
Desde o início, planejamos soluções de engenharia e produtos para que o Discord seja adequado para bate-papo por voz enquanto estiver jogando com os amigos. Essas soluções permitiram dimensionar bastante o sistema, com uma equipe pequena e recursos limitados.
Este artigo discute as várias tecnologias que o Discord usa para bate-papos de áudio / vídeo.
Para maior clareza, chamaremos todo o grupo de usuários e canalizaremos o "grupo" (guilda) - no cliente, eles são chamados de "servidores". Em vez disso, o termo "servidor" refere-se à nossa infraestrutura de servidores.Princípios principais
Cada bate-papo de áudio / vídeo no Discord suporta muitos participantes. Vimos milhares de pessoas conversando em conversas em grupo. Esse suporte requer uma arquitetura cliente-servidor, porque uma rede ponto a ponto ponto a ponto se torna proibitivamente cara com um aumento no número de participantes.
O roteamento do tráfego de rede através dos servidores Discord também garante que seu endereço IP nunca fique visível - e ninguém iniciará um ataque DDoS. O roteamento através de servidores tem outras vantagens: por exemplo, moderação. Os administradores podem desativar rapidamente o som e o vídeo para os invasores.
Arquitetura do cliente
A discórdia é executada em muitas plataformas.
- Web (Chrome / Firefox / Edge, etc.)
- Aplicativo autônomo (Windows, MacOS, Linux)
- Telefone (iOS / Android)
Podemos suportar todas essas plataformas de apenas uma maneira: através da reutilização do código
WebRTC . Essa especificação para comunicações em tempo real inclui componentes de rede, áudio e vídeo. O padrão é adotado
pelo World Wide Web Consortium e pelo
Internet Engineering Group . O WebRTC está disponível em todos os navegadores modernos e como uma biblioteca nativa para implementação em aplicativos.
O áudio e o vídeo no Discord são executados no WebRTC. Portanto, o aplicativo do navegador depende da implementação do WebRTC no navegador. No entanto, os aplicativos para desktops, iOS e Android usam um único mecanismo multimídia C ++, construído sobre sua própria biblioteca WebRTC, que é especialmente adaptada às necessidades de nossos usuários. Isso significa que algumas funções no aplicativo funcionam melhor do que no navegador. Por exemplo, em nossos aplicativos nativos, podemos:
- Ignorar o Volume do Windows Mute por padrão, quando todos os aplicativos são silenciados automaticamente ao usar um fone de ouvido . Isso é indesejável quando você e seus amigos realizam um ataque e coordenam as atividades de bate-papo do Discord.
- Use seu próprio controle de volume em vez do misturador global do sistema operacional.
- Processe os dados de áudio originais para detectar atividade de voz e transmitir áudio e vídeo em jogos.
- Reduza a largura de banda e o consumo de CPU durante períodos de silêncio - mesmo nas mais numerosas conversas por voz a qualquer momento, apenas algumas pessoas falam ao mesmo tempo.
- Forneça funcionalidade em todo o sistema para o modo push to talk.
- Envie junto com pacotes de áudio e vídeo informações adicionais (por exemplo, um indicador de prioridade no bate-papo).
Ter sua própria versão do WebRTC significa atualizações frequentes para todos os usuários: este é um processo demorado que estamos tentando automatizar. No entanto, esse esforço compensa graças às características específicas de nossos jogadores.
No Discord, a comunicação de voz e vídeo é iniciada inserindo um canal ou chamada de voz. Ou seja, a conexão é sempre iniciada pelo cliente - isso reduz a complexidade das partes do cliente e do servidor e também aumenta a tolerância a erros. No caso de uma falha na infraestrutura, os participantes podem simplesmente se reconectar ao novo servidor interno.
Sob nosso controle
O controle da biblioteca nativa permite implementar algumas funções de maneira diferente da implementação do WebRTC no navegador.
