 Tradução do artigo: Experimenters Rules of Thumb
Tradução do artigo: Experimenters Rules of ThumbProprietários de portais da web, dos menores aos maiores, como Amazon, Facebook, Google, LinkedIn, Microsoft e Yahoo, estão tentando melhorar seus sites otimizando várias métricas, desde o número de tempos de reutilização até o tempo e a receita. Fomos atraídos por milhares de experiências na Amazon, Booking.com, LinkedIn e Microsoft, e queremos compartilhar as sete regras práticas que deduzimos dessas experiências e de seus resultados. Acreditamos que essas regras são amplamente aplicáveis tanto na otimização da Web quanto durante análises fora dos experimentos de controle. Embora haja exceções.
Para tornar essas regras mais significativas, daremos exemplos reais de nosso trabalho, a maioria dos quais será publicada pela primeira vez. Algumas regras foram expressas anteriormente (por exemplo, “A velocidade é importante”), mas as complementamos com suposições que podem ser usadas na criação de experimentos e compartilhamos exemplos adicionais que melhoraram nossa compreensão de onde a velocidade é especialmente importante e em quais áreas da Web páginas não é crítico.
Este artigo tem dois propósitos.
Primeiro : ensine aos experimentadores as regras de bom gosto, que ajudarão a otimizar os sites.
Segundo : fornecer à comunidade KDD novos tópicos para explorar a aplicabilidade dessas regras, seu aprimoramento e a existência de exceções.
1. Introdução
Proprietários de portais da web, dos menores aos maiores gigantes, estão tentando melhorar seus sites. As empresas líderes usam testes de benchmarking (como testes A / B) para avaliar mudanças. Isso é feito pela Amazon [1], Ebay, Etsy [2], Facebook [3], Google [4], Groupon, Intuit [5], LinkedIn [6], Microsoft [7], Netflix [8], ShopDirect [9] , Yahoo e Zynga [10].
Adquirimos experiência em otimização de sites, trabalhando com muitas empresas, incluindo Amazon, Booking.com, LinkedIn e Microsoft. Por exemplo, Bing e LinkedIn realizam centenas de experimentos paralelos a qualquer momento [6; 11] Devido à variedade e multiplicidade de experimentos em que participamos, desenvolveram-se regras práticas que discutiremos aqui. Eles são confirmados por projetos reais, mas há exceções a qualquer regra (também falaremos sobre eles). Por exemplo, a regra 72 é um bom exemplo de uma regra prática no campo financeiro. Alega que você precisa multiplicar a porcentagem de crescimento anual por 72 para determinar aproximadamente quantos anos você dobrará seu investimento. Em situações normais, a regra é muito útil (quando a taxa de juros varia entre 4 e 12%), mas em outras áreas ela não funciona.
Como essas regras foram formuladas de acordo com os resultados das experiências de controle, elas são bem aplicáveis à otimização do local e análise simples, mesmo que as experiências de controle não sejam realizadas nos locais (embora, neste caso, não seja possível avaliar com precisão o efeito das alterações feitas).
O que você encontrará neste artigo:
- Regras úteis para experimentar sites. Eles ainda estão em desenvolvimento e precisamos avaliar adicionalmente a amplitude de sua aplicação e descobrir se há novas exceções a essas regras. A importância do uso de experimentos de controle foi discutida no artigo "Experimentos controlados on-line em grande escala" [11]
- Melhoria às regras anteriores. Observações como “assuntos de velocidade” já foram ditas por outros autores [12; 13] e por nós [14]. Mas fizemos algumas suposições ao projetar o experimento, e falaremos sobre estudos que demonstram que em algumas áreas da página, a velocidade é especialmente crítica e em outras não. Também aprimoramos a regra antiga de “milhares de usuários”, que responde à pergunta de quantas pessoas são necessárias para realizar um experimento de controle.
- Exemplos reais de experimentos de controle são publicados pela primeira vez. Na Amazon, Bing e LinkedIn, experimentos de controle são usados como parte do processo de desenvolvimento [7; 11]. Muitas empresas que ainda não usam experimentos de controle podem se beneficiar muito de exemplos adicionais de como trabalhar com mudanças com a introdução de novos paradigmas de desenvolvimento [7, 15]. As empresas que já usam experimentos de controle se beneficiarão das informações descritas.
Controlar experimentos, dados e o processo de extração de conhecimento dos dados
Discutiremos aqui o controle de experimentos on-line nos quais os usuários são divididos em grupos aleatoriamente (por exemplo, para mostrar várias opções de sites). Além disso, a divisão é realizada continuamente, ou seja, cada usuário terá a mesma experiência ao longo do experimento (ele sempre mostrará a mesma versão do site). A interação do usuário com o site (cliques, visualizações de página etc.) é registrada e as principais métricas (CTR, número de sessões por usuário, receita do usuário) são calculadas com base. Testes estatísticos são realizados para analisar as métricas calculadas. E se a diferença entre as métricas do grupo de controle (que viu a versão antiga do site) e a experimental (que viu a nova versão) do grupo for estatisticamente significativa, também podemos dizer com alta probabilidade que as alterações feitas afetarão as métricas observadas no experimento. Os detalhes são descritos em “Experimentos controlados na Web: pesquisa e guia prático” [16].
Participamos de muitas experiências cujos resultados estavam incorretos e gastamos muito tempo e esforço para entender os motivos e encontrar maneiras de corrigi-lo. Muitas armadilhas são descritas nos artigos [17] e [18]. Queremos destacar algumas perguntas sobre os dados usados na realização de experimentos de controle on-line e sobre o processo de obtenção de conhecimento a partir desses dados:
- A fonte de dados são os sites reais sobre os quais falamos acima. Não haverá informações geradas artificialmente. Todos os exemplos são baseados na interação real do usuário e as métricas são calculadas após a remoção dos bots [16].
- Os grupos de usuários nos exemplos são retirados aleatoriamente da distribuição uniforme do público-alvo (ou seja, usuários que, por exemplo, devem clicar no link para ver as alterações que estão sendo estudadas) [16]. O método de identificação do usuário depende do site: se o usuário não estiver logado, serão utilizados cookies e, se ele estiver logado, seu login será utilizado.
