 Recentemente, conversamos sobre por que criamos nosso próprio segmentador de RFM, que ajuda a fazer a análise de RFM em 20 segundos , e mostramos como usar seus resultados no marketing.
Recentemente, conversamos sobre por que criamos nosso próprio segmentador de RFM, que ajuda a fazer a análise de RFM em 20 segundos , e mostramos como usar seus resultados no marketing.
Agora dizemos como está organizado.
Tarefa: escrever um novo algoritmo de análise RFM
Não estávamos satisfeitos com as abordagens disponíveis para análise de RFM. Portanto, decidimos fazer nosso próprio segmentador, que:
- Funciona completamente automaticamente.
- Constrói de 3 a 15 segmentos.
- Adapta-se a qualquer campo de atividade do cliente (não importa o que seja: uma loja de ferramentas elétricas ou de flores).
- Ele determina o número e a localização dos segmentos com base nos dados disponíveis, e não nos parâmetros predefinidos que não podem ser universais.
- Ele seleciona segmentos para que eles sempre tenham consumidores (ao contrário de algumas abordagens quando alguns segmentos estão vazios).
Como resolver o problema
Quando realizamos a tarefa, percebemos que estava além do poder do homem e pedimos ajuda da inteligência artificial. Para ensinar o carro a dividir os consumidores em segmentos, decidimos usar métodos de agrupamento .
Os métodos de cluster são usados para procurar uma estrutura nos dados e selecionar grupos de objetos semelhantes neles - exatamente o que você precisa para a análise RFM.
Agrupamento refere-se aos métodos de aprendizado de máquina da classe " aprendendo sem professor ". Uma classe é chamada assim porque há dados, mas ninguém sabe o que fazer com ela; portanto, ela não pode ensinar uma máquina.
Não conseguimos encontrar empresas que usassem essa abordagem no mercado. Embora tenham encontrado um artigo em que o autor conduz pesquisas científicas sobre esse tema. Mas, como entendemos por nossa própria experiência, da ciência aos negócios não é de todo um passo.
Etapa 1. Processamento de dados
Os dados precisam ser preparados para cluster.
Primeiro, verificamos se há valores incorretos: valores negativos etc.
Em seguida, removemos as emissões - consumidores com características incomuns. Existem poucos, mas eles podem afetar muito o resultado, e não para melhor. Para separá-los, usamos um método especial de aprendizado de máquina - fator externo externo .

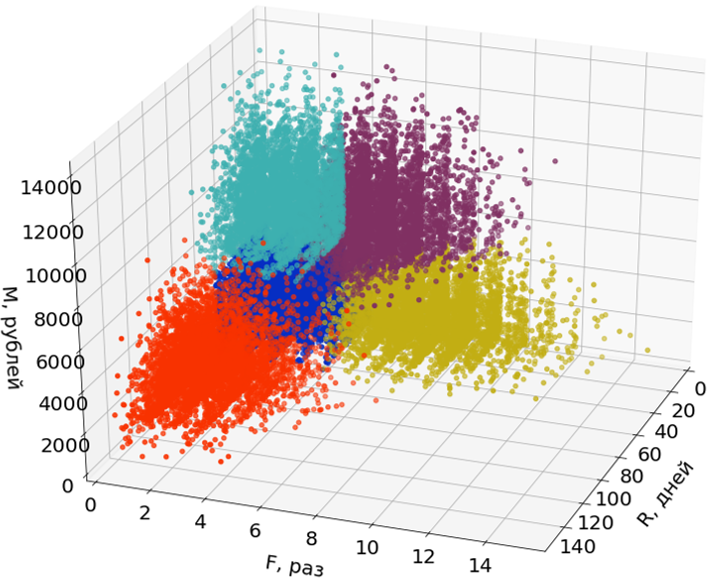
Aqui nas figuras, uso apenas duas das três dimensões (R e M) de três para facilitar a percepção.
As emissões não participam da construção dos segmentos, mas são alocadas a eles após a formação dos segmentos.
Etapa 2. Clustering do Consumidor
Esclarecemos a terminologia: por clusters, quero dizer grupos de objetos que são obtidos como resultado do uso de algoritmos de cluster e segmentos como resultado final, ou seja, o resultado da análise de RFM.
Existem várias dezenas de algoritmos de clustering. Exemplos de alguns deles podem ser encontrados na documentação do pacote scikit-learn .
Tentamos oito algoritmos com várias modificações. A maioria não tinha memória suficiente. Ou o tempo de seu trabalho tendia ao infinito. Quase todos os algoritmos que tecnicamente conseguiram lidar com a tarefa deram resultados terríveis: por exemplo, o popular DBSCAN considerou 55% dos objetos como ruído e dividiu o restante em 4302 clusters.
