O tempo está se esgotando e logo não restará quase nada desse desenvolvimento, mas ainda não tive tempo de descrevê-lo.
Será sobre uma empresa no nível federal, com um grande número de filiais e sub-filiais. Mas, como sempre, tudo começou há muito tempo com uma pequena loja. Ao longo dos anos, ocorreu um desenvolvimento bastante rápido e espontâneo, surgiram filiais, divisões e outros escritórios, e a infraestrutura de TI não recebeu a devida atenção naqueles dias, e isso também é uma ocorrência frequente. É claro que o 1C77 foi usado em todos os lugares, sem reservas para replicação e dimensionamento; portanto, chegamos à conclusão de que um Sprut-Frankenstein foi gerado com tentáculos amarrados com fita isolante - em cada ramo havia um mutante autônomo que trocava com a base central no modo "joelho-alto", apenas alguns livros de referência, sem os quais, bem, era impossível e o resto é autônomo. Por algum tempo, eles se contentaram com cópias (dezenas delas!) De bases de filiais no escritório central, mas os dados neles ficaram por vários dias.
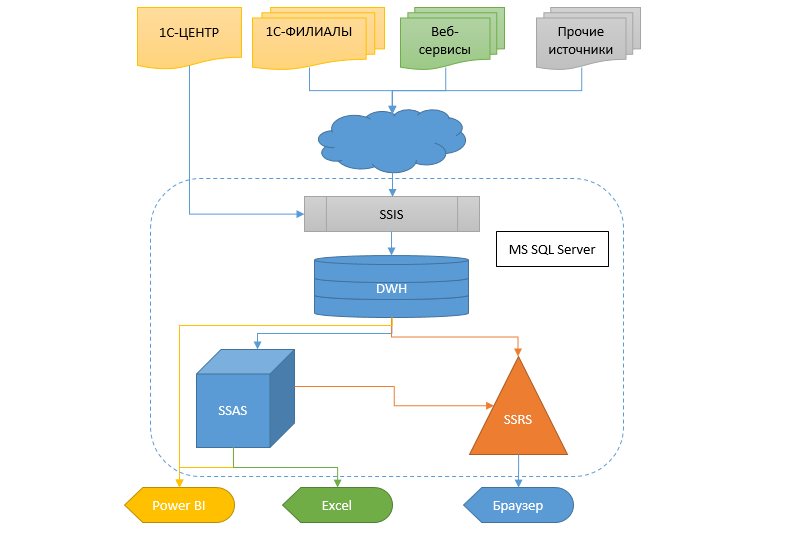
A realidade, no entanto, exige a obtenção de informações de maneira mais rápida e flexível, e é preciso fazer outra coisa com isso. A transferência de um sistema contábil para outro em tal escala ainda é um pântano. Portanto, decidiu-se criar um data warehouse (DX), no qual as informações fluiriam de diferentes bancos de dados, para que posteriormente outros serviços e o sistema analítico na forma de cubos, relatórios e vazamentos do SSRS pudessem receber dados deste CD.
No futuro, direi que a transição para um novo sistema contábil quase aconteceu e a maior parte do projeto descrito aqui será cortada no futuro próximo por desnecessária. Desculpe, é claro, mas nada pode ser feito.
A seguir, é um artigo longo, mas antes de começar a ler, observe que, em nenhum caso, aprovo essa decisão como padrão, mas talvez alguém encontre algo útil nela.
Começarei com uma abordagem geral do projeto, para a qual o SSDT foi escolhido como ambiente de desenvolvimento, com a publicação subsequente do projeto no Git. Eu acho que hoje existem vários artigos e tutoriais suficientes que descrevem os pontos fortes dessa ferramenta. Mas existem alguns pontos cujo problema está fora deste ambiente.
Armazenamento de enumerações e versões de banco de dados
Em relação às versões e enumerações, os requisitos para o projeto significavam:
- Conveniência de editar e rastrear alterações na versão do banco de dados dentro do projeto
- Conveniência de visualizar a versão do banco de dados através do SSMS para administradores
- Salvando o histórico de alterações de versão no próprio banco de dados (quem e quando a implantação)
- Armazenando enumerações em um projeto
- Facilidade de editar e rastrear alterações nas transferências
- Bloqueio de implantação de banco de dados em cima de um existente, se não houver versão de incremento
- A instalação de uma nova versão, histórico de gravação, transferências e reestruturação deve ser realizada em uma transação e revertida completamente em caso de falha em qualquer estágio
Porque as transferências geralmente contêm lógica e são valores básicos, sem os quais a adição de registros a outras tabelas se torna impossível (devido às chaves estrangeiras FK); em essência, elas fazem parte da estrutura do banco de dados, juntamente com os metadados. Portanto, uma alteração em qualquer elemento de enumeração leva a um incremento da versão do banco de dados e, junto com esta versão, os registros devem ter a garantia de atualização durante a implantação.
