Neste artigo, falaremos sobre como e por que desenvolvemos
o Sistema de Interação - um mecanismo que transfere informações entre aplicativos clientes e servidores 1C: Enterprise - desde a definição da tarefa até a reflexão sobre os detalhes da arquitetura e implementação.
O Sistema de Interação (doravante denominado CB) é um sistema de mensagens distribuído e tolerante a falhas com entrega garantida. O SV foi projetado como um serviço altamente carregado com alta escalabilidade e está disponível tanto como um serviço on-line (fornecido pela 1C) quanto como um produto de circulação que pode ser implantado nas capacidades de seu servidor.
O CB usa o armazenamento distribuído
Hazelcast e o mecanismo de pesquisa
Elasticsearch . Também falaremos sobre Java e como dimensionamos o PostgreSQL horizontalmente.

Declaração do problema
Para esclarecer por que criamos o Sistema de Interação, vou falar um pouco sobre como o desenvolvimento de aplicativos de negócios na 1C funciona.
Para começar, um pouco sobre nós para aqueles que ainda não sabem o que estamos fazendo :) Estamos criando a plataforma de tecnologia 1C: Enterprise. A plataforma inclui uma ferramenta para o desenvolvimento de aplicativos de negócios, bem como o tempo de execução, que permite que os aplicativos de negócios funcionem em um ambiente de plataforma cruzada.
Paradigma de desenvolvimento cliente-servidor
Aplicativos de negócios criados no 1C: Enterprise operam na arquitetura
cliente-servidor de três níveis “DBMS - application server - client”. O código do aplicativo escrito no
idioma incorporado 1C pode ser executado no servidor de aplicativos ou no cliente. Todo o trabalho com objetos de aplicativo (diretórios, documentos etc.), além da leitura e gravação no banco de dados, é realizado apenas no servidor. A funcionalidade dos formulários e da interface de comando também é implementada no servidor. O cliente recebe, abre e exibe formulários, "comunica" com o usuário (avisos, perguntas ...), pequenos cálculos em formulários que exigem uma reação rápida (por exemplo, multiplicando o preço pela quantidade), trabalhando com arquivos locais, trabalhando com equipamentos.
No código do aplicativo, os cabeçalhos dos procedimentos e funções devem indicar explicitamente onde o código será executado - usando as diretivas & No Cliente / & No Servidor (& AtClient / & AtServer na versão em inglês). Os desenvolvedores do 1C vão me corrigir agora, dizendo que existem realmente
mais diretivas, mas para nós isso não é essencial agora.
O código do servidor pode ser chamado do código do cliente, mas o código do cliente não pode ser chamado do código do servidor. Essa é uma limitação fundamental que fizemos por várias razões. Em particular, porque o código do servidor deve ser gravado para que seja executado igualmente, independentemente de onde for chamado - do cliente ou do servidor. E, no caso de chamar o código do servidor de outro código, o cliente está ausente. E porque durante a execução do código do servidor, o cliente que o causou poderia fechar, sair do aplicativo e o servidor não teria para quem ligar.
