
Eu amo Ceph. Trabalho com ele há 4 anos (0,80.x - 12.2.6 12.2.5). Às vezes sou tão apaixonada por ele que passo noites e noites na companhia dele, e não com minha namorada. Encontrei vários problemas neste produto e continuo vivendo com alguns até hoje. Às vezes me alegrava com decisões fáceis, e às vezes sonhava em me encontrar com desenvolvedores para expressar minha indignação. Mas o Ceph ainda é usado em nosso projeto e é possível que seja usado em novas tarefas, pelo menos por mim. Nesta história, compartilharei nossa experiência em operar o Ceph, de alguma maneira me expressarei sobre o que não gosto nessa solução e talvez ajude quem está apenas olhando para ela. Os eventos que começaram cerca de um ano atrás, quando eu trouxe o Dell EMC ScaleIO, agora conhecido como Dell EMC VxFlex OS, levaram-me a escrever este artigo.
Isso não é de forma alguma um anúncio para a Dell EMC ou seu produto! Pessoalmente, não sou muito bom com grandes corporações e caixas-pretas como o VxFlex OS. Mas como você sabe, tudo no mundo é relativo e, usando o exemplo do VxFlex OS, é muito conveniente mostrar o que o Ceph é do ponto de vista da operação, e tentarei fazê-lo.
Parâmetros São cerca de 4 dígitos!
Serviços Ceph, como MON, OSD, etc. possui vários parâmetros para configurar todos os tipos de subsistemas. Os parâmetros são definidos no arquivo de configuração, os daemons os leem no momento do lançamento. Alguns valores podem ser convenientemente alterados em tempo real usando o mecanismo de "injeção", descrito abaixo. Tudo é quase super, se você omitir o momento em que existem centenas de parâmetros:
Martelo:
> ceph daemon mon.a config show | wc -l 863
Luminoso:
> ceph daemon mon.a config show | wc -l 1401
Acontece ~ 500 novos parâmetros em dois anos. Em geral, a parametrização é legal, não é legal que haja dificuldades para entender 80% desta lista. A documentação descrita pelas minhas estimativas ~ 20% e em alguns lugares é ambígua. Um entendimento do significado da maioria dos parâmetros deve ser encontrado no github do projeto ou nas listas de discussão, mas isso nem sempre ajuda.
Aqui está um exemplo de vários parâmetros nos quais eu estava interessado recentemente, encontrei-os no blog de um Ceph-gadfly:
throttler_perf_counter = false // enable/disable throttler perf counter osd_enable_op_tracker = false // enable/disable OSD op tracking
Codifique comentários no espírito das melhores práticas. Como se eu entendesse as palavras e até aproximadamente o que elas tratam, mas o que isso me dará não é.
Ou aqui: osd_op_threads no Luminous se foi e apenas as fontes ajudaram a encontrar um novo nome: osd_peering_wq threads
Eu também gosto que existem opções especialmente holísticas. Aqui, cara, mostra que aumentar o rgw_num _rados_handles é bom :
e o outro cara acha que> 1 é impossível e até perigoso .
E minha coisa favorita é que os iniciantes dão exemplos de uma configuração em suas postagens no blog, onde todos os parâmetros são impensadamente copiados (parece-me) copiados de outro blog do mesmo tipo e, portanto, vários parâmetros que ninguém conhece, exceto o autor do código, desviam-se de config para config.
Eu também apenas queimo muito com o que eles fizeram no Luminous. Há um recurso super bacana - alterar parâmetros em tempo real, sem reiniciar os processos. Você pode, por exemplo, alterar o parâmetro de um OSD específico:
> ceph tell osd.12 injectargs '--filestore_fd_cache_size=512'
ou coloque '*' em vez de 12 e o valor será alterado em todos os OSDs. É muito legal mesmo. Mas, como em Ceph, isso é feito com o pé esquerdo. Design Bai nem todos os valores dos parâmetros podem ser alterados em tempo real. Mais precisamente, eles podem ser definidos e aparecerão alterados na saída, mas, na verdade, apenas alguns são relidos e reaplicados. Por exemplo, você não pode alterar o tamanho do pool de threads sem reiniciar o processo. Para que o executor da equipe entenda que é inútil alterar o parâmetro dessa maneira - eles decidiram imprimir uma mensagem. Olá.
Por exemplo:
> ceph tell mon.* injectargs '--mon_allow_pool_delete=true' mon.c: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.a: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.b: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
Ambíguo. De fato, a remoção de piscinas se torna possível após a injeção. Ou seja, esse aviso não é relevante para esse parâmetro. Ok, mas ainda existem centenas de parâmetros, incluindo parâmetros muito úteis, que também têm um aviso e não há como verificar sua aplicabilidade real. No momento, eu não consigo entender pelo código quais parâmetros são aplicados após a injeção e quais não são. Para garantir a confiabilidade, você precisa reiniciar os serviços e isso, enfurece. Enfurece porque sei que existe um mecanismo de injeção.