Primeiro, o WebRTC conta com o
SDP (Session Description Protocol) para negociar áudio / vídeo entre os participantes (até 10 KB por troca de pacotes). Em sua própria biblioteca, a API de nível inferior do WebRTC (
webrtc::Call ) é usada para criar os dois fluxos - de entrada e de saída. Quando conectado a um canal de voz, há uma troca mínima de informações. Este é o endereço e a porta do servidor back-end, o método de criptografia, as chaves, o codec e a identificação do fluxo (cerca de 1000 bytes).
webrtc::AudioSendStream* createAudioSendStream( uint32_t ssrc, uint8_t payloadType, webrtc::Transport* transport, rtc::scoped_refptr<webrtc::AudioEncoderFactory> audioEncoderFactory, webrtc::Call* call) { webrtc::AudioSendStream::Config config{transport}; config.rtp.ssrc = ssrc; config.rtp.extensions = {{"urn:ietf:params:rtp-hdrext:ssrc-audio-level", 1}}; config.encoder_factory = audioEncoderFactory; const webrtc::SdpAudioFormat kOpusFormat = {"opus", 48000, 2}; config.send_codec_spec = webrtc::AudioSendStream::Config::SendCodecSpec(payloadType, kOpusFormat); webrtc::AudioSendStream* audioStream = call->CreateAudioSendStream(config); audioStream->Start(); return audioStream; }
Além disso, o WebRTC usa o
ICE (Interactive Connectivity Establishment) para determinar a melhor rota entre os participantes. Como temos cada cliente conectado ao servidor, não precisamos do ICE. Isso permite que você forneça uma conexão muito mais confiável se estiver atrás do NAT e também mantenha seu endereço IP em segredo de outros participantes. Os clientes fazem ping periodicamente para que o firewall mantenha uma conexão aberta.
