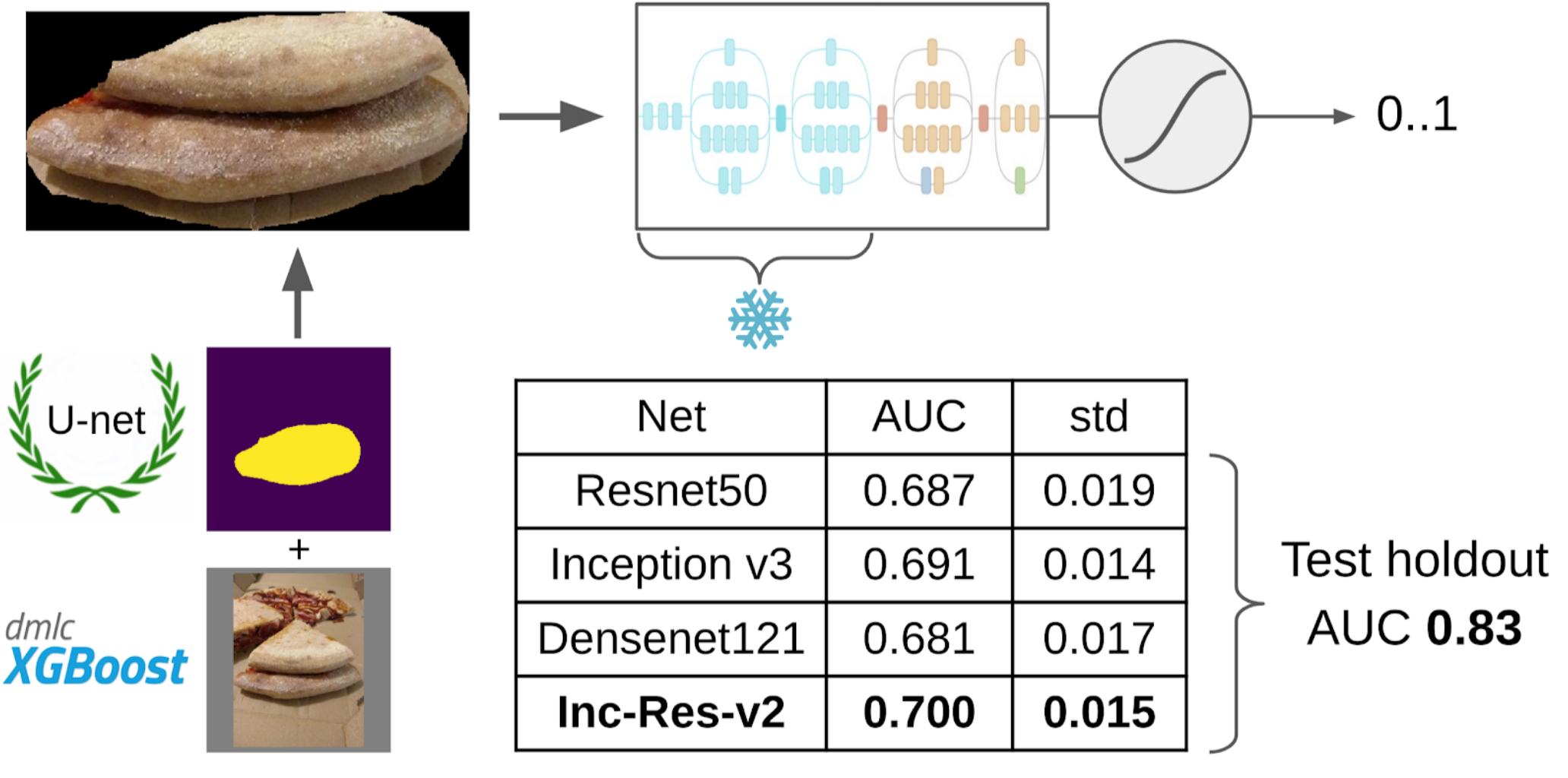
O melhor modelo único foi o Inception-Resnet-v2 e, para ela, o ROC-AUC em uma dobra foi de 0,700. Se você não selecionar nada e enviar imagens não processadas como estão, o ROC-AUC será 0,58. Enquanto eu desenvolvia a solução, o próximo lote de dados foi cozido na pizza DODO, e foi possível testar todo o pipeline de forma honesta. Verificamos o pipeline inteiro e obtivemos ROC-AUC 0,83.
Vejamos os erros agora:
Top Falso Negativo

Pode-se ver aqui que eles estão associados a um erro na marcação do bolo, pois há claramente sinais de um teste estragado.
Top falso positivo

Aqui, os erros estão relacionados ao fato de o primeiro modelo ter sido escolhido não com um ângulo muito bom, segundo o qual é difícil encontrar sinais importantes da qualidade do teste.
Conclusão
Às vezes, os colegas me provocam dizendo que eu resolvo muitos problemas por segmentação usando a Unet. No entanto, na minha opinião, esta é uma abordagem bastante poderosa e conveniente. Permite visualizar erros de modelo e a confiança de suas previsões. Além disso, toda a linha de pagamento parece muito simples e agora existem vários repositórios para qualquer estrutura.