Não vale a pena falar em detalhes sobre o conceito de computação lenta. A idéia de fazer a mesma coisa com menos frequência, especialmente se for longa e pesada, é tão antiga quanto o mundo. Porque imediatamente ao ponto.
Segundo o autor deste texto, um lenificador normal deve:
- Salve os cálculos entre as chamadas do programa.
- Rastreie as alterações na árvore de cálculo.
- Possui sintaxe moderadamente transparente.

Conceito
Em ordem:
- Salve os cálculos entre as chamadas do programa:
De fato, se chamamos o mesmo script várias dezenas de centenas de vezes por dia, por que devemos recalcular o mesmo cada vez que o script é chamado, se é possível armazenar o objeto de resultado em um arquivo. É melhor puxar um objeto do disco, mas ... devemos ter certeza de sua relevância. De repente, o script é reescrito e o objeto salvo está desatualizado. Com base nisso, não podemos carregar o objeto apenas com a existência de um arquivo. O segundo ponto segue a partir disso. - Acompanhe as alterações na árvore de cálculo:
A necessidade de atualizar o objeto deve ser calculada com base nos dados sobre os argumentos da função que o gera. Portanto, teremos certeza de que o objeto carregado é válido. De fato, para uma função pura, o valor de retorno depende apenas dos argumentos. Isso significa que, enquanto armazenamos em cache os resultados de funções puras e monitoramos a mudança de argumentos, podemos ter calma quanto à relevância do cache. Além disso, se o objeto calculado depender de outro objeto armazenado em cache (lento), que por sua vez depende de outro, será necessário trabalhar corretamente as alterações nesses objetos, atualizando oportunamente os nós da cadeia que deixaram de ser relevantes. Por outro lado, seria bom levar em consideração que nem sempre precisamos carregar os dados de toda a cadeia de cálculo. Freqüentemente, carregar apenas o objeto de resultado final é suficiente. - Possui sintaxe moderadamente transparente:
Este ponto é claro. Se, para reescrever o script para cálculos preguiçosos, for necessário alterar o código inteiro, essa é uma solução mais ou menos. As alterações devem ser feitas no mínimo.
Essa linha de raciocínio levou a uma solução técnica, denominada em python pela biblioteca evalcache (links no final do artigo).
Solução de sintaxe e mecanismo de trabalho
Exemplo simplesimport evalcache import hashlib import shelve lazy = evalcache.Lazy(cache = shelve.open(".cache"), algo = hashlib.sha256) @lazy def summ(a,b,c): return a + b + c @lazy def sqr(a): return a * a a = 1 b = sqr(2) c = lazy(3) lazyresult = summ(a, b, c) result = lazyresult.unlazy() print(lazyresult)
Como isso funciona?
A primeira coisa que chama sua atenção aqui é a criação do decorador preguiçoso. Essa solução sintática é bastante padrão para os pitães Python. O decorador lento é passado para um objeto de cache no qual o lenificator armazenará os resultados dos cálculos. Os requisitos da interface do tipo dict são sobrepostos ao tipo de cache. Em outras palavras, podemos armazenar em cache tudo o que implementa a mesma interface que o tipo de ditado. Para demonstrar no exemplo acima, usamos o dicionário da biblioteca de arquivar.
O decorador também recebe um protocolo de hash que ele usará para construir chaves de hash de objetos e algumas opções adicionais (permissão de gravação, permissão de leitura, saída de depuração), que podem ser encontradas na documentação ou no código.
O decorador pode ser aplicado a funções e objetos de outros tipos. Nesse momento, um objeto lento é construído com base em uma chave de hash calculada com base na representação (ou usando uma função de hash especialmente definida para esse tipo de função).
Um recurso importante da biblioteca é que um objeto lento pode gerar outros objetos preguiçosos, e o hash do pai (ou pais) será misturado à chave de hash do descendente. Para objetos preguiçosos, é permitido o uso da operação de obter um atributo, o uso de chamadas ( __call__ ) de objetos e o uso de operadores.
Ao passar por um script, de fato, nenhum cálculo é realizado. Para b, o quadrado não é calculado e para o resultado lazyres, a soma dos argumentos não é considerada. Em vez disso, uma árvore de operações é construída e chaves de hash de objetos preguiçosos são calculadas.
