System.IO.Pipelines é uma nova biblioteca que simplifica a organização do código no .NET. É difícil garantir alto desempenho e precisão se você precisar lidar com códigos complexos. A tarefa do System.IO.Pipelines é simplificar o código. Mais detalhes sob o corte!

A biblioteca surgiu como resultado dos esforços da equipe de desenvolvimento do .NET Core para tornar o Kestrel um dos
servidores da Web mais rápidos do setor . Ele foi originalmente concebido como parte da implementação do Kestrel, mas evoluiu para uma API reutilizável, disponível na versão 2.1 como uma API BCL de primeira classe (System.IO.Pipelines).
Que problemas ela resolve?
Para analisar corretamente os dados de um fluxo ou soquete, você precisa escrever uma grande quantidade de código padrão. Ao mesmo tempo, existem muitas armadilhas que complicam o próprio código e seu suporte.
Que dificuldades surgem hoje?
Vamos começar com uma tarefa simples. Precisamos escrever um servidor TCP que receba mensagens delimitadas por linha (\ n) do cliente.
Servidor TCP com NetworkStream
DESVIO: como em qualquer tarefa que exija alto desempenho, cada caso específico deve ser considerado com base nos recursos do seu aplicativo. Pode não fazer sentido gastar recursos no uso de várias abordagens, que serão discutidas mais adiante, se a escala do aplicativo de rede não for muito grande.
O código .NET regular antes de usar pipelines é algo como isto:
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; await stream.ReadAsync(buffer, 0, buffer.Length);
veja
sample1.cs no
githubEsse código provavelmente funcionará com testes locais, mas possui vários erros:
- Talvez após uma única chamada para o ReadAsync, a mensagem inteira não seja recebida (até o final da linha).
- Ele ignora o resultado do método stream.ReadAsync () - a quantidade de dados realmente transferida para o buffer.
- O código não controla o recebimento de várias linhas em uma única chamada ReadAsync.
Esses são os erros mais comuns de leitura de dados de streaming. Para evitá-los, é necessário fazer várias alterações:
- Você precisa armazenar em buffer os dados recebidos até que uma nova linha seja encontrada.
- É necessário analisar todas as linhas retornadas ao buffer.
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; var bytesBuffered = 0; var bytesConsumed = 0; while (true) { var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, buffer.Length - bytesBuffered); if (bytesRead == 0) {
veja
sample2.cs no
githubRepito: isso pode funcionar com testes locais, mas às vezes existem cadeias maiores que 1 Kb (1024 bytes). É necessário aumentar o tamanho do buffer de entrada até que uma nova linha seja encontrada.
Além disso, coletamos buffers em uma matriz ao processar seqüências longas. Podemos melhorar esse processo com o ArrayPool, que evita a realocação de buffers durante a análise de longas filas do cliente.
async Task ProcessLinesAsync(NetworkStream stream) { byte[] buffer = ArrayPool<byte>.Shared.Rent(1024); var bytesBuffered = 0; var bytesConsumed = 0; while (true) {
veja sample3.cs no githubO código funciona, mas agora o tamanho do buffer mudou, como resultado, muitas cópias dele aparecem. Também é usada mais memória, pois a lógica não reduz o buffer após o processamento das linhas. Para evitar isso, você pode salvar a lista de buffers, em vez de alterar o tamanho do buffer sempre que uma string chegar a mais de 1 Kb.
Além disso, não aumentamos o tamanho do buffer de 1 KB, até que esteja completamente vazio. Isso significa que transferiremos buffers cada vez menores para o ReadAsync, como resultado, o número de chamadas para o sistema operacional aumentará.
Vamos tentar eliminar isso e alocaremos um novo buffer assim que o tamanho do existente se tornar menor que 512 bytes:
public class BufferSegment { public byte[] Buffer { get; set; } public int Count { get; set; } public int Remaining => Buffer.Length - Count; } async Task ProcessLinesAsync(NetworkStream stream) { const int minimumBufferSize = 512; var segments = new List<BufferSegment>(); var bytesConsumed = 0; var bytesConsumedBufferIndex = 0; var segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) }; segments.Add(segment); while (true) {
veja sample4.cs no githubComo resultado, o código é significativamente complicado. Durante a pesquisa do delimitador, rastreamos os buffers preenchidos. Para fazer isso, use uma Lista, que exibe dados em buffer ao procurar um novo separador de linhas. Como resultado, ProcessLine e IndexOf aceitarão List em vez de byte [], deslocamento e contagem. A lógica de análise começará a processar um segmento do buffer ou vários.
