
Escalar um DBMS é um futuro que avança continuamente. Os DBMSs melhoram e escalam melhor nas plataformas de hardware, enquanto as próprias plataformas de hardware aumentam a produtividade, o número de núcleos e a memória - o Achilles está alcançando a tartaruga, mas ainda não o fez. O problema de dimensionar o DBMS está em pleno andamento.
O Postgres Professional teve um problema com o dimensionamento não apenas teoricamente, mas também praticamente: com seus clientes. E mais de uma vez. Um desses casos será discutido neste artigo.
O PostgreSQL se adapta bem aos sistemas NUMA, se for uma única placa-mãe com vários processadores e vários barramentos de dados. Algumas otimizações podem ser lidas
aqui e
aqui . No entanto, existe outra classe de sistemas, eles têm várias placas-mãe, cuja troca de dados é realizada por interconexão, enquanto uma instância do sistema operacional está trabalhando neles e para o usuário esse design parece uma única máquina. E, embora formalmente, esses sistemas também possam ser atribuídos ao NUMA, mas, em essência, eles estão mais próximos dos supercomputadores, como o acesso à memória local do nó e o acesso à memória do nó vizinho diferem radicalmente. A comunidade do PostgreSQL acredita que a única instância do Postgres em execução nessas arquiteturas é uma fonte de problemas, e ainda não existe uma abordagem sistemática para resolvê-los.
Isso ocorre porque a arquitetura do software que utiliza memória compartilhada é fundamentalmente projetada para o fato de que o tempo de acesso de diferentes processos à memória própria e remota é mais ou menos comparável. No caso em que trabalhamos com muitos nós, a aposta na memória compartilhada como um canal de comunicação rápido deixa de se justificar, porque, devido à latência, é muito "mais barato" enviar uma solicitação para executar uma determinada ação ao nó (nó) em que dados interessantes do que enviar esses dados no barramento. Portanto, para supercomputadores e, em geral, sistemas com muitos nós, as soluções de cluster são relevantes.
Isso não significa que a combinação de sistemas com vários nós e a arquitetura de memória compartilhada típica do Postgres precise ser encerrada. Afinal, se os processos do postgres passam a maior parte do tempo realizando cálculos complexos localmente, essa arquitetura será muito eficiente. Em nossa situação, o cliente já havia comprado um poderoso servidor de vários nós e tivemos que resolver os problemas do PostgreSQL nele.
Mas os problemas eram graves: as solicitações de gravação mais simples (alteram vários valores de campo em um registro) foram executadas em um período de alguns minutos a uma hora. Como foi confirmado posteriormente, esses problemas se manifestaram em toda a sua glória justamente por causa do grande número de núcleos e, consequentemente, pelo paralelismo radical na execução de solicitações com uma troca relativamente lenta entre os nós.
Portanto, o artigo será, por assim dizer, com duplo objetivo:
- Compartilhar experiência: o que fazer se, em um sistema com vários nós, o banco de dados ficar mais lento a sério. Por onde começar, como diagnosticar para onde se mover.
- Descreva como os problemas do DBMS do PostgreSQL podem ser resolvidos com um alto nível de simultaneidade. Incluindo como a alteração no algoritmo para bloquear bloqueios afeta o desempenho do PostgreSQL.
Servidor e DB
O sistema consistia em 8 lâminas com 2 soquetes em cada. No total, mais de 300 núcleos (excluindo hipertrefeição). Um pneu rápido (tecnologia proprietária do fabricante) conecta as lâminas. Não é um supercomputador, mas para uma instância do DBMS, a configuração é impressionante.
A carga também é bastante grande. Mais de 1 terabyte de dados. Cerca de 3000 transações por segundo. Mais de 1000 conexões para o postgres.
Tendo começado a lidar com as expectativas de gravação a cada hora, a primeira coisa que fizemos foi gravar no disco como causa de atrasos. Assim que começaram os atrasos incompreensíveis, os testes começaram a ser realizados exclusivamente em
tmpfs . A imagem não mudou. O disco não tem nada a ver com isso.