- Os tamanhos dos grupos de usuários, após a limpeza dos bots, variam de centenas de milhares a milhões (os valores exatos são indicados nos exemplos). Na maioria das experiências, isso é necessário para que pequenas diferenças nas métricas tenham alta significância estatística.
- Os resultados observados foram estatisticamente significantes no valor de p <0,05, e geralmente ainda menos. Os resultados surpreendentes (na regra 1) foram reproduzidos pelo menos mais uma vez, de modo que o valor p cumulativo baseado no teste de probabilidade cumulativa de Fisher tivesse um valor muito menor que o necessário.
- Cada experimento é a nossa experiência pessoal, verificada por pelo menos um dos autores quanto à presença de armadilhas padrão. Cada experimento foi realizado por pelo menos uma semana. As partes da audiência que demonstraram as opções do site permaneceram estáveis durante todo o período do experimento (para evitar o efeito do paradoxo de Simpson) e as proporções entre a audiência que observamos durante o experimento coincidiram com as proporções que estabelecemos quando o experimento foi lançado [17].
Regras práticas para experimentação
As três primeiras regras estão relacionadas ao impacto das alterações nas principais métricas:
- pequenas mudanças podem ter um grande impacto;
- a mudança raramente tem um grande efeito positivo;
- é mais provável que suas tentativas de repetir os sucessos estelares anunciados por outros tenham menos sucesso.
As quatro regras a seguir são independentes uma da outra, mas cada uma delas é muito útil.
Regra nº 1: pequenas mudanças podem ter um GRANDE impacto nas principais métricas
Qualquer pessoa que se deparou com a vida dos sites sabe que qualquer pequena alteração pode ter um grande impacto negativo nas principais métricas. Um pequeno erro de JavaScript pode tornar o pagamento impossível, e pequenos erros que destroem a pilha podem causar uma falha no servidor. Mas vamos nos concentrar em mudanças positivas nas principais métricas. A boa notícia é que existem muitos exemplos em que uma pequena mudança levou a uma melhoria nas principais métricas. Bryan Eisenberg escreveu que a remoção do campo de entrada do cupom no formulário de compra aumentou a conversão em 1000% no site da Doctor Footcare [20]. Jared Spool escreveu que a remoção do requisito de registro no momento da compra dava a um grande varejista US $ 300 milhões por ano [21].
No entanto, não vimos mudanças tão significativas no processo de experimentos conduzidos pessoalmente. Mas vimos melhorias significativas de pequenas mudanças com um retorno surpreendentemente alto sobre o investimento (alta taxa de lucro em relação ao custo do esforço investido).
Também queremos observar que estamos discutindo um efeito estabilizado, não um “flash no sol” ou um recurso com um efeito especial de notícias / vírus. Um exemplo de algo que não estamos procurando foi descrito no livro Sim !: 50 maneiras cientificamente comprovadas de ser persuasivo [22]. Collen Szot, o autor de um programa de televisão que quebrou um recorde de vendas de 20 anos no canal de TV Couch Store, substituiu três palavras em uma barra de informações padrão, resultando em um grande aumento no número de compras. Em vez da frase "Os operadores estão esperando, ligue agora", Collen deduziu "se os operadores estiverem ocupados, ligue novamente". Os autores explicam isso com as seguintes evidências sociológicas: os espectadores acham que, se a fila estiver ocupada, pessoas como eles assistindo o canal de notícias também ligam.
Se truques como o mencionado acima são usados regularmente, o efeito é nivelado, porque os usuários se acostumam. Em experimentos de controle nesses casos, o efeito desaparece rapidamente. Portanto, recomendamos que você conduza um experimento por pelo menos duas semanas e monitore a dinâmica. Embora na prática, essas coisas sejam raras [11; 18] As situações em que observamos um efeito positivo dos efeitos de tais mudanças foram associadas aos sistemas de recomendação quando a própria mudança produz um efeito de curto prazo ou quando os recursos finais são usados para processamento.
Por exemplo, quando o LinkedIn alterou o algoritmo de recurso “pessoas que você talvez conheça”, ele gerou apenas um aumento único nas métricas de cliques. Além disso, mesmo que o algoritmo funcione muito melhor, cada usuário conhece um número finito de pessoas e, após entrar em contato com seus principais conhecidos, o efeito de qualquer novo algoritmo diminui.
Exemplo: Abrindo Links em uma Nova Aba. Uma série de três experimentos
Em agosto de 2008, o MSN UK conduziu um experimento para mais de 900.000 usuários, no qual o link para o HotMail foi aberto em uma nova guia (ou uma nova janela em navegadores antigos). Relatamos anteriormente [7] que essa alteração mínima (uma linha de código) levou a um aumento no envolvimento dos usuários do MSN. O engajamento, medido no número de cliques por usuário na página inicial, cresceu 8,9% entre os usuários que clicaram no HotMail.
Em junho de 2010, reproduzimos o experimento em um público de 2,7 milhões de usuários do MSN nos Estados Unidos, e os resultados foram semelhantes. De fato, este também é um exemplo de um recurso com o efeito de novidade. No primeiro dia de lançamento para todos os usuários, 20% das críticas foram negativas. Na segunda semana, a parcela de insatisfeitos caiu para 4%, e durante a terceira e quarta semana - para 2%. A melhoria nas principais métricas permaneceu estável durante esse período.
Em abril de 2011, o MSN nos Estados Unidos conduziu um experimento muito grande com mais de 12 milhões de usuários que abriram uma página com resultados de pesquisa em uma nova guia. O engajamento, medido em cliques no usuário, cresceu 5%. Esse foi um dos melhores recursos relacionados ao envolvimento do usuário que o MSN já implementou e foi uma mudança trivial no código.
Todos os principais mecanismos de pesquisa experimentam abrir links em novas guias / janelas, mas os resultados da "página de resultados da pesquisa" não são tão impressionantes.
