Este artigo se concentrará no balanceamento de carga em projetos da web. Muitos acreditam que a solução para esse problema na distribuição de carga entre servidores - quanto mais preciso, melhor. Mas sabemos que isso não é inteiramente verdade.
A estabilidade do sistema é muito mais importante do ponto de vista comercial .
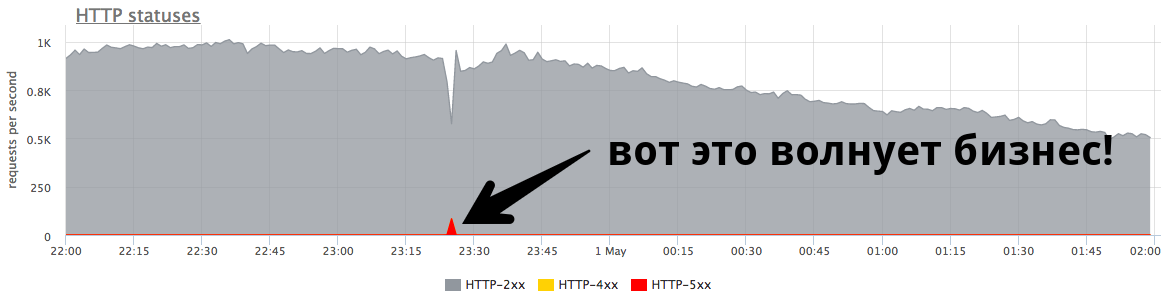
O pequeno pico de 84 RPS de "quinhentos" é de cinco mil erros que os usuários reais receberam. Isso é muito e é muito importante. É necessário procurar por razões, trabalhar com erros e tentar continuar a evitar tais situações.
Nikolay Sivko (
NikolaySivko ) em seu relatório no RootConf 2018 falou sobre os aspectos sutis e ainda não muito populares do balanceamento de carga:
- quando repetir a solicitação (tentativas);
- como selecionar valores para tempos limite;
- como não matar os servidores subjacentes no momento do acidente / congestionamento;
- se são necessários exames de saúde;
- como lidar com problemas de oscilação.
Sob decodificação de gato deste relatório.
Sobre o palestrante: Nikolay Sivko, cofundador da okmeter.io. Ele trabalhou como administrador de sistemas e líder de um grupo de administradores. Operação supervisionada em hh.ru. Ele fundou o serviço de monitoramento okmeter.io. Como parte deste relatório, o monitoramento da experiência de desenvolvimento é a principal fonte de casos.
Sobre o que vamos falar?
Este artigo irá falar sobre projetos da web. Abaixo está um exemplo de produção ao vivo: o gráfico mostra solicitações por segundo para um determinado serviço da web.
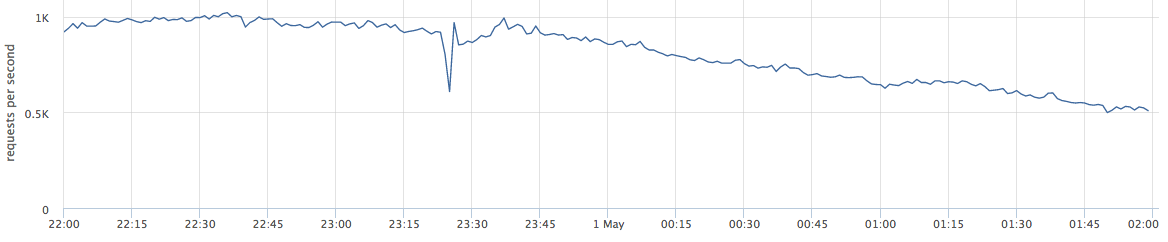
Quando falo sobre balanceamento, muitos o percebem como "precisamos distribuir a carga entre os servidores - quanto mais preciso, melhor".
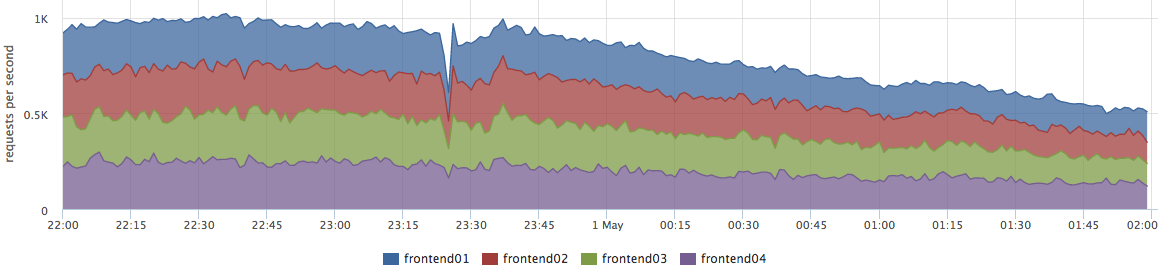
De fato, isso não é inteiramente verdade. Esse problema é relevante para um número muito pequeno de empresas. Mais frequentemente, os negócios estão preocupados com erros e estabilidade do sistema.
