No mundo do aprendizado de máquina, um dos tipos mais populares de modelos é a árvore e os conjuntos decisivos baseados neles. As vantagens das árvores são: facilidade de interpretação, não há restrições quanto ao tipo de dependência inicial, requisitos mínimos para o tamanho da amostra. As árvores também têm uma falha importante - a tendência de reciclagem. Portanto, quase sempre as árvores são combinadas em conjuntos: floresta aleatória, aumento de gradiente, etc. Tarefas teóricas e práticas complexas são compor árvores e combiná-las em conjuntos.
No mesmo artigo, consideraremos o procedimento para gerar previsões a partir de um modelo de conjunto de árvores já treinado, recursos de implementação nas populares
XGBoost aumento de gradiente
XGBoost e
LightGBM . Além disso, o leitor se familiarizará com a biblioteca de
leaves do Go, que permite fazer previsões para conjuntos de árvores sem usar a API C das bibliotecas originais.
De onde crescem as árvores?
Considere primeiro as disposições gerais. Eles geralmente trabalham com árvores, onde:
- partição em um nó ocorre de acordo com um recurso
- árvore binária - cada nó tem um descendente esquerdo e direito
- no caso de um atributo material, a regra de decisão consiste em comparar o valor do atributo com um valor limite
Tirei esta ilustração da
documentação do XGBoost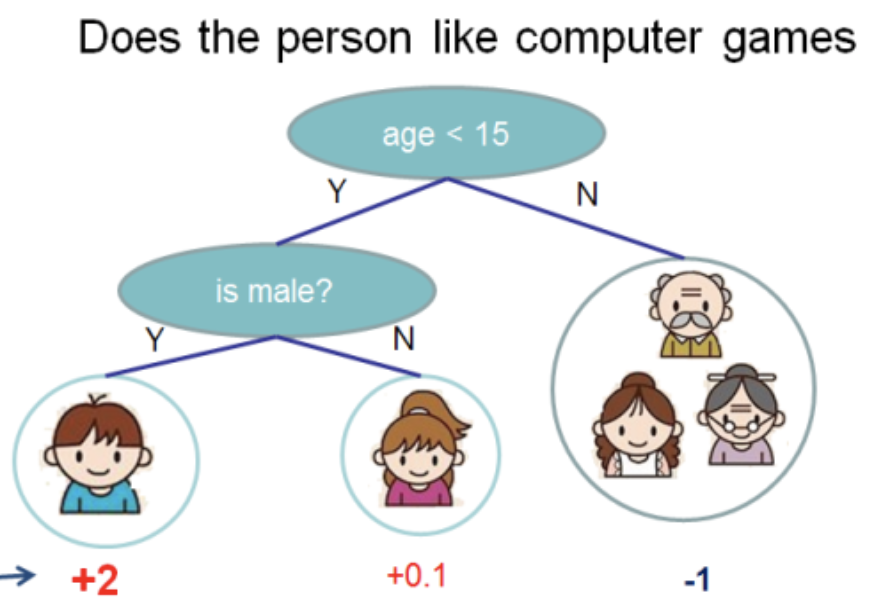
Nesta árvore, temos 2 nós, 2 regras de decisão e 3 folhas. Sob os círculos, os valores são indicados - o resultado da aplicação da árvore em algum objeto. Geralmente, uma função de transformação é aplicada ao resultado da computação de uma árvore ou conjunto de árvores. Por exemplo, um
sigmóide para um problema de classificação binária.
Para obter previsões do conjunto de árvores obtidas pelo aumento de gradiente, é necessário adicionar os resultados das previsões de todas as árvores:
double pred = 0.0; for (auto& tree: trees) pred += tree->Predict(feature_values);
A seguir, haverá
C++ , como é nessa linguagem que o
XGBoost e o
LightGBM são escritos. Omitirei detalhes irrelevantes e tentarei fornecer o código mais conciso.
Em seguida, considere o que está oculto no
Predict e como a estrutura de dados da árvore está estruturada.
