Esta nota é uma versão escrita do meu relatório "Como arruinar o desempenho com código ineficiente" da conferência JPoint 2018. Você pode assistir a vídeos e slides na página da conferência . No cronograma, o relatório é marcado com um copo ofensivo de smoothies; portanto, não haverá nada super complicado, é mais provável para iniciantes.
Assunto do relatório:
- como olhar o código para encontrar gargalos nele
- antipadrões comuns
- ancinho não óbvio
- desvio de ancinho
À margem, eles apontaram algumas imprecisões / omissões no relatório, são anotadas aqui. Comentários também são bem-vindos.
Impacto no desempenho
Existe uma classe de usuário:
class User { String name; int age; }
Como precisamos comparar os objetos, declaramos os métodos equals e hashCode :
import lombok.EqualsAndHashCode; @EqualsAndHashCode class User { String name; int age; }
O código é viável, a questão é diferente: o desempenho desse código será o melhor? Para responder, vamos relembrar os recursos do método Object::equals : ele retorna um resultado positivo apenas quando todos os campos comparados são iguais, caso contrário, o resultado será negativo. Em outras palavras, uma diferença já é suficiente para um resultado negativo.
Depois de analisar o código gerado para @EqualsAndHashCode veremos algo assim:
public boolean equals(Object that) {
A ordem de verificação dos campos corresponde à ordem de sua declaração, que no nosso caso não é a melhor solução, porque comparar objetos usando equals "mais difícil" do que comparar tipos simples.
Ok, vamos tentar criar métodos equals/hashCode usando a idéia:
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(name, that.name); }
Uma idéia cria um código mais inteligente que conhece a complexidade da comparação de diferentes tipos de dados. Bem, @EqualsAndHashCode e escreveremos explicitamente equals/hashCode . Agora vamos ver o que acontece quando a classe se estende:
class User { List<T> props; String name; int age; }
Recriando equals/hashCode :
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(props, that.props)
As listas são comparadas antes das cadeias, o que não faz sentido quando as cadeias são diferentes. À primeira vista, não há muita diferença, porque cadeias de comprimento igual são comparadas por sinais (ou seja, o tempo de comparação cresce junto com o comprimento da cadeia):
Houve uma imprecisãoO método java.lang.String::equals é invasivo , portanto, não há comparação de logon na execução.
Agora considere comparar duas ArrayList (como a implementação de lista mais usada). Examinando ArrayList , ficamos surpresos ao descobrir que ele não possui sua própria implementação de equals , mas usa uma implementação herdada:
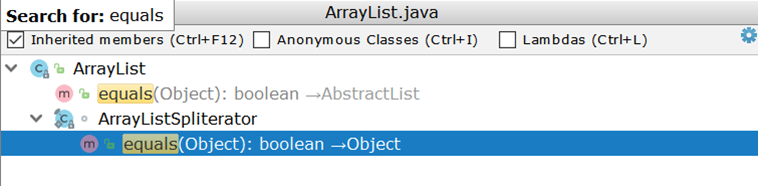
Importante aqui é a criação de dois iteradores e a passagem aos pares através deles. Suponha que haja duas ArrayList :
- em um número de 1 a 99
- no segundo número de 1 a 100
Idealmente, seria suficiente comparar os tamanhos das duas listas e, se não coincidirem, retornar imediatamente um resultado negativo (como o AbstractSet ), na realidade, 99 comparações serão realizadas e somente no centésimo ficará claro que as listas são diferentes.
O que há com os kotlinitas?
data class User(val name: String, val age: Int);
Aqui tudo é como um Lombok - a ordem de comparação corresponde à ordem do anúncio:
public boolean equals(Object o) { if (this == o) { return true; } if (o instanceof User) { User u = (User) o; if (Intrinsics.areEqual(name, u.name) && age == u.age) {
Como solução alternativa, você pode organizar manualmente as declarações de campo.
Vamos complicar a tarefa
void check(Dto dto) { SomeEntity entity = jpaRepository.findOne(dto.getId()); boolean valid = dto.isValid(); if (valid && entity.hasGoodRating()) {
O código envolve o acesso ao banco de dados, mesmo quando o resultado da verificação das condições indicadas pela seta é previsível com antecedência. Se o valor da variável valid for falso, o código no bloco if nunca será executado, o que significa que você pode fazer sem uma solicitação:
void check(Dto dto) { boolean valid = dto.isValid(); if (valid && hasGoodRating(dto)) {
Nota do lado de foraO afundamento pode ser insignificante quando a entidade retornada de JpaRepository::findOne já JpaRepository::findOne no cache do primeiro nível - então não haverá solicitação.
