
Há pouco mais de um ano,
analisamos o aplicativo
Splunk Machine Learning Toolkit , com o qual você pode analisar os dados da máquina na plataforma Splunk usando vários algoritmos de aprendizado de máquina.
Hoje queremos falar sobre as atualizações que apareceram no ano passado. Muitas novas versões foram lançadas, vários algoritmos e visualizações foram adicionados que permitirão levar a análise de dados no Splunk a um novo nível.
Novos algoritmos
Antes de falar sobre algoritmos, observe que existe uma
API ML-SPL com a qual você pode carregar qualquer algoritmo de código aberto com mais de 300 algoritmos Python. No entanto, para isso, você precisa ser capaz de programar em alguma extensão no Python.
Portanto, prestaremos atenção aos algoritmos que estavam disponíveis anteriormente somente após a manipulação do Python, mas agora estão incorporados ao aplicativo e podem ser facilmente usados por todos.
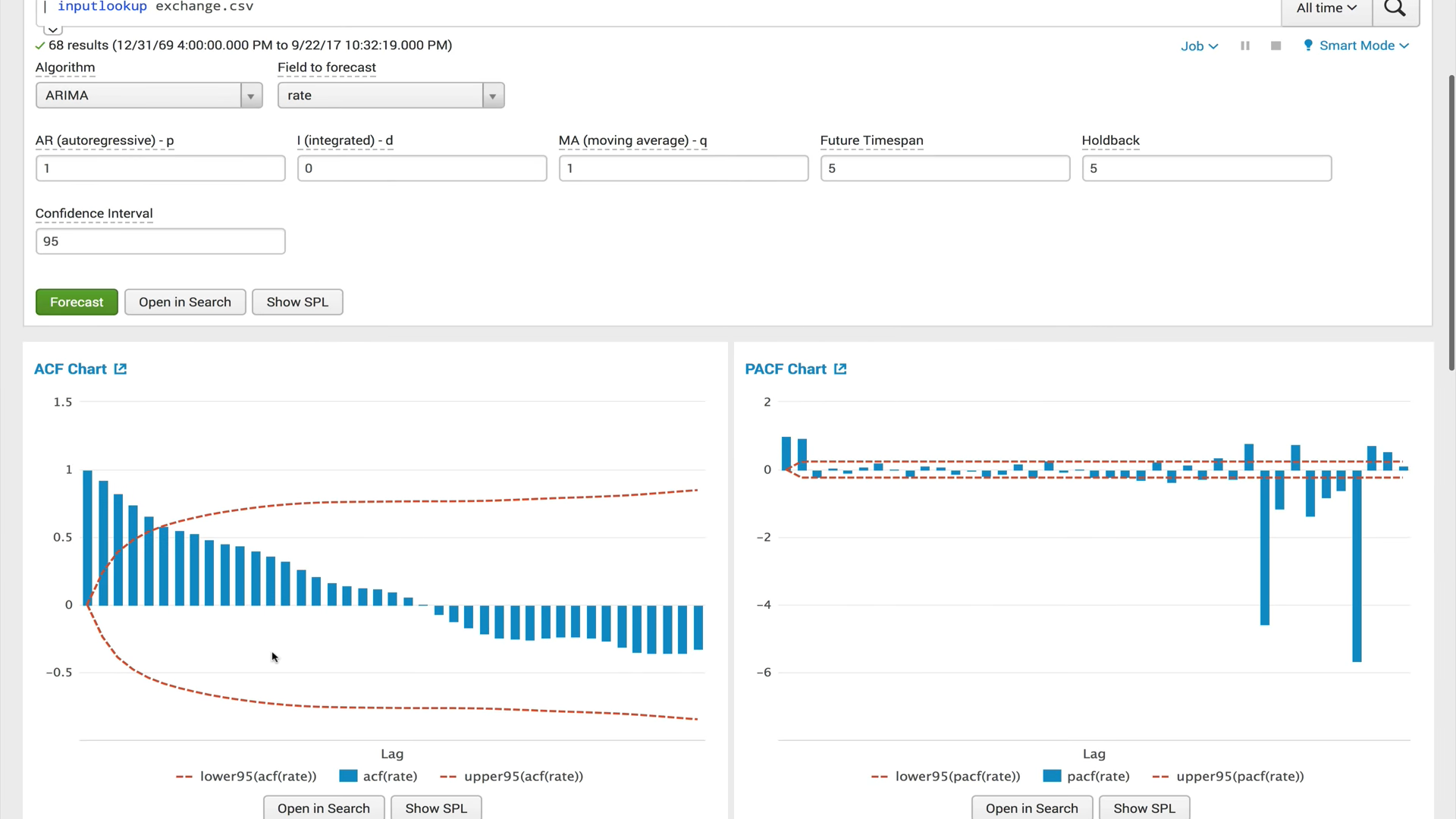
 ACF (função de autocorrelação)
ACF (função de autocorrelação)Uma função de autocorrelação mostra o relacionamento entre uma função e sua cópia alterada pela quantidade de tempo. O ACF ajuda a encontrar seções duplicadas ou determinar a frequência do sinal, oculto devido à sobreposição de ruídos e vibrações em outras frequências.
PACF (função de autocorrelação parcial)A função de autocorrelação privada mostra a correlação entre as duas variáveis, menos o efeito de todos os valores internos de autocorrelação. A autocorrelação privada em um certo atraso é semelhante à autocorrelação comum, mas seu cálculo exclui a influência da autocorrelação com atrasos menores. Na prática, a autocorrelação privada fornece uma imagem mais "limpa" das dependências periódicas.
