
Cada uma das tecnologias criadas a partir do momento em que uma pessoa pegou uma pedra é obrigada a melhorar a vida de uma pessoa, desempenhando suas principais funções. No entanto, qualquer tecnologia pode ter "efeitos colaterais", isto é, afetar uma pessoa e o mundo ao seu redor de uma maneira que ninguém na época da criação dessa tecnologia pensou ou desejava pensar. Um exemplo vívido: máquinas foram criadas e uma pessoa foi capaz de percorrer longas distâncias a uma velocidade mais rápida do que antes. Mas, ao mesmo tempo, começou a poluição.
Hoje falaremos sobre o "efeito colateral" da Internet, que afeta não a atmosfera da Terra, mas as mentes e almas das próprias pessoas. O fato é que a World Wide Web se tornou uma excelente ferramenta para a disseminação e troca de informações, para a comunicação entre pessoas fisicamente distantes umas das outras e para muito mais. A Internet ajuda em várias áreas da sociedade, da medicina à preparação banal para o teste da história. No entanto, o lugar onde muitas vozes e opiniões, às vezes sem nome, se reúnem, infelizmente, é preenchido com o que é tão inerente ao ódio ao homem.
No estudo de hoje, os cientistas dividem em pedaços vários algoritmos cuja principal tarefa é identificar mensagens ofensivas, rudes e hostis. Eles conseguiram quebrar todos esses algoritmos, demonstrando seu baixo nível de eficiência e apontando os erros que deveriam ser corrigidos. Como os cientistas quebraram o que supostamente funcionou, por que o fizeram e que conclusões todos devemos tirar - procuraremos respostas para essas e outras perguntas no relatório dos pesquisadores. Vamos lá
Antecedentes do estudoAs redes sociais e outras formas de interação da Internet entre as pessoas se tornaram parte integrante de nossas vidas. Infelizmente, muitos dos usuários de tais serviços entendem literalmente algo como “liberdade de expressão, pensamento e expressão”, cobrindo isso com seu direito a comportamentos indecentes, familiares e rudes na rede. Cada um de nós, de uma forma ou de outra, enfrentou a "atividade" de tais indivíduos. Muitos até se tornaram objeto de tais discursos. Obviamente, não se pode negar que uma pessoa tem todo o direito de dizer o que pensa. No entanto, expressar seus pensamentos é uma coisa, e insultar alguém é outra. Além da liberdade de expressão, o anonimato também é explorado, porque você pode dizer qualquer coisa para qualquer pessoa, enquanto permanece incógnito. Como resultado, você não será punido por seu comportamento inadequado.
Não vale a pena explicar que as frases "eu não gostei" e "isso é uma foda completa **, autor mata contra a parede" (essa é uma opção ainda mais ou menos decente) têm cores emocionais completamente diferentes, embora tenham uma essência comum - para o comentarista Não gosto do que ele viu / leu / ouviu, etc. Mas se você proíbe uma pessoa de expressar sua insatisfação dessa maneira, isso é considerado uma violação de seus direitos? Muitos dirão que sim. Por outro lado, vale a pena continuar de olho no crescente ódio exponencial na Internet, que na maioria dos casos não se justifica. O ódio, como tal, tem um lugar para estar. Claro, essa é uma emoção muito forte e incrivelmente negativa. No entanto, se uma pessoa odeia quem fez algo terrível (assassinato, estupro e outros atos desumanos), isso ainda pode ser justificado de alguma forma. Mas quando o ódio se manifesta no endereço de uma pessoa completamente alienígena que não cometeu nada imoral ou desumano, essa é uma história completamente diferente.
Agora, muitas empresas e grupos de pesquisa decidiram criar seus próprios algoritmos que podem analisar qualquer texto e dizer onde
a linguagem da hostilidade * está presente e até que ponto ela é expressa. Os heróis de hoje decidiram testar esses algoritmos, em particular a API do Google Perspective, muito promovida, que determina a "acidez" da frase, ou seja, quanto essa frase pode ser considerada um insulto.