Exemplo: Cor da fonte
Em 2013, o Bing conduziu uma série de experimentos com cores de fonte. A opção vencedora é mostrada na Figura 1 à direita. Veja como as três cores foram alteradas:
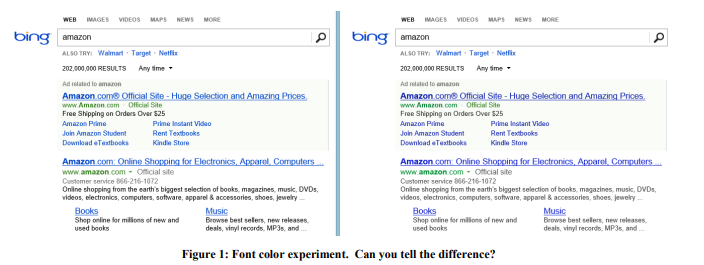
O custo dessa mudança? Barato: basta substituir várias cores no arquivo CSS. E o resultado do experimento mostrou que os usuários atingem seus objetivos (uma definição estrita de sucesso é um segredo comercial) mais rapidamente, e a monetização dessa revisão aumentou em mais de US $ 10 milhões por ano. Estávamos céticos em relação a esses resultados surpreendentes, então reproduzimos esse experimento em uma amostra muito maior de 32 milhões de usuários, e os resultados foram confirmados.

Exemplo: a oferta certa no momento certo
Em 2004, a página inicial da Amazon continha dois slots, cujo conteúdo foi testado automaticamente, para que o conteúdo que melhorasse melhor a métrica de destino fosse exibido com mais frequência. A oferta de obter um cartão de crédito da Amazon chegou ao topo, o que foi surpreendente desde esta oferta teve muito poucos cliques por impressão. Mas o fato é que esse aplicativo foi muito lucrativo; portanto, apesar da pequena CTR, o valor esperado era muito alto. Mas apenas se o local para esse anúncio foi escolhido com sucesso? Não! Como resultado, a proposta, juntamente com um exemplo simples do benefício, foi movida para o carrinho de compras que o usuário vê após adicionar o produto. Assim, a vantagem desta proposta foi enfatizada no exemplo de cada produto. Se o usuário adicionou mercadorias à cesta, esta é uma intenção clara de fazer uma compra e é hora de tal oferta.

Um experimento de controle mostrou que uma mudança tão simples gerava dezenas de milhões de dólares por ano.
Exemplo: Antivírus
A publicidade é um negócio lucrativo, e o software "gratuito" instalado pelos usuários geralmente contém uma parte maliciosa que obstrui as páginas dos anúncios. Por exemplo, a Figura 2 mostra a aparência da página de resultados do Bing para um usuário com um programa malicioso que adicionou muitos anúncios à página (destacados em vermelho).
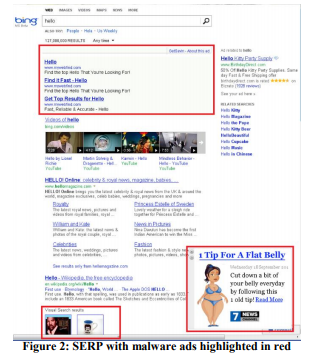
Os usuários geralmente nem percebem que tanta publicidade é mostrada não pelo site que eles estão visitando, mas pelo código malicioso que eles instalaram acidentalmente. O experimento foi difícil de implementar, mas ideologicamente relativamente simples: alterar os procedimentos básicos que modificam o DOM e limitar os aplicativos capazes de modificar a página. O experimento foi realizado com mais de 3,8 milhões de usuários cujos computadores possuíam códigos de terceiros que editavam o DOM. No grupo de teste, essas alterações foram bloqueadas. Os resultados mostraram uma melhoria em todas as principais métricas, incluindo uma orientadora, como o número de sessões por usuário, ou seja, as pessoas acessavam o site com mais frequência. Além disso, os usuários concluíram suas tarefas com mais êxito e rapidez, e a receita anual aumentou vários milhões de dólares. A velocidade de carregamento da página, que discutiremos na regra nº 4, diminuiu centenas de milissegundos nas páginas afetadas pelo experimento.
Duas outras pequenas mudanças no Bing, que são estritamente confidenciais, levaram dias para serem desenvolvidas, e cada uma levou a um aumento na receita de publicidade em quase US $ 100 milhões por ano. Em um relatório trimestral da Microsoft em outubro de 2013, ele dizia: "A receita de publicidade da pesquisa cresceu 47% devido ao aumento dos lucros de cada pesquisa e cada página". Essas duas mudanças contribuíram significativamente para o crescimento do lucro mencionado.
Após esses exemplos, você pode pensar que as organizações devem se concentrar em muitas pequenas mudanças. Mas abaixo você verá que esse não é o caso. Sim, as interrupções ocorrem com base em pequenas alterações, mas são muito raras e inesperadas: no Bing, provavelmente uma em cada 500 experiências alcança um ROI tão alto e um resultado positivo reproduzível. Não reivindicamos que esses resultados sejam reproduzíveis em outros domínios, apenas queremos transmitir a ideia: realizar experimentos simples vale o esforço e pode levar a um avanço.
O perigo resultante do foco em pequenas mudanças é o incrementalismo: uma organização que se preze deve ter um conjunto de mudanças com um ROI potencialmente alto, mas, ao mesmo tempo, deve haver várias mudanças importantes para atingir o grande jackpot [23].
Regra número 2: as mudanças raramente têm um grande impacto positivo nas principais métricas
Como Al Pacino disse no filme Todo domingo, a vitória é dada centímetro por centímetro. Centenas e milhares de experimentos são executados anualmente em sites como o Bing. A maioria falha e as que obtêm êxito afetam a métrica principal em 0,1% a 1,0%, adicionando uma queda ao impacto geral. As pequenas mudanças com grande efeito descritas na regra anterior acontecem, mas são raras.
É importante observar duas coisas:
- As principais métricas não são algo específico pertencente a um recurso individual que pode ser facilmente aprimorado, mas uma métrica significativa para toda a organização: por exemplo, o número de sessões por usuário [18] ou o tempo para atingir a meta do usuário [24].