ARIMA (processo integrado de auto-regressão e média móvel)O modelo ARIMA é um dos modelos mais populares para a criação de previsões de curto prazo. Os valores autoregressivos expressam a dependência do valor atual das séries temporais em relação aos anteriores, e a média móvel do modelo determina o efeito dos erros de previsão anteriores (também chamados de ruído branco) no valor atual.
 Classificador de aumento de gradiente e regressor de aumento de gradiente
Classificador de aumento de gradiente e regressor de aumento de gradienteO aumento de gradiente é um método de aprendizado de máquina usado para problemas de regressão e classificação que cria um modelo de previsão na forma de um conjunto de modelos fracos, geralmente árvores de decisão. Ele constrói o modelo em etapas, quando cada algoritmo subsequente procura compensar as deficiências da composição de todos os algoritmos anteriores. Inicialmente, o conceito de impulsionar surgiu nos trabalhos em conexão com a questão de saber se é possível, com muitos algoritmos de aprendizado ruins (ligeiramente diferentes da definição aleatória), obter um bom. Nos últimos 10 anos, o impulso continuou sendo um dos métodos mais populares de aprendizado de máquina, junto com as redes neurais. Os principais motivos são simplicidade, versatilidade, flexibilidade (a capacidade de criar várias modificações) e, mais importante, alta capacidade de generalização.
X-significaO algoritmo de agrupamento X-means é um algoritmo k-means avançado que determina automaticamente o número de clusters com base no critério de informação bayesiano (BIC). Esse algoritmo é conveniente de usar quando não há informações preliminares sobre o número de clusters nos quais esses dados podem ser divididos.