Cálculos reais (se o resultado não tiver sido colocado anteriormente no cache) serão executados apenas na linha: result = lazyresult.unlazy()
Se o objeto foi calculado anteriormente, ele será carregado a partir do arquivo.
Você pode visualizar a árvore de construção:
Criar visualização em árvore evalcache.print_tree(lazyresult) ... generic: <function summ at 0x7f1cfc0d5048> args: 1 generic: <function sqr at 0x7f1cf9af29d8> args: 2 ------- 3 -------
Como os hashes dos objetos são construídos com base nos dados dos argumentos que geram esses objetos, quando o argumento muda, o hash do objeto muda e, com ele, os hashes de toda a cadeia, dependendo dele. Isso permite que você mantenha os dados do cache atualizados, fazendo atualizações no prazo.
Objetos preguiçosos se alinham em uma árvore. Se realizarmos uma operação preguiçosa em um dos objetos, exatamente quantos objetos serão carregados e contados conforme necessário para obter um resultado válido. Idealmente, o objeto necessário simplesmente será carregado. Nesse caso, o algoritmo não puxará objetos formadores para a memória.
Em ação
Acima foi um exemplo simples que mostra a sintaxe, mas não demonstra o poder computacional da abordagem.
Aqui está um exemplo um pouco mais próximo da vida real (usado pelo sympy).
Exemplo usando sympy e numpy Operações para simplificar expressões simbólicas são extremamente caras e pedem literalmente lenificação. A construção adicional de uma grande variedade leva ainda mais tempo, mas, graças à lenificação, os resultados serão extraídos do cache. Observe que, se quaisquer coeficientes forem alterados na parte superior do script em que a expressão sympy é gerada, os resultados serão recalculados porque a chave de hash do objeto lento será alterada (graças às declarações __repr__ ).
Muitas vezes, uma situação ocorre quando um pesquisador realiza experimentos computacionais em um objeto gerado por um longo tempo. Ele pode usar vários scripts para separar a geração e o uso do objeto, o que pode causar problemas com a atualização prematura dos dados. A abordagem proposta pode facilitar esse caso.
O que é isso tudo?
evalcache faz parte do projeto zencad. Este é um pequeno script cadic, inspirado e explorando as mesmas idéias do openscad. Diferentemente do openscad orientado a malha, o zencad em execução no núcleo opencascade usa uma representação brep de objetos, e os scripts são escritos em python.
As operações geométricas são frequentemente realizadas por um longo período de tempo. A desvantagem dos sistemas de script cad é que toda vez que você executa o script, o produto é completamente recontado novamente. Além disso, com o crescimento e a complicação do modelo, os custos indiretos não crescem linearmente. Isso leva ao fato de que você pode trabalhar confortavelmente apenas com modelos extremamente pequenos.
A tarefa do evalcache era amenizar esse problema. No zencad, todas as operações são declaradas preguiçosas.
Exemplos:
Exemplo de construção de modelo
Este script gera o seguinte modelo:
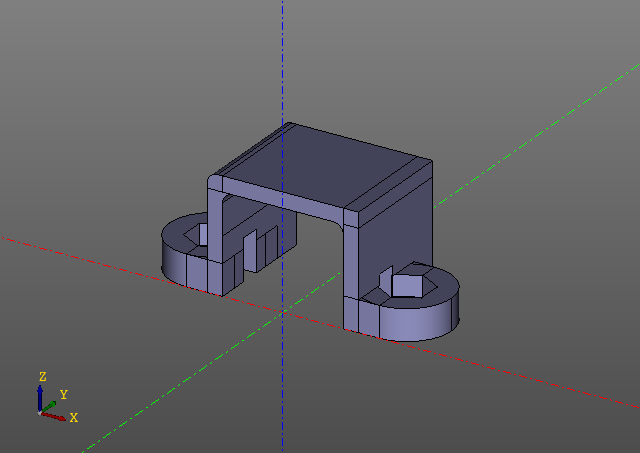
Observe que não há chamadas evalcache no script. O truque é que a lenificação é incorporada na própria biblioteca do zencad e nem é visível à primeira vista, embora todo o trabalho aqui esteja trabalhando com objetos preguiçosos, e o cálculo direto seja realizado apenas na função 'display'. Obviamente, se algum parâmetro do modelo for alterado, o modelo será recontado do local onde a primeira chave de hash foi alterada.
