Este relatório de Alexey Milovidov, chefe da equipe de desenvolvimento ClickHouse, é uma visão geral dos poucos sistemas de banco de dados conhecidos. Alguns deles estão desatualizados, outros interromperam seu desenvolvimento e foram abandonados. Alexey chama a atenção para soluções arquitetônicas interessantes nos exemplos listados, entende o destino deles e explica quais requisitos o seu projeto de código aberto deve atender.
- Meu relatório será sobre bancos de dados. Deixe-me perguntar imediatamente, qual mapa do metrô é mostrado neste slide? Todas as linhas seguem uma direção.
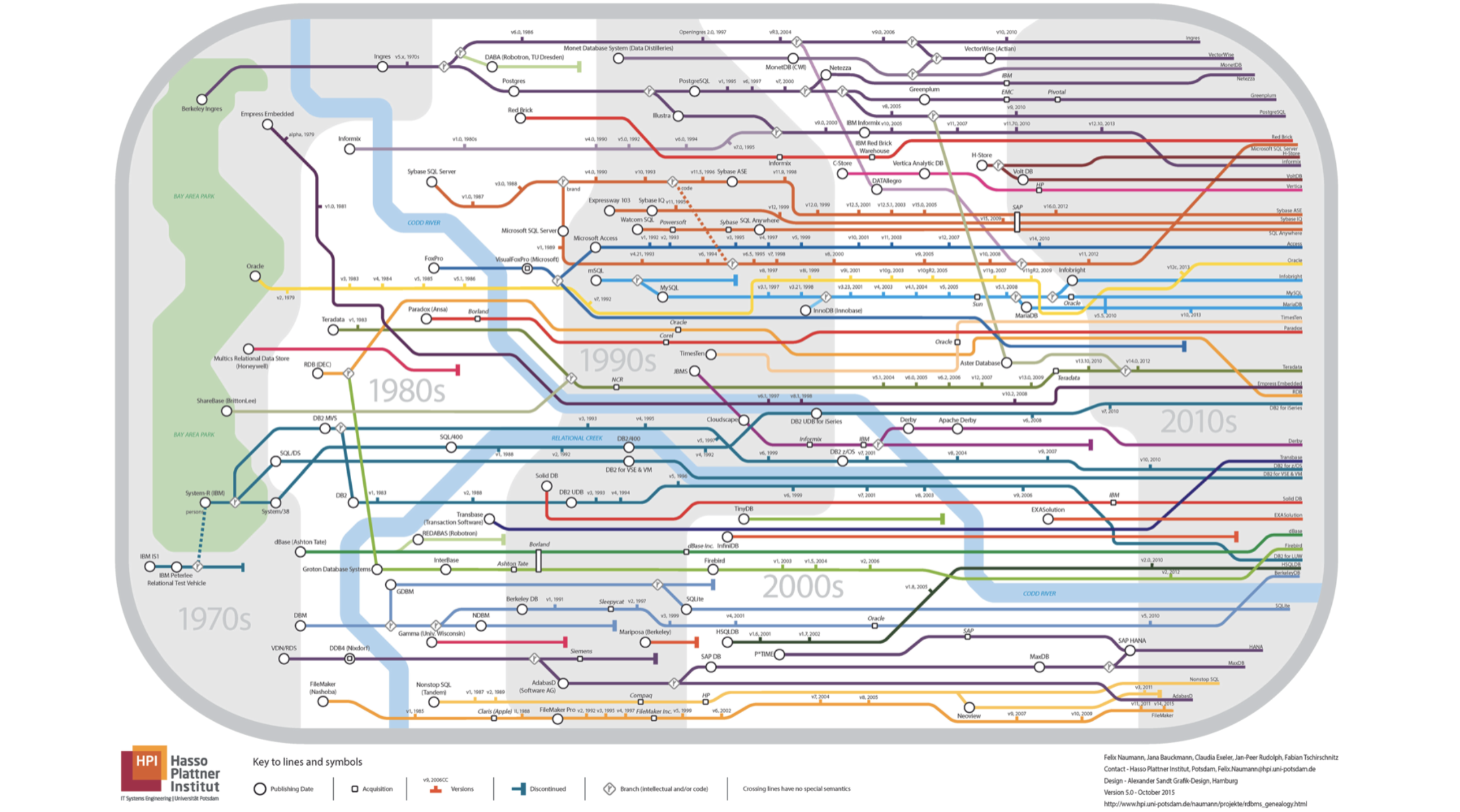
Tudo está errado, não é nada subterrâneo, é o pedigree dos bancos de dados relacionais. Se você olhar de perto, verá que o rio é o rio
Kodda .
Eu não vou falar sobre eles. O que poderia ser mais chato do que falar sobre MySQL, PostgreSQL ou algo assim? Em vez disso, falarei sobre a criação de bancos de dados.