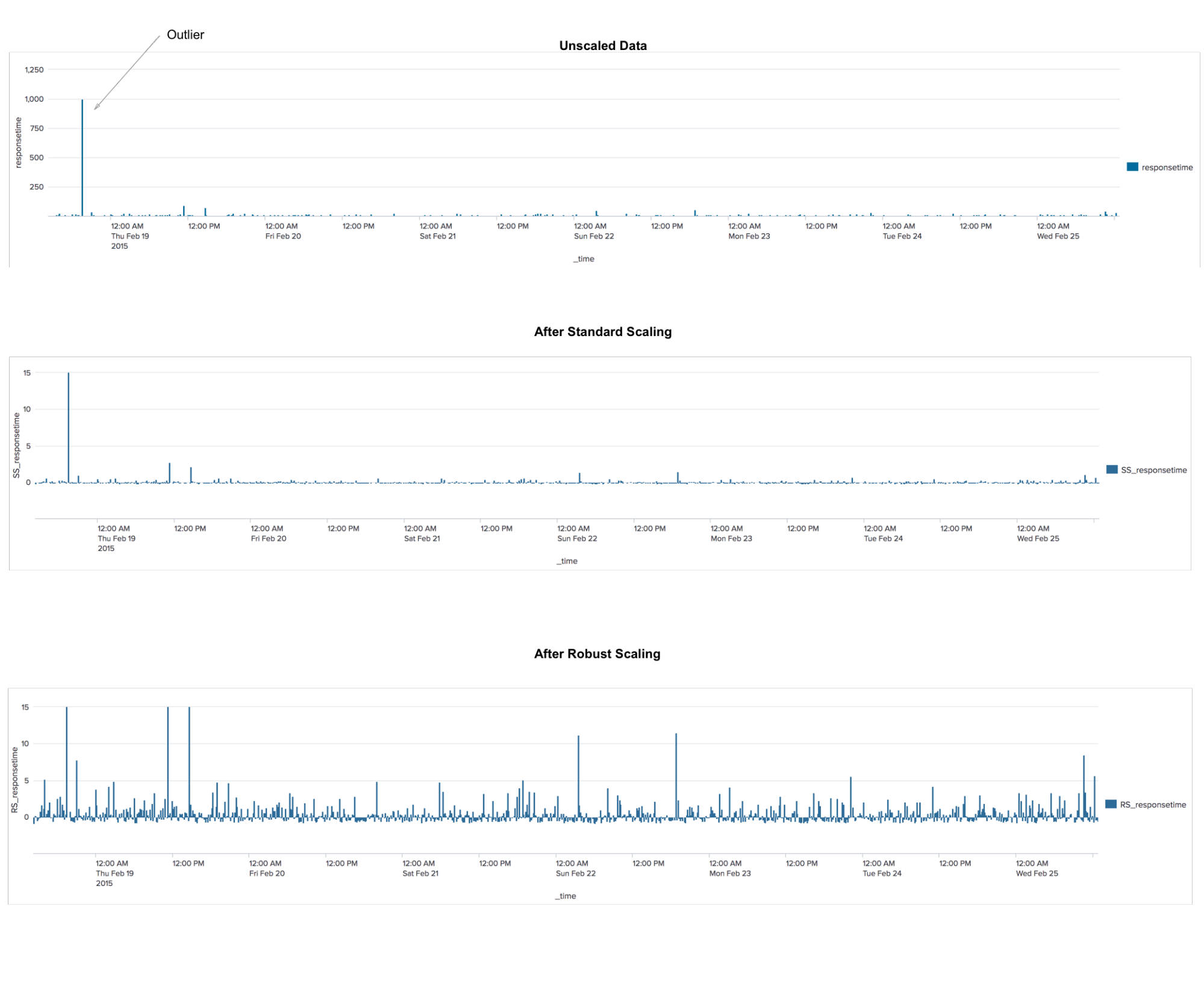
RobustscalerEste é um algoritmo de pré-processamento de dados. A aplicação é semelhante ao algoritmo StandardScaler, que transforma os dados para que, para cada característica, a média seja 0 e a variação seja 1, resultando em todas as características na mesma escala. No entanto, esse dimensionamento não garante o recebimento de nenhum valor mínimo e máximo específico dos atributos. O RobustScaler é semelhante ao StandardScaler, pois, como resultado de sua aplicação, os recursos terão a mesma escala. No entanto, o RobustScaler usa a mediana e os quartis em vez da média e variância. Isso permite ao RobustScaler ignorar erros de medição ou outliers, o que pode ser um problema para outros métodos de dimensionamento.