Árvores do XGBoost
XGBoost possui várias classes (no sentido de POO) de árvores. Falaremos sobre o
RegTree (consulte
include/xgboost/tree_model.h ), que, de acordo com a documentação, é o principal. Se você deixar apenas os detalhes importantes para as previsões, os membros da classe parecerão o mais simples possível:
class RegTree {
A regra de
GetNext é implementada na função
GetNext . O código é ligeiramente modificado, sem afetar o resultado dos cálculos:
Duas coisas seguem daqui:
RegTree funciona apenas com atributos reais (tipo float )- valores de característica ignorados são suportados
A peça central é a classe
Node . Ele contém a estrutura local da árvore, a regra de decisão e o valor da planilha:
class Node { public:
Os seguintes recursos podem ser distinguidos:
- folhas são representadas como nós para os quais
cleft_ = -1 - o campo
info_ representado como union , ou seja, dois tipos de dados (nesse caso, o mesmo) compartilham uma parte da memória, dependendo do tipo de nó - o bit mais significativo em
sindex_ é responsável por onde o objeto cujo valor de atributo é ignorado
Para poder rastrear o caminho, chamando o método
RegTree::Predict para receber a resposta, darei as duas funções ausentes:
float RegTree::Predict(const RegTree::FVec& feat, unsigned root_id) const { int pid = this->GetLeafIndex(feat, root_id); return nodes_[pid].leaf_value; } int RegTree::GetLeafIndex(const RegTree::FVec& feat, unsigned root_id) const { auto pid = static_cast<int>(root_id); while (!nodes_[pid].IsLeaf()) { unsigned split_index = nodes_[pid].SplitIndex(); pid = this->GetNext(pid, feat.Fvalue(split_index), feat.IsMissing(split_index)); } return pid; }
Na função
GetLeafIndex descemos os nós da árvore em um loop até
GetLeafIndex a folha.
Árvores LightGBM
O LightGBM não possui uma estrutura de dados para o nó. Em vez disso, a estrutura de dados da árvore em
Tree (arquivo
include/LightGBM/tree.h ) contém matrizes de valores, em que o número do nó é usado como um índice. Valores em folhas também são armazenados em matrizes separadas.
class Tree {
LightGBM suporta recursos categóricos. O suporte é fornecido usando um campo de bit, armazenado em
cat_threshold_ para todos os nós. Em
cat_boundaries_ armazena em qual nó qual parte do campo de bit corresponde. O campo
threshold_ para o caso categórico é convertido em
int e corresponde ao índice em
cat_boundaries_ para procurar o início do campo de bit.
Considere a regra decisiva para um atributo categórico:
int CategoricalDecision(double fval, int node) const { uint8_t missing_type = GetMissingType(decision_type_[node]); int int_fval = static_cast<int>(fval); if (int_fval < 0) { return right_child_[node];; } else if (std::isnan(fval)) {
Pode-se observar que, dependendo do tipo de
missing_type valor
NaN abaixa automaticamente a solução ao longo do ramo direito da árvore. Caso contrário, o
NaN será substituído por 0. Procurar um valor em um campo de bits é bastante simples:
bool FindInBitset(const uint32_t* bits, int n, int pos) { int i1 = pos / 32; if (i1 >= n) { return false; } int i2 = pos % 32; return (bits[i1] >> i2) & 1; }
ou seja, por exemplo, para o atributo categórico
int_fval=42 verificado se o 41º bit (numeração de 0) está definido na matriz.
Essa abordagem tem uma desvantagem significativa: se um atributo categórico pode aceitar valores grandes, por exemplo 100500, para cada regra de decisão para esse atributo, um campo de bit será criado com tamanho de até 12564 bytes!
Portanto, é desejável renumerar os valores dos atributos categóricos para que eles passem continuamente de 0 ao valor máximo .
Pela minha parte, fiz alterações explicativas no
LightGBM e as
aceitei .