Introdução ao diagnóstico: exibições
Como os problemas surgiram provavelmente devido à alta competição de processos que "batem" nos mesmos objetos, a primeira coisa a verificar são os bloqueios. No PostgreSQL, há uma visão
pg.catalog.pg_locks e
pg_stat_activity para essa verificação. O segundo, já na versão 9.6, adicionou informações sobre o que o processo está aguardando (
Amit Kapila, Ildus Kurbangaliev ) -
wait_event_type . Os valores possíveis para este campo estão descritos
aqui .
Mas primeiro, basta contar:
postgres=
Estes são números reais. Atingiu até 200.000 bloqueios.
Ao mesmo tempo, esses bloqueios dependiam do pedido infeliz:
SELECT COUNT(mode), mode FROM pg_locks WHERE pid =580707 GROUP BY mode; count | mode —
Ao ler o buffer, o DBMS usa o bloqueio de
share , enquanto escreve -
exclusive . Ou seja, os bloqueios de gravação foram responsáveis por menos de 1% de todas as solicitações.
Na visualização
pg_locks , os tipos de bloqueio nem sempre são os descritos
na documentação do usuário.
Aqui está a placa de fósforo:
AccessShareLock = LockTupleKeyShare RowShareLock = LockTupleShare ExclusiveLock = LockTupleNoKeyExclusive AccessExclusiveLock = LockTupleExclusive
A consulta SELECT mode FROM pg_locks mostrou que CREATE INDEX (sem CONCURRENTLY) aguardaria 234 INSERTs e 390 INSERTs para
buffer content lock . Uma solução possível é “ensinar” INSERTs de diferentes sessões para interceptar menos em buffers.
É hora de usar perf
O utilitário
perf coleta muitas informações de diagnóstico. No modo de
record ... ele grava estatísticas de eventos do sistema em arquivos (por padrão, eles estão em
./perf_data ) e no modo de
report analisa os dados coletados, por exemplo, é possível filtrar eventos que dizem respeito apenas ao
postgres ou a um determinado
pid :
$ perf record -u postgres $ perf record -p 76876 , $ perf report > ./my_results
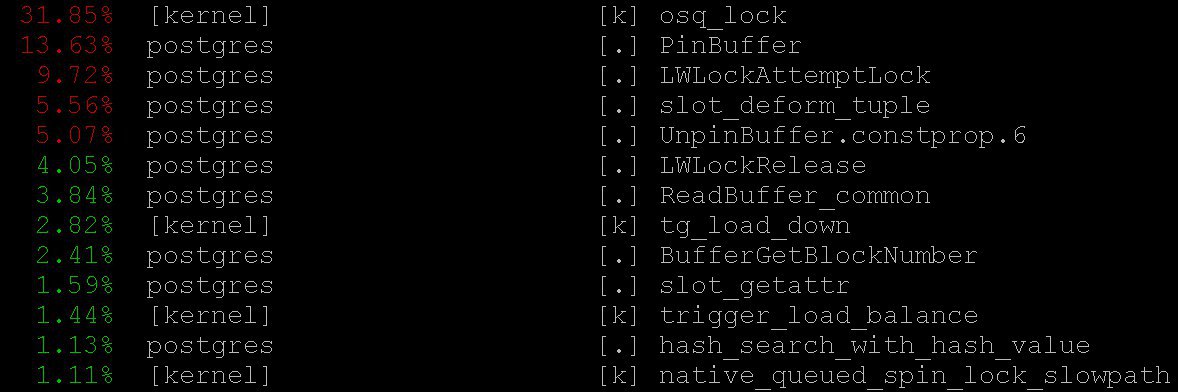
Como resultado, veremos algo como
Como usar o
perf para diagnosticar o PostgreSQL é descrito, por exemplo,
aqui , assim como no
wiki pg .
No nosso caso, até o modo mais simples forneceu informações importantes sobre o
perf top -
perf top , que funciona, é claro, no espírito do sistema operacional
top . Com o
perf top vimos que na maioria das vezes o processador gasta nos
PinBuffer() do núcleo, bem como nas
PinBuffer() e
LWLockAttemptLock(). .