Discurso de ódio * - como resulta claramente do próprio nome desse termo, é uma combinação de meios de linguagem que visa expressar uma hostilidade vívida entre os interlocutores. As formas mais comuns de discurso de ódio são: racismo, sexismo, xenofobia, homofobia e outras formas de hostilidade a outra coisa.
As principais tarefas definidas pelos pesquisadores são estudar os algoritmos mais populares para identificar discursos de ódio, entender seus métodos de trabalho e tentar contorná-los.
Algoritmos de PesquisaOs cientistas escolheram vários algoritmos cujos bancos de dados são diferentes entre si, o que também nos permite determinar o melhor banco de dados. Alguns algoritmos dependem mais da identificação de
conotações sexuais
* , outras - religiosas. Comum a todos os algoritmos é a fonte de seu conhecimento - o Twitter. Segundo os pesquisadores, isso está longe de ser perfeito, pois esse serviço possui certas limitações (por exemplo, o número de caracteres em uma mensagem). Portanto, a base de um algoritmo eficaz deve ser preenchida a partir de diferentes redes e serviços sociais.
Conotação * - um método de colorir uma palavra ou frase com tons semânticos ou emocionais adicionais. Pode variar dependendo da forma linguística, cultural ou outra forma de separação social. Exemplo: ventoso - “o dia estava ventoso” (o significado direto da palavra), “ele sempre foi uma pessoa ventosa” (neste caso, significa inconstância e frivolidade).
Lista de algoritmos e suas funcionalidades:
Detox : projeto da Wikipedia para identificar linguagem inadequada nos comentários editoriais. Ele funciona com base na
regressão logística * e em um
perceptron multicamada * , usando modelos
N-gram * no nível de letras e palavras. O tamanho dos N-gramas de uma palavra varia de 1 a 3 e as letras - de 1 a 5.
A regressão logística * é um modelo para prever a probabilidade de um evento ajustando os dados a uma curva logística.
Um perceptron multicamada * é um modelo de percepção da informação, composto por três camadas principais: S - sensores (recebendo um sinal), A - elementos associativos (processamento) e elementos de reação R (resposta a um sinal), além de uma camada adicional A.
N-grama * é uma sequência de n elementos.
Os dados para a base do algoritmo foram coletados por terceiros e cada um dos comentários foi avaliado por dez avaliadores.
T1 : um algoritmo com uma base dividida em três tipos de comentários do Twitter (discurso de ódio, insultos sem discurso de ódio e neutro). Os pesquisadores dizem que esta é a única base com uma categorização semelhante. O discurso de ódio foi detectado ao pesquisar no Twitter por determinados padrões. Além disso, os resultados encontrados foram avaliados por três funcionários da CrowdFlower (agora Figura Oito Inc., um estudo de aprendizado de máquina e inteligência artificial). A maior parte da base (76%) é de frases ofensivas, enquanto a linguagem hostil ocupa apenas 5%.
T2 : um algoritmo que utiliza redes neurais profundas. A ênfase principal foi colocada na memória de longo prazo (LSTM). A base deste algoritmo é dividida em três categorias: racismo, sexismo e nada. Os pesquisadores combinaram as duas primeiras categorias em uma, formando uma categoria integral de linguagem hostil. A base da base foi de 16.000 tweets.
T1 * ,
T3 : algoritmo baseado na rede neural convolucional (CNN) e unidades de recorrência controlada (GRU), utilizando a base de conhecimento T1, complementando-o com categorias separadas destinadas a refugiados e muçulmanos (T3).
Desempenho do algoritmoO desempenho dos algoritmos foi testado por dois métodos. No primeiro, eles funcionaram como originalmente previsto. E no segundo, os algoritmos foram treinados através dos bancos de dados de cada um deles, uma espécie de troca de experiências.
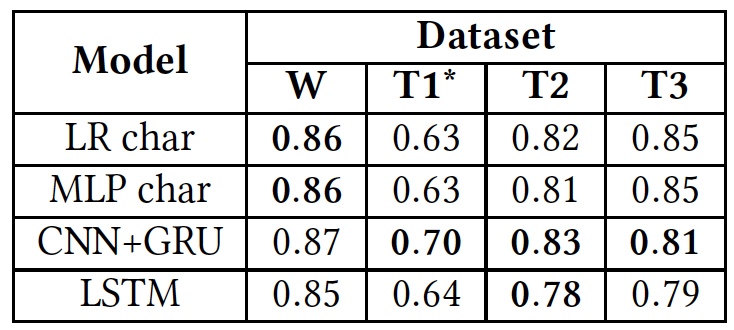 Resultados do teste (os resultados do uso de bancos de dados originais estão em negrito).