O pequeno pico no gráfico é "quinhentos", que o servidor retornou em um minuto e parou. Do ponto de vista de uma empresa, como uma loja on-line, esse pequeno pico a 84 RPS de "quinhentos" representa 5040 erros para usuários reais. Alguns não encontraram algo no seu catálogo, outros não puderam colocar as mercadorias na cesta. E isso é muito importante. Embora esse pico não pareça muito grande no gráfico,
é muito em usuários reais .
Como regra, todos têm esses picos, e os administradores nem sempre respondem a eles. Muitas vezes, quando uma empresa pergunta o que era, eles respondem:
- "Esta é uma pequena explosão!"
- "É apenas um lançamento rolando".
- "O servidor está morto, mas tudo já está em ordem."
- "Vasya trocou a rede de um dos back-ends."
Muitas vezes, as pessoas
nem tentam entender as razões pelas
quais isso aconteceu e não fazem nenhum pós-trabalho para que isso não aconteça novamente.
Ajuste fino
Chamei o relatório de “Ajuste fino” (Eng. Ajuste fino), porque pensei que nem todo mundo chegaria a essa tarefa, mas valeria a pena. Por que eles não chegam lá?
- Nem todo mundo chega nessa tarefa, porque quando tudo funciona, não é visível. Isso é muito importante para problemas. Fakapa não acontece todos os dias, e um problema tão pequeno requer esforços muito sérios para resolvê-lo.
- Você precisa pensar muito. Muitas vezes, o administrador - a pessoa que ajusta a balança - não é capaz de resolver esse problema independentemente. A seguir, veremos o porquê.
- Ele captura os níveis subjacentes. Essa tarefa está intimamente ligada ao desenvolvimento, com a adoção de decisões que afetam seu produto e seus usuários.
Afirmo que é hora de executar esta tarefa por vários motivos:- O mundo está mudando, se tornando mais dinâmico, há muitos lançamentos. Eles dizem que agora é correto liberar 100 vezes por dia, e o lançamento é o futuro fakap com uma probabilidade de 50 a 50 (assim como a probabilidade de encontrar um dinossauro)
- Do ponto de vista da tecnologia, tudo também é muito dinâmico. Kubernetes e outros orquestradores apareceram. Não há boa implantação antiga, quando um back-end em algum IP é desativado, uma atualização é rolada e o serviço é iniciado. Agora, no processo de lançamento no k8s, a lista de IP upstream está mudando completamente.
- Microsserviços: agora todos se comunicam pela rede, o que significa que você precisa fazer isso de forma confiável. O equilíbrio desempenha um papel importante.
Suporte de teste
Vamos começar com casos simples e óbvios. Para maior clareza, usarei uma bancada de testes. Este é um aplicativo Golang que fornece o http-200 ou você pode alterná-lo para o modo "give http-503".
Iniciamos 3 instâncias:
- 127.0.0.1:20001
- 127.0.0.1:20002
- 127.0.0.1:20003
Servimos 100rps via yandex.tank via nginx.
Nginx pronto para uso:
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; location / { proxy_pass http://backends; } }
Cenário primitivo
Em algum momento, ative um dos back-end no modo 503 e obteremos exatamente um terço dos erros.
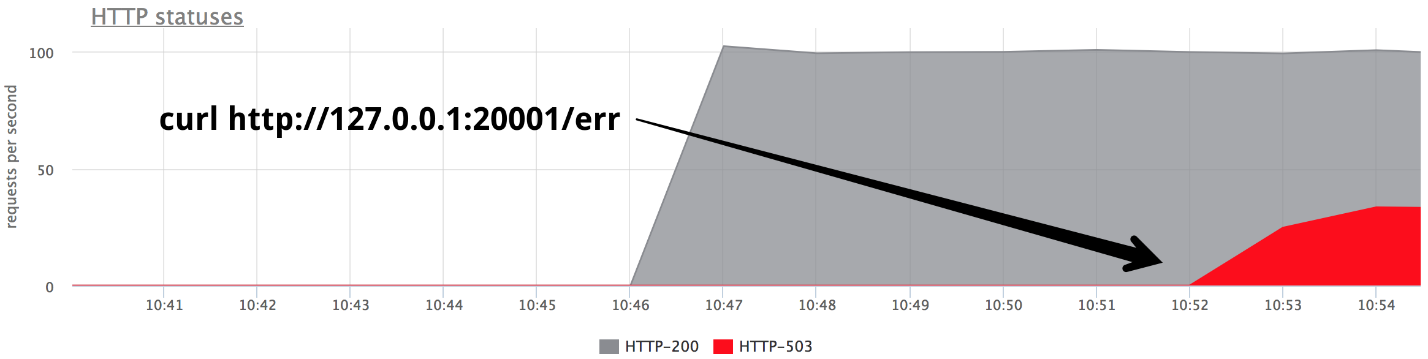
É claro que nada funciona imediatamente: o nginx não tenta novamente novamente se recebeu
alguma resposta do servidor.
Nginx default: proxy_next_upstream error timeout;
De fato, isso é bastante lógico do lado dos desenvolvedores do nginx: o nginx não tem o direito de decidir para você o que você deseja recuperar e o que não.
Portanto, precisamos de tentativas - tentativas e começamos a falar sobre elas.
Tentativas
É necessário encontrar um compromisso entre:
- A solicitação do usuário é santa, se machuca, mas responde. Queremos responder ao usuário a todo custo, o usuário é o mais importante.