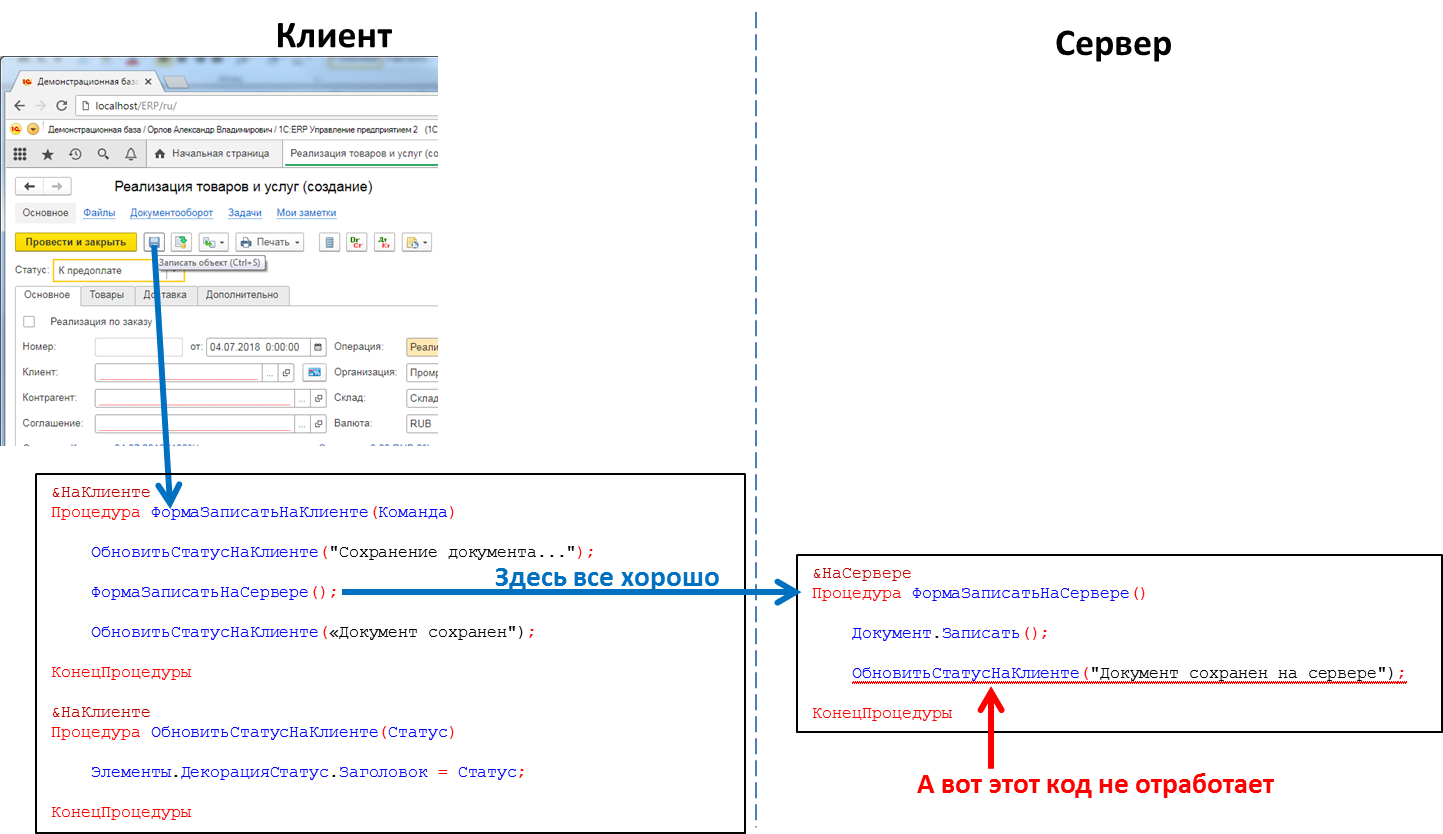 O código que processa o clique do botão: a chamada de procedimento do servidor do cliente funcionará, a chamada de procedimento do cliente do servidor não
O código que processa o clique do botão: a chamada de procedimento do servidor do cliente funcionará, a chamada de procedimento do cliente do servidor nãoIsso significa que, se queremos enviar alguma mensagem para o aplicativo cliente do servidor, por exemplo, que a formação de um relatório de "reprodução longa" terminou e o relatório pode ser visualizado, não temos esse método. Temos que fazer truques, por exemplo, do código do cliente para pesquisar periodicamente o servidor. Mas essa abordagem carrega o sistema com chamadas desnecessárias e, na verdade, não parece muito elegante.
Além disso, também é necessário, por exemplo, quando uma chamada telefônica
SIP chegar, notificar o aplicativo cliente sobre o assunto, para que, pelo número do chamador, ele o encontre no banco de dados da contraparte e mostre as informações do usuário sobre a contraparte que está chamando. Ou, por exemplo, após o recebimento do pedido no armazém, notifique o aplicativo do cliente sobre isso. Em geral, existem muitos casos em que esse mecanismo seria útil.
Realmente estadiamento
Crie um mecanismo do sistema de mensagens. Rápido, confiável, com entrega garantida, com a capacidade de procurar mensagens de forma flexível. Com base no mecanismo, implemente um messenger (mensagens, chamadas de vídeo) que funcione dentro dos aplicativos 1C.
Projete um sistema escalável horizontalmente. O aumento da carga deve ser fechado aumentando o número de nós.
Implementação
Decidimos não incorporar a parte do servidor do SV diretamente na plataforma 1C: Enterprise, mas implementá-la como um produto separado, cuja API pode ser chamada a partir do código do aplicativo 1C. Isso foi feito por várias razões, a principal delas foi possibilitar o intercâmbio de mensagens entre diferentes aplicativos 1C (por exemplo, entre a Administração de Comércio e a Contabilidade). Aplicativos diferentes da 1C podem ser executados em diferentes versões da plataforma 1C: Enterprise, em diferentes servidores etc. Em tais condições, a implementação do CB como um produto separado localizado “ao lado” das instalações da 1C é a solução ideal.
Então, decidimos fazer o CB como um produto separado. Para pequenas empresas, recomendamos o uso do servidor CB instalado em nossa nuvem (wss: //1cdialog.com) para evitar a sobrecarga associada à instalação e configuração do servidor localmente. Grandes clientes, no entanto, podem achar apropriado instalar seu próprio servidor CB em suas instalações. Usamos uma abordagem semelhante em nosso produto SaaS baseado na nuvem
1cFresh - ele é lançado como um produto de circulação para instalação pelos clientes e também é implantado em nossa nuvem
https://1cfresh.com/ .