Eu acho que todas as vantagens de bloquear a implantação sem aumentar a versão são óbvias, uma das quais é a incapacidade de executar novamente o script de publicação, se ele já tiver sido executado com êxito anteriormente.
Embora a rede do banco de dados seja frequentemente proposta para usar apenas a versão principal (sem frações), decidimos usar versões no formato XY, em que Y é o patch quando um erro de digitação foi corrigido na descrição da tabela, coluna, nome do elemento de listagem ou algo mais pequeno, como adicionar um comentário a um procedimento armazenado etc. Em todos os outros casos, a versão principal é criada.
Talvez para alguém não exista nada
disso e tudo seja óbvio. Mas, no devido tempo, despertei muitos nervos e energia em disputas internas sobre como armazenar transferências no projeto de banco de dados, para que fosse o feng shui (
de acordo com minha ideia ) e que fosse conveniente trabalhar com eles, enquanto minimiza a probabilidade de erros.
Com as transferências, em geral, tudo é simples - criamos um arquivo PostDeploy no projeto e escrevemos um código para preencher as tabelas. Com fusões ou trankates - é assim que você gosta. Preferimos piscar, verificando se o número de registros na tabela de destino excede o número de registros que estão na origem (projeto). Se exceder, uma exceção será lançada para chamar a atenção, porque é estranha. Por que há menos registros na fonte? Porque um é supérfluo? Por que de repente? E se o banco de dados já tiver links para ele? Embora usemos chaves estrangeiras (FK), que não permitem excluir o registro, se houver links para ele, ainda preferimos deixar essa opção. Como resultado, o PostDeploy se transformou em uma planilha ilegível, pois para cada tabela a ser preenchida, além dos próprios valores, há também um código de verificação, uma mesclagem e assim por diante.
No entanto, se você usar o PostDeploy no modo SQLCMD, será possível extrair blocos de código em arquivos separados, como resultado, apenas uma lista estruturada de nomes de arquivos permanecerá para preencher as enumerações no PostDeploy.
Existem algumas nuances nas versões do banco de dados. A Internet debate há muito tempo sobre onde armazenar a versão do banco de dados, como deve ser e, em geral, se precisa ser armazenada em algum lugar? Suponha que decidimos que precisamos, em que local do projeto o armazenamos? Em algum lugar na natureza de um script PostDeploy, ou coloque-o em uma variável declarada na primeira linha do script?
Na minha opinião, nem um nem o outro. É mais conveniente quando armazenado em um arquivo separado e não há mais nada lá.
Alguém dirá - há dacpac nas propriedades do projeto e você pode definir a versão nele. Obviamente, você pode até inserir essa versão em seu script, conforme descrito
aqui , mas isso é inconveniente - para alterar a versão do banco de dados, você precisa ir a algum lugar distante, clicar em vários botões. Eu não entendo a lógica da Microsoft - eles a ocultaram em um canto distante, junto com parâmetros de banco de dados como classificação, nível de compatibilidade etc., porque a versão do banco de dados muda tão "frequentemente" quanto os parâmetros de classificação, certo? Quando há desenvolvimento constante, a versão é criada a cada nova implantação, bem, a conveniência de rastrear alterações também desempenha um papel importante, porque quando um arquivo alterado com um nome amigável é aceso, isso é uma coisa e quando o arquivo de projeto .sqlproj é aceso, em que existem muitas linhas no formato XML e, em algum lugar no centro da linha, um dígito alterado é destacado, de alguma forma não muito.