Montagem manual. Sistemas quase desconhecidos para qualquer pessoa. Eles são projetados por uma pessoa ou há muito abandonados.

O primeiro exemplo é EventQL. Por favor, levante a mão se você já ouviu falar deste sistema. Nem uma pessoa, exceto aqueles que trabalham na Yandex e já ouviram meu relatório. Portanto, não foi em vão que incluí esse sistema na minha análise.

Este é um mecanismo de banco de dados de coluna distribuída projetado para processamento e análise de eventos. Ele realiza consultas SQL muito rápidas, de código aberto desde 26 de julho de 2016, escrito em C ++, o ZooKeeper é usado para coordenação, não há dependências além dele. Isso me lembra algo. Nosso maravilhoso sistema, todo mundo já sabe o nome. EventQL é algo como ClickHouse, mas melhor. Distribuído, massivamente paralelo, orientado a colunas, dimensiona para petabytes, solicitações de alcance rápido - tudo está claro, temos tudo. Suporte quase completo para o SQL 2009, inserções e atualizações em tempo real, distribuição automática de dados pelo cluster e até a linguagem ChartSQL para descrever gráficos. Que incrível! É isso que prometemos a todos e o que não temos.
No entanto, o último commit, quase um ano atrás, existe um site que não carrega, você precisa assistir através do web.archive.org.
Pergunte no GitHub - quais são seus planos de desenvolvimento, o que acontecerá a seguir? Ninguém respondeu.
O sistema possui dois desenvolvedores. Um é desenvolvedor de back-end, o segundo é front-end. Não mostrarei quais deles talvez adivinhem por si mesmos. Feito por DeepCortex. O nome parece familiar, mas há muitas empresas com a palavra Deep e a palavra Cortex. DeepCortex é uma empresa desconhecida de Berlim. O sistema foi desenvolvido desde 2014, foi desenvolvido internamente por um longo tempo, depois foi lançado em código aberto e abandonado um ano depois.

Parece algo assim: eles a jogaram no ar e pensaram: de repente alguém a notaria ou ela voaria para algum lugar. Infelizmente não.
Outra desvantagem é a licença AGPL, que é relativamente inconveniente. Mesmo que não imponha restrições sérias à sua empresa, ainda é temido, o departamento jurídico pode ter alguns pontos contra.
Comecei a procurar o que aconteceu, por que não está sendo desenvolvido. Eu olhei para a conta do desenvolvedor, em princípio está tudo bem, a pessoa vive, continua a confirmar, no entanto, todo o commit no repositório privado. Não está claro o que aconteceu.

A pessoa mudou-se para outra empresa e perdeu o interesse no suporte, ou as prioridades da empresa mudaram ou algumas circunstâncias da vida. Talvez a própria empresa não tenha se sentido muito mal e o código aberto tenha sido criado apenas por precaução. Ou apenas cansado. Não sei a resposta exata. Se alguém souber, por favor me diga.

Mas tudo isso não foi feito em vão. Primeiro de tudo, ChartSQL para a descrição declarativa dos gráficos. Agora, algo semelhante é usado no sistema de visualização de dados Tabix para ClickHouse. O EventQL possui um blog, no entanto, atualmente não está disponível, você deve procurar no web.archive.org, existem arquivos .txt. O sistema é implementado com muita competência e, se você estiver interessado, pode ler o código e ver soluções arquiteturais interessantes.
Isso é tudo sobre ela por enquanto. E o próximo sistema vence a todos, o que considerarei, porque tem o melhor e mais delicioso nome. Sistema Alenka.
Eu queria adicionar uma foto da embalagem de chocolate, mas receio que haja problemas de direitos autorais. O que é Alenka?

