Olá Habr! Apresento a você a tradução do artigo “
Aprendendo o modelo de morfabilidade de faces 3D a partir de imagens 2D ”.

O modelo morfável tridimensional da face (3D Morphable Model, a seguir denominado 3DMM) é um modelo estatístico da estrutura e textura da face, que é usado por visão computacional, computação gráfica, na análise do comportamento humano e em cirurgia plástica.
A singularidade de cada característica facial torna a modelagem de um rosto humano uma
tarefa não trivial . O 3DMM é criado para obter um modelo de face em um espaço de correspondências explícitas. Isso significa uma correspondência pontual entre o modelo resultante e outros modelos que permitem a transformação. Além disso, transformações de baixo nível, como as diferenças entre um rosto masculino e uma expressão facial neutra feminina de um sorriso, devem ser refletidas no 3DMM.

Pesquisadores da Universidade de Michigan oferecem o mais recente método 3DMM de aprendizado profundo. Usando a alta eficiência de redes neurais profundas para implementar mapeamentos não lineares, seu método permite obter 3DMM com base em uma imagem 2D capturada em um ambiente arbitrário.
Abordagens anteriores
Normalmente, os 3DMMs são obtidos usando um conjunto de digitalizações de faces 3D e um conjunto de imagens 2D das mesmas faces. A abordagem geralmente aceita é usar a redução dimensional no ensino com um professor, que é realizada usando a Análise de Componentes Principais (PCA) em um conjunto de dados de treinamento que consiste em digitalizações de face 3D e imagens 2D correspondentes. Ao usar modelos lineares como PCA, transformações não lineares e variações faciais não podem ser refletidas no 3DMM. Além disso, para modelar texturas 3D precisas de rostos, é necessária uma grande quantidade de "informações 3D". Assim, o uso dessa abordagem é ineficaz.
Método proposto
A idéia do
método proposto é usar redes neurais profundas ou, mais especificamente,
redes neurais convolucionais (que são mais adequadas ao problema em consideração e são menos caras em termos de tempo computacional do que os perceptrons de múltiplas camadas) para obter o 3DMM. Uma rede neural de codificação (codificador) pega uma imagem da face como entrada e gera parâmetros de textura e albedo da face com os quais duas redes neurais decodificadoras (decodificadores) avaliam a textura e o albedo.