E o VxFlex OS? Processos semelhantes como MON (no VxFlex é MDM), OSD (SDS no VxFlex) também possuem arquivos de configuração, nos quais existem dezenas de parâmetros para todos. É verdade que seus nomes também não dizem nada, mas a boa notícia é que nunca os recorremos a queimar tanto quanto em Ceph.
Dívida técnica
Quando você começa a conhecer o Ceph com a versão mais relevante para hoje, tudo parece bem e você deseja escrever um artigo positivo. Mas quando você mora com ele no prod da versão 0.80, tudo não parece tão otimista.
Antes do Jewel, os processos do Ceph eram executados como raiz. A Jewel decidiu que eles deveriam trabalhar com o usuário 'ceph' e isso exigia uma mudança de propriedade para todos os diretórios usados pelos serviços Ceph. Parece que isso? Imagine um OSD que atenda a um disco magnético SATA de 2 TB com capacidade total. Portanto, a exibição desse disco, em paralelo (para subdiretórios diferentes) com uma utilização completa do disco, leva de 3 a 4 horas. Imagine, por exemplo, você ter 3 centenas desses discos. Mesmo se você atualizar os nós (exibir imediatamente de 8 a 12 discos), você receberá uma atualização bastante longa, na qual o cluster terá OSD de versões diferentes e uma réplica de dados será menor no momento em que o servidor for atualizado. Em geral, pensamos que era absurdo, reconstruímos os pacotes Ceph e deixamos o OSD rodando como root. Decidimos que, ao inserir ou substituir o OSD, os transferiremos para um novo usuário. Agora estamos alterando 2-3 unidades por mês e adicionando 1-2, acho que podemos lidar com isso até 2022).
Ajustáveis CRUSH
CRUSH é o coração de Ceph, tudo gira em torno dele. Esse é o algoritmo pelo qual, de maneira pseudo-aleatória, o local dos dados é selecionado e, graças ao qual os clientes que trabalham com o cluster RADOS descobrem em qual OSD os dados (objetos) de que precisam estão armazenados. O principal recurso do CRUSH é que não há necessidade de servidores de metadados, como Luster ou IBM GPFS (agora Spectrum Scale). O CRUSH permite que clientes e OSD interajam diretamente entre si. Embora, é claro, seja difícil comparar o armazenamento de objetos RADOS e os sistemas de arquivos primitivos, que dei como exemplo, mas acho que a ideia é clara.
Os ajustáveis do CRUSH, por sua vez, são um conjunto de parâmetros / sinalizadores que afetam a operação do CRUSH, tornando-o mais eficiente, pelo menos em teoria.
Portanto, ao atualizar do Hammer para o Jewel (teste naturalmente), um aviso apareceu, dizendo que o perfil ajustável pode ter parâmetros que não são ideais para a versão atual (Jewel) e é recomendável mudar o perfil para o ideal. Em geral, tudo está claro. O dock diz que isso é muito importante e é o caminho certo, mas também é dito que após a troca de dados haverá uma rebelião de 10% dos dados. 10% - não parece assustador, mas decidimos testá-lo. Para um cluster, é cerca de 10 vezes menor do que em um produto, com o mesmo número de PGs por OSD, preenchidos com dados de teste, obtemos uma rebelião de 60%! Imagine, por exemplo, com 100 TB de dados, 60 TB começam a se mover entre OSDs e isso ocorre com a carga constante do cliente exigindo latência! Se ainda não disse, fornecemos o s3 e não temos muito menos carga no rgw mesmo à noite, dos quais existem 8 e 4 em sites estáticos. Em geral, decidimos que esse não era o nosso caminho, principalmente porque a reconstrução da nova versão, com a qual não havíamos trabalhado no prod, era pelo menos otimista demais. Além disso, tínhamos grandes índices de bucket que estão sendo reconstruídos muito pouco e esse também foi o motivo do atraso na mudança de perfil. Sobre os índices serão separadamente um pouco mais baixos. No final, simplesmente removemos o aviso e decidimos voltar a ele mais tarde.
E ao alternar o perfil nos testes, os cephfs-clients que estão nos kernels do CentOS 7.2 caíram porque não puderam trabalhar com o algoritmo de hash mais novo do novo perfil que veio. Não usamos cephfs no prod, mas se costumávamos usar, esse seria outro motivo para não mudar de perfil.
A propósito, o banco dos réus diz que se o que acontece durante a rebelião não combina com você, você pode reverter o perfil. De fato, após uma instalação limpa da versão Hammer e a atualização para o Jewel, o perfil fica assim:
> ceph osd crush show-tunables { ... "straw_calc_version": 1, "allowed_bucket_algs": 22, "profile": "unknown", "optimal_tunables": 0, ... }
É importante que seja "desconhecido" e se você tentar interromper a reconstrução alternando para "legado" (como declarado no banco dos réus) ou mesmo para "martelar", a rebelião não irá parar, apenas continuará de acordo com outros ajustáveis, e não " ideal ". Em geral, tudo precisa ser minuciosamente verificado e verificado, o ceph não é confiável.