Este é um DBMS analítico que executa consultas em aceleradores gráficos. Openors, licença Apache 2, 1103 estrelas, escrita em CUDA, um pouco de C ++, um desenvolvedor de Minsk. Existe até um driver JDBC. Abertura desde 2012. No entanto, desde 2016, por algum motivo, o sistema não se desenvolve mais.

Este é um projeto pessoal, não de propriedade da empresa, mas realmente um projeto de uma pessoa. Esse é um protótipo de pesquisa para explorar as possibilidades de como processar dados rapidamente na GPU. Existem testes interessantes de Mark Litvinchik, se estiver interessado, você pode olhar para o blog. Provavelmente, muitos já viram seus testes lá, de que o ClickHouse é o mais rápido.

Não tenho resposta por que o sistema foi abandonado, apenas suposições. Agora, uma pessoa trabalha para a nVidia, provavelmente isso é apenas uma coincidência.

Este é um ótimo exemplo, porque aumenta o interesse, os horizontes, você pode ver e entender como fazê-lo, como o sistema pode funcionar na GPU.
Mas se você estiver interessado neste tópico, há várias outras opções. Por exemplo, o sistema MapD.
Quem ouviu falar sobre o MapD? Ofender. Esta é uma startup ousada, também desenvolvendo um banco de dados da GPU. Lançado recentemente em código aberto sob a licença Apache 2. Não sei para que serve, bom ou vice-versa. Esta inicialização é tão bem-sucedida que é apresentada em código aberto ou vice-versa, e será fechada em breve.
Existe um PGStorm. Se você é versado no PostgreSQL, deve ouvir sobre o PGStorm. Também de código aberto, desenvolvido por uma pessoa. Dos sistemas fechados, há BrytlytDB, Kinetica e a empresa russa Polymatic, que fabrica o sistema de Business Intelligence. Análise, visualização e tudo isso. E para processamento de dados, ele também pode usar aceleradores gráficos, pode ser interessante ver.

É possível fazer algo mais legal do que uma GPU? Por exemplo, havia um sistema que processava dados em um FPGA. Este é o Kickfire. Ela entregou sua solução na forma de ferro com o software imediatamente. É verdade que a empresa foi fechada há muito tempo, essa solução era bastante cara e não podia competir com outros gabinetes desse tipo quando algum fornecedor traz esse gabinete para você e tudo funciona de maneira mágica.
Além disso, existem processadores que contêm instruções para acelerar o SQL - SQL no Silicon nos novos modelos de processador SPARC. Mas você não precisa pensar que escreve join no Assembler, ele não está lá. Existem instruções simples que fazem a descompressão usando alguns algoritmos simples e um pouco de filtragem. Em princípio, ele não pode apenas acelerar o SQL. Por exemplo, os processadores Intel têm um conjunto de instruções SSE 4.2 para processar seqüências de caracteres. Quando apareceu em 2008, o site da Intel tinha um artigo intitulado "Usando novas instruções do processador Intel para acelerar o processamento de XML". É sobre o mesmo aqui. Instruções úteis para acelerar um banco de dados também podem ser usadas.
Outra opção muito interessante é transferir a tarefa de filtrar dados parcialmente para o SSD. Agora, os SSDs tornaram-se bastante poderosos, este é um computador pequeno com um controlador e, basicamente, você pode fazer upload de seu código para ele, se realmente tentar. Seus dados serão lidos a partir do SSD, mas serão filtrados imediatamente e transferirão apenas os dados necessários para o seu programa. Muito legal, mas tudo isso ainda está em fase de pesquisa. Aqui está um artigo sobre VLDB, leia.
Além disso, um certo ViyaDB.

Foi inaugurado há apenas um mês. "Banco de dados analítico para dados não classificados." Por que “não classificado” é colocado no nome, não está claro por que essa ênfase deve ser feita. O que, em outros bancos de dados apenas com os classificados, você pode trabalhar?
Está tudo bem, o código-fonte do GitHub, licença Apache 2.0, escrito no C ++ mais moderno, está tudo bem. Um desenvolvedor, mas nada.