Modelos de computação volumososAqui está outro exemplo. Desta vez, nos limitaremos a fotos:
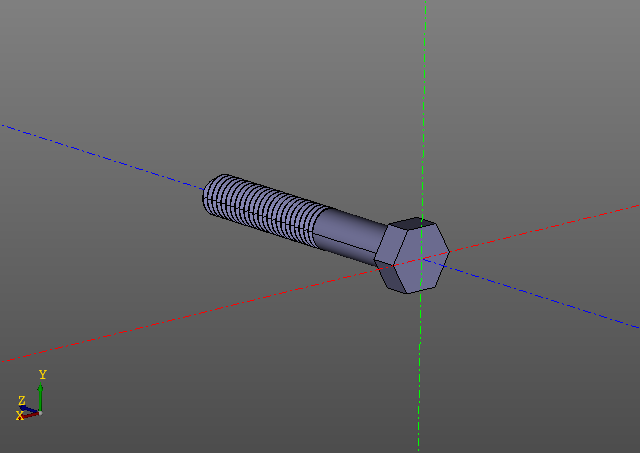
O cálculo de uma superfície rosqueada não é uma tarefa fácil. No meu computador, esse parafuso é construído na ordem de dez segundos ... A edição de um modelo com threads é muito mais agradável usando o cache.
E agora isso é um milagre:

Cruzar superfícies rosqueadas é uma tarefa computacional complexa. Valor prático, no entanto, nada além de verificar a matemática. O cálculo leva um minuto e meio. Um objetivo digno de lenificação.
Os problemas
O cache pode não funcionar como planejado.
Os erros de cache podem ser divididos em falso positivo e falso negativo .
Erros negativos falsos
Erros de falso negativo são situações em que o resultado do cálculo está no cache, mas o sistema não o encontrou.
Isso acontece se o algoritmo de chave de hash usado pelo evalcache, por algum motivo, produziu uma chave diferente para recálculo. Se a função hash não for substituída pelo objeto do tipo em cache, o evalcache utilizará o __repr__ objeto para construir a chave.
Ocorre um erro, por exemplo, se a classe que está sendo object.__repr__ não substituir o object.__repr__ padrão object.__repr__ , que muda do início ao início. Ou, se o __repr__ substituído, depende de alguma forma insignificante para o cálculo dos dados alterados (como o endereço do objeto ou o carimbo de data / hora).
Ruim:
class A: def __init__(self): self.i = 3 A_lazy = lazy(A) A_lazy().unlazy()
Bom:
class A: def __init__(self): self.i = 3 def __repr__(self): return "A({})".format(self.i) A_lazy = lazy(A) A_lazy().unlazy()
Os erros falsos negativos levam ao fato de que a lenificação não funciona. O objeto será recontado a cada nova execução de script.
Erros de falsos positivos
Este é um tipo de erro mais vil, pois leva a erros no objeto final de cálculo:
Isso pode acontecer por duas razões.
- Incrível:
Ocorreu uma colisão de chave de hash no cache. Para o algoritmo sha256 com um espaço de 115792089237316195423570985008687907853269984665640564039457584007913129639936 chaves possíveis, a probabilidade de uma colisão é desprezível. - Provável:
Uma representação de um objeto (ou uma função de hash substituída) não a descreve completamente ou coincide com a representação de um objeto de outro tipo.
class A: def __init__(self): self.i = 3 def __repr__(self): return "({})".format(self.i) class B: def __init__(self): self.i = 3 def __repr__(self): return "({})".format(self.i) A_lazy = lazy(A) B_lazy = lazy(B) a = A_lazy().unlazy() b = B_lazy().unlazy()
Ambos os problemas estão relacionados a um objeto __repr__ incompatível. Se, por algum motivo, for impossível substituir o tipo de objeto __repr__ , a biblioteca permitirá definir uma função de hash especial para o tipo de usuário.
Sobre análogos
Existem muitas bibliotecas de lenificação que basicamente consideram suficiente executar um cálculo não mais de uma vez por chamada de script.
Existem muitas bibliotecas de cache de disco que, a seu pedido, salvarão um objeto com a chave necessária para você.
Mas ainda não consegui encontrar bibliotecas que permitissem resultados de armazenamento em cache na árvore de execução. Se houver, por favor, inseguro.
Referências:
Projeto Github
Projeto Pypi