PinBuffer() é uma função que aumenta o contador de referências ao buffer (mapeando uma página de dados para a RAM), graças a quais processos do postgres sabem quais buffers podem ser forçados a sair e quais não.
LWLockAttemptLock() - função de captura do
LWLock .
LWLock é um tipo de bloqueio com dois níveis de
shared e
exclusive , sem definir
deadlock , os bloqueios são pré-alocados para a
shared memory , os processos em espera estão aguardando em uma fila.
Essas funções já foram seriamente otimizadas no PostgreSQL 9.5 e 9.6. Os spinlocks dentro deles foram substituídos pelo uso direto de operações atômicas.
Gráficos de chama
É impossível sem eles: mesmo que fossem inúteis, ainda valeria a pena contar sobre eles - eles são extraordinariamente bonitos. Mas eles são úteis. Aqui está uma ilustração do
github , não do nosso caso (nem nós nem o cliente estamos prontos para a divulgação de detalhes ainda).

Essas belas imagens mostram claramente o que os ciclos do processador levam. O mesmo
perf pode coletar dados, mas o
flame graph visualiza os dados de maneira inteligente e constrói árvores com base nas pilhas de chamadas coletadas. Você pode ler mais sobre criação de perfil com gráficos de chama, por exemplo,
aqui , e baixar tudo o que precisa
aqui .
No nosso caso, uma enorme quantidade de
nestloop era visível nos gráficos de chama. Aparentemente, as JOINs de um grande número de tabelas em várias solicitações de leitura simultâneas causaram um grande número de bloqueios de
access share de
access share .
As estatísticas coletadas pelo
perf mostram para onde os ciclos do processador vão. E, embora vimos que a maior parte do tempo do processador passa por bloqueios, não vimos exatamente o que leva a expectativas tão longas de bloqueios, pois não vemos exatamente onde as expectativas de bloqueio ocorrem, porque O tempo da CPU não é desperdiçado em espera.
Para ver as próprias expectativas, você pode criar uma solicitação para a visualização do sistema
pg_stat_activity .
SELECT wait_event_type, wait_event, COUNT(*) FROM pg_stat_activity GROUP BY wait_event_type, wait_event;
revelou que:
LWLockTranche | buffer_content | UPDATE ************* LWLockTranche | buffer_content | INSERT INTO ******** LWLockTranche | buffer_content | \r | | insert into B4_MUTEX | | values (nextval('hib | | returning ID Lock | relation | INSERT INTO B4_***** LWLockTranche | buffer_content | UPDATE ************* Lock | relation | INSERT INTO ******** LWLockTranche | buffer_mapping | INSERT INTO ******** LWLockTranche | buffer_content | \r
(os asteriscos aqui simplesmente substituem os detalhes da solicitação que não divulgamos).
Você pode ver os valores
buffer_content (bloqueando o conteúdo dos buffers) e
buffer_mapping (bloqueando os componentes da placa de hash
shared_buffers ).
Para ajuda ao gdb
Mas por que existem tantas expectativas para esses tipos de bloqueios? Para informações mais detalhadas sobre as expectativas, tive que usar o depurador
GDB . Com o
GDB , podemos obter uma pilha de chamadas de processos específicos. Ao aplicar a amostragem, ou seja, Depois de coletar um certo número de pilhas de chamadas aleatórias, você pode ter uma idéia de quais pilhas têm as maiores expectativas.
Considere o processo de compilação de estatísticas. Consideraremos a coleção “manual” de estatísticas, embora na vida real sejam utilizados scripts especiais que fazem isso automaticamente.