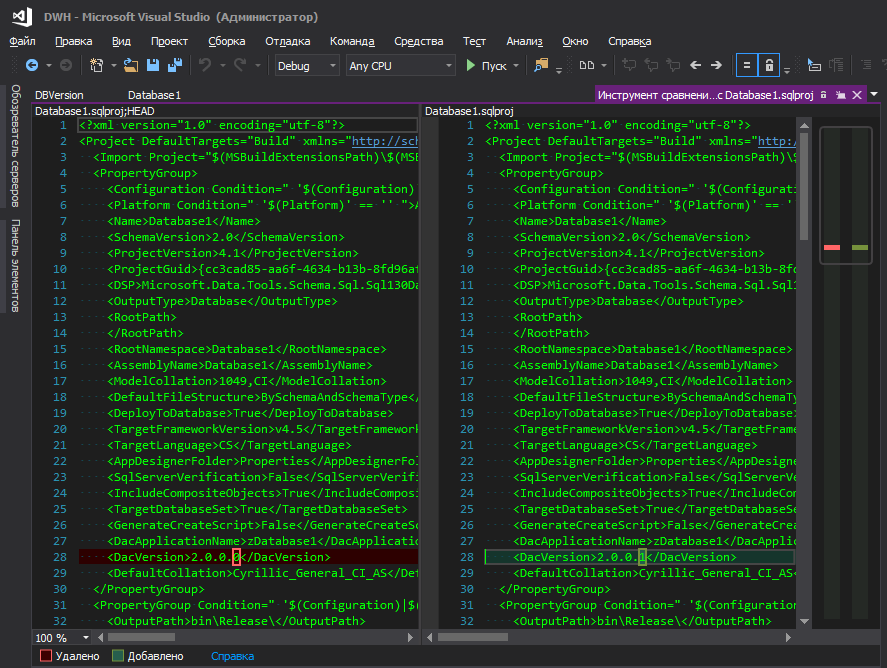
Melhor assim
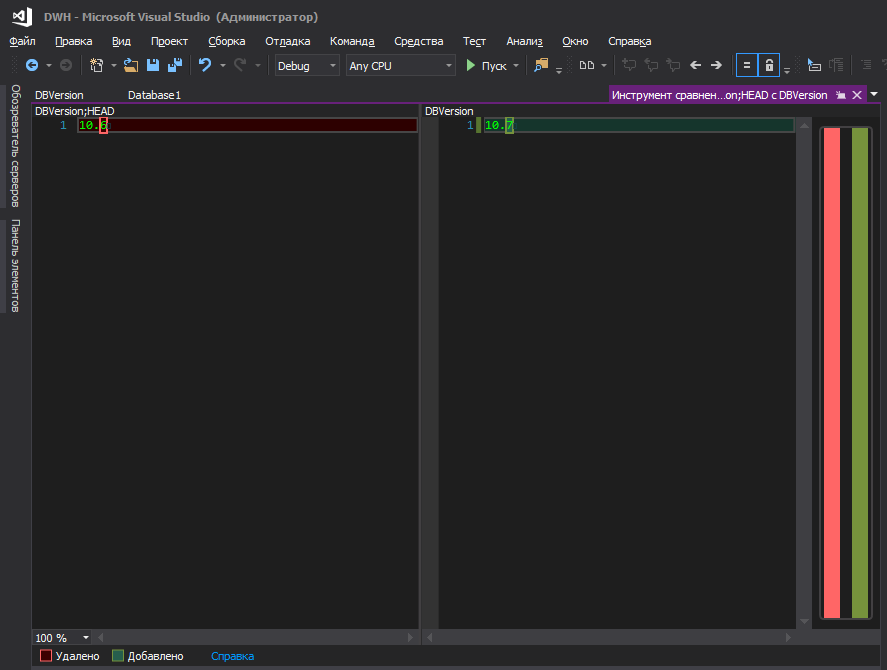
No entanto, talvez sejam apenas minhas baratas e você não deve prestar atenção nelas.
Agora, a pergunta é: onde armazenar esta versão já no banco de dados implantado. Novamente, parece que o dacpac faz isso lindamente - ele grava tudo nas placas do sistema, mas para ver a versão, você precisa executar a solicitação (ou pode ser de outra forma, mas não sei como cozinhá-las? Parece que nas versões mais antigas do SSMS havia uma interface para isso, e agora não)
select * from msdb.dbo.sysdac_instances_internal
para o administrador (e não apenas), não é muito conveniente. É muito mais lógico que a versão seja exibida diretamente nas propriedades do próprio banco de dados.

Ou não?
Para fazer isso, você precisa adicionar um arquivo ao projeto, incluído na compilação, descrevendo as propriedades avançadas
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = '';
Sim, eles estão vazios e parecem feios em um script de publicação, mas você não pode ficar sem eles. Se eles não estiverem descritos no projeto e estiverem no banco de dados, o estúdio tentará excluí-los sempre que for implantado. (Houve muitas tentativas de contornar isso de forma sucinta e sem opções de implantação desnecessárias, mas sem sucesso)
Definiremos os valores para eles no script PostDeploy.
declare @username varchar(256) = suser_sname() ,@curdatetime varchar(20) = format(getdate(),'dd.MM.yyyy HH:mm:ss') EXECUTE sp_updateextendedproperty @name = N'DeployerName', @value = @username; EXECUTE sp_updateextendedproperty @name = N'DBVersion', @value = [$(DBVersion)]; EXECUTE sp_updateextendedproperty @name = N'DeploymentDate', @value = @curdatetime;
sp_updateextendedproperty sem nenhuma verificação, porque no momento em que o bloco foi iniciado no PostDeploy, todas as propriedades já foram criadas se elas não estavam lá.
Bem, seria bom manter o histórico, sobre quem e quando estava implantando o banco de dados.
A implantação de alterações de metadados pode ser realizada na transação usando ferramentas padrão, marcando a
caixa Ativar scripts de transação na janela
Opções avançadas de publicação . Mas esse sinalizador não afeta os scripts (Pré / Pós) e eles continuam sendo executados sem uma transação. Obviamente, nada impede que a transação seja iniciada no início do script PostDeploy, mas será uma transação separada dos metadados, e temos a tarefa de reverter as alterações de metadados se ocorrer uma exceção no PostDeploy.