Um exemplo semelhante sem ramificação explícita:
boolean checkChild(Dto dto) { Long id = dto.getId(); Entity entity = jpaRepository.findOne(id); return dto.isValid() && entity.hasChild(); }
Um retorno rápido permite adiar a solicitação:
boolean checkChild(Dto dto) { if (!dto.isValid()) { return false; } return jpaRepository.findOne(dto.getId()).hasChild(); }
Uma adição bastante óbvia que não apareceu no relatórioImagine que uma determinada verificação usa uma entidade semelhante:
@Entity class ParentEntity { @ManyToOne(fetch = LAZY) @JoinColumn(name = "CHILD_ID") private ChildEntity child; @Enumerated(EnumType.String) private SomeType type;
Se a verificação usar a mesma entidade, verifique se a chamada para as entidades / coleções filho "preguiçosas" é executada após a chamada para os campos que já estão carregados. À primeira vista, uma solicitação adicional não terá um impacto significativo na imagem geral, mas tudo pode mudar quando uma ação é executada em um loop.
Conclusão: as cadeias de ações / verificações devem ser ordenadas em ordem crescente de complexidade das operações individuais, talvez algumas delas não precisem ser executadas.
Ciclos e processamento em massa
O exemplo a seguir não precisa de explicações especiais:
@Transactional void enrollStudents(Set<Long> ids) { for (Long id : ids) { Student student = jpaRepository.findOne(id);
Devido a várias consultas ao banco de dados, o código é lento.
ObservaçãoO desempenho pode enrollStudents ainda mais se o método enrollStudents executado fora de uma transação: cada chamada para osdjrJpaRepository::findOne será executada em uma nova transação (consulte SimpleJpaRepository ), o que significa receber e retornar uma conexão ao banco de dados, além de criar e liberar o cache de primeiro nível.
Fix:
@Transactional void enrollStudents(Set<Long> ids) { if (ids.isEmpty()) { return; } for (Student student : jpaRepository.findAll(ids)) { enroll(student); } }
Vamos medir o tempo de execução (em microssegundos) para uma coleção de chaves (10 e 100 peças) Referência
ObservaçãoSe você usa Oracle e passa mais de 1000 chaves para findAll , a exceção ORA-01795: maximum number of expressions in a list is 1000 .
Além disso, executar uma consulta pesada (com muitas chaves) in consultas pode ser pior que n consultas. Tudo depende da aplicação específica, portanto a substituição mecânica do ciclo para o processamento em massa pode prejudicar o desempenho.
Um exemplo mais complexo sobre o mesmo tópico
for (Long id : ids) { Region region = jpaRepository.findOne(id); if (region == null) {
Nesse caso, não podemos substituir o ciclo por JpaRepository::findAll , JpaRepository::findAll isso quebrará a lógica: todos os valores obtidos de JpaRepository::findAll não serão null e o bloco if não funcionará.
O fato de que para cada chave de banco de dados nos ajudará a resolver essa dificuldade
retorna o valor real ou sua ausência. Ou seja, em certo sentido, um banco de dados é um dicionário. O Java da caixa nos fornece uma implementação pronta do dicionário - HashMap - sobre a qual construiremos a lógica para substituir o banco de dados:
Map<Long, Region> regionMap = jpaRepository.findAll(ids) .stream() .collect(Collectors.toMap(Region::getId, Function.identity())); for (Long id : ids) { Region region = map.get(id); if (region == null) { region = new Region(); region.setId(id); } use(region); }
Exemplo reverso
Esse código sempre cria uma nova transação para salvar uma lista de entidades. A flacidez começa com várias chamadas para um método que abre uma nova transação:
Solução: aplique o método Saver::save imediatamente para todo o conjunto de dados:
@Transactional public void audit(List<AuditDto> inserts) { List<AuditEntity> bulk = inserts .map(this::toEntities) .flatMap(List::stream)
Muitas transações se fundem em uma, o que fornece um aumento tangível (tempo em microssegundos): Referência
É difícil formalizar um exemplo com várias transações, o que não pode ser dito sobre a chamada de JpaRepository::findOne em um loop.