 TFIDF
TFIDFUma medida estatística usada para avaliar a importância de uma palavra no contexto de um documento que faz parte de uma coleção de documentos. O princípio é o seguinte: se uma palavra é freqüentemente encontrada em um documento, embora raramente seja encontrada em todos os outros documentos, portanto, essa palavra é de grande importância para o próprio documento.
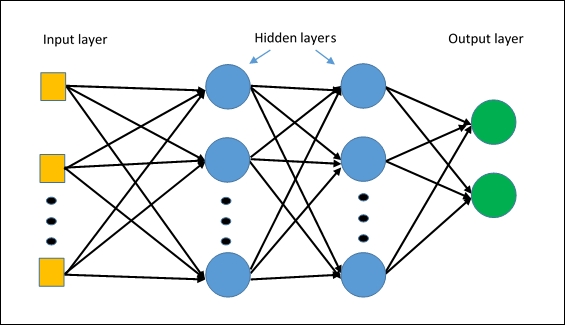
MLPClassifierO primeiro algoritmo de rede neural no Splunk. O algoritmo é construído com base em um
perceptron multicamada , que captura relações não lineares nos dados.
Administração
Nas novas versões, a administração do aplicativo mudou significativamente.
Primeiramente, foi adicionado um
modelo de acesso a vários modelos e experimentos.