Primeiro, o
gdb precisa ser anexado ao processo do PostgreSQL. Para fazer isso, encontre o
pid processo
pid servidor, digamos em
$ ps aux | grep postgres
Digamos que encontramos:
postgres 2025 0.0 0.1 172428 1240 pts/17 S 23 0:00 /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/data
e agora insira o
pid no depurador:
igor_le:~$gdb -p 2025
Uma vez dentro do depurador, escrevemos
bt [ou seja,
backtrace ] ou
where . E temos muitas informações sobre esse tipo:
(gdb) bt #0 0x00007fbb65d01cd0 in __write_nocancel () from /lib64/libc.so.6 #1 0x00000000007c92f4 in write_pipe_chunks ( data=0x110e6e8 "2018‐06‐01 15:35:38 MSK [524647]: [392‐1] db=bp,user=bp,app=[unknown],client=192.168.70.163 (http://192.168.70.163) LOG: relation 23554 new block 493: 248.389503\n2018‐06‐01 15:35:38 MSK [524647]: [393‐1] db=bp,user=bp,app=["..., len=409, dest=dest@entry=1) at elog.c:3123 #2 0x00000000007cc07b in send_message_to_server_log (edata=0xc6ee60 <errordata>) at elog.c:3024 #3 EmitErrorReport () at elog.c:1479
Depois de coletar estatísticas, incluindo pilhas de chamadas de todos os processos do postgres, coletadas repetidamente em diferentes momentos, vimos que o
buffer partition lock dentro do
relation extension lock durava 3706 segundos (cerca de uma hora), ou seja, bloqueia uma parte da tabela de hash do buffer gerente, necessário substituir o buffer antigo, para substituí-lo posteriormente por um novo correspondente à parte estendida da tabela. Um certo número de bloqueios de
buffer content lock do
buffer content lock também foi perceptível, o que correspondeu à expectativa de bloquear as páginas do índice da
B-tree para inserção.

A princípio, duas explicações vieram para um tempo de espera tão monstruoso:
- Alguém pegou esse
LWLock e ficou preso. Mas isso é improvável. Porque nada complicado acontece dentro do bloqueio da partição de buffer. - Encontramos algum comportamento patológico do
LWLock . Ou seja, apesar do fato de ninguém ter demorado muito na fechadura, sua expectativa durou excessivamente.
Patches de diagnóstico e tratamento de árvores
Ao reduzir o número de conexões simultâneas, provavelmente descarregaríamos o fluxo de solicitações para bloqueios. Mas isso seria como se render. Em vez disso,
Alexander Korotkov , arquiteto-chefe do Postgres Professional (claro, ele ajudou a preparar este artigo), propôs uma série de patches.
Antes de tudo, era necessário obter uma imagem mais detalhada do desastre. Não importa quão boas sejam as ferramentas acabadas, as correções de diagnóstico de sua própria fabricação também serão úteis.
Foi criado um patch que adiciona um registro detalhado do tempo gasto na
relation extension , o que está acontecendo dentro da função
RelationAddExtraBlocks() . Portanto, descobrimos o tempo gasto dentro do
RelationAddExtraBlocks().E em apoio a ele, outro patch foi escrito relatando em
pg_stat_activity o que estamos fazendo agora em
relation extension . Isso foi feito da seguinte maneira: quando a
relation expande,
application_name se torna
RelationAddExtraBlocks . Agora, esse processo é convenientemente analisado com o máximo de detalhes usando
gdb bt e
perf .
Na verdade, remendos médicos (e não diagnósticos) foram escritos dois. O primeiro patch mudou o comportamento dos bloqueios das folhas da
B‐tree : antes, quando solicitado a inserção, a folha era bloqueada como
share e, depois disso, era
exclusive . Agora ele imediatamente se torna
exclusive . Agora, este patch
já foi confirmado para o
PostgreSQL 12 . Felizmente, este ano,
Alexander Korotkov recebeu o
status de committer - o segundo commit do PostgreSQL na Rússia e o segundo na empresa.
O valor
NUM_BUFFER_PARTITIONS também foi aumentado de 128 para 512 para reduzir a carga nos bloqueios de mapeamento: a tabela de hash do gerenciador de buffer foi dividida em partes menores, na esperança de que a carga em cada parte específica fosse reduzida.