O que eu mais gostei, onde você pode dar um exemplo, é a excelente preparação para o lançamento. Portanto, estou surpreso que ninguém tenha ouvido. Existe um site maravilhoso, há documentação, há um artigo sobre Habré, há um artigo sobre Medium, LinkedIn, Hacker News. E daí? Tudo isso é em vão? Você não olhou para nada disso. Aqui eles dizem, Habr não é um bolo. Bem, talvez, mas uma grande coisa.
Como é esse sistema?

Dados na RAM, o sistema está trabalhando com dados agregados. A pré-agregação está em andamento. Sistema para consultas analíticas. Existe algum suporte inicial ao SQL, mas está apenas começando a ser desenvolvido, inicialmente as consultas precisavam ser escritas em algum tipo de JSON. Entre os recursos interessantes, você solicita e grava código para C ++ na sua solicitação, esse código é gerado, compilado, carregado dinamicamente e processa seus dados. Como sua solicitação seria processada da melhor maneira possível. Código C ++ idealmente especializado, escrito para sua solicitação. Há escala e o Consul é usado para coordenação. Isso também é uma vantagem, como você sabe, é mais legal que o ZooKeeper. Ou não Não tenho certeza, mas parece que sim.
Algumas das premissas das quais esse sistema procede são algo contraditórios. Sou um grande entusiasta de várias tecnologias e não quero repreender ninguém. Esta é apenas a minha opinião, talvez eu esteja errado.
A premissa é que, para registrar constantemente novos dados no sistema, inclusive retroativamente, uma hora atrás, um dia atrás, um evento uma semana atrás. E, ao mesmo tempo, execute imediatamente consultas analíticas nesses dados.

O autor afirma que, para isso, o sistema deve estar necessariamente na memória. Isto não é verdade. Se você estiver interessado no motivo, pode ler o artigo "Evolução das estruturas de dados no Yandex.Metrica". Uma pessoa na sala estava lendo.
Não é necessário armazenar dados na RAM. Não direi o que precisa ser feito e qual sistema instalar se você estiver interessado em resolver esse problema.

Que bom você pode aprender? Uma solução arquitetônica interessante é a geração de código em C ++. Se você está interessado neste tópico, pode prestar atenção a esse projeto de pesquisa DBToaster. Pesquisa do Instituto EPFL, disponível no GitHub, Apache 2.0. Código Scala, você fornece uma consulta SQL, esse código gera fontes C ++ para você, que lê e processa dados de algum lugar da maneira mais ideal. Provavelmente, mas não tenho certeza.

Essa é apenas uma abordagem para geração de código, para processamento de consultas. Existe uma abordagem ainda mais popular - geração de código LLVM. A linha inferior é que seu programa, por assim dizer, escreve dinamicamente o código no Assembler. Bem, na verdade não, no LLVM. Há o MemSQL como exemplo. Originalmente, é um banco de dados OLTP, mas também é adequado para análises. Fechado, proprietário, o C ++ foi originalmente usado lá para geração de código. Então eles mudaram para o LLVM. Porque Você escreveu o código C ++, precisa compilá-lo e leva cinco segundos preciosos para fazer isso. E bem, se suas solicitações forem mais ou menos iguais, você poderá gerar o código uma vez. Mas quando se trata de análise, você tem solicitações ad hoc e é bem possível que cada vez que elas não sejam apenas diferentes, mas que tenham uma estrutura diferente. Se a geração de código estiver no LLVM, levará milissegundos ou dezenas de milissegundos, diferentemente, às vezes mais.
Outro exemplo é o Impala. Também usa LLVM. Mas se falamos sobre o ClickHouse, também há geração de código, mas principalmente o ClickHouse depende do processamento de solicitações vetoriais. Um intérprete, mas que funciona em matrizes, portanto, funciona muito rápido, como sistemas como o kdb +.
Outro exemplo interessante. O melhor logotipo na minha análise.