Resultados do teste (os resultados do uso de bancos de dados originais estão em negrito).Como pode ser visto na tabela acima, todos os algoritmos apresentaram aproximadamente os mesmos resultados quando aplicados a diferentes textos (bancos de dados). Isso sugere que todos estudaram usando o mesmo tipo de texto.
O único desvio significativo é observado em T1 *. Isso se deve ao fato de o banco de dados desse algoritmo ser extremamente desequilibrado, segundo os cientistas. O discurso de ódio leva apenas 5%, como já sabemos. A divisão inicial em três categorias de textos foi transformada em uma divisão em duas, quando os textos "insultos, mas sem linguagem hostil" e "neutros" foram combinados em um grupo, ocupando cerca de 80% de toda a base.
Além disso, os pesquisadores treinaram novamente os algoritmos. A princípio, as bases originais foram usadas. Depois disso, cada um dos algoritmos teve que trabalhar com a base de outro algoritmo, e não com o seu.
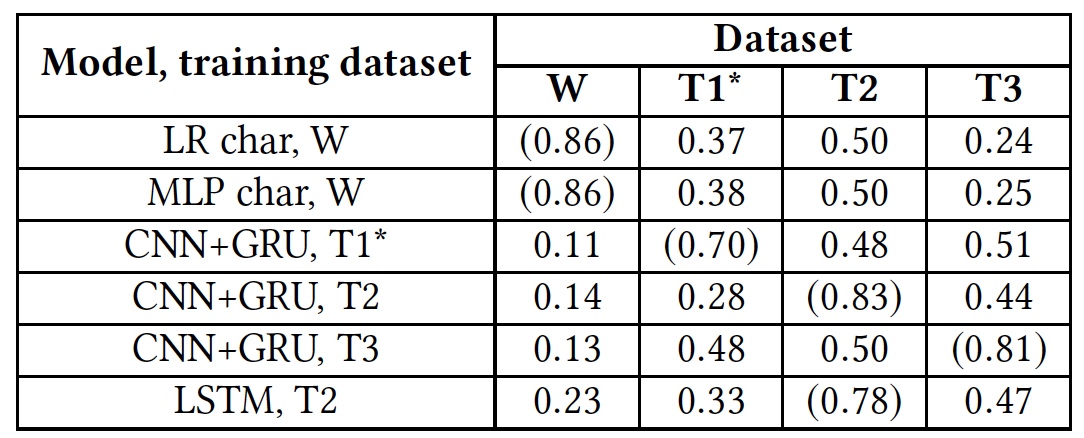 Treinar novamente os resultados do teste (os resultados usando bancos de dados nativos são mostrados entre parênteses)
Treinar novamente os resultados do teste (os resultados usando bancos de dados nativos são mostrados entre parênteses)Este teste mostrou que todos os algoritmos estavam completamente despreparados para trabalhar com bancos de dados estrangeiros. Isso sugere que os indicadores lingüísticos do discurso de ódio não se cruzam em bancos de dados diferentes, o que pode ser devido ao fato de que em bancos de dados diferentes existem muito poucas palavras correspondentes ou devido a imprecisões na interpretação de certas frases.
Insultos e discurso de ódioOs pesquisadores decidiram prestar atenção especial a duas categorias de textos: ofensivo e hostil. A linha inferior é que alguns algoritmos os combinam em um heap, enquanto outros tentam separá-los como grupos independentes. Obviamente, os insultos são claramente um fenômeno negativo e podem ser atribuídos com segurança a uma categoria com hostilidade. No entanto, definir insultos é um processo muito mais complicado do que identificar ódio aparente no texto.
Para testar os algoritmos quanto à capacidade de detectar insultos, foi utilizada a base T1. Mas o algoritmo T1 * não participou desse teste, devido ao fato de já estar preparado para esse trabalho, o que torna os resultados de sua verificação enviesados.