Por fim, o WebRTC usa o
SRTP (Secure Real-Time Transport Protocol) para criptografar a mídia. As chaves de criptografia são definidas usando o protocolo
DTLS (Datagram Transport Layer Security) com base no TLS padrão. A biblioteca interna do WebRTC permite implementar sua própria camada de transporte usando a API
webrtc::Transport .
Em vez de DTLS / SRTP, decidimos usar uma
criptografia Salsa20 mais rápida. Além disso, não enviamos dados de áudio durante períodos de silêncio - uma ocorrência comum, especialmente em grandes salas de bate-papo. Isso leva a uma economia significativa em largura de banda e recursos da CPU; no entanto, o cliente e o servidor devem estar prontos a qualquer momento para parar de receber dados e reescrever os números de série dos pacotes de áudio / vídeo.
Como o aplicativo Web usa a implementação baseada em navegador da
API WebRTC , SDP, ICE, DTLS e SRTP não podem ser abandonados. O cliente e o servidor trocam todas as informações necessárias (menos de 1200 bytes ao trocar pacotes) - e a sessão SDP é estabelecida com base nessas informações para os clientes. O back-end é responsável por resolver as diferenças entre aplicativos de desktop e navegador.
Arquitetura de back-end
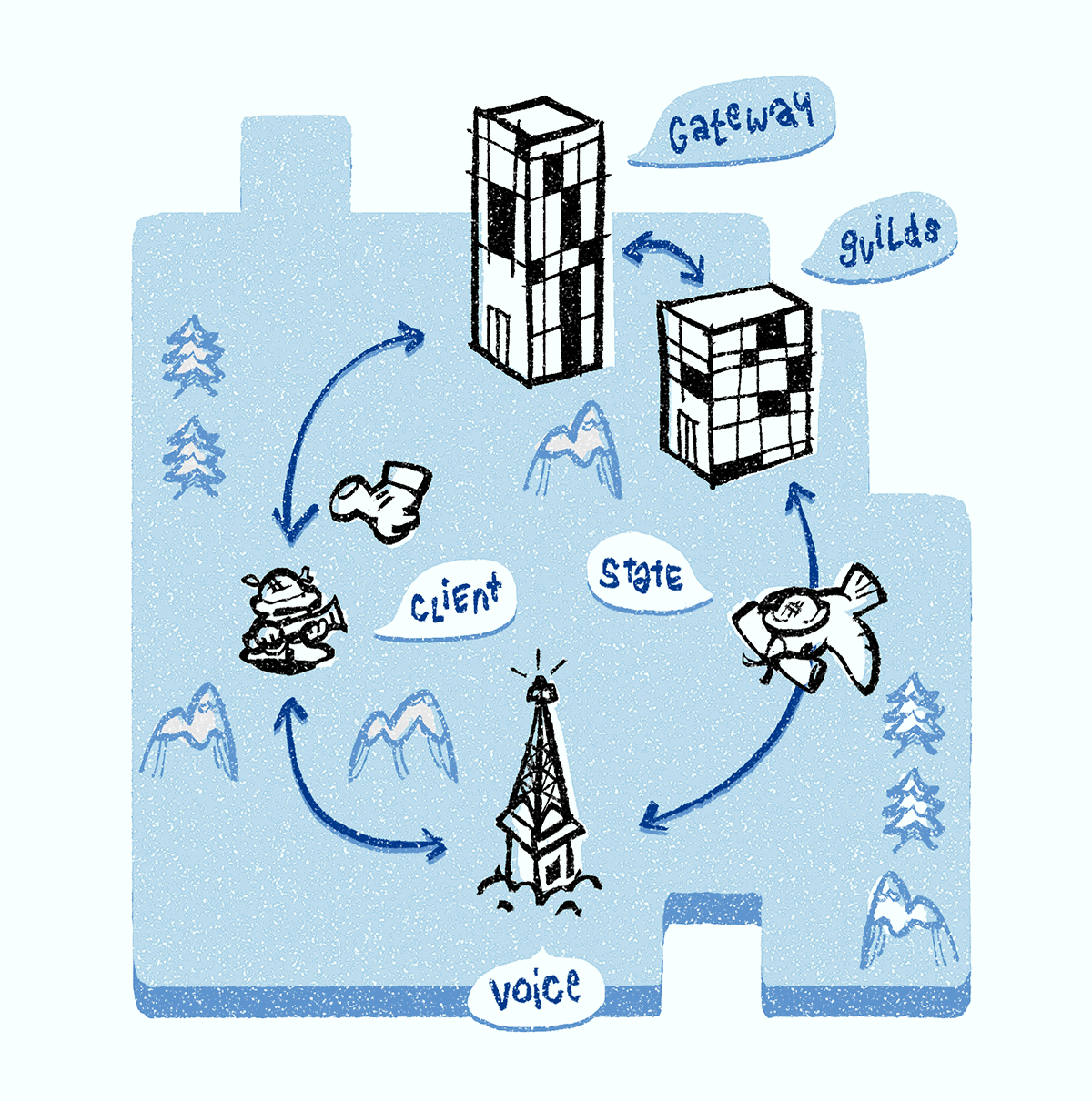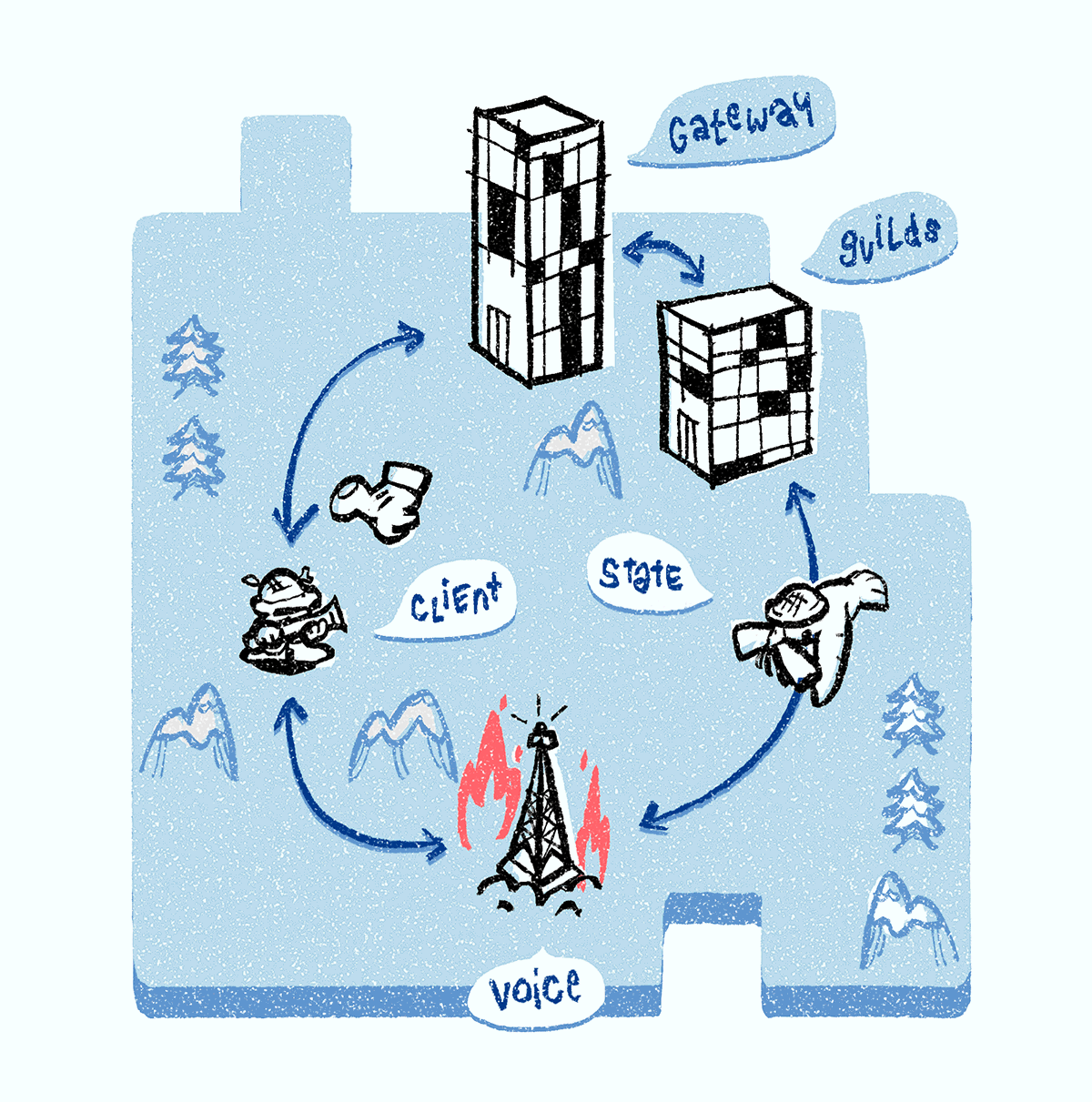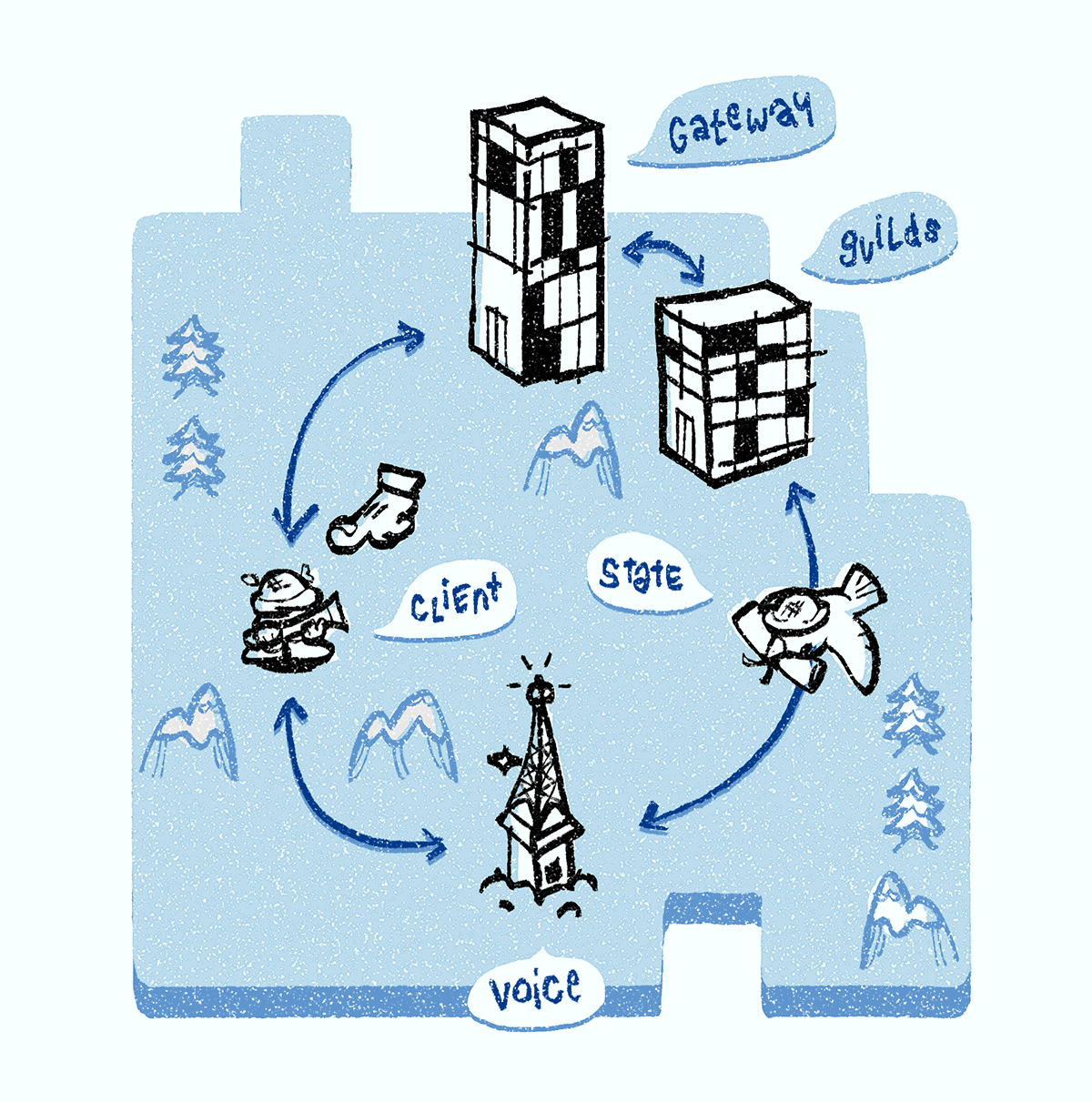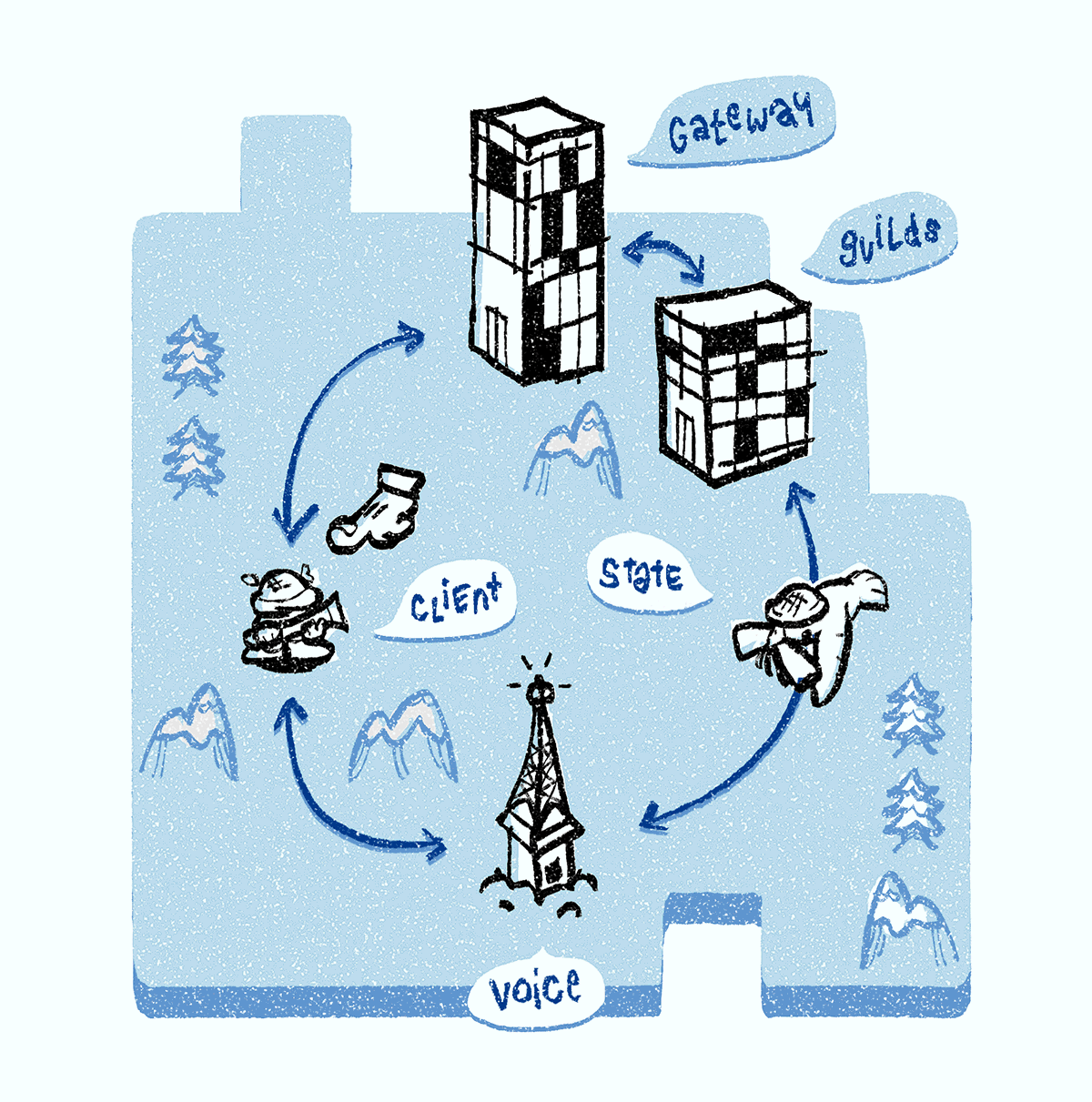
Existem vários serviços de bate-papo por voz no back-end, mas vamos nos concentrar em três: Discord Gateway, Discord Guilds e Discord Voice. Todos os nossos servidores de sinal são escritos em
Elixir , o que nos permite reutilizar o código repetidamente.