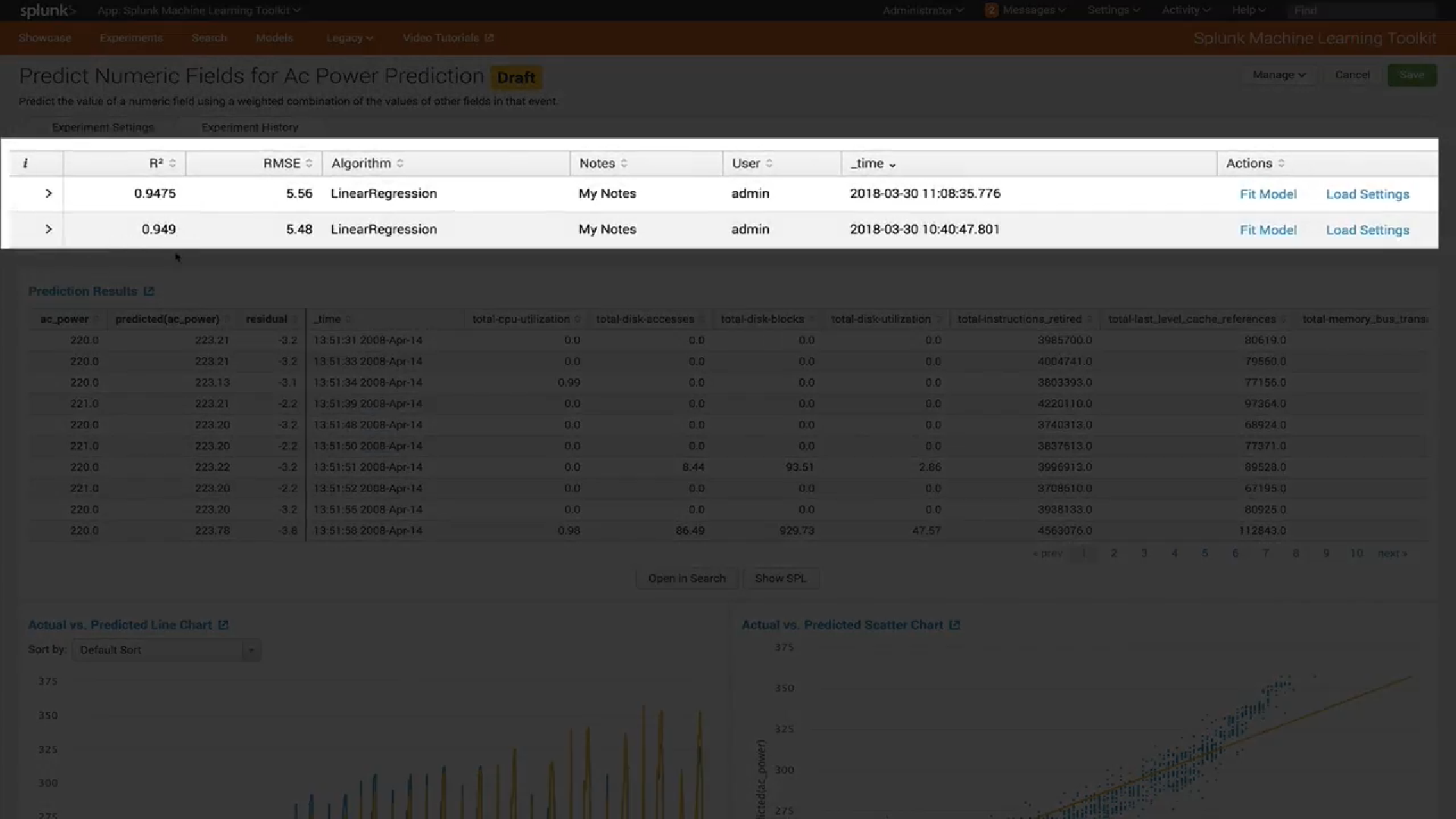
Em segundo lugar, uma nova interface para
gerenciar modelos foi introduzida. Agora você pode ver facilmente quais tipos de modelos você possui, verificar as configurações de cada modelo (por exemplo, quais variáveis foram usadas para treiná-lo) e visualizar ou atualizar as configurações de compartilhamento de cada modelo.
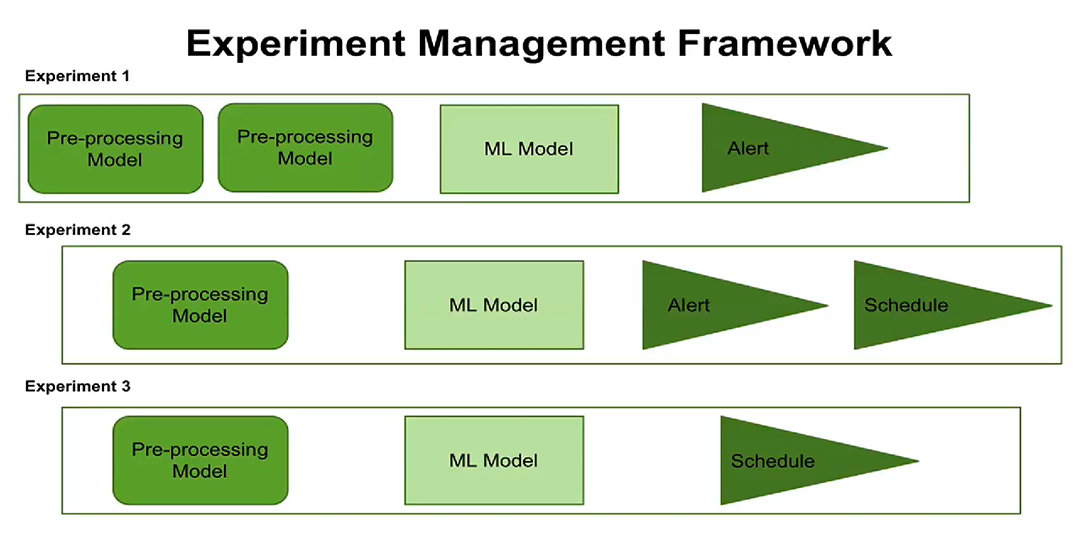
Terceiro, o surgimento do conceito de gerenciamento de experimentos. Agora você pode
configurar a execução de experimentos em um agendamento, configurar alertas. Os usuários podem ver quando cada experiência está programada para executar, quais etapas e parâmetros de processamento estão configurados para cada experiência.