E agora o servidor processará mensagens parciais e usará a memória compartilhada para reduzir o consumo geral de memória. No entanto, várias alterações precisam ser feitas:
- No ArrayPoolbyte, usamos apenas Byte [] - matrizes gerenciadas de maneira padrão. Em outras palavras, quando as funções ReadAsync ou WriteAsync são executadas, o período de validade dos buffers é vinculado ao tempo da operação assíncrona (para interagir com as próprias APIs de E / S do sistema operacional). Como a memória fixada não pode ser movida, isso afeta o desempenho do coletor de lixo e pode causar fragmentação da matriz. Pode ser necessário alterar a implementação do pool, dependendo de quanto tempo as operações assíncronas aguardarão a execução.
- A taxa de transferência pode ser aprimorada quebrando o link entre a lógica de leitura e o processo. Temos o efeito do processamento em lote, e agora a lógica de análise poderá ler grandes quantidades de dados, processando grandes blocos de buffers, em vez de analisar linhas individuais. Como resultado, o código fica ainda mais complicado:
- É necessário criar dois ciclos que funcionam independentemente um do outro. O primeiro lerá os dados do soquete e o segundo analisará os buffers.
- O que é necessário é uma maneira de dizer à lógica de análise que os dados estão se tornando disponíveis.
- Também é necessário determinar o que acontece se o loop lê os dados do soquete muito rapidamente. Precisamos de uma maneira de ajustar o ciclo de leitura se a lógica de análise não o acompanhar. Isso geralmente é chamado de "controle de fluxo" ou "resistência ao fluxo".
- Devemos garantir que os dados sejam transmitidos com segurança. Agora, o conjunto de buffers é usado tanto pelo ciclo de leitura quanto pelo ciclo de análise; eles funcionam independentemente um do outro em threads diferentes.
- A lógica de gerenciamento de memória também está envolvida em duas partes diferentes de código: emprestando dados do buffer pool, que lê dados do soquete, e retornando do buffer pool, que é a lógica de análise.
- É preciso ter muito cuidado com o retorno de buffers após a execução da lógica de análise. Caso contrário, existe a chance de retornarmos o buffer no qual a lógica de leitura do soquete ainda está sendo gravada.
A complexidade começa a atravessar o telhado (e isso está longe de todos os casos!). Para criar uma rede de alto desempenho, você precisa escrever um código muito complexo.
O objetivo do System.IO.Pipelines é simplificar esse procedimento.
Servidor TCP e System.IO.Pipelines
Vamos ver como o System.IO.Pipelines funciona:
async Task ProcessLinesAsync(Socket socket) { var pipe = new Pipe(); Task writing = FillPipeAsync(socket, pipe.Writer); Task reading = ReadPipeAsync(pipe.Reader); return Task.WhenAll(reading, writing); } async Task FillPipeAsync(Socket socket, PipeWriter writer) { const int minimumBufferSize = 512; while (true) {
veja sample5.cs no githubA versão em pipeline do nosso leitor de linha possui dois loops:
- FillPipeAsync lê do soquete e grava no PipeWriter.
- O ReadPipeAsync lê no PipeReader e analisa as linhas recebidas.
Ao contrário dos primeiros exemplos, não há buffers especialmente atribuídos. Essa é uma das principais funções do System.IO.Pipelines. Todas as tarefas de gerenciamento de buffer são transferidas para as implementações do PipeReader / PipeWriter.
O procedimento é simplificado: usamos o código apenas para lógica de negócios, em vez de implementar um gerenciamento de buffer complexo.
No primeiro loop, PipeWriter.GetMemory (int) é chamado primeiro para obter uma certa quantidade de memória do gravador principal. Em seguida, PipeWriter.Advance (int) é chamado, o que informa ao PipeWriter quantos dados são realmente gravados no buffer. Isso é seguido por uma chamada para PipeWriter.FlushAsync () para que PipeReader possa acessar os dados.