Quando você está on-line, seu cliente suporta uma conexão WebSocket com um Discord Gateway (nós chamamos de conexão de
gateway WebSocket). Por meio dessa conexão, seu cliente recebe eventos relacionados a grupos e canais, mensagens de texto, pacotes de presença etc.
Quando conectado a um canal de voz, o status da conexão é exibido pelo
objeto de status de voz. O cliente atualiza esse objeto pela conexão do gateway.
defmodule VoiceStates.VoiceState do @type t :: %{ session_id: String.t(), user_id: Number.t(), channel_id: Number.t() | nil, token: String.t() | nil, mute: boolean, deaf: boolean, self_mute: boolean, self_deaf: boolean, self_video: boolean, suppress: boolean } defstruct session_id: nil, user_id: nil, token: nil, channel_id: nil, mute: false, deaf: false, self_mute: false, self_deaf: false, self_video: false, suppress: false end
Quando conectado a um canal de voz, você recebe um dos servidores de voz do Discord. Ele é responsável por transmitir som para cada participante do canal. Todos os canais de voz em um grupo são atribuídos a um servidor. Se você é o primeiro a conversar, o servidor do Discord Guilds é responsável por atribuir o servidor do Discord Voice a todo o grupo usando o processo descrito abaixo.
Destino do servidor de voz Discord
Cada servidor do Discord Voice reporta periodicamente seu status e carga. Essas informações são colocadas em um sistema de descoberta de serviço (usamos o
etcd ), conforme discutido em um
artigo anterior .
O servidor Discord Guilds monitora o sistema de descoberta de serviço e atribui ao grupo o servidor Discord Voice menos usado na região. Quando selecionado, todos os objetos de status de voz (também suportados pelo servidor do Discord Guilds) são transferidos para o servidor do Discord Voice para que ele possa configurar o encaminhamento de áudio / vídeo. Os clientes são notificados do servidor Discord Voice selecionado. Em seguida, o cliente abre a
segunda conexão WebSocket com o servidor de voz (chamamos de conexão de
voz WebSocket), que é usada para configurar o encaminhamento de multimídia e a indicação de fala.
Quando o cliente exibe o status
Aguardando ponto de extremidade , isso significa que o servidor do Discord Guilds está procurando o servidor ideal do Discord Voice. Uma mensagem
Voice Connected indica que o cliente trocou pacotes UDP com sucesso com o servidor Discord Voice selecionado.
O servidor Discord Voice contém dois componentes: um módulo de sinal e uma unidade de retransmissão multimídia, denominada unidade de encaminhamento seletivo (
SFU ). O módulo de sinal controla totalmente o SFU e é responsável por gerar identificadores de fluxo e chaves de criptografia, redirecionando indicadores de fala, etc.
Nosso SFU (em C ++) é responsável por direcionar o tráfego de áudio e vídeo entre os canais. Ele é desenvolvido por si só: para o nosso caso em particular, o SFU oferece desempenho máximo e, portanto, a maior economia. Quando os moderadores violam (silenciam o servidor), seus pacotes de áudio não são processados. O SFU também funciona como uma ponte entre aplicativos nativos e baseados em navegador: implementa transporte e criptografia para aplicativos nativos e de navegador, convertendo pacotes durante a transmissão. Por fim, o SFU é responsável pelo processamento do protocolo
RTCP , usado para otimizar a qualidade do vídeo. O SFU coleta e processa relatórios RTCP dos destinatários - e notifica os remetentes sobre qual banda está disponível para transmissão de vídeo.