A abordagem é aplicável não apenas ao banco de dados, então Tagir lany Valeev foi além. E se anteriormente escrevemos assim:
List<Long> list = new ArrayList<>(); for (Long id : items) { list.add(id); }
e estava tudo bem, agora a "Idéia" sugere se corrigir:
List<Long> list = new ArrayList<>(); list.addAll(items);
Mas mesmo essa opção nem sempre a satisfaz, porque você pode torná-la ainda mais curta e mais rápida:
List<Long> list = new ArrayList<>(items);
Compare (tempo em ns)Para ArrayList, essa melhoria oferece um aumento notável:
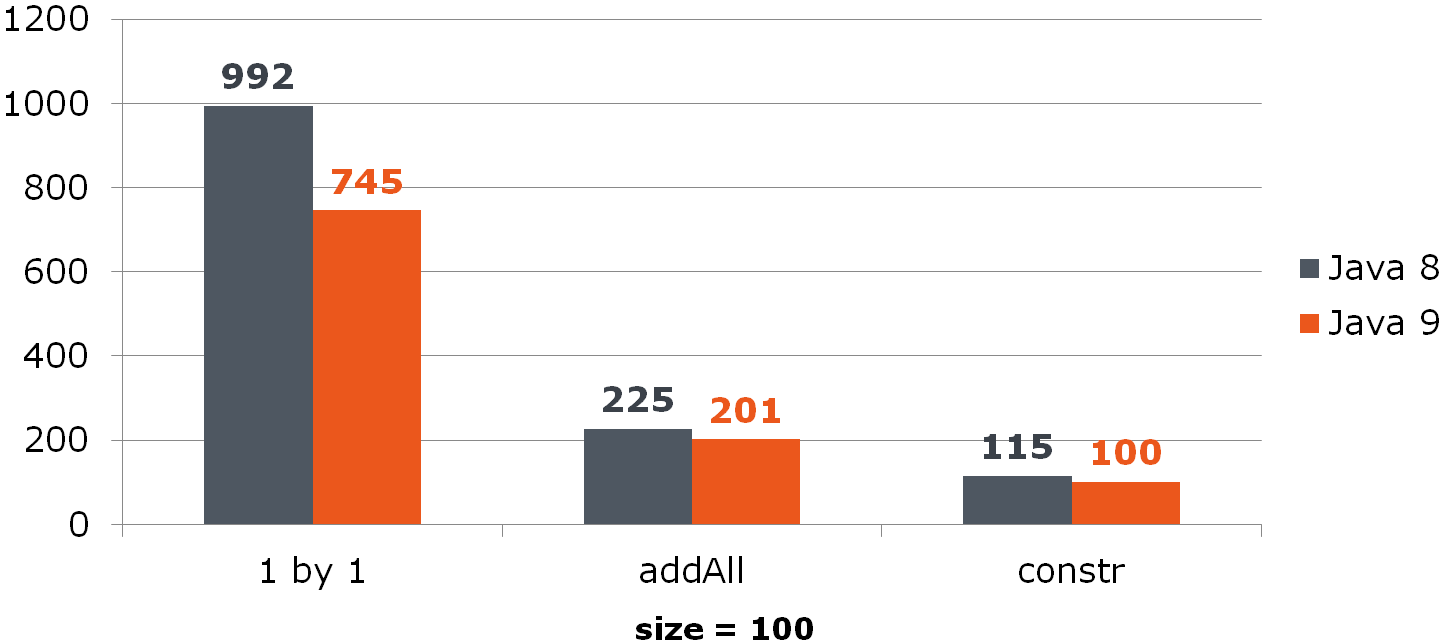
Para o HashSet, não é tão otimista:

Referência
Removendo do ArrayList
for (int i = from; i < to; i++) { list.remove(from); }
O problema está na implementação do método List::remove :
public E remove(int index) { Objects.checkIndex(index, size); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) { System.arraycopy(array, index + 1, array, index, numMoved);
Solução:
list.subList(from, to).clear();
Mas e se o valor remoto for usado no código-fonte?
for (int i = from; i < to; i++) { E removed = list.remove(from); use(removed); }
Agora você precisa primeiro passar pela lista limpa:
List<String> removed = list.subList(from, to); removed.forEach(this::use); removed.clear();
Se você realmente deseja excluir o ciclo, uma mudança na direção da passagem pela lista ajudará a aliviar a dor. Seu significado é mudar um número menor de elementos após a limpeza da célula:
Compare todos os três métodos (nas colunas estão% itens removidos de uma lista de tamanho 100):
A propósito, alguém notou a anomalia?