App
Para balanceamento de carga e tolerância a falhas, implantaremos não um aplicativo Java, mas vários, colocaremos um balanceador de carga na frente deles. Se você precisar transferir uma mensagem de nó para nó - use a publicação / assinatura no Hazelcast.
Comunicação do cliente com o servidor - por websocket. É adequado para sistemas em tempo real.
Cache distribuído
Escolha entre Redis, Hazelcast e Ehcache. No quintal de 2015. Redis acaba de lançar um novo cluster (muito novo, assustador), há um Sentinel com várias restrições. O Ehcache não sabe como montar em um cluster (essa funcionalidade apareceu mais tarde). Decidimos tentar com o Hazelcast 3.4.
Hazelcast está indo para o cluster fora da caixa. No modo de nó único, não é muito útil e pode apenas caber como cache - não sabe como despejar dados no disco, perdeu um único nó - perdeu dados. Implementamos vários Hazelcasts entre os quais fazemos backup de dados críticos. O cache não é de backup - não é uma pena.
Para nós, Hazelcast é:
- Repositório de sessões do usuário. Cada vez que o acesso ao banco de dados para uma sessão é muito longo, colocamos todas as sessões no Hazelcast.
- Cache. Procurando um perfil de usuário - verifique o cache. Escreveu uma nova mensagem - coloque-a no cache.
- Tópicos para comunicar instâncias de aplicativos. Noda gera um evento e o coloca no tópico Hazelcast. Outros nós de aplicativos inscritos neste tópico recebem e processam o evento.
- Bloqueios de cluster. Por exemplo, criamos uma discussão sobre uma chave exclusiva (debate-singleton na estrutura do banco de dados 1C):
conversationKeyChecker.check(""); doInClusterLock("", () -> { conversationKeyChecker.check(""); createChannel(""); });
Verificado se não há canal. Eles pegaram a fechadura, conferiram novamente, criaram. Se você não verificar o bloqueio depois de tomá-lo, há uma chance de que outro segmento naquele momento também tenha verificado e tentará criar a mesma discussão - mas ela já existe. É impossível fazer o bloqueio através do java Lock sincronizado ou usual. Através da base - lentamente, e a base é uma pena, através do Hazelcast - do que você precisa.
Escolhendo um DBMS
Temos uma experiência extensa e bem-sucedida trabalhando com o PostgreSQL e colaborando com os desenvolvedores deste DBMS.
O PostgreSQL não é fácil com um cluster - ele possui
XL ,
XC ,
Citus , mas, em geral, eles não são noSQL, que são escalonáveis. O NoSQL não era considerado o repositório principal; bastava usarmos o Hazelcast, com o qual não tínhamos trabalhado antes.
Como você precisa dimensionar um banco de dados relacional, isso significa
fragmentação . Como você sabe, ao compartilhar, dividimos o banco de dados em partes separadas, para que cada uma delas possa ser movida para um servidor separado.
A primeira versão do nosso sharding implicava na capacidade de distribuir cada uma das tabelas do nosso aplicativo para diferentes servidores em diferentes proporções. Há muitas mensagens no servidor A - por favor, vamos transferir parte desta tabela para o servidor B. Essa solução acabou de gritar sobre otimização prematura, por isso decidimos nos limitar a uma abordagem de vários locatários.
Você pode
ler sobre vários inquilinos, por exemplo, no site do
Citus Data .
No SV, existem conceitos de aplicativo e assinante. Um aplicativo é uma instalação específica de um aplicativo comercial, como ERP ou Contabilidade, com seus usuários e dados corporativos. Um assinante é uma organização ou um indivíduo em nome de quem o aplicativo está registrado no servidor CB. Um assinante pode registrar vários aplicativos, e esses aplicativos podem trocar mensagens entre si. O assinante também se tornou o inquilino em nosso sistema. Mensagens de vários assinantes podem estar em uma base física; se percebermos que algum assinante começou a gerar muito tráfego - nós o levamos para uma base física separada (ou mesmo para um servidor de banco de dados separado).
Temos um banco de dados principal onde uma tabela de roteamento com informações sobre a localização de todos os bancos de dados de assinantes é armazenada.