Tolerância a falhas
Como apenas os servidores Discord Voice estão disponíveis diretamente na Internet, falaremos sobre eles.
O módulo de sinal monitora continuamente o SFU. Se travar, reiniciará instantaneamente com uma pausa mínima no serviço (vários pacotes perdidos). O status do SFU é restaurado pelo módulo de sinal sem qualquer interação com o cliente. Embora as falhas do SFU sejam raras, usamos o mesmo mecanismo para atualizar o SFU sem interrupções no serviço.
Quando o servidor do Discord Voice falha, ele não responde ao ping - e é removido do sistema de descoberta de serviço. O cliente também percebe uma falha no servidor devido a uma conexão de voz do WebSocket interrompida e solicita o
ping do servidor de voz através da conexão do gateway do WebSocket. O servidor do Discord Guilds confirma a falha, consulta o sistema de descoberta de serviços e atribui um novo servidor do Discord Voice ao grupo. As Discord Guilds enviam todos os objetos de status de voz para o novo servidor de voz. Todos os clientes recebem uma notificação sobre o novo servidor e se conectam a ele para iniciar a configuração de multimídia.
Freqüentemente, os servidores Discord Voice se enquadram no DDoS (vemos isso pelo rápido aumento dos pacotes IP recebidos). Nesse caso, executamos o mesmo procedimento de quando o servidor travou: nós o removemos do sistema de descoberta de serviço, selecionamos um novo servidor, transferimos todos os objetos de estado de comunicação de voz para ele e notificamos os clientes sobre o novo servidor. Quando o ataque DDoS desaparece, o servidor retorna ao sistema de descoberta de serviço.
Se o proprietário do grupo decidir escolher uma nova região para a votação, seguiremos um procedimento muito semelhante. O Discord Guilds Server seleciona o melhor servidor de voz disponível em uma nova região em consulta com um sistema de descoberta de serviço. Em seguida, ele traduz para ele todos os objetos do estado da comunicação de voz e notifica os clientes sobre o novo servidor. Os clientes interrompem a conexão atual do WebSocket com o antigo servidor Discord Voice e criam uma nova conexão com o novo servidor Discord Voice.
Dimensionamento
Toda a infraestrutura do Discord Gateway, do Discord Guilds e do Discord Voice suporta o dimensionamento horizontal. O Discord Gateway e o Discord Guilds funcionam no Google Cloud.
Temos mais de 850 servidores de voz em 13 regiões (localizadas em mais de 30 data centers) em todo o mundo. Essa infraestrutura fornece maior redundância em caso de falhas nos datacenters e DDoS. Trabalhamos com vários parceiros e usamos nossos servidores físicos em seus data centers. Mais recentemente, a região sul-africana foi adicionada. Graças aos esforços de engenharia nas arquiteturas de clientes e servidores, o Discord agora pode atender simultaneamente a mais de 2,6 milhões de usuários de bate-papo por voz com tráfego de saída de mais de 220 Gbit / se 120 milhões de pacotes por segundo.
O que vem a seguir?
Monitoramos constantemente a qualidade das comunicações de voz (as métricas são enviadas do lado do cliente para os servidores back-end). No futuro, essas informações ajudarão na detecção e eliminação automática da degradação.
Embora tenhamos lançado bate-papo por vídeo e screencasts há um ano, agora eles só podem ser usados em mensagens privadas. Comparado ao áudio, o vídeo requer significativamente mais energia e largura de banda da CPU. O desafio é equilibrar a quantidade de largura de banda e os recursos de CPU / GPU usados para garantir a melhor qualidade de vídeo, especialmente quando um grupo de jogadores em um canal está em dispositivos diferentes.
A tecnologia
Scalable Video Coding (SVC), uma extensão do padrão H.264 / MPEG-4 AVC, pode se tornar uma solução para o problema.
Os screencasts precisam de mais largura de banda que o vídeo, devido ao maior FPS e resolução do que as webcams convencionais. Atualmente, estamos trabalhando no suporte à codificação de vídeo baseada em hardware em um aplicativo de desktop.