CRUSH trade-of
Como você sabe, tudo neste mundo é equilibrado e as desvantagens são aplicadas a todas as vantagens. A desvantagem do CRUSH é que os PGs são distribuídos de maneira desigual entre diferentes OSDs, mesmo com o mesmo peso do último. Além disso, nada impede que diferentes PGs cresçam em velocidades diferentes, enquanto a função hash cairá. Especificamente, temos uma faixa de utilização de OSD de 48 a 84%, apesar de terem o mesmo tamanho e, consequentemente, peso. Até tentamos igualar os servidores em peso, mas é assim, apenas o nosso perfeccionismo, nada mais. E com o fato de que as E / Ss são distribuídas de maneira desigual entre os discos, o pior é que, quando você alcança o status completo (95%) de pelo menos um OSD no cluster, toda a gravação é interrompida e o cluster passa a ser apenas leitura. Todo o aglomerado! E não importa que o cluster ainda esteja cheio de espaço. Tudo, a final, sai! Esse é um recurso arquitetônico do CRUSH. Imagine que você está de férias, algum OSD quebrou a marca de 85% (o primeiro aviso por padrão) e você tem 10% em estoque para impedir que a gravação pare. E 10% com gravação ativa não é muito / muito longo. Idealmente, com esse projeto, o Ceph precisa de uma pessoa de plantão que possa seguir as instruções preparadas nesses casos.
Então, decidimos que isso significa desequilibrar os dados no cluster, porque vários OSDs estavam próximos da marca quase completa (85%).
Existem várias maneiras:
A maneira mais fácil é um pouco de desperdício e não muito eficaz, porque os dados em si podem não sair do OSD lotado ou o movimento será insignificante.
- Alterar o peso permanente do OSD (PESO)
Isso leva a uma alteração no peso de toda a hierarquia de bucket mais alta (terminologia CRUSH), servidor OSD, data center etc. e, como resultado, à movimentação de dados, inclusive daqueles que não são necessários.
Tentamos, reduzimos o peso de um OSD, depois que os dados de reconstrução de outro foram preenchidos, reduzimos e depois o terceiro e percebemos que tocaríamos isso por um longo tempo.
- Alterar o peso OSD não permanente (REWEIGHT)
Isto é o que é feito chamando 'ceph osd reweight-by-use'. Isso leva a uma alteração no chamado peso de ajuste do OSD, e o peso do balde superior não muda. Como resultado, os dados são balanceados entre diferentes OSDs de um servidor, por assim dizer, sem ir além dos limites do intervalo CRUSH. Realmente gostamos dessa abordagem, analisamos o funcionamento a seco que mudanças seriam e as que ocorreram no produto. Tudo correu bem até que o processo de rebeldia tenha uma participação no meio. Mais uma vez pesquisando no Google, lendo boletins, experimentando diferentes opções e, no final, a parada foi causada pela falta de alguns ajustes no perfil mencionado acima. Novamente fomos apanhados em dívidas técnicas. Como resultado, seguimos o caminho de adicionar discos e a reconstrução mais ineficaz. Felizmente, ainda precisávamos fazer isso porque Foi planejado mudar o perfil CRUSH com uma margem suficiente em capacidade.
Sim, conhecemos o balanceador (Luminoso e superior), que faz parte do mgr, projetado para resolver o problema de distribuição desigual de dados movendo o PG entre OSDs, por exemplo, à noite. Mas ainda não ouvi críticas positivas sobre seu trabalho, mesmo no atual Mimic.
Você provavelmente dirá que a dívida técnica é puramente um problema nosso e eu provavelmente concordaria. Mas por quatro anos com Ceph no produto, tivemos apenas um tempo de inatividade s3 registrado, que durou uma hora inteira. E então, o problema não estava no RADOS, mas no RGW, que, tendo digitado seus 100 threads padrão, ficou travado e a maioria dos usuários não atendeu às solicitações. Ainda estava no Hammer. Na minha opinião, este é um bom indicador e é alcançado devido ao fato de não fazermos movimentos bruscos e sermos bastante céticos em relação a tudo no Ceph.