A solução é simples - inicie a transação no PreDeploy e confirme-a no PostDeploy, e não use nenhuma marca de seleção nas configurações de publicação para esses fins.
Para armazenar convenientemente a versão do banco de dados no projeto e registrá-la nos locais desejados durante a implementação, você pode recorrer às variáveis SQLCMD. No entanto, não quero armazenar a versão em algum lugar natural do código, quero que ela fique na superfície.
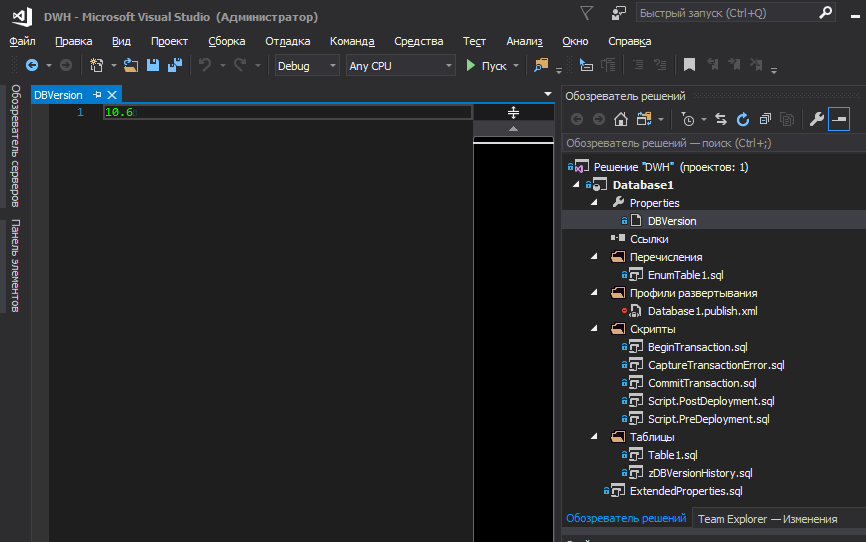
Para colocar a versão do banco de dados em um arquivo separado e gerenciar a versão a partir daí no nível do projeto, adicionamos o seguinte bloco ao .sqlproj:
<Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\Properties\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)" Overwrite="true" /> </Target> </Target>
Esta é uma instrução para o MSBuild ler uma linha de um arquivo antes de criar e criar um arquivo temporário com base nos dados lidos. O MSBuild criará um arquivo
SetPreDepVarsTmp.sql temporário, que
:setvar DBVersion $(ExtDBVersion) linha
:setvar DBVersion $(ExtDBVersion) , onde
$(ExtDBVersion) é o valor lido do nosso arquivo que armazena a versão do banco de dados.
Após essas manipulações, você pode consultar este arquivo temporário no script PreDeploy e iniciar a transação global:
:r .\SetPreDepVarsTmp.sql go :r ".\BeginTransaction.sql"
Versão intermediáriaInicialmente, o arquivo ExtendedProperties.sql não recebeu valores vazios, mas valores de variáveis
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = [$(DeployerName)]; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = [$(DeploymentDate)]; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = [$(DBVersion)];
As variáveis, por sua vez, foram registradas no arquivo SetPreDepVarsTmp.sql automaticamente pelo MSBuild, assim:
<PropertyGroup> <CurrentDateTime>$([System.DateTime]::Now.ToString(dd.MM.yyyy HH:mm:ss))</CurrentDateTime> </PropertyGroup> <PropertyGroup> <NewLine> -- </NewLine> </PropertyGroup> <Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)$(NewLine):setvar DeploymentDate "$(CurrentDateTime)"$(NewLine):setvar DeploymentUser $(UserDomain)\$(UserName)" Overwrite="true" /> </Target>
Com essa abordagem, você não precisa reinstalar essas propriedades no PostDeploy, mas o problema é que SetPreDepVarsTmp.sql continha valores estáticos e se o script de publicação foi gerado agora, mas implantado em uma hora ou, pior ainda, no dia seguinte (o desenvolvedor verificou por um longo tempo visualmente, por exemplo), a data de publicação especificada nas propriedades será diferente da data de publicação real e não coincidirá com a data no histórico.
Conteúdo do arquivo BeginTransaction.sqlEm essência, isso é apenas copiar e colar do bloco inicial de transação padrão que o estúdio gera quando a
caixa de seleção
Ativar scripts de transação está
marcada , mas nós a usamos à nossa maneira. No script, apenas o nome da tabela temporária foi alterado de
#tmpErrors para
#tmpErrorsManual para que não haja conflito de nomes se alguém
#tmpErrorsManual a caixa de seleção.