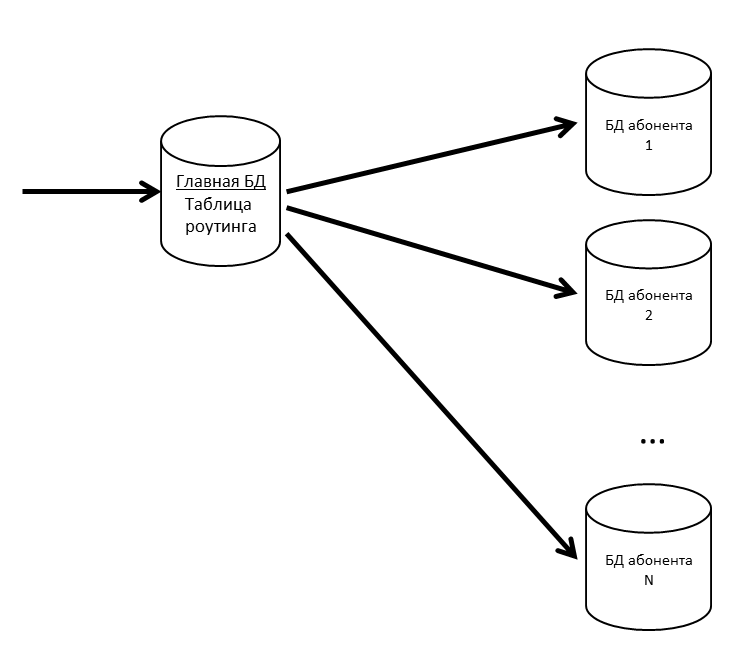
Para que o banco de dados principal não seja um gargalo, mantemos a tabela de roteamento (e outros dados solicitados com freqüência) no cache.
Se o banco de dados do assinante começar a ficar mais lento, nós o dividiremos em partições internas. Em outros projetos, usamos pg_pathman para particionar tabelas grandes.
Como perder mensagens do usuário é ruim, suportamos nossos bancos de dados com réplicas. A combinação de réplicas síncronas e assíncronas permite que você esteja seguro em caso de perda do banco de dados principal. A perda de mensagens ocorrerá apenas em caso de falha simultânea do banco de dados principal e de sua réplica síncrona.
Se a réplica síncrona for perdida, a réplica assíncrona se tornará síncrona.
Se o banco de dados principal for perdido, a réplica síncrona se tornará o banco de dados principal, a réplica assíncrona se tornará a réplica síncrona.
Elasticsearch para pesquisa
Como, entre outras coisas, o CB também é um mensageiro, aqui você precisa de uma pesquisa rápida, conveniente e flexível, levando em consideração a morfologia, por correspondências imprecisas. Decidimos não reinventar a roda e usar o mecanismo de pesquisa gratuito Elasticsearch, baseado na biblioteca
Lucene . Também implantamos o Elasticsearch em um cluster (mestre - dados - dados) para eliminar problemas em caso de falha dos nós do aplicativo.
No github, encontramos um
plugin da morfologia russa para o Elasticsearch e o usamos. No índice Elasticsearch, armazenamos as raízes das palavras (definidas pelo plug-in) e N-gramas. À medida que o usuário digita o texto a pesquisar, procuramos o texto digitado entre os N-gramas. Quando armazenada no índice, a palavra "textos" será dividida nos seguintes N gramas:
[aqueles, tecnologia, tex, texto, textos, ek, eks, ekst, eksts, ks, kst, kst, st, st, você,],
E também a raiz da palavra "texto" será salva. Essa abordagem permite pesquisar no início, no meio e no final da palavra.
Quadro geral
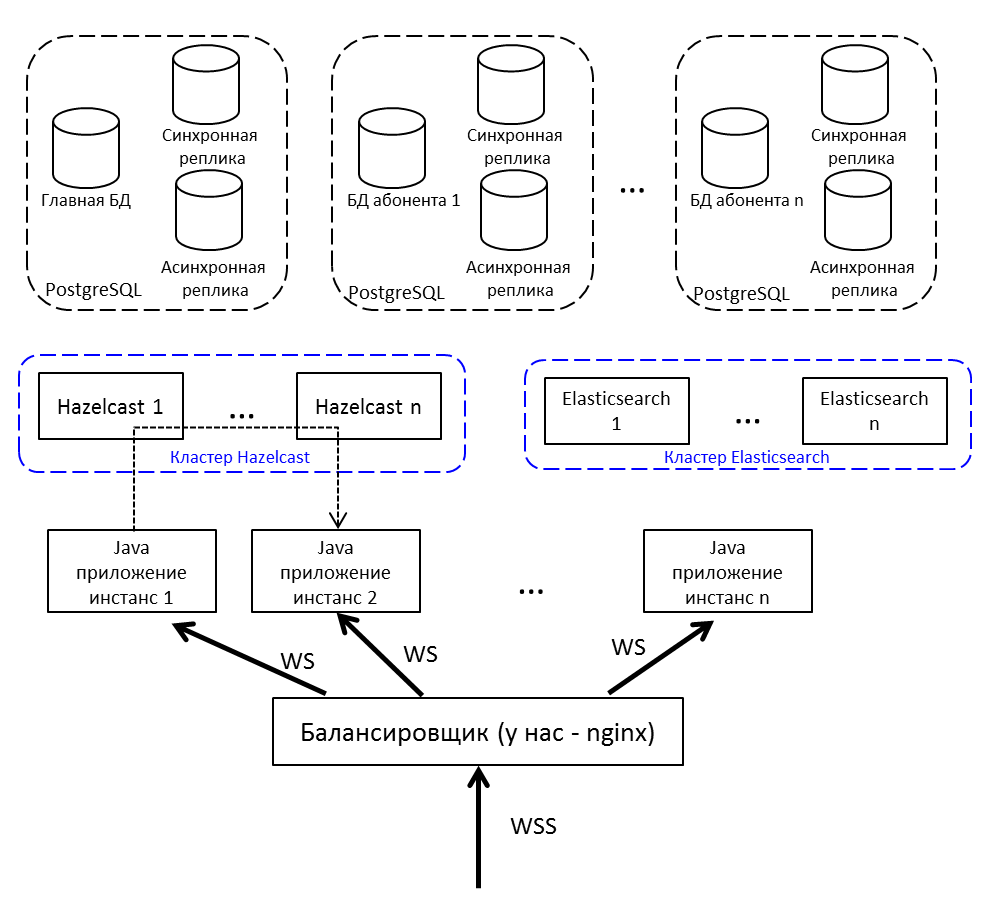
Repetindo a imagem desde o início do artigo, mas com explicações:
- Balanceador de Internet; temos nginx, pode ser qualquer um.