- Melhor responder com um erro do que sobrecarregar os servidores.
- Integridade dos dados (para solicitações não idempotentes), ou seja, é impossível repetir certos tipos de solicitações.
A verdade, como sempre, está em algum lugar no meio - somos forçados a equilibrar entre esses três pontos. Vamos tentar entender o que e como.
Dividi as tentativas fracassadas em 3 categorias:
1.
Erro de transportePara o transporte HTTP é TCP e, como regra, aqui falamos sobre erros de configuração de conexão e tempos limite de configuração de conexão. No meu relatório, mencionarei três balanceadores comuns (falaremos um pouco mais sobre o Enviado):
- nginx : erros + tempo limite (proxy_connect_timeout);
- HAProxy : conexão de tempo limite;
- Enviado : falha na conexão + fluxo recusado.
O Nginx tem a oportunidade de dizer que uma tentativa com falha é um erro de conexão e um tempo limite de conexão; O HAProxy tem um tempo limite de conexão, o Envoy também tem tudo padrão e normal.
2.
Solicitar tempo limite:Suponha que tenhamos enviado uma solicitação ao servidor, conectada com êxito a ele, mas a resposta não chegue até nós, esperamos por ela e entendemos que não há sentido em esperar mais. Isso é chamado de tempo limite da solicitação:
- O Nginx possui: timeout (prox_send_timeout * + proxy_read_timeout *);
- O HAProxy possui OOPS :( - ele não existe em princípio. Muitas pessoas não sabem que o HAProxy, se tiver estabelecido uma conexão com sucesso, nunca tentará reenviar a solicitação.
- O enviado pode fazer tudo: timeout || per_try_timeout.
3.
status HTTPTodos os balanceadores, exceto o HAProxy, são capazes de processar, mesmo assim o back-end respondeu, mas com algum tipo de código incorreto.
- nginx : http_ *
- HAProxy : OOPS :(
- Enviado : 5xx, erro de gateway (502, 503, 504), retriable-4xx (409)
Timeouts
Agora, vamos falar detalhadamente sobre os intervalos, parece-me que vale a pena prestar atenção nisso. Não haverá mais ciência de foguetes - essas informações são simplesmente estruturadas sobre o que geralmente acontece e como elas se relacionam.
Tempo limite de conexão
O tempo limite de conexão é o tempo para estabelecer uma conexão. Essa é uma característica da sua rede e servidor específico e não depende da solicitação. Geralmente, o valor padrão para o tempo limite da conexão é definido como pequeno. Em todos os proxies, o valor padrão é grande o suficiente, e isso está errado - devem ser
unidades, às vezes dezenas de milissegundos (se estamos falando de uma rede em um DC).
Se você deseja identificar servidores problemáticos um pouco mais rápido que essas unidades - dezenas de milissegundos, você pode ajustar a carga no back-end, configurando um pequeno backlog para receber conexões TCP. Nesse caso, quando o backlog do aplicativo estiver cheio, você poderá solicitar ao Linux para redefini-lo para estourar o backlog. Em seguida, você poderá capturar o back-end sobrecarregado "ruim" um pouco antes do tempo limite da conexão:
fail fast: listen backlog + net.ipv4.tcp_abort_on_overflow
Tempo limite da solicitação
O tempo limite da solicitação não é uma característica da rede, mas uma
característica de um grupo de solicitações (manipulador). Existem solicitações diferentes - elas são diferentes em gravidade, possuem uma lógica completamente diferente, precisam acessar repositórios completamente diferentes.
O Nginx em si
não tem um tempo limite para toda a solicitação. Ele tem:
- proxy_send_timeout: tempo entre duas operações de gravação bem-sucedidas write ();
- proxy_read_timeout: tempo entre duas leituras de leitura bem-sucedidas ().
Ou seja, se você tem um back-end lentamente, um byte de vezes, fornece algo em um tempo limite, tudo está bem. Como tal, o nginx não possui request_timeout. Mas estamos falando sobre a montante. Em nosso data center, eles são controlados por nós, portanto, assumindo que a rede não possui loris lentos, então, em princípio, o read_timeout pode ser usado como request_timeout.
O enviado tem tudo: timeout || per_try_timeout.
Selecionar tempo limite da solicitação
Agora, o mais importante, na minha opinião, é qual request_timeout colocar. Nós procedemos de quanto é permitido ao usuário esperar - este é um certo máximo. É claro que o usuário não esperará mais de 10 s, portanto, é necessário responder a ele mais rapidamente.
- Se quisermos lidar com a falha de um único servidor, o tempo limite deve ser menor que o tempo limite máximo permitido: request_timeout <max.
- Se você deseja ter 2 tentativas garantidas de enviar uma solicitação para dois back-end diferentes, o tempo limite para uma tentativa é igual à metade desse intervalo permitido: per_try_timeout = 0,5 * máx.
- Há também uma opção intermediária - 2 tentativas otimistas , caso o primeiro back-end tenha "diminuído", mas o segundo responderá rapidamente: per_try_timeout = k * max (onde k> 0,5).
Existem abordagens diferentes, mas, em geral, a
escolha de um tempo limite é difícil . Sempre haverá casos de limite, por exemplo, o mesmo manipulador em 99% dos casos é processado em 10 ms, mas há 1% dos casos quando esperamos 500 ms, e isso é normal. Isso terá que ser resolvido.