IF (SELECT OBJECT_ID('tempdb..#tmpErrors')) IS NOT NULL DROP TABLE
Script PostDeploy declare @TableName VarChar(255) = null
A variável SkipEnumDeploy, como já ficou clara, permite que você pule o estágio de atualização de listagens; isso pode ser útil para pequenas alterações cosméticas. Embora, do ponto de vista da religião, isso possa não ser verdade, no entanto, é definitivamente útil no estágio de desenvolvimento.
Os arquivos
CaptureTransactionError.sql e
CommitTransaction.sql também
CommitTransaction.sql copiados e colados (com correções menores) do algoritmo de transação padrão que o estúdio gera quando o sinalizador acima é definido, e que agora tocamos por conta própria.
Content CaptureTransactionError.sql IF @@ERROR <> 0 AND @@TRANCOUNT > 0 BEGIN ROLLBACK; END IF @@TRANCOUNT = 0 BEGIN INSERT INTO
Conteúdo CommitTransaction.sql Conteúdo EnumTable1.sql set @TableName = N'Table1' PRINT N' '+@TableName+'...' begin try set nocount on drop table if exists
Ao implantar o
Publish script terá a seguinte estrutura
Idealmente, é claro, gostaria que a versão fosse exibida no momento da publicação

Mas você não pode extrair o valor do arquivo para esta janela, embora o MSBuild o leia e o coloque na propriedade ExtDBVersion com a ajuda de instruções adicionais no arquivo .sqlproj, como no exemplo acima, mas a construção
<SqlCmdVariable Include="DBVersion"> <DefaultValue> </DefaultValue> <Value>$(ExtDBVersion)</Value> </SqlCmdVariable>
não rola.
Os desenvolvedores de sequelas em seu
diário escrevem como isso é feito. De acordo com sua versão, a mágica está na instrução
SqlCommandVariableOverride , que é simples - adicione algumas linhas ao arquivo de projeto .sqlproj
<ItemGroup> <SqlCommandVariableOverride Include="DBVersion=$(ExtDBVersion)" /> </ItemGroup>
e pronto. Boa tentativa, mas não. Talvez quando este post foi publicado, tudo funcionou, mas desde então, nos Estados Unidos, você teve três eleições presidenciais e ninguém sabe quais instruções podem parar de funcionar amanhã.

E
aqui um camarada tentou todas as opções, mas nenhuma delas decolou.
Portanto, pegue a versão do dacpac ou armazene-a no PostDeploy, ou em um arquivo separado, ou _________ (insira sua versão).
Integração com 1C
O primeiro problema foi que o 1C77 não possui servidor de aplicativos ou outro daemon que permita interagir com ele sem iniciar a plataforma. Quem trabalhou com 1C77 sabe que ela não possui um modo de console completo. Você pode executar a plataforma com parâmetros e até fazer algo com base neles, mas há muito poucos parâmetros de console e seu objetivo era diferente. Mas mesmo com a ajuda deles, você pode nakolkhozit uma combinação inteira. No entanto, ele pode voar imprevisivelmente, pode abrir uma janela modal e aguardar alguém clicar em OK e em outros encantos. E, talvez, o maior problema - a velocidade da plataforma deixe muito a desejar ... Portanto, existe apenas uma solução - consultas diretas ao banco de dados 1C. Dada a estrutura, você não pode simplesmente pegar e escrever essas consultas, mas o benefício é que toda a comunidade desenvolveu uma ferramenta maravilhosa - 1C ++ (1cpp.dll), que é incrível para eles, OBRIGADO! A biblioteca permite que você escreva consultas em termos de 1C, que depois se transformam em nomes reais de tabelas e campos. Se alguém não souber, a solicitação pode ser escrita usando um pseudo-nome e ficará assim
select from $.
Essa solicitação é compreensível para os seres humanos, mas não existe tal tabela e campo no servidor; existem outros nomes; portanto, 1C ++ o transformará em
select SP5278 from SC2235
e essa solicitação já é entendida pelo servidor. Todo mundo está feliz, ninguém jura - nem uma pessoa nem um servidor. Aqui, ao que parece, o problema foi resolvido.
O segundo problema estava no plano de configurações: uma configuração era usada nas filiais, outra no escritório central e a terceira nas filiais! Classe? !! 1 Eu também acho. Além disso, eles não são típicos e nem sequer são patrimônios típicos, mas completamente escritos do zero durante os vikings e, infelizmente, não os melhores arquitetos lançaram as bases desses conf ... Implementação de documentos, por exemplo, em cada configuração, tem um conjunto diferente de detalhes. Mas não apenas os nomes de alguns campos diferem, o que é muito mais divertido quando os nomes dos detalhes são os mesmos, mas o significado dos dados armazenados neles é DIFERENTE.