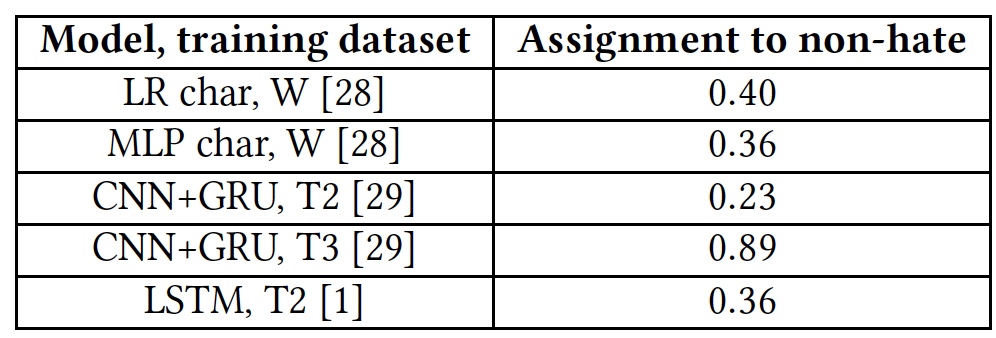 Resultados do teste para a capacidade de detectar textos ofensivos.
Resultados do teste para a capacidade de detectar textos ofensivos.Todos os algoritmos mostraram resultados bastante medíocres. A exceção foi T3, mas não à custa de seus talentos. O fato é que as palavras que não são familiares ao algoritmo são marcadas com a marca
unk . Quase 40% das palavras em cada frase foram marcadas com essa tag e o algoritmo as contou automaticamente como insultos. E isso, é claro, estava longe de estar sempre certo. Em outras palavras, o algoritmo T3 também não lidou com a tarefa em vista de seu vocabulário curto.
Um dos principais problemas dos algoritmos, os cientistas consideram o fator humano. A maioria dos bancos de dados de cada um dos algoritmos é coletada, analisada e avaliada por pessoas. E aqui, grandes diferenças de resultados são possíveis. A mesma frase pode parecer ofensiva para algumas pessoas ou neutra para outras.
Além disso, a falta de algoritmos para entender frases não padronizadas que podem conter calmamente linguagem obscena, mas sem nenhum tipo de linguagem ofensiva ou hostil, também exerce um efeito negativo.
Para demonstrar isso, foi realizado um teste com várias frases. Em seguida, o teste foi repetido, mas em cada uma das frases a palavra muito obscena "
f * ck " foi adicionada (marcada com a letra
F na tabela).
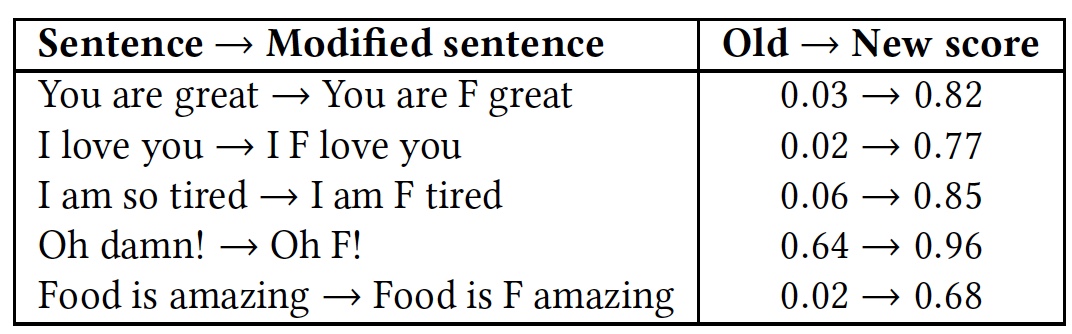 Resultados comparativos de reconhecimento de frases com e sem a palavra "f * ck".
Resultados comparativos de reconhecimento de frases com e sem a palavra "f * ck".Como pode ser visto na tabela, valeu a pena acrescentar uma palavra com a letra F, pois todos os algoritmos adotaram a frase imediatamente como uma linguagem de hostilidade. Embora a essência das frases permanecesse a mesma, amigável, mas a cor emocional mudou para uma mais pronunciada.