O segundo loop consome os buffers que foram escritos pelo PipeWriter, mas originalmente recebidos do soquete. Quando a solicitação para PipeReader.ReadAsync () é retornada, obtemos um ReadResult contendo duas mensagens importantes: dados lidos no formato ReadOnlySequence, bem como o tipo de dados lógicos IsCompleted, que informa ao leitor se o gravador terminou de trabalhar (EOF). Quando o terminador de linha (EOL) for encontrado e a sequência for analisada, dividiremos o buffer em partes para pular o fragmento que já foi processado. Depois disso, PipeReader.AdvanceTo é chamado e informa ao PipeReader quantos dados foram consumidos.
No final de cada ciclo, o leitor e o escritor são concluídos. Como resultado, o canal principal libera toda a memória alocada.
System.io.pipelines
Leitura parcial
Além de gerenciar a memória, o System.IO.Pipelines desempenha outra função importante: verifica os dados no canal, mas não os consome.
O PipeReader possui duas APIs principais: ReadAsync e AdvanceTo. O ReadAsync recebe dados do canal, AdvanceTo informa ao PipeReader que esses buffers não são mais necessários pelo leitor, para que você possa se livrar deles (por exemplo, retorne-os ao buffer pool principal).
A seguir, é apresentado um exemplo de um analisador HTTP que lê dados de buffers de dados parciais do canal até receber uma linha inicial adequada.

ReadOnlySequenceT
A implementação do canal armazena uma lista de buffers relacionados passados entre o PipeWriter e o PipeReader. PipeReader.ReadAsync expõe ReadOnlySequence, que é um novo tipo de BCL e consiste em um ou mais segmentos ReadOnlyMemory <T>. É semelhante ao Span ou Memory, que nos dá a oportunidade de examinar matrizes e strings.
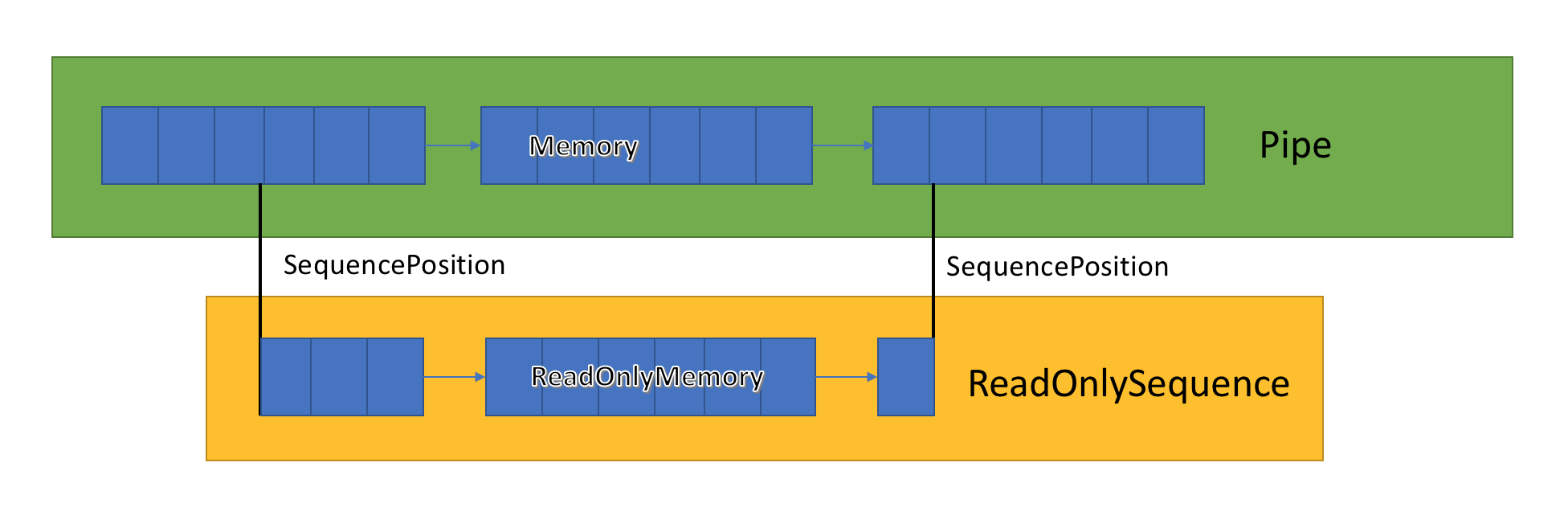
Dentro do canal, existem indicadores que mostram onde o leitor e o gravador estão localizados no conjunto geral de dados destacados e também os atualizam à medida que os dados são gravados e lidos. SequencePosition é um ponto único em uma lista vinculada de buffers e é usado para separar eficientemente ReadOnlySequence <T>.