Ao desenvolver um recurso, é muito fácil melhorar significativamente o número de cliques nesse recurso (ou outra métrica do recurso) simplesmente destacando-o ou aumentando-o. Mas aumentar a CTR da página inteira ou toda a experiência do usuário é onde está o desafio. A maioria dos recursos gera cliques na página, redistribuindo-os entre diferentes áreas. - As métricas devem ser divididas em pequenos segmentos, para facilitar a otimização. Por exemplo, uma equipe pode melhorar facilmente as métricas para consultas meteorológicas no Bing ou comprar programas de TV na Amazon? adicionando uma boa ferramenta de comparação. No entanto, uma melhoria de 10% nas principais métricas se dissolverá nas métricas de todo o produto devido ao tamanho do segmento. Por exemplo, uma melhoria de 10% em um segmento de 1% afetará o projeto inteiro em cerca de 0,1% (aproximadamente, porque, se as métricas do segmento forem diferentes da média, o efeito também poderá ser diferente).
A importância desta regra é grande porque erros falsos positivos ocorrem durante as experiências. Eles têm dois tipos de razões:
- Os primeiros são causados por estatísticas. Se realizarmos mil experimentos por ano, a probabilidade de um erro falso positivo de 0,05 leva ao fato de que, para uma métrica fixa, obteremos um resultado falso positivo centenas de vezes. E se usarmos várias métricas que não estão correlacionadas, esse resultado será fortalecido. Mesmo sites grandes como o Bing não têm tráfego suficiente para aumentar a sensibilidade e tirar conclusões com um valor-p mais baixo para métricas como o número de sessões por usuário.
- , , .
[11]. [25;26]. , , p-value 0,05 - .
:
se tivermos uma probabilidade preliminar de sucesso igual a ⅓ (como dissemos em [7], esse é o valor médio entre os experimentos da Microsoft), então a probabilidade posterior de um experimento estatisticamente significativo verdadeiramente positivo é de 89%. E se o experimento for um daqueles sobre os quais falamos na primeira regra, quando apenas 1 em 500 contém uma solução inovadora, a probabilidade cai para 3,1%.
Uma conseqüência engraçada dessa regra é o fato de que segurar alguém é muito mais fácil do que se desenvolver sozinho. As decisões tomadas em uma empresa que se concentra na significância estatística têm maior probabilidade de ter um efeito positivo. Por exemplo, se tivermos uma taxa de sucesso de 10 a 20%, se fizermos testes dos recursos que foram bem-sucedidos e lançados para batalhas em outros mecanismos de pesquisa, nosso nível de sucesso será maior. O inverso também é verdadeiro: outros mecanismos de pesquisa também devem testar e colocar em ação as coisas que o Bing implementou.
Com a experiência, aprendemos a não confiar em resultados que parecem bons demais para ser verdade. As pessoas reagem de maneira diferente a diferentes situações. Eles suspeitam que algo está errado e estudam os resultados negativos das experiências com seus excelentes recursos novos, fazem perguntas e mergulham mais fundo na busca pelas razões para esse resultado. Mas se o resultado é simplesmente positivo, a suspeita recua e as pessoas começam a comemorar, e não estudam mais profundamente e não procuram anomalias.
Quando os resultados são excepcionalmente impressionantes, estamos acostumados a seguir a lei de Twyman [27]: Tudo o que parece interessante ou diferente é geralmente falso.
A lei de Twyman pode ser explicada com inferência bayesiana. Em nossa experiência, sabíamos que um avanço é uma ocorrência rara. Por exemplo, várias experiências melhoraram significativamente nossa métrica orientadora, o número de sessões por usuário. Imagine que a distribuição que encontramos nas experiências é normal, centralizada no ponto 0 e com um desvio padrão de 0,25%. Se o experimento mostrou + 2% ao valor da métrica principal, chamamos a lei de Twyman e dizemos que este é um resultado muito interessante, que está a uma distância de 8 desvios padrão da média e tem uma probabilidade de 10 a
15 , excluindo outros fatores. Mesmo com significância estatística, a expectativa preliminar é tão forte que adiaremos a celebração do sucesso e aprofundaremos a busca pela causa do erro falso positivo do segundo tipo. A lei de Twyman é frequentemente aplicada para provar que
=NP . Hoje, nenhum editor de site ficará feliz se receber essas evidências. Provavelmente, ele responderá imediatamente com uma resposta de modelo: "na sua prova de que P = NP, um erro foi cometido na página X".
Exemplo: Métrica Substituta do Office Online
Cook e sua equipe [17] conversaram sobre um experimento interessante que eles conduziram com o Microsoft Office Online. A equipe testou um novo design de página no qual um botão se destacava fortemente, pedindo para pagar pelo produto. A principal métrica que a equipe queria avaliar: o número de compras por usuário. Mas o rastreamento de compras reais exigia a modificação do sistema de cobrança e, na época, era difícil. Em seguida, a equipe decidiu usar a métrica "cliques que levam a uma compra" e aplicar a fórmula
( ) * = , onde a conversão de cliques para compra é realizada.
Para sua surpresa, no experimento, o número de cliques diminuiu 64%. Esses resultados chocantes forçaram uma análise mais profunda dos dados e resultou que a suposição de uma conversão estável de clique para compra é falsa. A página experimental, que mostrou o custo do produto, atraiu menos cliques, mas os usuários que clicaram nela foram mais qualificados e tiveram uma conversão muito maior do clique para a compra.
Exemplo: mais cliques em uma página lenta
O JavaScript foi adicionado à página de resultados da pesquisa do Bing. Esse script geralmente diminuiu a velocidade da página; portanto, todos esperavam ter um leve impacto negativo nas principais métricas de engajamento, como o número de cliques em um usuário. Mas os resultados mostraram o contrário, houve mais cliques! [18] Apesar da dinâmica positiva, seguimos a lei de Twyman e resolvemos o enigma. Os rastreadores de cliques são baseados em web beacons e alguns navegadores não fazem uma ligação se o usuário sair da página. [28] Assim, o JavaScript afetou a precisão das contagens de cliques.