Lidar com atributos físicos não é muito diferente do
XGBoost , e vou pular isso por uma questão de brevidade.
leaves - biblioteca para previsões em Go
XGBoost e
LightGBM bibliotecas muito poderosas para a construção de modelos de
LightGBM gradiente em árvores de decisão. Para usá-los em um serviço de back-end, onde são necessários algoritmos de aprendizado de máquina, é necessário resolver as seguintes tarefas:
- Treinamento periódico de modelos offline
- Entrega de modelos no serviço de back-end
- Modelos de pesquisa online
Para escrever um serviço de back-end carregado, o
Go é um idioma popular.
XGBoost ou
LightGBM pela API C e cgo não é a solução mais fácil - a compilação do programa é complicada, devido ao manuseio descuidado, você pode pegar o
SIGTERM , problemas com o número de threads do sistema (OpenMP dentro de bibliotecas versus threads de tempo de execução).
Por isso, decidi escrever uma biblioteca em puro
Go para previsões usando modelos criados no
XGBoost ou no
LightGBM . É chamado de
leaves .

Principais recursos da biblioteca:
- Para modelos
LightGBM
- Lendo modelos de um formato padrão (texto)
- Suporte para atributos físicos e categóricos
- Suporte a valores ausentes
- Otimização do trabalho com variáveis categóricas
- Otimização de previsão com estruturas de dados somente de previsão
- Para modelos
XGBoost
- Lendo modelos de um formato padrão (binário)
- Suporte a valores ausentes
- Otimização de previsão
Aqui está um programa
Go mínimo que carrega um modelo do disco e exibe uma previsão:
package main import ( "bufio" "fmt" "os" "github.com/dmitryikh/leaves" ) func main() {
A API da biblioteca é mínima. Para usar o modelo
XGBoost basta chamar o método
leaves.XGEnsembleFromReader vez do método acima. As previsões podem ser feitas em lotes chamando os
model.PredictCSR ou
model.PredictCSR . Mais cenários de uso podem ser encontrados nos
testes de folhas .
Apesar do
Go mais lento que o
C++ (principalmente devido a verificações mais pesadas de tempo de execução e tempo de execução), graças a várias otimizações, foi possível obter uma taxa de previsão comparável à chamada da API C das bibliotecas originais.
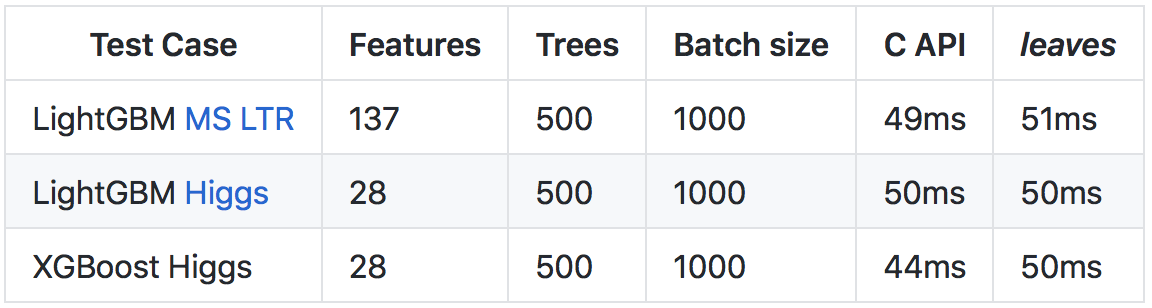
Mais detalhes sobre os resultados e o método de comparação estão no
repositório no github .
Veja a raiz
Espero que este artigo abra as portas para a implementação de árvores nas
LightGBM e
LightGBM . Como você pode ver, as construções básicas são bastante simples, e eu encorajo os leitores a aproveitar o código-fonte aberto - a estudar o código quando houver dúvidas sobre como ele funciona.
Para aqueles interessados no tópico de uso de modelos de aumento de gradiente em seus serviços no idioma Go, recomendo que você se familiarize com a biblioteca de
folhas . Usando
leaves você pode facilmente usar soluções de ponta no aprendizado de máquina em seu ambiente de produção, quase sem perder velocidade em comparação com as implementações C ++ originais.
Boa sorte