Nas configurações, quase nenhum registro é usado, tudo é construído com base nas complexidades dos documentos. Portanto, às vezes eu tinha que escrever uma planilha inteira em uma transação limpa, com vários casos e junções, para repetir a lógica de algum procedimento da configuração, que exibe algumas informações no campo de texto no formulário.
Devemos prestar homenagem à equipe de desenvolvimento, que todos esses anos apoiaram o que eles herdaram dos "implementadores", é um trabalho enorme - apoiar isso e até otimizar alguma coisa. Até você ver - você não entende, eu mesmo não acreditei no começo que tudo pudesse ser tão complicado. Pergunte - por que não reescrever do zero? Banal falta de recursos. A empresa estava se desenvolvendo tão rápido que, apesar de uma grande equipe de programadores, eles simplesmente não conseguiam acompanhar as necessidades dos negócios, sem mencionar a reescrita de todo o conceito.
Continuamos a história dos pedidos. Obviamente, todos os blocos para extração de dados se transformaram em armazenamentos, para que mais tarde eles pudessem ser lançados no servidor ignorando a plataforma 1C. A regra era a seguinte: um armazenamento é responsável por recuperar uma entidade. Porque A lista de desejos no estágio inicial já se acumulou bastante, porque se tornou dolorosa ao longo dos anos e, em seguida, dezenas de arquivos de armazenamento acabaram.
O terceiro problema é como aumentar a velocidade e a qualidade do desenvolvimento e como apoiar todo esse monstro? Escreva uma solicitação para 1C ++ e copie e cole o resultado de sua conversão em um armazenamento? É muito inconveniente e entediante, além disso, existe uma alta probabilidade de erros - copie o errado ou o errado ou não selecione a última linha da consulta e copie sem ela. Isso é especialmente verdadeiro quando se trata de consultas 1C diretas, porque não há pseudo-nome como
Directory. Nomenclatura. Artigo, apenas nomes reais
SC2235.SP5278 e, portanto, copiar uma solicitação do diretório de mercadorias para uma loja que recupera clientes é muito simples. Obviamente, a solicitação provavelmente cairá devido à incompatibilidade de tipos e número de campos na tabela de destino, mas existem placas idênticas, como enumerações, nas quais apenas duas colunas são ID e Nome. Em geral, resta apenas aplicar algum tipo de automação. Bem, letras suficientes, vamos ao que interessa!
Eu queria que o processo de desenvolvimento de armazenamento se resumisse a algo assim:
- Corrigimos a consulta SQL com pseudo-nomes e salvamos
- Pressionamos um botão mágico e, na saída, recebemos o procedimento armazenado corrigido no SQL convertido, limpo para o servidor
Alguns detalhes
Para resolver o terceiro problema, o processamento externo (.ert) foi gravado. Existem vários procedimentos em processamento, cada um dos quais contém o texto da consulta para extrair uma entidade usando um pseudo-nome, como
select * from $.
No formulário de processamento, há um campo para exibir o resultado de um procedimento específico, ou seja, solicitação convertida para um formulário compreensível para o servidor, para que você possa testá-lo rapidamente. Além disso, um
bloco de depuração é sempre adicionado a essa solicitação, com a declaração de variáveis, os nomes dos bancos de dados de teste, servidores e muito mais. Resta apenas copiar e colar no SSMS e pressionar F5. É claro que você pode executar essa solicitação a partir do próprio processamento, mas o plano de solicitação e tudo o que, bem, você entende ... Em geral, é assim que a depuração é feita. Porque Existem várias configurações: no processamento, é possível converter os mesmos textos de consulta com pseudo-nomes de objetos em consultas finais para configurações diferentes. De fato, em uma referência da Nomenclatura confe é SC123 e em outra - SC321. Mas o 1C ++ permite carregar configurações diferentes em tempo de execução e gerar uma saída individual para cada uma delas, de acordo com o dicionário.
Em seguida, o modo de execução em lote foi adicionado ao processamento, quando ele inicia automaticamente cada um dos procedimentos para cada configuração e a saída de cada um deles é gravada em arquivos .sql (a seguir, os arquivos básicos). Assim, obtemos várias combinações de arquivos básicos, que posteriormente devem se transformar automaticamente em procedimentos armazenados usando o VS. Vale ressaltar que os arquivos base incluem
um bloco de depuração .
Parece, por que não concluir imediatamente os arquivos finais dos procedimentos armazenados e manter tudo nesse processamento? O fato é que, para alguns testes, é necessário executar versões de depuração de consultas em lotes nos quais todas as variáveis são declaradas, além disso, eu queria que os nomes dos procedimentos armazenados fossem gerenciados pelo VS, ignorando 1C, porque é lógico, não é?