Exemplo: Bing Edge
Por vários meses em 2013, o Bing mudou sua rede de entrega de conteúdo da Akamai para o seu próprio Bing Edge. A mudança de tráfego para o Bing Edge foi combinada com muitas outras melhorias. Várias equipes relataram que aprimoraram as principais métricas: a CTR da página inicial do Bing aumentou, os recursos começaram a ser usados com mais frequência e a saída começou a diminuir. E, portanto, todas essas melhorias estavam relacionadas a contagens limpas de cliques: o Bing Edge melhorou não apenas a velocidade da página, mas também a capacidade de entrega de cliques. Para avaliar o efeito, lançamos um experimento no qual a abordagem farol para rastrear cliques foi substituída por uma abordagem com recarregamento de página. Essa técnica é usada na publicidade e leva a uma leve perda de cliques, diminuindo o efeito de cada clique. Os resultados mostraram que a porcentagem de cliques perdidos caiu mais de 60%! E a maioria das conquistas anunciadas durante esse período foram o resultado da entrega aprimorada de cliques.
Exemplo: Pesquisa do MSN Bing
O preenchimento automático é uma lista suspensa que oferece opções para concluir uma solicitação enquanto a pessoa digita. O MSN planejava melhorar esse recurso usando um algoritmo novo e aprimorado (as equipes de desenvolvimento de recursos estão sempre prontas para explicar por que seu novo algoritmo é a priori melhor do que o antigo, mas geralmente ficam chateadas quando veem os resultados dos experimentos). O experimento foi um grande sucesso; o número de pesquisas que chegaram ao Bing com o MSN aumentou significativamente. Seguindo nossas regras, começamos a entender e descobrimos que, quando o usuário clicava na dica de ferramenta, o novo código fazia duas consultas de pesquisa (uma das quais foi imediatamente fechada pelo navegador assim que os resultados da pesquisa apareceram).
Portanto, a explicação para muitos resultados positivos pode não ser tão emocionante. E nossa tarefa é encontrar um impacto real no usuário, e a regra de Twyman realmente ajudou nisso e na compreensão de muitos dos resultados experimentais.
Regra número 3. Seu benefício variará.
Existem muitos exemplos documentados de experimentos de controle bem-sucedidos. Por exemplo, “
Qual teste venceu? ” Contém centenas de exemplos de testes A / B e a lista é atualizada a cada semana.
Embora este seja um ótimo gerador de idéias, esses exemplos têm vários problemas:
- Qualidade varia. Nesses estudos, alguém de uma empresa fala sobre o resultado de um teste A / B. Houve uma avaliação de especialistas? Foi realizado corretamente? Houve emissões? O valor de p foi pequeno o suficiente (vimos testes A / B publicados com valor de p maior que 0,05, o que geralmente é considerado estatisticamente insignificante)? Houve armadilhas sobre as quais falamos anteriormente e quais os autores do teste não verificaram corretamente?
- O que funciona em um domínio pode não funcionar em outro. Por exemplo, Neil Patel [29] recomenda o uso da palavra "grátis" em anúncios que oferecem uma versão de avaliação de 30 dias em vez de uma "garantia de devolução do dinheiro em 30 dias". Isso pode funcionar com um produto e um público, mas suspeitamos que o resultado dependerá muito do produto e do público. Joshua Porter [30] afirma que “Vermelho é melhor que verde” para os botões que ligam para “Começar agora”. Mas como não vimos muitos sites com um botão vermelho de apelo à ação, aparentemente esse resultado não é tão bem reproduzido.
- O efeito da novidade e primeira vez. Alcançamos estabilidade em nossos experimentos, e muitos experimentos em muitos exemplos não foram realizados por tempo suficiente para verificar esses efeitos.
- Interpretação incorreta dos resultados. Alguma razão oculta ou fator específico pode não ser reconhecido ou mal interpretado. Nós damos dois exemplos. Um deles é o primeiro experimento de controle documentado.
Exemplo 1 O escorbuto é uma doença causada por uma deficiência de vitamina C. Matou mais de 100.000 pessoas nos séculos 16 a 18, a maioria delas marinheiros que fizeram longas viagens e permaneceram no mar por mais tempo do que frutas e legumes poderiam sobreviver. Em 1747, o Dr. James Lind observou que o escorbuto é menos afetado em navios no Mediterrâneo. Ele começou a dar limões e laranjas a alguns marinheiros, deixando outros na dieta usual. O experimento teve muito sucesso, mas o médico não entendeu o motivo. No Royal Maritime Hospital, no Reino Unido, ele tratou pacientes com escorbuto com suco de limão concentrado, que ele chamou de rob. O médico concentrou-o pelo aquecimento, que destruiu a vitamina C. Lind perdeu a fé e frequentemente recorria a derramamento de sangue. Em 1793, testes reais foram conduzidos. e suco de limão tornou-se parte da dieta diária dos marinheiros. O escorbuto desapareceu rapidamente e os marinheiros britânicos ainda são chamados de capim-limão.
Exemplo 2 Marissa Mayer falou sobre um experimento em que o Google aumentou o número de resultados em uma página de pesquisa de 10 para 30. O tráfego e o lucro dos usuários que pesquisaram no Google caíram 20%. E como ela explicou isso? Assim, a página precisou de meio segundo a mais para ser gerada. Obviamente, a produtividade é um fator importante, mas suspeitamos que isso afetou apenas uma pequena fração das perdas. Aqui está a nossa visão das causas:
- Bing conduziu experimentos isolados de desaceleração [11], durante os quais apenas o desempenho mudou. Um atraso na resposta do servidor de 250 milissegundos afetou a receita em aproximadamente 1,5% e a CTR em 0,25%. Essa é uma grande influência e pode-se supor que 500 milissegundos afetarão a receita e a CTR em 3% e 0,5%, respectivamente, mas não em 20% (suponha que uma aproximação linear seja aplicável aqui). Testes antigos no Bing [32] mostraram um efeito semelhante nos cliques e menos impacto na receita com um atraso de 2 segundos.
- Jake Brutlag, do Google, escreveu em um post de blog sobre um experimento [12], mostrando que diminuir a velocidade dos resultados de pesquisa de 100 milissegundos para 400 tem um efeito significativo no número específico de pesquisas e varia entre 0,2% e 0,6%, o que funciona muito bem com nossos experimentos, mas muito longe dos resultados de Marissa Mayer.
- O BIng conduziu um experimento com a exibição de 20 resultados de pesquisa em vez de 10. A perda de lucro eliminou completamente a adição de publicidade adicional (o que tornou a página ainda mais lenta). Acreditamos que a proporção de publicidade e algoritmos de pesquisa é muito mais importante que o desempenho.