Como o ReadOnlySequence <T> suporta um ou mais segmentos, a operação padrão da lógica de alto desempenho é separar caminhos rápidos e lentos com base no número de segmentos.
Como exemplo, aqui está uma função que converte ASCII ReadOnlySequence em uma cadeia de caracteres:
string GetAsciiString(ReadOnlySequence<byte> buffer) { if (buffer.IsSingleSegment) { return Encoding.ASCII.GetString(buffer.First.Span); } return string.Create((int)buffer.Length, buffer, (span, sequence) => { foreach (var segment in sequence) { Encoding.ASCII.GetChars(segment.Span, span); span = span.Slice(segment.Length); } }); }
veja
sample6.cs no
githubResistência ao fluxo e controle de fluxo
Idealmente, a leitura e a análise trabalham juntas: o fluxo de leitura consome dados da rede e os coloca em buffers, enquanto o fluxo de análise cria estruturas de dados adequadas. A análise geralmente leva mais tempo do que apenas copiar blocos de dados da rede. Como resultado, o fluxo de leitura pode sobrecarregar facilmente o fluxo de análise. Portanto, o fluxo de leitura será forçado a diminuir a velocidade ou consumir mais memória para salvar dados para o fluxo de análise. Para garantir o desempenho ideal, é necessário um equilíbrio entre a frequência de pausa e a alocação de uma grande quantidade de memória.
Para resolver esse problema, o pipeline possui duas funções de controle de fluxo de dados: PauseWriterThreshold e ResumeWriterThreshold. PauseWriterThreshold determina quantos dados precisam ser armazenados em buffer antes que PipeWriter.FlushAsync seja pausado. ResumeWriterThreshold determina quanta memória o leitor pode consumir antes do gravador retomar a operação.
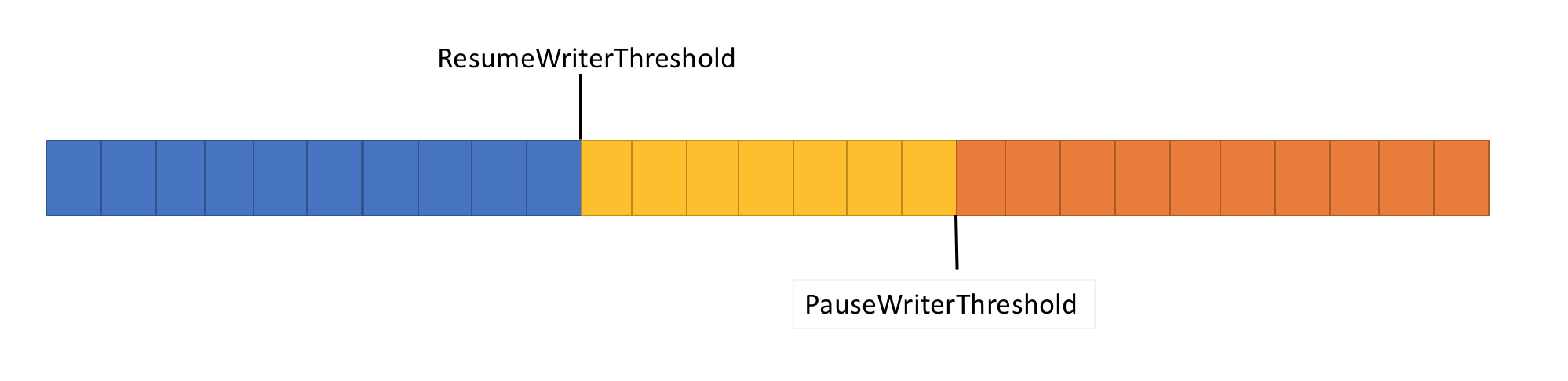
PipeWriter.FlushAsync "bloqueia" quando a quantidade de dados no fluxo em pipeline excede o limite definido em PauseWriterThreshold e "desbloqueia" quando cai abaixo do limite definido em ResumeWriterThreshold. Para evitar exceder o limite de consumo, apenas dois valores são usados.