Com esse 1%, algo precisa ser feito, porque todo o grupo de solicitações deve, por exemplo, cumprir o SLA e caber em 100 ms. Muitas vezes, nesses momentos, o aplicativo é processado:
- A paginação aparece nos locais em que é impossível retornar todos os dados em um tempo limite.
- Os administradores / relatórios são separados em um grupo separado de URLs para aumentar o tempo limite para eles e sim para diminuir as solicitações do usuário.
- Reparamos / otimizamos as solicitações que não se encaixam no nosso tempo limite.
Aqui, precisamos tomar uma decisão, o que não é muito simples do ponto de vista psicológico, de que, se não tivermos tempo para responder ao usuário no prazo estipulado, cometeremos um erro (é como em um ditado chinês antigo: "Se a égua estiver morta, desça!")
.Depois disso, o processo de monitorar seu serviço do ponto de vista do usuário é simplificado:
- Se houver erros, tudo está ruim, ele precisa ser corrigido.
- Se não houver erros, ajustamos o tempo de resposta correto, tudo está bem.
Tentativas especulativas # nifig
Garantimos que escolher um valor de tempo limite é bastante difícil. Como você sabe, para simplificar algo, você precisa complicar algo :)
Retray especulativo - uma solicitação repetida para outro servidor, que é iniciada por alguma condição, mas a primeira solicitação não é interrompida. Tomamos a resposta do servidor que respondeu mais rapidamente.
Eu não vi esse recurso nos balanceadores conhecidos por mim, mas há um excelente exemplo com o Cassandra (proteção rápida de leitura):
speculative_retry = N ms |
M percentilDessa forma, você
não precisa atingir o tempo limite . Você pode deixá-lo em um nível aceitável e, em qualquer caso, ter uma segunda tentativa de obter uma resposta à solicitação.
Cassandra tem uma oportunidade interessante de definir um speculative_retry ou dinâmico estático; a segunda tentativa será feita através do percentil do tempo de resposta. Cassandra acumula estatísticas sobre os tempos de resposta de pedidos anteriores e adapta um valor de tempo limite específico. Isso funciona muito bem.
Nessa abordagem, tudo depende do equilíbrio entre confiabilidade e carga espúria, não servidores. Você fornece confiabilidade, mas às vezes recebe solicitações extras para o servidor. Se você estava com pressa em algum lugar e enviou uma segunda solicitação, mas a primeira ainda respondeu, o servidor recebeu um pouco mais de carga. Em um único caso, esse é um pequeno problema.

A consistência do tempo limite é outro aspecto importante. Falaremos mais sobre o cancelamento da solicitação, mas, em geral, se o tempo limite da solicitação inteira do usuário for de 100 ms, não faz sentido definir o tempo limite da solicitação no banco de dados por 1 s. Existem sistemas que permitem fazer isso dinamicamente: serviço a serviço transfere o restante do tempo que você esperará por uma resposta para essa solicitação. É complicado, mas se você precisar de repente, poderá descobrir facilmente como fazê-lo no mesmo enviado.
O que mais você precisa saber sobre novas tentativas?
Ponto sem retorno (V1)
Aqui o V1 não é a versão 1. Na aviação, existe esse conceito - velocidade V1. Essa é a velocidade após a qual é impossível desacelerar a aceleração na pista. É necessário decolar e tomar uma decisão sobre o que fazer a seguir.
O mesmo ponto sem retorno está nos balanceadores de carga:
quando você passa 1 byte da resposta ao seu cliente, nenhum erro pode ser corrigido . Se o back-end morrer neste momento, nenhuma nova tentativa ajudará. Você só pode reduzir a probabilidade de um cenário desse tipo ser acionado, fazer um desligamento normal, ou seja, informar seu aplicativo: “Você não aceita novas solicitações agora, mas modifica as antigas!”, E só então a extingue.
Se você controla o cliente, este é um aplicativo móvel ou Ajax complicado, ele pode tentar repetir a solicitação e você pode sair dessa situação.
Ponto de não retorno [Enviado]
O enviado teve um truque tão estranho. Existe per_try_timeout - limita quanto cada tentativa de obter uma resposta a uma solicitação pode demorar. Se esse tempo limite funcionou, mas o back-end já começou a responder ao cliente, tudo foi interrompido, o cliente recebeu um erro.
Meu colega Pavel Trukhanov (
tru_pablo ) fez um
patch , que já está no master Envoy e estará em 1.7. Agora ele funciona como deveria: se a resposta começou a ser transmitida, apenas o tempo limite global funcionará.
Tentativas: necessidade de limitar
As novas tentativas são boas, mas existem os chamados pedidos matadores: consultas pesadas que executam uma lógica muito complexa acessam muito o banco de dados e geralmente não se encaixam em per_try_timeout. Se enviarmos novas tentativas repetidamente, matamos nossa base. Porque
na maioria dos serviços de banco de dados (99,9%) não há cancelamento de solicitação .
Solicitar cancelamento significa que o cliente desengatou; é necessário interromper todo o trabalho no momento. A Golang está promovendo ativamente essa abordagem, mas infelizmente termina com um back-end, e muitos repositórios de banco de dados não suportam isso.