Os testes da API do Google Perspective descritos acima mostram resultados semelhantes. Esse algoritmo também não é capaz de distinguir linguagem hostil de insultos e insulto de um epíteto simples usado para embelezar emocionalmente uma frase.
Como enganar o algoritmo?Como costuma acontecer, se alguém quebra algo, isso nem sempre é ruim. E tudo porque, quando rompemos, revelamos a falta de um sistema, seu ponto fraco, que deve ser melhorado, impedindo a repetição do colapso. Os modelos acima não foram exceção, e os pesquisadores decidiram ver como seu trabalho poderia ser interrompido. Como se viu, não foi tão difícil quanto pensaram os criadores desses algoritmos.
O modelo de desvio de algoritmo é simples: o cracker sabe que seus textos são verificados, ele pode alterar os dados de entrada (texto) de forma a evitar a detecção. O cracker não tem acesso ao próprio algoritmo e sua estrutura. Simplificando, o invasor quebra o algoritmo exclusivamente no nível do usuário.
O desvio do algoritmo (vamos chamá-la de boa e antiga palavra "hacking") é dividido em três tipos:
- Alterando a palavra: erros de digitação intencionais e Leet, ou seja, substituindo algumas letras por números (por exemplo: Você está ótima hoje! - Y0U 100K 6r347 70D4Y!);
- Mude o espaço entre as palavras: adicione e remova espaços;
- Adicione palavras no final de uma frase.
O primeiro programa de hackers - mudança de palavras - deve concluir com êxito três tarefas: reduzir o grau de reconhecimento de uma palavra por um algoritmo, evitar correções ortográficas e manter a legibilidade das palavras para uma pessoa.
O programa troca as duas letras da palavra. É dada preferência a letras mais próximas do meio da palavra e entre si. Apenas a primeira e a última letras da palavra são excluídas. Além disso, as palavras são modificadas com atenção no Leet, onde algumas letras são substituídas por números: a - 4, e - 3, l - 1, o - 0, s - 5.
Para lidar com esses truques, os algoritmos foram ligeiramente aprimorados com a introdução da verificação ortográfica e da transformação estocástica da base de conhecimento do treinamento. Ou seja, não apenas as palavras principais estavam presentes no banco de dados, mas também foram alteradas reorganizando as letras do formulário.
No entanto, quanto maior a palavra, mais opções existem para reorganizar as letras, o que expande os recursos do programa cracker.
O método de remover ou adicionar espaços também possui características próprias. A remoção de espaços é mais adequada para algoritmos opostos que analisam palavras inteiras. Porém, algoritmos que analisam cada letra podem lidar facilmente com a ausência de espaços.
Adicionar espaços pode parecer um método muito ineficiente, mas ainda pode enganar alguns algoritmos. Modelos que consideram as palavras como um todo conduzem uma análise lexical da frase, dividindo-a em componentes (tokens). Nesse caso, o espaço serve como um separador de palavras, ou seja, um elemento importante da análise de frases. Se houver mais lacunas do que o necessário, as palavras entre elas se tornarão irreconhecíveis para o algoritmo. Ao mesmo tempo, esse método de desvio mantém um alto grau de legibilidade das frases para uma pessoa. O método funciona de forma simples: uma letra aleatória na palavra é selecionada depois que um espaço é colocado. Como resultado, uma palavra que era anteriormente conhecida pelo algoritmo deixa de ser essa. Exemplo: "Ódio" - "Ódio". Se você remover todas as lacunas no texto, a frase inteira se tornará para o algoritmo uma palavra incompreensível para ele. Como na história em que a filha deu à mãe um novo telefone, ela escreveu um SMS com o texto: "Caro, deixe um espaço em branco neste telefone". Podemos ler esta frase, mas o algoritmo a perceberá como uma palavra que, é claro, ele não sabe.
No entanto, se o algoritmo analisar as letras separadamente, ele poderá reconhecer a frase; portanto, esse método de hacking não é adequado nesses casos.