- Instâncias de aplicativos Java se comunicam através do Hazelcast.
- Para trabalhar com um soquete da Web, usamos o Netty .
- O aplicativo Java escrito em Java 8 consiste em pacotes configuráveis OSGi . Os planos - migração para Java 10 e transição para módulos.
Desenvolvimento e teste
No processo de desenvolvimento e teste do CB, encontramos vários recursos interessantes dos produtos usados por nós.
Teste de carga e vazamentos de memória
A liberação de cada liberação do CB é um teste de estresse. Foi bem sucedido quando:
- O teste funcionou por vários dias e não houve negação de serviço
- O tempo de resposta para as principais operações não excedeu um limite confortável
- A degradação do desempenho em comparação com a versão anterior não é superior a 10%
Enchemos a base de testes com dados - para isso, obtemos informações sobre o assinante mais ativo do servidor de produção, multiplicamos seus números por 5 (o número de mensagens, discussões, usuários) e, por isso, testamos.
Realizamos testes de carga do sistema de interação em três configurações:
- Teste de estresse
- Apenas conexões
- Registro de Assinante
Durante o teste de estresse, iniciamos várias centenas de threads e eles carregam o sistema sem parar: escreva mensagens, crie discussões, obtenha uma lista de mensagens. Simulamos as ações de usuários comuns (obtenha uma lista das minhas mensagens não lidas, escreva para alguém) e soluções de software (transfira um pacote de uma configuração diferente, processe a notificação).
Por exemplo, isso faz parte do teste de estresse:
- O usuário efetua login.
- Solicita discussões não lidas
- 50% de chance de ler mensagens
- Com 50% de probabilidade, escreve mensagens
- Próximo usuário:
- Com 20% de probabilidade, cria uma nova discussão.
- Seleciona aleatoriamente qualquer uma de suas discussões
- Vai para dentro
- Solicita mensagens, perfis de usuário
- Cria cinco mensagens endereçadas a usuários aleatórios a partir desta discussão.
- Fora de discussão
- Repete 20 vezes
- Desconecta-se, volta ao início do script
- O bot de bate-papo entra no sistema (emula a troca de mensagens do código de soluções aplicadas)
- Com 50% de probabilidade, cria um novo canal para troca de dados (discussão especial)
- Com uma probabilidade de 50%, escreve uma mensagem em qualquer um dos canais existentes
O cenário "Somente conexões" apareceu por um motivo. Existe uma situação: os usuários conectaram o sistema, mas ainda não se envolveram. Cada usuário de manhã às 09:00 liga o computador, estabelece uma conexão com o servidor e fica silencioso. Esses caras são perigosos, existem muitos deles - dos pacotes eles só têm PING / PONG, mas mantêm a conexão com o servidor (eles não conseguem) - mas de repente uma nova mensagem). O teste reproduz a situação quando, em meia hora, um grande número desses usuários tenta efetuar login no sistema. Parece um teste de estresse, mas se concentra precisamente nesta primeira entrada - para que não haja falhas (uma pessoa não usa o sistema, mas já está caindo - é difícil encontrar algo pior).