Ver
Se excluirmos metade de todos os dados movidos do final, o último elemento será sempre excluído e não haverá mudança:
Referência
Conclusão: operações em massa geralmente são mais rápidas que operações únicas.
Escopo e desempenho
Este código não precisa de explicações especiais:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); List<Student> underAchieving = repository.findUnderAchieving();
Limitamos o escopo, o que fornece menos 1 consulta:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); if (Settings.leaveBothCategories()) { List<Student> underAchieving = repository.findUnderAchieving();
E aqui o leitor atento deve perguntar: e a análise estática? Por que a Idea não nos contou sobre a melhoria que está na superfície?
O fato é que as possibilidades de análise estática são limitadas: se o método é complexo (principalmente interagindo com o banco de dados) e afeta o estado geral, a transferência de sua execução pode interromper o aplicativo. O analisador estático é capaz de relatar execuções muito simples, cuja transferência, digamos, dentro do bloco não quebrará nada.
Você pode usar o destaque variável como uma ersatz, mas novamente, use-o com cuidado, pois os efeitos colaterais são sempre possíveis. Você pode usar a anotação @org.jetbrains.annotations.Contract(pure = true) , disponível na biblioteca jetbrains-annotations para indicar métodos que não mudam de estado:
Conclusão: na maioria das vezes, o excesso de trabalho só piora o desempenho.
Exemplo mais incomum
@Service public class RemoteService { private ContractCounter contractCounter; @Transactional(readOnly = true)
Essa implementação abre uma transação mesmo quando a transação não é necessária (retorno rápido -1 do método).
Tudo que você precisa fazer é remover a transacionalidade dentro do ContractCounter::countContracts , onde for necessário, e removê-la do método "externo".
Compare o tempo de execução para o caso quando -1 (ns) for retornado: Compare o consumo de memória (bytes): Referência
Conclusão: controladores e serviços "externos" precisam ser liberados da transacionalidade (essa não é sua responsabilidade) e toda a lógica da verificação de dados de entrada, que não requer acesso ao banco de dados e aos componentes transacionais, deve ser executada lá.
Converter data / hora em string
Uma das tarefas eternas é transformar data / hora em uma sequência. Antes do G8, fizemos o seguinte:
SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.yyyy"); String dateAsStr = formatter.format(date);
Com o lançamento do JDK 8, obtivemos LocalDate/LocalDateTime e, portanto, DateTimeFormatter
DateTimeFormatter formatter = ofPattern("dd.MM.yyyy"); String dateAsStr = formatter.format(localDate);
Vamos medir o seu desempenho:
Date date = new Date(); LocalDate localDate = LocalDate.now(); SimpleDateFormat sdf = new SimpleDateFormat("dd.MM.yyyy"); DateTimeFormatter dtf = DateTimeFormatter.ofPattern("dd.MM.yyyy"); @Benchmark public String simpleDateFormat() { return sdf.format(date); } @Benchmark public String dateTimeFormatter() { return dtf.format(localDate); }
Pergunta: digamos que nosso serviço receba dados de fora e não possamos recusar o java.util.Date . Seria vantajoso converter Date em LocalDate se o último for convertido mais rapidamente em uma string? Calcular:
@Benchmark public String measureDateConverted(Data data) { LocalDate localDate = toLocalDate(data.date); return data.dateTimeFormatter.format(localDate); } private LocalDate toLocalDate(Date date) { return date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate(); }
Portanto, a conversão Date -> LocalDate benéfica ao usar o "nove". No G8, os custos de conversão absorvem todos os benefícios do DateTimeFormatter -a.
Referência
Conclusão: tire proveito de novas soluções.