Depois de aplicar esse patch, os bloqueios no conteúdo dos buffers desapareceram, mas, apesar do aumento de
NUM_BUFFER_PARTITIONS , o
buffer_mapping permaneceu, ou seja, lembramos de bloquear partes da tabela de hash do gerenciador de buffer:
locks_count | active_session | buffer_content | buffer_mapping ----‐‐‐--‐‐‐+‐------‐‐‐‐‐‐‐‐‐+‐‐‐------‐‐‐‐‐‐‐+‐‐------‐‐‐ 12549 | 1218 | 0 | 15
E mesmo isso não é muito. A árvore B não é mais um gargalo. A extensão da
heap- veio à tona.
Tratamento de consciência
Em seguida, Alexander apresentou a seguinte hipótese e solução:
Aguardamos muito tempo no
buffer parittion lock do
buffer parittion lock ao
buffer parittion lock buffer. Talvez no mesmo
buffer parittion lock exista alguma página muito exigida, por exemplo, a raiz de alguma
B‐tree Nesse ponto, há um fluxo contínuo de solicitações de
shared lock das solicitações de leitura.
A fila de espera no
LWLock "não é justa". Como
shared lock podem ser obtidos quantos forem necessários ao mesmo tempo, se o
shared lock já
shared lock sido realizado, os
shared lock subsequentes serão transmitidos sem enfileiramento. Portanto, se o fluxo de bloqueios compartilhados tiver intensidade suficiente para que não haja "janelas" entre eles, aguardar um
exclusive lock será quase infinito.
Para corrigir isso, você pode tentar oferecer - um patch de comportamento "cavalheiro" dos bloqueios. Isso desperta a consciência dos
shared locker e eles fazem fila honestamente quando já existe um
exclusive lock (curiosamente, fechaduras pesadas -
hwlock - não têm problemas com a consciência: sempre fazem fila honestamente)
locks_count | active_session | buffer_content | buffer_mapping | reladdextra | inserts>30sec ‐‐‐‐‐‐-‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐--‐-‐+‐‐‐‐‐‐-‐‐‐‐‐‐+‐‐‐‐------ 173985 | 1802 | 0 | 569 | 0 | 0
Está tudo bem! Não há
insert longas. Embora os bloqueios nas peças das placas de hash permanecessem. Mas o que fazer, essas são as propriedades dos pneus do nosso pequeno supercomputador.
Este patch também foi
oferecido à comunidade . Mas não importa como o destino desses patches na comunidade se desenvolva, nada os impede de entrar nas próximas versões do
Postgres Pro Enterprise , projetadas especificamente para clientes com sistemas muito carregados.
Moral
Bloqueios
share leves de alta moral - blocos
exclusive pulam a fila - resolveram o problema de atrasos por hora em um sistema de vários nós. A tag hash do
buffer manager não funcionou devido ao excesso de fluxo de
share lock , o que não deixou chance para os bloqueios necessários para suplantar buffers antigos e carregar novos. Problemas com a extensão do buffer para as tabelas do banco de dados foram apenas uma consequência disso. Antes disso, era possível expandir o gargalo com acesso à raiz da
B-treeO PostgreSQL não foi projetado para arquiteturas e supercomputadores NUMA. A adaptação a essas arquiteturas do Postgres é um trabalho enorme que exigiria (e possivelmente exigiria) os esforços coordenados de muitas pessoas e até de empresas. Mas as conseqüências desagradáveis desses problemas arquitetônicos podem ser mitigadas. E precisamos: os tipos de carga que levaram a atrasos semelhantes aos descritos são bastante típicos, sinais de socorro semelhantes de outros lugares continuam chegando até nós. Problemas semelhantes apareceram anteriormente - em sistemas com menos núcleos, apenas as consequências não eram tão monstruosas e os sintomas foram tratados com outros métodos e outros patches. Agora outro medicamento apareceu - não universal, mas claramente útil.
Portanto, quando o PostgreSQL trabalha com a memória de todo o sistema como local, nenhum barramento de alta velocidade entre os nós pode comparar com o tempo de acesso à memória local. As tarefas surgem por causa disso difícil, muitas vezes urgente, mas interessante. E a experiência de resolvê-los é útil não apenas para os decisivos, mas também para toda a comunidade.