Somos céticos em relação aos muitos resultados notáveis dos testes A / B publicados em várias fontes. Ao verificar os resultados dos experimentos, pergunte-se que nível de confiança você tem neles? E lembre-se, mesmo que a ideia funcione em um site, não é necessário que funcione em outro. A melhor coisa que podemos fazer é falar sobre a reprodução de experimentos e seu sucesso ou fracasso. Será mais benéfico para a ciência.
Regra número 4: Velocidade significa muito
Os desenvolvedores da Web que testam seus recursos usando experimentos de controle rapidamente perceberam que o desempenho ou a velocidade do site são parâmetros críticos [13; 14; 33]. Mesmo um pequeno atraso na operação do site pode afetar as principais métricas do grupo de teste.
A melhor maneira de avaliar os efeitos do desempenho é realizar um experimento de desaceleração isolado, ou seja, apenas com adição de atraso. A Figura 3 mostra um gráfico padrão da relação entre desempenho e a métrica sendo testada (CTR, taxa de sucesso unitário e receita). Normalmente, quanto mais rápido o site, melhor (mais alto neste gráfico). Retardando o trabalho do grupo de teste em relação ao grupo de controle, você pode medir o impacto do desempenho na métrica em que está interessado. É importante observar:
- O efeito da desaceleração no grupo de teste é medido aqui e agora (linha tracejada no gráfico) e depende do site e do público. Se o site ou o público mudar, a degradação do desempenho poderá afetar as principais métricas de maneira diferente.
- O experimento mostra o efeito da desaceleração nas principais métricas. Isso pode ser muito útil quando você está tentando medir o efeito de um novo recurso cuja primeira implementação não é eficaz. Suponha que ele melhore a métrica de M em X% e, ao mesmo tempo, diminua o site em T%. Usando o experimento com desaceleração, podemos avaliar o efeito da desaceleração na métrica M, corrigir o efeito do recurso e obter o efeito previsto X '% (é lógico supor que esses efeitos tenham a propriedade de aditividade). E, assim, podemos responder à pergunta: “Como isso afetará a métrica principal se for implementada de maneira eficaz?”.
- Podemos assumir como o fato de o site começar a funcionar mais rapidamente e ajudar a calcular o ROI dos esforços de otimização afetará a métrica principal. Usando uma aproximação linear (o primeiro termo da série de Taylor), podemos assumir que o efeito na métrica é o mesmo em ambas as direções. Assumimos que o delta vertical seja o mesmo nas duas direções e apenas com um sinal diferente. Portanto, experimentando a desaceleração em vários valores, podemos aproximadamente imaginar como a aceleração afetará esses mesmos valores. Realizamos esses testes no Bing e nossa teoria foi totalmente confirmada.
Quão importante é o desempenho? Criticamente importante. Na Amazon, uma desaceleração de 100 milissegundos leva a uma queda de 1% nas vendas, como Greg Linded disse [34 p.10]. E os palestrantes do Bing e do Google [32] mostram um impacto significativo do desempenho nas principais métricas.
Exemplo: experiência de desaceleração do servidor
Realizamos um experimento de duas semanas no Bing para desacelerar o serviço em 100 milissegundos para 10% dos usuários, e em 250 milissegundos para outros 10% dos usuários. Aconteceu que a cada 100 milissegundos de aceleração de serviço aumentava a receita em 0,6%. A partir daqui, até apareceu uma frase que reflete bem a essência da nossa organização:
um engenheiro que melhorará o desempenho do servidor em 10 milissegundos (1/30 da velocidade dos nossos olhos) ganhará à empresa mais de um ano. Cada milissegundo é importante.
No experimento descrito, diminuímos o tempo de resposta do servidor e, em seguida, diminuímos o tempo de operação de todos os elementos da página. Mas a página tem partes mais importantes e há partes menos importantes. Por exemplo, os usuários podem não saber que itens fora do escopo da tela ainda não foram carregados. Mas existem elementos exibidos imediatamente que podem ser mais lentos sem prejudicar o usuário? Como você verá abaixo, existem esses elementos.
Exemplo: o desempenho do painel direito não é tão crítico
No Bing, alguns elementos chamados snapshots estão localizados no painel direito e são carregados com atraso (após o evento window.onload). Recentemente, realizamos um experimento: elementos do painel direito abrandaram em 250 milissegundos. Se isso afetou as principais métricas, é tão insignificante que não notamos nada. E o experimento envolveu quase 20 milhões de usuários.
O tempo de carregamento da página (PLT) geralmente é calculado usando o evento window.onload, como um sinal da conclusão de atividades úteis do navegador. Hoje, porém, essa métrica tem uma falha séria ao trabalhar com navegadores modernos. Como Steve Souders [32] mostrou, o topo da página da Amazon é renderizado em 2 segundos, enquanto o windows.onload é acionado em 5,2 segundos. Schurman [32] afirmou que eles eram capazes de renderizar a página dinamicamente, por isso era importante que mostrassem o cabeçalho muito rapidamente. O oposto também é verdadeiro: no Gmail, o windows.onload é acionado após 3,3 segundos, enquanto naquele momento apenas a barra de download apareceu na tela e todo o conteúdo é mostrado em 4,8 segundos.
Existem métricas relacionadas ao tempo, por exemplo: tempo para o primeiro resultado (por exemplo, tempo para o primeiro tweet no Twitter, primeiro resultado da pesquisa na página de resultados). Mas o termo "desempenho percebido" é sempre usado para descrever essa velocidade da página, de modo que o usuário a perceba suficientemente cheia. O conceito de "desempenho percebido" é mais fácil de descrever intuitivamente do que estritamente formulado; portanto, nenhum dos navegadores tem planos de implementar o evento
perception.ready() . Para resolver esse problema, muitas premissas e premissas são usadas, por exemplo:
- Hora no topo da página (AFT) [37]. Medido como o momento em que todos os pixels superiores da página são exibidos. A implementação é baseada em heurísticas que são especialmente complexas ao lidar com vídeos, gifs, galerias de rolagem e outro conteúdo dinâmico que altera a parte superior da página. Os limites podem ser definidos como "porcentagem de pixels desenhados" para evitar a influência de elementos pequenos e insignificantes que podem aumentar a métrica medida.