Outro "oito"
Neste código, vemos redundância óbvia:
Iterator<Long> iterator = items
Nós o removemos:
Iterator<Long> iterator = items
Vamos ver quanto desempenho melhorou: Incrível né? Argumentei acima que o excesso de trabalho prejudica o desempenho. Mas aqui removemos o excesso - e (de repente) fica pior. Para entender o que está acontecendo, pegue dois iteradores e olhe para eles sob uma lupa:
Divulgar Iterator iterator1 = items.stream().collect(toList()).iterator(); Iterator iterator2 = items.stream().iterator();

O primeiro iterador é o ArrayList$Itr regular.
A passagem por ele é simples: public boolean hasNext() { return cursor != size; } public E next() { checkForComodification(); int i = cursor; if (i >= size) { throw new NoSuchElementException(); } Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } cursor = i + 1; return (E) elementData[lastRet = i]; }
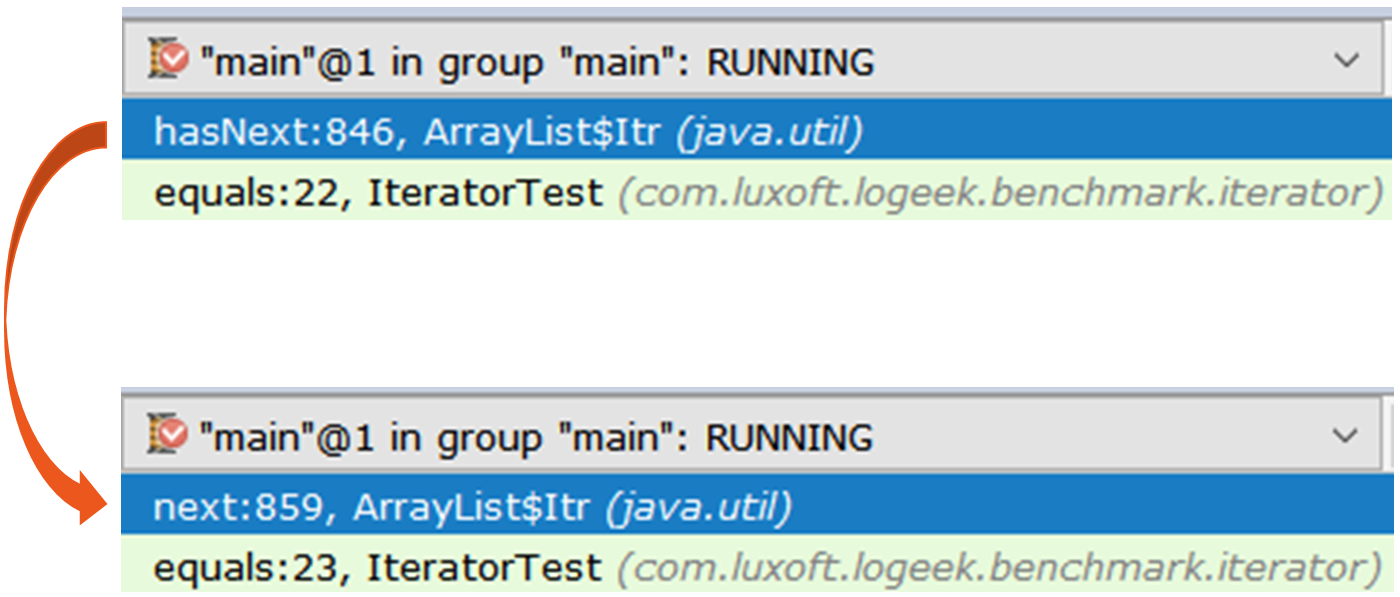
O segundo é mais interessante, é o Spliterators$Adapter , que é baseado em ArrayList$ArrayListSpliterator .
Passando por isso é mais difícil Vejamos a iteração do iterador através do async-profiler :
15.64% juArrayList$ArrayListSpliterator.tryAdvance 10.67% jusSpinedBuffer.clear 9.86% juSpliterators$1Adapter.hasNext 8.81% jusStreamSpliterators$AbstractWrappingSpliterator.fillBuffer 6.01% oojiBlackhole.consume 5.71% jusReferencePipeline$3$1.accept 5.57% jusSpinedBuffer.accept 5.06% cllbir.IteratorFromStreamBenchmark.iteratorFromStream 4.80% jlLong.valueOf 4.53% cllbiIteratorFromStreamBenchmark$$Lambda$8.885721577.apply
Pode-se observar que a maior parte do tempo é gasta passando pelo iterador, embora em geral não seja necessário, pois a pesquisa pode ser feita assim:
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Stream::forEach claramente um vencedor, mas isso é estranho: ainda é baseado no ArrayListSpliterator , mas seu uso melhorou significativamente.