O primeiro e único sistema de gerenciamento de banco de dados relacional de código aberto projetado especificamente para data warehousing e business intelligence. Disponível no GitHub, a licença do Apache 2. Havia uma GPL, mas foi alterada e corretamente executada. Está escrito em Java. Última confirmação há seis anos. Inicialmente, o sistema foi desenvolvido pela organização sem fins lucrativos Eigenbase, o objetivo da organização era desenvolver uma estrutura, uma base de código máxima expansível para bancos de dados, que não são apenas OLTP, mas, por exemplo, uma para análise, o próprio LucidDB e o outro StreamBase para processar dados de streaming.

O que aconteceu seis anos atrás? Boa arquitetura, base de código bem extensível, mais de um desenvolvedor. Ótima documentação. Nada está carregando agora, mas você pode vê-lo através do WebArchive. Ótimo suporte para SQL.

Mas algo está errado. A idéia é boa, mas isso foi feito por uma organização sem fins lucrativos para algumas doações, e algumas startups estavam por perto. Por alguma razão, tudo estava dobrado. Eles não conseguiram encontrar financiamento, não havia entusiastas e todas essas startups fecharam há muito tempo.
Mas não é tão simples. Tudo isso não foi em vão.

Existe essa estrutura - Apache Calcite. É uma espécie de front-end para bancos de dados SQL. Ele pode analisar consultas, analisar, executar todos os tipos de transformações de otimização, elaborar um plano de execução de consultas e fornecer um driver JDBC pronto.
Imagine que você acordou de repente, estava de bom humor e decidiu desenvolver seu DBMS relacional. Você nunca sabe, isso acontece. Agora você pode usar o Apache Calcite, basta adicionar armazenamento de dados, leitura de dados, processamento de consultas, replicação, tolerância a falhas, sharding, tudo é simples. O Apache Calcite é baseado na base de código LucidDB, que era um sistema tão avançado que eles tiraram todo o frontend de lá, que agora é usado de alguma forma adaptada em quase todos os produtos Apache, Hive, Drill, Samza, Storm e até MapD, apesar de está escrito em C ++, de alguma forma conectado esse código em Java.

Todos esses sistemas interessantes usam o Apache Calcite.
O próximo sistema é o InfiniDB. A partir desses nomes tonto.

Havia o Calpont, originalmente InfiniDB, um sistema proprietário, e os gerentes de vendas entraram em contato com nossa empresa e nos venderam esse sistema. Foi interessante participar disso. Eles dizem que um DBMS analítico, maravilhoso, mais rápido que o Hadoop, orientado a colunas, naturalmente, todas as consultas funcionará rapidamente. Mas então eles não tinham um cluster, o sistema não foi dimensionado. Eu digo que não há cluster - não podemos comprar. Olha, depois de meio ano que a versão do InfiniDB 4.0 foi lançada, adicionamos integração com o Hadoop, dimensionamento, está tudo bem.
Seis meses se passaram e o código fonte está disponível em código aberto. Eu então pensei no que estava sentado, desenvolvendo algo, devemos levá-lo, há algo pronto.
Eles começaram a olhar como se adaptar, usar. Um ano depois, a empresa faliu. Mas o código fonte está disponível.
Isso é chamado de código aberto post-mortem. E isso é bom. Se uma empresa não se sente muito bem, é necessário que pelo menos algum legado permaneça, para que outros possam usá-lo.

Foi tudo em vão. Com base na fonte InfiniDB, o MariaDB agora tem um mecanismo de tabela chamado ColumnStore. De fato, este é o InfiniDB. A empresa não está mais lá, as pessoas agora trabalham em outros lugares, mas o legado permanece, e isso é maravilhoso. Todo mundo sabe sobre o MariaDB. Se você o usar e precisar prender o mecanismo analítico orientado a colunas rapidamente, poderá usar o ColumnStore. Em segredo, direi que essa não é a melhor solução. Se você precisa da melhor solução, sabe a quem recorrer e o que usar.
Outro sistema com a palavra Infini no nome. Eles têm um logotipo estranho, esta linha parece estar curvada. E outra fonte incompreensível, por algum motivo, não há antialiasing, como se fosse pintado no Paint. E todas as letras são grandes, provavelmente para intimidar os concorrentes.