Planejamento de E / S
Ao usar async / waitit, as operações subseqüentes geralmente são chamadas nos threads do pool ou no SynchronizationContext atual.
Ao executar a E / S, é muito importante monitorar cuidadosamente onde é executada, a fim de aproveitar melhor o cache do processador. Isso é crítico para aplicativos de alto desempenho, como servidores da web. O System.IO.Pipelines usa o PipeScheduler para determinar onde executar retornos de chamada assíncronos. Isso permite controlar com precisão quais fluxos usar para E / S.
Um exemplo de uma aplicação prática é o transporte Kestrel Libuv, no qual os retornos de chamada de E / S são executados em canais dedicados do loop de eventos.
Existem outros benefícios para o modelo PipeReader.
- Alguns sistemas básicos suportam “espera sem buffer”: você não precisa alocar um buffer até que os dados disponíveis apareçam no sistema básico. Portanto, no Linux com epoll, você não pode fornecer um buffer de leitura até que os dados estejam prontos. Isso evita a situação quando há muitos threads aguardando dados e você precisa reservar imediatamente uma quantidade enorme de memória.
- O pipeline padrão facilita a gravação de testes de unidade de código de rede: a lógica de análise é separada do código de rede, e os testes de unidade executam essa lógica apenas em buffers na memória, em vez de consumi-la diretamente da rede. Também facilita o teste de padrões complexos enviando dados parciais. O ASP.NET Core o utiliza para testar vários aspectos das ferramentas de análise http do Kestrel.
- Os sistemas que permitem que o código do usuário use os principais buffers do SO (por exemplo, APIs de E / S do Windows registradas) são inicialmente adequados para o uso de pipelines porque a implementação do PipeReader sempre fornece buffers.
Outros tipos relacionados
Também adicionamos vários novos tipos simples de BCL ao System.IO.Pipelines:
- MemoryPoolT , IMemoryOwnerT , MemoryManagerT . ArrayPoolT foi adicionado no .NET Core 1.0 e, no .NET Core 2.1, agora existe uma representação abstrata mais geral para um pool que funciona com qualquer MemoryT. Obtemos um ponto de extensibilidade que nos permite implementar estratégias de distribuição mais avançadas, bem como controlar o gerenciamento de buffer (por exemplo, use buffers predefinidos em vez de matrizes gerenciadas exclusivamente).
- IBufferWriterT é um receptor para registrar dados em buffer sincronizados (implementados pelo PipeWriter).
- IValueTaskSource - ValueTaskT existe desde o lançamento do .NET Core 1.1, mas no .NET Core 2.1 ele adquiriu ferramentas extremamente eficazes que fornecem operações assíncronas ininterruptas sem distribuição. Veja aqui para mais informações.
Como usar transportadores?
As APIs estão no pacote de nuget
System.IO.Pipelines .
Para um exemplo de aplicativo de servidor .NET Server 2.1 que usa pipelines para processar mensagens em minúsculas (do exemplo acima), consulte
aqui . Pode ser iniciado usando o dotnet run (ou Visual Studio). No exemplo, espera-se que os dados sejam transmitidos do soquete na porta 8087 e, em seguida, as mensagens recebidas serão gravadas no console. Você pode usar um cliente, como netcat ou putty, para conectar-se à porta 8087. Envie uma mensagem em minúscula e veja como ela funciona.
Atualmente, o pipeline é executado no Kestrel e no SignalR, e esperamos que ele encontre aplicativos mais amplos em muitas bibliotecas de rede e componentes da comunidade .NET no futuro.