O novo conceito de gerenciamento de experimentos agora oferece a oportunidade de criar e gerenciar vários experimentos de uma só vez, para registrar quando esses experimentos foram realizados e quais resultados foram obtidos.
Visualização
Na versão mais recente do MLTK 3.4, um novo tipo de visualização foi adicionado. O famoso
Box Plot ou, como também chamamos, "Caixas com bigode".
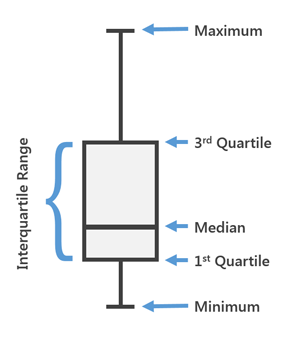
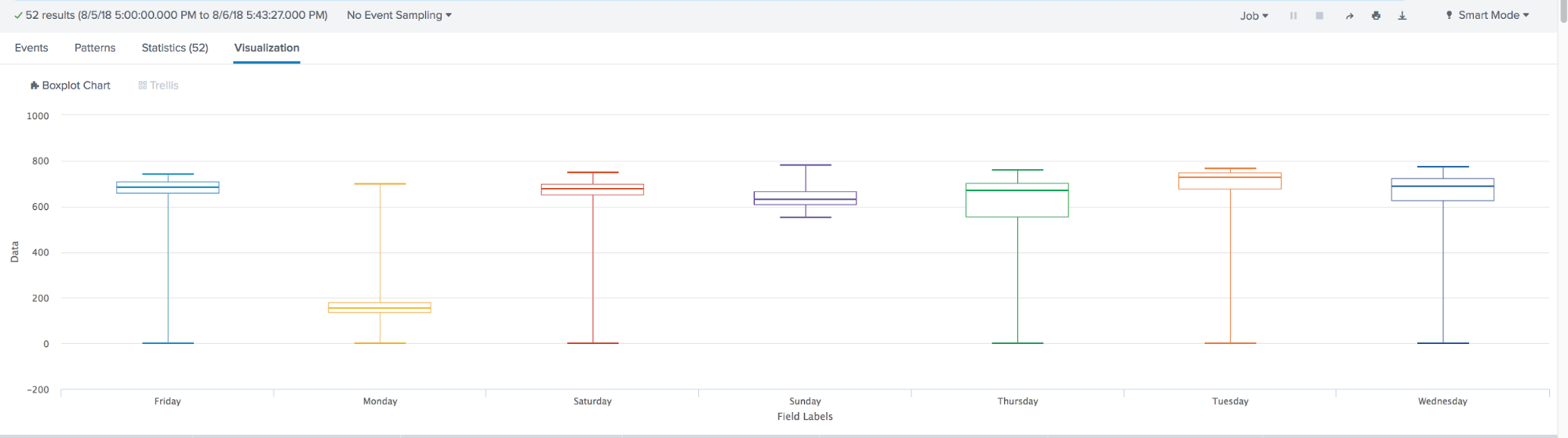
O Box Plot é usado na estatística descritiva, e é possível ver convenientemente a mediana (ou, se necessário, a média), os quartis inferior e superior, os valores mínimo e máximo da amostra e dos valores extremos. Várias dessas caixas podem ser desenhadas lado a lado para comparar visualmente uma distribuição com outra. As distâncias entre diferentes partes da caixa permitem determinar o grau de dispersão (dispersão) e assimetria dos dados e identificar discrepantes.
Resumindo, ao longo do ano, o aprendizado de máquina na Splunk deu um grande passo à frente. Apareceu:
- Muitos novos algoritmos integrados, como: ACF, PACF, ARIMA, Gradient BoostingClassifier, Gradient Boosting Regressor, X-means, RobustScaler, TFIDF, MLPClassifier;
- Modelo de acesso baseado em função e capacidade de gerenciar modelos e experimentos;
- Gráfico da caixa de visualização