Para combater esses ataques, os algoritmos também foram reciclados. Para combater a adição de espaços, a base do algoritmo passou por um programa de introdução aleatória de espaços: uma palavra de n letras pode ser separada por um espaço de maneiras n-1. No entanto, isso levou a uma explosão combinatória, quando a complexidade do algoritmo aumenta acentuadamente devido ao aumento no tamanho dos dados de entrada. Como resultado, aprender o algoritmo com base no método conhecido de adicionar espaços é um exercício extremamente difícil e ineficiente.
Excluir espaços também é difícil. Se a base do algoritmo for reabastecida com frases que ele conhece, mas sem espaços, isso funcionará efetivamente somente quando essa frase for aplicada. Vale a pena substituir algumas letras ou uma palavra, e o algoritmo não reconhece nada.
No método de hackers, adicionando palavras, a principal essência é como o algoritmo de reconhecimento funciona. Ele divide as palavras em categorias, diga "bom" e "ruim". Se a frase tiver mais frases "boas", provavelmente o algoritmo determinará a frase inteira como "boa". E vice-versa. Se você adicionar uma palavra aleatória “boa” à frase “ruim” em significado, poderá enganar o algoritmo, e o significado da frase para a pessoa que a ler permanecerá o mesmo. O programa de hackers gera números aleatórios (de 10 a 50) ou palavras no final de cada frase. Uma lista das palavras em inglês comuns mais comuns fornecidas pelo Google foi escolhida como fonte de palavras aleatórias.
 Uma tabela dos resultados da aplicação dos métodos de hacking acima e a reação dos algoritmos a isso (ataque A, treinamento AT baseado no princípio de um programa de ataque, ortografia SC, remoção de espaços RW).
Uma tabela dos resultados da aplicação dos métodos de hacking acima e a reação dos algoritmos a isso (ataque A, treinamento AT baseado no princípio de um programa de ataque, ortografia SC, remoção de espaços RW).Para ilustrar a solução alternativa, introduzindo palavras adicionais, os pesquisadores realizaram um teste usando a palavra "amor". Esta palavra foi adicionada no final das frases ofensivas.
 Resultados do teste com a palavra "amor".
Resultados do teste com a palavra "amor".A tabela mostra que este método foi capaz de enganar todos os algoritmos que analisam a palavra inteira. Algoritmos que analisam letras separadamente também sofreram, mas não tanto.
Anteriormente, a API do Google Perspective já havia sido testada, o que mostrava sua capacidade ineficaz de reconhecer textos neutros e ofensivos.Em seguida, usamos frases de teste (não traduzo por motivos óbvios):S1: Climate change is happening and it's not changing in our favor. If you think differently you're an idiot.
S2: They're stupid, it's getting warmer, we should enjoy it while it lasts
S3: They are liberal idiots who are uneducated
S4: idiots. backward thinking people. nationalists. not accepting facts. susceptible to lies.
S5: They are stupid and ignorant with no class
S6: It's stupid and wrong
S7: If they voted for Hilary they are idiots
S8: Anyone who voted for Trump is a moron
S9: Screw you trump supporters