Wild gc
Como você sabe, excluir dados diretamente do disco é uma tarefa bastante exigente e, em sistemas avançados, a exclusão é atrasada ou não é realizada. O Ceph também é um sistema avançado e, no caso do RGW, ao excluir um objeto s3, os objetos RADOS correspondentes não são excluídos imediatamente do disco. O RGW marca os objetos s3 como excluídos e um gc-stream separado exclui os objetos diretamente dos pools RADOS e, portanto, é adiado dos discos. Após a atualização para Luminous, o comportamento do gc mudou notavelmente, ele começou a trabalhar de forma mais agressiva, embora os parâmetros do gc continuassem os mesmos. Pela palavra visivelmente, quero dizer que começamos a ver o gc trabalhando no monitoramento externo do serviço para aumentar a latência. Isso foi acompanhado por um IO alto no pool rgw.gc. Mas o problema que enfrentamos é muito mais épico do que apenas IO. Quando o gc está em execução, muitos logs do formulário são gerados:
0 <cls> /builddir/build/BUILD/ceph-12.2.5/src/cls/rgw/cls_rgw.cc:3284: gc_iterate_entries end_key=1_01530264199.726582828
Onde 0 no início é o nível de registro no qual esta mensagem é impressa. Por assim dizer, não há lugar para baixar o log abaixo de zero. Como resultado, ~ 1 GB de logs foram gerados em nós por um OSD em algumas horas, e tudo ficaria bem se os nós ceph não estivessem sem disco ... Carregamos o sistema operacional via PXE diretamente na memória e não usamos disco local ou NFS, NBD para a partição do sistema (/) Acontece servidores sem estado. Após uma reinicialização, todo o estado é rolado pela automação. Como funciona, descreverei de alguma forma em um artigo separado, agora é importante que 6 GB de memória sejam alocados para "/", dos quais ~ 4 geralmente são gratuitos. Enviamos todos os logs para o Graylog e usamos uma política de rotação de logs bastante agressiva e geralmente não temos problemas com o estouro de disco / RAM. Mas não estávamos prontos para isso, com 12 OSDs, o servidor "/" encheu-se muito rapidamente, os atendentes no prazo não responderam ao gatilho no Zabbix e o OSD começou a parar devido à incapacidade de gravar um log. Como resultado, reduzimos a intensidade de gc, o ticket não foi iniciado porque Ele já estava lá e adicionamos um script ao cron, no qual forçamos os logs OSD a truncar quando uma certa quantia é excedida sem aguardar a rotação do log. A propósito, o nível de registro foi aumentado .
Grupos de canais e escalabilidade elogiada
Na minha opinião, PG é a abstração mais difícil de entender. O PG é necessário para tornar o CRUSH mais eficaz. O principal objetivo do PG é agrupar objetos para reduzir o consumo de recursos, aumentar a produtividade e a escalabilidade. Endereçar objetos diretamente, individualmente, sem combiná-los no PG seria muito caro.
O principal problema do PG é determinar seu número para um novo pool. No blog Ceph:
"Escolher o número certo de PGs para o seu cluster é um pouco de arte negra - e um pesadelo na usabilidade".
Isso é sempre muito específico para uma instalação específica e requer muita reflexão e cálculo.
Principais recomendações:
- Muitos PGs no OSD são ruins; haverá um gasto excessivo de recursos para manutenção e freios durante o reequilíbrio / recuperação.
- Poucos PGs no OSD são ruins, o desempenho sofrerá e os OSDs serão preenchidos de maneira desigual.
- O número PG deve ser um múltiplo de grau 2. Isso ajudará a obter o "poder do CRUSH".
E aqui queima comigo. PGs não são limitados em volume ou no número de objetos. Quantos recursos (em números reais) são necessários para atender um PG? Depende do seu tamanho? Depende do número de réplicas deste PG? Devo tomar banho a vapor se tiver memória suficiente, CPUs rápidas e uma boa rede?
E você também precisa pensar sobre o crescimento futuro do cluster. O número do PG não pode ser reduzido - apenas aumentado. Ao mesmo tempo, não é recomendável fazer isso, pois isso implicará, em essência, a divisão de parte do PG na reconstrução nova e selvagem.
"Aumentar a contagem de PG de um pool é um dos eventos mais impactantes em um Ceph Cluster e deve ser evitado para clusters de produção, se possível."
Portanto, você precisa pensar no futuro imediatamente, se possível.
Um exemplo real.
Um cluster de 3 servidores com OSD de 14x2 TB cada, um total de 42 OSDs. Réplica 3, local útil ~ 28 TB. Para ser usado no S3, você precisa calcular o número de PGs para o conjunto de dados e o conjunto de índices. O RGW usa mais pools, mas os dois são primários.
Entramos na calculadora PG (existe uma calculadora), consideramos com os 100 PG recomendados no OSD, obtemos apenas 1312 PG. Mas nem tudo é tão simples: temos uma introdução - o cluster definitivamente crescerá três vezes em um ano, mas o ferro será comprado um pouco mais tarde. Aumentamos "PGs alvo por OSD" três vezes, para 300 e obtemos 4480 PG.