Vamos ver o perfil: 29.04% oojiBlackhole.consume 22.92% juArrayList$ArrayListSpliterator.forEachRemaining 14.47% jusReferencePipeline$3$1.accept 8.79% jlLong.valueOf 5.37% cllbiIteratorFromStreamBenchmark$$Lambda$9.617691115.accept 4.84% cllbiIteratorFromStreamBenchmark$$Lambda$8.1964917002.apply 4.43% jusForEachOps$ForEachOp$OfRef.accept 4.17% jusSink$ChainedReference.end 1.27% jlInteger.longValue 0.53% jusReferencePipeline.map
Nesse perfil, a maior parte do tempo é gasta “engolindo” os valores dentro do Blackhole . Comparado a um iterador, uma parte significativamente maior do tempo é gasta diretamente na execução do código Java. Pode-se supor que o motivo seja o menor peso específico da coleta de lixo, comparado com a força bruta do iterador. Verifique:
forEach:·gc.alloc.rate.norm 100 avgt 30 216,001 ± 0,002 B/op iteratorFromStream:·gc.alloc.rate.norm 100 avgt 30 416,004 ± 0,006 B/op
De fato, o Stream::forEach fornece metade do consumo de memória.
Por que é mais rápido?A cadeia de chamadas do começo ao buraco negro é assim:
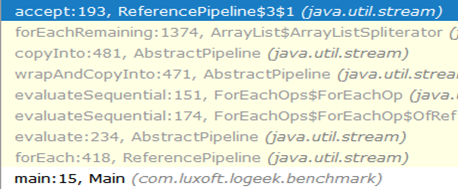
Como você pode ver, a chamada para ArrayListSpliterator::tryAdvance desapareceu da cadeia e ArrayListSpliterator::forEachRemaining apareceu:
ArrayListSpliterator::forEachRemaining alta velocidade ArrayListSpliterator::forEachRemaining obtido usando uma passagem por toda a matriz em uma chamada de método. Ao usar um iterador, a passagem é limitada a um elemento, portanto, sempre nos ArrayListSpliterator::tryAdvance .
ArrayListSpliterator::forEachRemaining tem acesso a toda a matriz e a ArrayListSpliterator::forEachRemaining com um ciclo de contagem sem chamadas adicionais.
Aviso importanteObserve que a substituição mecânica
Iterator<Long> iterator = items .stream() .map(Long::valueOf) .collect(toList()) .iterator(); while (iterator.hasNext()) { bh.consume(iterator.next()); }
em
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Nem sempre é equivalente, porque no primeiro caso usamos uma cópia dos dados para a passagem sem afetar o próprio fluxo e, no segundo caso, os dados são coletados diretamente do fluxo.
Referência
Conclusão: ao lidar com representações complexas de dados, esteja preparado para o fato de que mesmo as regras "de ferro" (trabalho extra prejudicial) param de funcionar. O exemplo acima mostra que a lista intermediária aparentemente supérflua oferece a vantagem de uma implementação mais rápida da enumeração.
Dois truques
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays .asList(trace) .subList(0, depth) .toArray(new StackTraceElement[newDepth]);
A primeira coisa que chama sua atenção é uma "melhoria" podre, a saber, passar uma matriz de comprimento diferente de zero para o método Collection::toArray . Explica detalhadamente por que isso é prejudicial.
O segundo problema não é tão óbvio e, para sua compreensão, podemos traçar um paralelo entre o trabalho do revisor e o historiador.
Isto é o que Robin Collingwood escreve sobre isso: . :
1)
2)
3)
, :
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays.copyOf(trace, depth);
List<T> list = getList(); Set<T> set = getSet(); return list.stream().allMatch(set::contains);
, , :
List<T> list = getList(); Set<T> set = getSet(); return set.containsAll(list);
:
interface FileNameLoader { String[] loadFileNames(); }
:
private FileNameLoader loader; void load() { for (String str : asList(loader.loadFileNames())) {
, forEach , :
private FileNameLoader loader; void load() { for (String str : loader.loadFileNames()) {
: :
, , , . , : "" ( ), "" ( ), .
→
→