O cenário de registro do assinante é originário do primeiro lançamento. Realizamos um teste de estresse e tínhamos certeza de que o sistema não fica lento na correspondência. Mas os usuários foram e o registro começou a cair em um tempo limite. Ao se registrar, usamos
/ dev / random , que está vinculado à entropia do sistema. O servidor não conseguiu acumular entropia suficiente e congelou por dezenas de segundos ao solicitar um novo SecureRandom. Existem várias maneiras de sair dessa situação, por exemplo: alterne para o menos seguro / dev / urandom, coloque um quadro especial que gere entropia, gere números aleatórios antecipadamente e armazene no pool. Encerramos temporariamente o problema com um pool, mas desde então executamos um teste separado para registrar novos assinantes.
Como gerador de carga, usamos o
JMeter . Ele não sabe trabalhar com um soquete da Web; é necessário um plug-in. O primeiro nos resultados de pesquisa para "jmeter websocket" são
artigos com BlazeMeter , que recomendam um
plug-in de Maciej Zaleski .
Com ele, decidimos começar.
Quase imediatamente após o início de testes sérios, descobrimos que vazamentos de memória começaram no JMeter.
O plugin é uma grande história separada, com 176 estrelas e 132 garfos no github. O próprio autor não se comprometeu com ele desde 2015 (o levamos em 2015, então isso não levantou suspeitas), vários problemas do github sobre vazamentos de memória, 7 solicitações de recebimento não fechadas.
Se você decidir realizar testes de carga com este plug-in, preste atenção às seguintes discussões:
- Em um ambiente multithread, o LinkedList usual foi usado; como resultado, eles receberam o NPE em tempo de execução. É resolvido alternando para ConcurrentLinkedDeque ou por blocos sincronizados. Eles escolheram a primeira opção para eles mesmos ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/43 ).
- O vazamento de memória, a desconexão não exclui as informações de conexão ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/44 ).
- No modo de streaming (quando o soquete da Web não fecha no final da amostra, mas é usado mais adiante no plano), os padrões de Resposta ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/19 ) não funcionam.
Este é um daqueles no github. O que fizemos:
- Eles pegaram o garfo Elyran Kogan (@elyrank) - os problemas 1 e 3 foram corrigidos
- Problema resolvido 2
- Pontão atualizado de 9.2.14 a 9.3.12
- SimpleDateFormat embrulhado em ThreadLocal; SimpleDateFormat não é seguro para threads, o que levou ao tempo de execução do NPE
- Eliminado mais um vazamento de memória (a conexão foi fechada incorretamente quando desconectada)
E ainda assim flui!
A memória começou a terminar não em um dia, mas em dois. Não havia absolutamente tempo, eles decidiram executar menos threads, mas com quatro agentes. Isso deveria ter sido suficiente por pelo menos uma semana.
Dois dias se passaram ...
Agora a memória começou a se esgotar no Hazelcast. Ficou evidente nos logs que, após alguns dias de teste, o Hazelcast começa a reclamar de falta de memória e, após algum tempo, o cluster se desfaz e os nós continuam morrendo individualmente. Conectamos o JVisualVM ao hazelcast e vimos uma “serra ascendente” - ele ligava regularmente para GC, mas não conseguia limpar sua memória.
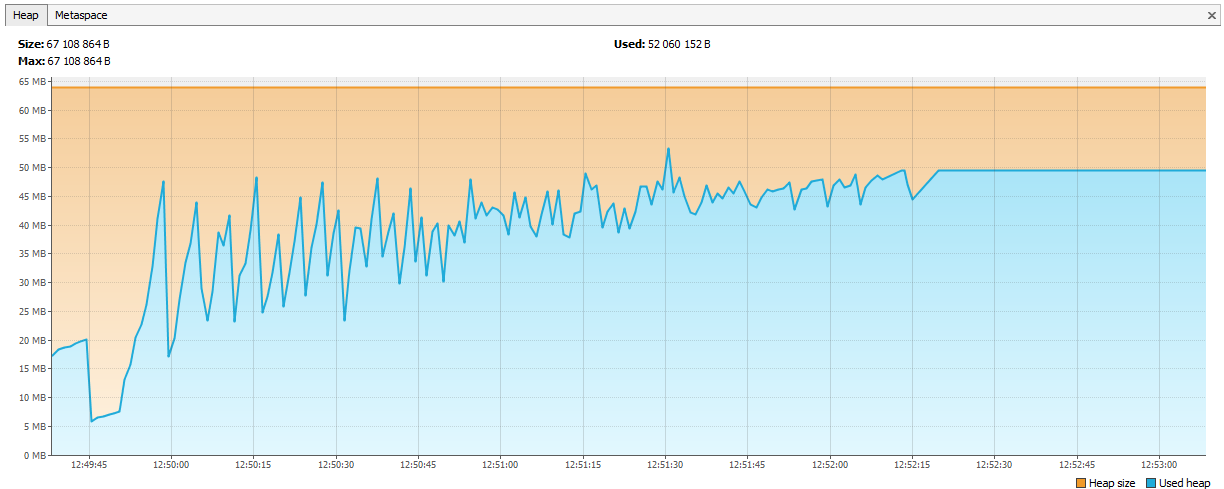
Aconteceu que no hazelcast 3.4, ao remover map / multiMap (map.destroy ()), a memória não é completamente liberada:
github.com/hazelcast/hazelcast/issues/6317github.com/hazelcast/hazelcast/issues/4888Agora o bug foi corrigido na versão 3.5, mas foi um problema. Criamos um novo multiMap com nomes dinâmicos e excluídos de acordo com nossa lógica. O código tinha algo parecido com isto:
public void join(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.put(auth.getUserId(), auth); } public void leave(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.remove(auth.getUserId(), auth); if (sessions.size() == 0) { sessions.destroy(); } }
Ligue para:
service.join(auth1, "____UUID1"); service.join(auth2, "____UUID1");
O multiMap foi criado para cada assinatura e excluído quando não era necessário. Decidimos que iniciaremos o Map <String, Set>, a chave será o nome da assinatura e os valores serão os identificadores das sessões (das quais você poderá obter os IDs do usuário, se necessário).