Sou um entusiasta de todos os tipos de tecnologias, muito respeitoso com todos os tipos de soluções interessantes. Não estou brincando, não precisa pensar.
Como era esse sistema? Isso não é mais um sistema analítico, é OLTP. Um sistema para processar transações em escalas extremas. Existe um site, as vantagens deste sistema é que o site está carregando. Porque quando olho para todos os outros, estou acostumado ao fato de que haverá estacionamento no domínio ou algo mais. Fontes estão disponíveis. Agora a GPL. Antes era AGPL, mas, felizmente, o autor mudou rapidamente. Escrito em C ++, mais de um desenvolvedor, publicado em código aberto em novembro de 2013 e já abandonado em janeiro de 2014. Um mês e meio. Porque Qual é o objetivo? Por que fazer isso?

Banco de dados OLTP com suporte inicial a SQL, um projeto pessoal, nenhuma empresa está por trás disso. O próprio autor do Hackers News diz que postou em código aberto na esperança de atrair entusiastas que trabalharão neste produto.

Essa esperança está sempre fadada ao fracasso. Você tem uma ideia, você é ótimo, é um entusiasta. Então você tem que fazer essa ideia. É improvável que mais alguém se inspire nisso. Ou você terá que trabalhar duro para inspirar alguém. Portanto, é difícil esperar que do nada do outro lado do mundo apareça uma pessoa que começará a adicionar o código de outra pessoa no GitHub.
Em segundo lugar, talvez apenas subestime a complexidade. O desenvolvimento do DBMS não é uma aventura por 20 minutos. É difícil, longo, caro.
Este é um caso muito interessante, muitos já ouviram o RethinkDB. Este exemplo não é uma base analítica, não OLTP, mas orientada a documentos.

Este sistema mudou seu conceito muitas vezes. Repensado. Digamos, em 2011, foi escrito que este é um mecanismo para o MySQL, que é cem vezes mais rápido no SSD, como foi escrito no site oficial. Foi dito que este é um sistema com protocolo memcached, também otimizado para SSD. E depois de um tempo, é um banco de dados para aplicativos em tempo real. Ou seja, para assinar dados e receber atualizações diretamente em tempo real. Digamos que todos os tipos de bate-papos interativos, jogos online. Uma tentativa de encontrar um nicho. -, JSON. MongoDB. . MongoDB , ? MongoDB . , , «PostgreSQL ».
? — . . , .
RethinkDB? , RAFT. , , , . JSON, - LINQ . ReQL, ++, , ++.

. . , , , , . , , . 20938 GitHub. - .

, , , , , . Porque ?

, 2009 , , , . , , 2016 . , , , . , , RethinkDB, , , The Linux Foundation. AGPL Apache 2, . , — .

, , , , , , . , .
, , . , - , , , , .
. , , . , XML 15 .
- , 2000-, . , XML . - - , . , .

, Sedna. XML , . , . , . , Sedna, , , , . , .
2013, , . XML , , .
— .
— , , . garret.ru, , . , . , , , . .

. 2014 — IMCS, PostgreSQL, . PostgreSQL, SQL, , . select, . -, . , , , . , . , , , - . , .
, - ? .

, , ? , — . : , - , . , . .
— . , , . , , .
— . , -. - , — , , , -.
, , , .
— , ? , - .
, , . . , , , .
— - - . -, KPHP.
— . , , , .

, , : , , , ? — . , . , . ? : , .
. , , . , .
. , - , , multimodel DB, , , OLTP, , , , . , ? , , - . - -, , , , . , .
Suporte confiável da empresa matriz. Não há comentários. Não é uma licença restritiva, para que outras empresas não assustem o departamento jurídico, essas pessoas têm medo de tudo. Os benefícios do seu sistema devem vir de razões fundamentais. Digamos, se você possui um banco de dados para processamento XML, isso não é muito bom. Talvez ninguém mais precise armazenar dados em XML. E se você tem um banco de dados orientado a documentos, esse é outro. Todo mundo precisa manter documentos, e não importa o que exatamente. Além disso, o apoio ao desenvolvimento da comunidade é muito importante para um bom código aberto. Isso significa não apenas que você precisa reter solicitações pull. Isso significa - você precisa que as pessoas sintam que você é, existe, responde a perguntas, que o produto está em desenvolvimento. É isso que criará um código aberto bom e ao vivo. Isso é tudo, obrigado.