- O Índice de velocidade [38] é uma generalização do AFT que calcula a média do tempo durante o qual os elementos visíveis da página aparecem na tela. A velocidade não sofre com pequenos elementos que parecem atrasados, mas ainda é afetada pelo conteúdo dinâmico que altera a parte superior da página.
- Tempo da fase da página e tempo de disponibilidade do usuário [39]. Tempo da fase da página - o tempo necessário para cada fase individual de renderização da página. , . — , .
W3C- , HTML, , , . , , , .
Bing , « » (TTS) [24] . — . , 30 . — «Perceived performance». , ; , , . , , , . , . , , , , — .
№5: — , —
, Bing — , , . , — , , . , , . , , .
:
Bing . , «data mining», Bing «Examples of data mining», «Advantages of Data Mining», «definition of data mining», «Data mining companies»,«data mining software» .. . 10 . , (p-value 0,64).
:
Bing , , , , . . 17 %, (p-value 0,71).
:
Bing , 10 . , :
- , , «ebay», CTR 75 %. 10 . : 8 , , 4 . (p-value 0,92), production.
- , «» , Bing (14 ). , 3 «» , : 1,8 % , 30 , 18 % ( ), (p-value 0,93). .
:
. 10 , 12 % ( $150 , ). , (p-value 0,83)
, , . , , .
, ( Microsoft, Amazon .), CTR. , , . , . , . «» . : — , — .
№6: ,
. .. [40]: « , , . , — ». , online-, , [17;41], , , . , . LinkedIn.
: LinkedIn
LinkedIn . 2013 , , , , — LinkedIn, . , : , . , , , . . : . , , , . , , - , , - . .
: LinkedIn
LinkedIn . , . , . , . , , . , . , , , . , , , . , , . , . , .
offline- , , online, , , [4;11]. (Mullty-Variable) , MV-. ( /B/C/D) .
— Agile, MVP [15]: MVT, , . , . , , .. MV- - .
: 1 % , . Agile- Knight Capital, 2012 440 Knights 75 %.
№7:
. , , . , , . , . , [42] , , n > 30, . , . — , Neil Patel , .
, ( ) [16], , . , , .
,
355 * s^2 , , .
s — , :
$$s = \frac{E (XE (X))^3}{\Var (X)^{3/2}}$$, 1. , , Bing:
|
|
|
|
Revenue/User
| 17,9
| 114 .
| 4,4 %
|
Revenue/User (capped)
| 5,2
| 9,7 .
| 10,5 %
|
Sessions/User
| 3,6
| 4,7 .
| 5,4 %
|
Time To Success
| 2,1
| 1,55 .
| 12,3 %
|
, « » 10, « » — 30. 95 % , , 0,025, 0,3 0,2. Boos Hughes-Oliver [43]. , . , 18,2, 114 . . 4 , 100 1000 , QQ. 95- , , 5 %. 100 000 , -2 2.

, - , . , « » , , 18 5, . , 30 % , .
, , . , , , , 0. , 1.
, [16]. bootstrap [44].
Conclusão
7 , , . , , , , . , Twyman' , , . , , , , . — — . , , , , — . , , (, ). , , . — , , , . , : , . , , . , . Agile. — , . , , . , — . , , , .
, , . Mujtaba Khambatti, John Psaroudakis, Sreenivas Addagatke, . Juan Lavista Ferres, Urszula Chajewska, Greben Langendijk, Lukas Vermeer, Jonas Alves. Eytan Bakshy, Brooks Bell Colin McFarland.
- Kohavi, Ron and Round, Matt. Front Line Internet Analytics at Amazon.com. [ed.] Jim Sterne. Santa Barbara, CA: sn, 2004. ai.stanford.edu/~ronnyk/emetricsAmazon.pdf .
- McKinley, Dan. Design for Continuous Experimentation: Talk and Slides. [Online] Dec 22, 2012. mcfunley.com/designfor-continuous-experimentation .
- Bakshy, Eytan and Eckles, Dean. Uncertainty in Online Experiments with Dependent Data: An Evaluation of Bootstrap Methods. KDD 2013: Proceedings of the 19th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2013.
- Tang, Diane, et al. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. Proceedings 16th Conference on Knowledge Discovery and Data Mining. 2010.
- Moran, Mike. Multivariate Testing in Action: Quicken Loan's Regis Hadiaris on multivariate testing. Biznology Blog by Mike Moran. [Online] December 2008. www.biznology.com/2008/12/multivariate_testing_in_action .
- Posse, Christian. Key Lessons Learned Building LinkedIn Online Experimentation Platform. Slideshare. [Online] March 20, 2013. www.slideshare.net/HiveData/googlecontrolledexperimentationpanelthe-hive .
- Kohavi, Ron, Crook, Thomas and Longbotham, Roger. Online Experimentation at Microsoft. Third Workshop on Data Mining Case Studies and Practice Prize. 2009. http://expplatform.com/expMicrosoft.aspx .
- Amatriain, Xavier and Basilico, Justin. Netflix Recommendations: Beyond the 5 stars. [Online] April 2012. techblog.netflix.com/2012/04/netflix-recommendationsbeyond-5-stars.html .
- McFarland, Colin. Experiment!: Website conversion rate optimization with A/B and multivariate testing. sl: New Riders, 2012. 978-0321834607.
- Smietana, Brandon. Zynga: What is Zynga's core competency? Quora. [Online] Sept 2010. www.quora.com/Zynga/What-is-Zyngas-corecompetency/answer/Brandon-Smietana .
- Kohavi, Ron, et al. Online Controlled Experiments at Large Scale. KDD 2013: Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 2013. bit.ly/ExPScale .
- Brutlag, Jake. Speed Matters. Google Research blog. [Online] June 23, 2009. googleresearch.blogspot.com/2009/06/speed-matters.html .
- Sullivan, Nicole. Design Fast Websites. Slideshare. [Online] Oct 14, 2008. www.slideshare.net/stubbornella/designingfast-websites-presentation .