Portanto, as novas tentativas precisam ser limitadas, o que permite quase todos os balanceadores (deixamos de considerar o HAProxy a partir de agora).
Nginx:- proxy_next_upstream_timeout (global)
- proxt_read_timeout ** como per_try_timeout
- proxy_next_upstream_tries
Enviado:- tempo limite (global)
- per_try_timeout
- num_retries
No Nginx, podemos dizer que estamos tentando fazer novas tentativas na janela X, ou seja, em um determinado intervalo de tempo, por exemplo, 500 ms, fazemos tantas tentativas quanto caber. Ou há uma configuração que limita o número de amostras repetidas. No
Enviado , o mesmo é quantidade ou tempo limite (global).
Tentativas: aplicar [nginx]
Considere um exemplo: definimos tentativas de repetição no nginx 2 - de acordo com o recebimento do HTTP 503, tentamos enviar uma solicitação ao servidor novamente. Em seguida, desligue os
dois back-ends.
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; proxy_next_upstream error timeout http_503; proxy_next_upstream_tries 2; location / { proxy_pass http://backends; } }
Abaixo estão os gráficos da nossa bancada de testes. Não há erros no gráfico superior, porque são muito poucos. Se você deixar apenas erros, é claro que eles são.
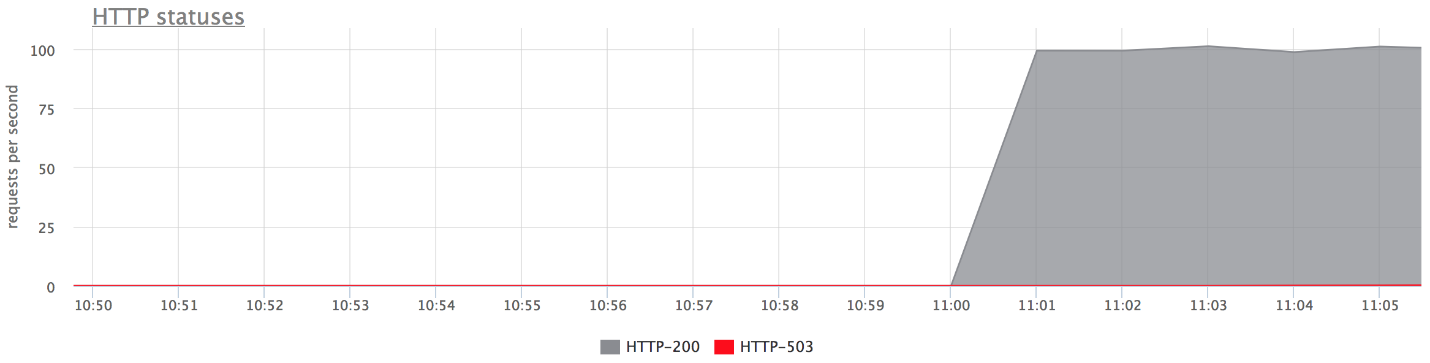
 O que aconteceu
O que aconteceu- proxy_next_upstream_tries = 2.
- No caso em que você faz a primeira tentativa no servidor "inoperante" e a segunda - no outro "inoperante", você obtém o HTTP-503 no caso de ambas as tentativas nos servidores "inoperantes".
- Existem alguns erros, já que o nginx "proíbe" um servidor inválido. Ou seja, se no nginx alguns erros retornaram do back-end, ele para de fazer as seguintes tentativas de enviar uma solicitação a ele. Isso é governado pela variável fail_timeout.
Mas há erros, e isso não nos convém.
O que fazer sobre isso?Podemos aumentar o número de novas tentativas (mas depois retornar ao problema de "solicitações assassinas") ou reduzir a probabilidade de uma solicitação chegar a back-ends "mortos". Isso pode ser feito com
verificações de saúde.Verificações de integridade
Sugiro considerar as verificações de integridade como uma otimização do processo de escolha de um servidor "ativo".
Isso não oferece nenhuma garantia. Consequentemente, durante a execução de uma solicitação do usuário, é mais provável que consigamos acessar apenas servidores "ativos". O balanceador acessa regularmente um URL específico, o servidor responde: "Estou vivo e pronto".
Verificações de integridade: em termos de back-end
Do ponto de vista de back-end, você pode fazer coisas interessantes:
- Verifique a prontidão para a operação de todos os subsistemas subjacentes dos quais a operação de back-end depende: o número necessário de conexões com o banco de dados é estabelecido, o pool tem conexões livres, etc., etc.
- Você pode suspender sua própria lógica no URL de verificações de integridade se o balanceador usado não for muito inteligente (por exemplo, você usa o Balanceador de Carga do host). O servidor pode se lembrar de que "no último minuto, cometi tantos erros - provavelmente sou um servidor" errado "e, nos próximos 2 minutos, responderei com" quinhentos "às verificações de integridade. Então eu vou me banir! " Às vezes, isso ajuda muito quando você tem um balanceador de carga não controlado.
- Normalmente, o intervalo de verificação é de cerca de um segundo e você precisa do manipulador de verificação de integridade para não matar o servidor. Deve ser leve.