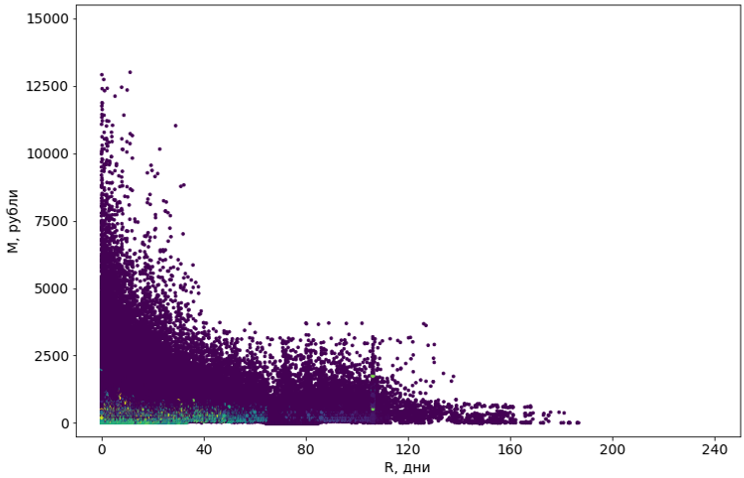
Objetos violetas são definidos como "ruído"
Como resultado, escolhemos o algoritmo K-Means (K-means) porque ele não procura grupos de pontos, mas simplesmente agrupa os pontos ao redor dos centros. Como se viu, esta foi a decisão certa.
Mas primeiro, resolvemos alguns problemas:
Instabilidade. Esse é um problema conhecido com a maioria dos algoritmos de cluster, incluindo o K-Means. A instabilidade reside no fato de que, com lançamentos repetidos, os resultados podem ser diferentes, uma vez que é utilizado um elemento aleatório.
Portanto, agrupamos várias vezes e, em seguida, agrupamos novamente, mas já os centros dos agrupamentos. Como centros finais dos clusters, tomamos os centros dos clusters resultantes (ou seja, clusters formados pelos centros dos primeiros clusters).
O número de clusters. Os dados podem ser diferentes e o número de clusters também deve ser diferente.
Para encontrar o número ideal de clusters para cada base de clientes, realizamos o cluster com um número diferente de clusters e, em seguida, selecionamos o melhor resultado .
Velocidade. O algoritmo K-means não é muito rápido, mas é aceitável (alguns minutos para uma base média de várias centenas de milhares de consumidores). No entanto, executamos várias vezes: primeiro, para aumentar a estabilidade e, segundo, para selecionar o número de clusters. E o tempo de operação está aumentando muito.
Para aceleração, usamos uma modificação do Mini Batch K-Means . Ele recalcula os centros de cluster em cada iteração, não para todos os objetos, mas apenas para uma pequena subamostra. A qualidade cai um pouco, mas o tempo é reduzido significativamente.
Assim que resolvemos esses problemas, o cluster começou a prosseguir com sucesso.
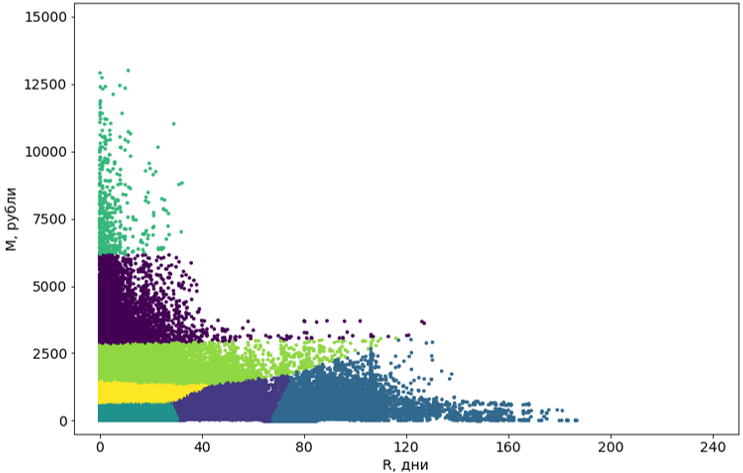
Etapa 3. Pós-processamento de clusters
Os clusters obtidos usando o algoritmo devem ser trazidos para um formato conveniente para a percepção.
Primeiro, transformamos esses clusters de curvas em retangulares. Na verdade, isso os torna segmentos. A retangularidade dos segmentos é uma exigência do nosso sistema e, além disso, agrega compreensão aos próprios segmentos. Para converter, usamos outro algoritmo de aprendizado de máquina - a árvore de decisão .