public void join(Authentication auth, String sub) { addValueToMap(sub, auth.getSessionId()); } public void leave(Authentication auth, String sub) { removeValueFromMap(sub, auth.getSessionId()); }
Gráficos endireitados.
O que mais aprendemos sobre o teste de estresse
- O JSR223 precisa ser gravado no cache de compilação groovy e ativado - isso é muito mais rápido. Link
- Os gráficos Jmeter-Plugins são mais fáceis de entender do que o padrão. Link
Sobre nossa experiência com Hazelcast
O Hazelcast era um produto novo para nós. Começamos a trabalhar com ele a partir da versão 3.4.1, agora nosso servidor de produção possui a versão 3.9.2 (no momento da redação deste artigo, a versão mais recente do Hazelcast é a 3.10).
Geração de ID
Começamos com identificadores inteiros. Vamos imaginar que precisamos de outro Long para uma nova entidade. A sequência não se encaixa no banco de dados, as tabelas participam do sharding - acontece que há um ID da mensagem = 1 no DB1 e um ID da mensagem = 1 no DB2, você não pode colocar esse ID no Elasticsearch, no Hazelcast, mas o pior é se você deseja reduzir os dados de dois bancos de dados em um (por exemplo, decidir que um banco de dados é suficiente para esses assinantes). Você pode criar vários AtomicLongs no Hazelcast e manter o contador lá; o desempenho da obtenção de um novo ID é incrementAndGet mais o tempo para uma solicitação no Hazelcast. Mas há algo mais ideal no Hazelcast - FlakeIdGenerator. Cada cliente recebe um intervalo de ID no contato, por exemplo, o primeiro de 1 a 10.000, o segundo de 10.001 a 20.000 e assim por diante. Agora o cliente pode emitir novos identificadores de forma independente até o intervalo emitido para ele terminar. Funciona rapidamente, mas quando você reinicia o aplicativo (e o cliente Hazelcast), uma nova sequência começa - daí as lacunas etc. Além disso, os desenvolvedores não sabem muito bem por que os IDs são inteiros, mas são tão diferentes. Todos nós pesamos e mudamos para UUIDs.
A propósito, para quem quer ser como o Twitter, existe uma biblioteca do Snowcast - essa é uma implementação do Snowflake sobre o Hazelcast. Você pode vê-lo aqui:
github.com/noctarius/snowcastgithub.com/twitter/snowflakeMas não alcançamos as mãos dela.
TransactionalMap.replace
Outra surpresa: TransactionalMap.replace não está funcionando. Aqui está um teste:
@Test public void replaceInMap_putsAndGetsInsideTransaction() { hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { context.getMap("map").put("key", "oldValue"); context.getMap("map").replace("key", "oldValue", "newValue"); String value = (String) context.getMap("map").get("key"); assertEquals("newValue", value); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); } Expected : newValue Actual : oldValue
Eu tive que escrever minha substituição usando getForUpdate:
protected <K,V> boolean replaceInMap(String mapName, K key, V oldValue, V newValue) { TransactionalTaskContext context = HazelcastTransactionContextHolder.getContext(); if (context != null) { log.trace("[CACHE] Replacing value in a transactional map"); TransactionalMap<K, V> map = context.getMap(mapName); V value = map.getForUpdate(key); if (oldValue.equals(value)) { map.put(key, newValue); return true; } return false; } log.trace("[CACHE] Replacing value in a not transactional map"); IMap<K, V> map = hazelcastInstance.getMap(mapName); return map.replace(key, oldValue, newValue); }
Teste não apenas estruturas de dados regulares, mas também suas versões transacionais. Acontece que o IMap funciona, mas o TransactionalMap se foi.