Verificações de integridade: implementações
Como regra, tudo aqui é o mesmo para todos:
- Solicitação;
- Tempo limite nele;
- Intervalo através do qual fazemos verificações. Os proxies enganados têm jitter , ou seja, alguma randomização, para que todas as verificações de integridade não cheguem ao back-end de uma vez e não o matem.
- Limite não íntegro - o limite de quantas verificações de integridade com falha devem passar para que o serviço o marque como Não íntegro.
- Limite saudável - pelo contrário, quantas tentativas bem-sucedidas devem passar para que o servidor retorne à operação.
- Lógica adicional. Você pode analisar Verificar status + corpo, etc.
O Nginx implementa as funções de verificação de integridade apenas na versão paga do nginx +.
Percebo um recurso do
Envoy , ele tem um
modo de pânico de verificação de saúde
. Quando banimos, como "não saudáveis", mais de N% dos hosts (digamos 70%), ele acredita que todos os nossos exames de saúde estão mentindo e que todos os hosts estão realmente vivos. Em um caso muito ruim, isso ajudará você a não se deparar com uma situação em que você mesmo matou a perna e baniu todos os servidores. Esta é uma maneira de estar seguro novamente.
Juntando tudo
Normalmente, para verificações de integridade definidas:
- Ou nginx +;
- Ou nginx + outra coisa :)
Em nosso país, há uma tendência de definir nginx + HAProxy, porque a versão gratuita do nginx não possui verificações de saúde e, até a versão 1.11.5, não havia limite no número de conexões com o back-end. Mas essa opção é ruim porque o HAProxy não sabe se aposentar depois de estabelecer uma conexão. Muitas pessoas pensam que, se o HAProxy retornar um erro nas tentativas nginx e nginx, tudo ficará bem. Na verdade não. Você pode acessar outro HAProxy e o mesmo back-end, porque os pools de back-end são os mesmos. Então, você introduz mais um nível de abstração para si mesmo, o que reduz a precisão do seu equilíbrio e, consequentemente, a disponibilidade do serviço.
Temos o nginx + Envoy, mas se você ficar confuso, poderá limitar-se apenas ao Envoy.
Que tipo de enviado?
O Envoy é um balanceador de carga para jovens da moda, originalmente desenvolvido em Lyft, escrito em C ++.
Fora da caixa, ele pode fazer um monte de pães no nosso tópico hoje. Você provavelmente o viu como uma malha de serviço para o Kubernetes. Como regra, o Envoy atua como um plano de dados, ou seja, equilibra diretamente o tráfego, e também existe um plano de controle que fornece informações sobre o que você precisa para distribuir a carga (descoberta de serviço etc.).
Vou lhe dizer algumas palavras sobre os pães dele.
Para aumentar a probabilidade de uma resposta de nova tentativa bem-sucedida na próxima vez que tentar, você pode dormir um pouco e esperar que os back-end voltem ao normal. Dessa forma, lidaremos com pequenos problemas no banco de dados. O enviado tem um
backoff para tentativas - pausa entre tentativas. Além disso, o intervalo de atraso entre as tentativas aumenta exponencialmente. A primeira tentativa ocorre após 0-24 ms, a segunda após 0-74 ms e, para cada tentativa subseqüente, o intervalo aumenta e o atraso específico é selecionado aleatoriamente nesse intervalo.
A segunda abordagem não é específica do enviado, mas um padrão chamado de
quebra de circuito (lit. disjuntor ou fusível). Quando nosso back-end diminui, na verdade tentamos terminá-lo sempre. Isso ocorre porque os usuários em qualquer situação incompreensível clicam na página de atualização, enviando cada vez mais solicitações. Seus balanceadores ficam nervosos, enviam novas tentativas, o número de solicitações aumenta - a carga está aumentando e, nessa situação, seria bom não enviar solicitações.
O disjuntor apenas permite determinar que estamos nesse estado, disparar rapidamente o erro e dar aos back-ends "recuperar o fôlego".
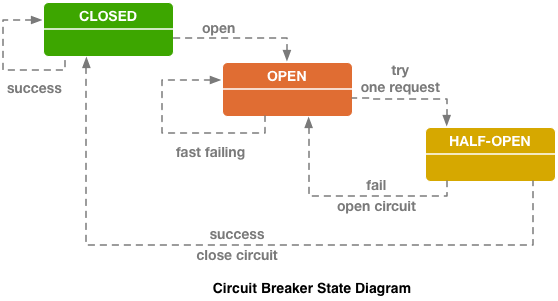 Disjuntor (hystrix como libs), original no blog do ebay.
Disjuntor (hystrix como libs), original no blog do ebay.Acima está o circuito do disjuntor Hystrix. Hystrix é a biblioteca Java da Netflix projetada para implementar padrões de tolerância a falhas.
- O "fusível" pode estar no estado "fechado" quando todas as solicitações são enviadas para o back-end e não há erros.
- Quando um certo limite de falha é acionado, ou seja, alguns erros ocorreram, o disjuntor entra no estado "Aberto". Ele retorna rapidamente um erro ao cliente e as solicitações não chegam ao back-end.
- Uma vez em um determinado período de tempo, ainda uma pequena parte das solicitações é enviada ao back-end. Se um erro for acionado, o estado permanecerá "Aberto". Se tudo começar a funcionar bem e responder, o "fusível" será fechado e o trabalho continuará.