Como mencionado anteriormente, o 3DMM linear apresenta vários problemas, como a necessidade de digitalizações de face 3D, a incapacidade de usar imagens tiradas de um ângulo arbitrário e a precisão limitada da apresentação devido ao uso de PCA linear. Por sua vez, o método proposto permite obter um modelo 3DMM não linear com base em imagens 2D de faces de alta resolução,
obtidas de um ângulo arbitrário .
Vista plana
Em sua abordagem, os pesquisadores usam um mapa de face 2D detalhado para representar sua textura e albedo. Eles argumentam que levar em conta as informações espaciais desempenha um papel importante, uma vez que utilizam redes neurais convolucionais, e as imagens frontais da face contêm pouca informação sobre os lados. Por isso, a escolha deles recaiu sobre a representação planar.
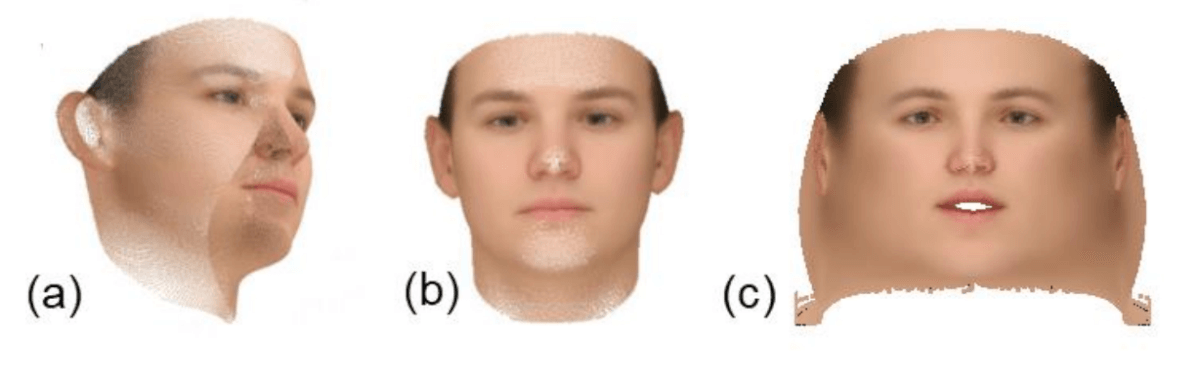
Três pontos de vista diferentes de albedo. (a) - representação 3D, (c) - albedo como imagem frontal 2D de uma face, (c) - representação plana.
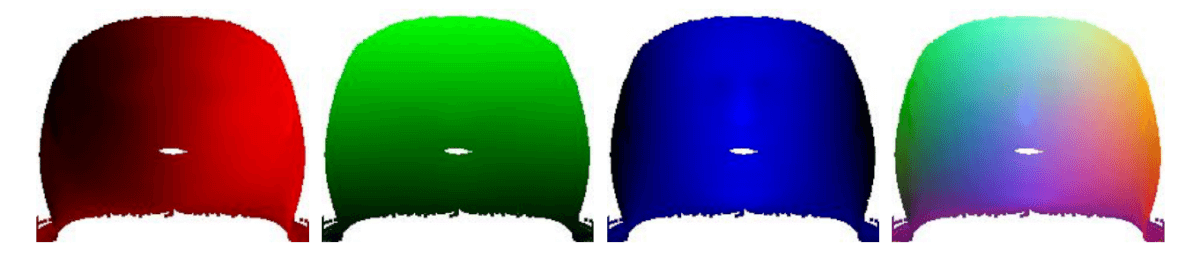
Vista plana. x, y, z e representação sumária da textura.
Arquitetura de rede neural
Os pesquisadores projetaram uma rede neural que, tomando uma imagem como entrada, a codifica em um vetor de textura, albedo e iluminação. Os vetores ocultos codificados para albedo e textura são decodificados usando dois decodificadores, que são usados em redes neurais convolucionais. Na saída, os decodificadores emitem o brilho da face, seu albedo e a textura da face 3D. Usando esses parâmetros, uma camada de renderização diferenciável gera um modelo de rosto combinando os parâmetros de textura 3D, albedo, iluminação e localização da câmera obtidos pelo codificador. A arquitetura é apresentada no diagrama abaixo.
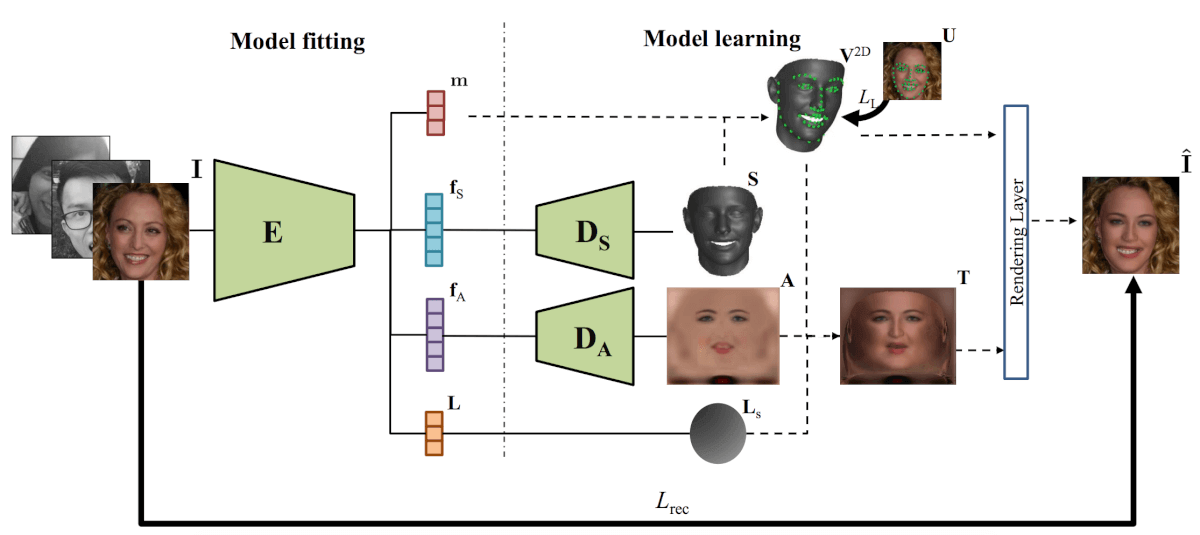
A arquitetura do método proposto para obter 3DMM não linear
O 3DMM não linear estável estável pode ser usado para sobreposição de faces 2D e resolução de problemas de reconstrução tridimensional de faces.
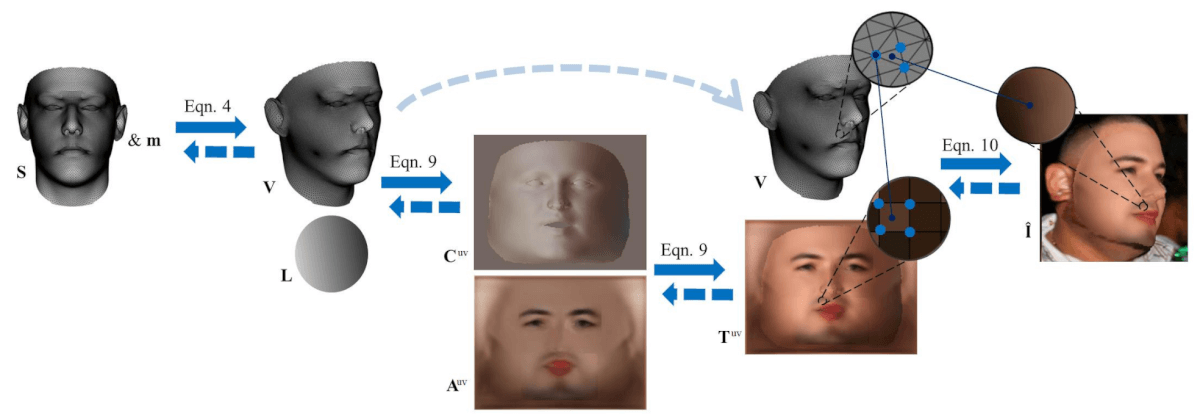
Layout da camada de renderização
Comparação com outros métodos
O método em questão foi comparado com outros métodos, usando as seguintes tarefas como exemplo:
sobreposição 2D, reconstrução e edição de faces 3D . O método proposto é superior a outras abordagens modernas para resolver esses problemas. Os resultados da comparação são apresentados abaixo.
Sobreposição de face 2D
Uma das aplicações do método é a sobreposição de faces, o que deve melhorar significativamente a análise de faces em várias tarefas (por exemplo, reconhecimento de faces). A imposição facial não é uma tarefa fácil, mas o método considerado mostra altos resultados ao resolvê-lo.