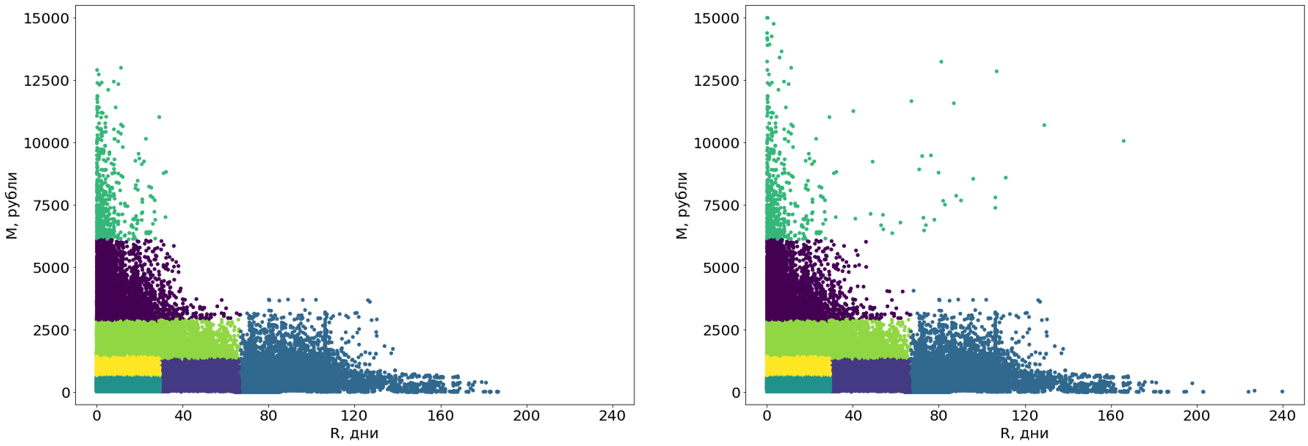
A árvore de decisão é construída com dados livres de discrepantes e os discrepantes são alocados aos segmentos concluídos
Em segundo lugar, fizemos outra coisa interessante - a descrição dos segmentos. Um algoritmo especial, usando um dicionário, descreve cada segmento em russo ao vivo, para que as pessoas não sintam desejo ao olhar para números sem alma.

Resultados dos testes
O produto está pronto. Mas antes de começar a vender, ele precisa ser testado. Ou seja, verifique se a análise de RFM é executada como pretendido.
Sabemos que a melhor maneira de entender se fizemos algo que vale a pena é descobrir o quão útil é a análise para nossos clientes. E nós faremos isso. Mas isso é muito tempo, e os resultados serão mais tarde, e queremos saber com que êxito concluímos a tarefa agora.
Portanto, como uma métrica mais simples e rápida, usamos o método "grupo de controle histórico".
Para fazer isso, pegamos vários bancos de dados e os segmentamos usando a análise RFM em diferentes pontos no passado: um banco de dados para o estado há seis meses, o outro há um ano, etc.
Com base em cada segmentação para cada base, construímos nossa previsão de ações do cliente desde o momento selecionado até o presente. Depois, eles compararam essas previsões com o comportamento real dos clientes.

Exemplo de teste em um grupo de controle histórico com um período de controle de seis meses
Na foto:
- As colunas R, F e M indicam convencionalmente os limites dos segmentos ao longo de cada eixo. Este é o resultado da segmentação de base na forma em que ocorreu há meio ano.
- A coluna "Tamanho" mostra o tamanho do segmento há seis meses em relação ao tamanho total do banco de dados.
- As colunas "Probabilidade de compra" e "Valor" são dados sobre o comportamento real do consumidor nos próximos seis meses.
- A probabilidade de compra é definida como a razão entre o número de consumidores do segmento que efetuou uma compra e o número total de consumidores no segmento.
- Valor - o valor total gasto pelos consumidores do segmento em relação ao valor gasto pelos consumidores de todos os segmentos.
Os resultados são consistentes. Por exemplo, clientes de segmentos para os quais previmos uma alta frequência de compras compraram com mais frequência.
Embora não possamos garantir a operação correta do algoritmo em 100%, com base nesses testes, decidimos que foi bem-sucedido.
O que entendemos
O aprendizado de máquina é realmente capaz de ajudar uma empresa a resolver problemas insolúveis ou muito mal resolvidos.
Mas o verdadeiro desafio não é a concorrência do Kaggle. Aqui, além de obter melhor qualidade em uma determinada métrica, você precisa pensar em quanto o algoritmo funcionará, se será conveniente para as pessoas e, em geral, se é necessário resolver o problema usando o ML ou se você pode criar uma maneira mais simples.
E, finalmente, a falta de uma métrica formal de qualidade complica a tarefa várias vezes, porque é difícil avaliar corretamente o resultado.