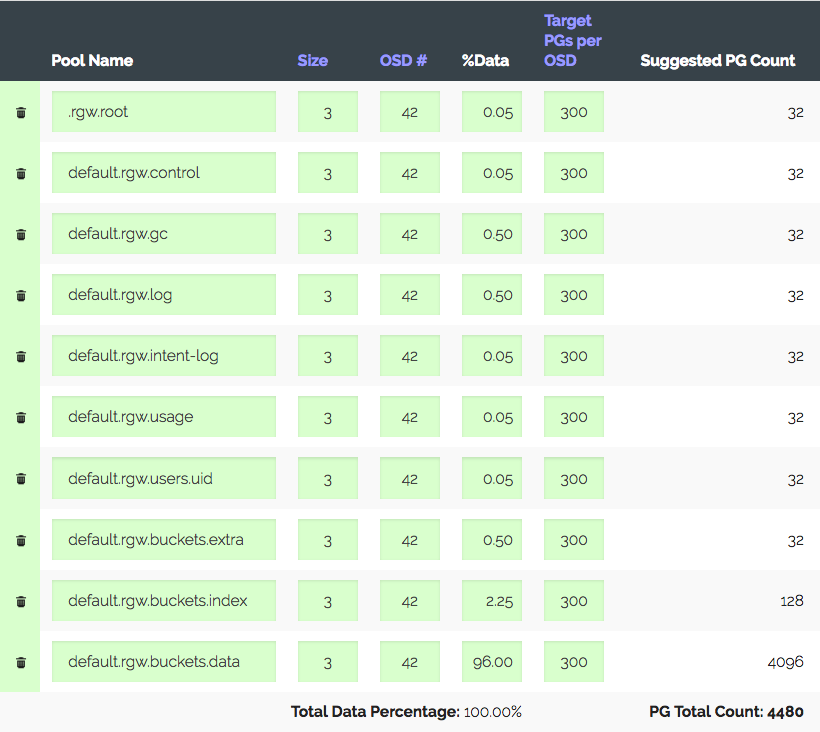
Defina o número de PGs para os pools correspondentes - recebemos um aviso: muitos PG por OSD ... chegaram. Recebeu ~ 300 PG no OSD com um limite de 200 (Luminoso). A propósito, costumava ser 300. E o mais interessante é que nem todos os PGs desnecessários podem espiar, ou seja, isso não é apenas um aviso. Como resultado, acreditamos que estamos fazendo tudo certo, aumentando limites, desativando o aviso e seguindo em frente.
Outro exemplo real é mais interessante.
S3, volume utilizável de 152 TB, OSD 252 a 1,81 TB, ~ 105 PG no OSD. O cluster cresceu gradualmente, tudo correu bem até que, com as novas leis em nosso país, era necessário aumentar para 1 PB, ou seja, ~ ~ 850 TB e, ao mesmo tempo, você precisava manter o desempenho, que agora é muito bom para o S3. Suponha que pegamos discos de 6 TB (5,7 reais) e, levando em consideração a réplica 3, obtemos + 447 OSD. Levando em conta os atuais, obtemos 699 OSDs com 37 PGs cada e, se levarmos em conta pesos diferentes, os OSDs antigos têm apenas uma dúzia de PGs. Então você me diz o quão tolerável isso vai funcionar? O desempenho de um cluster com um número diferente de PGs é bastante difícil de medir sinteticamente, mas os testes que eu conduzi mostram que, para um desempenho ideal, é necessário de 50 PG a OSD de 2 TB. E quanto a mais crescimento? Sem aumentar o número de PG, você pode ir para o mapeamento de PG para OSD 1: 1. Talvez eu não entenda alguma coisa?
Sim, você pode criar um novo pool para o RGW com o número desejado de PGs e mapear uma região S3 separada para ele. Ou até mesmo criar um novo cluster nas proximidades. Mas você deve admitir que essas são todas muletas. E acontece que parece um Ceph bem escalável devido ao seu conceito, o PG é escalável com reservas. Você terá que conviver com vorings desativados na preparação para o crescimento ou, em algum momento, reconstruir todos os dados no cluster ou pontuar no desempenho e viver com o que acontece. Ou passar por tudo isso.
Fico feliz que os desenvolvedores do Ceph entendam que o PG é uma abstração complexa e supérflua para o usuário e é melhor ele não saber disso.
"No Luminous, tomamos as principais medidas para finalmente eliminar uma das maneiras mais comuns de levar seu cluster a um fosso. Esperamos, com o futuro, ocultar os PGs por completo para que eles não sejam algo que a maioria dos usuários precise saber ou pense em ".
No vxFlex, não há conceito de PG ou qualquer análogo. Você acabou de adicionar discos ao pool e é isso. E assim por diante até 16 PB. Imagine, nada precisa ser calculado, não há montes de status desses PGs; os discos são descartados uniformemente durante o crescimento. Porque os discos são fornecidos ao vxFlex como um todo (não existe um sistema de arquivos em cima deles), não há como avaliar a plenitude e não existe esse problema. Eu nem sei como transmitir a você como é agradável.
"Precisa esperar pelo SP1"
Outra história de "sucesso". Como você sabe, o RADOS é o armazenamento de valor-chave mais primitivo. O S3, implementado sobre o RADOS, também é primitivo, mas ainda um pouco mais funcional. , S3 . , , RGW . — RADOS-, OSD. . , . OSD down. , , . , scrub' . , - 503, .
Bucket Index resharding — , (RADOS-) , , OSD, .
, , Jewel ! Hammer, .. -. ?
Hammer 20+ , , OSD Graylog , . , .. IO . Luminous, .. . Luminous, , . , . IO index-, , . , IO , . , … ; , :
, . , .. , .
, Hammer->Jewel - . OSD - . , OSD .
— , , . Hammer s3, . , . , , etag, body, . . , . Suspend . "" . , .
, 2 — , Cloudmouse. , Ceph, , .
vxFlex OS 2 . , . , . , . , , , Dell EMC.
. , ? . , . , Ceph, vxFlex . - . , .
9 ceph-devel : , CPU ( Xeon' !) IOPS All-NVMe Ceph 12.2.7 bluestore.