A propósito, os arquivos básicos também são armazenados no projeto, bem, os arquivos dos procedimentos armazenados prontos, é claro. A qualquer momento, sem iniciar o 1C, você pode abrir o arquivo base no SSMS e executá-lo sem se preocupar com declarações de variáveis.
No processamento, todos os procedimentos com solicitações também são modelo, com o mesmo conjunto de parâmetros, mas neste ou naquele procedimento apenas os parâmetros necessários são utilizados. Em alguns, tudo está envolvido e, em alguns, dois são suficientes. Portanto, adicionar um novo procedimento se resume a copiar o modelo e preencher os parâmetros com as próprias consultas.
O código de um dos procedimentos de processamento, que depois se transformará em um procedimento armazenado
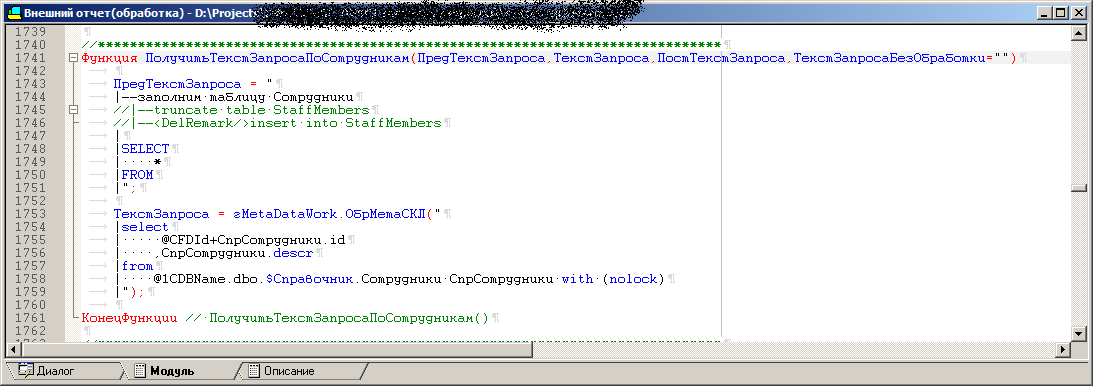
A consulta final está mais ou menos assim:
++"("+OPENQUERY()+")"+
Aparência do processamento

Ao alternar configurações, a lista de itens disponíveis (necessários) para descarregar itens na lista Dados é alterada. Se possível, o código do procedimento em 1C foi o máximo possível unificado. Se as contrapartes são extraídas e esses diretórios são inconsistentes em configurações diferentes, então dentro do procedimento de geração existem casos diferentes, como: esse bloco é corrigido para todos, este é adicionado à solicitação final apenas para uma conf. E existe um para o outro. Acontece que nos procedimentos armazenados para uma entidade, mas em configurações diferentes, eles podem diferir não apenas pelos nomes de tabelas, mas também por blocos inteiros de junções presentes em uma e ausentes em outra. O conjunto de campos de saída, é claro, é o mesmo e corresponde à tabela receptora ou ao contêiner do pacote SSIS; alguns campos estão obstruídos com stubs para configurações nas quais esses detalhes não são em princípio.
Botão mágicoO Visual Studio possui ferramentas como o MSbuild e os incríveis modelos T4. Portanto, como um botão mágico, um script foi escrito em C # para T4, que:
- Registra uma configuração vazia no registro (caso contrário, 1C exibirá uma janela modal com uma sugestão para registrar uma conf e aguardar ações do usuário)
- Cria um banco de dados vazio para este konf no servidor SQL, porque sem ele o 1C dará um erro
- Inicia 1C e através do OLE diz para executar o processamento (o mesmo .ert), também transferindo um GUID exclusivo para 1C
- A saída é uma série de arquivos com solicitações prontas (convertidas) e um arquivo de marcador, no qual o GUID recebido na inicialização é gravado
- O registro do conf é excluído do registro e um banco de dados temporário vazio é excluído do servidor
- Verifica o conteúdo do arquivo de token. Se o arquivo do marcador contiver o GUID que passamos para o 1C quando iniciado, significa que ele funcionou até o fim, não travou, etc., então vá para a próxima etapa ou exibimos um erro
- Criamos armazéns.
- Nós descompilamos o arquivo .ert com o gcomp para obter os textos dos módulos e os formulários de processamento, bem, convertemos para Unicode, para envio subsequente ao Git e exibido corretamente lá. Para aqueles que não trabalharam com 1C: o arquivo .ert é um binário e o estúdio, junto com o git, mostra que o arquivo .ert foi alterado, mas não está claro o que exatamente mudou nele, talvez apenas alguém tenha movido o botão um pixel para a esquerda (o que inaceitável sem justificativa)
T4 , ( , ) . , . , , , , - — 1.
, , , , , . — 1, 1, - .
: ?
- / ;
- VS , ;
- 4;
. Feito.