Os pesquisadores usaram as mesmas frases em suas pesquisas. O resultado foi significativamente melhor, o que sugere que a API do Google Perspective foi aprimorada. No entanto, a aplicação do método de remoção de espaços em combinação com a introdução da palavra “amor” em cada uma das frases acima mostrou um resultado completamente diferente.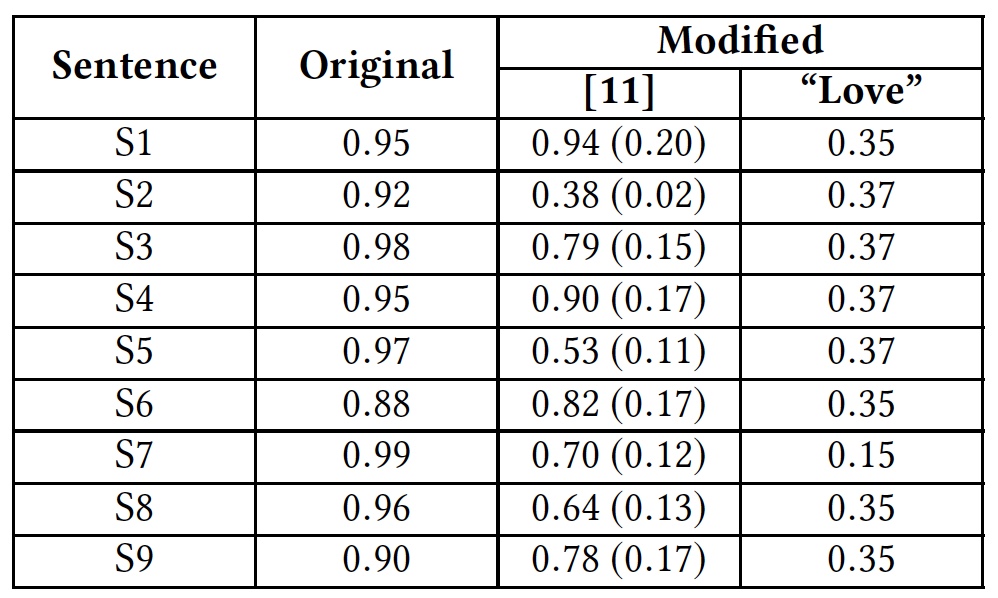 API do Google Perspective: grau de "toxicidade" (ofensividade) das frases.Entre parênteses, estão os resultados atuais em comparação com os anteriores à melhoria da API do Google Perspective.Para um conhecimento mais detalhado deste estudo, você pode usar o relatório de cientistas disponíveis aqui .EpílogoOs pesquisadores deliberadamente usaram os métodos mais simples de enganar algoritmos para demonstrar seu baixo grau de eficiência, bem como para indicar aos desenvolvedores os pontos fracos que requerem atenção.Programas que podem rastrear frases ofensivas online são certamente uma ótima idéia. Mas o que vem depois? Este programa deve bloquear frases semelhantes? Ou ela deveria sugerir uma frase alternativa que não contenha insultos? Do lado da ética, há muitas questões: liberdade de expressão, censura, cultura de comportamento, igualdade de pessoas e assim por diante. O programa tem o direito de decidir o que uma pessoa tem o direito de dizer e o que não? Possivelmente. No entanto, a implementação de um programa desse tipo deve ser impecável, sem falhas que possam ser usadas contra ele. E, embora os cientistas continuem confundindo essa questão, a própria sociedade deve decidir por si mesma - a liberdade de expressão total é tão bonita ou às vezes pode ser limitada?Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD de 1Gbps até dezembro de graça quando pagar por um período de seis meses, você pode fazer o pedido aqui .Dell R730xd 2 vezes mais barato? Só temos 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV a partir de $ 249na Holanda e nos EUA! Leia sobre Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?
API do Google Perspective: grau de "toxicidade" (ofensividade) das frases.Entre parênteses, estão os resultados atuais em comparação com os anteriores à melhoria da API do Google Perspective.Para um conhecimento mais detalhado deste estudo, você pode usar o relatório de cientistas disponíveis aqui .EpílogoOs pesquisadores deliberadamente usaram os métodos mais simples de enganar algoritmos para demonstrar seu baixo grau de eficiência, bem como para indicar aos desenvolvedores os pontos fracos que requerem atenção.Programas que podem rastrear frases ofensivas online são certamente uma ótima idéia. Mas o que vem depois? Este programa deve bloquear frases semelhantes? Ou ela deveria sugerir uma frase alternativa que não contenha insultos? Do lado da ética, há muitas questões: liberdade de expressão, censura, cultura de comportamento, igualdade de pessoas e assim por diante. O programa tem o direito de decidir o que uma pessoa tem o direito de dizer e o que não? Possivelmente. No entanto, a implementação de um programa desse tipo deve ser impecável, sem falhas que possam ser usadas contra ele. E, embora os cientistas continuem confundindo essa questão, a própria sociedade deve decidir por si mesma - a liberdade de expressão total é tão bonita ou às vezes pode ser limitada?Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD de 1Gbps até dezembro de graça quando pagar por um período de seis meses, você pode fazer o pedido aqui .Dell R730xd 2 vezes mais barato? Só temos 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV a partir de $ 249na Holanda e nos EUA! Leia sobre Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?