, , "" Ceph . ( Hammer) Ceph , s3 . , ScaleIO Ceph RBD . Ceph, — CPU. RDMA InfiniBand, jemalloc . , 10-20 , iops, io, Ceph . vxFlex . — Ceph system time, scaleio — io wait. , bluestore, , , -, , Ceph. ScaleIO . , , Ceph Dell EMC.
, , PG. (), IO. - PG IO, , . , nearfull. , .
vxFlex - , . ( ceph-volume), , .
Scrub
, . , , Ceph.
, . " " — - , . , 2 TB >50%, Ceph, . . , .
vxFlex OS , , . — bandwidth . . , .
, , vxFlex scrub-error. Ceph 2 .
Luminous — . . MGR- Zabbix (3 ). . , , - IO , gc, . — RGW .

. .
S3, "" :
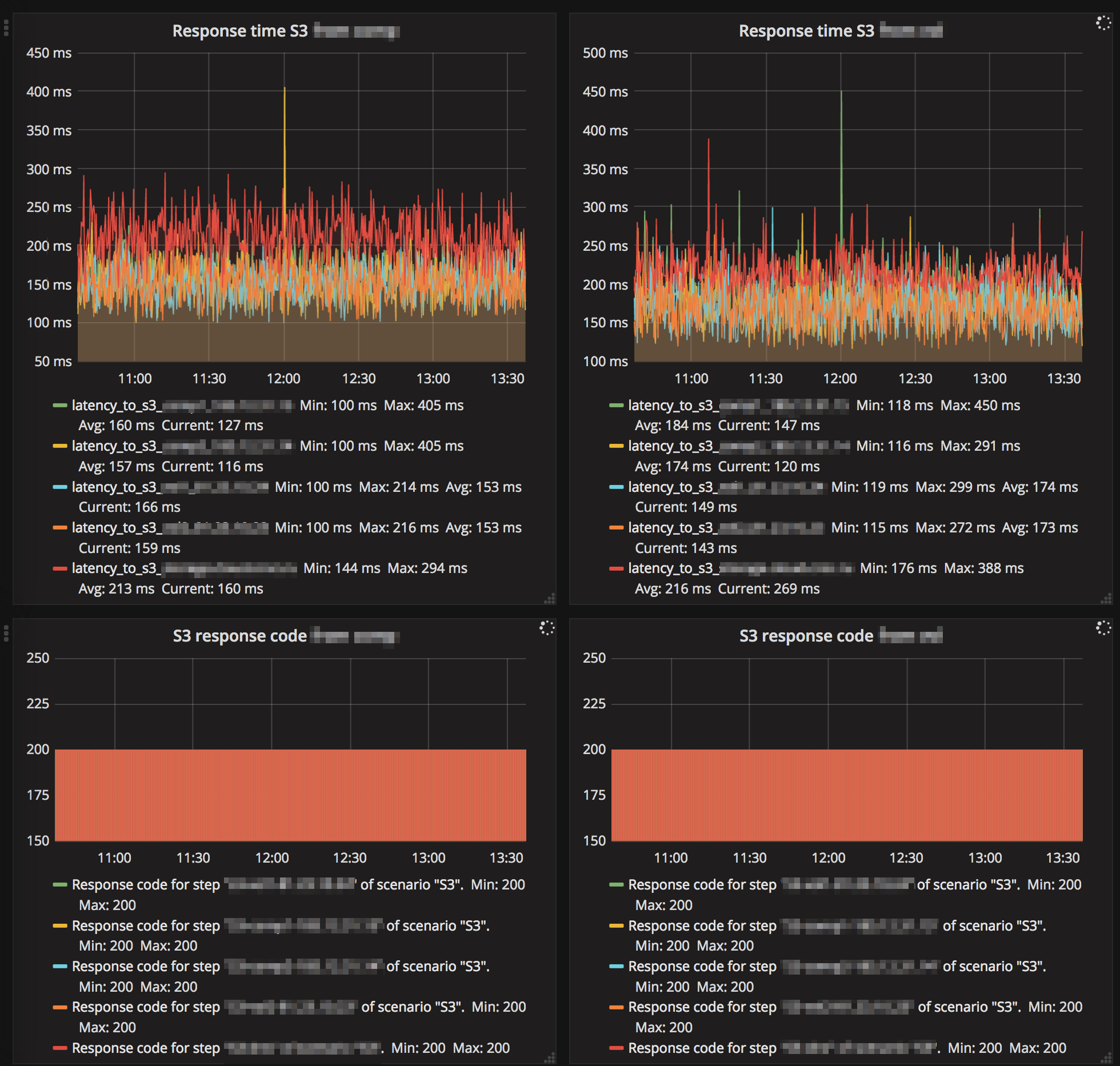
Ceph , , , , .
, eph Graylog GELF . , , OSD down, out, failed . , , OSD down , .