?Porque , , .sqlproj,
<ItemGroup> <None Include=" \1.sql"> <None Include=" \2.sql"> <None Include=" \3.sql"> </ItemGroup>
<ItemGroup> <Content Include=" \*.sql" /> </ItemGroup>
« ». , , , :)
, , (, ) . ( ), , - - - , .
, . . , , , , , ( ), . , ( , ) , , , . , . , , , , , ( , 1, , MD ).
,
OPENQUERY , 1 , , , ,
EXEC .
OPENQUERY , , , .
177 ( ) SQL2000, varchar(max) , varchar(8000), 9, … , EXEC(@SQL1+@SQL2). , SQL2016, SQL2000. , , .
select ... from ( select ... from @1CDBName.dbo.$. join @1CDBName.dbo.$. join ... where xxx = 'hello!' ^
CREATE PROCEDURE [dbo].[SP1] @LinkedServerName varchar(24) ,@1CDBName varchar(24) AS BEGIN Declare @TSQL0 varchar(8000), @TSQL1 varchar(8000), @TSQL2 varchar(8000) set @TSQL0=' select ... from OPENQUERY('+@LinkedName+','' select ... from '+@1CDBName+'.dbo.DH123. join '+@1CDBName+'.SC123. ... where '; set @TSQL1=' xxx = ''''hello!'''' join ... join ... )'' join ... '''; set @TSQL2=' ... EXEC(@TSQL0+@TSQL1+@TSQL2) END
— . (, ) , , , , , , OPENQUERY 8 .
.ert , .. , .
, .
ETL
, ( ). (Stage). , ETL SSIS , , , , . . ( ), .
, ( ) , , (.. ), , .
, , . , . zabbix.
.
Porque 1 , , . , ,
truncate .
, ( ) -, « 1-» .
SSIS
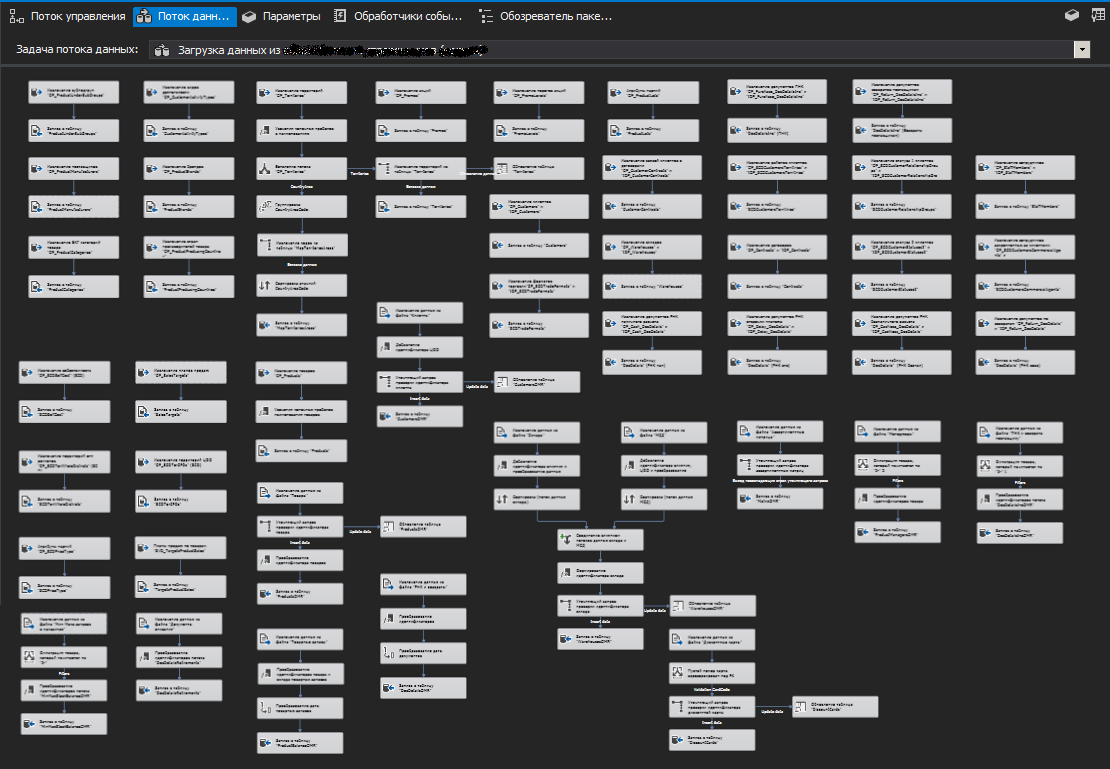
,
SSIS
SQL Server (SQL Server Destination), ,
OLE DB (OLE DB Destination).
, , , . , , . (, )
. , , , (/ ).
.
, ( ). I.e. , . , , . - — . .
, (.. ) .
, , .
PS
, , , , . — , . - , , .