- Kohavi, Ron, Henne, Randal M and Sommerfield, Dan. Practical Guide to Controlled Experiments on the Web: Listen to Your Customers not to the HiPPO. The Thirteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2007). August 2007, pp. 959-967. www.expplatform.com/Documents/GuideControlledExperiments.pdf .
- Ries, Eric. The Lean Startup: How Today's Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses. sl: Crown Business, 2011. 978-0307887894.
- Kohavi, Ron, et al. Controlled experiments on the web: survey and practical guide. Data Mining and Knowledge Discovery. February 2009, Vol. 18, 1, pp. 140-181. www.exp-platform.com/Pages/hippo_long.aspx .
- Crook, Thomas, et al. Seven Pitfalls to Avoid when Running Controlled Experiments on the Web. [ed.] Peter Flach and Mohammed Zaki. KDD '09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 2009, pp. 1105-1114. www.expplatform.com/Pages/ExPpitfalls.aspx .
- Kohavi, Ron, et al. Trustworthy online controlled experiments: Five puzzling outcomes explained. Proceedings of the 18th Conference on Knowledge Discovery and Data Mining. 2012, www.expplatform.com/Pages/PuzzingOutcomesExplained.aspx .
- Wikipedia contributors. Fisher's method. Wikipedia. [Online] Jan 2014. http://en.wikipedia.org/wiki/Fisher %27s_method .
- Eisenberg, Bryan. How to Increase Conversion Rate 1,000 Percent. ClickZ. [Online] Feb 28, 2003. www.clickz.com/showPage.html?page=1756031 .
- Spool, Jared. The $300 Million Button. USer Interface Engineering. [Online] 2009. www.uie.com/articles/three_hund_million_button .
- Goldstein, Noah J, Martin, Steve J and Cialdini, Robert B. Yes!: 50 Scientifically Proven Ways to Be Persuasive. sl: Free Press, 2008. 1416570969.
- Collins, Jim and Porras, Jerry I. Built to Last: Successful Habits of Visionary Companies. sl: HarperBusiness, 2004. 978- 0060566104.
- Badam, Kiran. Looking Beyond Page Load Times – How a relentless focus on Task Completion Times can benefit your users. Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/32 820.
- Why Most Published Research Findings Are False. Ioannidis, John P. 8, 2005, PLoS Medicine, Vol. 2, p. e124. www.plosmedicine.org/article/info :doi/10.1371/journal.pme d.0020124.
- Wacholder, Sholom, et al. Assessing the Probability That a Positive Report is False: An Approach for Molecular Epidemiology Studies. Journal of the National Cancer Institute. 2004, Vol. 96, 6. jnci.oxfordjournals.org/content/96/6/434.long .
- Ehrenberg, ASC The Teaching of Statistics: Corrections and Comments. Journal of the Royal Statistical Society. Series A, 1974, Vol. 138, 4.
- Ron Kohavi, David Messner,Seth Eliot, Juan Lavista Ferres, Randy Henne, Vignesh Kannappan,Justin Wang. Tracking Users' Clicks and Submits: Tradeoffs between User Experience and Data Loss. Redmond: sn, 2010.
- Patel, Neil. 11 Obvious A/B Tests You Should Try. QuickSprout. [Online] Jan 14, 2013. http://www.quicksprout.com/2013/01/14/11-obvious-ab-tests-youshould-try/ .
- Porter, Joshua. The Button Color A/B Test: Red Beats Green. Hutspot. [Online] Aug 2, 2011. blog.hubspot.com/blog/tabid/6307/bid/20566/The-ButtonColor-AB-Test-Red-Beats-Green.aspx .
- Linden, Greg. Marissa Mayer at Web 2.0. Geeking with Greg. [Online] Nov 9, 2006. glinden.blogspot.com/2006/11/marissa-mayer-at-web20.html .
- Performance Related Changes and their User Impact. Schurman, Eric and Brutlag, Jake. sl: Velocity 09: Velocity Web Performance and Operations Conference, 2009.
- Souders, Steve. High Performance Web Sites: Essential Knowledge for Front-End Engineers. sl: O'Reilly Media, 2007. 978-0596529307.
- Linden, Greg. Make Data Useful. [Online] Dec 2006. sites.google.com/site/glinden/Home/StanfordDataMining.20 06-11-28.ppt.
- Wikipedia contributors. Above the fold. Wikipedia, The Free Encyclopedia. [Online] Jan 2014. en.wikipedia.org/wiki/Above_the_fold .
- Souders, Steve. Moving beyond window.onload (). High Performance Web Sites Blog. [Online] May 13, 2013. www.stevesouders.com/blog/2013/05/13/moving-beyondwindow-onload .
- Brutlag, Jake, Abrams, Zoe and Meenan, Pat. Above the Fold Time: Measuring Web Page Performance Visually. Velocity: Web Performance and Operations Conference. 2011. en.oreilly.com/velocitymar2011/public/schedule/detail/18692 .
- Meenan, Patrick. Speed Index. WebPagetest. [Online] April 2012. sites.google.com/a/webpagetest.org/docs/usingwebpagetest/metrics/speed-index .
- Meenan, Patrick, Feng, Chao (Ray) and Petrovich, Mike. Going Beyond onload — How Fast Does It Feel? Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/31 344.
- Fisher, Ronald A. Presidential Address. Sankhyā: The Indian Journal of Statistics. 1938, Vol. 4, 1. www.jstor.org/stable/40383882 .
- Kohavi, Ron and Longbotham, Roger. Unexpected Results in Online Controlled Experiments. SIGKDD Explorations. 2010, Vol. 12, 2. www.exp-platform.com/Documents/2010- 12 %20ExPUnexpectedSIGKDD.pdf.
- Montgomery, Douglas C. Applied Statistics and Probability for Engineers. 5th. sl: John Wiley & Sons, Inc, 2010. 978- 0470053041.
- Boos, Dennis D and Hughes-Oliver, Jacqueline M. How Large Does n Have to be for Z and t Intervals? The American Statistician. 2000, Vol. 54, 2, pp. 121-128.
- Efron, Bradley and Robert J. Tibshirani. An Introduction to the Bootstrap. New York: Chapman & Hall, 1993. 0-412-04231- 2.