No Enviado, como tal, isso não é tudo. Existem limites de nível superior no fato de que não pode haver mais de N solicitações para um grupo upstream específico. Se houver mais, algo está errado aqui - retornamos um erro. Não pode haver mais N tentativas ativas (ou seja, tentativas que estão acontecendo no momento).
Você não teve tentativas, algo explodiu - envie tentativas. O enviado entende que mais de N é anormal e todas as solicitações devem ser disparadas com erro.
Quebra de circuitos [Enviado]- Máximo de conexões de cluster (grupo upstream)
- Solicitações pendentes máximas do cluster
- Solicitações máximas de cluster
- Máximo de tentativas ativas do cluster
Essa coisa simples funciona bem, é configurável, você não precisa criar parâmetros especiais e as configurações padrão são muito boas.
Disjuntor: nossa experiência
Costumávamos ter um coletor de métricas HTTP, ou seja, agentes instalados nos servidores de nossos clientes enviavam métricas para nossa nuvem via HTTP. Se houver algum problema na infraestrutura, o agente gravará as métricas no disco e tentará enviá-las para nós.
E os agentes constantemente fazem tentativas de enviar dados para nós, eles não ficam chateados porque, de alguma forma, respondemos incorretamente e não saímos.
( , ) , , .
nginx limit req. , , , 200 RPS. , , , limit req.
TCP HTTP ( nginx limit req). . limit req .
, , .
Circuit breaker, , N , , - , , . , , spool .
Circuit breaker + request cancellation ( ). , N Cassandra, N Elastic, , — , . — , .
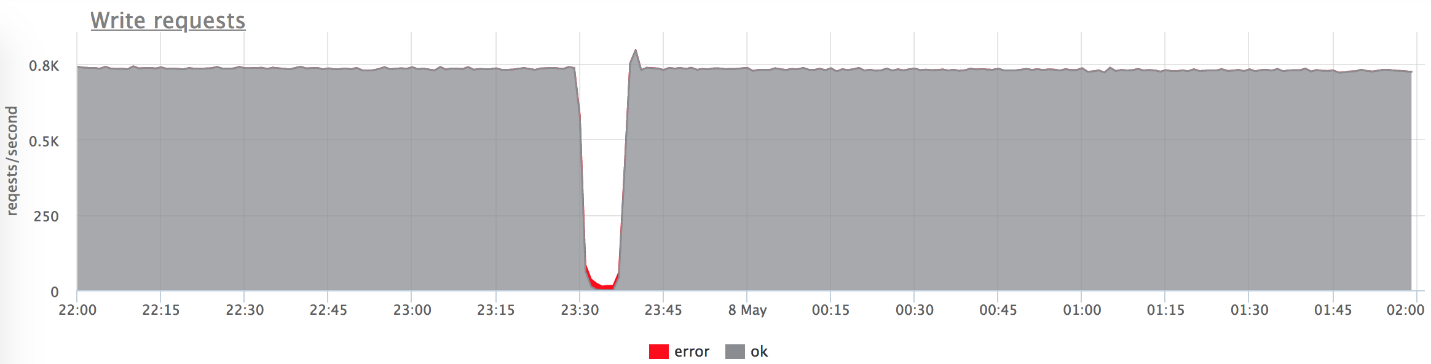
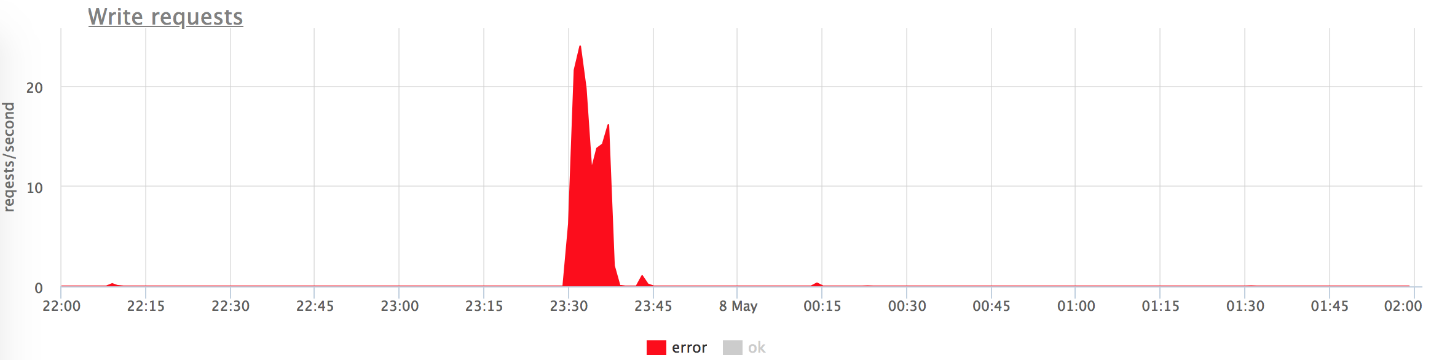
, (: — «», — «»). , 800 RPS 20-30. «», , .
— , .
, , — . .
, , , , Health checks — HTTP 200.
.