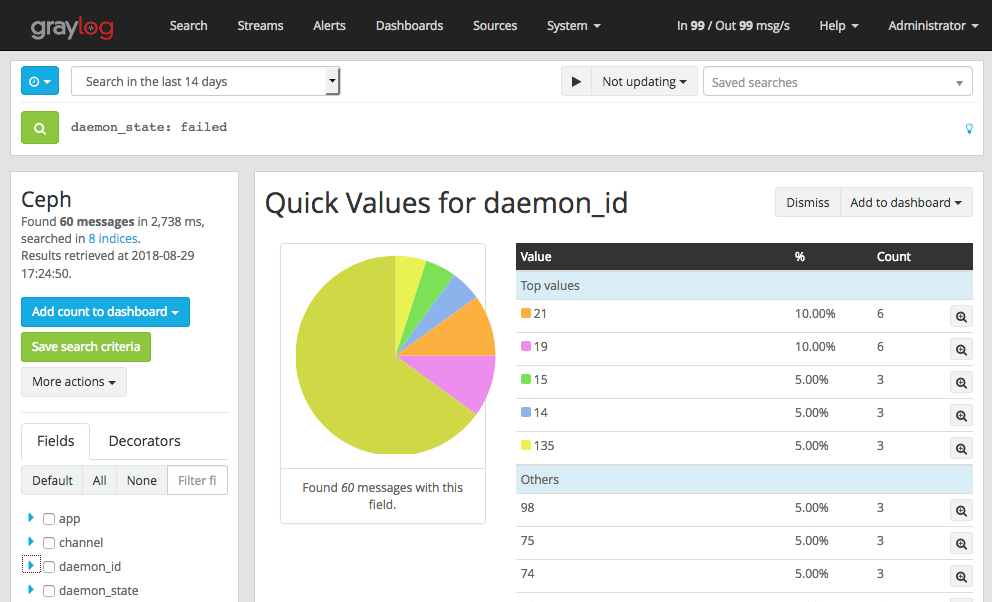
- , OSD heartbeat failed (. ). vm.zone_reclaim_mode=1 NUMA.
Ceph. c vxFlex . :
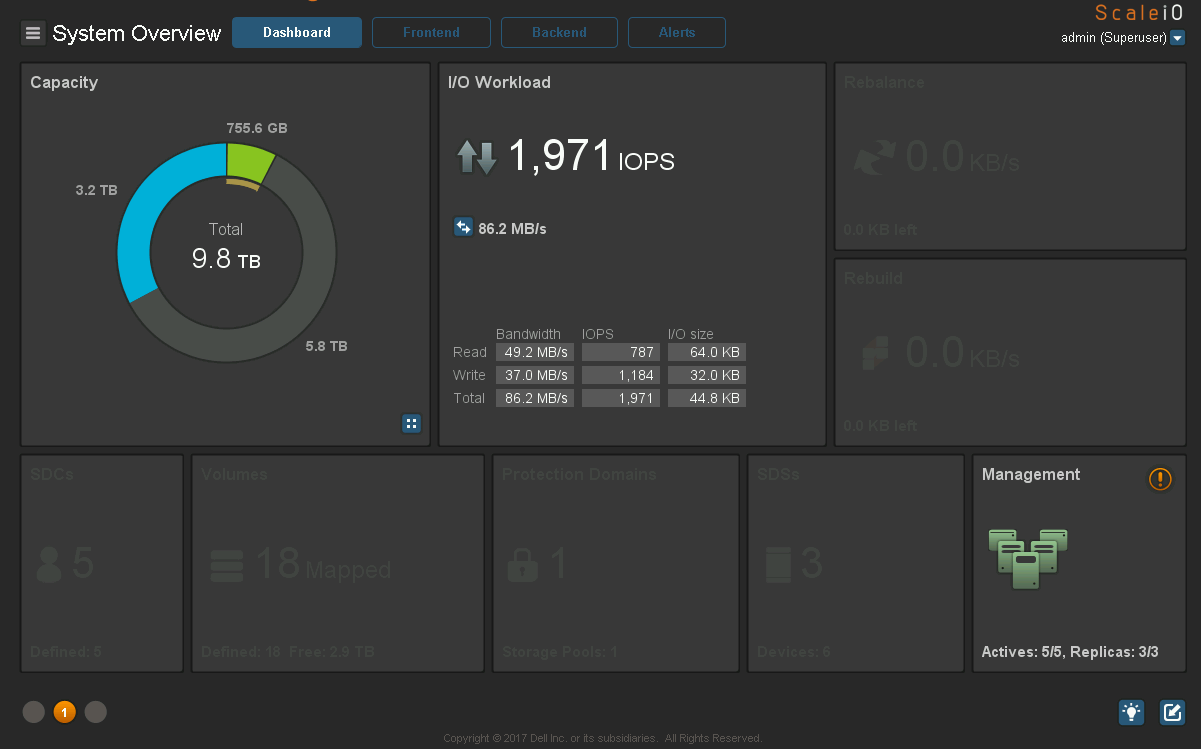
:

IO :
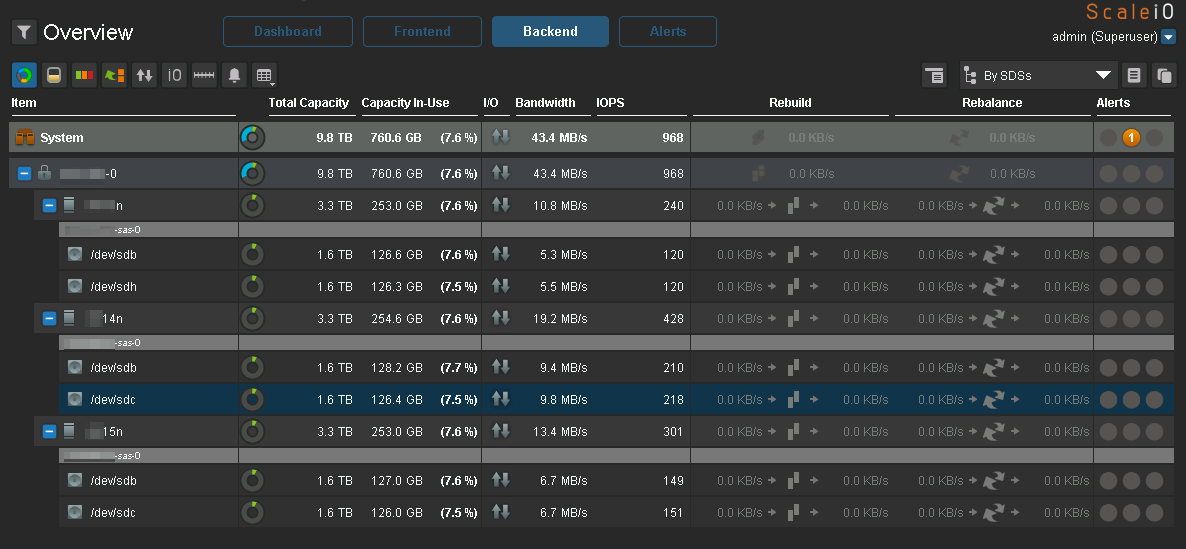
IO, Ceph.
:
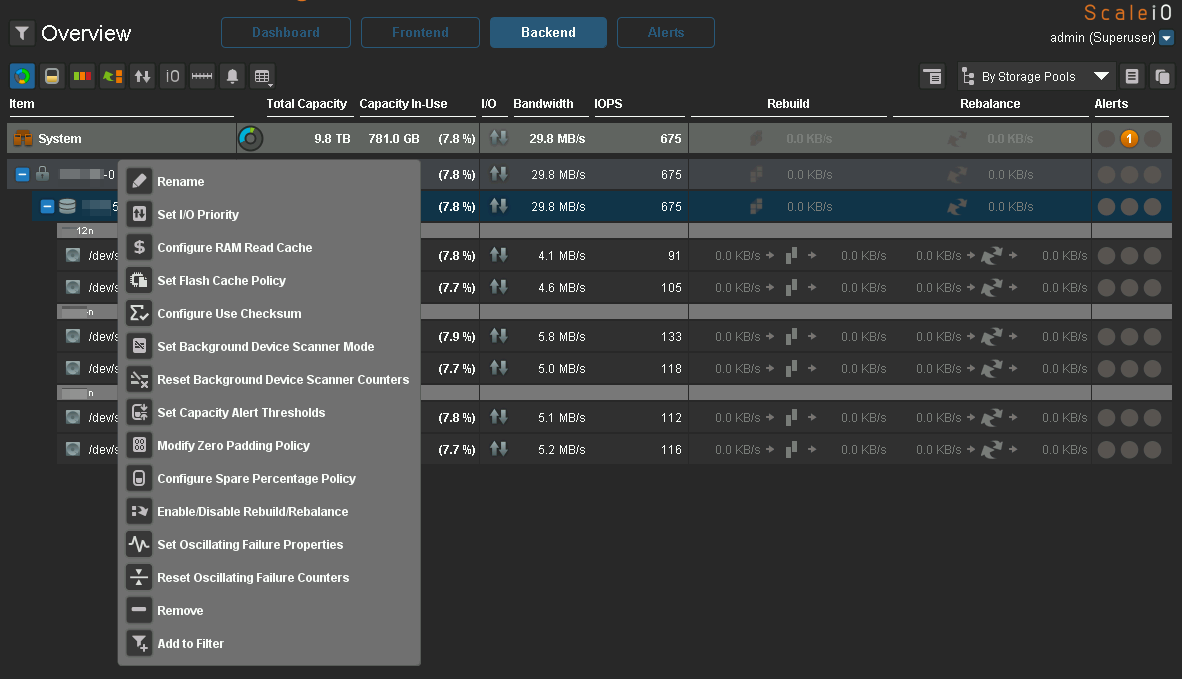
Ceph, Luminous . 2.0, Mimic , .
vxFlex
Degraded state , .
vxFlex — RH . 7.5 , . Ceph RBD cephfs — .
vxFlex Ceph. vxFlex — , , , .
16 PB, . eph 2 PB …
Conclusão
, Ceph , , , Ceph — . .
, Ceph " ". , " , , R&D, - ". . " ", Ceph , , .
Ceph 2k18 , . 24/7 ( S3, , EBS), , Ceph . , . — . / maintenance backfilling , c Ceph , , .
Ceph ? , " ". Ceph. . , , , , …
!
HEALTH_OK!