Resultados de sobreposição 2D. Marcas invisíveis são marcadas em vermelho. O método considerado reflete posturas incomuns, iluminação e expressões faciais.
Reconstrução facial 3D
O método em questão também foi comparado usando a reconstrução de face 3D e mostrou excelentes resultados em comparação com outros métodos.

Comparação quantitativa dos resultados da reconstrução 3D

Os resultados da reconstrução tridimensional em comparação com o método de Sela et al. O método proposto economiza muito melhor os pêlos faciais e outras características da face que esse método.

Os resultados da reconstrução 3D em comparação com o VRN de Jackson e outros no exemplo do famoso conjunto de dados CelebA.

Os resultados da reconstrução 3D em comparação com o método de Tewari e outros.Como você pode ver, o método proposto resolve o problema de comprimir o rosto na presença de várias texturas (como pêlos faciais).
Edição de rosto
O método discutido divide a imagem da face em elementos separados e permite alterar a face manipulando-os. Os resultados desse método ao editar faces foram avaliados no exemplo de tarefas como alterar a iluminação e adicionar elementos de face adicionais.

Os resultados da adição de uma barba. A primeira coluna contém a imagem original, a próxima - diferentes graus de mudança na barba.

Comparação com o método de Shu et al. (Segunda linha). Como você pode ver, o método proposto fornece imagens mais realistas e, além disso, a identidade do rosto é melhor preservada.
Conclusão
O método proposto, presumivelmente, será amplamente utilizado, pois permite obter 3DMM preciso e estável. Embora o 3DMM tenha sido difundido desde o início, até o advento do método em questão, não havia uma maneira eficaz de obter esse modelo usando imagens 2D de um ângulo arbitrário.
O método proposto utiliza redes neurais profundas como um aproximador para modelagem sustentável de rostos humanos com todas as suas características. Uma maneira incomum de obter o 3DMM permite manipular a imagem e pode ser usada em várias tarefas, algumas das quais foram apresentadas ao artigo.
Tradução - Boris Rumyantsev.