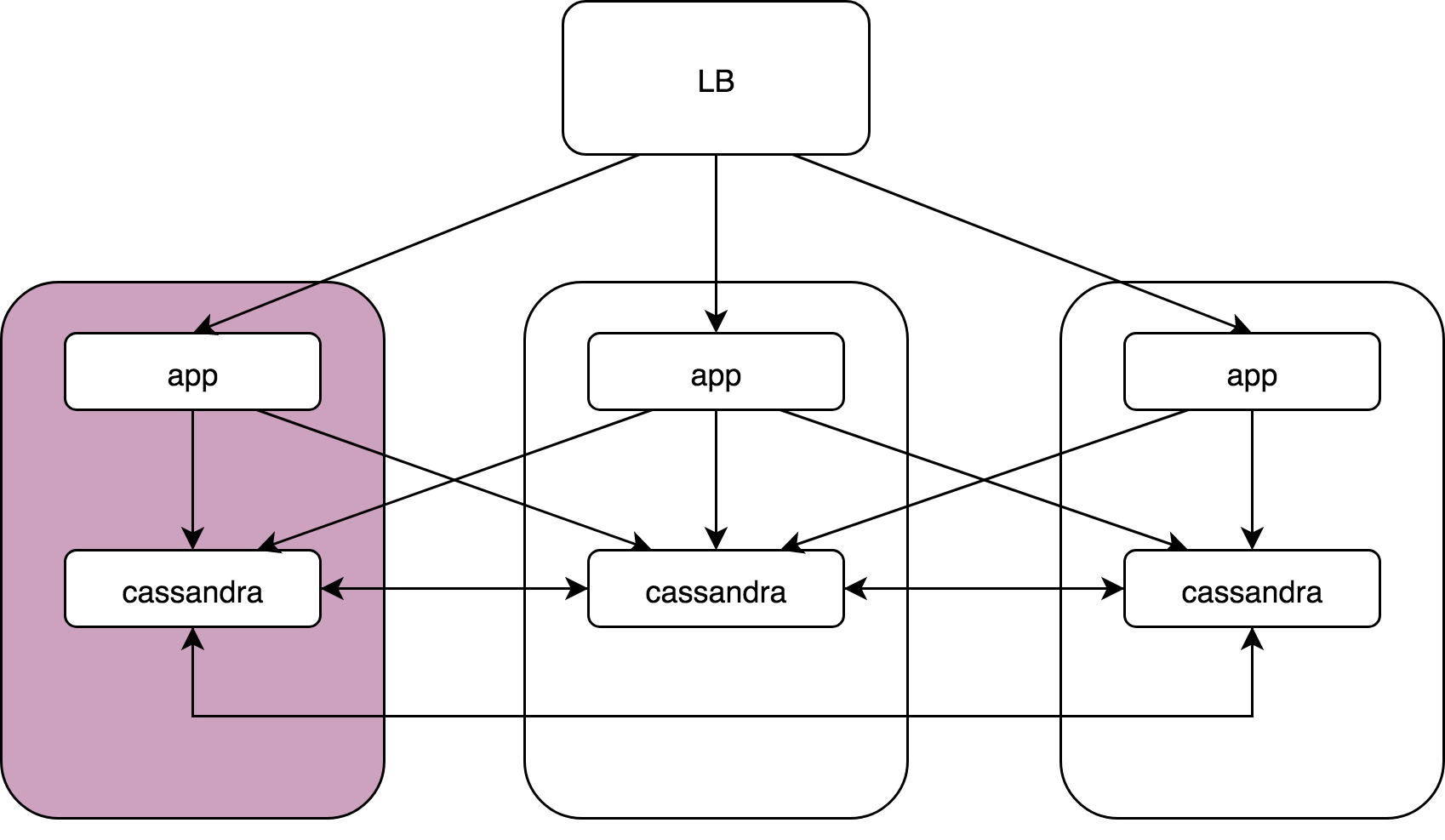
Load Balancer, 3 , Cassandra. Cassandra, Cassandra , Cassandra data noda.
— :
kernel: NETDEV WATCHDOG: eth0 (ixgbe): transmit queue 3 timed out.: ( ), 64 . , 1/64 . reboot, .
, , , . , , , . , , . , .
Cassandra: coordinator -> nodesCassandra, (speculative retries), . latency 99 , .
App -> cassandra coordinator. Cassandra «» , , , latency ..
gocql — cassandra client. . HostSelectionPolicy,
bitly/go-hostpool . Epsilon greedy , .
,
Epsilon-greedy .
(multi-armed bandit): , , N .
:
- « explore» — : 10 , , .
- « exploit» — .
, (10 — 30%)
round -
robin , , , . 70 — 90% .
Host-pool . . ( — , , ). . , , , .
«» () —Cassandra Cassandra coordinator-data. (nginx, Envoy — ) «» Application, Cassandra , , .
Envoy
Outlier detection :
- Consecutive http-5xx.
- Consecutive gateway errors (502,503,504).
- Success rate.
«» , - , . , . — , , . , , .
, «», max_ejection_percent. , outlier, . , 70% — , — , !
, — !
, , . , latency , :
,
, . , , , — , .
. 99% nginx/
HAProxy /Envoy. proxy , «».
proxy ( HAProxy:)),
, .DevOpsConf Russia Kubernetes . .
, — DevOps.
, , YouTube- — .