Anexe novo JAR sem tempo de inatividade
Primeiro, decidimos gravar objetos de nossas aulas no Hazelcast. Por exemplo, temos uma classe Application, queremos salvar e ler. Salvar:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); map.set(id, application);
Lemos:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); return map.get(id);
Tudo funciona. Decidimos criar um índice no Hazelcast para procurá-lo:
map.addIndex("subscriberId", false);
E ao escrever uma nova entidade, eles começaram a receber uma ClassNotFoundException. O Hazelcast tentou suplementar o índice, mas não sabia nada sobre a nossa classe e queria que ele tivesse um JAR com essa classe. Fizemos isso, tudo funcionou, mas apareceu um novo problema: como atualizar o JAR sem parar o cluster completamente? O Hazelcast não pega o novo JAR durante uma atualização em nível de pod. Nesse momento, decidimos que poderíamos viver muito bem sem pesquisar por índice. Afinal, se você usar o Hazelcast como um armazenamento de valor-chave, tudo funcionará? Na verdade não. Aqui, novamente, o comportamento diferente do IMap e do TransactionalMap. Onde o IMap não importa, o TransactionalMap gera um erro.
IMap Nós escrevemos 5000 objetos, lemos. Tudo é esperado.
@Test void get5000() { IMap<UUID, Application> map = hazelcastInstance.getMap("application"); UUID subscriberId = UUID.randomUUID(); for (int i = 0; i < 5000; i++) { UUID id = UUID.randomUUID(); String title = RandomStringUtils.random(5); Application application = new Application(id, title, subscriberId); map.set(id, application); Application retrieved = map.get(id); assertEquals(id, retrieved.getId()); } }
E não funciona na transação, obtemos uma ClassNotFoundException:
@Test void get_transaction() { IMap<UUID, Application> map = hazelcastInstance.getMap("application_t"); UUID subscriberId = UUID.randomUUID(); UUID id = UUID.randomUUID(); Application application = new Application(id, "qwer", subscriberId); map.set(id, application); Application retrievedOutside = map.get(id); assertEquals(id, retrievedOutside.getId()); hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { TransactionalMap<UUID, Application> transactionalMap = context.getMap("application_t"); Application retrievedInside = transactionalMap.get(id); assertEquals(id, retrievedInside.getId()); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); }
Em 3.8, o mecanismo de implantação de classe de usuário apareceu. Você pode atribuir um nó principal e atualizar o arquivo JAR nele.
Agora, mudamos completamente a abordagem: a serializamos em JSON e a salvamos no Hazelcast. O Hazelcast não precisa conhecer a estrutura de nossas classes, mas podemos atualizar sem tempo de inatividade. O controle de versão dos objetos de domínio é controlado pelo aplicativo. Versões diferentes do aplicativo podem ser iniciadas ao mesmo tempo, e é possível que um novo aplicativo grave objetos com novos campos, mas o antigo não conhece esses campos. E, ao mesmo tempo, o novo aplicativo lê objetos registrados pelo aplicativo antigo, nos quais não há novos campos. Lidamos com essas situações dentro do aplicativo, mas, por simplicidade, não alteramos nem excluímos campos, apenas estendemos as classes adicionando novos campos.
Como fornecemos alto desempenho
Quatro viagens ao Hazelcast - boas, duas ao banco de dados - ruins
Acessar dados no cache é sempre melhor do que no banco de dados, mas você não deseja armazenar registros não reclamados. A decisão sobre o que armazenar em cache, adiamos para o último estágio de desenvolvimento. Quando a nova funcionalidade é codificada, ativamos o PostgreSQL para registrar todas as consultas (log_min_duration_statement para 0) e executar o teste de carga por 20 minutos.Usando logs coletados, utilitários como pgFouine e pgBadger podem criar relatórios analíticos. Nos relatórios, procuramos principalmente consultas lentas e frequentes. Para consultas lentas, criamos um plano de execução (EXPLAIN) e avaliamos se essa consulta pode ser acelerada. Solicitações frequentes para os mesmos dados de entrada são bem armazenadas em cache. Tentamos manter as solicitações "planas", uma tabela por solicitação.
Operação
O SV como serviço on-line foi lançado na primavera de 2017, e um produto SV separado foi lançado em novembro de 2017 (naquele momento, no status beta).
Em mais de um ano de operação, não ocorreram problemas graves na operação do serviço online da CB. Monitoramos o serviço online através do
Zabbix , coletamos e implantamos no
Bamboo .
O kit de distribuição do servidor CB é entregue na forma de pacotes nativos: RPM, DEB, MSI. Além disso, para Windows, fornecemos um único instalador na forma de um EXE, que instala o servidor Hazelcast e Elasticsearch em uma máquina. Inicialmente, chamamos essa versão da instalação de "demo", mas agora ficou claro que esta é a opção de implantação mais popular.